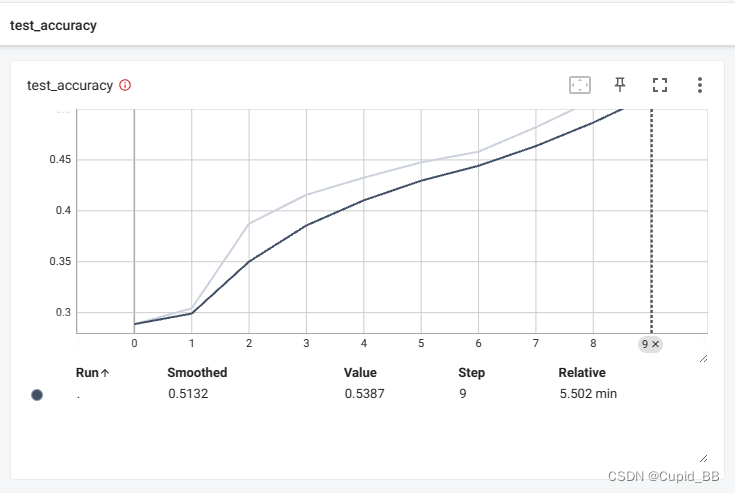
登录MySQL
win+R 打开查询命令
输入 cmd
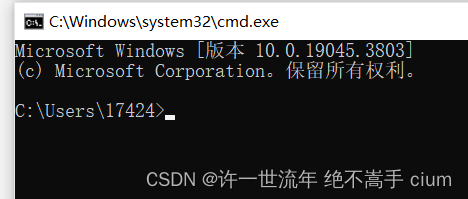
输入net start MySQL 打开mysql
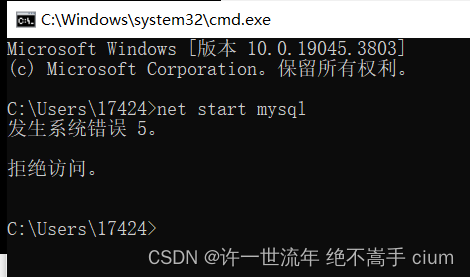
报错:系统错误,拒绝访问 (没权限!)
解决办法:搜索栏查询‘cmd’ 使用管理员身份运行
(或鼠标右键‘开始’,windows powershell(管理员) )
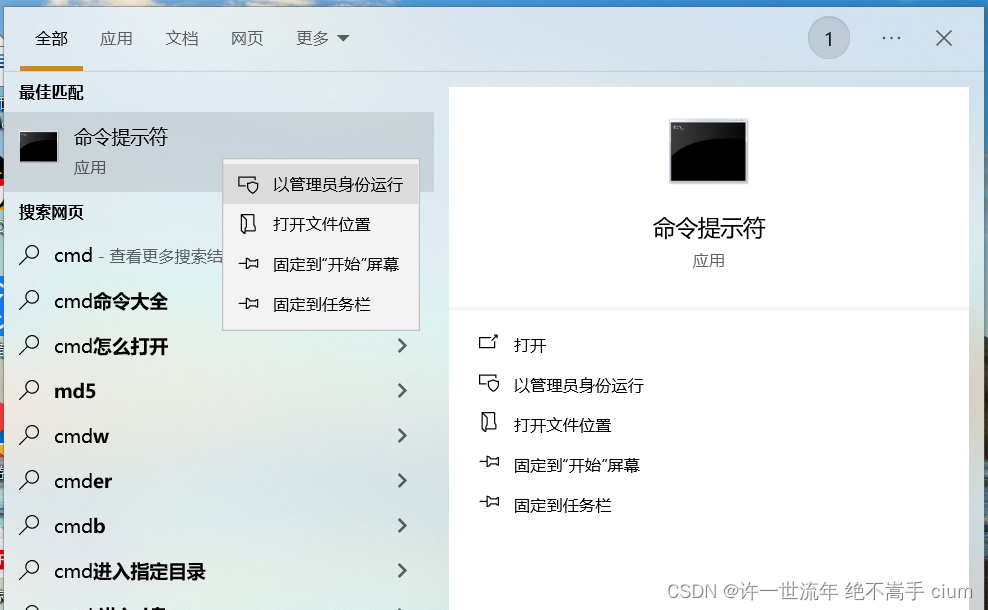
重新打开MySQL
net start mysql
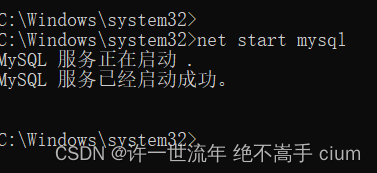
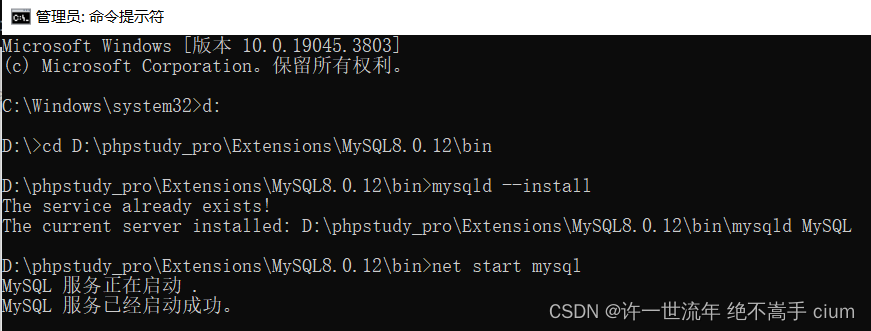
打开MySQL所在地址D:\phpstudy_pro\Extensions\MySQL8.0.12\bin
C:\Windows\system32>d: /*跳转到安装MySQL的d盘*/
D:\>cd D:\phpstudy_pro\Extensions\MySQL8.0.12\bin /*cd 跳转mysql安装目录下bin文件*/
D:\phpstudy_pro\Extensions\MySQL8.0.12\bin>mysql -uroot -p /*输入MySQL账号和密码*/
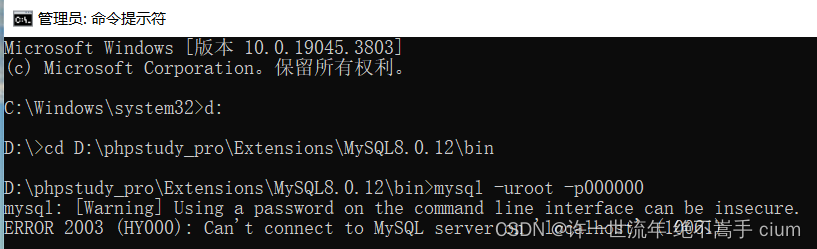
报错 Can’t connect to MySQL server on ‘localhost’ (10061)
解决办法: 将mysql加入到window系统服务中mysqld --install

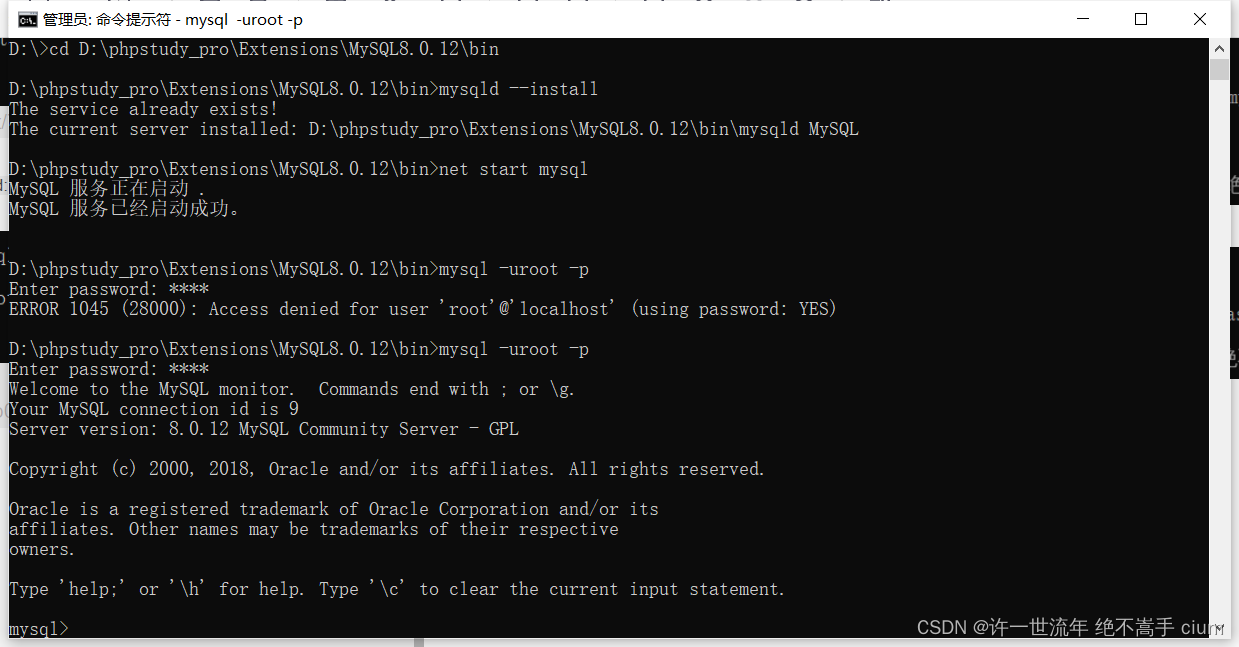
报错: Access denied for user 'root'@'localhost' (using password: YES)
解决办法:这个提示是密码错误。。
如果忘记了密码,先关闭MySQL服务net stop mysql,
后跳过密码验证 mysqld --skip-grant-tables,
mysql 8.0之后的版本mysqld -console --skip-grant-tables --shared-memory
重新尝试密码 成功进入MySQL
MySQL 数据库定义语言 (DDL)
查看MySQL中存在的数据库
mysql> show databases;
注意!MySQL数据库中必须用 “;” 分开,否则MySQL默认语句未写完!

