文章目录
- 10 Trade 交易操作
- 10.1 量化回测分析流程
- 10.2 Cerebro 类模块
- 10.3 案例:Trade 交易
- 10.4 实盘交易机器隐性规则
- 10.5 Stake 交易数额和 Trade 交易执行价格
10 Trade 交易操作
10.1 量化回测分析流程
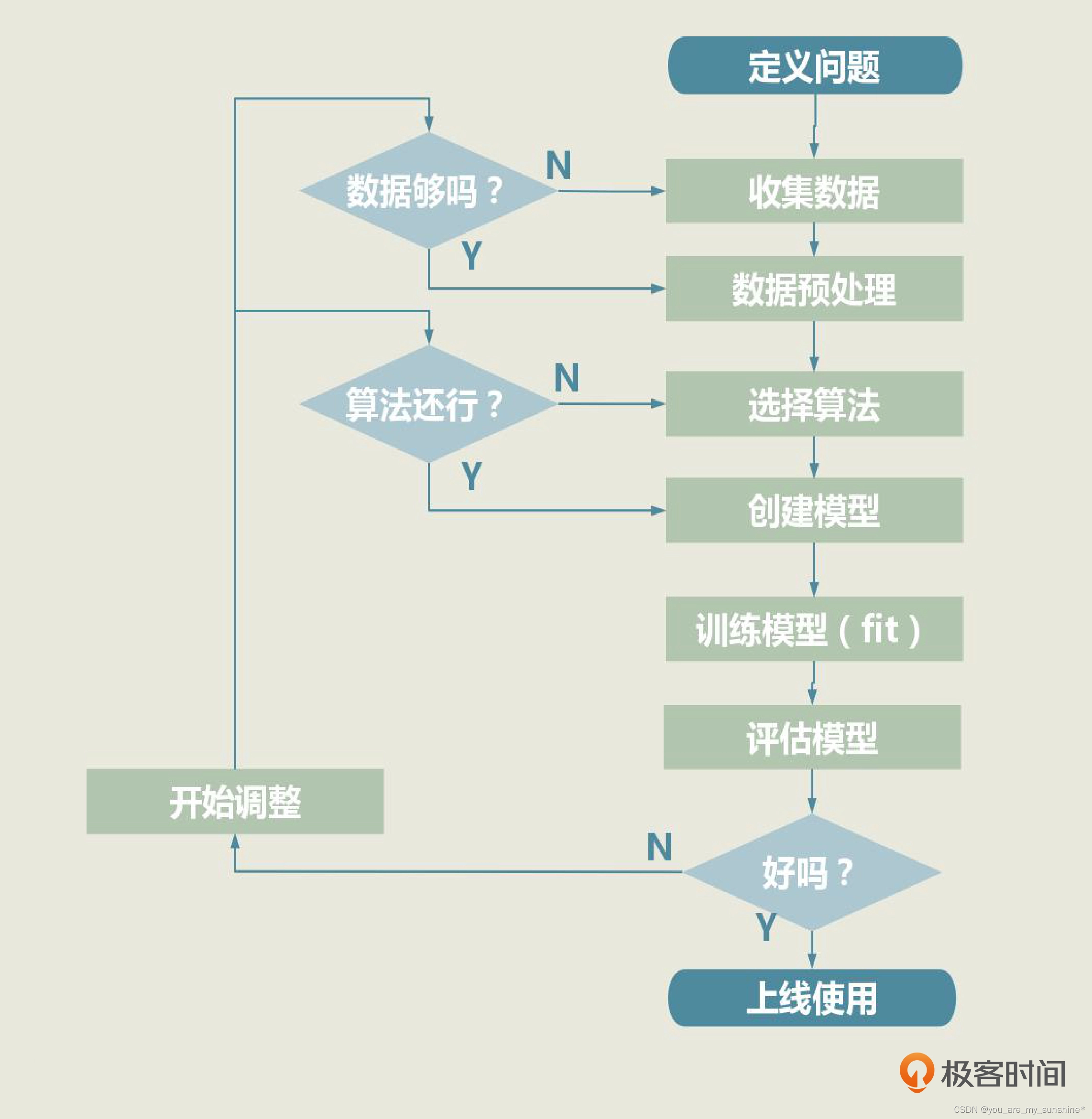
从本章开始讲解 BackTrader 的实盘操作。前面的章节讲过,一个完整的量化回测分析/交易流程可以分为四个步骤:
- 设置一个回测主函数;
- 设置量化回测参数;
- 调用量化回测程序,开始
run运行量化回测分析; - 回测数据分析,或者根据回测推荐结果进行交易。
其中第二步的量化回测参数的设置相对比较复杂,包括设置数据源、起始资金、回测数据、读取数据、添加数据,以及进行数据清洗等于处理工作。然后,添加策略和与策略相关的变量参数、策略分析参数。
第三步的调用量化回测程序和第一步的设置回测主函数类似,都很简单,通常都只有一行代码。
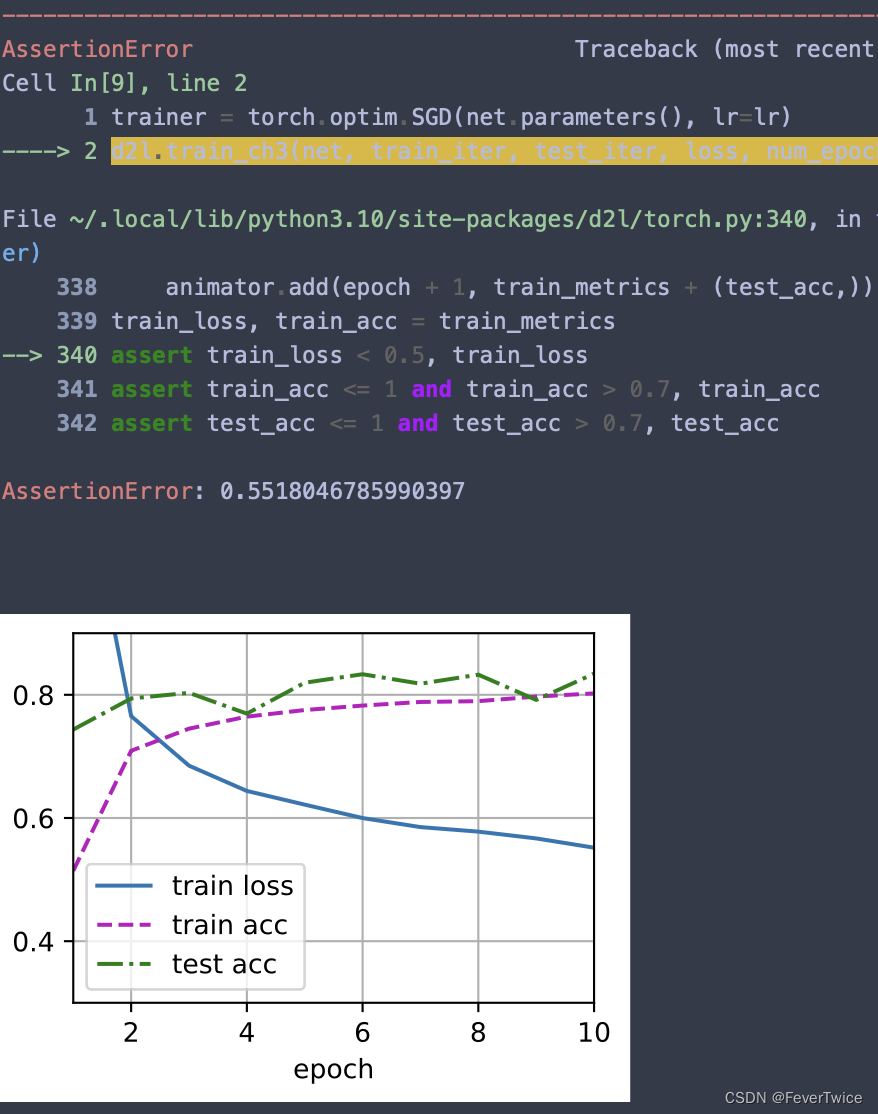
所有的量化策略在进行回测数据分析时, 最重要的指标就是ROI投资回报率。 在实盘操作查看收益图时, 大家最关心的也是ROI投资回报率。ROI指标重点在于检验策略模型的盈利性, 如果ROI投资回报率为负数, 或者低于市场的平均水平, 那么该策略模型后续就不要再使用了, 说明其稳定性和盈利性非常差。
10.2 Cerebro 类模块
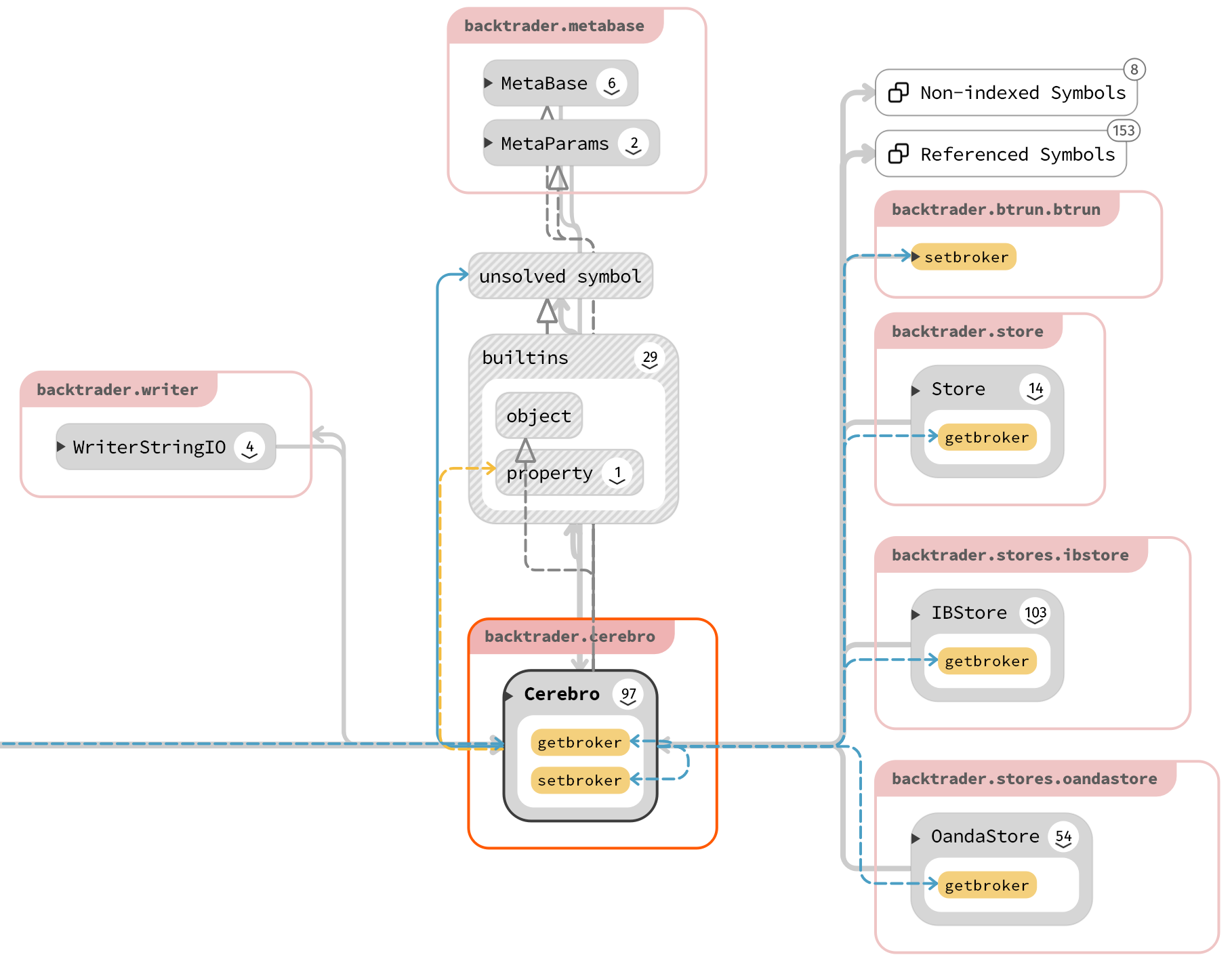
cerebro在西班牙语中是“大脑”的意思, 所以变量cerebro是BackTrader量化分析程序的全局主变量, 表示量化引擎源自BackTrader
的Cerebro模块库。Cerebro类的关系属性图如下:
10.3 案例:Trade 交易
本实例代码 :Cerebro.py 。
本案例的主流程部分代码如下:
print("\n#1,设置 BT 量化回测程序入口")
cerebro = bt.Cerebro() # create a "Cerebro" engine instance
print("\n#2,设置BT回测初始参数及策略")
