前言
动态网页是一种在用户浏览时实时生成或变化的网页。与静态网页不同,后者通常是预先编写好的HTML文件,直接由服务器传送给浏览器,内容在服务端生成且固定不变,获取静态数据的文章课查阅博主上一篇文章:详解静态网页数据获取以及浏览器数据和网络数据交互流程-Python。相比之下,动态网页可以根据用户的互动、请求或其他条件在浏览器端或服务器端生成新的内容。而且现在的网页一般都是采用前后端分离的架构,前端负责展示和用户交互,后端负责数据处理。这种架构使得前端可以更加灵活地实现动态内容的加载和展示。所以说以后想要获取到数据,动态网页数据获取会成为我们主流获取网页数据的技术。所以在动态网页数据获取这方面我们需要下足功夫了解动态网页数据交互形式、数据存储访问模式等方方面面的知识,我们才好更加灵活的获取到数据。
博主将尽可能将简化涉及到垂直领域的专业知识,转化为大众小白可以读懂易于理解的知识,将繁杂的程序创建步骤逐个拆解,以逐步递进的方式由难转易逐渐掌握并实践,欢迎各位学习者关注博主,博主将不断创作技术实用前沿文章。
一、动态网页和静态网页的区别
当我们谈论动态网页和静态网页时,我们主要是在讨论网页的内容是如何生成和呈现给用户的。想象一下,网页就像是餐厅里的菜单。
静态网页
就像是一张印刷好的菜单,上面的内容是固定的。每次你去餐厅,看到的菜单都是一样的,不会根据你的偏好或者是时间的变化而改变。
在网页方面,静态网页是一次创建好,之后内容就不再改变的。无论何时访问这个网页,你都会看到同样的内容。它们是直接从服务器上以文件形式提供的,不涉及任何内容的即时生成或处理。
动态网页
就像是一张电子菜单,可以根据你的口味偏好、季节、甚至是目前的库存来动态调整菜单内容。比如,如果是夏天,菜单可能会显示更多清凉饮品或沙拉;如果你是素食者,它会向你展示更多素食选项。
动态网页在你访问时才生成内容。这意味着网页可以根据用户的请求、时间、用户互动等因素来更改显示的内容。动态网页通常会使用服务器端的脚本语言(如PHP、ASP.NET、Java等)来生成页面内容,并且经常与数据库交互,以提供实时更新的内容。
这就是动态网页和静态网页之间的主要区别。动态网页更加灵活,能够提供个性化和交互式的体验,而静态网页则相对简单,内容固定。
二、网页何谓动态
动态网页技术在网页的HTML源码中通常不直接可见,因为它们在服务器端进行处理,然后生成最终的HTML内容发送给用户的浏览器。动态网页技术在网页HTML源码中通常不局限于特定的板块,而是遍布于整个页面的各个部分。比如用户登录状态的动态显示(比如显示用户的名字或头像)、基于用户角色或权限动态生成菜单项、分页或无限滚动,动态加载更多内容。最常见的当属通过按钮、滑块、标签页等,这些元素响应用户操作,如点击或滑动,来触发动态变化。
我们以一个网页实例开发会遇到的问题来看,比如评论区的开发,许多网站有文章或产品评论区,这些评论是实时从数据库加载的,并根据用户的浏览或互动实时更新。以Django的实例展示:
# Django 示例
def article(request, article_id):
article = Article.objects.get(pk=article_id)
comments = Comment.objects.filter(article=article).order_by('-date')
return render(request, 'article.html', {'article': article, 'comments': comments})
一些网站使用动态表单,根据用户的输入或选择来调整表单的选项。这些通常是通过JavaScript实现的,但可能会与服务器端代码交互以获取必要的数据。
document.getElementById('country-select').addEventListener('change', function() {
var country = this.value;
fetch('/api/getStates?country=' + country)
.then(response => response.json())
.then(data => {
// 更新状态选择框
});
});
动态网页技术的一个关键特点是它们通常依赖于JavaScript来操控DOM(文档对象模型),使得页面可以在不重新加载的情况下更新其内容。这种技术可以应用于几乎任何页面元素,并使得网页能够提供更加丰富和交互式的用户体验。
常见动态元素判断
在HTML中,通常没有固定的标签或类名专门用于表示动态内容,因为这些标记取决于开发者的个人选择或团队规范。不过我们可以讨论一些常见的模式和命名惯例来识别可能包含动态内容的元素。
1. 数据绑定的属性和类名
在使用现代前端框架(如React, Angular, Vue等)的网站中,你可能会看到一些特殊的属性,如ng-bind, v-model, {{data}}(在Vue和Angular中),这些通常表示与动态数据源绑定的元素。
<!-- Angular -->
<div ng-bind="user.name"></div>
<!-- Vue -->
<div v-bind:title="message"></div>
2. 通用的动态内容类名
一些常见的类名如dynamic, async, loader, content, ajax, update, fetch等,可能被用于表示动态加载或更新的内容。.
