目录
一.引言
二.服务搭建
1.服务配置
2.服务代码
3.服务踩坑
三.服务使用
1.服务启动
2.服务调用
3.服务结果
四.总结
一.引言
上一篇文章我们介绍了如果使用 conda 搭建 Bert-VITS2 最新版本的环境并训练自定义语音,通过 1000 个 epoch 的训练,我们得到了自定义语音模型,本文基于上文得到的生成器模型介绍如何部署语音推理服务,获取自定义角色音频。
Tips:
训练流程: Bert-VITS2 自定义训练语音
二.服务搭建
1.服务配置
查看项目根目录下的配置文件修改对应配置:
vim config.yml这里主要修改如下几点:
- port 修改服务监听的端口,主要不要与其他服务的端口重复
- models 自定义生成的模型内 G-xxxx.pth 为对应的生成器,可以尝试不同 Epoch 的模型都可以
- config 配置文件读取 ./configs/config.json 内的配置
- launguage 博主使用中文 ZH、大家如果是其他语言的话也可以修改
server:
# 端口号
port: 9876
# 模型默认使用设备:但是当前并没有实现这个配置。
device: "cuda"
# 需要加载的所有模型的配置,可以填多个模型,也可以不填模型,等网页成功后手动加载模型
# 不加载模型的配置格式:删除默认给的两个模型配置,给models赋值 [ ],也就是空列表。参考模型2的speakers 即 models: [ ]
# 注意,所有模型都必须正确配置model与config的路径,空路径会导致加载错误。也可以不填模型,等网页加载成功后手动填写models。
models:
- # 模型的路径
model: "data/models/G_15000.pth"
# 模型config.json的路径
config: "configs/config.json"
# 模型使用设备,若填写则会覆盖默认配置
device: "cuda"
# 模型默认使用的语言
language: "ZH"
# 模型人物默认参数
# 不必填写所有人物,不填的使用默认值
# 暂时不用填写,当前尚未实现按人区分配置
speakers:
- speaker: "科比"
sdp_ratio: 0.2
noise_scale: 0.6
noise_scale_w: 0.8
length_scale: 1
- speaker: "五条悟"
sdp_ratio: 0.3
noise_scale: 0.7
noise_scale_w: 0.8
length_scale: 0.5
- speaker: "安倍晋三"
sdp_ratio: 0.2
noise_scale: 0.6
noise_scale_w: 0.8
length_scale: 1.2
- # 模型的路径
model: "data/models/G_15000.pth"
# 模型config.json的路径
config: "configs/config.json"
# 模型使用设备,若填写则会覆盖默认配置
device: "gpu"
# 模型默认使用的语言
language: "ZH"2.服务代码
创建服务代码:
vim server_fastapi.py"""
api服务 多版本多模型 fastapi实现
"""
import logging
import gc
import random
from pydantic import BaseModel
import gradio
import numpy as np
import utils
from fastapi import FastAPI, Query, Request
from fastapi.responses import Response, FileResponse
from fastapi.staticfiles import StaticFiles
from io import BytesIO
from scipy.io import wavfile
import uvicorn
import torch
import webbrowser
import psutil
import GPUtil
from typing import Dict, Optional, List, Set
import os
from tools.log import logger
from urllib.parse import unquote
from infer import infer, get_net_g, latest_version
import tools.translate as trans
from re_matching import cut_sent
from config import config
os.environ["TOKENIZERS_PARALLELISM"] = "false"
class Model:
"""模型封装类"""
def __init__(self, config_path: str, model_path: str, device: str, language: str):
self.config_path: str = os.path.normpath(config_path)
self.model_path: str = os.path.normpath(model_path)
self.device: str = device
self.language: str = language
self.hps = utils.get_hparams_from_file(config_path)
self.spk2id: Dict[str, int] = self.hps.data.spk2id # spk - id 映射字典
self.id2spk: Dict[int, str] = dict() # id - spk 映射字典
for speaker, speaker_id in self.hps.data.spk2id.items():
self.id2spk[speaker_id] = speaker
self.version: str = (
self.hps.version if hasattr(self.hps, "version") else latest_version
)
self.net_g = get_net_g(
model_path=model_path,
version=self.version,
device=device,
hps=self.hps,
)
def to_dict(self) -> Dict[str, any]:
return {
"config_path": self.config_path,
"model_path": self.model_path,
"device": self.device,
"language": self.language,
"spk2id": self.spk2id,
"id2spk": self.id2spk,
"version": self.version,
}
class Models:
def __init__(self):
self.models: Dict[int, Model] = dict()
self.num = 0
# spkInfo[角色名][模型id] = 角色id
self.spk_info: Dict[str, Dict[int, int]] = dict()
self.path2ids: Dict[str, Set[int]] = dict() # 路径指向的model的id
def init_model(
self, config_path: str, model_path: str, device: str, language: str
) -> int:
"""
初始化并添加一个模型
:param config_path: 模型config.json路径
:param model_path: 模型路径
:param device: 模型推理使用设备
:param language: 模型推理默认语言
"""
# 若路径中的模型已存在,则不添加模型,若不存在,则进行初始化。
model_path = os.path.realpath(model_path)
if model_path not in self.path2ids.keys():
self.path2ids[model_path] = {self.num}
self.models[self.num] = Model(
config_path=config_path,
model_path=model_path,
device=device,
language=language,
)
logger.success(f"添加模型{model_path},使用配置文件{os.path.realpath(config_path)}")
else:
# 获取一个指向id
m_id = next(iter(self.path2ids[model_path]))
self.models[self.num] = self.models[m_id]
self.path2ids[model_path].add(self.num)
logger.success("模型已存在,添加模型引用。")
# 添加角色信息
for speaker, speaker_id in self.models[self.num].spk2id.items():
if speaker not in self.spk_info.keys():
self.spk_info[speaker] = {self.num: speaker_id}
else:
self.spk_info[speaker][self.num] = speaker_id
# 修改计数
self.num += 1
return self.num - 1
def del_model(self, index: int) -> Optional[int]:
"""删除对应序号的模型,若不存在则返回None"""
if index not in self.models.keys():
return None
# 删除角色信息
for speaker, speaker_id in self.models[index].spk2id.items():
self.spk_info[speaker].pop(index)
if len(self.spk_info[speaker]) == 0:
# 若对应角色的所有模型都被删除,则清除该角色信息
self.spk_info.pop(speaker)
# 删除路径信息
model_path = os.path.realpath(self.models[index].model_path)
self.path2ids[model_path].remove(index)
if len(self.path2ids[model_path]) == 0:
self.path2ids.pop(model_path)
logger.success(f"删除模型{model_path}, id = {index}")
else:
logger.success(f"删除模型引用{model_path}, id = {index}")
# 删除模型
self.models.pop(index)
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
return index
def get_models(self):
"""获取所有模型"""
return self.models
if __name__ == "__main__":
app = FastAPI()
app.logger = logger
# 挂载静态文件
StaticDir: str = "./Web"
dirs = [fir.name for fir in os.scandir(StaticDir) if fir.is_dir()]
files = [fir.name for fir in os.scandir(StaticDir) if fir.is_dir()]
for dirName in dirs:
app.mount(
f"/{dirName}",
StaticFiles(directory=f"./{StaticDir}/{dirName}"),
name=dirName,
)
loaded_models = Models()
# 加载模型
models_info = config.server_config.models
for model_info in models_info:
loaded_models.init_model(
config_path=model_info["config"],
model_path=model_info["model"],
device=model_info["device"],
language=model_info["language"],
)
@app.get("/")
async def index():
return FileResponse("./Web/index.html")
class Text(BaseModel):
text: str
@app.post("/voice")
def voice(
request: Request, # fastapi自动注入
text: Text,
model_id: int = Query(..., description="模型ID"), # 模型序号
speaker_name: str = Query(
None, description="说话人名"
), # speaker_name与 speaker_id二者选其一
speaker_id: int = Query(None, description="说话人id,与speaker_name二选一"),
sdp_ratio: float = Query(0.2, description="SDP/DP混合比"),
noise: float = Query(0.2, description="感情"),
noisew: float = Query(0.9, description="音素长度"),
length: float = Query(1, description="语速"),
language: str = Query(None, description="语言"), # 若不指定使用语言则使用默认值
auto_translate: bool = Query(False, description="自动翻译"),
auto_split: bool = Query(False, description="自动切分"),
):
"""语音接口"""
text = text.text
logger.info(
f"{request.client.host}:{request.client.port}/voice { unquote(str(request.query_params) )} text={text}"
)
# 检查模型是否存在
if model_id not in loaded_models.models.keys():
return {"status": 10, "detail": f"模型model_id={model_id}未加载"}
# 检查是否提供speaker
if speaker_name is None and speaker_id is None:
return {"status": 11, "detail": "请提供speaker_name或speaker_id"}
elif speaker_name is None:
# 检查speaker_id是否存在
if speaker_id not in loaded_models.models[model_id].id2spk.keys():
return {"status": 12, "detail": f"角色speaker_id={speaker_id}不存在"}
speaker_name = loaded_models.models[model_id].id2spk[speaker_id]
# 检查speaker_name是否存在
if speaker_name not in loaded_models.models[model_id].spk2id.keys():
return {"status": 13, "detail": f"角色speaker_name={speaker_name}不存在"}
if language is None:
language = loaded_models.models[model_id].language
if auto_translate:
text = trans.translate(Sentence=text, to_Language=language.lower())
if not auto_split:
with torch.no_grad():
audio = infer(
text=text,
emotion=None,
sdp_ratio=sdp_ratio,
noise_scale=noise,
noise_scale_w=noisew,
length_scale=length,
sid=speaker_name,
language=language,
hps=loaded_models.models[model_id].hps,
net_g=loaded_models.models[model_id].net_g,
device=loaded_models.models[model_id].device,
)
else:
texts = cut_sent(text)
audios = []
with torch.no_grad():
for t in texts:
audios.append(
infer(
text=t,
sdp_ratio=sdp_ratio,
noise_scale=noise,
noise_scale_w=noisew,
length_scale=length,
sid=speaker_name,
language=language,
hps=loaded_models.models[model_id].hps,
net_g=loaded_models.models[model_id].net_g,
device=loaded_models.models[model_id].device,
)
)
audios.append(np.zeros((int)(44100 * 0.3)))
audio = np.concatenate(audios)
audio = gradio.processing_utils.convert_to_16_bit_wav(audio)
wavContent = BytesIO()
wavfile.write(
wavContent, loaded_models.models[model_id].hps.data.sampling_rate, audio
)
response = Response(content=wavContent.getvalue(), media_type="audio/wav")
return response
@app.get("/voice")
def voice(
request: Request, # fastapi自动注入
text: str = Query(..., description="输入文字"),
model_id: int = Query(..., description="模型ID"), # 模型序号
speaker_name: str = Query(
None, description="说话人名"
), # speaker_name与 speaker_id二者选其一
speaker_id: int = Query(None, description="说话人id,与speaker_name二选一"),
