目录
概述
RDD的依赖
DAG和Stage
DAG执行流程图形成和Stage划分
Stage内部流程
Spark Shuffle
Spark中shuffle的发展历程
优化前的Hash shuffle
经过优化后的Hash shuffle
Sort shuffle
Sort shuffle的普通机制
Job调度流程
Spark RDD并行度
概述
Spark内核调度任务:
1.构建DAG有向无环图
2.划分stage夹断
3.Driver底层的运转
4.分区的划分(线程)
的Spark内核调度的目的:尽可能用最少的资源高效地完成任务计算
RDD的依赖
RDD的依赖:一个RDD的形成可能由一个或者多个RDD得到的,此时这个RDD和之前的RDD之间产生依赖关系
Spark中,RDD之间的依赖关系,只要有两种类型:宽依赖和窄依赖
窄依赖:
作用:能够让Spark程序并行计算,也就是一个分区数据计算出现问题的时候,其它分区不受影响
特点:父RDD的分区和子RDD的分区是一对一关系,也就是父RDD分区的数据会整个被下游子RDD的分区接收

宽依赖:
作用:划分stage的重要依据,宽依赖也叫shuffle依赖
特点:父RDD的分区和子RDD的分区关系是一对多的关系,也就是父RDD的分区数据会被划成多份给到下游子RDD的多个分区做接收
注意:如果有宽依赖,shuffle下游的其他操作,必须等待shuffle执行完成以后才能够继续执行,为了避免数据的不完整
算子中一般以ByKey结尾的会发生shuffle;另外是重分区算子会发生shuffle

DAG和Stage
DAG:有向无环图,只要描述一段执行任务,从开始一直往下走,不允许出现回调操作
Spark应用程序中,遇到一个Action算子,就会触发一个JOB任务的产生
对于每个JOB的任务,都会产生一个DAG执行流程图,流程图的形成的层级关系如下:
层级关系:
1.一个spark应用程序→遇到一个Action算子,就会触发形成一个JOB任务
2.一个JOB任务只有一个DAG有向无环图
3.一个DAG有向无环图→有多个stage
4.一个stage→有多个Task线程
5.一个RDD→有多个分区
6.一个分区会被一个Task线程所处理
DAG执行流程图形成和Stage划分

1.spark应用程序遇到Action算子后,就会触发一个JOB任务的产生,JOB任务就会将它所依赖的算子全部加载进来,形成一个stage
2.接着从action算子从后往前回溯,遇到窄依赖就将算子放在同一个stage中,如果遇到宽依赖,就划分形成新的stage,最后一直到回溯完成
Stage内部流程

默认并行度值的确认:
1.使用textFile读取HDFS上的文件,因此RDD分区数=max(文件的block块数量,defaultminpartition),继续需要知道defaultminpartition的值是多少
2.defaultminpartition=min(spark.default.parallelism,2)取最小值,最终确认spark.default.parallelism的参数值就能最终确认RDD的分区数有多少个
spark.default.parallelism参数值的确认:
1.如果有父RDD,就取父RDD的最大分区数
2.如果没有父RDD,根据集群模式进行取值
本地模式:机器的最大cpu核数
Mesos:默认是8
其它模式:所有执行节点上的核总数或2,以较大者为准
Spark Shuffle
Spark中shuffle的发展历程
1- 在1.1版本以前,Spark采用Hash shuffle (优化前 和 优化后)
2- 在1.1版本的时候,Spark推出了Sort Shuffle
3- 在1.5版本的时候,Spark引入钨丝计划(优化为主)
4- 在1.6版本的时候,将钨丝计划合并到sortShuffle中
5- 在2.0版本的时候,将Hash Shuffle移除,将Hash shuffle方案移植到Sort Shuffle
优化前的Hash shuffle

存在的问题:
上游(map端)的每个Task会产生与下游Task个数相等的小文件个数,导致上游有非常多的小文件,下游(reduce端)来拉取文件的时候,会有大量的网络IO和磁盘IO过程,因为要打开和读取多个小文件
经过优化后的Hash shuffle

优化后的Hash shuffle:
变成了由每个Executor进程产生与下游Task个数相等的小文件数,这样可以大量减少小文件的产生,以及降低下游拉取文件时候的网络IO和磁盘IO过程
Sort shuffle