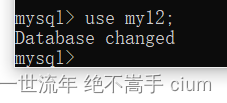
使用数据库my12
mysql> use my12;
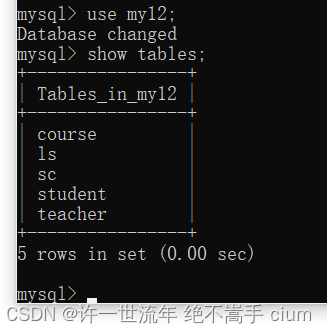
查看my12数据库中所有表 show tables
mysql> show tables;
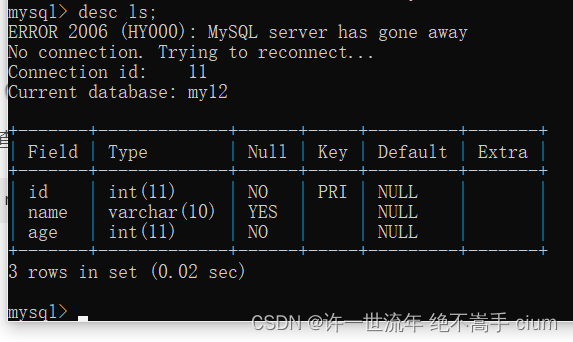
查看表设计结构 desc/show create table xx
mysql> desc ls;
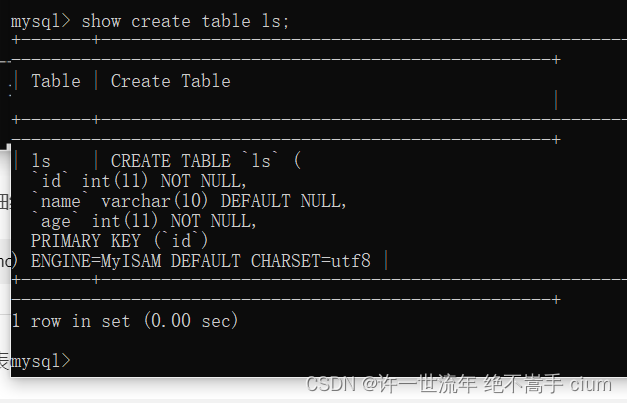
查看表详细结构
mysql> show create table ls;
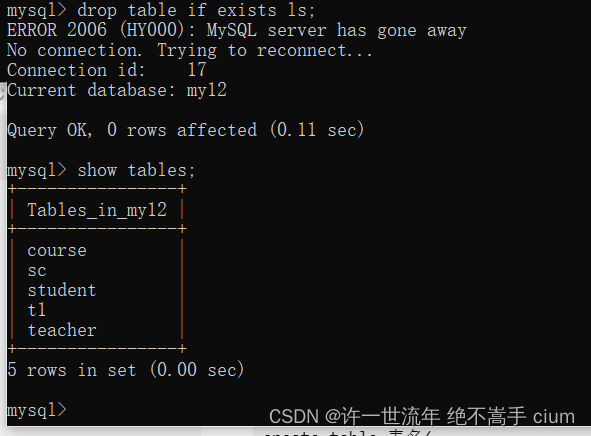
删除表 drop table if exists xx
mysql> drop table if exists ls;
创建一个表create table xx()
create table 表名(
列名 数据类型 [列级约束条件],
列名 数据类型 [列级约束条件],
...
列名 数据类型 [列级约束条件]);
mysql> create table t1(
-> id int primary key not null auto_increment,
-> name varchar(10) not null,
-> sex enum('男','女') not null default '男');
报错原因:primary key 后面要加 not null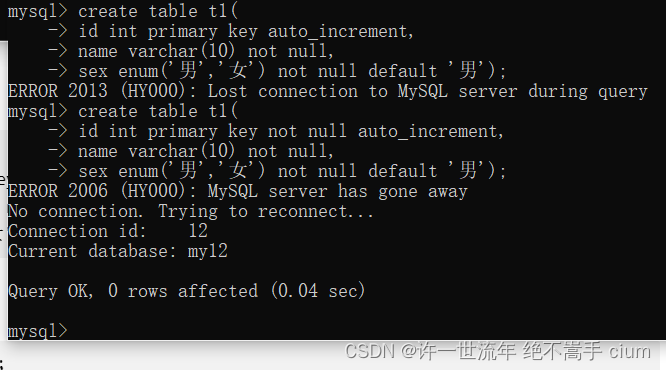
查看表结构 desc
mysql> desc t1;
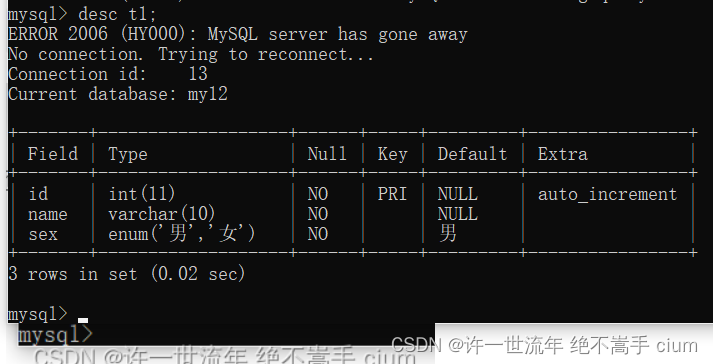
修改表信息 alter 增(add)删(drop)改(change)
alter table 表名
[add column 新列名 数据类型[列级约束条件]],
[drop column 列名[restrict|cascade]],
[change column 原列名 新列名 数据类型[列级约束条件]];
修改表名
修改表名称为t11
mysql> alter table t1 rename to t11;
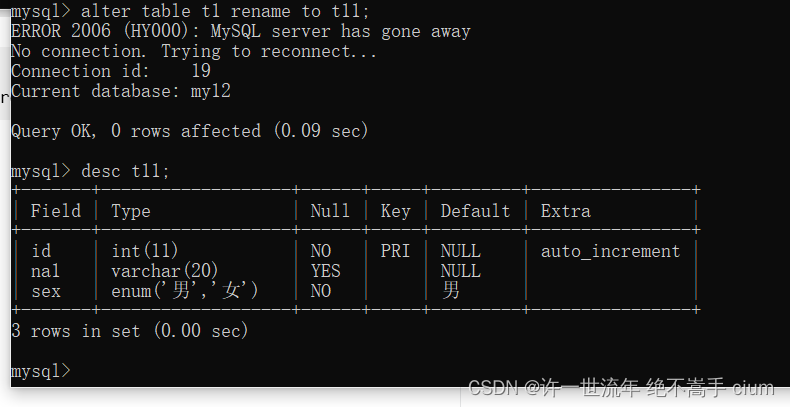
新增列
新增一个列‘age’, int型,非空,在‘sex’列之后
mysql> alter table t1
-> add column `age` int not null after `sex`;
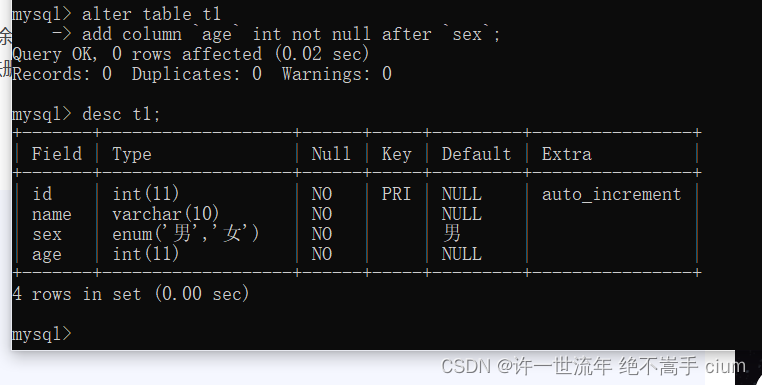
删除列
删除age列
mysql> alter table t1
-> drop column age;
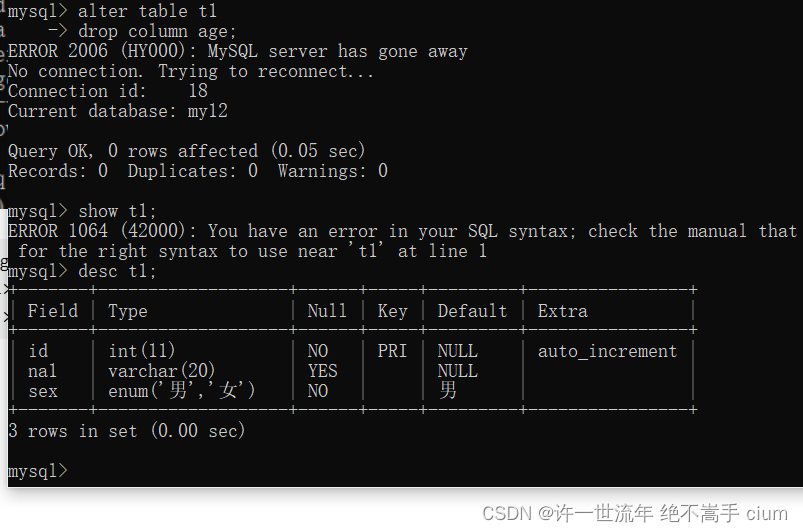
修改列名称
修改‘name’列为‘na1’,varchar(10)为varchar(20)
mysql> alter table t1
-> change column `name` `na1` varchar(20);
注意:修改列名的同时需要将列类型给写上,否则报错
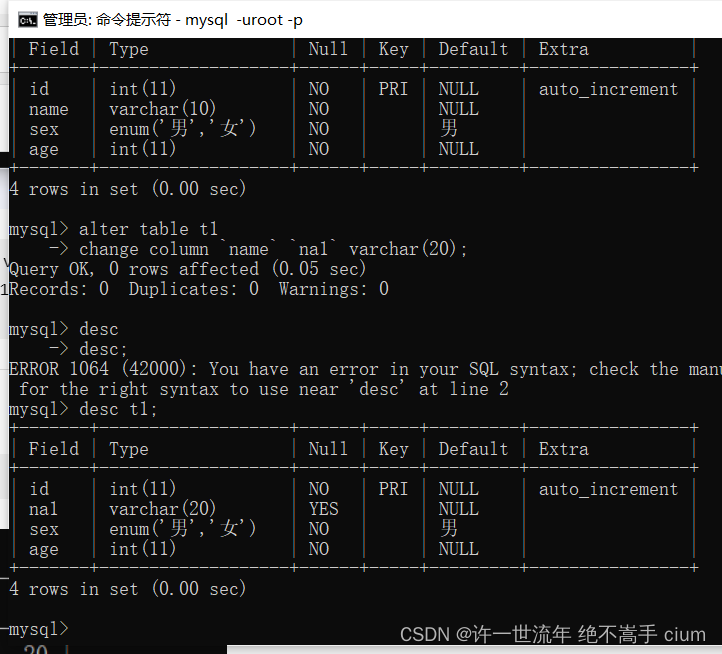
修改列 数据类型
mysql> alter table t11 modify na1 int;
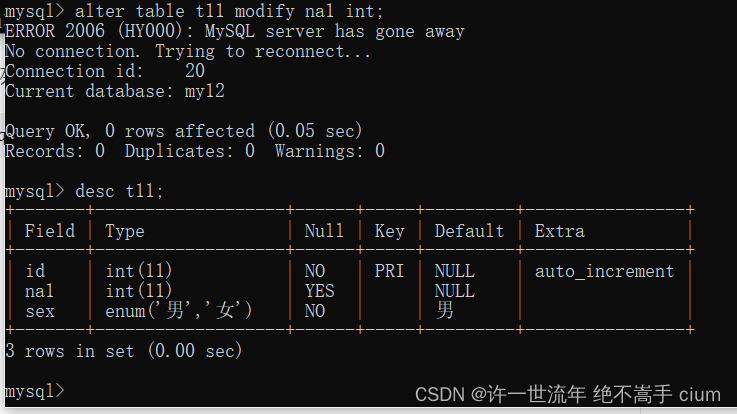
修改列排序
ALTER TABLE <表名> MODIFY <字段名> <字段数据类型> [FIRST/AFTER] <如果使用AFTER,排列在哪个字段后面,就写哪个字段的名称,FIRST就不需要了>
修改第一列 first
修改name为第一列
mysql> alter table t11 modify name varchar(10) first;
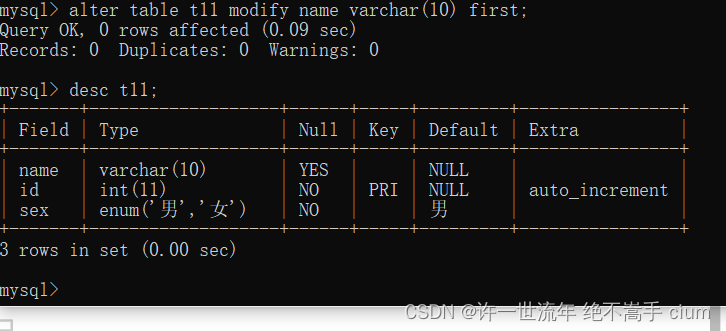
将xx放在xx后面 after
将name放在sex后面
mysql> alter table t11 modify name varchar(10) after sex;
修改存储引擎
ALTER TABLE <表名> ENGINE=<更改后的引擎> ;
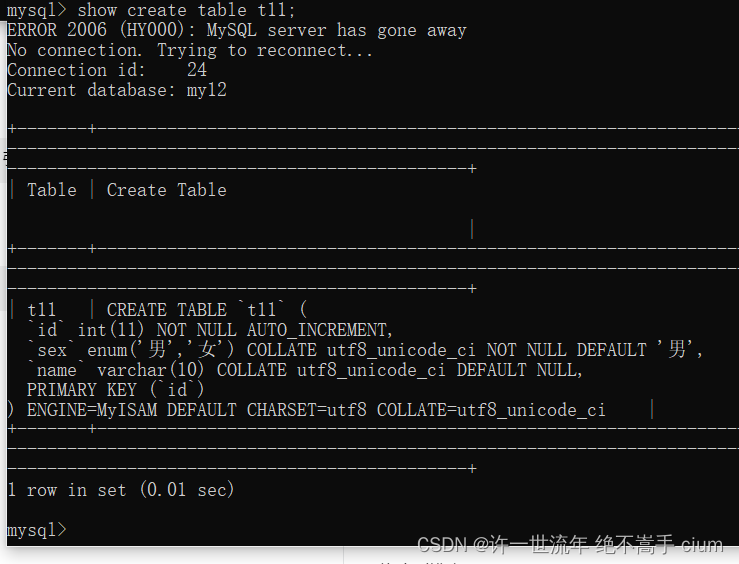
首先,查看现有表的存储引擎
mysql> show create table t11;
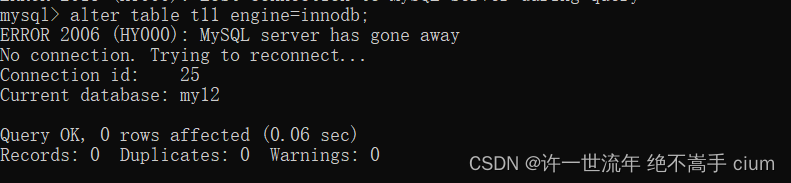
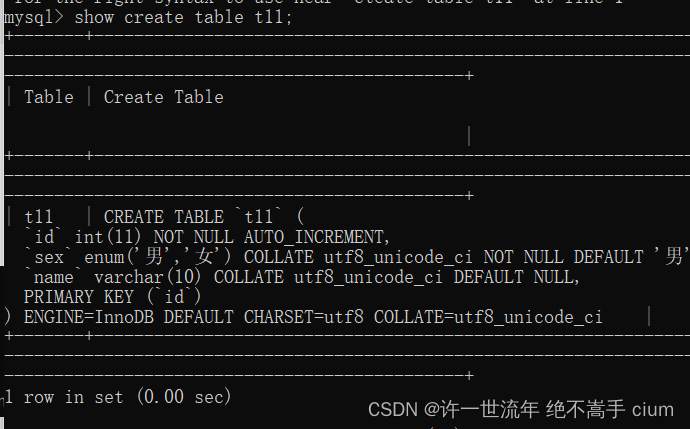
