目录
一. 项目概述与贡献
二. 方法详解
三. 应用总览
四. 个性化视频生成
五. 实时卷积合成
六. 更多结果
七. 论文
八. 个人思考
AI生成高分辨率视频一直是一个挑战。
今天讲解一篇潜在扩散模型(LDM)用于高分辨率、时间一致且多样化的视频生成的工作——来自英伟达的《Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models》。
一. 项目概述与贡献
回顾LDM的优势:
潜在扩散模型 (LDM) 可实现高质量图像合成,同时通过在压缩的低维潜在空间中训练扩散模型来避免过多的计算需求。
本文将 LDM 范式应用于高分辨率视频生成,这是一项特别资源密集型的任务。具体步骤如下:
1. 首先仅在图像上预训练 LDM;
2. 然后,通过向潜在空间扩散模型引入时间维度并对编码图像序列(即视频)进行微调,将图像生成器变成视频生成器。类似地,我们在时间上对齐扩散模型上采样器,将它们转变为时间一致的视频超分辨率模型。
具体贡献:
1. 提出了一种有效的方法来训练基于LDM的高分辨率、长期一致的视频生成模型。关键思路是利用预先训练的图像DM,并通过插入学习以时间一致的方式对齐图像的时间层将它们转换为视频生成器。
2. 进一步对文献中普遍存在的超分辨率 DM 进行了时间微调。
3. 将公开可用的稳定扩散文本到图像LDM转换为强大且富有表现力的文本到视频LDM。
4.具备可迁移性。学习到的时间层可以与不同的图像模型权重(例如,DreamBooth)相结合。

上面动图是本文中视频潜在扩散模型(视频 LDM)中的时间视频微调动画。将预先训练的图像扩散模型转变为时间一致的视频生成器。最初,模型合成的同一批次的不同样本是独立的。经过时间视频微调后,样本在时间上对齐并形成连贯的视频。对于一维分布的扩散模型,微调前后的随机生成过程可视化。 为了清楚起见,该图对应于像素空间中的对齐。在实践中,我们在LDM的潜在空间中进行对齐,并在应用LDM的解码器后获得视频。
二. 方法详解
-
本文提出了用于高效计算的高分辨率视频生成的视频潜在扩散模型(Video LDMs)。
-
为了缓解高分辨率视频合成对计算和内存的密集需求,利用 LDM 范例并将其扩展到视频生成。
-
本文的视频 LDM 将视频映射到压缩潜空间,并建立与视频帧相对应的潜变量序列模型(见上图动画)。
-
从图像 LDM 中初始化模型,并在 LDM 的去噪神经网络中插入时间层,对编码视频帧序列进行时间建模。

