本文主要介绍磁盘性能评估的方法,针对用户态驱动Kernel与SPDK中各种IO测试工具的使用方法做出总结。其中fio是一个常用的IO测试工具,可以运行在Linux、Windows等多种系统之上,可以用来测试本地磁盘、网络存储等的性能。为了和SPDK的fio工具相区别,我们称之为内核fio。
SPDK有自己的IO测试工具,包括fio_plugin,perf和bdevperf。SPDK采用异步I/O(Asynchronous I/O)加轮询(Polling)的工作模式,通常与Kernel的异步I/O作为对比。在此,主要介绍通过使用fio评估Kernel异步I/O,SPDK的三种IO测试工具。
一 . FIO准备工作
在测试内核fio和SPDK fio_plugin工具之前,我们先准备好环境。
1. 编译fio
首先,下载fio源码,建议至少切换到3.3及以上版本。
git clone https : //github . com/axboe/fio
cd fio && git checkout fio-3.3
make2. 编译SPDK
下载最新的SPDK源码。然后,运行SPDK configure脚本以启用fio(将其指向fio代码库的根)。
git clone https : //github . com/spdk/spdk
cd spdk
git submodule update --init
./configure--with-fio=/path/to/fio/repo <other configuration options>
(例如:./configure --with-fio=/usr/src/fio)
make 当使用参数--with-fio编译时,我们会发现在<spdk_repo>/build/fio目录会有下面两个文件,这就是fio_plugin的可执行程序。
二. 内核fio工具测试磁盘性能
典型的fio工作过程:
1)写一个job文件来描述要访真的io负载。一个job文件可以控制产生任意数目的线程和文件。典型的job文件有一个global段(定义共享参数),一个或多个job段(描述具体要产生的job)。
2)运行时,fio从文件读这些参数,做处理,并根据这些参数描述,启动这些线程/进程。
运行fio:
# fio job_file它会根据job_file的内容来运行。我们可以在命令行中指定多个job file,fio串行化运行这些文件。
Job文件格式:
job file格式采用经典的ini文件,[]中的值表示job name,可以采用任意的ASCII字符。
IO引擎:
ioengine=str定义job向文件发起IO的方式。使用I/O引擎就是使用某些函数,以某些特定方式来访问存储,Linux可以使用 libaio,sync,psync等。这里只介绍libaio的例子,以用作和下文SPDK的fio_plugin做对比。
libaio,即异步I/O的引擎。这时通常,I/O请求会发送到相应的队列中,等待被处理,因此队列深度将会影响磁盘性能。所以在测试异步I/O的时候,根据磁盘的特性指定相应的队列深度(iodepth)。
一个典型的fio配置文件,nvme_bdev_job.fio:
[global]
ioengine=libaio
thread=1
group_reporting=1
direct=1
norandommap=1
cpumask=1
bs=4k
rw=randread
iodepth=256
time_based=1
ramp_time=0
runtime=30
[job]
filename=/dev/nvme0n1部分参数解释
ioengine:指定I/O引擎,在这里测试Kernel的异步I/O,因此指定I/O引擎为libaio;
direct:指定direct模式O_DIRECT,I/O会绕过系统的page buffer;
rw:读写模式,这里指定randrw表示混合随机读写;
rwmixread:混合随机读写模式下read请求所占比例;
thread:指定使用线程模式。由于spdk fio_plugin只支持线程模式,因此与Kernel对比时,通常都统一指定线模式来对比;
norandommap:指定I/O时,每次都获取一个新的随机offset,防止额外的CPU使用消耗;
time_based:指定采用时间模式;
runtime:测试时长,单位是秒;
ramp_time:统计性能之前所运行的时间,为了防止没有进行稳态而造成的性能虚高带来的影响,单位是秒;
bs:I/O块大小;
iodepth:队列深度;
numjobs:worker的个数;
filename:指定测试的对象。
运行fio(带配置文件)举例:
[root@server spdk]# fio nvme_bdev_job.fio另一种用法,不使用fio文件,直接使用参数
# fio -filename=/dev/nvme0n1 -direct=1 -iodepth 1 -thread -rw=randread \
-ioengine=libaio -bs=4k -size=1G -runtime=10 -group_reporting -name=rand_read_4k三. SPDK的fio_plugin工具