Sort shuffle分成了两种:普通机制和bypass机制,具体使用哪种由spark底层决定
Sort shuffle的普通机制
普通机制的运行过程:
每个上游task线程处理数据,数据处理完以后,先放在内存中,接着对内存中的数据进行分区,排序,将内存中的数据溢写到磁盘,形成一个个小文件,溢写完成后,将多个小文件合并成一个大的磁盘文件,并且针对每个大的磁盘文件,提供一个索引文件,接着是下游Task根据索引文件来读取相应的数据
Sort shuffle的bypass机制
bypass机制 :就是在普通机制的基础上,省略了排序的过程
bypass机制的触发条件:
1.上游的RDD数量不能超过100个
2.上游不能对数据进行提前聚合操作(因为提前聚合,需要先进行分组操作,而分组的操作实际上是有排序的操作)
Job调度流程
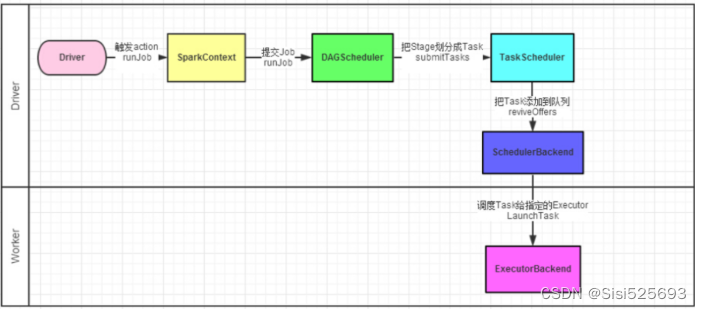
主要是讨论:在Driver内部,是如何调度任务
1.Driver进程启动后,底层PY4J创建SparkContext顶级对象,在创建该对象的进程中,还会创建另外两个对象,分别是:DAGScheduler和TaskScheduler
DAGScheduler:DAG调度器,将Job任务形成DAG有向无环图和划分Stage的阶段
TaskScheduler:Task调度器,将Task线程分配给到具体的Executor执行
2.一个saprk程序遇到一个action算子触发产生一个job任务,SparkContext将job任务给到DAG调度器,拿到job任务后,会将job任务形成有向无环图和划分stage阶段,并且确定每个stage有多少个Task线程,会将众多的Task线程放到TaskSet的集合中,DAG调度器将TaskSet集合给到Task调度器
3.Task调度器拿到TaskSet集合以后,将Task分配给到具体的Executor执行,底层是基于SchedulerBackend调度队列来实现的
4.Executor开始执行任务,并且Driver会监控各个Executor的执行状态,知道所有的Executor执行完成,就认为任务运行结束
5.Driver通知Namenote释放资源
Spark RDD并行度
整个Spark应用中,影响并行度的因素有以下两个原因:
1.资源的并行度:Executor数量和CPU核数以及内存的大小
2.数据的并行度:Task的线程和分区数量
一般将Task想层数量设置为CPU核数的2-3被,另外每个线程分配3-5GB的内存资源
说明: spark.default.parallelism该参数是SparkCore中的参数。该参数只会影响shuffle以后的分区数量。另外该参数对parallelize并行化本地集合创建的RDD不起作用。
import time
from pyspark import SparkConf, SparkContext
import os
# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 创建main函数
if __name__ == '__main__':
print("Spark入门案例: WordCount词频统计")
# 1- 创建SparkContext对象
conf = SparkConf()\
.set("spark.default.parallelism", "5")\
.setAppName('spark_wordcount_demo')\
.setMaster('local[*]')
# 设置并行度参数方式一
# conf.set("spark.default.parallelism", "4")
sc = SparkContext(conf=conf)
# 2- 数据输入
init_rdd = sc.textFile("file:///export/data/gz16_pyspark/01_spark_core/data/content.txt")
# 3- 数据处理
flatmap_rdd = init_rdd.flatMap(lambda line: line.split(" "))
map_rdd = flatmap_rdd.map(lambda word: (word,1))
# shuffle前分区数
print("shuffle前分区数",map_rdd.getNumPartitions())
result = map_rdd.reduceByKey(lambda agg,curr: agg+curr)
# shuffle后分区数
print("shuffle后分区数", result.getNumPartitions())
# 4- 数据输出
print(result.collect())
# 5- 释放资源
sc.stop()通过parallelize构建得到RDD的分区情况(了解):
from pyspark import SparkConf, SparkContext
import os
# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
print("并行化本地集合创建RDD")
# 1- 创建SparkContext对象
conf = SparkConf().setAppName('parallelize_rdd').setMaster('local[1]')
# 设置并行度参数
conf.set("spark.default.parallelism", 4)
sc = SparkContext(conf=conf)
# 2- 数据输入
# 并行化本地集合得到RDD
init_rdd = sc.parallelize([1,2,3,4,5])
# shuffle前分区数
print("分区数", init_rdd.getNumPartitions())
# 3- 数据处理
# 4- 数据输出
# 获取分区数
print(init_rdd.getNumPartitions())
# 获取具体分区内容
print(init_rdd.glom().collect())
# 5- 释放资源
sc.stop()