文章目录
- 一、分库分表原理
- 垂直切分:分库
- 水平切分:分表
- 二、分库分表环境准备
- 示例:
- 开始准备环境
- 三、实现分库分表
- 3.1 分库分表--广播表(BROADCAST)
- 3.2 分库分表--分片表(dbpartition、tbpartition)
- 3.3 分库分表--ER表(自动识别)
- 四、常用的分片规则
- 常用分片规则简介
- MOD_HASH
- RIGHT_SHIFT
- YYYYMM
- MMDD
- 五、全局序列
- 1. 建表语句方式关闭全局序列(AUTO_INCREMENT)
- 2. 设置mycat数据库方式获取全局序列
一、分库分表原理
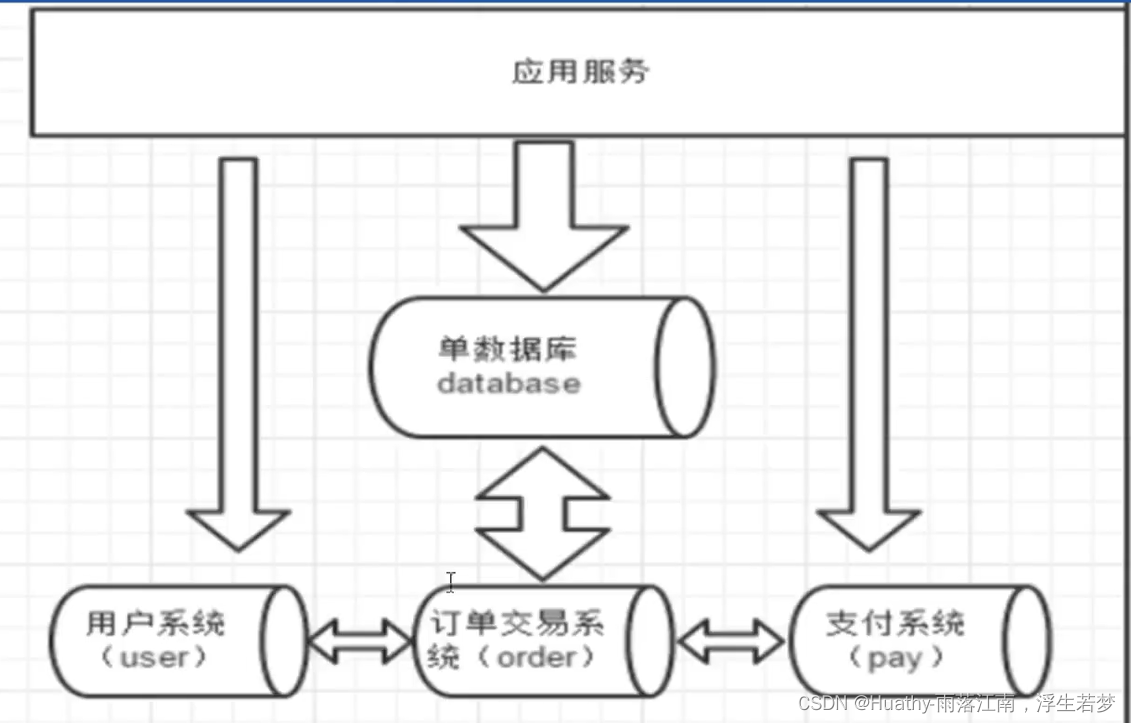
一个数据库由很多表的构成,每个表对应着不同的业务,垂直切分是指按照业务将表进行分布到不同的数据库上面,这样也就将数据或者说压力分担到不同的库上面,如下图:
垂直切分:分库
系统被拆分为用户、订单、支付多个模块,部署在不同机器上。
分库的原则:由于跨库不能关联查询,所以有紧密关联的表应当放在一个数据库中,相互没有关联的表可以分不到不同的数据库。
eg:
客户表 customer rows 20W
订单表 orders rows 600W
订单详情表 orders_detail rows 600W
订单状态字典表 dic_order_type rows 600W
分库方案:将客户表单独分到一个数据库,订单相关联的表放到一个数据库。
水平切分:分表
- 分表字段
以orders表为例,可以根据不同的字段来进行分表。
| 分表字段 | 效果 |
|---|---|
| ID(主键、创建时间) | 查询订单注重实效,历史订单查询次数少。带来的问题是会造成一个时间段分片数据多则该节点访问多,另一个访问少。分片不均匀。 |
| customer_id(客户ID) | 根据客户ID分片,俩个节点平均访问,一个客户的订单都在一个库中,查询历史订单较快 |
二、分库分表环境准备
示例:
执行注释脚本,创建集群配置
/*! mycat:createCluster{
"name":"prototype",
"masters":["rwSepw1"],
"replicas":["rwSepr1"]
} */
也可以修改配置文件
{
"clusterType":"MASTER_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetryCount":3,
"minSwitchTimeInterval":300,
"showLog":false,
"slaveThreshold":0.0
},
"masters":[
"rwSepw1"
],
"maxCon":2000,
"name":"prototype",
"readBalanceType":"BALANCE_ALL",
"replicas":[
"rwSepr1"
],
"switchType":"SWITCH"
}
注意:如果MySQL服务没有启动的话,需要注释掉mycat\conf\datasource下的数据源文件再启动,否则报错会导致mycat启动失败。
mycat2分库分表的优势:可以在终端直接使用注释脚本创建数据源、集群、库存,并在创建时指定分库、分表。
开始准备环境
- 添加数据源