通常,在内核模式下,使用fio工具来测试设备在实际的工作负载下所能承受的最大压力。用户可启动多个线程,对设备来模拟各种IO操作,使用filename指定所被测试的设备。然而,在SPDK用户态模式情况下,SPDK在使用前会unbind内核驱动,直接通过PCI地址来识别设备,因此用户在系统上无法直接看到设备。为此,SPDK推出fio_plugin与SPDK深度集成,用户可以通过指定设备的PCI地址,来决定所要进行压力测试的设备。同时,在fio_plugin内部,采用SPDK用户态设备驱动提供的轮询和异步的方式进行I/O操作,I/O通过SPDK直接写入磁盘。
SPDK提供两种形态的fio_plugin:
- 基于裸盘NVMe的fio_plugin,其特点为I/O通过SPDK用户态驱动直接访问裸盘,常用于评估SPDK用户态驱动在裸盘上的性能。
- 基于bdev的fio_plugin,其特点为I/O测试基于SPDK块设备bdev之上,所有I/O经由块设备层bdev,再传送至裸盘设备。常用于评估SPDK块设备bdev的性能。
1. 基于NVMe的fio_plugin
前提条件
按照第一章节步骤,下载好内核fio和SPDK代码并编译。
测试方法
a. 使用fio_plugin测试裸盘,需要引入fio_plugin路径,因此在运行fio时,在fio命令之前加如下参数:
export LD_PRELOAD(只需要一遍)
LD_PRELOAD=<path to spdk repo>/build/fio/spdk_nvme(如果解除,用unset LD_PRELOAD)
也可以export LD_PRELOAD=spdk/examples/… 写成一句
b. 其次,需要在fio配置文件中设定ioengine为spdk。
ioengine=spdkc. 运行fio_plugin时,同时要通过额外的参数'--filename'指定SPDK能够识别的设备地址信息。
但是,NVMe的fio_plugin配置文件里不需要指定spdk_json_conf。
通常,NVMe的fio_plugin支持两种模式下的测试,
一是本地的NVMe设备,即NVMe over PCIe;
二是远端的NVMe设备,即NVMe over Fabrics。
运行,NVMe over PCIe:
[root@server spdk]# LD_PRELOAD=build/fio/spdk_nvme /usr/src/fio/fio \
spdk_nvme1.fio '--filename=trtype=PCIe traddr=0000.06.00.0 ns=1'在initiator端执行NVMe over Fabrics(transport=RDMA):
[root@server2 spdk]# LD_PRELOAD=build/fio/spdk_nvme \
/usr/src/fio/fio spdk_nvme1.fio \
'--filename=trtype=RDMA adrfam=IPv4 traddr=192.168.100.8 trsvcid=4420 ns=1'或者,在initiator端执行NVMe over Fabrics(transport=TCP):
[root@server2 spdk]# LD_PRELOAD=build/fio/spdk_nvme \
/usr/src/fio/fio spdk_nvme1.fio \
'--filename=trtype=TCP adrfam=IPv4 traddr=192.168.100.8 trsvcid=4420 ns=1'配置文件spdk_nvme1.fio如下所示:
[global]
ioengine=spdk (前提./configure --with-fio=/usr/src/fio,如果是=libaio则不需要--with-fio)
thread=1
group_reporting=1
direct=1
verify=0
time_based=1
ramp_time=0
runtime=20
iodepth=128
rw=randrw
bs=4k
numjobs=1
[job]执行NVMe over Fabrics(RDMA/TCP)的前提条件是target端要启动nvmf进程,
[root@server1 spdk]#./build/bin/nvmf_tgt --json spdk_tgt_nvmf.jsonspdk_tgt_nvmf.json(以transport=TCP为例)文件如下:
{
"subsystems": [
{
"subsystem": "bdev",
"config": [
{
"method": "bdev_nvme_attach_controller",
"params": {
"name": "Nvme0",
"trtype": "PCIe",
"traddr": "0000:81:00.0",
"prchk_reftag": false,
"prchk_guard": false
}
}
]
},
{
"subsystem": "nvmf",
"config": [
{
"method": "nvmf_set_config",
"params": {
"acceptor_poll_rate": 10000,
"admin_cmd_passthru": {
"identify_ctrlr": false
}
}
},
{
"method": "nvmf_set_max_subsystems",
"params": {
"max_subsystems": 1024
}
},
{
"method": "nvmf_create_transport",
"params": {
"trtype": "TCP",
"max_queue_depth": 128,