sdp_ratio: float = Query(0.2, description="SDP/DP混合比"),
noise: float = Query(0.2, description="感情"),
noisew: float = Query(0.9, description="音素长度"),
length: float = Query(1, description="语速"),
language: str = Query(None, description="语言"), # 若不指定使用语言则使用默认值
auto_translate: bool = Query(False, description="自动翻译"),
auto_split: bool = Query(False, description="自动切分"),
):
"""语音接口"""
logger.info(
f"{request.client.host}:{request.client.port}/voice { unquote(str(request.query_params) )}"
)
# 检查模型是否存在
if model_id not in loaded_models.models.keys():
return {"status": 10, "detail": f"模型model_id={model_id}未加载"}
# 检查是否提供speaker
if speaker_name is None and speaker_id is None:
return {"status": 11, "detail": "请提供speaker_name或speaker_id"}
elif speaker_name is None:
# 检查speaker_id是否存在
if speaker_id not in loaded_models.models[model_id].id2spk.keys():
return {"status": 12, "detail": f"角色speaker_id={speaker_id}不存在"}
speaker_name = loaded_models.models[model_id].id2spk[speaker_id]
# 检查speaker_name是否存在
if speaker_name not in loaded_models.models[model_id].spk2id.keys():
return {"status": 13, "detail": f"角色speaker_name={speaker_name}不存在"}
if language is None:
language = loaded_models.models[model_id].language
if auto_translate:
text = trans.translate(Sentence=text, to_Language=language.lower())
if not auto_split:
with torch.no_grad():
audio = infer(
text=text,
emotion=None,
sdp_ratio=sdp_ratio,
noise_scale=noise,
noise_scale_w=noisew,
length_scale=length,
sid=speaker_name,
language=language,
hps=loaded_models.models[model_id].hps,
net_g=loaded_models.models[model_id].net_g,
device=loaded_models.models[model_id].device,
)
else:
texts = cut_sent(text)
audios = []
with torch.no_grad():
for t in texts:
audios.append(
infer(
text=t,
sdp_ratio=sdp_ratio,
noise_scale=noise,
noise_scale_w=noisew,
length_scale=length,
sid=speaker_name,
language=language,
hps=loaded_models.models[model_id].hps,
net_g=loaded_models.models[model_id].net_g,
device=loaded_models.models[model_id].device,
)
)
audios.append(np.zeros((int)(44100 * 0.3)))
audio = np.concatenate(audios)
audio = gradio.processing_utils.convert_to_16_bit_wav(audio)
wavContent = BytesIO()
wavfile.write(
wavContent, loaded_models.models[model_id].hps.data.sampling_rate, audio
)
response = Response(content=wavContent.getvalue(), media_type="audio/wav")
return response
@app.get("/models/info")
def get_loaded_models_info(request: Request):
"""获取已加载模型信息"""
result: Dict[str, Dict] = dict()
for key, model in loaded_models.models.items():
result[str(key)] = model.to_dict()
return result
@app.get("/models/delete")
def delete_model(
request: Request, model_id: int = Query(..., description="删除模型id")
):
"""删除指定模型"""
logger.info(
f"{request.client.host}:{request.client.port}/models/delete { unquote(str(request.query_params) )}"
)
result = loaded_models.del_model(model_id)
if result is None:
return {"status": 14, "detail": f"模型{model_id}不存在,删除失败"}
return {"status": 0, "detail": "删除成功"}
@app.get("/models/add")
def add_model(
request: Request,
model_path: str = Query(..., description="添加模型路径"),
config_path: str = Query(
None, description="添加模型配置文件路径,不填则使用./config.json或../config.json"
),
device: str = Query("cuda", description="推理使用设备"),
language: str = Query("ZH", description="模型默认语言"),
):
"""添加指定模型:允许重复添加相同路径模型,且不重复占用内存"""
logger.info(
f"{request.client.host}:{request.client.port}/models/add { unquote(str(request.query_params) )}"
)
if config_path is None:
model_dir = os.path.dirname(model_path)
if os.path.isfile(os.path.join(model_dir, "config.json")):
config_path = os.path.join(model_dir, "config.json")
elif os.path.isfile(os.path.join(model_dir, "../config.json")):
config_path = os.path.join(model_dir, "../config.json")
else:
return {
"status": 15,
"detail": "查询未传入配置文件路径,同时默认路径./与../中不存在配置文件config.json。",
}
try:
model_id = loaded_models.init_model(
config_path=config_path,
model_path=model_path,
device=device,
language=language,
)
except Exception:
logging.exception("模型加载出错")
return {
"status": 16,
"detail": "模型加载出错,详细查看日志",
}
return {
"status": 0,
"detail": "模型添加成功",
"Data": {
"model_id": model_id,
"model_info": loaded_models.models[model_id].to_dict(),
},
}
def _get_all_models(root_dir: str = "Data", only_unloaded: bool = False):
"""从root_dir搜索获取所有可用模型"""
result: Dict[str, List[str]] = dict()
files = os.listdir(root_dir) + ["."]