<div class="dynamic-content"></div>
<div class="loader"></div>
3. 列表和容器
对于动态加载的列表、评论、文章等,开发者可能会使用包含list, container, wrapper等单词的类名。
<ul class="comment-list"></ul>
<div class="article-container"></div>
4. 与API交互的元素
用于显示从API请求中获得数据的元素可能会有特定的类名,如api-data, fetch-data等。
<div class="api-response"></div>
<div class="fetch-data"></div>
5. JavaScript控制的元素
有时,元素可能没有明显的类名或属性来表明它们是动态的,但如果它们具有事件监听器或由JavaScript直接操作(如通过document.getElementById或document.querySelector),则这些元素也可能是动态的。
<button id="loadMore">加载更多</button>
<div id="dynamicSection"></div>
虽然这些命名习惯可以作为识别动态内容的线索,但它们并不是硬性规则。每个网站或应用可能有其独特的命名约定。通常理解一个网站的HTML结构和动态内容需要结合HTML源码和相关的JavaScript代码进行分析。
三、获取动态网页数据
获取动态网页数据可以使用多种技术,一般来说如果你需要频繁地与动态内容互动,Selenium或Puppeteer可能是较好的选择。如果你只需要抓取API返回的数据,网络请求分析可能更高效。具体分类下来有:
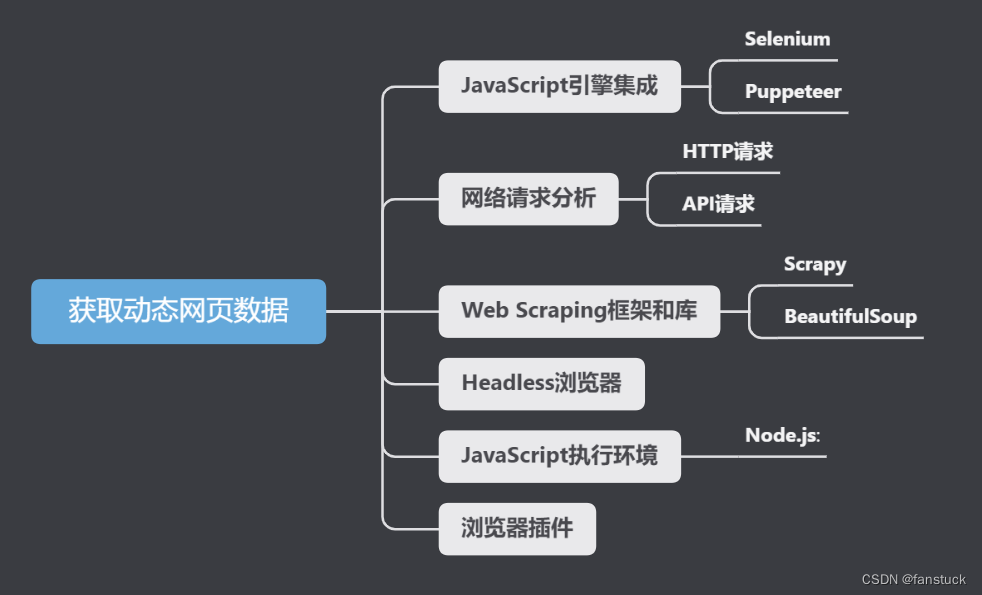
JavaScript引擎集成
Selenium
Selenium是一个自动化测试工具,它可以模拟用户在浏览器中执行的操作,如点击、滚动等。Selenium非常适合于爬取JavaScript动态加载的内容,因为它实际上是运行在一个真正的浏览器中,可以执行JavaScript。我之前的项目一半以上都是用selenium来做,现在各类反爬技术都在逐渐普及运用,selenium虽然较慢但不失为保底的技术策略。举一个简易的selenium的例子:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
# 配置Selenium驱动器(以Chrome为例)
driver = webdriver.Chrome(executable_path='path/to/chromedriver')
# 打开目标网页
driver.get('https://example-ecommerce.com/products')
# 等待页面动态加载完成
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, 'product'))
)
# 模拟向下滚动以加载更多产品(如果需要)
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(3) # 等待额外内容加载
# 获取产品信息
products = driver.find_elements(By.CLASS_NAME, 'product')
for product in products:
name = product.find_element(By.CLASS_NAME, 'product-name').text
price = product.find_element(By.CLASS_NAME, 'product-price').text
print(f'Product Name: {name}, Price: {price}')
# 关闭浏览器
driver.quit()
以上通常要注意:
- 动态内容加载时间:根据网站的响应时间,可能需要调整等待时间。