-
时间层基于时间注意力和三维卷积。
-
本文还对模型的解码器进行了微调,以生成视频(见下图)。
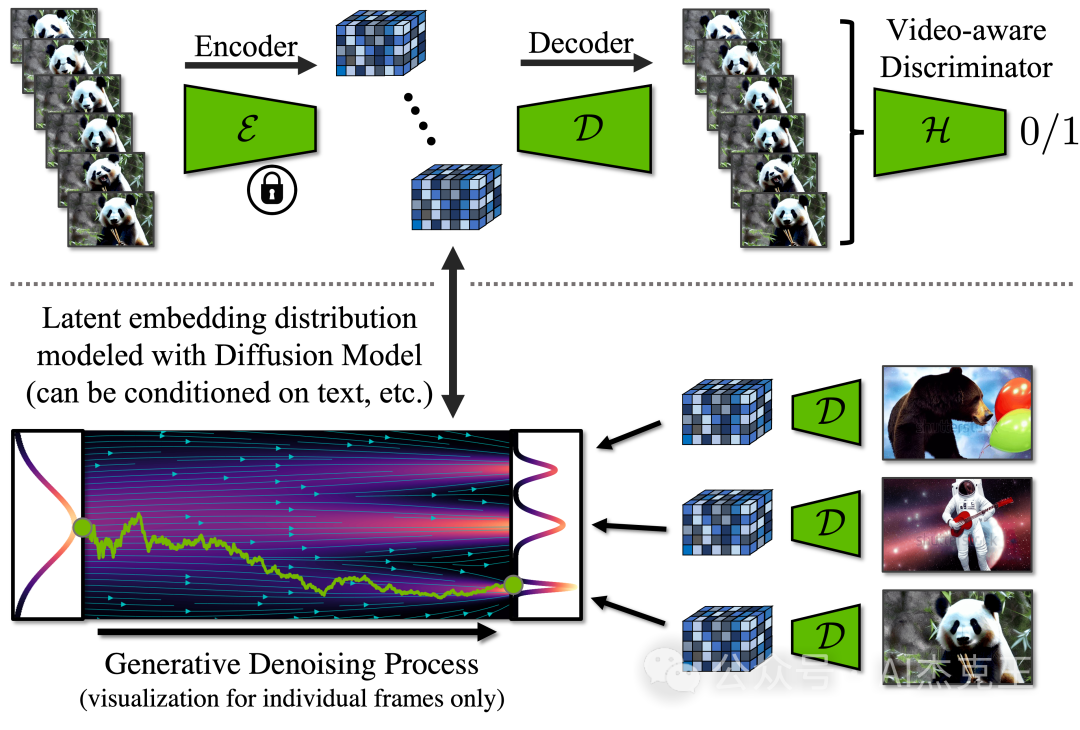
潜在扩散模型框架和视频解码器微调。
上图:在时间解码器微调过程中,使用冻结的每帧编码器处理视频序列,并在各帧之间执行时间一致性重建。此外,我们还采用了视频感知鉴别器。
下图:在 LDM 中,扩散模型是在潜在空间中训练的。它可以合成潜在特征,然后通过解码器将其转换为图像。实践中,对整个视频进行建模,并通过视频微调潜在扩散模型,以生成时间上一致的帧序列。
-
视频 LDM 模型最初以低帧率生成稀疏关键帧,然后通过另一个插值潜扩散模型对其进行两次时间上采样。
-
此外,通过对起始帧进行有条件的视频 LDM 视频预测训练,我们还能以自回归的方式生成长视频。
-
为了实现高分辨率生成,我们进一步利用空间扩散模型上采样器,并对它们进行时间对齐,以进行视频上采样。
整个生成堆栈如下所示:

视频 LDM 堆栈。首先生成稀疏的关键帧。然后,我们使用相同的插值模型分两步进行时间插值,以实现高帧率。这些操作使用共享相同图像骨干的潜像扩散模型(LDM)。最后,将潜在视频解码到像素空间,并选择性地应用视频上采样器扩散模型。
三. 应用总览
-
视频 LDM 能够生成分辨率为 512 x 1024 的时间连贯、多分钟长的视频,从而实现最先进的性能。
-
对于文本到视频,我们演示了几秒长度的短视频的合成,分辨率高达 1280 x 2048,利用稳定扩散作为主干图像 LDM 以及稳定扩散放大器。
-
我们还探索了模型的实时卷积应用,作为延长视频长度的替代方法。
-
我们的主要关键帧模型仅训练新插入的时间层,但不接触主干图像LDM的层。因此,学习到的时间层可以转移到其他图像 LDM 主干,例如已使用 DreamBooth 进行微调的主干。利用这一特性,我们还展示了个性化文本到视频生成的初步结果。
四. 个性化视频生成
我们将为视频 LDM 训练的用于文本到视频合成的时间层插入到图像 LDM 主干中,我们之前在DreamBooth之后的一组图像上微调过这些主干。时间层推广到 DreamBooth 权重,从而实现个性化的文本到视频的生成。

五. 实时卷积合成
文中还探索通过及时卷积应用我们学习的时间层来“免费”合成稍长的视频。以下视频由175 帧组成,以 24 fps 渲染,产生 7.3 秒长的剪辑。可以观察到轻微的质量下降。

六. 更多结果

七. 论文
https://arxiv.org/pdf/2304.08818.pdf
八. 个人思考
英伟达的工作还是一如既往的“硬核”。不仅实现高分辨率的视频生成,同时还实现了长时间的视频生成。并且训练的时间层可以作用于其他文生图模型,从而实现“免费”长时间文生视频的生成,这点很值得借鉴和学习尝试。
欢迎加入AI杰克王的免费知识星球,海量干货等着你,一起探讨学习AIGC!