print("\n\t#2-1,设置BT回测初始参数:起始资金等")
dmoney0 = 100000.0
cerebro.broker.setcash(dmoney0)
dcash0 = cerebro.broker.startingcash
print("\n\t#2-2,设置数据文件,需要按时间字段正序排序")
rs0 = os.path.abspath(os.path.dirname(__file__)) + "/../data/"
filename = "002046.SZ.csv"
fdat = rs0 + filename
print("\t@数据文件名:", fdat)
print("\t 设置数据BT回测运算:起始时间、结束时间")
print("\t 数据文件,可以是股票期货、外汇黄金、数字货币等交易数据")
print("\t 格式为:标准OHLC格式,可以是日线、分时数据")
t0stx, t9stx = datetime(2020, 1, 1), datetime(2021, 12, 31)
data = bt.feeds.YahooFinanceCSVData(dataname=fdat, fromdate=t0stx, todate=t9stx)
cerebro.adddata(data) # Add the data feed
print("\n\t#2-3,添加BT量化回测程序,对应的策略参数")
print("\n\t# 案例当中,使用的是MA均线策略")
cerebro.addstrategy(MyStrategy)
print("\n\t#2-4,添加broker经纪人佣金,默认为:千一")
cerebro.broker.setcommission(commission=0.001)
print("\n\t#2-5,设置每手交易数目为:10,不再使用默认值:1手")
cerebro.addsizer(bt.sizers.FixedSize, stake=10)
print("\n\t#2-6,设置addanalyzer分析参数")
cerebro.addanalyzer(SQN)
#
cerebro.addanalyzer(bt.analyzers.SharpeRatio, _name="SharpeRatio", legacyannual=True)