"max_io_qpairs_per_ctrlr": 127,
"in_capsule_data_size": 4096,
"max_io_size": 131072,
"io_unit_size": 24576,
"max_aq_depth": 128,
"max_srq_depth": 4096,
"abort_timeout_sec": 1
}
},
{
"method": "nvmf_create_subsystem",
"params": {
"nqn": "nqn.2018-09.io.spdk:cnode1",
"allow_any_host": true,
"serial_number": "SPDK001",
"model_number": "SPDK bdev Controller",
"max_namespaces": 8
}
},
{
"method": "nvmf_subsystem_add_listener",
"params": {
"nqn": "nqn.2018-09.io.spdk:cnode1",
"listen_address": {
"trtype": "TCP",
"adrfam": "IPv4",
"traddr": "192.168.100.8",
"trsvcid": "4420"
}
}
},
{
"method": "nvmf_subsystem_add_ns",
"params": {
"nqn": "nqn.2018-09.io.spdk:cnode1",
"namespace": {
"nsid": 1,
"bdev_name": "Nvme0n1",
"uuid": "51581506-537f-4236-9bc1-d926c966d09b"
}
}
}
]
}
]
}目前SPDK只支持Json格式配置文件,以前习惯使用INI格式的用户,可以使用SPDK的自动转换工具,把INI格式变为Json格式。
[root@server spdk]# ./scripts/config_converter.py < config.ini \
> config_converter.jsona. 对于使用1个core,测试多块盘的情况,通常只需要设定numjob为1,同时在fio命令通过多个filename参数来指定多块要测试的盘(多个filename参数之间用空格相隔即可),例如同时测试三块盘:
[root@server spdk]# LD_PRELOAD=build/fio/spdk_nvme \
/usr/src/fio/fio spdk_nvme1.fio \
'--filename=trtype=PCIe traddr=0000.06.00.0 ns=1' \
'--filename=trtype=PCIe traddr=0000.07.00.0 ns=1' \
'--filename=trtype=PCIe traddr=0000.08.00.0 ns=1'b. 对于使用fio_plugin作为新的ioengine而引入的新的fio参数说明,可以通过以下命令查看:
[root@server spdk]# LD_PRELOAD=build/fio/spdk_nvme /usr/src/fio/fio --enghelp=spdk
表3.1 nvme fio_plugin的格式
c. 此外,可以通过直接在ioengine中指定fio_plugin的路径,而无须每次运行fio都动态加载LD_PRELOAD。
ioengine=<path to spdk repo>/build/fio/spdk_nvme只需运行:
[root@server spdk]# /usr/src/fio/fio spdk_nvme2.fio \
'--filename=trtype=PCIe traddr=0000.06.00.0 ns=1'配置文件spdk_nvme2.fio如下所示:
[global]
ioengine=build/fio/spdk_nvme
thread=1
group_reporting=1
direct=1
verify=0
time_based=1
ramp_time=0
runtime=20
iodepth=128
rw=randrw
bs=4k
numjobs=1
[job]也可以把filename写到配置文件里,
[job]
filename=trtype=PCIe traddr=0000.06.00.0 ns=1这时只需运行,
[root@server spdk]# /usr/src/fio/fio spdk_nvme2.fio2. 基于bdev的fio_plugin
基于bdev的fio_plugin是将I/O在SPDK块设备bdev之上进行发送。而基于裸盘的fio_plugin,I/O是直接到裸盘上进行处理。两者最大的差别在于I/O是否经过bdev这一层。因此,基于bdev的fio_plugin能够很好的评估SPDK块设备层bdev的性能。其编译安装与裸盘的fio_plugin完全相同。
测试方法
a. 使用fio_plugin测试bdev性能,需要指定bdev fio_plugin的路径,因此在运行fio时,在fio命令前加如下参数
LD_PRELOAD=<path to spdk repo>/build/fio/spdk_bdevb. 需要在fio配置文件中设定ioengine为spdk_bdev。
