本篇文章,聊聊如何在新版本 PyTorch 和 CUDA 容器环境中完成 xFormers 的编译构建。
让你的模型应用能够跑的更快。
写在前面
xFormers 是 FaceBook Research (Meta)开源的使用率非常高的 Transformers 加速选型,当我们使用大模型的时候,如果启用 xFormers 组件,能够获得非常明显的性能提升。

因为 xFormers 对于 Pytorch 和 CUDA 新版本支持一般会晚很久。所以,时不时的我们能够看到社区提出不能在新版本 CUDA 中构建的问题(#935或 #958),以及各种各样的编译失败的问题。
另外,xFormers 的安装还有一个问题,会在安装的时候调整当前环境已经安装好的 PyTorch 和 Numpy 版本,比如我们使用的是已经被验证过的环境,比如 Nvidia 的月度发布的容器环境,这显然是我们不乐见的事情。
下面,我们就来解决这两个问题,让 xFormers 能够在新的 CUDA 环境中完成编译,以及让 xFormers 的安装不需要变动我们已经安装好的 Pytorch 或者 Numpy。
环境准备
环境的准备一共有两步,下载容器和 xFormers 源代码。
Nvidia 容器环境
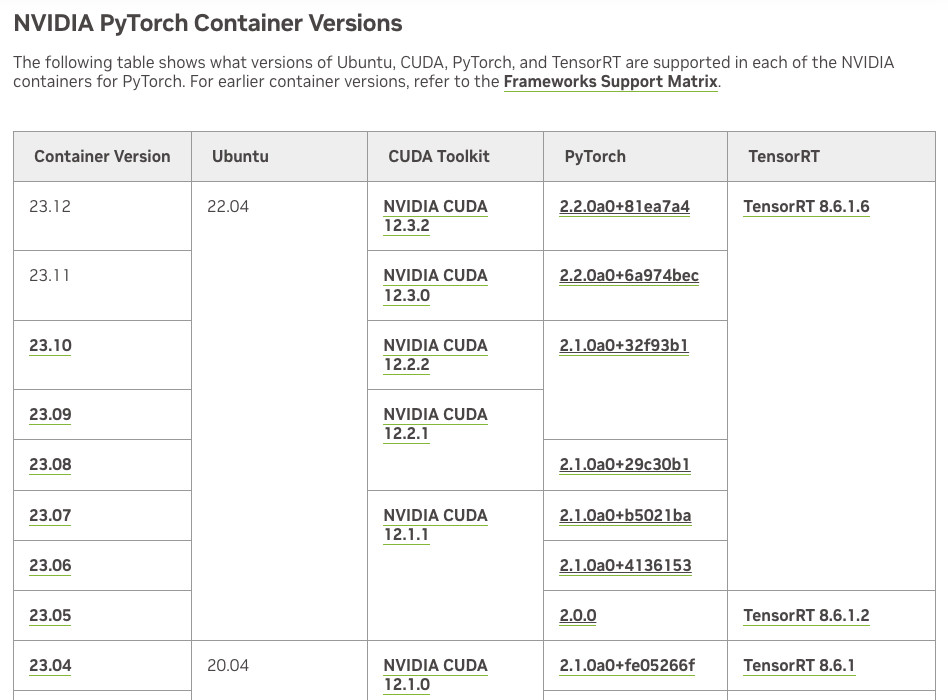
在之前的许多文章中,我提过很多次为了高效运行模型,我推荐使用 Nvidia 官方的容器镜像(nvcr.io/nvidia/pytorch:23.12-py3)。
下载镜像很简单,一条命令就行:
docker pull nvcr.io/nvidia/pytorch:23.12-py3
完成镜像下载后,准备工作就完成了一半。
准备好镜像后,我们可以检查下镜像中的具体组件环境,使用 docker run 启动镜像:
docker run --rm -it --gpus all --ipc=host --ulimit memlock=-1 -v `pwd`:/app nvcr.io/nvidia/pytorch:23.12-py3 bash
然后,使用 python -m torch.utils.collect_env 来获取当前环境的信息,方便后续完成安装后确认原始环境稳定:
# python -m torch.utils.collect_env
Collecting environment information...