for file in files:
if os.path.isdir(os.path.join(root_dir, file)):
sub_dir = os.path.join(root_dir, file)
# 搜索 "sub_dir" 、 "sub_dir/models" 两个路径
result[file] = list()
sub_files = os.listdir(sub_dir)
model_files = []
for sub_file in sub_files:
relpath = os.path.realpath(os.path.join(sub_dir, sub_file))
if only_unloaded and relpath in loaded_models.path2ids.keys():
continue
if sub_file.endswith(".pth") and sub_file.startswith("G_"):
if os.path.isfile(relpath):
model_files.append(sub_file)
# 对模型文件按步数排序
model_files = sorted(
model_files,
key=lambda pth: int(pth.lstrip("G_").rstrip(".pth"))
if pth.lstrip("G_").rstrip(".pth").isdigit()
else 10**10,
)
result[file] = model_files
models_dir = os.path.join(sub_dir, "models")
model_files = []
if os.path.isdir(models_dir):
sub_files = os.listdir(models_dir)
for sub_file in sub_files:
relpath = os.path.realpath(os.path.join(models_dir, sub_file))
if only_unloaded and relpath in loaded_models.path2ids.keys():
continue
if sub_file.endswith(".pth") and sub_file.startswith("G_"):
if os.path.isfile(os.path.join(models_dir, sub_file)):
model_files.append(f"models/{sub_file}")
# 对模型文件按步数排序
model_files = sorted(
model_files,
key=lambda pth: int(pth.lstrip("models/G_").rstrip(".pth"))
if pth.lstrip("models/G_").rstrip(".pth").isdigit()
else 10**10,
)
result[file] += model_files
if len(result[file]) == 0:
result.pop(file)
return result
@app.get("/models/get_unloaded")
def get_unloaded_models_info(
request: Request, root_dir: str = Query("Data", description="搜索根目录")
):
"""获取未加载模型"""
logger.info(
f"{request.client.host}:{request.client.port}/models/get_unloaded { unquote(str(request.query_params) )}"