cerebro.addanalyzer(bt.analyzers.AnnualReturn, _name="AnnualReturn")
#
cerebro.addanalyzer(bt.analyzers.TradeAnalyzer, _name="TradeAnalyzer")
cerebro.addanalyzer(bt.analyzers.DrawDown, _name="DW")
#
# 周期回报率,不同时间周期
cerebro.addanalyzer(
bt.analyzers.TimeReturn, timeframe=bt.TimeFrame.Years, _name="timReturns"
)
# cerebro.addanalyzer(bt.analyzers.TimeReturn, timeframe=bt.TimeFrame.Months,_name='timReturns')
#
# 动态加权回报率 Variability-Weighted Return: Better SharpeRatio with Log Returns
cerebro.addanalyzer(bt.analyzers.VWR, _name="VWR")
print("\n#3,调用BT回测入口程序,开始执行run量化回测运算")
results = cerebro.run()
print("\n#4,完成BT量化回测运算")
dval9 = cerebro.broker.getvalue()
dget = dval9 - dcash0
kret = (dval9 - dcash0) / dcash0 * 100
print("\t 起始资金Starting Portfolio Value:%.2f" % dcash0)
print("\t 资产总值Final Portfolio Value:%.2f" % dval9)
print("\t 利润总额: %.2f," % dget)
print("\t ROI投资回报率Return on investment: %.2f %%" % kret)
# ---------
print("\n#5,analyzer分析BT量化回测数据")
strat = results[0]
anzs = strat.analyzers
