目标
- 学习SIFT 算法的概念
- 学习在图像中查找SIFT关键点和描述符
原理及介绍
在前面两节我们学习了一些角点检测技术:比如Harris 等。它们具有旋转不变特性,即使图片发生了旋转,我们也能找到同样的角点。很明显即使图像发生旋转之后角点还是角点。但是,如果我们对图像进行缩放呢?角点可能就不再是角点了。以下图为例:在一副小图中使用一个小的窗口可以检测到一个角点,但是如果图像被放大,再使用同样的窗口就检测不到角点了。
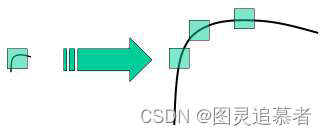
所以在2004 年,D.Lowe 提出了一个新的算法,尺度不变特征变换(SIFT),这个算法可以帮助我们提取图像中的关键点并计算它们的描述符。
步骤
SIFT 算法主要由以下几步构成。接下来我们来分步来进行学习。
尺度空间极值检测
从上图我们可以很明显的看出来在不同的尺度空间不能使用相同的窗口检测极值点。对小的角点要用小的窗口,对大的角角点只能使用大的窗口。为了达到这个目的我们要使用尺度空间滤波器。(尺度空间滤波器可以使用一系列具有不同方差σ 的高斯卷积核构成)。使用具有不同方差值σ 的高斯拉普拉斯算子(LoG)对图像进行卷积,LoG 由于具有不同的方差值σ 所以可以用来检测不
同大小的斑点(当LoG 的方差σ 与斑点直径相等时能够使斑点完全平滑)。简单来说,方差σ 就是一个尺度变换因子。例如,上图中使用一个小方差σ 的高斯卷积核是可以很好的检测出小的角点,而使用大方差σ 的高斯卷积核时可以很好的检测到大的角点。所以我们可以在尺度空间和二维平面中检测到局部最大值。如(x,y,σ), 这表示在σ 尺度中(x,y)点可能是一个关键点。(高斯方差的大小与窗口的大小存在一个倍数关系:窗口大小等于6 倍方差加1,所以方差的大小也决定了窗口大小)
但是这个LoG 的计算量非常大,所以SIFT 算法使用高斯差分算子(DoG)来对LoG 做近似。这里需要再介绍一下图像金字塔,我们可以通过减少采样(如只取奇数行或奇数列)来构成一组图像尺寸(1,0.5,0.25 等)不同的金字塔,然后对这一组图像中的每一张图像使用具有不同方差σ 的高斯卷积核构建出具有不同分辨率的图像金字塔(不同的尺度空间)。DoG 就是这组具有不同分辨率的图像金字塔中相邻的两层之间的差值。如下图所示:
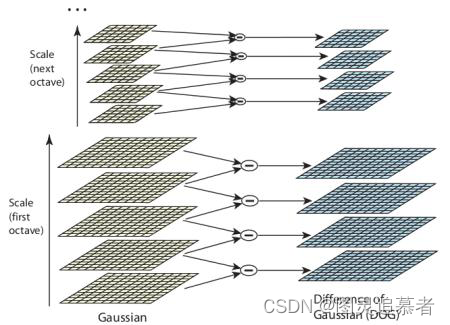
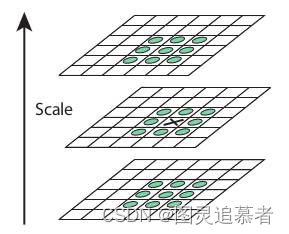
在DoG 搞定之后,就可以在不同的尺度空间和2D 平面中搜索局部最大值了。对于图像中的一个像素点而言,它需要与自己周围的8 邻域以及尺度空间中上下两层中的相邻的18(2x9)个点相比。如果是局部最大值,它就可能是一个关键点。基本上来说,关键点是图像在相应尺度空间中的最好代表。如下图所示:
该算法的作者在文章中给出了SIFT 参数的经验值:octaves=4(通过降低采样从而减小图像尺寸,构成尺寸减小的图像金字塔4 层)尺度空间为5,也就是每个尺寸使用5 个不同方差的高斯核卷积,初始方差是1.6,k 等于√2 等。
关键点(极值点)定位
一旦找到关键点,我们就需要对它们进行修正从而得到更准确的结果。作者使用尺度空间的泰勒级数展开来获得极值的准确位置。如果极值点的灰度值小于阈值(0.03)就会被忽略掉。在OpenCV 中这种阈值被称为contrastThreshold。
DoG 算法对边界非常敏感,所以我们必须把边界去掉。前面我们讲的Harris 算法除了可以用于角点检测之外还可以用于检测边界。作者就是使用了同样的思想。作者使用2x2 的Hessian 矩计算算主曲率。从Harris 角点检测的算法中,我们知道当一个特征值远远大于另外一个特征值时检测到的是边界。所以他们使用了一个简单的函数,如果比例高于阈值(OpenCV 中称为边界阈值)这个关键点就会被忽略。文章中给出的边界阈值为10。所以低对比度的关键点和边界关键点都会被去掉,剩下的就是我们感兴趣的关键点了。
为关键点(极值点)指定方向参数
现在我们要为每一个关键点赋予一个反向参数,这样它才会具有旋转不变性。获取关键点(所在尺度空间)的邻域,然后计算这个区域的梯度级和方向。根据计算得到的结果创建一个含有36 个bins(每10 度一个bin)的方向直方图。(使用当前尺度空间σ 值的1.5 倍为方差的圆形高斯窗口和梯度级做权重)。直方图中的峰值为主方向参数,如果其他的任何柱子的高度高于峰值的80% 被认为是辅方向。这就会在相同的尺度空间相同的位置构建具有不同方向的关键点。这对于匹配的稳定性会有所帮助。
关键点描述符
新的关键点描述符被创建了。选取与关键点周围一个16x16 的邻域,把它分成16 个4x4 的小方块,为每个小方块创建一个具有8 个bin 的方向直方图。总共加加来有128 个bin。由此组成长度为128 的向量就构成了关键点描述符。除此之外,还要进行几个测量以达到对光照变化、旋转等的稳定性。
关键地匹配
下一步就可以利用关键点特征向量的欧氏距离来作为两幅图像中关键点的相似性判定度量。取第一个图的某个关键点,通过遍历找到第二幅图像中的距离最近的那个关键点。但有些情况下,第二个距离最近的关键点与第一个距离最近的关键点靠的太近。这可能是由于噪声等引起的。此时要计算最近距离与第二近距离的比值。如果比值大于0.8就忽略掉。这会去除 90% 的错误匹,同时只去除5% 的正确匹配。如文章所说。