)
return _get_all_models(root_dir, only_unloaded=True)
@app.get("/models/get_local")
def get_local_models_info(
request: Request, root_dir: str = Query("Data", description="搜索根目录")
):
"""获取全部本地模型"""
logger.info(
f"{request.client.host}:{request.client.port}/models/get_local { unquote(str(request.query_params) )}"
)
return _get_all_models(root_dir, only_unloaded=False)
@app.get("/status")
def get_status():
"""获取电脑运行状态"""
cpu_percent = psutil.cpu_percent(interval=1)
memory_info = psutil.virtual_memory()
memory_total = memory_info.total
memory_available = memory_info.available
memory_used = memory_info.used
memory_percent = memory_info.percent
gpuInfo = []
devices = ["cpu"]
for i in range(torch.cuda.device_count()):
devices.append(f"cuda:{i}")
gpus = GPUtil.getGPUs()
for gpu in gpus:
gpuInfo.append(
{
"gpu_id": gpu.id,
"gpu_load": gpu.load,
"gpu_memory": {
"total": gpu.memoryTotal,
"used": gpu.memoryUsed,
"free": gpu.memoryFree,
},
}
)
return {
"devices": devices,
"cpu_percent": cpu_percent,
"memory_total": memory_total,
"memory_available": memory_available,
"memory_used": memory_used,
"memory_percent": memory_percent,
"gpu": gpuInfo,
}
@app.get("/tools/translate")
def translate(
request: Request,
texts: str = Query(..., description="待翻译文本"),
to_language: str = Query(..., description="翻译目标语言"),
):
"""翻译"""
logger.info(
f"{request.client.host}:{request.client.port}/tools/translate { unquote(str(request.query_params) )}"
)
return {"texts": trans.translate(Sentence=texts, to_Language=to_language)}
all_examples: Dict[str, Dict[str, List]] = dict() # 存放示例