修改表引擎为 innodb
mysql> alter table t11 engine=innodb;
数据库操纵语言 (DML)
插入数据 inster
①单行+全列插入
insert into 表名 values (xx, xx, xx, xx);
insert into 表名 values (xx, xx, xx, xx);
②多行+指定列插入
insert into 表名 (id, sn, name) values
(xx, xx, ‘xx’),
(xx, xx, ‘xx’),
(xx, xx, ‘xx’);
删除数据 delete
DELETE FROM 表名 WHERE 条件;
-- 删除孙悟空的信息
delete from student where name = ‘孙悟空’;
-- 仅删除表的全部数据 for-each
delete from student;
更新数据 update
UPDATE 表名 SET 列名=值,... WHERE 条件;
-- 修改曹孟德的数学成绩为80分,语文成绩为90分
update student set math = 80, chinese = 90 where name = ‘曹孟德’;
-- 将总分倒数三名同学的数学成绩加上20分 (支持limit,不支持offset)
update student set math = math + 20 order by Chinese + math + english limit 3; ????
-- 将所有同学的语文成绩更新为2倍
update student set chinese = chinese * 2;
数据库查询语言(DQL)
单表查询
select 查询列名
from 表名
where 条件
group by 分组条件
order by desc降序,asc升序 (默认值)
having 筛选条件(优先级最低)
limit 分页数量
select
-- 全表查询,不建议使用
select * from student;
-- 指定列查询
select id, name, english from student;
-- 结果集为表达式
select id, name, (chinese + math + english) / 3 from student;
-- 自定义结果集的列名
select id, name, chinese + math + english 总分 from student;
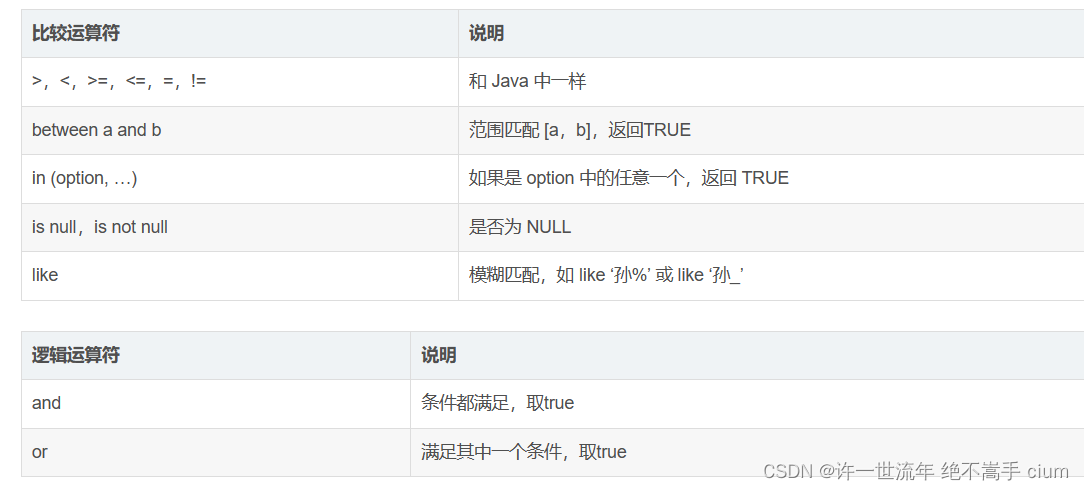
where
-- 查询english成绩高于60分的学生
select * from student where english > 60;
-- and与or
select * from student where english > 60 and math > 60;
select * from student where english > 90 or math > 90;
-- 范围查询
select * from student where english between 80 and 100;
-- in查询
select * from student where math in (80, 85, 90, 95, 100);
-- 模糊查询 like
-- %匹配任意多个(包括0个)字符
select name from student where name like ‘孙%’;
select name from student where name like ‘%孙’;
select name from student where name like ‘%孙%’;
-- _严格匹配一个任意字符
select name from student where name like ‘孙_’;
-- NULL查询
select * from student where qq_mail is not null;
select * from student where qq_mail is null;
去重 distinct
-- 可以列出所有不重复的math成绩集合
select distinct math from student;
-- 此时就没有去重功能了,因为没有id和math同时重复的学生
select distinct id, math from student;
分组group by
GROUP BY <字段名>[,<字段名>,<字段名>]
group by 关键字可以根据一个或多个字段对查询结果进行分组
group by 一般都会结合Mysql聚合函数来使用
如果需要指定条件来过滤分组后的结果集,需要结合 having 关键字;