#
dsharp = anzs.SharpeRatio.get_analysis()["sharperatio"]
#
dw = anzs.DW.get_analysis()
max_drowdown_len = dw["max"]["len"]
max_drowdown = dw["max"]["drawdown"]
max_drowdown_money = dw["max"]["moneydown"]
#
print("\t5-1夏普指数SharpeRatio : ", dsharp)
print("\t最大回撤周期 max_drowdown_len : ", max_drowdown_len)
print("\t最大回撤 max_drowdown : ", max_drowdown)
print("\t最大回撤(资金)max_drowdown_money : ", max_drowdown_money)
#
print("\t#5-2,常用量化分析数据")
print("\tSQN指数、AnnualReturn年化收益率,Trade交易分析报告")
print("\t可以通过修改参数,改为其他时间周期:周、月、季度等")
for alyzer in strat.analyzers:
alyzer.print()
# ----------
print("\n#6,绘制BT量化分析图形")
cerebro.plot(style="candle")
案例输出中有收盘价,还有买卖执行等信息:
2021-08-17, 当前收盘价Close, 9.72
2021-08-18, 买单执行BUY EXECUTED,成交价: 9.57,小计 Cost: 95.70,佣金 Comm 0.10
2021-08-18, 当前收盘价Close, 10.02
2021-08-19, 卖单执行SELL EXECUTED,成交价: 10.08,小计 Cost: 95.70,佣金 Comm 0.10
2021-08-19, 交易操盘利润OPERATION PROFIT, 毛利GROSS 5.10, 净利NET 4.90
本案例是一个完整的量化分析流程, 使用了一个完整的量化交易策略——MA均线策略。
第一步设置一个回测主函数, 代码如下:
print("\n#1,设置 BT 量化回测程序入口")