- 滚动页面:有些网站可能需要滚动才能加载更多内容。
execute_script方法用于执行JavaScript代码以模拟滚动。 - 异常处理:实际应用中,应添加异常处理逻辑来处理元素未找到、超时等问题。
Puppeteer
Puppeteer是一个Node库,提供了一个高级API来控制Chrome或Chromium。与Selenium类似,Puppeteer也能处理动态内容。
const puppeteer = require('puppeteer');
async function scrapeData() {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example-news.com/latest-news', {waitUntil: 'networkidle2'});
// 等待特定元素加载完成,确保页面已经加载了所需数据
await page.waitForSelector('.news-item');
// 获取数据
const newsItems = await page.evaluate(() => {
const items = [];
document.querySelectorAll('.news-item').forEach(item => {
const title = item.querySelector('.title').innerText;
const link = item.querySelector('a').href;
items.push({title, link});
});
return items;
});
console.log(newsItems);
await browser.close();
}
scrapeData();
以上示例仅为简单介绍 Puppeteer 的基本用法。在实际使用中,你可能需要处理更复杂的场景,如处理登录、处理分页、滚动页面等。
基于HTTP请求
基于HTTP请求的方法通常涉及分析网站的网络请求,特别是AJAX(异步JavaScript和XML)请求。一般可以用requests库来爬取动态生成的内容。
- 个假设的新闻网站,例如 "example-news-api.com/api/latest-news"
- 目标数据:新闻标题和链接
import requests
def fetch_news():
url = 'https://example-news-api.com/api/latest-news'
response = requests.get(url)
if response.status_code == 200:
news_data = response.json() # 假设API返回JSON格式数据
for news_item in news_data:
print(f"标题: {news_item['title']}, 链接: {news_item['url']}")
else:
print("无法获取数据")
if __name__ == "__main__":
fetch_news()
一般使用浏览器的开发者工具来分析网络请求,找出实际负责数据加载的API。动态内容通常以JSON格式返回,需要使用相应的方法来解析,实际应用中应当包含错误处理逻辑,例如处理非200的HTTP状态码。这种方法的优势在于效率较高,不需要加载整个网页,而是直接请求负责数据的API,但是可能还需要处理身份验证、会话管理或其他安全措施。
Web Scraping框架
使用Web Scraping框架(如Scrapy)爬取动态网页数据的案例通常涉及到与JavaScript交互或处理异步加载的内容。这里暂不展开,以后会有详细拿一篇文章专门讲述此内容。
想要获取更多内容欢迎私聊交流,点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
本章内容已经足够多了,下篇文章将展开selenium的采集项目讲解。