where不能与聚合函数联合使用 并且 where 是在 group by 之前执行的
再次筛选 hiving
group by 后面的having是对分组后的字段进行再次过滤筛查,
此时行已经被分组。
(大部分都)使用了聚合函数。
满足HAVING 子句中条件的分组将被显示。
HAVING 不能单独使用,必须要跟 GROUP BY 一起使用
HAVING子句可包含一个或多个用AND和OR连接的谓词
WHERE 和 HAVING 也不是互相排斥的,我们可以在一个查询里面同时使用 WHERE 和 HAVING。包含分组 统计函数的条件用 HAVING,普通条件用 WHERE。这样,我们就既利用了 WHERE 条件的高效快速,又发挥了 HAVING 可以使用包含分组统计函数的查询条件的优点

窗口函数 partition by
窗口函数在使用时需要定义一个窗口(分组),然后对每一行应用窗口函数,正在计算的这行叫做"当前行"(current row)。
窗口函数与group by的区别:
在使用聚合函数的时候我们通过 group by 关键字来定义如何分组,
而窗口函数是通过 over 关键字和 partition by 关键字来定义分组
(这里的 partition by 是分组的意思,和分区表没有任何关系)
聚合函数(例如:sum/avg/min/max)会针对每个分组(窗口)聚合出一个结果(每一组返回一个结果)。
窗口函数会对每一条数据进行计算,并不会使返回的数据变少(每行在最后增添一列返回一个结果)
窗口函数会逐行计算,其重点是计算当前行与窗口内其他成员之间的关系,例如:组内排序,累积分布
聚合函数作为窗口函数使用
#查询每个人的总成绩
SELECT sno 学生姓名,kc1,kc2,
SUM(kc1+kc2) 总成绩
FROM score
GROUP BY sno,kc1,kc2
SELECT sno 学生姓名,kc1,kc2,
SUM(kc1+kc2) OVER(PARTITION BY sno) 总成绩
FROM score
#这种情况下的窗口函数,和分组group by差不多,只不过一个是查询的时候分组,一个是from 表之后分组
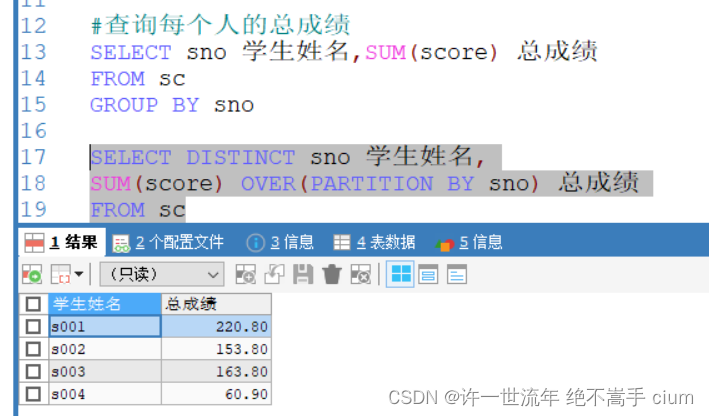
SELECT sno 学生姓名,SUM(score) 总成绩
FROM sc
GROUP BY sno
SELECT DISTINCT sno 学生姓名,
SUM(score) OVER(PARTITION BY sno) 总成绩
FROM sc
命名窗口 window wind_name as ()
当一个窗口被多次引用的时候,在每个over后面都写一遍定义就显得有些繁琐了,此场景可以通过命名窗口优化:一次定义,多次引用。
命名窗口的定义是通过 window wind_name as () 来进行定义的,括号内的部分就是原over子句后的窗口定义,在用over关键字调用窗口时,直接引用窗口名wind_name即可:
select x1,
sum(x2) over w -- 通过名称 w 引用窗口 (为了好看,也可以起个别名)
from 表名
window w as (partition by x1); -- 命名窗口定义
重复出现的分类就单独拎出来,做一个窗口函数去定义,在上面进行调用
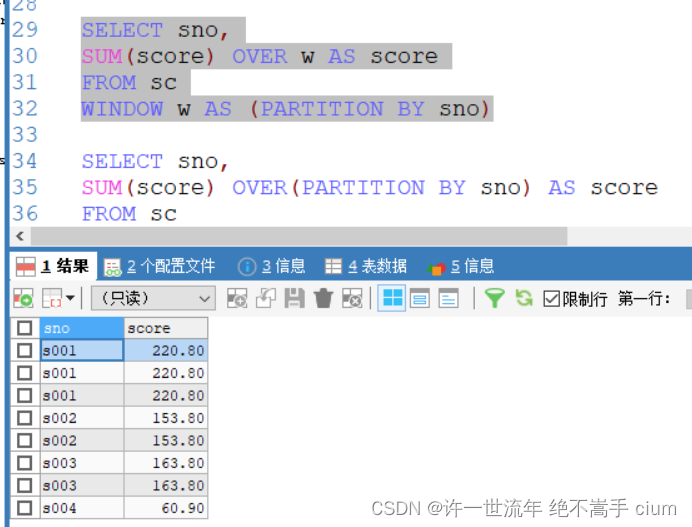
SELECT sno,
SUM(score) OVER(PARTITION BY sno) AS score
FROM sc
将 PARTITION BY sno 单独拎出来命名为 w ,在上面over 后面进行调用
SELECT sno,
SUM(score) OVER w AS score
FROM sc
WINDOW w AS (PARTITION BY sno)
专用窗口函数 row_number()、rank()、dense_rank()
专用窗口函数在使用时必须搭配 over 关键字
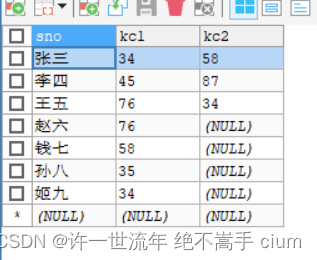
建表
CREATE TABLE score(
sno VARCHAR(10) NOT NULL ,
kc1 VARCHAR(10) NOT NULL,
kc2 VARCHAR(10) NOT NULL
);
添数据
INSERT INTO score
(sno, kc1, kc2) VALUES
("张三", 34, 58),
("李四", 45, 87),
("王五", 76, 34);
插入数据
INSERT INTO score
(sno,kc1) VALUES
('赵六',76),('钱七',58),('孙八',35),('姬九',34);
报错:kc2 设置非空,却没有插入数据