-- 添加数据源dw1-13306、dw2-23306、dr1-33306、dr2-43306 /*+ mycat:createDataSource{ "name":"dw1", "url":"jdbc:mysql://127.0.0.1:13306/db1?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true", "user":"root", "password":"admin" }*/; -- 查看 /*+ mycat:showDataSources{} */ - 添加集群配置
/*! mycat:createCluster{ "name":"c1", "masters":["dw1"], "replicas":["dr1"] } */ -- 查看 /*! mycat:showClusters{} */
三、实现分库分表
3.1 分库分表–广播表(BROADCAST)
关键字:BROADCAST
- 执行建表语句
create table db1. `dic_order_type` ( id int not null auto_increment, dcode varchar(100) not null, dname varchar(100) not null, primary key(id) )engine=InnoDB default charset=utf8 BROADCAST; -- 这里我们加上关键字 BROADCAST,即可将创建的表标识为广播表。 - 在mycat中执行sql脚本,我们可以看到
mycat\conf\schemas\db1.schema.json已经发生了变化。globalTables增加了dic_order_type表配置,其中的broadcast配置了两个targetName。{ "customTables":{}, "globalTables":{ "dic_order_type":{ "broadcast":[ { "targetName":"c1" }, { "targetName":"c2" } ], "createTableSQL":"/* ApplicationName=DBeaver 22.3.1 - SQLEditor <Script-4.sql> */\nCREATE TABLE db1.`dic_order_type` (\n\tid int NOT NULL AUTO_INCREMENT,\n\tdcode varchar(100) NOT NULL,\n\tdname varchar(100) NOT NULL,\n\tPRIMARY KEY (id)\n) BROADCAST ENGINE = InnoDB CHARSET = utf8", "sequenceType":"NO_SEQUENCE" } }, "normalProcedures":{}, "normalTables":{}, "schemaName":"db1", "shardingTables":{}, "views":{} } - 验证:打开13306-43306可以发现四个表中都已存在数据。原理:mycat2对建表sql进行拦截,并全局转发到所有数据节点上。
3.2 分库分表–分片表(dbpartition、tbpartition)
关键语法:
dbpartition BY mod_hash(customer_id) tbpartition BY mod_hash(customer_id) tbpartitions 1 dbpartitions 2;
- 建表语句
CREATE TABLE db1.orders( id BIGINT NOT NULL AUTO_INCREMENT, order_type INT, customer_id INT, amount DECIMAL(10,2), PRIMARY KEY(id), KEY id(id) )ENGINE=INNODB DEFAULT CHARSET=utf8 dbpartition BY mod_hash(customer_id) tbpartition BY mod_hash(customer_id) tbpartitions 1 dbpartitions 2; -- dbpartition 设置数据库分片规则;tbpartition 设置表分片规则 -- tbpartitions 1 dbpartitions 2 配置分片数。表分成一片,数据库分成两片(即两个数据库各分1片)注意:这里我在执行的时候遇到了一个问题,就是报错说c0集群can not found。是由于我在之前准备环境的时候准备的c1,和c2。这里我们把c2改成c0即可。 - 插入数据
-- 新增数据 INSERT INTO db1.orders values(1,101,100,2010); INSERT INTO db1.orders values(2,101,100,2020); INSERT INTO db1.orders values(3,101,101,2030); INSERT INTO db1.orders values(4,101,101,2040); INSERT INTO db1.orders values(5,102,101,2050); INSERT INTO db1.orders values(6,102,100,2060); - 查看数据:我们可以看到数据是按照分片键排序的,而不是按照ID排序的。这说明数据是分布在不同是库,然后分别查询拼接起来的。我们打开物理库也可以看到数据分布到了不同的物理表上。
映射关系:`--> mysql db1_0.orders_0 mycat db1.orders `--> mysql db1_1.orders_1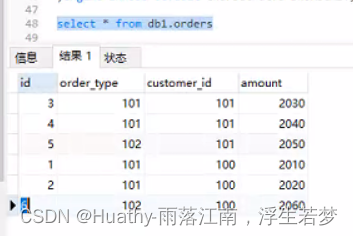
- 查看配置信息
mycat\conf\schemas\db1.schema.json,可见shardingTables中新增了配置信息{ "customTables":{}, "globalTables":{}, "normalProcedures":{}, "normalTables":{}, "schemaName":"db1", "shardingTables":{ "orders":{ "createTableSQL":"/* ApplicationName=DBeaver 22.3.1 - SQLEditor <Script-4.sql> */\nCREATE TABLE db1.orders (\n\tid BIGINT NOT NULL AUTO_INCREMENT,\n\torder_type INT,\n\tcustomer_id