文章目录
- 介绍机器学习的实战框架
- 1.定义问题
- 2.收集数据和预处理
- (1).收集数据
- (2).数据可视化
- (3).数据清洗
- (4).特征工程
- (5).构建特征集和标签集
- (6).拆分训练集、验证集和测试集。
- 3.选择算法并建立模型
- 4.训练模型
- 5.模型的评估和优化
介绍机器学习的实战框架
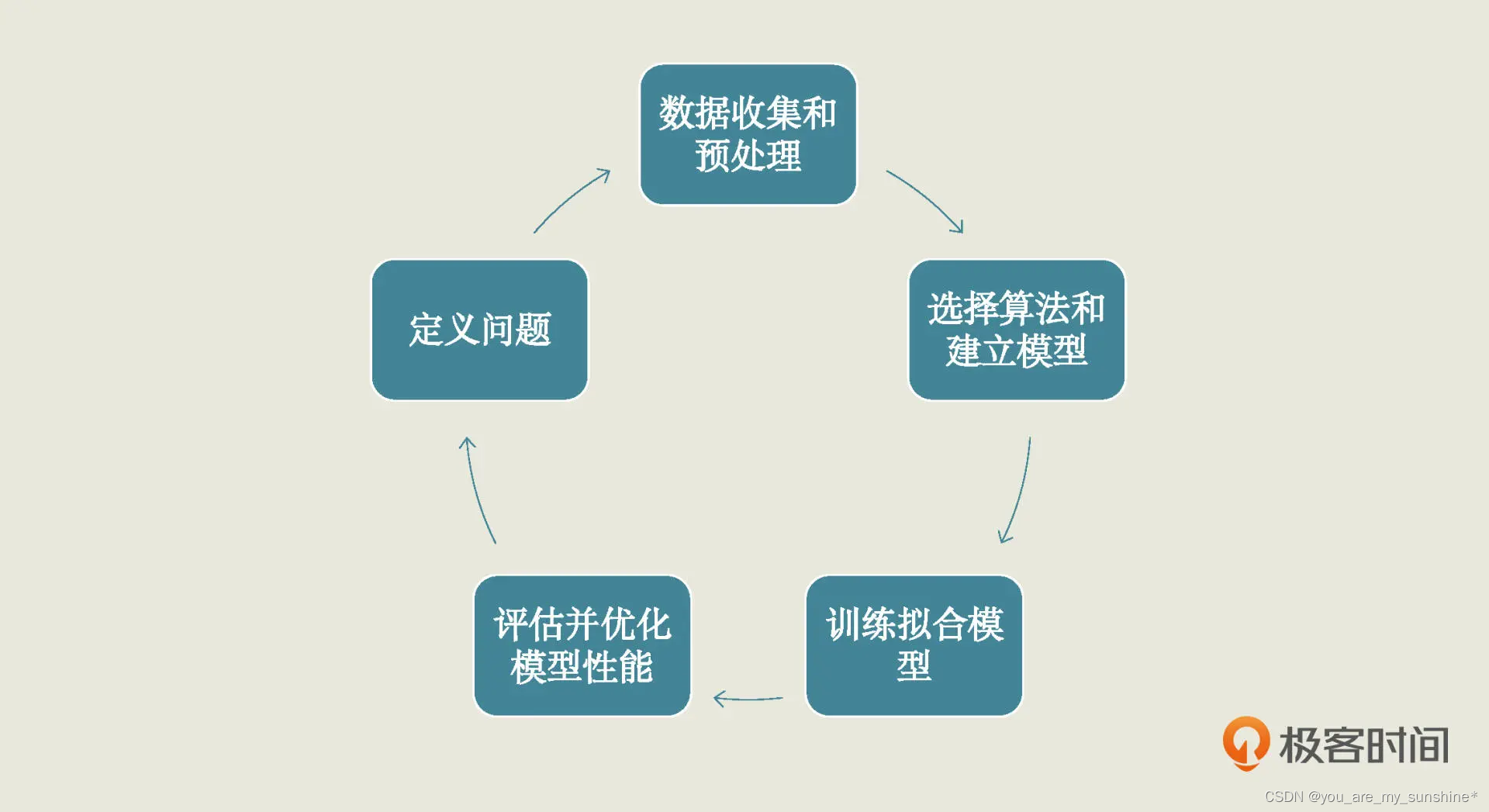
一个机器学习项目从开始到结束大致分为 5 步,分别是定义问题、收集数据和预处理、选择算法和确定模型、训练拟合模型、评估并优化模型性能。这 5 步是一个循环迭代的过程,你可以参考下面的图片:
1.定义问题
我们项目的目标就是,建立一个机器学习模型,根据点赞数和转发数等指标,估计一篇文章能实现多大的浏览量。
因为要估计浏览量,所以在这个数据集中:点赞数、转发数、热度指数、文章评级,这 4 个字段都是特征,浏览量就是标签。这里我们已经有要估计的标签了,所以这是一个监督学习问题。再加上我们的标签是连续性的数值,因此它是一个回归问题。
2.收集数据和预处理
(1).收集数据
首先是收集数据,这一步又叫采集数据。
在现实中,收集数据通常很辛苦,要在运营环节做很多数据埋点、获取用户消费等行为信息和兴趣偏好信息,有时候还需要上网爬取数据。
收集数据的方法有很多,这里推荐之前写过的相关文章:
数据爬虫(JSON格式)&数据地图可视化(pyecharts)【步骤清晰,一看就懂】:https://blog.csdn.net/weixin_42504788/article/details/134588642
数据爬取+数据可视化实战_哪里只得我共你(Dear Jane)_词云展示----网易云:https://blog.csdn.net/weixin_42504788/article/details/134622850
数据爬取+可视化实战_告白气球_词云展示----酷狗音乐:https://blog.csdn.net/weixin_42504788/article/details/134622575
处理Json格式的数据,如何用Python将数据存放入Excel中(步骤清晰,一看就懂):https://blog.csdn.net/weixin_42504788/article/details/134543733
(2).数据可视化
数据可视化是个万金油技能,能做的事非常多。比如说,可以看一看特征和标签之间可能存在的关系,也可以看看数据里有没有“脏数据”和“离群点”等。
常用的工具包有:
import matplotlib.pyplot as plt # Matplotlib – Python画图工具库
import seaborn as sns # Seaborn – 统计学数据可视化工具库
(3).数据清洗
处理缺失的数据:用均值填充、众数填充或0。如果建模用树模型,也可以不填充,树模型算法自身可以处理缺失值。
处理重复的数据:完全相同,删去即可。
处理错误的数据:部门人数、销量、销售金额小于0,遇到这类情况删去即可。
处理不可用的数据:建模的时候,数据必须是数字,不能是中英文等情况。比如性别出现男女字样,需要转化后再进行建模
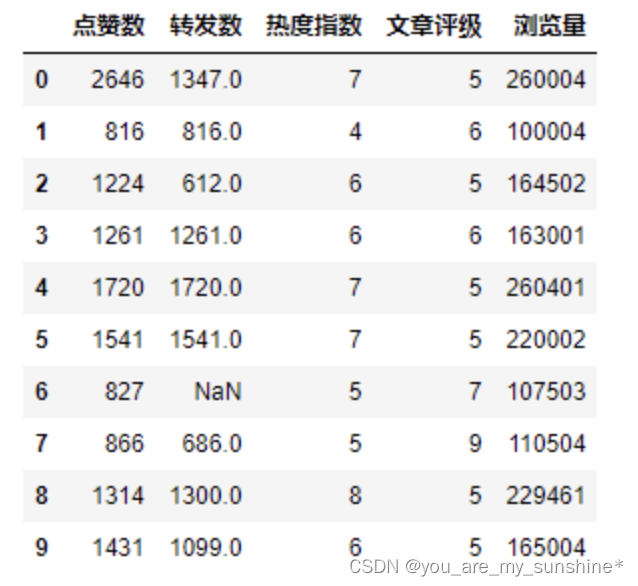
查看空缺值NaN出现的次数:df.isna().sum()
把出现了NaN的数据行删掉:df = df.dropna()
(4).特征工程
特征贴合业务实际,特征越丰富,模型效果会更好
(5).构建特征集和标签集
特征是输入机器学习模型的变量。
X = df.drop(['浏览量'],axis=1)
X.head()
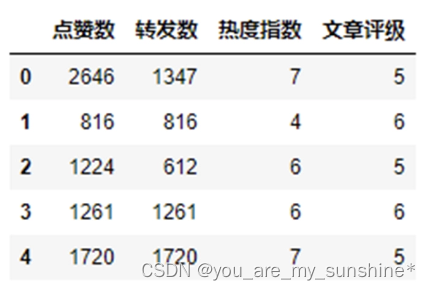
标签是结果或目标。
y = df.浏览量
y.head()

(6).拆分训练集、验证集和测试集。
一般为了简化,验证集会省略,这里展示如何从数据中切分出训练集跟测试集
#将数据集进行80%(训练集)和20%(验证集)的分割
from sklearn.model_selection import train_test_split #导入train_test_split工具
