论文题目
Zero-Shot Learning across Heterogeneous Overlapping Domains
基准方法
-
Naïve Bayes (Unigram)
- P ( u t t e r a n c e ∣ d o m a i n ) P(utterance | domain) P(utterance∣domain) is modeled with Naïve Bayes model with features being word unigrams in the utterance.
-
Naïve Bayes (Unigram + Bigram)
- Same as above but word bigrams are added as features in addition to unigrams。
-
Language Model
- A trigram language model is used per
domain to model P(utterance | domain). Kneser-Ney
smoothing for n-gram backoff has been applied.
- A trigram language model is used per
-
. Embeddings k-NN:
- K-NN using intent embeddings from a classifier trained on data excluding the zero-shot partition .
-
a加粗样式 vocabulary size of 10,000 unique words
-
Words not included in the vocabulary are mapped to a special rare word token, so their counts are shared per domain model.
-
Each of domain consists of multiple intents,
-
they are more homogeneous and therefore easier to model
(更异构,因此更加容易的取建模)
结论和未来工作
本文工作
- 引入
c
l
a
s
s
a
t
t
r
i
b
u
t
e
s
class attributes
classattributes : a generic framework for achiev-
ing zero-shot language understanding - We have also demonstrated a flexible neural network architecture to perform inference over classes never encountered in training
- (256-dimensional compared to 10k-100k for n-gram baselines
- replace all domain-specific models with a single joint model.
We introduced class attributes, a generic framework for achiev-
ing zero-shot language understanding. We have also demon-
strated a flexible neural network architecture to perform infer-
ence over classes never encountered in training. The model
improves upon an averaged-embeddings baseline and performs
at par with generative models while requiring much smaller
vectors to be stored per domain (256-dimensional compared
to 10k-100k for n-gram baselines) and also shows promise to
replace all domain-specific models with a single joint model.
The zero-shot architecture also provides a general framework
for incorporating contextual conditioning such as personalized
features into the model.
未来工作
- Future work can explore techniques that better map from feature spaces in one modality to another
-
Compact Bilinear Pooling popularized by[9]
-
incorporating syntactic information into the model via subword embeddings [18]
-
replacing the dot product based scoring function with a learned
model as has recently been popularized by adversarial methods[10] -
In the context of Spoken Language Understanding, we can augment the encoders with context features and generalize them to consume ASR lattices and developer grammars [11]
-
Future work can explore techniques that better map from
feature spaces in one modality to another, such as Compact
Bilinear Pooling popularized by [9], incorporating syntactic
information into the model via subword embeddings [18], or
replacing the dot product based scoring function with a learned
model as has recently been popularized by adversarial methods
[10]. In the context of Spoken Language Understanding, we can
augment the encoders with context features and generalize them
to consume ASR lattices and developer grammars [11].
总结
先将各个论文创新点,全部都罗列出来,整理论文的基准方法及未来工作,慢慢的将其打磨透彻,研究彻底都行啦的理由与打算,后期租台电脑时候,开始正式搞研究。
- 会挖掘自己的创新点,慢慢的将各种创新点,设计自己的网络架构,设计的自己网络架构。
论文题目
题目
Learn to Adapt for Generalized Zero-Shot Text Classification
基准方法

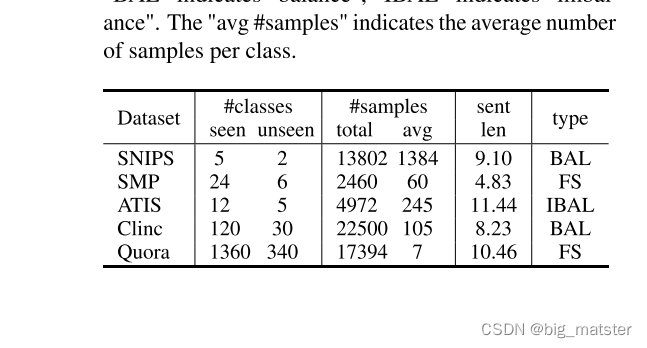
Datasets
- Intent Classification Datasets.
- SNIPS-SLU
- SMP-18
- ATIS
- CLINC
- Question Classification Dataset
Baselines Methods
- Supervised Learning Methods.
- BiLSTM
- BERT
- Metric Learning Methods
- Metric-based embedding methods are commonly used as baselines for GZSL
- EucSoftmax
- Zero-shot DNN
- CosT
- SOTA Methods
- ReCapsNet
- SEG (Yan et al., 2020) is an outlier detection approach
- RIDE
未来工作与展望
we select a representative case “when is
it time for a tire change” and show its atten-
tion weights used as calibration parameters in ©.
The case is still misclassified after the prototype
adaptation due that the common word “time” and
“change” also appear in seen classes. After the
sample adaptation, however, it can be seen that
the word “tire” which is a keyword for classifying,
gets the highest attention while the other confusing
words do not. This result suggests that calibrating
using attention weights helps acquire a prototype-
aware representation that guides the sample adap-
tation.
- In particular, it efficiently alleviated the bias towards seen classes by utilizing both prototype adaptation and sample adaptation
- Experiments on five text classification datasets validated that our model achieved compelling results on both seen classes and unseen classes meanwhile was capable of fast adapting to new classes
未来工作
As the partition of seen and unseen classes is fixed
in previous experiments, to study the robustness
of the proposed adaptation method, we conduct
the experiment across unseen class sets of differ-
ent scales on CLINC dataset. Specifically, we se-
lect 70 classes as seen classes and 10 classes as
validating unseen classes. The number of testing
unseen classes is varied from 1 to 70, which are
randomly sampled from the remaining 70 classes.
Each experiment is repeated 50 times with different
sampling sets for a more stable result. Figure 3 (a)
shows the HM accuracy on all classes as the num-
ber of the unseen classes increases. We can see that
our LTA model outperforms the metric learning
baseline and ablation models in all cases, where
the improved performance is mainly attributed to
the improvements on unseen classes as shown in
Figure 3 (b). These results suggest that our adap-
tation method is robust and effective for adapting
to increasing new classes as well as improving the
overall performance of all classes.
总结
- 会慢慢的将各种网络架构全部都搞清楚,慢慢的将会自己设计自己的网络架构,慢慢的将各种方法都搞清楚, 学习研究透彻。研究彻底。
参考连接
Zero-Shot Learning across Heterogeneous Overlapping Domains
Learn to Adapt for Generalized Zero-Shot Text Classification
经验
明天开始一天一篇,并将各种网络架构全部设计完整,慢慢的将各种网络架构全部设计完整。会设计自己的网络架构,锻炼自己的架构思维。