ioengine=<path to spdk>/build/fio/spdk_bdevc. 与nvme的fio_plugin相比,fio配置文件必须包含一个新参数spdk_json_conf,需要在配置文件中指定SPDK启动配置文件。如下所示:
spdk_json_conf=./examples/bdev/fio_plugin/bdev.jsonbdev.json中指定了所用的bdev信息,以创建malloc为例:
{
"subsystems": [
{
"subsystem": "bdev",
"config": [
{
"params": {
"block_size": 512,
"num_blocks": 262144,
"name": "Malloc0"
},
"method": "bdev_malloc_create"
}
]
}d. 运行fio的时候,通过'--filename'直接指定所要测试的bdev名称即可,运行:
[root@server spdk]# LD_PRELOAD=build/fio/spdk_bdev /usr/src/fio/fio \
spdk_bdev1.fio '--filename=Malloc0'spdk_bdev1.fio如下所示:
[global]
ioengine=spdk_bdev
spdk_json_conf=./examples/bdev/fio_plugin/bdev.json
thread=1
group_reporting=1
direct=1
verify=0
time_based=1
ramp_time=0
runtime=2
iodepth=128
rw=randrw
bs=4k
numjobs=1
[test]也可以把filename写进配置文件里,
[test]
filename=Malloc0这时只需运行,
[root@server spdk]# LD_PRELOAD=build/fio/spdk_bdev /usr/src/fio/fio spdk_bdev1.fio其他说明
a. 使用基于bdev的fio_plugin测试多个设备时候,需要在spdk运行配置文件中写入相应的bdev配置信息,其次在fio运行时,指定多个filename参数即可,多个filename之间用空格相隔。例如同时测两个设备Malloc0与Nvme0n1,如下所示:
[root@server spdk]# LD_PRELOAD=build/fio/spdk_bdev /usr/src/fio/fio \
spdk_bdev1.fio '--filename=Nvme0n1' '--filename=Malloc0'b. 同理,若查看基于bdev的fio_plugin相关参数说明,可以通过如下命令:
[root@server spdk]# LD_PRELOAD=build/fio/spdk_bdev /usr/src/fio/fio \
--enghelp=spdk_bdevc. 此外,可以通过直接在ioengine中指定fio_plugin的路径,而无须每次运行fio都动态加载LD_PRELOAD。即:
fio配置文件中添加修改
ioengine=<path to spdk repo>/build/fio/spdk_bdev运行:
[root@server spdk]# /usr/src/fio/fio examples/bdev/fio_plugin/example_config.fio \ '--filename=Malloc0'即可测试。

表3.2 bdev fio_plugin的格式
d. 测试两个bdev的例子,先通过json文件创建两个malloc块设备。
bdev2.json示例如下:
{
"subsystems": [
{
"subsystem": "bdev",
"config": [
{
"method": "bdev_malloc_create",
"params": {
"name": "Malloc0",
"num_blocks": 102400,
"block_size": 512
}
},
{
"method": "bdev_malloc_create",
"params": {
"name": "Malloc1",
"num_blocks": 102400,
"block_size": 512
}
}
]
}
]
}运行
[root@server spdk]# /usr/src/fio/fio spdk_bdev2.fio spdk_bdev2.fio如下所示:
[global]
ioengine=build/fio/spdk_bdev
spdk_json_conf=./examples/bdev/fio_plugin/bdev2.json
thread=1
group_reporting=1
direct=1
verify=0
time_based=1
ramp_time=0
runtime=2
iodepth=128
rw=randrw
bs=4k
numjobs=1
[test1]
filename=Malloc0
[test2]
filename=Malloc1也可以写成:
[test]
filename=Malloc0:Malloc1上面的例子是测试本地的bdev设备,fio_plugin也可以测试远端的bdev设备。先在target端启动nvmf进程,
[root@server1 spdk]# ./build/bin/nvmf_tgt --json spdk_tgt_nvmf.json接着在initiator端运行fio_plugin,