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2, random_state=0)
random_state设置一个值,保证每次切分的数据都一致,再次运行建模的效果也出现一致性。
X_train:训练集的特征
X_test:测试集的特征
y_train:训练集的标签
y_test:测试集的标签
3.选择算法并建立模型
进行多个机器学习算法进行比较,将最优的算法作为baseline
这里举个经典的逻辑回归例子,
from sklearn.linear_model import LinearRegression # 导入线性回归算法模型
linereg_model = LinearRegression() # 使用线性回归算法创建模型
对于 LinearRegression 模型来讲,它的外部参数主要包括两个布尔值:
- fit_intercept ,默认值为 True,代表是否计算模型的截距。
- normalize,默认值为 False,代表是否对特征 X 在回归之前做规范化。
4.训练模型
训练模型就是用训练集中的特征变量和已知标签,根据当前样本的损失大小来逐渐拟合函数,确定最优的内部参数,最后完成模型
fit 方法是机器学习的核心环节,里面封装了很多具体的机器学习核心算法,我们只需要把特征训练数据集和标签训练数据集,同时作为参数传进 fit 方法就行了。
linereg_model.fit(X_train, y_train) # 用训练集数据,训练机器,拟合函数,确定内部参数
不要小看上面那个简单的 fit 语句,这是模型进行自我学习的关键过程。
fit 的核心就是减少损失,使函数对特征到标签的模拟越来越贴切。
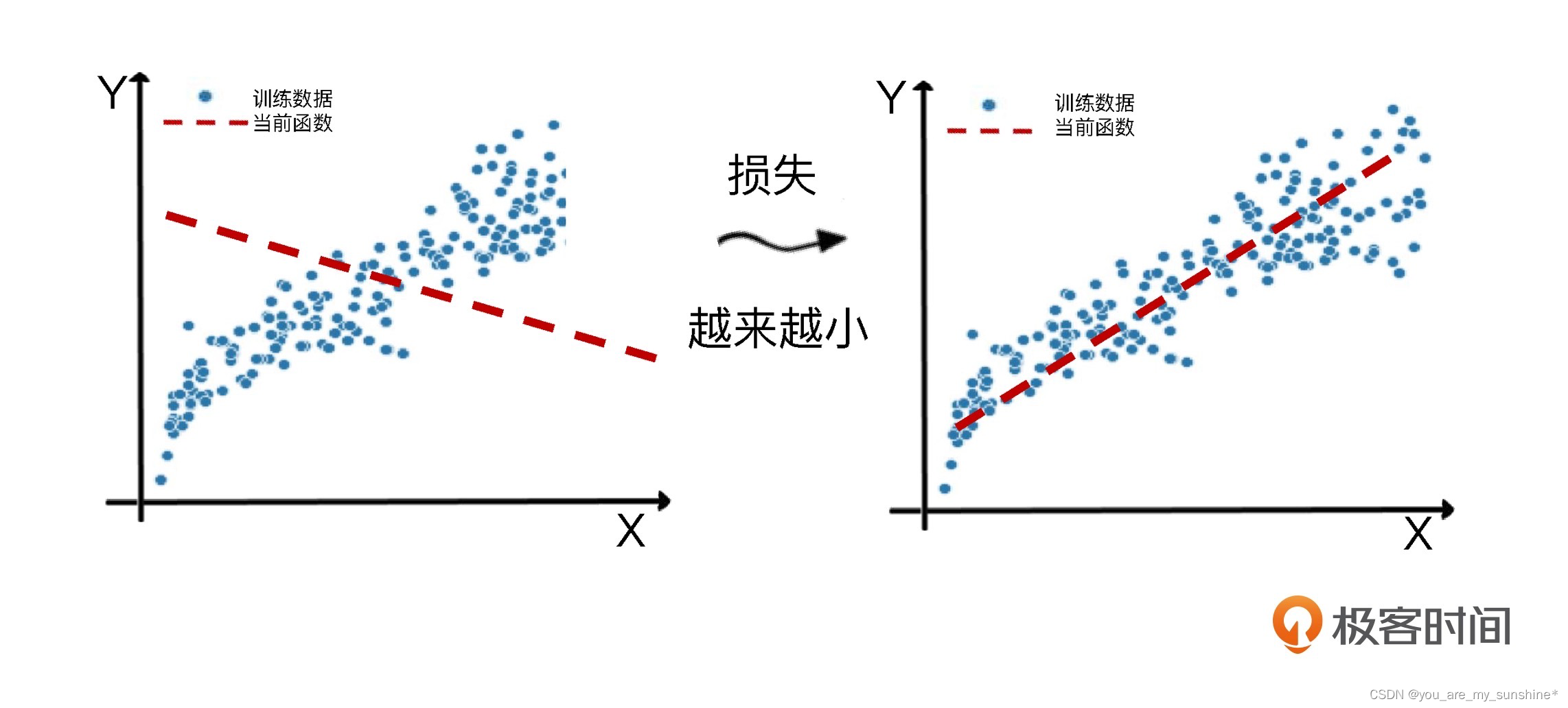
这个拟合的过程,同时也是机器学习算法优化其内部参数的过程。而优化参数的关键就是减小损失。
那什么是损失呢?它其实是对糟糕预测的惩罚,同时也是对模型好坏的度量。如果模型的预测完全准确,则损失为 0;如果不准确,就有损失。
在机器学习中,我们追求的当然是比较小的损失。不过,模型好不好,还不能仅看单个样本,还要针对所有数据样本,找到一组平均损失“较小”的函数模型。样本的损失大小,从几何意义上基本可以理解为预测值和真值之间的几何距离。平均距离越大,说明误差越大,模型越离谱。在下面这个图中,左边是平均损失较大的模型,右边是平均损失较小的模型,模型所有数据点的平均损失很明显大过右边模型。
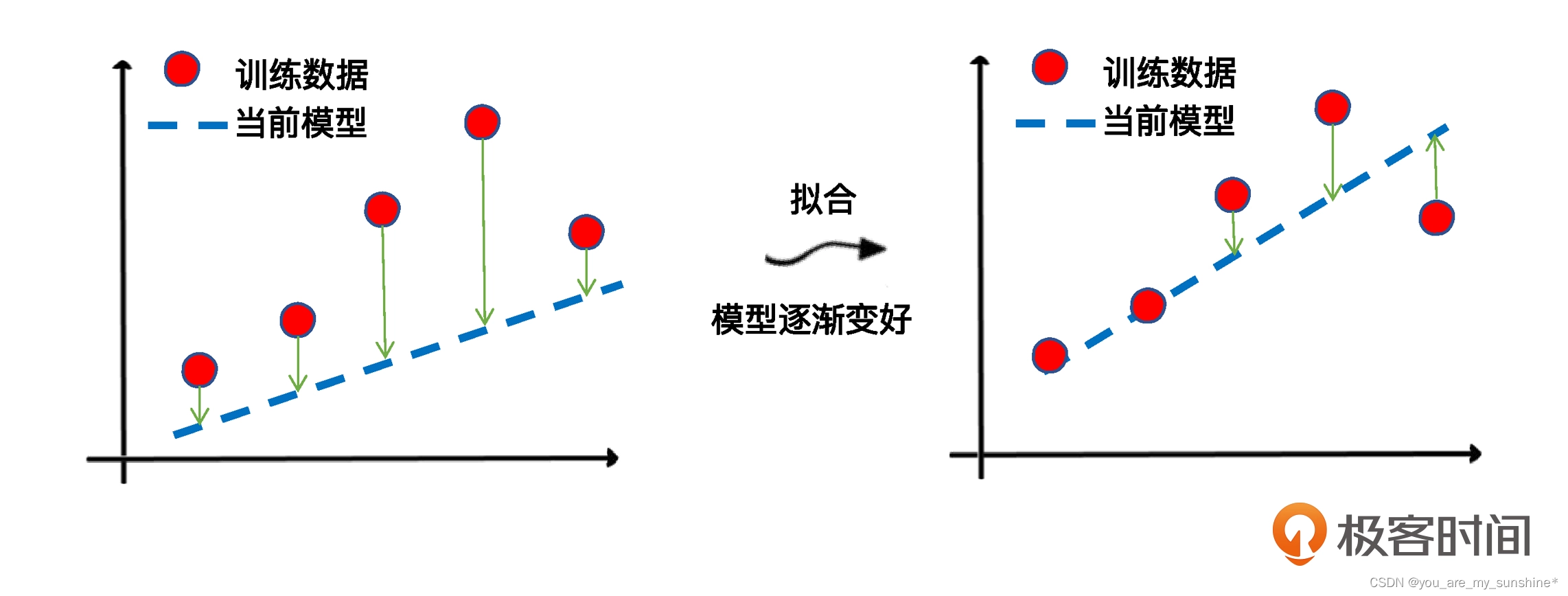
回归模型的拟合,它的关键环节就是通过梯度下降,逐步优化模型的参数,使训练集误差值达到最小。这也就是我们刚才讲的那个 fit 语句所要实现的最优化过程。
