目录:
- 1.使用分布式爬取XX电影信息
- (1)settings.py文件中的配置:
- (2)spider文件的更改:
- (3)items.py文件(两个项目一致!):
- (4)pipelines.py文件:
- 分布式实现效果:
- ①直接运行项目,发现在等待:
- ②再开一个终端,做如下操作:
- 总结:
- 效果:
- 2.解决一些小问题:
- 2.1 解决爬空问题:(在两个项目中都进行以下操作!)
- ①使用拓展程序(这个文件就是为了解决爬空而生的):
- ②在settings.py文件中设置这个拓展程序:
- 3. 关于分布式(Scrapy\_redis)的总结:
1.使用分布式爬取XX电影信息
- (此处做了限制,只爬取四页电影数据共计100条,可去除限制爬取全部10页250条数据!)
**项目源码:
链接:https://pan.baidu.com/s/13akXDxNbtBeRTUzUB_2SNQ
提取码:bcuy
**
目标:在本机上使用两个完全一模一样的豆瓣项目,去使用分布式下载XX电影top250电影信息!

其实,我们要进行修改的就只有settings.py文件以及爬虫文件,别的文件都不需要进行改动。
(1)settings.py文件中的配置:
- (两个项目都做此配置)
#设置scrapy-redis
#1.启用调度将请求存储进redis
from scrapy_redis.scheduler import Scheduler
SCHEDULER="scrapy_redis.scheduler.Scheduler"
#2.确保所有spider通过redis共享相同的重复过滤
from scrapy_redis.dupefilter import RFPDupeFilter
DUPEFILTER_CLASS="scrapy_redis.dupefilter.RFPDupeFilter"
#3.指定连接到Redis时要使用的主机和端口 目的是连接上redis数据库
REDIS_HOST="localhost"
REDIS_PORT=6379
# 不清理redis队列,允许暂停/恢复抓取 (可选) 允许暂停,redis数据不丢失 可以实现断点续爬!!!
SCHEDULER_PERSIST = True
# 第二步:开启将数据存储进redis公共区域的管道!
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 100, # 开启数据交给redis公共区域的管道
'douban.pipelines.DoubanPipeline': 200, # 存储本地txt文件的管道
}
(2)spider文件的更改:
- (两个项目略有不同!)
总共四步:
-
导入RedisSpider类:(既然要使用它,肯定首先要导入!)
from scrapy_redis.spiders import RedisSpider -
继承使用RedisSpider类:(既然要使用它,就要继承去使用这个类)
class DbSpider(RedisSpider): -
既然将请求都放进了Redis里,那爬虫文件中就不再需要start_urls这个初始请求了:
#start_urls = ['https://movie.douban.com/top250'] -
设置一个键,寻找起始的url:(这个键就会在redis中寻找初始的url,所以后面我们只需往redis里放请求即可!)
redis_key="db:start_urls"
完整版爬虫文件:
第一个项目下的爬虫文件:
# -*- coding: utf-8 -*-
import scrapy
import re
from ..items import DoubanItem
from scrapy_redis.spiders import RedisSpider # 1.导出RedisSpider类
class DbSpider(RedisSpider): # 2.使用RedisSpider类
name = 'db'
allowed_domains = ['movie.douban.com']
# start_urls = ['https://movie.douban.com/top250'] # 3.将请求放进redis里
redis_key = "db:start_urls" # 4.设置一个键,寻找起始的url
page_num = 0 # 类变量
def parse(self, response): # 解析和提取数据
print('第一个项目:', response.url)
print('第一个项目:', response.url)
print('第一个项目:', response.url)
# 获取电影信息数据
# films_name=response.xpath('//div[@class="info"]/div/a/span[1]/text()').extract()
node_list = response.xpath('//div[@class="info"]') # 25个
if node_list: # 此判断的作用:在爬取到10页之后,就获取不到了!判断每次是否获取到数据,如果没有则返回空(即停止了)
for node in node_list:
# 电影名字
film_name = node.xpath('./div/a/span[1]/text()').extract()[0]
# 主演 拿标签内容,再正则表达式匹配
con_star_name = node.xpath('./div/p[1]/text()').extract()[0]
if "主" in con_star_name:
star_name = re.findall("主演?:? ?(.*)", con_star_name)[0]
else:
star_name = "空"
# 评分
score = node_list.xpath('./div/div/span[@property="v:average"]/text()').extract()[0]
# 使用字段名 收集数据
item = DoubanItem()
item["film_name"] = film_name
item["star_name"] = star_name
item["score"] = score
# 形式:{"film_name":"肖申克的救赎","star_name":"蒂姆","score":"9.7"}
detail_url = node.xpath('./div/a/@href').extract()[0]
yield scrapy.Request(detail_url,callback=self.get_detail,meta={"info":item})