@app.get("/tools/random_example")
def random_example(
request: Request,
language: str = Query(None, description="指定语言,未指定则随机返回"),
root_dir: str = Query("Data", description="搜索根目录"),
):
"""
获取一个随机音频+文本,用于对比,音频会从本地目录随机选择。
"""
logger.info(
f"{request.client.host}:{request.client.port}/tools/random_example { unquote(str(request.query_params) )}"
)
global all_examples
# 数据初始化
if root_dir not in all_examples.keys():
all_examples[root_dir] = {"ZH": [], "JP": [], "EN": []}
examples = all_examples[root_dir]
# 从项目Data目录中搜索train/val.list
for root, directories, _files in os.walk(root_dir):
for file in _files:
if file in ["train.list", "val.list"]:
with open(
os.path.join(root, file), mode="r", encoding="utf-8"
) as f:
lines = f.readlines()
for line in lines:
data = line.split("|")
if len(data) != 7:
continue
# 音频存在 且语言为ZH/EN/JP
if os.path.isfile(data[0]) and data[2] in [
"ZH",
"JP",
"EN",
]:
examples[data[2]].append(
{
"text": data[3],
"audio": data[0],
"speaker": data[1],
}
)
examples = all_examples[root_dir]
if language is None:
if len(examples["ZH"]) + len(examples["JP"]) + len(examples["EN"]) == 0:
return {"status": 17, "detail": "没有加载任何示例数据"}
else:
# 随机选一个
rand_num = random.randint(
0,
len(examples["ZH"]) + len(examples["JP"]) + len(examples["EN"]) - 1,
)
# ZH
if rand_num < len(examples["ZH"]):
return {"status": 0, "Data": examples["ZH"][rand_num]}
# JP
if rand_num < len(examples["ZH"]) + len(examples["JP"]):
return {
"status": 0,
"Data": examples["JP"][rand_num - len(examples["ZH"])],
}
# EN
return {
"status": 0,
"Data": examples["EN"][
rand_num - len(examples["ZH"]) - len(examples["JP"])
],
}
else:
if len(examples[language]) == 0:
return {"status": 17, "detail": f"没有加载任何{language}数据"}
return {
"status": 0,
"Data": examples[language][
random.randint(0, len(examples[language]) - 1)
],
}
@app.get("/tools/get_audio")
def get_audio(request: Request, path: str = Query(..., description="本地音频路径")):
logger.info(
f"{request.client.host}:{request.client.port}/tools/get_audio { unquote(str(request.query_params) )}"
)
if not os.path.isfile(path):
return {"status": 18, "detail": "指定音频不存在"}
if not path.endswith(".wav"):
return {"status": 19, "detail": "非wav格式文件"}
return FileResponse(path=path)
server_ip="1.1.1.1"
logger.warning("本地服务,请勿将服务端口暴露于外网")
logger.info(f"api文档地址 http://{server_ip}:{config.server_config.port}/docs")
webbrowser.open(f"http://{server_ip}:{config.server_config.port}")
uvicorn.run(
app, port=config.server_config.port, host=server_ip, log_level="warning"
)
这里代码很长,但我们只需要修改结尾处的 server_ip 即可。而真正对应推理的在代码的 import 处,我们可以查看目录下的 infer.py 内的 infer 函数关注具体的推理流程:
from infer import infer, get_net_g, latest_version
3.服务踩坑
◆ NLTK Not Found
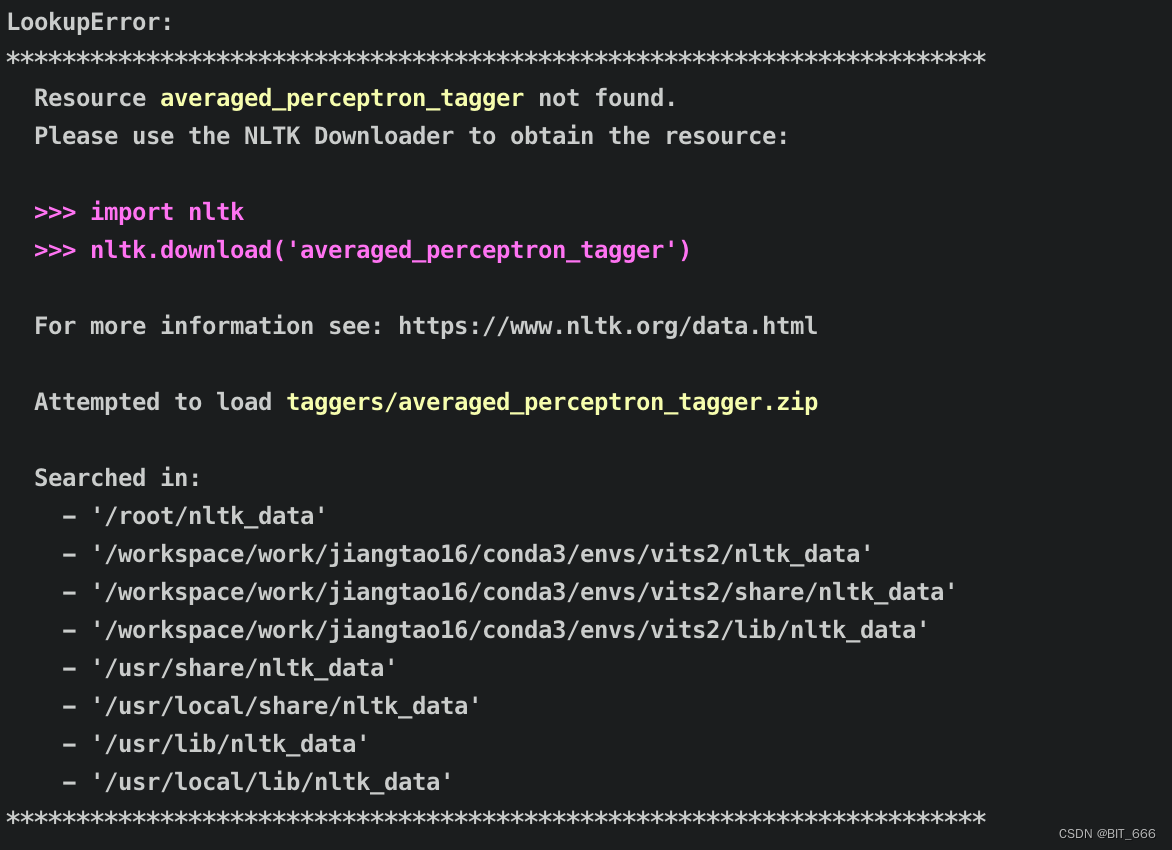
我们需要到 NLTK 的官方 github 代码库下载,下载地址: https://github.com/nltk/nltk_data
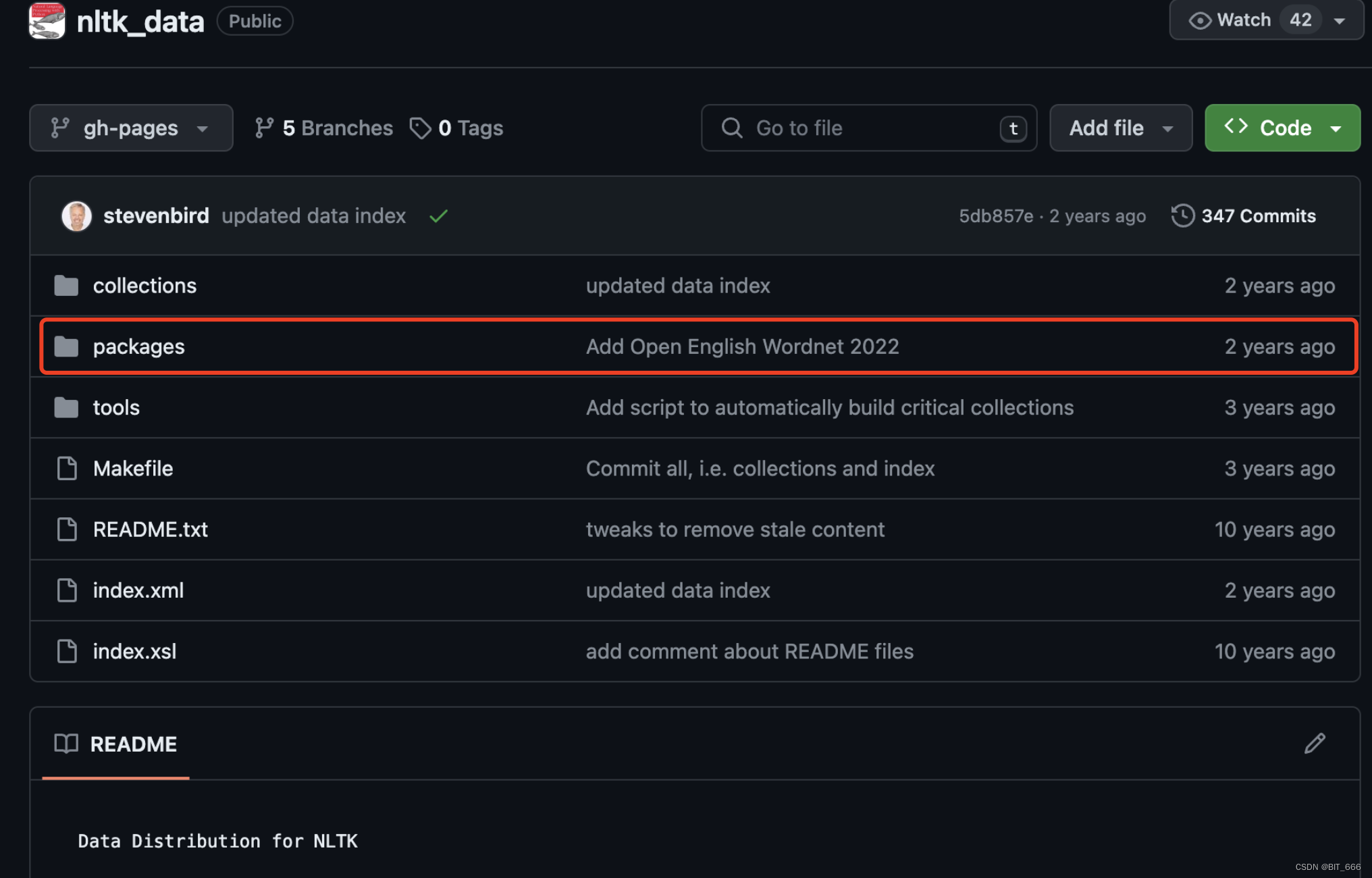
下载后把 packages 文件夹更名为 nltk_data,放置到上面 Searched in 的任一个目录下即可。
◆ No Such File or Dir
![]()
server 代码需要建立一个默认的 Web 文件夹,否则会报错:
mkdir Web◆ Missing Argument
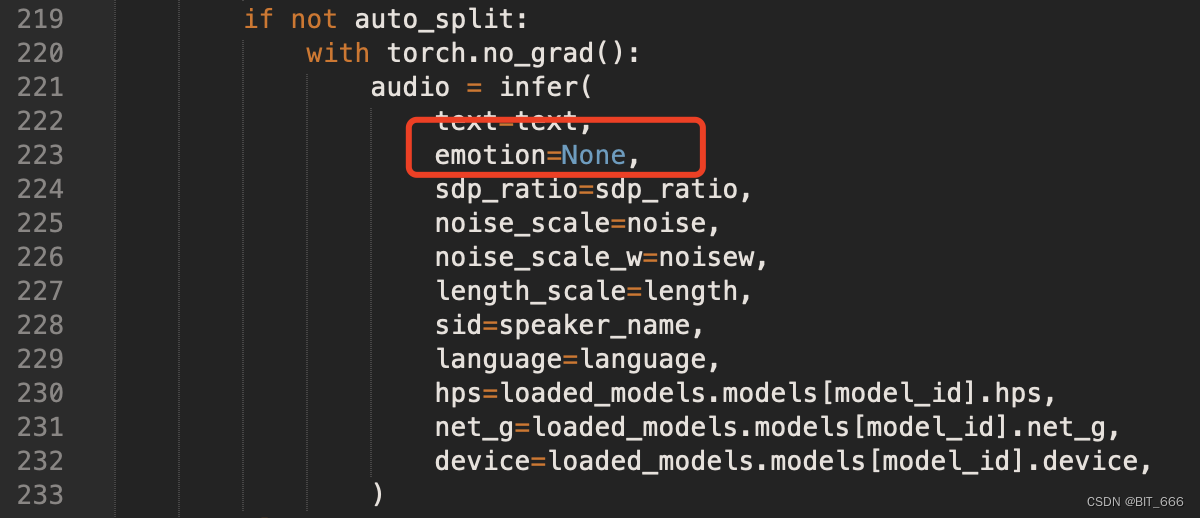
audio = infer(
TypeError: infer() missing 1 required positional argument: 'emotion'VITS2 社区的更新比较频繁,最近在 Infer 的参数中新增了 emotion 的参数,我们这里直接偷懒 Pass 了,传参为 None,如果大家有 emotion 的需求,也可以在 infer 相关代码里研究下:
三.服务使用
1.服务启动
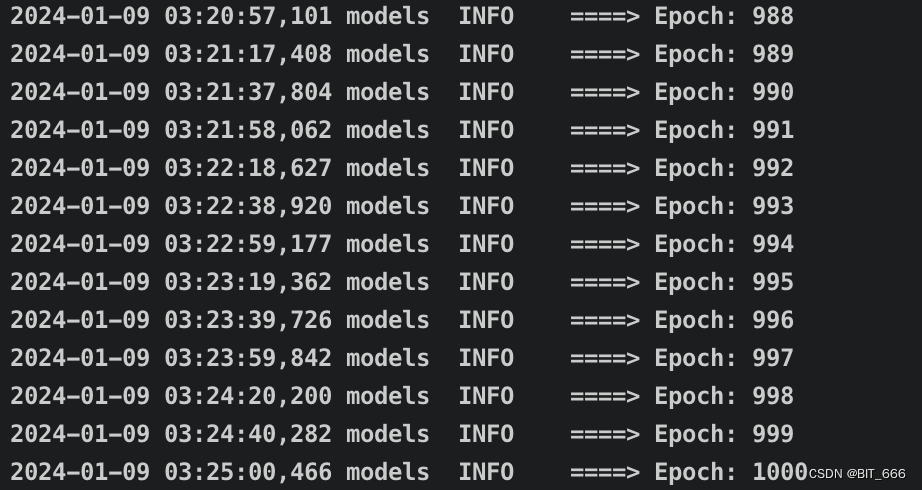