cerebro = bt.Cerebro() # create a "Cerebro" engine instance
第二步设置参数, 包括数据源、 起始资金的设置, 然后读取数据、添加数据, 代码如下:
print("\n#2,设置BT回测初始参数及策略")
print("\n\t#2-1,设置BT回测初始参数:起始资金等")
dmoney0 = 100000.0
cerebro.broker.setcash(dmoney0)
dcash0 = cerebro.broker.startingcash
print("\n\t#2-2,设置数据文件,需要按时间字段正序排序")
rs0 = os.path.abspath(os.path.dirname(__file__)) + "/../data/"
filename = "002046.SZ.csv"
fdat = rs0 + filename
print("\t@数据文件名:", fdat)
print("\t 设置数据BT回测运算:起始时间、结束时间")
print("\t 数据文件,可以是股票期货、外汇黄金、数字货币等交易数据")
print("\t 格式为:标准OHLC格式,可以是日线、分时数据")
t0stx, t9stx = datetime(2020, 1, 1), datetime(2021, 12, 31)
data = bt.feeds.YahooFinanceCSVData(dataname=fdat, fromdate=t0stx, todate=t9stx)
cerebro.adddata(data) # Add the data feed
在设置完量化分析数据源等基础数据后, 添加策略和与策略相关的变量参数。
MyStrategy 类是量化回测策略,需要完成 next、notify_order、notify_trade、stop 等函数。使用如下代码设置策略:
print("\n\t#2-3,添加BT量化回测程序,对应的策略参数")
print("\n\t# 案例当中,使用的是MA均线策略")
cerebro.addstrategy(MyStrategy)
在设置完量化回测策略后, 还需要设置交易佣金参数, 默认费用为千分之一, 交易数额默认是1手, 但本书案例中的交易数额设置为10手:
print("\n\t#2-4,添加broker经纪人佣金,默认为:千一")
cerebro.broker.setcommission(commission=0.001)
print("\n\t#2-5,设置每手交易数目为:10,不再使用默认值:1手")
cerebro.addsizer(bt.sizers.FixedSize, stake=10)
然后设置常用的分析参数, 如SQN指数、 Sharp指数、 回报率、MaxDown、 交易数据等, 代码如下:
print("\n\t#2-6,设置addanalyzer分析参数")
cerebro.addanalyzer(SQN)
#
cerebro.addanalyzer(bt.analyzers.SharpeRatio, _name="SharpeRatio", legacyannual=True)
cerebro.addanalyzer(bt.analyzers.AnnualReturn, _name="AnnualReturn")
#
cerebro.addanalyzer(bt.analyzers.TradeAnalyzer, _name="TradeAnalyzer")
cerebro.addanalyzer(bt.analyzers.DrawDown, _name="DW")
#
# 周期回报率,不同时间周期
cerebro.addanalyzer(
bt.analyzers.TimeReturn, timeframe=bt.TimeFrame.Years, _name="timReturns"
)
# cerebro.addanalyzer(bt.analyzers.TimeReturn, timeframe=bt.TimeFrame.Months,_name='timReturns')
#
# 动态加权回报率 Variability-Weighted Return: Better SharpeRatio with Log Returns
cerebro.addanalyzer(bt.analyzers.VWR, _name="VWR")
然后调用回测程序,开始运行回测分析:
print("\n#3,调用BT回测入口程序,开始执行run量化回测运算")
results = cerebro.run()
