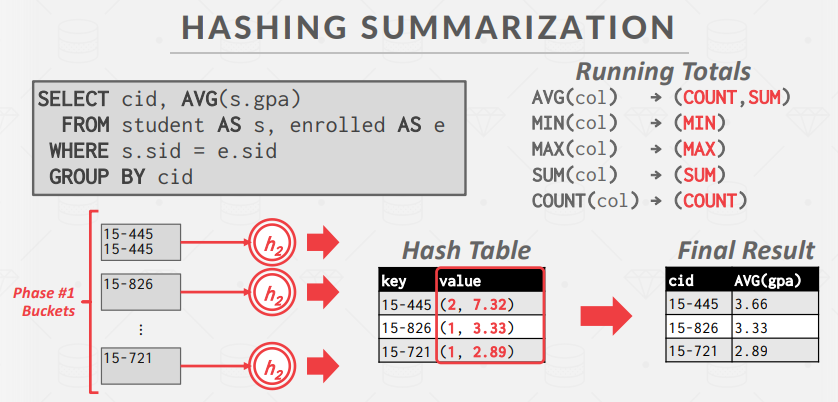
目录
一、Attention原理简介
二、LSTM+Attention文本分类实战
1、数据读取及预处理
2、文本序列编码
3、LSTM文本分类
三、划重点
少走10年弯路
LSTM是一种特殊的循环神经网络(RNN),用于处理序列数据和时间序列数据的建模和预测。而在NLP和时间序列领域上Attention-注意力机制也早已有了大量应用,本文将介绍在LSTM基础上如何添加Attention来优化模型效果。
一、Attention原理简介
注意力机制通过聚焦于重要的信息,忽略不重要的信息,从而有效地处理输入信息。在神经网络中,注意力机制可以帮助模型更好地关注输入中的重要特征,从而提高模型的性能。
简单而言,在文本处理任务中,self-attention对每一个词会随机初始化q、k、v三个向量,用每个词的q向量和其他k向量做点积、再归一化得到这个词的权重向量w,用w给v向量加权求和得到z向量(该词attention之后的向量)。再延伸一点,其实可以初始化多组q、k、v矩阵,从而得到多组z矩阵拼接起来(类似于CNN中的多个卷积核、来提取不同信息),再乘上一个矩阵压缩回原来的维度,得到最终的embedding。
细节原理相对繁琐,推荐大家可以去看一下这篇博客的bert介绍,其中self-attention部分详细且清晰。
https://blog.csdn.net/jiaowoshouzi/article/details/89073944
二、LSTM+Attention文本分类实战
1、数据读取及预处理
import re
import os
from sqlalchemy import create_engine
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
import sklearn
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve,roc_auc_score
import xgboost as xgb
from xgboost.sklearn import XGBClassifier
import lightgbm as lgb
import matplotlib.pyplot as plt
import gc
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras import models
from tensorflow.keras import layers
from tensorflow.keras import optimizers
# 2、数据读取+预处理
data=pd.read_excel('Inshorts Cleaned Data.xlsx')
def data_preprocess(data):
df=data.drop(['Publish Date','Time ','Headline'],axis=1).copy()
df.rename(columns={'Source ':'Source'},inplace=True)
df=df[df.Source.isin(['YouTube','India Today'])].reset_index(drop=True)
df['y']=np.where(df.Source=='YouTube',1,0)
df=df.drop(['Source'],axis=1)
return df
df=data.pipe(data_preprocess)
print(df.shape)
df.head()
# 导入英文停用词
from nltk.corpus import stopwords
from nltk.tokenize import sent_tokenize
stop_english=stopwords.words('english')
stop_spanish=stopwords.words('spanish')
stop_english
# 4、文本预处理:处理简写、小写化、去除停用词、词性还原
from nltk.stem import WordNetLemmatizer
from nltk.corpus import stopwords
from nltk.tokenize import sent_tokenize
import nltk
def replace_abbreviation(text):
rep_list=[
("it's", "it is"),
("i'm", "i am"),
("he's", "he is"),
("she's", "she is"),
("we're", "we are"),
("they're", "they are"),
("you're", "you are"),
("that's", "that is"),
("this's", "this is"),
("can't", "can not"),
("don't", "do not"),
("doesn't", "does not"),
("we've", "we have"),
("i've", " i have"),
("isn't", "is not"),
("won't", "will not"),
("hasn't", "has not"),
("wasn't", "was not"),
("weren't", "were not"),
("let's", "let us"),
("didn't", "did not"),
("hadn't", "had not"),
("waht's", "what is"),
("couldn't", "could not"),
("you'll", "you will"),
("i'll", "i will"),
("you've", "you have")
]
result = text.lower()
for word_replace in rep_list:
result=result.replace(word_replace[0],word_replace[1])