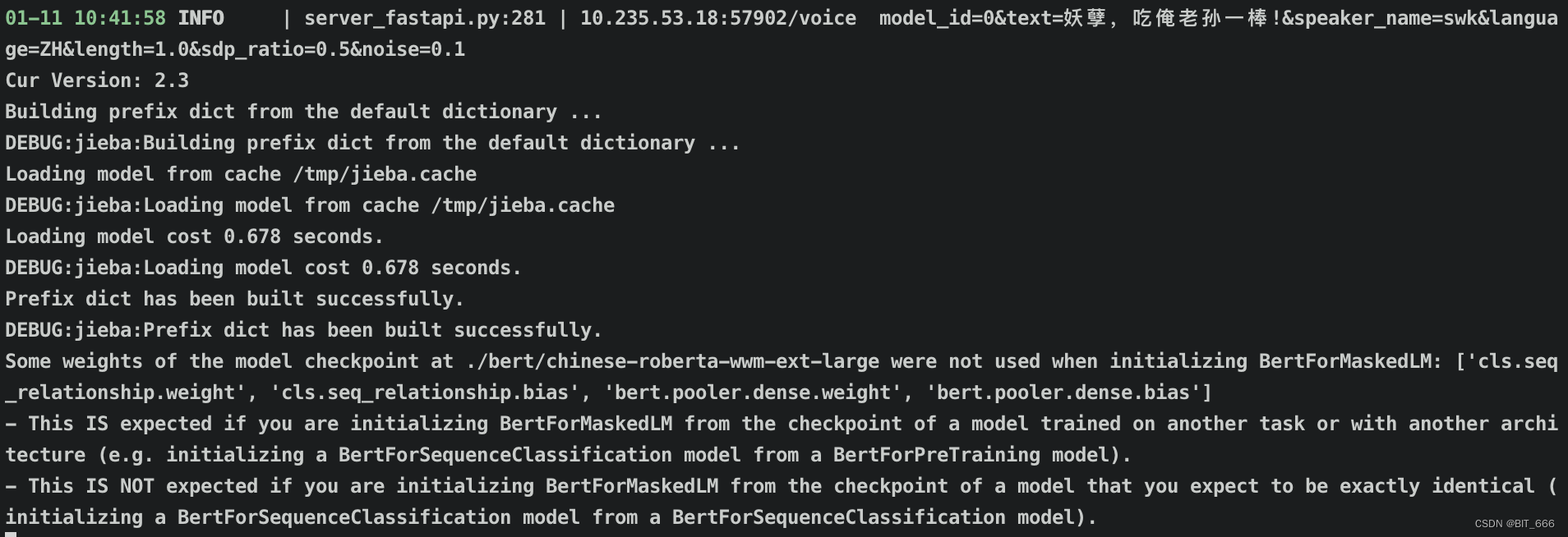
nohup python server_fastapi.py > log 2>&1 &直接后台启动即可,得到如下日志代表启动成功:

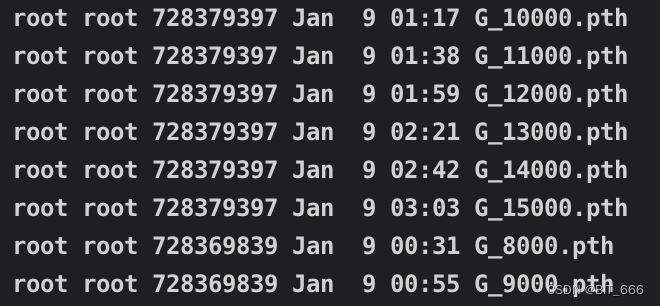
这里模型我们配置中保留最近的 8 个 Checkpoint, 可以尝试不同步数的 CK 填写的 config.yml:
2.服务调用
FastAPI 服务对应的 url 根据 server_fastapi.py 的 ip 和 config.yml 内的 port 决定:
url=${ip}:${port} => 1.1.1.1:9876◆ Get Voice
修改下面的 URL 对应我们的 ip 与 port,随后 Http get,Params 需传入我们对应的角色以及音频的参数配置。
#! /usr/bin/env python
# -*- coding: utf-8 -*-
import requests
import datetime
def get(typ, output, params={}):
url = "http://$ip:$port"
url_type = url + typ
if params.keys() == 0:
response = requests.get(url_type)
else:
response = requests.get(url_type, params=params)
if response.status_code == 200:
print('成功获取!')
if typ == "/voice":
with open(f'{output}.mp3', 'wb') as f: # 将音频文件写入到“目标音乐.mp3”中
f.write(response.content)
elif typ == "/models/info":
data = response.text
print("data:", data)
else:
print('请求失败,状态码:', response.status_code)
◆ Main
names 可以对照前面训练数据处理时传入的 person 名称,根据不同的 name,构建 json 调用 voice 接口,text 传文字,output 传音频输出地址。
def getMp3(text, output):
names = ["swk"]
for name in names:
prams = {
'model_id': 0,
'text': text,
'speaker_name': name,
'language': 'ZH',
'length': 1.0,
'sdp_ratio': 0.5,
'noise': 0.1
}
get("/voice", output=output, params=prams)
if __name__ == '__main__':
time_now = datetime.datetime.now().strftime("%Y%m%d%H%M")
print(time_now)
getMp3("妖孽,吃俺老孙一棒!", "swk")3.服务结果
调用后得到我们对应 output 的 mp3 结果,这里无法上传语音,大家可以自行测试听听效果。由于是语音生成,难免存在一些噪声,大家有兴趣也可以在服务后面添加噪声处理的逻辑。
四.总结
结合上文的训练流程,我们现在实现了自定义语音的训练到推理到服务的完整链路。整体来说音色还是比较相似的,由于训练音频的原因 G 生成器生成的音频可能存在噪声,也可以在生成 mp3 后再进行一道去噪的流程,优化整体语音质量。