[root@server2 spdk]# LD_PRELOAD=build/fio/spdk_bdev \
/usr/src/fio/fio spdk_bdev3.fiospdk_bdev3.fio如下所示:
[global]
ioengine=spdk_bdev
spdk_json_conf=./examples/bdev/fio_plugin/nvmf_bdev.json
thread=1
group_reporting=1
direct=1
verify=0
time_based=1
ramp_time=0
runtime=10
iodepth=128
rw=randrw
bs=4k
numjobs=1
[test]
filename=Nvme0n1nvmf_bdev.json如下所示:
{
"subsystems": [
{
"subsystem": "bdev",
"config": [
{
"params": {
"name": "Nvme0",
"trtype": "rdma",
"traddr": "192.168.100.8",
"adrfam": "ipv4",
"trsvcid": "4420",
"subnqn": "nqn.2018-09.io.spdk:cnode1"
},
"method": "bdev_nvme_attach_controller"
}
]
}
]
}上面是RDMA的例子,TCP的也是一样,只需把"trtype"设为"tcp"。
3. NVMe/bdev fio_plugin的比较
测试裸盘块设备,使用NVMe fio_plugin。在bdev这一层测试块设备,使用bdev fio_plugin,这个区别体现在配置文件里。
[job] 这是nvme层的写法,spdk_nvme使用
filename=trtype=PCIe traddr=0000.06.00.0 ns=1[job1] 这是bdev层的写法,spdk_bdev使用
filename=/dev/nvme0n1[job2]
filename=/dev/nvme1n1[job3] 多个bdev的写法
filename=Null0:Null1:Null2:Null3:Null4:Null5:Null6:Null7:Null8:Null9
表3.3 NVMe/bdev fio_plugin的比较
四. SPDK的perf工具
1. 基于NVMe的perf工具
SPDK提供自己的性能测试工具perf。SPDK的perf与通常Linux系统中的perf工具有所不同,SPDK中的perf主要是用于对设备做压力测试,来评估其性能的工具。perf相比于fio_plugin更加灵活,可以直接配置core mask来指定进行I/O操作的CPU核。SPDK通过使用CPU的亲和性,将线程和CPU核做绑定,每个线程对应一个CPU核。在启动perf时,可通过core mask指定所用的CPU核,在所指定的每个CPU核上,都会为之注册一个worker_thread进行I/O操作。每个worker_thread都会调用SPDK所提供的I/O操作接口,通过异步的方式向底层的裸盘发送读写命令。
成功编译SPDK后,可在build/examples/目录下找到perf工具的可执行文件。Perf命令参数如下所示:
perf
-c <core mask for I/O submission/completion>
-q <io depth>
-t <time in seconds>
-w <io pattern type: write|read|randread|randwrite>
-s <DPDK huge memory size in MB>
-o <io size in bytes>
-r <transport ID for local PCIe NVMe or NVMeoF>perf支持本地的NVMe设备,同时也支持远端的NVMeoF的设备。使用范例如下:
NVMe over PCIe:
[root@server spdk]#./build/examples/perf -q 32 -s 1024 -w randwrite -t 1200 \
-c 0xF -o 4096 -r 'trtype:PCIe traddr:0000:06:00.0'
NVMe over Fabrics(transport=RDMA/TCP):
[root@server2 spdk]#./build/examples/perf -q 32 -s 1024 -w randwrite -t 1200 \
-c 0xF -o 4096 -r 'trtype:RDMA adrfam:IPv4 traddr:192.168.100.8 trsvcid:4420'对于同时测试多块盘,只需要添加-r并指定设备地址即可,例如一个core测试三块盘:
[root@server spdk]#./build/examples/perf -q 32 -s 1024 -w randwrite -t 1200 \
-c 0x1 -o 4096 \
-r 'trtype:PCIe traddr:0000:06:00.0' \
-r 'trtype:PCIe traddr:0000:07:00.0' \
-r 'trtype:PCIe traddr:0000:08:00.0'2. perf评估Linux异步I/O(AIO)
使用方式与测试spdk driver相同,只需要在perf命令后添加设备名称即可。使用范例如下:
[root@server spdk]#./build/examples/perf -q 32 -s 1024 -w randwrite -t 1200 \
-c 0xF -o 4096 /dev/nvme0n1
(./scripts/setup.sh reset后才能看到/dev/nvme0n1)相对于fio_plugin,perf有以下优势:
a. 可以通过core mask灵活指定CPU核。
b. 如果使用单个线程来测试多块盘性能的时候,fio_plugin的所得到的性能与perf所的到的性能有很大的差距。这是由于fio软件架构的问题,所以不适用于单个线程来操作多块盘。因此在评估单个线程(单核)的能力的时候,一般选用perf作为测试工具。若为多个线程对应操作多块盘,则无需顾虑。在这种情况下,fio_plugin与perf结果无差异。
3. 基于bdev的perf工具bdevperf
成功编译SPDK后,可在test/bdev//目录下找到bdevperf工具的可执行文件。命令参数如下:
--json <config>
-q <io depth>
-t <time in seconds>
-w <io pattern type: write|read|randread|randwrite>
-s <memory size in MB for DPDK>
-o < size in bytes>
-m <core mask for DPDK>其中,--json是指定配置文件,需要测试的bdev设备都在配置文件中指定。下面给出3个具体的例子。
例1: bdevperf最基本的用法。
若需要测试本地的两块malloc设备,则bdevperf启动参数示例如下:
[root@server spdk]#./test/bdev/bdevperf/bdevperf -q 32 -s 1024 -w randwrite \
-t 60 -o 4096 -m 0xF --json bdev2.json如果要测试远端块设备,请替换配置文件,类似3.1章节的spdk_tgt_nvmf.json。
例2: 实时监控I/O的刷新。
-z 参数等待RPC命令启动bdevperf,-S参数是显示性能数据的刷新频率。
[root@server spdk]# ./test/bdev/bdevperf/bdevperf -S 1 -q 32 -t 60 \
-m 0xF -o 4096 -w write -z在另一个窗口,用RPC命令创建两个NVMe bdev。
[root@server spdk]# ./scripts/rpc.py bdev_nvme_attach_controller -b "Nvme0" \
-t "pcie" -a 0000:06:00.0
[root@server spdk]# ./scripts/rpc.py bdev_nvme_attach_controller -b "Nvme1" \
-t "pcie" -a 0000:07:00.0接着运行bdevperf.py,启动bdevperf。
[root@server spdk]# ./test/bdev/bdevperf/bdevperf.py perform_tests第一个窗口就会不断显示I/O刷新,持续时间为-t的值。顺便说一句,-T参数可以让I/O跑在指定的bdev上。
Job: Nvme0n1 (Core Mask 0x1)
Nvme0n1 : 48352.50 IOPS 188.88 MiB/s
Job: Nvme1n1 (Core Mask 0x2)
Nvme1n1 : 55140.50 IOPS 215.39 MiB/s
=====================================================
Total : 103493.00 IOPS 404.27 MiB/s
……例3: 指定job文件。
-j,可以把自定义的I/O文件作为参数传入。
./test/bdev/bdevperf/bdevperf -t 10 --json bdev2.json -j bdev2.fiobdev2.fio如下所示:
[global]
bs=1024
rwmixread=70
rw=read
iodepth=256
cpumask=0xff
[test1]
filename=Malloc0
[test2]
filename=Malloc1五. SPDK的fio.py工具
SPDK把fio封装进了python文件,目前使用的ioengine是libaio,也可以改为其他ioengine。
fio.py在scripts文件夹里,命令参数如下所示:
-i IO_SIZE,
The desired I/O size in bytes.
-p PROTOCOL,
The protocol we are testing against. One of iscsi or nvmf.
-d QUEUE_DEPTH,
The desired queue depth for each job.
-t TEST_TYPE,
The fio I/O pattern to run. e.g. read, randwrite, randrw.
-r RUNTIME,
Time in seconds to run the workload.
-n NUM_JOBS,
The number of fio jobs to run in your workload.