解决办法:修改kc2属性,取消非空
ALTER TABLE score
CHANGE COLUMN kc2 kc2 VARCHAR(10);
row_number() over window
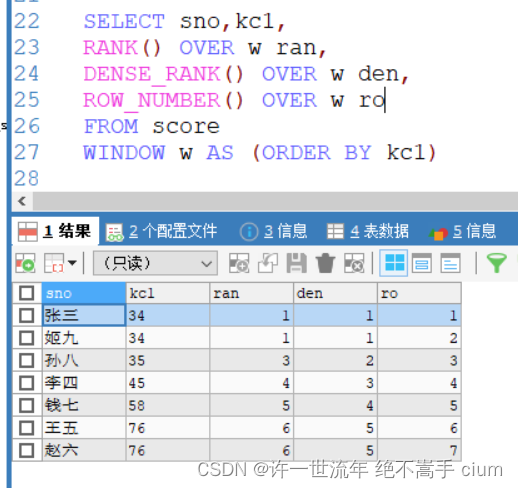
ROW_NUMBER()函数,对同一个字段排序,排名是连续的,即使出现相同,也不会出现并列排名
rank()
RANK()函数,对同一个字段排序,出现相同时,会并列排名,并且会出现排名间隙
dense_rank()
DENSE_RANK()函数,对同一个字段排序,出现相同时,会出现并列排名
只按照一个关键词排序
#根据kc1进行降序,不需要分区,所以不需要partition by
SELECT sno,kc1,
RANK() OVER(ORDER BY kc1) ran,
DENSE_RANK() OVER(ORDER BY kc1) den,
ROW_NUMBER() OVER(ORDER BY kc1) ro
FROM score
调用命令窗口:
SELECT sno,kc1,
RANK() OVER w ran,
DENSE_RANK() OVER w den,
ROW_NUMBER() OVER w ro
FROM score
WINDOW w AS (ORDER BY kc1)
成绩中存在各科,多种类排序
#整体排序
SELECT sc.*,
RANK() OVER(ORDER BY score) ran
FROM sc
#各科排序
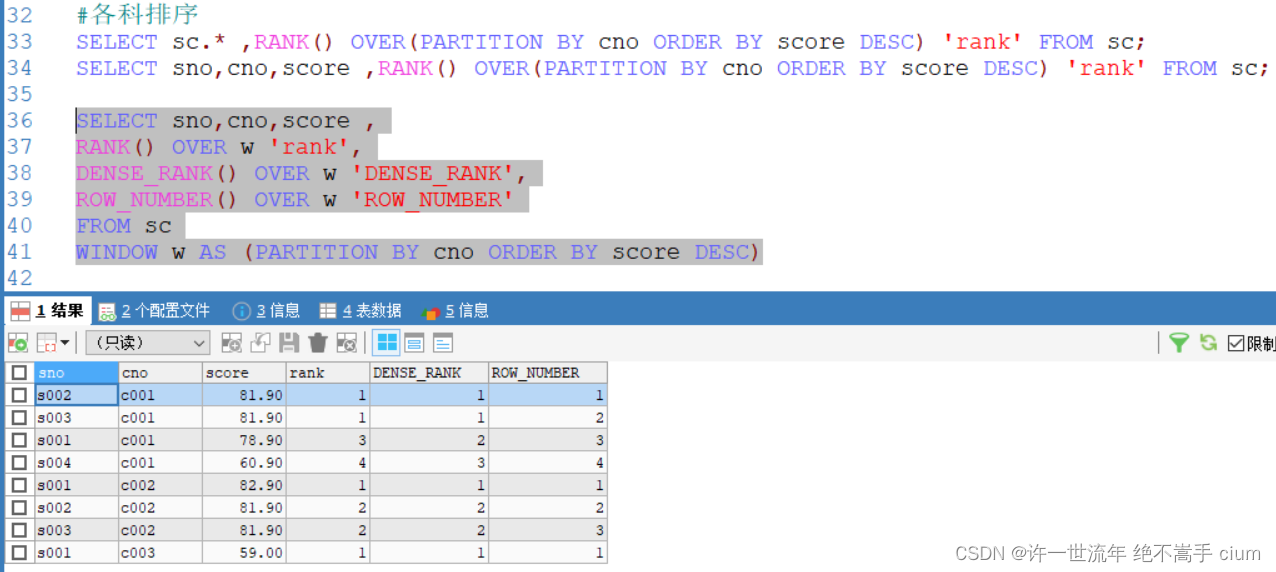
SELECT sc.* ,RANK() OVER(PARTITION BY cno ORDER BY score DESC) 'rank' FROM sc;
SELECT sno,cno,score ,RANK() OVER(PARTITION BY cno ORDER BY score DESC) 'rank' FROM sc;
SELECT sno,cno,score ,
RANK() OVER w 'rank',
DENSE_RANK() OVER w 'DENSE_RANK',
ROW_NUMBER() OVER w 'ROW_NUMBER'
FROM sc
WINDOW w AS (PARTITION BY cno ORDER BY score DESC)
排序 order by
-- 先优先 math 升序;若 math 相等,则按 Chinese 降序;若都相等,按 id 升序
select * from student order by math asc, chinese desc, id;
-- 使用表达式 + 别名排序
select name, math + chinese + english 总分 from student order by 总分;
分页 limit
-- 从下标0开始,筛选5条结果
select * from student limit 5;
-- 从下标2开始,筛选5条结果
select * from student limit 2, 5;
-- 筛选5条结果,从下标2开始。这种写法意思更明确
select * from student limit 5 offset 2;
-- 综合运用
-- 查询数学成绩高于80分,且排名前三的学生
select name, math from student where math > 80 order by math desc limit 3;
聚合函数
count(*):统计所有的行数
count(列名):统计某列的值总和
sum(列名):求一列的和
avg(列名):求一列的平均值
max(列名):求一列的最大值
min(列名):求一列的最小值
聚合函数和group by 的使用
SELECT sum(*) FROM 表名 WHERE 条件 GROUP BY 列名;
-- 查询每种角色的最高工资、最低工资、平均工资
select role, max(salary), min(salary), avg(salary) from emp group by role;
-- 统计每种角色薪资高于500的人数
select role, count(*) from emp where salary > 500 group by role;
-- 多聚合,在不同列的组合下进行聚合查询
select company, role, count(*) from emp2 group by company, role;
聚合函数和group by、having使用
-- having关键字用于聚合之后进行过滤操作
select role, avg(salary) from emp group by role having avg(salary) > 300;