# result = result.replace("'s", "")
return result
def drop_char(text):
result=text.lower()
result=re.sub('[^\w\s]',' ',result) # 去掉标点符号、特殊字符
result=re.sub('\s+',' ',result) # 多空格处理为单空格
return result
def stemed_words(text,stop_words,lemma):
word_list = [lemma.lemmatize(word, pos='v') for word in text.split() if word not in stop_words]
result=" ".join(word_list)
return result
def text_preprocess(text_seq):
stop_words = stopwords.words("english")
lemma = WordNetLemmatizer()
result=[]
for text in text_seq:
if pd.isnull(text):
result.append(None)
continue
text=replace_abbreviation(text)
text=drop_char(text)
text=stemed_words(text,stop_words,lemma)
result.append(text)
return result
df['short']=text_preprocess(df.Short)
df[['Short','short']]
# 5、划分训练、测试集
test_index=list(df.sample(2000).index)
df['label']=np.where(df.index.isin(test_index),'test','train')
df['label'].value_counts()2、文本序列编码
按照词频排序,创建长度为6000的高频词词典、来对文本进行序列化编码。
from tensorflow.keras.preprocessing.text import Tokenizer
def word_dict_fit(train_text_list,num_words):
'''
train_text_list: ['some thing today ','some thing today2']
'''
tok_params={
'num_words':num_words, # 词典的长度,仅保留词频top的num_words个词
'filters':'!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n',
'lower':True,
'split':' ',
'char_level':False,
'oov_token':None, # 设定词典外的词编码
}
tok = Tokenizer(**tok_params) # 分词
tok.fit_on_texts(train_text_list)
return tok
def word_dict_apply_sequences(tok_model,text_list,len_vec):
'''
text_list: ['some thing today ','some thing today2']
'''
list_tok = tok_model.texts_to_sequences(text_list) # 编码映射
pad_params={
'sequences':list_tok,
'maxlen':len_vec, # 补全后向量长度
'padding':'pre', # 'pre' or 'post',在前、在后补全
'truncating':'pre', # 'pre' or 'post',在前、在后删除长度多余的部分
'value':0, # 补全0
}
seq_tok = pad_sequences(**pad_params) # 补全编码向量,返回二维array
return seq_tok
num_words,len_vec = 6000,40
tok_model= word_dict_fit(df[df.label=='train'].short,num_words)
tok_train = word_dict_apply_sequences(tok_model,df[df.label=='train'].short,len_vec)
tok_test = word_dict_apply_sequences(tok_model,df[df.label=='test'].short,len_vec)
tok_test
3、LSTM文本分类
LSTM层的输入是三维张量(batch_size, timesteps, input_dim),所以使用的数据可以是时间序列、也可以是文本数据的embedding;输出设置return_sequences为False,返回尺寸为 (batch_size, units) 的 2D 张量。
'''
LSTM层核心参数
units:输出维度
activation:激活函数
recurrent_activation: RNN循环激活函数
use_bias: 布尔值,是否使用偏置项
dropout:0~1之间的浮点数,神经元失活比例
recurrent_dropout:0~1之间的浮点数,循环状态的神经元失活比例
return_sequences: True时返回RNN全部输出序列(3D),False时输出序列的最后一个输出(2D)
'''
def init_lstm_model(max_features, embed_size):
model = Sequential()
model.add(Embedding(input_dim=max_features, output_dim=embed_size))
model.add(Bidirectional(LSTM(units=32,activation='relu', recurrent_dropout=0.1)))