# 此处几行的代码配合yield里传的参数meta={"num":self.page_num},共同作用实现:
# 两个项目的共享变量page_num能正确变化,不导致冲突!!!
if response.meta.get("num"):
self.page_num = response.meta["num"]
self.page_num += 1
if self.page_num == 4:
return
print("page_num:", self.page_num)
page_url = "https://movie.douban.com/top250?start={}&filter=".format(self.page_num * 25)
yield scrapy.Request(page_url, callback=self.parse, meta={"num": self.page_num})
# 注意:各个模块的请求都会交给引擎,然后经过引擎的一系列操作;但是,切记:引擎最后要把得到的数据再来给到
# spider爬虫文件让它解析并获取到真正想要的数据(callback=self.parse)这样就可以再给到自身。
else:
return
def get_detail(self, response):
item = DoubanItem()
# 获取电影简介信息
# 1.meta会跟随response一块返回 2.可以通过response.meta接收 3.通过updata可以添加到新的item对象
info = response.meta["info"] # 接收电影的基本信息
item.update(info) # 把电影基本信息的字段加进去
# 将电影简介信息加入相应的字段里
description = response.xpath('//div[@id="link-report-intra"]//span[@property="v:summary"]/text()').extract()[0]\
.strip()
item['description'] = description
yield item
第二个项目下的爬虫文件:
# -*- coding: utf-8 -*-
import scrapy
import re
from ..items import DoubanItem
from scrapy_redis.spiders import RedisSpider # 1.导出RedisSpider类
class DbSpider(RedisSpider): # 2.使用RedisSpider类
name = 'db'
allowed_domains = ['movie.douban.com']
# start_urls = ['https://movie.douban.com/top250'] # 3.将请求放进redis里
redis_key = "db:start_urls" # 4.设置一个键,寻找起始的url
page_num = 0 # 类变量
def parse(self, response): # 解析和提取数据
print('第二个项目:', response.url)
print('第二个项目:', response.url)
print('第二个项目:', response.url)
# 获取电影信息数据
# films_name=response.xpath('//div[@class="info"]/div/a/span[1]/text()').extract()
node_list = response.xpath('//div[@class="info"]') # 25个
if node_list: # 此判断的作用:在爬取到10页之后,就获取不到了!判断每次是否获取到数据,如果没有则返回空(即停止了)
for node in node_list:
# 电影名字
film_name = node.xpath('./div/a/span[1]/text()').extract()[0]
# 主演 拿标签内容,再正则表达式匹配
con_star_name = node.xpath('./div/p[1]/text()').extract()[0]
if "主" in con_star_name:
star_name = re.findall("主演?:? ?(.*)", con_star_name)[0]
else:
star_name = "空"
# 评分
score = node_list.xpath('./div/div/span[@property="v:average"]/text()').extract()[0]
# 使用字段名 收集数据
item = DoubanItem()
item["film_name"] = film_name
item["star_name"] = star_name
item["score"] = score
# 形式:{"film_name":"肖申克的救赎","star_name":"蒂姆","score":"9.7"}
detail_url = node.xpath('./div/a/@href').extract()[0]
yield scrapy.Request(detail_url,callback=self.get_detail,meta={"info":item})
# 此处几行的代码配合57行yield里传的参数meta={"num":self.page_num},共同作用实现:
# 两个项目的共享变量page_num能正确变化,不导致冲突!!!
if response.meta.get("num"):
self.page_num = response.meta["num"]
self.page_num += 1
if self.page_num == 4:
return
print("page_num:", self.page_num)
page_url = "https://movie.douban.com/top250?start={}&filter=".format(self.page_num * 25)
yield scrapy.Request(page_url, callback=self.parse, meta={"num": self.page_num})
# 注意:各个模块的请求都会交给引擎,然后经过引擎的一系列操作;但是,切记:引擎最后要把得到的数据再来给到
# spider爬虫文件让它解析并获取到真正想要的数据(callback=self.parse)这样就可以再给到自身。
else:
return
def get_detail(self, response):
item = DoubanItem()
# 获取电影简介信息
# 1.meta会跟随response一块返回 2.可以通过response.meta接收 3.通过updata可以添加到新的item对象
info = response.meta["info"] # 接收电影的基本信息
item.update(info) # 把电影基本信息的字段加进去
# 将电影简介信息加入相应的字段里
description = response.xpath('//div[@id="link-report-intra"]//span[@property="v:summary"]/text()').extract()[0]\
.strip()
item['description'] = description
yield item
(3)items.py文件(两个项目一致!):
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#需要定义字段名 就像数据库那样,有字段名,才能插入数据(即存储数据)
# films_name=scrapy.Field() #定义字段名
film_name=scrapy.Field()
star_name=scrapy.Field()
score=scrapy.Field()
description = scrapy.Field()
(4)pipelines.py文件:
- (两个项目存储本地txt文件名可改为不一样的,便于观察!)