注意顺序:where > group by > having
多表查询
#方式1:
SELECT ...,....,...
FROM ...,...,....
WHERE 多表的连接条件 AND 不包含组函数的过滤条件
GROUP BY ...,...
HAVING 包含组函数的过滤条件
ORDER BY ... ASC/DESC
LIMIT ...,...
#方式2:
SELECT ...,....,...
FROM ... JOIN ...
ON 多表的连接条件
JOIN ...
ON ...
WHERE 不包含组函数的过滤条件
AND/OR 不包含组函数的过滤条件
GROUP BY ...,...
HAVING 包含组函数的过滤条件
ORDER BY ... ASC/DESC
LIMIT ...,...
#其中:
#(1)from:从哪些表中筛选
#(2)on:关联多表查询时,去除笛卡尔积
#(3)where:从表中筛选的条件
#(4)group by:分组依据
#(5)having:在统计结果中再次筛选
#(6)order by:排序
#(7)limit:分页
多表连接的分类
可以根据3个角度进行分类:
角度1:是否使用"="符号
等值接连:where条件中,表字段与表字段直接使用等于符号(“=”)进行判断
非等值连接:where条件中,表字段与表字段使用非"="符号,如:<=(小于等于)、>=(大于等于)、between and等等。
角度2:连接表的数量是否大于1
自连接:一张表直接的关联查询,自己表连接自己进行查询,如菜单表查子级
非自连接:多表关联查询
角度3:多表关联时,是否只查询有关联的数据
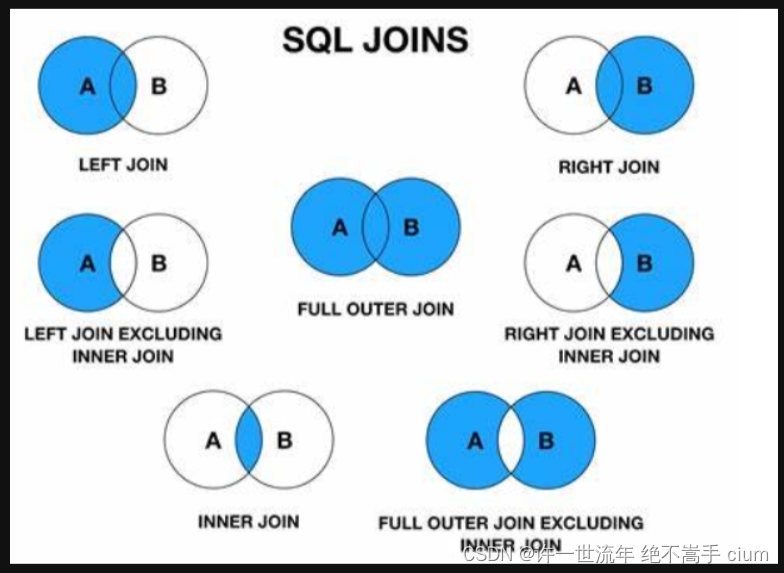
内连接:合并具有同一列的两个以上的表的行,结果集中不包含一个表与另一个表不匹配的行
外连接:合并具有同一列的两个以上的表的行,结果集中包含一个表与另一个表匹配的行之外,还包含了左表 或 右表不匹配的行
内连接
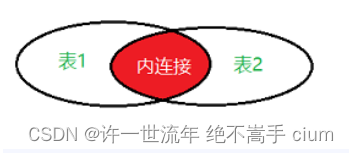
只显示两者交叉的对方,其他的完全不包含
select 字段 from 表1 (inner) join 表2 on 连接条件 where 其他条件;
select 字段 from 表1,表2 where 表1.xx=表2.xx;
-- inner 可以省略
select * from users join articles on uid = author_id where users.name = '小红';
-- 查询作者对应的书籍
select name, title from users inner join articles on users.uid = articles.author_id;
左连接
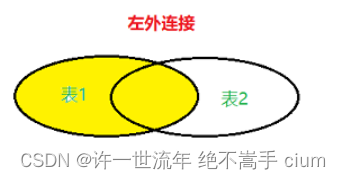
左外连接(left outer join,可缩写为left join):两个表连接过程中,除了返回满足条件的行以外,还会返回左表中不满足条件的行,这种连接称为左连接
select 字段名 from 表名1 left join 表名2 on 连接条件;
select
t1.id -- 学生ID
,t1.name -- 学生姓名
,t1.age -- 学生年龄
,t2.name -- 班级名称
from student t1
left join classinfo t2 --注意:left join是缩写,也可以写为:left outer join
on t1.classid=t2.classid
右连接
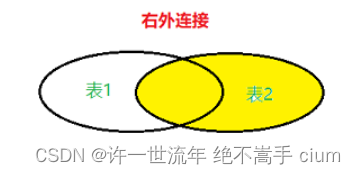
右外连接(right outer join,可缩写为right join):两个表连接过程中,除了返回满足条件的行以外,还会返回右表中不满足条件的行,这种连接称为右连接
select 字段名 from 表名1 right join 表名2 on 连接条件;
select
t2.id -- 学生ID
,t2.name -- 学生姓名
,t2.age -- 学生年龄
,t1.name -- 班级名称
from classinfo t1
right join student t2
on t1.classid=t2.classid
全连接
全连接(full outer join,可缩写为full join):又称为"满外连接",两个表连接过程中,返回两表直接的所有数据,这种连接称为全连接
MySQL不支持全连接,但是Oracle支持
SQL99全连接写法(Oracle):
关键字:full join ... on ... 或者 full outer join ... on ...