运行完成后,进行回测结果分析,包括回执量化分析表。
10.4 实盘交易机器隐性规则
大家对于BackTrader的使用属于准实盘交易阶段, 准实盘交易和实盘交易最主要的差别在于以下两个方面:
- 数据源的实时更新。
- 操作资金的实际投入
如果做实盘交易, 必须使用每天的最新数据。
BackTrader 在原生版本中对股票池的支持有限。为了提升对股票池的回测能力,可以在BackTrader的基础上增加一个外部循环来遍历整个股票池。实盘操作中,一些资金雄厚的金融团队采用全市场模式,即将市场中所有可交易的股票作为股票池。此模式没有预设的股票池限制,所有交易股票都作为输入数据。进一步地,可以在全市场模式基础上进行二次筛选,类似于单因子分析,比如与前几天的收益进行比较。
在量化交易实盘操作中,还存在一些隐性规则需要注意:
-
策略测试与参数优化:使用的交易策略应经过充分测试并优化参数。例如,尽管MA均线策略可能默认设定为15天周期,但这并不意味着它是最优的选择。实际操作中需对这些参数进行调整以寻找最佳方案。
-
缩短回测周期:为了提高回测分析的速度和效率,可以考虑缩短回测周期。这有助于更快地评估策略的有效性和适应性。
-
注意仓位检查:在实施策略时,应持续关注仓位(Position)的变化。仓位管理是量化交易中的关键部分,需要精确控制以避免潜在的风险。
这些考虑因素有助于提高量化交易策略的实际应用效率和成功率。
Position 子模块关系属性示意图如下:
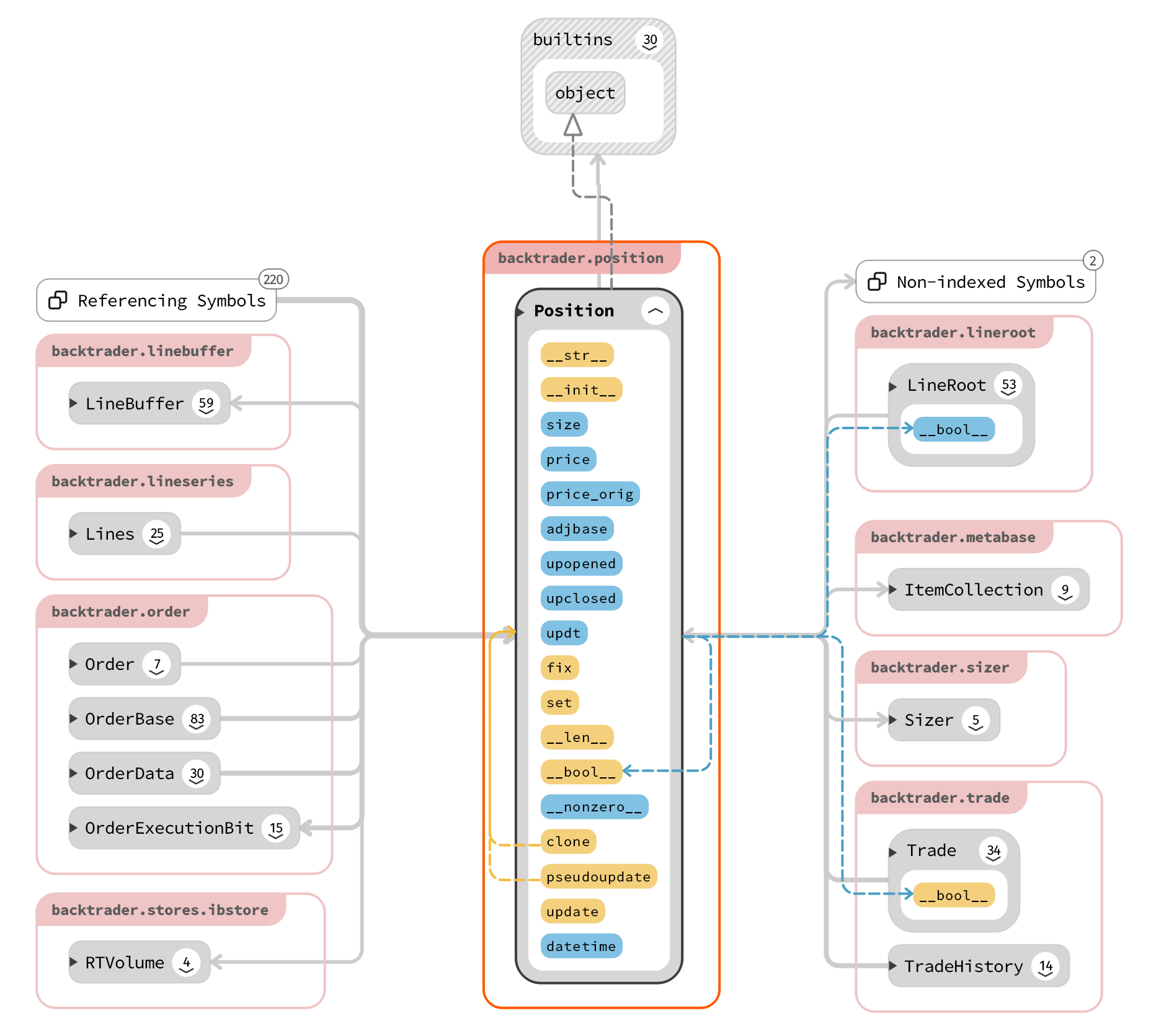
主要相关的子模块库有LineBuffer、 Order、Sizer、 Trade等。使用BackTrader的position类函数还可以看到买入时的价格,随时根据平均仓位成本进行操作。
下面再看看案例策略源码, position函数主要用于next函数:
def next(self):
# 检查当前股票的仓位position
if not self.position:
#
# 如果该股票仓位为0 ,可以进行BUY买入操作,
......
else:
# 如果该股票仓位>0 ,可以进行SELL卖出操作,
......
在使用BackTrader进行量化交易时,执行买卖操作前需先确认持仓状态(Position)。这样做确保了只在持有股票时才能进行卖出操作,从而提高回测效率。策略逻辑主要在next()函数执行,而数据源和指标参数在init()中设置。