INT,\n\tamount DECIMAL(10, 2),\n\tPRIMARY KEY (id),\n\tKEY id (id)\n) ENGINE = INNODB CHARSET = utf8\nDBPARTITION BY mod_hash(customer_id) DBPARTITIONS 2\nTBPARTITION BY mod_hash(customer_id) TBPARTITIONS 1", "function":{ "properties":{ "dbNum":"2", "mappingFormat":"c${targetIndex}/db1_${dbIndex}/orders_${index}", "tableNum":"1", "tableMethod":"mod_hash(customer_id)", "storeNum":2, "dbMethod":"mod_hash(customer_id)" } }, "shardingIndexTables":{} } }, "views":{} }
3.3 分库分表–ER表(自动识别)
- 建表语句:创建orders_detail表,与orders表关联。
-- 这里我们并没有写orders_detail与orders的关系,但是mycat会自动的将这张表与orders分到一个库中。
CREATE TABLE orders_detail(
id BIGINT NOT NULL AUTO_INCREMENT,
detail VARCHAR(2000),
order_id INT,
PRIMARY KEY(id)
)ENGINE=INNODB DEFAULT CHARSET=utf8
dbpartition BY mod_hash(order_id) tbpartition BY mod_hash(order_id)
tbpartitions 1 dbpartitions 2;
- 插入数据
INSERT INTO orders_detail VALUES(1,'1111',1);
INSERT INTO orders_detail VALUES(2,'2222',2);
INSERT INTO orders_detail VALUES(3,'3333',3);
INSERT INTO orders_detail VALUES(4,'4444',4);
INSERT INTO orders_detail VALUES(5,'5555',5);
INSERT INTO orders_detail VALUES(6,'6666',6);
- 验证:查询数据库,并打开物理表可以看到数据分布到了不同的库和表中。
select * from orders o;
id|order_type|customer_id|amount |id0|detail|order_id|
--+----------+-----------+-------+---+------+--------+
1| 101| 100|2010.00| 1|1111 | 1|
2| 101| 100|2020.00| 2|2222 | 2|
3| 101| 101|2030.00| 3|3333 | 3|
4| 101| 101|2040.00| 4|4444 | 4|
5| 102| 101|2050.00| 5|5555 | 5|