MySQL实现全连接,需要使用关键字"union"或者"union all"
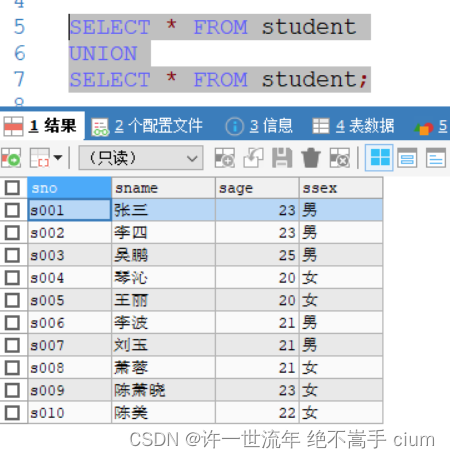
union:联合、合并的意思
union:对两个查询的结果集,进行合并操作,会对重复的数据进行去重,同时进行默认规则(主键升序)的排序(因此效率比较低)。
union all:对两个查询的结果集,进行合并操作,不对数据进行去重,也不进行排序,直接把两个结果进行合并(效率高)。
union 进行去重
union all 不去重
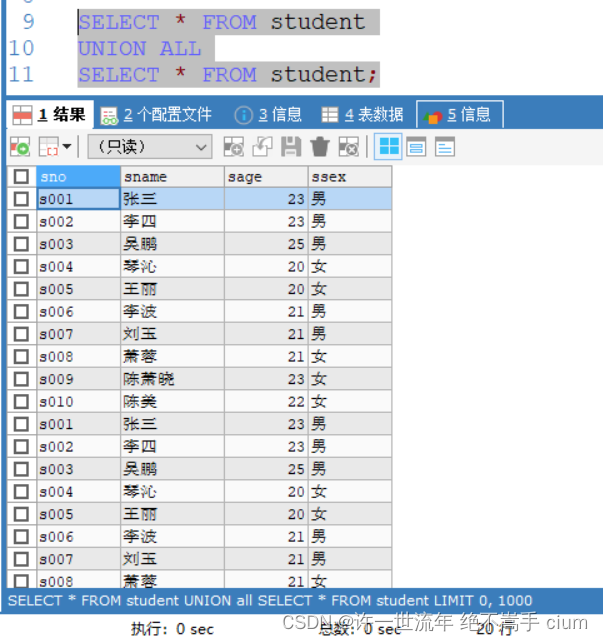
注: union和union all使用时,select下的字段数量必须一致,否则会报错
自连接
自连接是指将自身的某一列看成一个表,在同一张表连接自身另一列进行查询
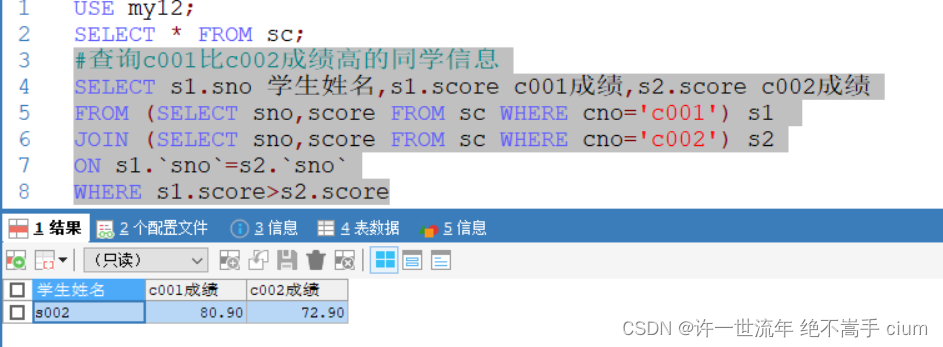
#查询c001比c002成绩高的同学信息
SELECT s1.sno 学生姓名,s1.score c001成绩,s2.score c002成绩
FROM (SELECT sno,score FROM sc WHERE cno='c001') s1
JOIN (SELECT sno,score FROM sc WHERE cno='c002') s2
ON s1.`sno`=s2.`sno`
WHERE s1.score>s2.score
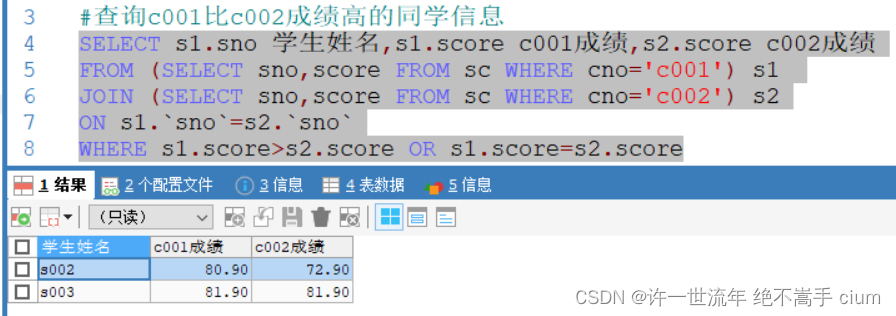
感觉也是把两张表连起来(普通多表查询与内连接区别)
-- 区别 : on是先筛选后关联,优先级高,所以先做hash筛选匹配,再两张表合并
-- where 是先关联合并表后 筛选匹配(量大),
-- on指匹配到一条需要的记录后就结束,其他的不匹配,然后合并表,
-- 而where的会一直匹配直到结束,再合并表
-- on 匹配到相同的数据 -> join (合并) -> select查询
-- 合并biao1,biao2 , -->where 对合并的所以信息筛选 -->select 查询
-- on 效率高 先hash,后合并,效率 0 logN
-- where 效率低: 多个from笛卡尔集 合并 再筛选 0(n^2)
笛卡尔积
数学上,有两个集合A={a,b},B={1,2,3},则两个集合的笛卡尔积={{a,1}, {a,2}, {a,3}, {b,1}, {b,2}, {b,3}} 列出所有情况,一共是2*3=6条记录
在数据库中,笛卡尔积是多表查询没有连接条件时返回的表结果
mysql> select *from 表1,表2;
实际开发中应该避免全笛卡尔积 ----在 where 加入有效的连接条件【等值连接】
1.指定连接条件 (等于、大于、小于)
2.指定查询条件 (少用select *)
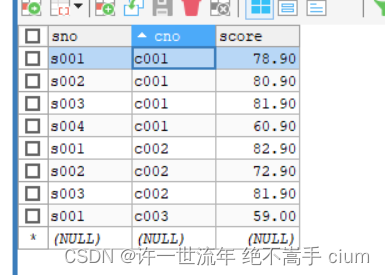
行转列
行转列,值将一行内的数据‘炸裂’成各个行(case 查询词句 when ‘列名’ then 值 else 返回值 end)
将需要拆分的那一列,通过group by函数查找出总类别,放置到第一列;
通过 case … when … then … else … end 函数查找出对应的(科目)列名
原数据
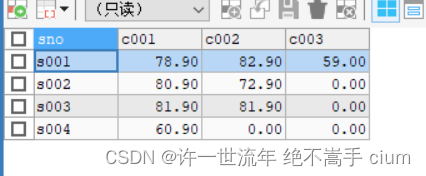
#行转列
SELECT sno,
MAX(CASE cno WHEN 'c001' THEN score ELSE 0 END) AS 'c001',
MAX(CASE cno WHEN 'c002' THEN score ELSE 0 END) AS 'c002',
MAX(CASE cno WHEN 'c003' THEN score ELSE 0 END) AS 'c003'
FROM sc
GROUP BY sno
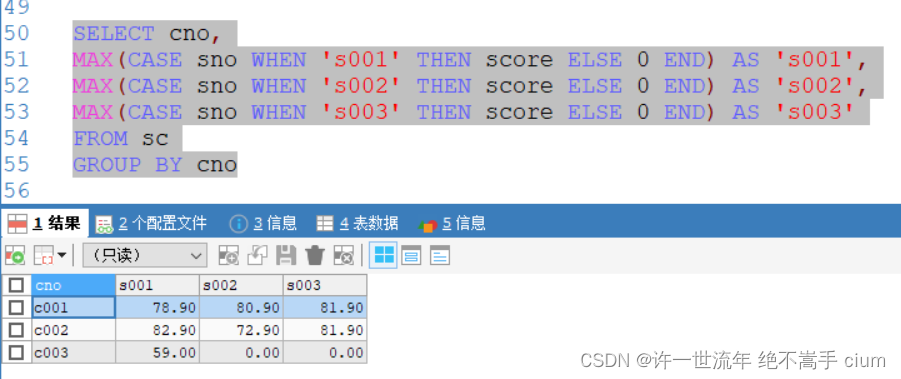
SELECT cno,
MAX(CASE sno WHEN 's001' THEN score ELSE 0 END) AS 's001',
MAX(CASE sno WHEN 's002' THEN score ELSE 0 END) AS 's002',
MAX(CASE sno WHEN 's003' THEN score ELSE 0 END) AS 's003'
FROM sc
GROUP BY cno
查询的时候用case … when … then … else … end选择需要进行转行的字段以及字段结果,
即当Subject是xx的时候,选择Subject对应的Score作为Subject的成绩,
这里需要注意case when then的结果要用max函数包裹,不然结果也会变成行,但是每行只有一科的成绩,用max包裹就是选择最大成绩,把多行合并成一行完成行转列。
问题???? 如果只知道课程编号的情况下,如何把行炸裂成 课程名称?
