一、说明
数据集读取,使用、在磁盘上存储和构建图像数据集有一些约定,以便在训练和评估深度学习模型时能够快速高效地加载。本文介绍Keras 深度学习库中的ImageDataGenerator类等工具自动加载训练、测试和验证数据集。
二、ImageDataGenerator加载数据集
您可以使用Keras 深度学习库中的ImageDataGenerator类等工具自动加载训练、测试和验证数据集。此外,生成器将逐步加载数据集中的图像,使您可以处理包含数千或数百万张可能无法放入系统内存的图像的小型和非常大的数据集。
在本教程中,您将了解如何构建图像数据集以及如何在拟合和评估深度学习模型时逐步加载它。
完成本教程后,您将了解:
- 如何将训练、测试和验证图像数据集组织成一致的目录结构。
- 如何使用ImageDataGenerator类逐步加载给定数据集的图像。
- 如何使用准备好的数据生成器通过深度学习模型进行训练、评估和预测。
使用我的新书《计算机视觉深度学习》来启动您的项目,其中包括分步教程和所有示例的Python 源代码文件。让我们开始吧。
三、教程概述
本教程分为三个部分;他们是:
- 数据集目录结构
- 数据集结构示例
- 如何逐步加载图像
四、数据集目录结构
有一种标准方法可以布置用于建模的图像数据。
收集图像后,必须首先按数据集对它们进行排序,例如训练、测试和验证,然后按类别对它们进行排序。
例如,想象一个图像分类问题,我们希望根据汽车的颜色对照片进行分类,例如红色汽车、蓝色汽车等。
首先,我们有一个data/目录,我们将在其中存储所有图像数据。
接下来,我们将有一个用于训练数据集的data/train/目录和一个用于保留测试数据集的data/test/目录。在训练期间,我们还可能有用于验证数据集的数据/验证/ 。
到目前为止,我们已经:
|
1
2
3
4
|
data/
data/train/
data/test/
data/validation/
|
在每个数据集目录下,我们都会有子目录,每个类都有一个子目录,其中将放置实际的图像文件。
例如,如果我们有一个将汽车照片分类为红色汽车或蓝色汽车的二元分类任务,则我们将有两个类“红色”和“蓝色”,因此每个数据集目录下有两个类目录。
例如:
|
1
2
3
4
5
6
7
8
9
10
|
data/
data/train/
data/train/red/
data/train/blue/
data/test/
data/test/red/
data/test/blue/
data/validation/
data/validation/red/
data/validation/blue/
|
然后红色汽车的图像将被放置在适当的类目录中。
例如:
|
1
2
3
4
5
6
7
8
|
data/train/red/car01.jpg
data/train/red/car02.jpg
data/train/red/car03.jpg
...
data/train/blue/car01.jpg
data/train/blue/car02.jpg
data/train/blue/car03.jpg
...
|
请记住,我们不会将相同的文件放在red/和blue/目录下;相反,分别有红色汽车和蓝色汽车的不同照片。
另请记住,我们在训练、测试和验证数据集中需要不同的照片。
用于实际图像的文件名通常并不重要,因为我们将加载具有给定文件扩展名的所有图像。
如果您能够一致地重命名文件,一个好的命名约定是使用某个名称,后跟一个填充零的数字,例如image0001.jpg(如果您有数千个类的图像)。
五、示例数据集结构
我们可以通过一个例子使图像数据集结构具体化。
想象一下,我们正在对汽车照片进行分类,正如我们在上一节中讨论的那样。具体来说,就是红色汽车和蓝色汽车的二元分类问题。
我们必须创建上一节中概述的目录结构,具体来说:
|
1
2
3
4
5
6
7
8
9
10
|
data/
data/train/
data/train/red/
data/train/blue/
data/test/
data/test/red/
data/test/blue/
data/validation/
data/validation/red/
data/validation/blue/
|
让我们实际创建这些目录。
我们还可以将一些照片放在目录中。
您可以使用知识共享图像搜索来查找一些具有宽松许可的图像,您可以下载这些图像并将其用于此示例。
我将使用两张图片:
- 丹尼斯·贾维斯 (Dennis Jarvis) 的《红色汽车》。
- 蓝色汽车,比尔·史密斯 (Bill Smith) 着。

丹尼斯·贾维斯 (Dennis Jarvis) 的《红色汽车》

蓝色汽车,比尔·史密斯 (Bill Smith)