PyTorch version: 2.2.0a0+81ea7a4
Is debug build: False
CUDA used to build PyTorch: 12.3
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.3 LTS (x86_64)
GCC version: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
Clang version: Could not collect
CMake version: version 3.27.9
Libc version: glibc-2.35
Python version: 3.10.12 (main, Nov 20 2023, 15:14:05) [GCC 11.4.0] (64-bit runtime)
Python platform: Linux-6.5.0-14-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 12.3.107
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 4090
Nvidia driver version: 525.147.05
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.9.7
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.9.7
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.9.7
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.9.7
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.9.7
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.9.7
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.9.7
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 39 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 32
On-line CPU(s) list: 0-31
Vendor ID: GenuineIntel
Model name: 13th Gen Intel(R) Core(TM) i9-13900KF
CPU family: 6
Model: 183
Thread(s) per core: 2
Core(s) per socket: 24
Socket(s): 1
Stepping: 1
CPU max MHz: 5800.0000
CPU min MHz: 800.0000
BogoMIPS: 5990.40
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 sdbg fma cx16 xtpr pdcm sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb ssbd ibrs ibpb stibp ibrs_enhanced tpr_shadow flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid rdseed adx smap clflushopt clwb intel_pt sha_ni xsaveopt xsavec xgetbv1 xsaves split_lock_detect avx_vnni dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp hwp_pkg_req hfi vnmi umip pku ospke waitpkg gfni vaes vpclmulqdq rdpid movdiri movdir64b fsrm md_clear serialize arch_lbr ibt flush_l1d arch_capabilities
Virtualization: VT-x
L1d cache: 896 KiB (24 instances)
L1i cache: 1.3 MiB (24 instances)
L2 cache: 32 MiB (12 instances)
L3 cache: 36 MiB (1 instance)
NUMA node(s): 1
NUMA node0 CPU(s): 0-31
Vulnerability Gather data sampling: Not affected
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Not affected
Vulnerability Spec rstack overflow: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced / Automatic IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] numpy==1.24.4
[pip3] onnx==1.15.0rc2
[pip3] optree==0.10.0
[pip3] pytorch-quantization==2.1.2
[pip3] torch==2.2.0a0+81ea7a4
[pip3] torch-tensorrt==2.2.0a0
[pip3] torchdata==0.7.0a0
[pip3] torchtext==0.17.0a0
[pip3] torchvision==0.17.0a0
[pip3] triton==2.1.0+6e4932c
获取 xFormers
下载 xFormers 的源代码,并且记得使用 --recursive 确保所有依赖都下载完毕:
git clone --recursive https://github.com/facebookresearch/xformers.git --depth 1
xFormers 的源码包含三个核心组件 cutlass、flash-attention、sputnik,除去最后一个开源软件在 xFormers 项目 sputnik 因为 Google 不再更新,被固定了代码版本,其他两个组件的版本分别为:cutlass@3.2 和 flash-attention@2.3.6。

Dao-AILab/flash-attention目前最新的版本是 v2.4.2,不过更新的主干版本包含了更多错误的修复,推荐直接升级到最新版本。在 v2.4.2 版本中,它依赖的 cutlass 版本为 3.3.0,所以我们需要升级 cutlass 到合适的版本。
cd xformers/third_party/flash-attention
git pull origin main
Nvidia/cutlass 在 3.1+ 的版本对性能提升明显。
不过如果直接更新 3.2 到目前最新的 3.4 flash-attention 找不到合适的版本,会发生编译不通过的问题,所以我们将版本切换到 v3.3.0 即可。
cd xformers/third_party/cutlass
git pull origin main
git checkout v3.3.0
另外,在前文中提到了在安装 xFormers 的时候,会连带更新本地已经安装好的依赖。想要保护本地已经安装好的环境不被覆盖,尤其是 Nvidia 容器中的依赖不被影响,我们需要将 xformers/requirements.txt 内容清空。
echo '' > xformers/requirements.txt
好了,到这里准备工作就结束了。
完成容器中的 xFormers 的安装
想要顺利完成 xFormers 的构建,还有一些小细节需要注意。为了让我们能够从源码进行构建,我们需要关闭我们下载 xFormers 路径的 Git 安全路径检查:
git config --global --add safe.directory /app/xformers
git config --global --add safe.directory /app/xformers/third_party/flash-attention
git config --global --add safe.directory /app/xformers/third_party/cutlass
为了让构建速度有所提升,我们需要安装一个能够让我们加速完成构建的工具 ninja:
pip install ninja
当上面的工具都完成后,我们就可以执行命令,开始构建安装了:
pip install -v -e .