model.add(Dropout(0.25,seed=1))
model.add(Dense(64))
model.add(Dropout(0.3,seed=1))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
return model
def model_fit(model, x, y,test_x,test_y):
return model.fit(x, y, batch_size=100, epochs=2, validation_data=(test_x,test_y))
embed_size = 128
lstm_model=init_lstm_model(num_words, embed_size)
model_train=model_fit(lstm_model,tok_train,np.array(df[df.label=='train'].y),tok_test,np.array(df[df.label=='test'].y))
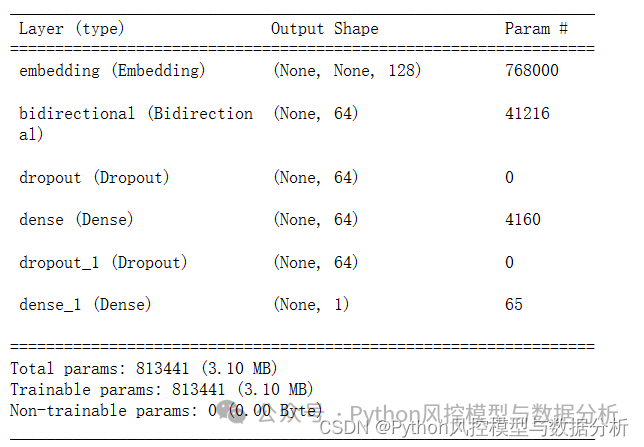
lstm_model.summary()
def model_fit(model, x, y,test_x,test_y):
return model.fit(x, y, batch_size=100, epochs=2, validation_data=(test_x,test_y))
embed_size = 128
lstm_model=init_lstm_model(num_words, embed_size)
model_train=model_fit(lstm_model,tok_train,np.array(df[df.label=='train'].y),tok_test,np.array(df[df.label=='test'].y))
lstm_model.summary()
def ks_auc_value(y_value,y_pred):
fpr,tpr,thresholds= roc_curve(list(y_value),list(y_pred))
ks=max(tpr-fpr)
auc= roc_auc_score(list(y_value),list(y_pred))
return ks,auc
print('train_ks_auc',ks_auc_value(df[df.label=='train'].y,lstm_model.predict(tok_train)))
print('test_ks_auc',ks_auc_value(df[df.label=='test'].y,lstm_model.predict(tok_test)))
'''
train_ks_auc (0.7223217797649937, 0.922939132379851)
test_ks_auc (0.7046603930606234, 0.9140880065296716)
'''4、LSTM+Attention文本分类
在LSTM层之后添加Attention层优化效果。
from tensorflow.keras.models import Model
def init_lstm_model(max_features, embed_size ,embedding_matrix):
input_=layers.Input(shape=(40,))
x=Embedding(input_dim=max_features, output_dim=embed_size,weights=[embedding_matrix],trainable=False)(input_)
x=Bidirectional(layers.LSTM(units=32,activation='relu', recurrent_dropout=0.1,return_sequences=True))(x)
x=layers.Attention(40)([x,x])
x=Dropout(0.25)(x)
x=layers.Flatten()(x)
x=Dense(64)(x)
x=Dropout(0.3)(x)
x=Dense(1,activation='sigmoid')(x)
model = Model(inputs=input_, outputs=x)
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
return model
def model_fit(model, x, y,test_x,test_y):
return model.fit(x, y, batch_size=100, epochs=5, validation_data=(test_x,test_y))
num_words,embed_size = 6000,128
lstm_model2=init_lstm_model(num_words, embed_size ,embedding_matrix)
model_train=model_fit(lstm_model2,tok_train,np.array(df[df.label=='train'].y),tok_test,np.array(df[df.label=='test'].y))
print('train_ks_auc',ks_auc_value(df[df.label=='train'].y,gru_model.predict(tok_train)))
print('test_ks_auc',ks_auc_value(df[df.label=='test'].y,gru_model.predict(tok_test)))
'''
train_ks_auc (0.7126925954159541, 0.9199721561742299)
test_ks_auc (0.7239373279559567, 0.917086274086166)
'''三、划重点
少走10年弯路
关注威信公众号 Python风控模型与数据分析,回复 文本分类5 获取本篇数据及代码
还有更多理论、代码分享等你来拿