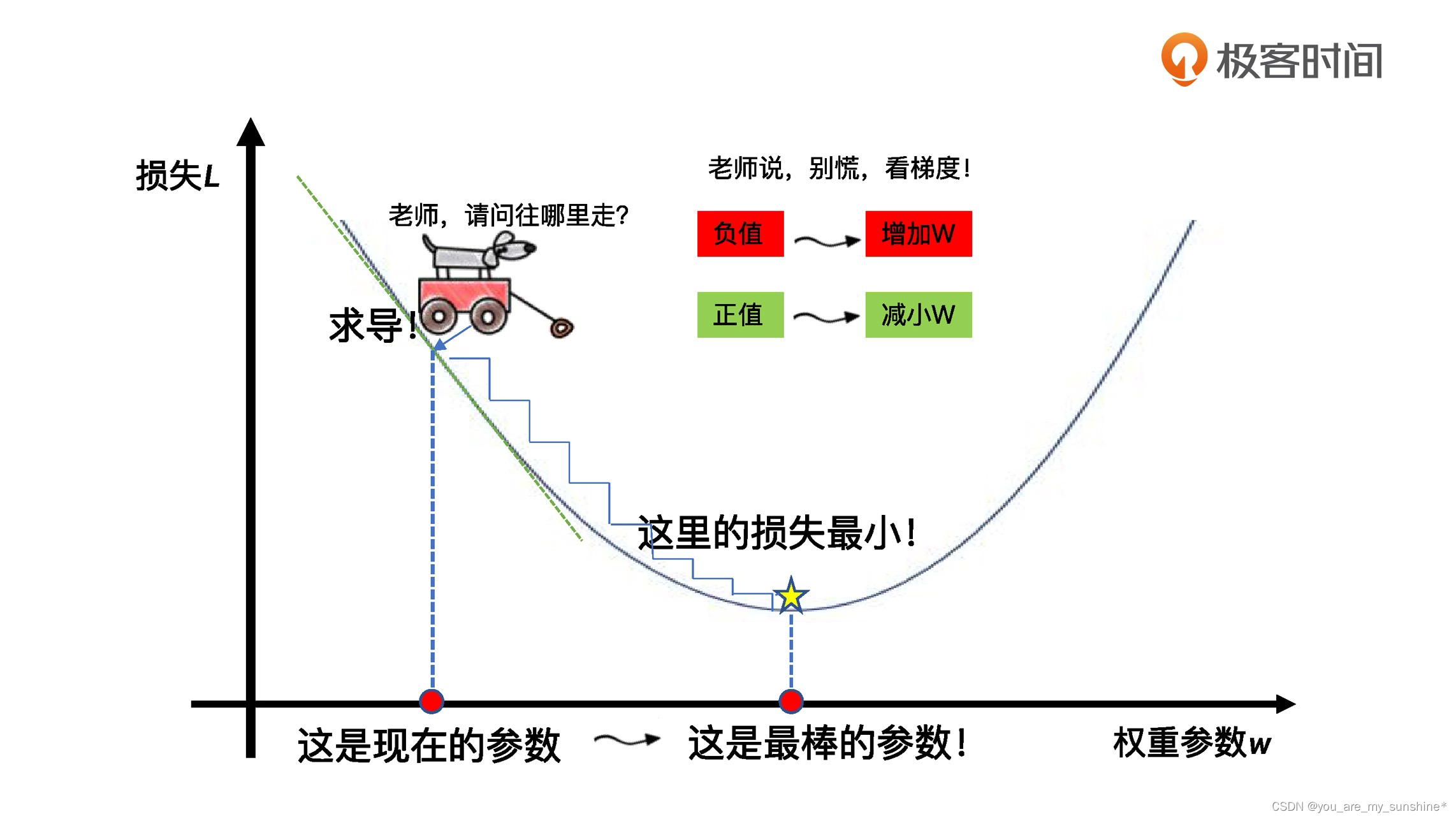
就像图里这样,梯度下降其实就和下山一样。你可以想象一下,当你站在高处,你的目标就是找到一系列的参数,让训练数据集上的损失值最小。那么你该往哪走才能保证损失值最小呢?关键就是通过求导的方法,找到每一步的方向,确保总是往更小的损失方向前进。
5.模型的评估和优化
梯度下降是在用训练集拟合模型时最小化误差,这时候算法调整的是模型的内部参数。而在验证集或者测试集进行模型效果评估的过程中,我们则是通过最小化误差来实现超参数(模型外部参数)的优化。
机器学习工具包(如 scikit-learn)中都会提供常用的工具和指标,对验证集和测试集进行评估,进而计算当前的误差。比如 R2 或者 MSE 均方误差指标,就可以用于评估回归分析模型的优劣。
当我们预测完测试集的浏览量后,我们要再拿这个预测结果去和测试集已有的真值去比较,这样才能够求出模型的性能。而这整个过程也同样是一个循环迭代的过程
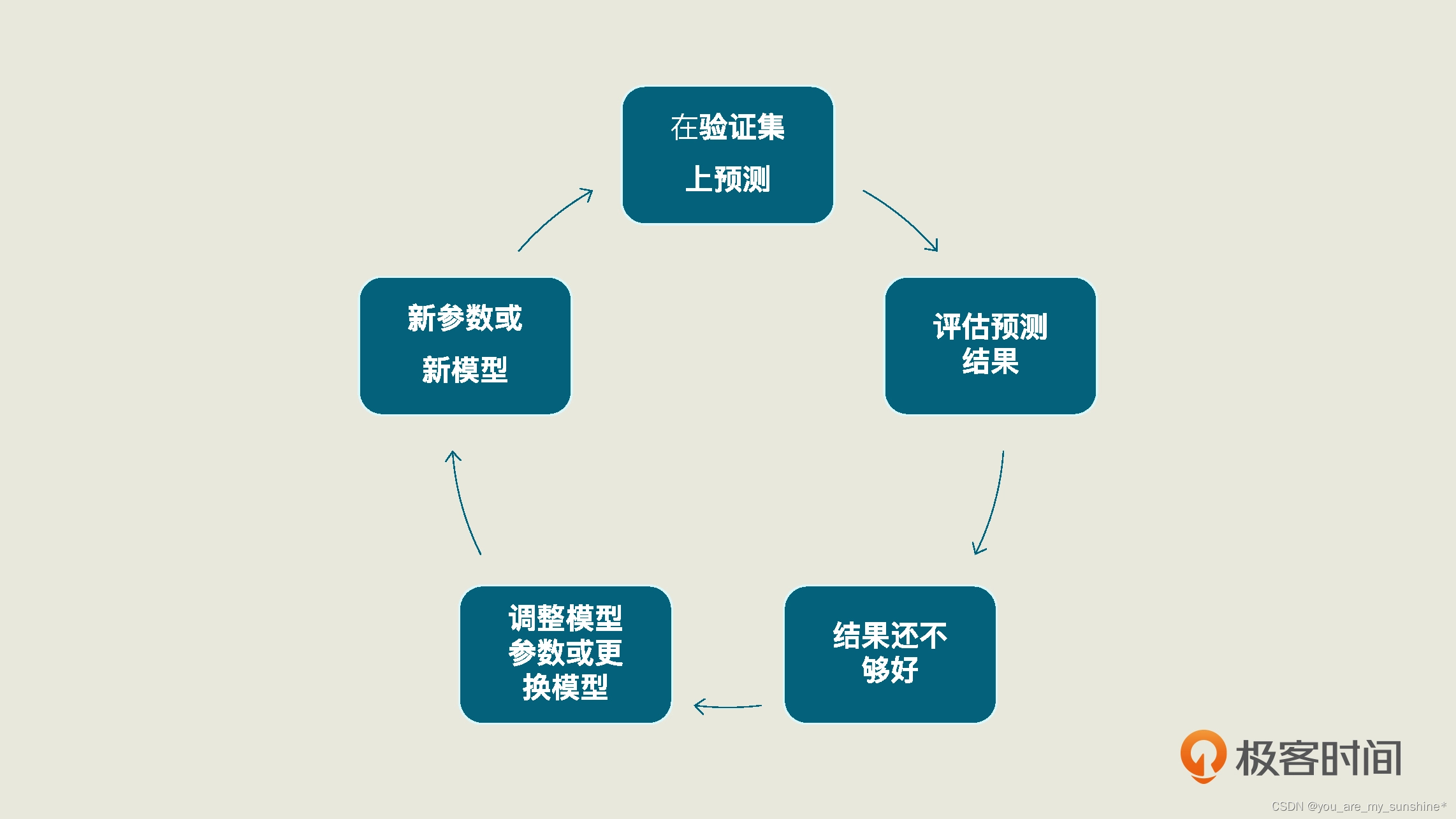
预测测试集的浏览量,只需要用训练好的模型 linereg_model 中的 predict 方法,在 X_test(特征测试集)上进行预测,这个方法就会返回对测试集的预测结果。
y_pred = linereg_model.predict(X_test) #预测测试集的Y值