这种情况下,一定是要‘起别名’的,但是,如果表中本没有课程名称,只有课程编号,要怎么去炸裂成课程名称?
难道只能查询两次,看着第一次的查询结果重新 起别名 吗????
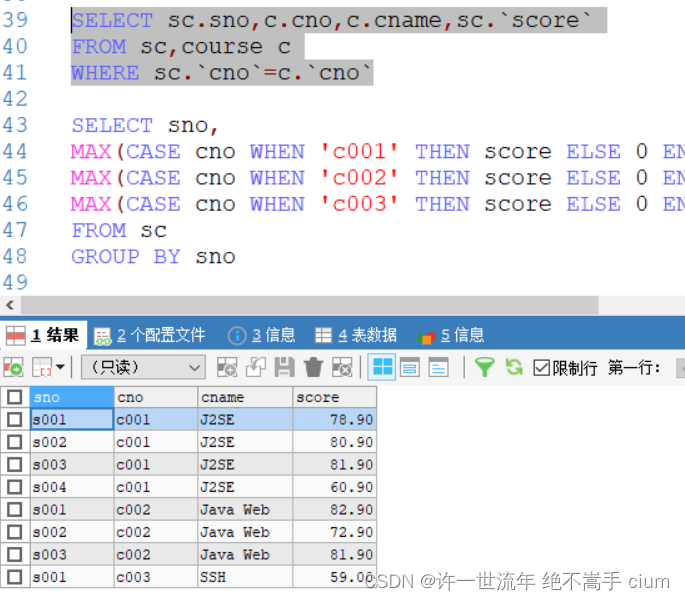
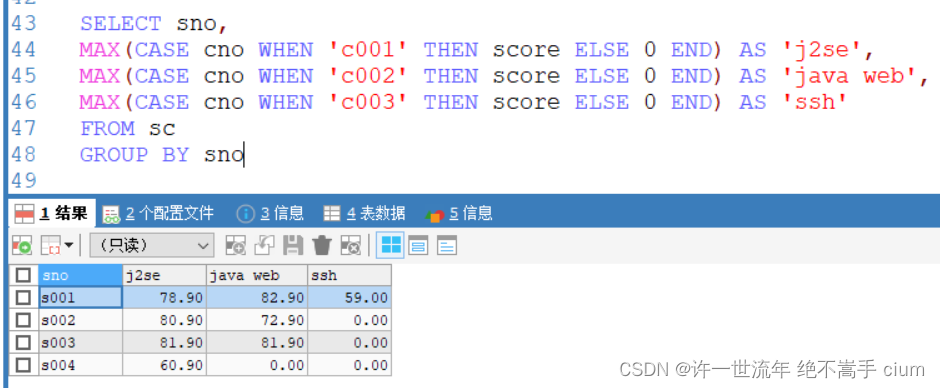
SELECT sno,
MAX(CASE cno WHEN 'c001' THEN score ELSE 0 END) AS 'j2se',
MAX(CASE cno WHEN 'c002' THEN score ELSE 0 END) AS 'java web',
MAX(CASE cno WHEN 'c003' THEN score ELSE 0 END) AS 'ssh'
FROM sc
GROUP BY sno
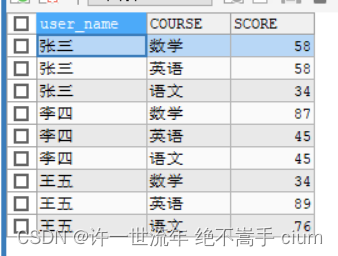
列转行
将想要的列名,通过select 查询出来,通过union全连接拼接到下方
目前是学生-课程1成绩-课程2成绩 想变成 学生-课程-成绩
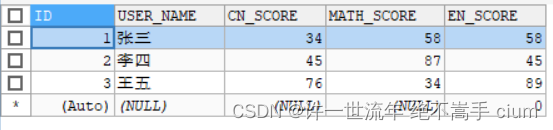
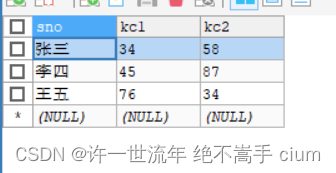
建表
CREATE TABLE score(
sno VARCHAR(10) NOT NULL ,
kc1 VARCHAR(10) NOT NULL,
kc2 VARCHAR(10) NOT NULL
);
添数据
INSERT INTO score
(sno, kc1, kc2) VALUES
("张三", 34, 58),
("李四", 45, 87),
("王五", 76, 34);
目前的表内容
SELECT sno,kc1 course,kc1 score
FROM score
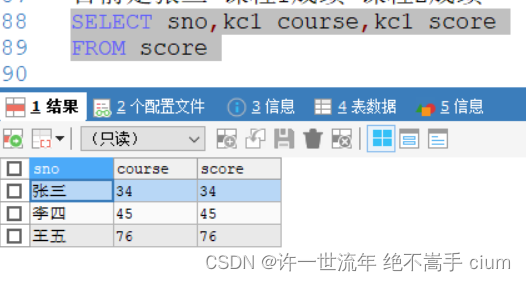
出现错误,只修改了‘列名’,里面的数据还是传进来了,但并不需要他传参
解决办法: 加引号,加引号之后,只会传当前字符段,不在传参
SELECT sno,'kc1' course,kc1 score
FROM score
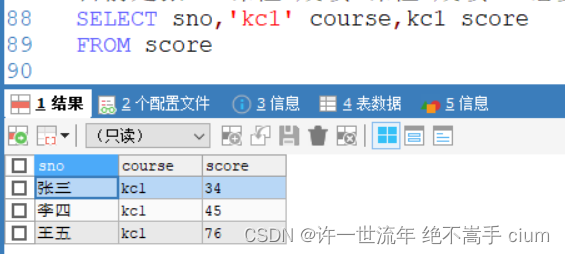
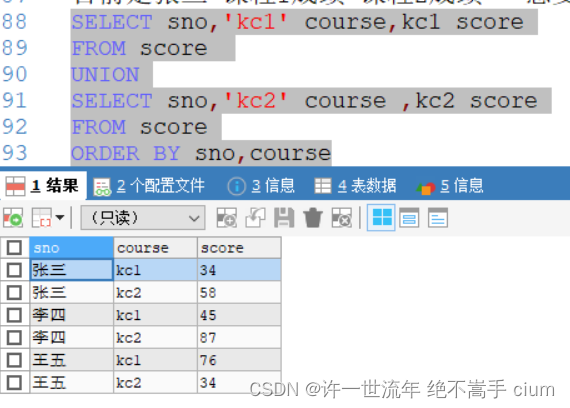
将两个科目的内容拼一下
SELECT sno,'kc1' course,kc1 score
FROM score
UNION
SELECT sno,'kc2' course ,kc2 score
FROM score
ORDER BY sno,course