将照片下载到您当前的工作目录,并将红色汽车的照片保存为“red_car_01.jpg”,将蓝色汽车的照片保存为“blue_car_01.jpg”。
对于每个训练、测试和验证数据集,我们必须有不同的照片。
为了保持本教程的重点,我们将在三个数据集中的每一个数据集中重复使用相同的图像文件,但假装它们是不同的照片。
将“red_car_01.jpg”文件的副本放在 data/train/red/、data/test/red/ 和 data/validation/red/ 目录中。
现在,将“blue_car_01.jpg”文件的副本放在 data/train/blue/、data/test/blue/ 和 data/validation/blue/ 目录中。
现在,我们有一个非常基本的数据集布局,如下所示(tree 命令的输出):
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
data
├── test
│ ├── blue
│ │ └── blue_car_01.jpg
│ └── red
│ └── red_car_01.jpg
├── train
│ ├── blue
│ │ └── blue_car_01.jpg
│ └── red
│ └── red_car_01.jpg
└── validation
├── blue
│ └── blue_car_01.jpg
└── red
└── red_car_01.jpg
|
下面是目录结构的屏幕截图,取自 macOS 上的 Finder 窗口。
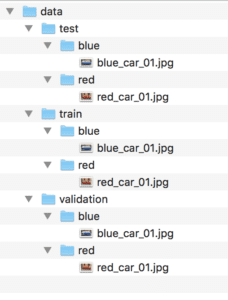
图像数据集目录和文件结构的屏幕截图
现在我们有了基本的目录结构,让我们练习从文件加载图像数据以用于建模。
六、如何逐步加载图像
可以编写代码来手动加载图像数据并返回准备建模的数据。
这将包括遍历数据集的目录结构、加载图像数据以及返回输入(像素数组)和输出(类整数)。
值得庆幸的是,我们不需要编写此代码。相反,我们可以使用 Keras 提供的 ImageDataGenerator 类。
使用此类加载数据的主要好处是,将批量加载单个数据集的图像,这意味着它既可用于加载小型数据集,也可用于加载具有数千或数百万个图像的超大型图像数据集。
在训练和评估深度学习模型时,它不会将所有图像加载到内存中,而是将刚好足够的图像加载到内存中,以供当前甚至接下来的几个小批量使用。我将其称为渐进式加载,因为数据集是从文件中渐进式加载的,只需检索足够的数据即可立即使用。
使用 ImageDataGenerator 类的另一个好处是,它还可以自动缩放图像的像素值,并且可以自动生成图像的增强版本。我们将把这些主题留到另一个教程中讨论,而是专注于如何使用 ImageDataGenerator 类从文件加载图像数据。
使用 ImageDataGenerator 类的模式如下所示:
- 构造和配置 ImageDataGenerator 类的实例。
- 通过调用 flow_from_directory() 函数检索迭代器。
- 在模型的训练或评估中使用迭代器。
让我们仔细看看每个步骤。
ImageDataGenerator 的构造函数包含许多参数,用于指定如何在加载图像数据后对其进行操作,包括像素缩放和数据增强。在此阶段,我们不需要任何这些功能,因此配置 ImageDataGenerator 很容易。
|
1
2
3
|
...
# create a data generator
datagen = ImageDataGenerator()
|
接下来,需要一个迭代器来逐步加载单个数据集的图像。
这需要调用 flow_from_directory() 函数并指定数据集目录,例如训练、测试或验证目录。
该功能还允许您配置与图像加载相关的更多详细信息。值得注意的是“target_size”参数,它允许您将所有图像加载到特定大小,这在建模时通常需要。该函数默认为大小为 (256, 256) 的方形图像。
该函数还允许您通过“class_mode”参数指定分类任务的类型,特别是它是“二进制”还是“分类”的多类分类。
默认的“batch_size”是 32,这意味着在训练时,每批都会返回 32 张从数据集中各个类中随机选择的图像。可能需要更大或更小的批次。在评估模型时,您可能还希望以确定性顺序返回批次,这可以通过将“shuffle”设置为“False”来实现。
还有许多其他选项,我鼓励您查看 API 文档。
我们可以使用相同的 ImageDataGenerator 为单独的数据集目录准备单独的迭代器。如果我们希望将相同的像素缩放应用于多个数据集(例如 trian、test 等),这将非常有用。
|
1
2
3
4
5
6
7
|
...