这就是SIFT 算法的摘要。非常推荐你对原始文献进行阅读,会加深你对算法的理解。记住,个算法是受专利保护的。所以这个算法包含在OpenCV 中的收费模块中。
OpenCV中的SIFT算法
现在让我们来看看OpenCV 中关于SIFT 的函数吧。让我们从关键点检测和绘制开始吧。首先我们先创建对象。我们可以使用不同的参数,这并不是必须的,关于参数的解释可以查看文档。
import cv2
import numpy as np
img = cv2.imread('home.jpg')
gray= cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
sift = cv2.SIFT()
kp = sift.detect(gray,None)
img=cv2.drawKeypoints(gray,kp)
cv2.imwrite('sift_keypoints.jpg',img)函数sift.detect() 可以在图像中找到关键点。如果你只想在图像中的一个区域搜索的话也可以创建一个掩模图像作为参数使用。返回的关键点是一个带有很多不同属性的特殊结构体,这些属性中包含它的坐标(x,y),有意义的邻域大小、确定其方向的角度等。
OpenCV 也提供了绘制关键点的函数cv2.drawKeyPoints(),它可以在关键点的部位绘制一个小圆圈。如果你设置参数为cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS,就会绘制代表关键点大小的圆圈甚至可以绘制制关键点的方向。
img=cv2.drawKeypoints(gray,kp,flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
cv2.imwrite('sift_keypoints.jpg',img)结果如下:

现在来计算关键点描述符,OpenCV 提供了两种方法:
- 由于我们已经找到了关键点,我们可以使用函数sift.compute() 来计算这些关键点的描述符。例如:kp, des = sift.compute(gray, kp)。
- 如果还没有找到关键点,还可以使用函数sift.detectAndCompute()一步到位直接找到关键点并计算出其描述符。
这里我们来看看第二个方法:
这里 kp 是一个关键点列表。des 是一个Numpy 数组,其大小是关键点数目乘以128。
所以我们得到了关键点和描述符等。现在我们想看看如何在不同图像之间进行关键点匹配,这就是我们在接下来的章节将要学习的内容。
图像匹配示例
import cv2
import numpy as np
#from psd_tools import PSDImage
# 1) psd to png
'''psd1 = PSDImage.load('200x800.ai.psd')
psd1.as_PIL().save('psd_image_to_detect1.png')
psd2 = PSDImage.load('800x200.ai.psd')
psd2.as_PIL().save('psd_image_to_detect2.png')'''
# 2) 以灰度图的形式读入图片
psd_img_1 = cv2.imread('./images/1.png', cv2.IMREAD_GRAYSCALE)
psd_img_2 = cv2.imread('./images/2.png', cv2.IMREAD_GRAYSCALE)
# 3) SIFT特征计算
sift = cv2.xfeatures2d.SIFT_create()
psd_kp1, psd_des1 = sift.detectAndCompute(psd_img_1, None)
psd_kp2, psd_des2 = sift.detectAndCompute(psd_img_2, None)
# 4) Flann特征匹配
FLANN_INDEX_KDTREE = 1
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(psd_des1, psd_des2, k=2)
goodMatch = []
for m, n in matches:
# goodMatch是经过筛选的优质配对,如果2个配对中第一匹配的距离小于第二匹配的距离的1/2,基本可以说明这个第一配对是两幅图像中独特的,不重复的特征点,可以保留。
if m.distance < 0.75*n.distance:
goodMatch.append(m)
# 增加一个维度
goodMatch = np.expand_dims(goodMatch, 1)
print(goodMatch[:50])
img_out = cv2.drawMatchesKnn(psd_img_1, psd_kp1, psd_img_2, psd_kp2, goodMatch[:15], None, flags=2)
cv2.imshow('image', img_out)#展示图片
cv2.waitKey(0)#等待按键按下
cv2.destroyAllWindows()#清除所有窗口