-v,
Supply this argument to verify the I/O.值得注意的是,要启动SPDK target进程后,才能使用fio.py。
举个例子:
在target端启动nvmf进程
[root@server1 spdk]# ./build/bin/nvmf_tgt在initiator端通过rpc命令创建malloc的bdev,设定传输模式为rdma,并创建nvmf_subsystem和listener
[root@server2 spdk]# ./scripts/rpc.py bdev_malloc_create 64 512 -b Malloc0
[root@server2 spdk]# ./scripts/rpc.py nvmf_create_transport -t rdma -u 8192
[root@server2 spdk]# ./scripts/rpc.py nvmf_create_subsystem \
nqn.2016-06.io.spdk:cnode1 -a -s SPDK1
[root@server2 spdk]# ./scripts/rpc.py nvmf_subsystem_add_ns \
nqn.2016-06.io.spdk:cnode1 Malloc0
[root@server2 spdk]# ./scripts/rpc.py nvmf_subsystem_add_listener \
nqn.2016-06.io.spdk:cnode1 -t rdma -a 192.168.100.8 -s 4420initiator端连接到target端
[root@server2 spdk]# nvme connect -t rdma -n "nqn.2016-06.io.spdk:cnode1" \
-a 192.168.100.8 -s 4420运行fio.py(当然这里也可以直接使用内核fio测试)
[root@server2 spdk]# ./scripts/fio.py -p nvmf -i 262144 -d 64 -t read -r 10fio结束后,断开target连接
[root@server2 spdk]# nvme disconnect -n "nqn.2016-06.io.spdk:cnode1"上面启动target和多条RPC命令,也可以写进json文件一并执行。
[root@server spdk]# ./build/bin/nvmf_tgt --json spdk_tgt_nvmf.json六. 以上性能测试工具的比较
目前SPDK fio_plugin仅限于线程使用模型,因此在使用SPDK fio_plugin时,fio job还必须指定thread = 1。
如果通过ioengine参数指定引擎的完整路径来动态加载ioengine,则fio当前也会在关闭时出现竞争条件 - 建议使用LD_PRELOAD以避免此竞争条件。在测试随机工作负载时,建议设置norandommap = 1。
fio的随机映射处理会消耗额外的CPU周期,这将使fio_plugin的性能随着时间的推移而降低,因为所有I/O都是在单个CPU内核上提交和完成的。
在使用SPDK插件在多个NVMe SSD上测试FIO时,建议在FIO配置中使用多个Jobs。
据观察,在测试多个NVMe SSD时,FIO(启用了SPDK plugin)和SPDK perf(examples/nvme/perf/perf)之间存在一些性能差距。
如果使用一个配置用于FIO测试的Job(即使用一个CPU核心),则性能比多个NVMe SSD时的SPDK perf(也使用一个CPU核心)差。 但是如果你使用多个Jobs进行FIO测试,FIO的性能就与SPDK perf相当。 在分析了这一现象后,我们认为这是由FIO架构引起的。 主要是FIO可以使用多个线程进行扩展(即使用多个CPU内核),但是对于多个I/O设备时,使用一个线程并不好。
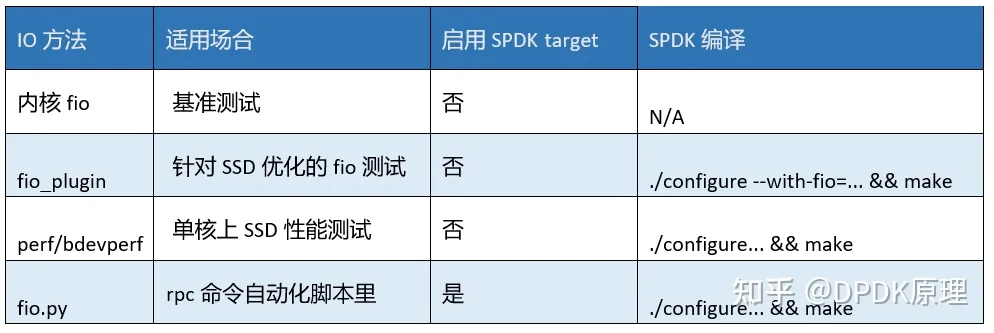
表6.1 四种性能测试工具的比较
七. 常见问题
1. perf的性能比fio高
通过fio与perf对SPDK进行性能评估,得到的结果不同,大部分时候perf所得到的性能会比fio所得到的性能要高。
两种工具最大的差别在于,fio是通过与Linux fio工具进行集成,使其可以用fio_plugin引擎测试SPDK设备。而由于fio本身架构的问题,不能充分发挥SPDK的优势,整个应用框架仍然使用fio原本的架构。例如fio使用Linux的线程模型,在使用的时候,线程仍然被内核调度。而对于perf来说,是针对SPDK所设计的性能测试工具,因此在底层,不仅是I/O通过SPDK下发,同时一些底层应用框架都是为SPDK所设计的。例如刚刚所提到的线程模型,perf中是使用DPDK所提供的线程模型,通过使用CPU的亲和性将CPU核与线程捆绑,不再受内核调度,因此可以充分发挥SPDK下发I/O时的异步无锁化优势。这就是为什么perf所测得的性能要比fio高,尤其是在使用单个线程(单核)同时测试多块盘的情况下,fio所得性能要明显小于perf所得性能。因此,在同等情况下,我们更推荐用户使用perf工具对SPDK进行性能评估。