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import json
import pymysql
class DoubanPipeline(object):
def open_spider(self,spider): #爬虫文件开启,此方法就开启
self.f=open("films.txt","w",encoding="utf-8") #打开文件
def process_item(self, item, spider): #会来25次,就会调用25次这个方法 如果按常规来写,文件就会被操作25次打开关闭
#为了能写进text json.dumps将dic数据转换为str
json_str=json.dumps(dict(item),ensure_ascii=False)+"\n"
self.f.write(json_str) #爬虫文件开启时,文件就已经打开,在此直接写入数据即可!
return item
def close_spider(self,spider): #爬虫文件关闭,此方法就开启
self.f.close() #爬虫文件关闭时,引擎已经将全部数据交给管道,关闭文件
分布式实现效果:
①直接运行项目,发现在等待:
分别在两个终端中开启两个scrapy项目:(注意:之前要开启redis数据库)

会发现,这俩项目都在等待,不会继续执行。这是因为没有给redis这个公共区域一个初始的请求,这俩项目都在周而复始的向redis要初始url,结果一直要不到!
在两个项目的settings.py文件中设置两个的日志不显示在控制台,而是存储到.log文件中。为了便于观察:
LOG_FILE="db.log"
LOG_ENABLED=False
②再开一个终端,做如下操作:
lpush db:start_urls https://movie.douban.com/top250

会发现我们的两个项目都会成功的跑起来:(而且总共获取数据刚好是四页的电影信息,共计100条)
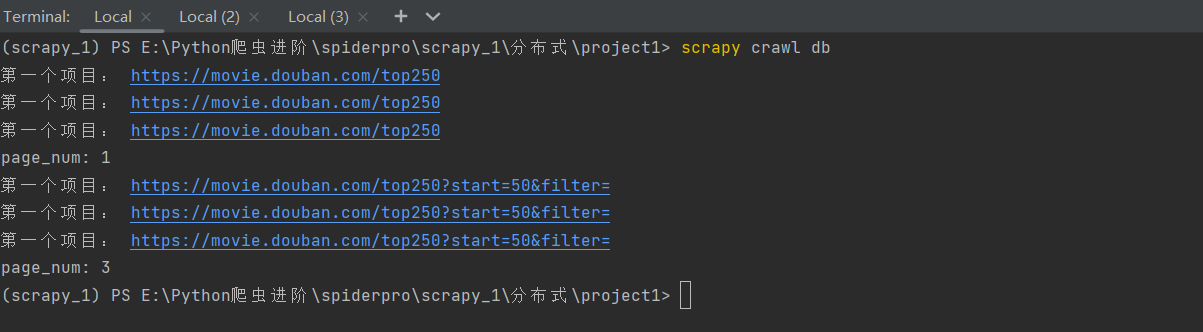
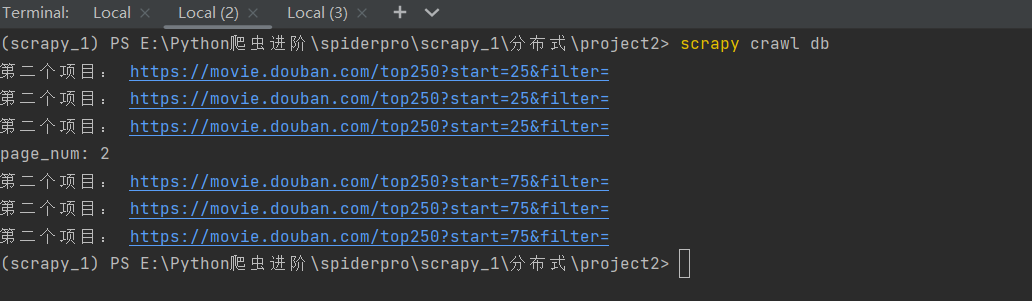
总结:
会发现,第一个项目运行会显示使用了parse函数,这也就说明在redis这个公共区域的start_urls请求被第一个项目抢到了,然后就会运行这个项目,
但是,在这个项目的爬虫文件代码执行的过程中会在25次循环中给引擎发送共25次url请求,引擎得到这25个request请求后会将它们都交给scheduler调度器,再通过调度器交给redis数据库这个公共区域。
然后,两个项目的scheduler调度器就会一起抢这公共区域里的请求,并在各自的爬虫程序运行过程中提交给redis别的请求,两个项目继续抢,直到爬空。这就实现了咱爬虫的分布式爬取数据!!!