需要注意的是,默认情况下安装程序会根据你的 CPU 核心数来设置构建进程数,不过过高的工作进程,会消耗非常多的内存。如果你的 CPU 核心数非常多,那么默认情况下直接执行上面的命令,会得到非常多的 Killed 的编译错误。
想要解决这个问题,我们需要设置合理的 MAX_JOBS 参数。如果你的硬件资源有限,可以设置 MAX_JOBS=1,如果你资源较多,可以适当增加数值。我的构建设备有 64G 内存,我一般会选择设置 MAX_JOBS=3 来使用大概最多 50GB 的内存,来完成构建过程,MAX_JOBS 的构建内存消耗并不是完全严格按照线性增加的,当我们设置为 1 的时候,16GB 的设备就能够完成构建、当我们设置为 2 的时候,使用 32GB 的设备构建会比较稳妥,当设置到 4 的时候,构建需要的内存就需要 60GB 以上了。
MAX_JOBS=按照你的情况来 python setup.py develop
构建的过程非常漫长,过程中我们可以去干点别的事情。
当然,为了我们后续使用镜像方便,最好的方案是编写一个 Dockerfile,然后将构建的产物保存在镜像中,以方便后续各种场景使用:
FROM nvcr.io/nvidia/pytorch:23.12-py3
LABEL maintainer="soulteary@gmail.com"
# according to your situation, use pypi mirrors
RUN pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
WORKDIR /app
# xformers
RUN git clone --recursive https://github.com/facebookresearch/xformers.git --depth 1
RUN git config --global --add safe.directory /app/xformers && \
git config --global --add safe.directory /app/xformers/third_party/flash-attention && \
git config --global --add safe.directory /app/xformers/third_party/cutlass
RUN cd /app/xformers/third_party/flash-attention && git pull origin main && \
cd /app/xformers/third_party/cutlass && git pull origin main && git checkout v3.3.0
WORKDIR /app/xformers
RUN echo '' > requirements.txt
RUN pip install ninja
ARG MAX_JOBS=1
RUN pip install -v -e .
在构建的时候,我们可以使用类似下面的命令,来搞定既使用了最新的 Nvidia 镜像,包含最新的 Pytorch 和 CUDA 版本,又包含 xFormers 加速组件的容器环境。
docker build -t soulteary/common-runtime --build-arg MAX_JOBS=3 .
如果你是在本机上进行构建,没有使用 Docker,那么构建成功,你将看到类似下面的日志:
...
Creating /usr/local/lib/python3.10/dist-packages/xformers.egg-link (link to .)