此外,在多numjob的情况下,fio与perf对iodepth的分配是不同的。通常在fio中,指定的iodepth表示所有job一共的iodepth,而在perf指定的iodepth(perf中-q参数)通常指每个job所使用的iodepth。举例如下:Fio:numjob=4, iodepth=128。则每个job对应的iodepth为32(128/4)。Perf:-c 0xF(相当于fio中numjob=4),-q 128(相当于fio中iodepth=128)。则每个job对应的iodepth为128。
2. 为什么测不出性能差异
对SPDK和内核的性能评估时,虽然性能有所提升,但是没有看到SPDK官方所展示的特别大的性能差异。
首先,如问题1中所述,不同的工具之间所得出的性能结果是不同的,另外最主要的因素还是硬盘本身的性能瓶颈所导致的问题。例如,以2D NAND为介质的Intel DC P4510,本身的性能都存在一定的瓶颈,因此无论是SPDK用户态驱动还是内核驱动,都不会达到较高的IOPS。若换用更高性能的硬盘,例如使用以3D Xpoint为介质的Optane(Intel DC P4800X)为测试对象,便会看到很大的性能差异。因此,硬盘性能越高,SPDK所发挥出的优势越明显,这也是SPDK产生的初衷,其本身就是为高性能硬盘所订制的。
3. 硬盘(iodepth)与CPU core
关于评估不同硬盘的队列深度(iodepth)与CPU core的问题。
通常根据不同硬盘的特点,选择不同的iodepth以及所使用的CPU core。通常在评估以2D NAND、3D NAND介质的硬盘,一般情况下,为了达到磁盘的最高性能,通常会选择较高的iodepth(128或256)。对于P4XXX的硬盘,通常可能一个CPU core无法达到满IOPS,此时并不是由于一个core的能力不够,而是由于硬盘中硬件队列本身限制的问题。因此,通常需使用两个CPU core才能够达到specification中的满IOPS。此外,对于以3D Xpoint为介质的Optane(Intel P4800X),通常只需要一个core并使用较小的iodepth即可达到满IOPS,此时已经达到硬盘的上限,若再次增大iodepth只会是latency变大而IOPS不再增长。
下面给出各种硬盘建议的评估参数:
Intel P4500、Intel P4510、Intel P4600:numjob=2, iodepth=256
Intel Optane(Intel P4800X):numjob=1, iodepth=8/16/324. 写性能虚高
通常以2D NAND、3D NAND为介质的硬盘,在测试write/randwrite的性能时候,通常要比sepcification里的最高值高很多。这是由于这类介质本身的问题,所以在测试时会出现write/randwrite性能虚高的问题。因此在测试该类硬盘,为了避免此类现象,通常需要对磁盘做一次precondition。通常的做法为:在格式化之后,对磁盘不断进行写操作,写满整个磁盘,使其进行稳态。以DC P4510 2TB为例,通常首先以4KB的大小顺序写两小时,之后再随机写一小时。此外,在测试的时候,fio参数中的ramp_time可以设置较大一些,避免初始的虚高值计入最终结果。
5. 磁盘性能测试指标
通常,对于一个磁盘的性能,我们主要从三方面去评估:IOPS、bandwidth、latency。
IOPS:通常评估磁盘的IOPS,主要关注块大小为4k,随机读写的情况。因此,通常fio关键参数设为:
bs=4k
iodepth=128
direct=1
rw=randread/randwriteBandwidth:评估磁盘的bandwidth,通常是关注块大小为128k,顺序读写的情况。因此通常fio关键参数设为:
bs=128k
iodepth=128
direct=1
rw=read/writeLatency:评估latency通常情况下,是关注一个I/O发送/完成的延迟情况,因此,通常选择iodepth为1。因此,通常fio关键参数设为:
bs=4k
iodepth=1
direct=1
rw=randread/randwrite此外,对于latency的结果,不仅要关注平均值,同时也要注意长尾延迟,即99.99%的延迟情况。
注意:通常在测试磁盘的性能时,要添加direct=1,即绕过系统的cache buffer。这时测得的性能为裸盘的性能。