6| 102| 100|2060.00| 6|6666 | 6|
- 查询与关联查询:通过查询我们发现orders表与orders_detail表中order_id相同的并没有分布在同一个数据库。
SELECT * FROM orders o ;
SELECT * FROM orders_detail od;
SELECT * FROM orders o
LEFT JOIN orders_detail od ON o.id = od.order_id ;
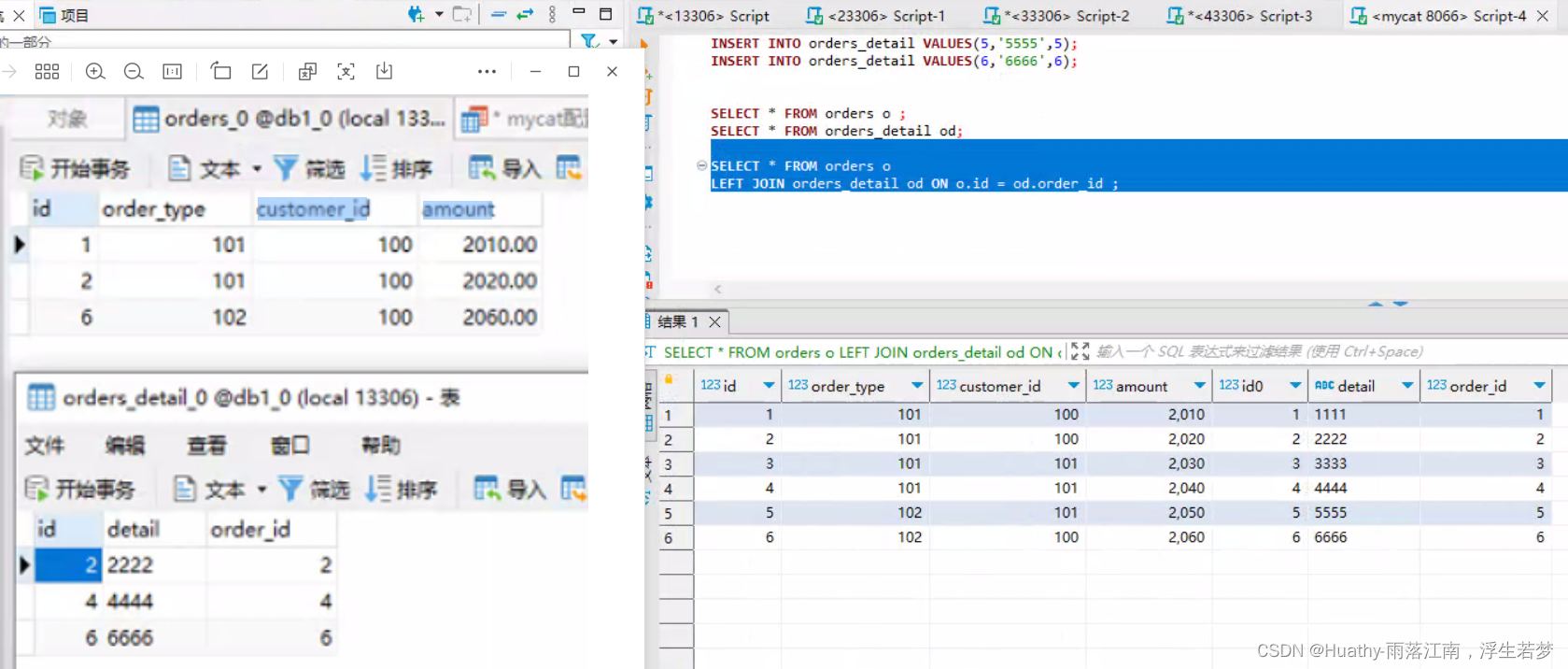
但俩个表具有相同的分片算法,但是分片字段不同。
mycat2在涉及这种两个表join分片字段等价关系的时候可以完成join的下推。
其无需指定ER表,是自动识别的,具体看分片算法的接口。我们可以用/*+ mycat:showErGroup{} */脚本来查看配置的表是否具有ER关系。
其中groupId表示相同的分组,在该分组的表具有相同的存储分布。
/*+ mycat:showErGroup{} */
groupId|schemaName|tableName |
-------+----------+-------------+
0 |db1 |orders |
0 |db1 |orders_detail|
四、常用的分片规则
- 分片算法简介
Mycat2支持常用的(自动)HASH型分片算法也兼容1.6的内置的(cobar)分片算法。
HASH型分片算法默认要求集群名字以c为前缀,数字为后缀,c0就是分片表第一个节点,c1就是第二个节点,该命名规则允许用户手动改变。 - mycat2与1.X版本区别
mycat2的hash型分片算法多基于MOD_HASH,对应Java的%取余运算。
mycat2的hash型分片算法对于值的处理,总是把分片值转换到列属性的数据类型再做计算。
mycat2的hash型分片算法适用于等价条件查询。 - 分片规则与适用性
| 分片算法 | 描述 | 分库 | 分表 | 数值类型 |
|---|---|---|---|---|
| MOD_HASH | 取模哈希 | 是 | 是 | 数值,字符串 |
| UNI_HASH | 取模哈希 | 是 | 是 | 数值,字符串 |
| RIGHT_SHIFT | 右移哈希 | 是 | 是 | 数值 |
| RANGE_HASH | 两字段其一取模 | 是 | 是 | 数值,字符串 |
| YYYYMM | 按年月哈希 | 是 | 是 | DATE,DATETIME |
| YYYYDD | 按年月哈希 | 是 | 是 | DATE,DATETIME |
| YYYYWEEK | 按年周哈希 | 是 | 是 | DATE,DATETIME |
| HASH | 取模哈希 | 是 | 是 | 数值,字符串,如果不是,则转换成字符串 |
| MM | 按月哈希 | 否 | 是 | DATE,DATETIME |
| DD | 按日期哈希 | 否 | 是 | DATE,DATETIME |
| MMDD | 按月日哈希 | 是 | 是 | DATE,DATETIME |
| WEEK | 按周哈希 | 否 | 是 | DATE,DATETIME |
| STR_HASH | 字符串哈希 | 是 | 是 | 字符串 |
常用分片规则简介
MOD_HASH