# load and iterate training dataset
train_it = datagen.flow_from_directory('data/train/', class_mode='binary', batch_size=64)
# load and iterate validation dataset
val_it = datagen.flow_from_directory('data/validation/', class_mode='binary', batch_size=64)
# load and iterate test dataset
test_it = datagen.flow_from_directory('data/test/', class_mode='binary', batch_size=64)
|
准备好迭代器后,我们可以在拟合和评估深度学习模型时使用它们。
例如,可以通过在模型上调用 fit_generator() 函数并传递训练迭代器 (train_it) 来实现使用数据生成器拟合模型。通过“validation_data”参数调用此函数时,可以指定验证迭代器 (val_it)。
必须为训练迭代器指定“steps_per_epoch”参数,以便定义定义单个纪元的图像批次。
例如,如果训练数据集中有 1,000 张图像(跨所有类),并且批处理大小为 64,则steps_per_epoch约为 16 或 1000/64。
同样,如果应用了验证迭代器,则还必须指定“validation_steps”参数,以指示定义一个纪元的验证数据集中的批次数。
|
1
2
3
4
5
|
...
# define model
model = ...
# fit model
model.fit_generator(train_it, steps_per_epoch=16, validation_data=val_it, validation_steps=8)
|
模型拟合后,可以使用 evaluate_generator() 函数在测试数据集上对其进行评估,并传入测试迭代器 (test_it)。“steps”参数定义在停止之前评估模型时要逐步执行的样本批次数。
|
1
2
3
|
...
# evaluate model
loss = model.evaluate_generator(test_it, steps=24)
|
最后,如果你想使用拟合模型对一个非常大的数据集进行预测,你也可以为该数据集创建一个迭代器(例如predict_it),并在模型上调用 predict_generator() 函数。
|
1
2
3
|
...
# make a prediction
yhat = model.predict_generator(predict_it, steps=24)
|
让我们使用上一节中定义的小型数据集来演示如何定义 ImageDataGenerator 实例并准备数据集迭代器。
下面列出了一个完整的示例。
|
1
2
3
4
5
6
7
8
9
10
11
|
# example of progressively loading images from file
from keras.preprocessing.image import ImageDataGenerator
# create generator
datagen = ImageDataGenerator()
# prepare an iterators for each dataset
train_it = datagen.flow_from_directory('data/train/', class_mode='binary')
val_it = datagen.flow_from_directory('data/validation/', class_mode='binary')
test_it = datagen.flow_from_directory('data/test/', class_mode='binary')
# confirm the iterator works
batchX, batchy = train_it.next()
print('Batch shape=%s, min=%.3f, max=%.3f' % (batchX.shape, batchX.min(), batchX.max()))
|
运行该示例首先使用所有默认配置创建 ImageDataGenerator 的实例。
接下来,创建三个迭代器,分别用于训练、验证和测试二进制分类数据集。创建每个迭代器时,我们可以看到调试消息,其中报告了发现和准备的映像和类的数量。
最后,我们测试了用于拟合模型的训练迭代器。检索到第一批图像,我们可以确认该批次包含两个图像,因为只有两个图像可用。我们还可以确认图像被加载并强制到 256 行和 256 列像素的正方形尺寸,并且像素数据没有缩放并保持在 [0, 255] 范围内。
|
1
2
3
4
|
Found 2 images belonging to 2 classes.
Found 2 images belonging to 2 classes.
Found 2 images belonging to 2 classes.
Batch shape=(2, 256, 256, 3), min=0.000, max=255.000
|