Adding xformers 0.0.24+6600003.d20240112 to easy-install.pth file
Installed /app/docker/xformers
Successfully installed xformers-0.0.24+6600003.d20240112
等待漫长的构建结束,我们可以使用下面的命令,来启动一个包含构建产物的容器,来测试下构建是否成功:
docker run --rm -it --gpus all --ipc=host --ulimit memlock=-1 -v `pwd`:/app soulteary/common-runtime bash
当我们进入容器的交互式命令行之后,我们可以执行 python -m xformers.info,来验证 xFromers 是否构建正常:
xFormers 0.0.24+6600003.d20240112
memory_efficient_attention.cutlassF: available
memory_efficient_attention.cutlassB: available
memory_efficient_attention.decoderF: available
memory_efficient_attention.flshattF@v2.3.6: available
memory_efficient_attention.flshattB@v2.3.6: available
memory_efficient_attention.smallkF: available
memory_efficient_attention.smallkB: available
memory_efficient_attention.tritonflashattF: unavailable
memory_efficient_attention.tritonflashattB: unavailable
memory_efficient_attention.triton_splitKF: available
indexing.scaled_index_addF: available
indexing.scaled_index_addB: available
indexing.index_select: available
swiglu.dual_gemm_silu: available
swiglu.gemm_fused_operand_sum: available
swiglu.fused.p.cpp: available
is_triton_available: True
pytorch.version: 2.2.0a0+81ea7a4
pytorch.cuda: available
gpu.compute_capability: 8.9
gpu.name: NVIDIA GeForce RTX 4090
dcgm_profiler: unavailable
build.info: available
build.cuda_version: 1230
build.python_version: 3.10.12
build.torch_version: 2.2.0a0+81ea7a4
build.env.TORCH_CUDA_ARCH_LIST: 5.2 6.0 6.1 7.0 7.2 7.5 8.0 8.6 8.7 9.0+PTX
build.env.XFORMERS_BUILD_TYPE: None
build.env.XFORMERS_ENABLE_DEBUG_ASSERTIONS: None
build.env.NVCC_FLAGS: None
build.env.XFORMERS_PACKAGE_FROM: None
build.nvcc_version: 12.3.107
source.privacy: open source
以及,使用 python -m torch.utils.collect_env 再次确认下环境是否一致:
# python -m torch.utils.collect_env
PyTorch version: 2.2.0a0+81ea7a4
Is debug build: False
CUDA used to build PyTorch: 12.3
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.3 LTS (x86_64)
GCC version: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
Clang version: Could not collect
CMake version: version 3.27.9
Libc version: glibc-2.35
Python version: 3.10.12 (main, Nov 20 2023, 15:14:05) [GCC 11.4.0] (64-bit runtime)
Python platform: Linux-6.5.0-14-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 12.3.107
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 4090
Nvidia driver version: 525.147.05
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.8.9.7
/usr/lib/x86_64-linux-gnu/libcudnn_adv_infer.so.8.9.7
/usr/lib/x86_64-linux-gnu/libcudnn_adv_train.so.8.9.7
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_infer.so.8.9.7
/usr/lib/x86_64-linux-gnu/libcudnn_cnn_train.so.8.9.7
/usr/lib/x86_64-linux-gnu/libcudnn_ops_infer.so.8.9.7
/usr/lib/x86_64-linux-gnu/libcudnn_ops_train.so.8.9.7
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
...
Versions of relevant libraries:
[pip3] numpy==1.24.4
[pip3] onnx==1.15.0rc2
[pip3] optree==0.10.0
[pip3] pytorch-quantization==2.1.2
[pip3] torch==2.2.0a0+81ea7a4
[pip3] torch-tensorrt==2.2.0a0
[pip3] torchdata==0.7.0a0
[pip3] torchtext==0.17.0a0
[pip3] torchvision==0.17.0a0
[pip3] triton==2.1.0+6e4932c
最后
好了,这篇文章就先写到这里啦。
–EOF
我们有一个小小的折腾群,里面聚集了一些喜欢折腾、彼此坦诚相待的小伙伴。
我们在里面会一起聊聊软硬件、HomeLab、编程上、生活里以及职场中的一些问题,偶尔也在群里不定期的分享一些技术资料。
关于交友的标准,请参考下面的文章:
致新朋友:为生活投票,不断寻找更好的朋友
当然,通过下面这篇文章添加好友时,请备注实名和公司或学校、注明来源和目的,珍惜彼此的时间 😄
关于折腾群入群的那些事
本文使用「署名 4.0 国际 (CC BY 4.0)」许可协议,欢迎转载、或重新修改使用,但需要注明来源。 署名 4.0 国际 (CC BY 4.0)
本文作者: 苏洋
创建时间: 2024年01月12日
统计字数: 10731字
阅读时间: 22分钟阅读
本文链接: https://soulteary.com/2024/01/12/xformers-source-code-compilation-with-nvidia-docker.html