效果:
- (因为没有解决爬空,所以项目运行完并不会自己关闭,而且,哪怕项目运行完了,也会一直无限的爬空,就导致两个项目爬取的保存本地的数据不够100条,所以,在两个项目运行完在爬空的时候,强制关闭两个项目,就会发现数据是完整的了!!!)
两个项目下的获取存储到本地的txt文本内的电影信息共计刚好我们所要爬取的所有目标数据:四页共100部电影的信息。
2.解决一些小问题:
2.1 解决爬空问题:(在两个项目中都进行以下操作!)
①使用拓展程序(这个文件就是为了解决爬空而生的):
两个项目进行防爬空设置后,如果数据爬取完成,在指定时间内就会自动停止爬虫!!!
(文件名:extensions.py,放到settings.py同级目录里)
加入此拓展之后完整的项目代码:
链接:https://pan.baidu.com/s/1Naie1HsWCxS-1ntorT3_RQ
提取码:e30p
# -*- coding: utf-8 -*-
# Define here the models for your scraped Extensions
import logging
from scrapy import signals
from scrapy.exceptions import NotConfigured
logging = logging.getLogger(__name__)
class RedisSpiderSmartIdleClosedExensions(object):
def __init__(self, idle_number, crawler):
self.crawler = crawler
self.idle_number = idle_number
self.idle_list = []
self.idle_count = 0
@classmethod
def from_crawler(cls, crawler):
# first check if the extension should be enabled and raise
# NotConfigured otherwise
if not crawler.settings.getbool('MYEXT_ENABLED'):
raise NotConfigured
if not 'redis_key' in crawler.spidercls.__dict__.keys():
raise NotConfigured('Only supports RedisSpider')
# get the number of items from settings
idle_number = crawler.settings.getint('IDLE_NUMBER', 360)
# instantiate the extension object
ext = cls(idle_number, crawler)
# connect the extension object to signals
crawler.signals.connect(ext.spider_opened, signal=signals.spider_opened)
crawler.signals.connect(ext.spider_closed, signal=signals.spider_closed)
crawler.signals.connect(ext.spider_idle, signal=signals.spider_idle)
return ext
def spider_opened(self, spider):
spider.logger.info("opened spider {}, Allow waiting time:{} second".format(spider.name, self.idle_number * 5))
def spider_closed(self, spider):
spider.logger.info(
"closed spider {}, Waiting time exceeded {} second".format(spider.name, self.idle_number * 5))
def spider_idle(self, spider):
# 程序启动的时候会调用这个方法一次,之后每隔5秒再请求一次
# 当持续半个小时都没有spider.redis_key,就关闭爬虫
# 判断是否存在 redis_key
if not spider.server.exists(spider.redis_key):
self.idle_count += 1
else:
self.idle_count = 0
if self.idle_count > self.idle_number:
# 执行关闭爬虫操作
self.crawler.engine.close_spider(spider, 'Waiting time exceeded')
②在settings.py文件中设置这个拓展程序:
# Enable or disable extensions #扩展程序
# See https://docs.scrapy.org/en/latest/topics/extensions.html
EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
'film.extensions.RedisSpiderSmartIdleClosedExensions':500, #开启extensions.py这个拓展程序
}
MYEXT_ENABLED = True # 开启扩展
IDLE_NUMBER = 3 # 配置空闲持续时间单位为 3个 ,一个时间单位为5s
注意:redis中存储的数据:
- spidername:items
list类型,保存爬虫获取到的数据item内容是json字符串。 - spidername:dupefilter
set类型,用于爬虫访问的URL去重内容是40个字符的url的hash字符串 - spidername:start_urls
list类型,用于接收redisspider启动时的第一个url - spidername:requests
zset类型,用于存放requests等待调度。内容是requests对象的序列化字符串。
3. 关于分布式(Scrapy_redis)的总结:
(一)分布式爬虫
一.settings里的配置
# 启用调度将请求存储进redis
# 1.必须
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
#2. 必须
# 确保所有spider通过redis共享相同的重复过滤。
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 3.必须
# 指定连接到Redis时要使用的主机和端口。
REDIS_HOST = 'localhost'
REDIS_PORT = 6379
二.spider文件更改
from scrapy_redis.spiders import RedisSpider #1 导出 RedisSpider
class DbSpider(RedisSpider): #2使用RedisSpider类
# start_urls = ['https://movie.douban.com/top250/'] #3将要请求放在 公共区域 redis里面
redis_key = "db:start_urls"#4 设置一个键 寻找起始url
三.redis数据库中 写入 start_urls
lpush db:start_urls https://movie.douban.com/top250/
四.解决爬空的问题
1.解决爬空的文件 extensions.py 主要是RedisSpiderSmartIdleClosedExensions
2.设置
MYEXT_ENABLED = True # 开启扩展
IDLE_NUMBER = 3 # 配置空闲持续时间单位为 3个 ,一个时间单位为5s