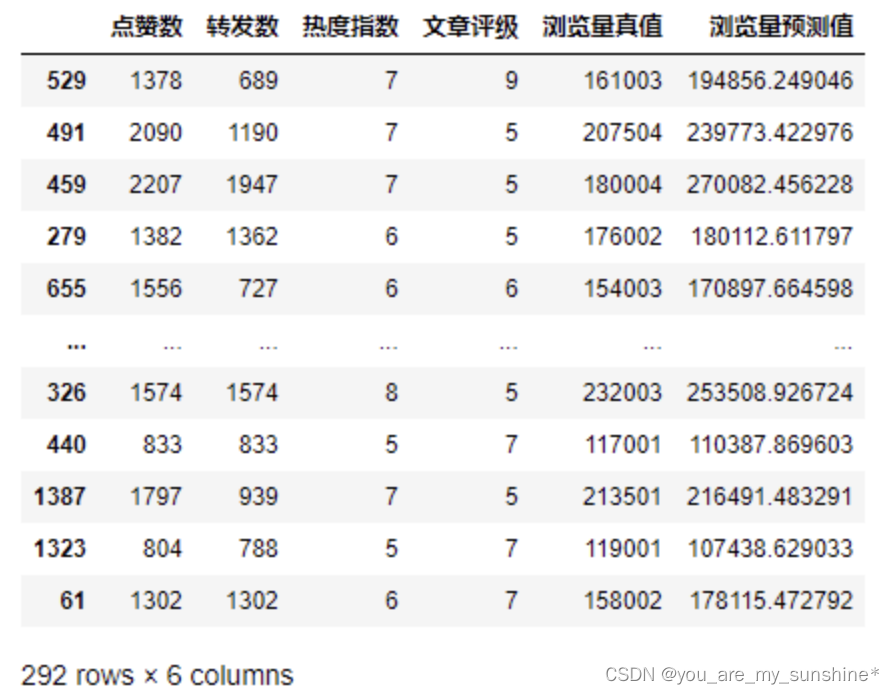
拿到预测结果后,我们再通过下面的代码,把测试数据集的原始特征数据、原始标签真值,以及模型对标签的预测值组合在一起进行显示、比较。
df_ads_pred = X_test.copy() # 测试集特征数据
df_ads_pred['浏览量真值'] = y_test # 测试集标签真值
df_ads_pred['浏览量预测值'] = y_pred # 测试集标签预测值
df_ads_pred #显示数据
如果你想看看现在的模型长得什么样?你可以通过 LinearRegression 的 coef_ 和 intercept_ 属性打印出各个特征的权重和模型的偏置来。它们也就是模型的内部参数。
print('当前模型的4个特征的权重分别是: ', linereg_model.coef_)
print('当前模型的截距(偏置)是: ', linereg_model.intercept_)
# 输出结果:
# 当前模型的4个特征的权重分别是: [ 48.08395224 34.73062229 29730.13312489 2949.62196343]
# 当前模型的截距(偏置)是: -127493.90606857178
这也就是说,我们现在的模型的线性回归公式是:
yy=48.08x1(点赞)+34.73x2(转发)+29730.13x3(热度)+2949.62x4(评级)−127493.91
对当前这个模型,给出评估分数:
print("线性回归预测评分:", linereg_model.score(X_test, y_test)) # 评估模型
# 输出结果:
# 线性回归预测评分: 0.7085754407718876
一般来说,R2 的取值在 0 到 1 之间,R2 越大,说明所拟合的回归模型越优。现在我们得到的 R2 值约为 0.708,在没有与其它模型进行比较之前,我们实际上也没法确定它是否能令人满意。
如果模型的评估分数不理想,我们就需要回到第 3 步,调整模型的外部参数,重新训练模型。要是得到的结果依旧不理想,那我们就要考虑选择其他算法,创建全新的模型了。如果很不幸,新模型的效果还是不好的话,我们就得回到第 2 步,看看是不是数据出了问题。
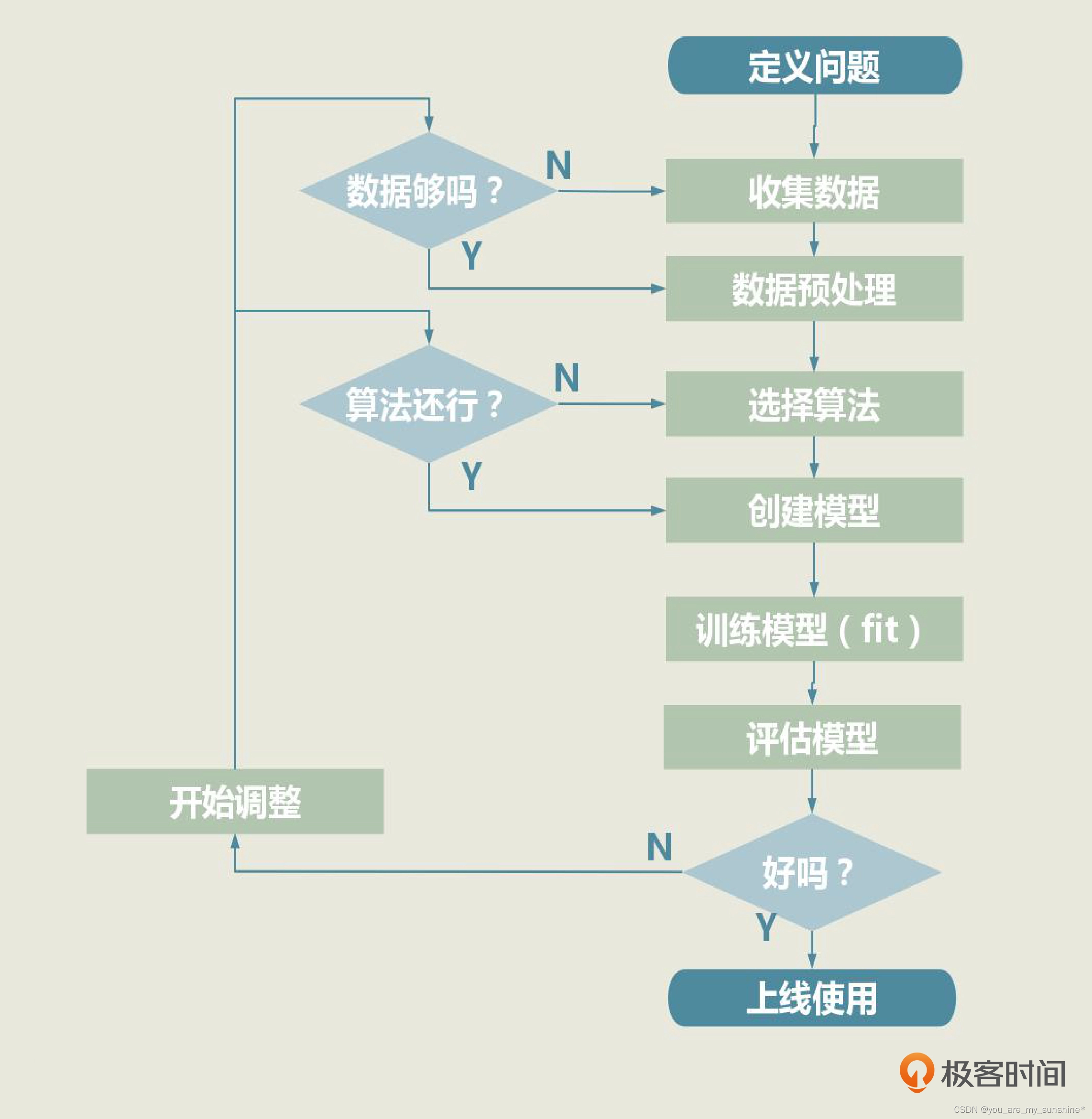
当模型通过了评估,就可以去解决实际问题了,机器学习项目也算是基本结束。
学习机器学习的参考资料:
(1)书籍
利用Python进行数据分析
西瓜书
百面机器学习
机器学习实战
阿里云天池大赛赛题解析(机器学习篇)
白话机器学习中的数学
零基础学机器学习
图解机器学习算法
…
(2)机构
光环大数据
开课吧
极客时间
七月在线
深度之眼
贪心学院
拉勾教育
博学谷
…