BackTrader默认不支持空头交易,用户必须拥有股票才能卖出。Position函数用于检查持仓状态,确保在持有股票时才执行卖单操作,而买单则无此限制。用户可以灵活设置Position,如设定持仓量或资金阈值以控制卖出,或依据现金比例购买股票。这种灵活性使BackTrader适应多样化的交易策略和风险管理需求。
10.5 Stake 交易数额和 Trade 交易执行价格
每次的交易数额都可以通过参数进行设置。在主流程中, 可以设置每次交易是10手:
print("\n\t#2-5,设置每手交易数目为:10,不再使用默认值:1手")
cerebro.addsizer(bt.sizers.FixedSize, stake=10)
使用固定交易数额的方法在操作上更加直接和简便。对于初学者来说,在设置持仓(Position)和交易数量(Stake)时,推荐采用简单的设置方法,避免过于复杂的操作。
接下来考虑交易执行价格的设置。BackTrader在设定买卖单时,默认会根据当天的收盘价来确定交易价格。市场上的交易价格一旦达到这个设定值,系统就会执行买卖操作。值得注意的是,这个价格并非固定不变,而是有一定的浮动范围,这个范围也是可以设定的。
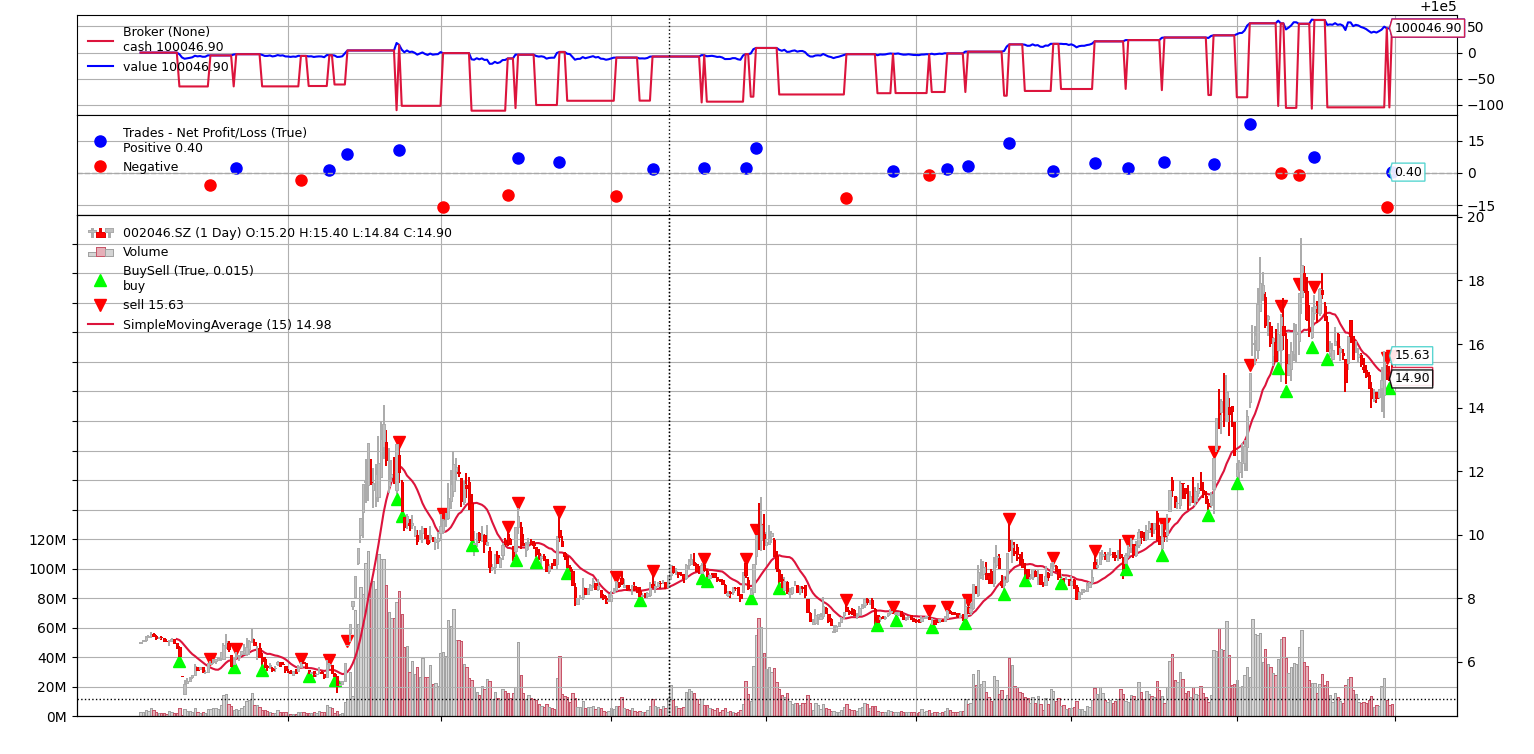
所有买卖操作都由系统在后台自动完成。用户只需设置交易指令,一旦买入和卖出的价格达到一致,订单就会自动进入交易队列。订单的成交遵循“先到先得”的原则。买单和卖单操作比较复杂, BackTrader采用了一个独立的子模块BuySell来进行操作, 如图11-7所示是BuySell子模块关系属性示意图如下所示:

在订单执行时, 系统会输出成交价格、 佣金数额等信息。再看看案例输出信息, 以及图表的买卖点图标信息:
2021-09-29, 设置买单 BUY CREATE, 12.50, name : 002046.SZ
2021-09-30, 买单执行BUY EXECUTED,成交价: 11.84,小计 Cost: 118.40,佣金 Comm 0.12
代码仓库链接:CPythoner/BackTraderDemo at develop (github.com)