[数据分片]hash形式的分片算法。如果分片键是字符串,会将字符串hash转换为数值类型。
- 分库键和分表键相同:
- 分表下标:分片值%(分库数量*分表数量)
- 分库下标:分表下表/分库数量
- 分库键和分表键相同:
- 分表下标:分片值%分表数量
- 分库下标:分片值%分库数量
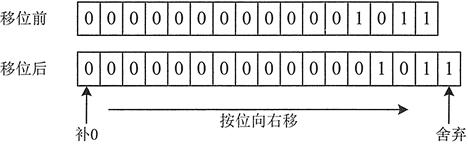
RIGHT_SHIFT
[数据分片]hash形式的分片算法。仅支持数值类型。
分片值右移两位,按分片数量取余。
YYYYMM
[数值分片]hash形式的分片算法。仅用于分库。
(YYYY*12+MM)%分库数量,MM为1–12。
MMDD
仅用于分表。仅DATE、DATETIME类型。
一年之中第几天%分表数。tbpartitions不能超过366。
五、全局序列
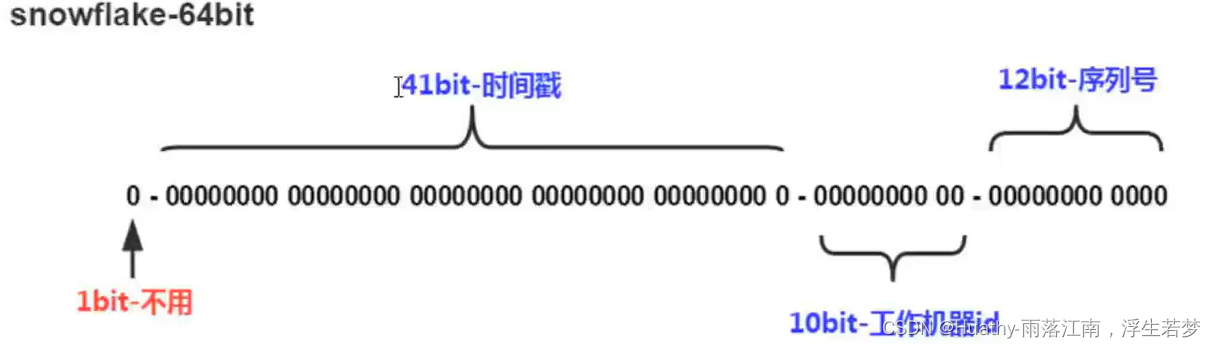
Mycat2默认使用雪花算法作为全局序列。如果不需要mycat默认的全局序列,可以通过配置关闭自动全局序列。
1. 建表语句方式关闭全局序列(AUTO_INCREMENT)
如果不需要自增序列,则修改mycat配置文件中的建表SQL,取消AUTO_INCREMENT关键字即可。需要则配置上即可。
这样mycat则不认为该字段为自增字段,而会交给mysql的自增主键功能补全自增键。
雪花算法:引入了时间戳和ID保持自增的分布式ID生成算法。
2. 设置mycat数据库方式获取全局序列
- 在prototype服务器的db1数据库导入
conf\dbseq.sql文件。
mycat2已经提供了相关sql脚本,需要在对应数据库下运行脚本,但不能通过mycat客户端执行。 - 添加全局序列配置文件
进入mycat\conf\sequences目录,添加配置文件{数据库名}_{表名}.sequence.json
配置如下内容:
{
"clazz": "io.mycat.plug.sequence.SequenceMySQLGenerator",
"name": "db1_tableName",
"targetName": "prototype",
"schemaName": "db1"
}
可选参数targetName更改序列号服务器,targetName是执行自增序列的节点,也是dbseq.sql导入的节点。其导入的当前库的苦命与逻辑表的逻辑库名一致。
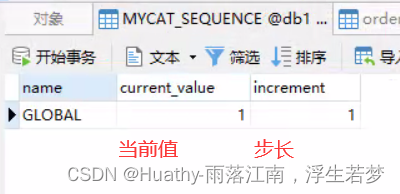
导入后可以检查库下是否有mycat_sequence表。在有多个mycat做集群的时候需要修改increment值,不能严格的让其自增。Name列的值是对应的库名_表名,需要自己设置,即插入一条数据,用于记录序列号。
- 切换为数据库方式全局序列号
在MySQL中执行dbseq.sql,然后执行脚本:
/*+ mycat:setSequence {
"name": "db1_tableName",
"clazz": "io.mycat.plug.sequence.SequenceMySQLGenerator",
"targetName": "prototype",
"schemeName": "db1"
}*/
- 切换为雪花算法方式的全局序列号
/*+ mycat:setSequence {
"name": "db1_tableName",
"time": true
}*/