在快速发展的人工智能领域中,高效、有效地使用大型语言模型变得日益重要,参数高效微调是这一追求的前沿技术,它允许研究人员和实践者在最小化计算和资源占用的同时,重复使用预训练模型。这还使我们能够在更广泛的硬件范围内训练AI模型,包括计算能力有限的设备,如笔记本电脑、智能手机和物联网设备。
本文解释了微调的广义概念,并讨论了流行的参数高效微调方法,如Prefix Tuning和Adapter。最后,我们将关注最新的LLaMA-Adapter方法,并探讨其实际应用。
1. 大语言模型的微调
自GPT-2和GPT-3以来,我们已经看到,预训练在通用文本语料库上的生成性大型语言模型(LLM)能够进行上下文学习,这不需要我们进一步训练或微调预训练的LLM,就能执行LLM未显式训练过的特定或新任务。相反,我们可以直接通过输入提示提供目标任务的一些示例,如下面的例子所示。

上下文学习是一种用户友好的方法,适用于直接访问大型语言模型(LLM)受限的情况,比如通过API或用户界面与LLM交互时。
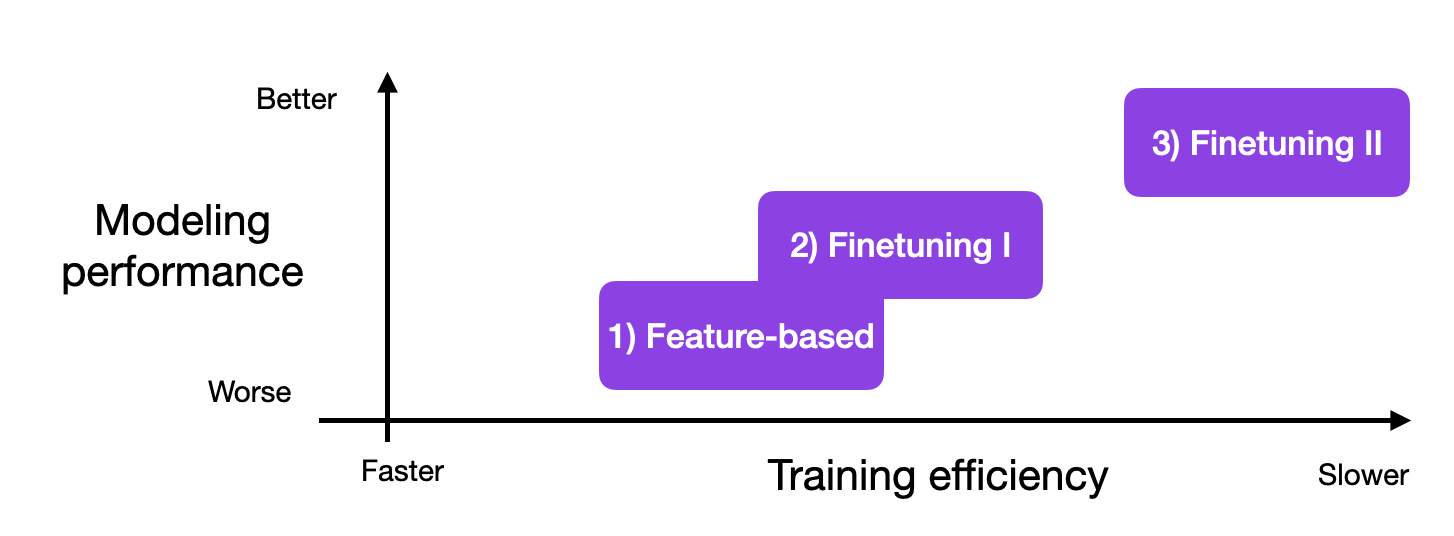
然而,如果我们能够访问LLM,在目标领域的数据上对其进行适应和微调,通常会带来更好的结果。那么,我们如何使模型适应特定任务呢?下面的图表概述了三种常规的方法。

上述方法适用于生成式(解码器风格)模型,如GPT,以及重点关注嵌入的(编码器风格)模型,如BERT。与这三种方法相比,上下文学习只适用于生成式模型。值得强调的是,当我们对生成式模型进行微调时,我们使用并构建它们创建的嵌入,而不是生成的输出文本。
2. Feature-based: 基于特征的方法
在基于特征的方法中,我们加载一个预训练的LLM,并将其应用于我们的目标数据集。在这里,我们特别感兴趣的是为训练集生成输出嵌入,我们可以将其用作训练分类模型的输入特征。虽然这种方法对于重点关注嵌入的BERT来说特别常见,但我们也可以从生成式GPT风格模型中提取嵌入。
然后,分类模型可以是逻辑回归模型、随机森林或XGBoost —— 任何我们心之所向的模型。
从概念上讲,我们可以用以下代码来说明基于特征的方法:
model = AutoModel.from_pretrained("distilbert-base-uncased")
# ...
# tokenize dataset
# ...
# generate embeddings
@torch.inference_mode()
def get_output_embeddings(batch):
output = model(
batch["input_ids"],
attention_mask=batch["attention_mask"]
).last_hidden_state[:, 0]
return {"features": output}
dataset_features = dataset_tokenized.map(
get_output_embeddings, batched=True, batch_size=10)
X_train = np.array(dataset_features["train"]["features"])
y_train = np.array(dataset_features["train"]["label"])
X_val = np.array(dataset_features["validation"]["features"])
y_val = np.array(dataset_features["validation"]["label"])
X_test = np.array(dataset_features["test"]["features"])
y_test = np.array(dataset_features["test"]["label"])
# train classifier
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression()
clf.fit(X_train, y_train)
print("Training accuracy", clf.score(X_train, y_train))
print("Validation accuracy", clf.score(X_val, y_val))
print("test accuracy", clf.score(X_test, y_test))3. 微调 I —— 更新输出层
一种与上述基于特征的方法相关的流行方法是微调输出层(我们将其称为微调 I)。类似于基于特征的方法,我们保持预训练LLM的参数不变。我们只训练新添加的输出层,类似于在嵌入特征上训练逻辑回归分类器或小型多层感知器。
在代码中,这看起来如下所示:
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased",
num_labels=2 # suppose target task is a binary classification task
)
# freeze all layers
for param in model.parameters():
param.requires_grad = False
# then unfreeze the two last layers (output layers)
for param in model.pre_classifier.parameters():
param.requires_grad = True
for param in model.classifier.parameters():
param.requires_grad = True
# finetune model
lightning_model = CustomLightningModule(model)
trainer = L.Trainer(
max_epochs=3,
...
)
trainer.fit(
model=lightning_model,
train_dataloaders=train_loader,
val_dataloaders=val_loader)
# evaluate model
trainer.test(lightning_model, dataloaders=test_loader)理论上,由于我们使用相同的冻结骨架模型,这种方法在建模性能和速度方面应该与基于特征的方法表现相似。然而,由于基于特征的方法更容易预先计算并存储训练数据集的嵌入特征,因此在特定的实际情况下,基于特征的方法可能更方便。
4. 微调 II —— 更新所有层
虽然原始的BERT论文报告称,只微调输出层就可以实现与微调所有层相当的建模性能,但后者涉及更多参数,因此成本显著更高。例如,BERT基础模型大约有1.1亿个参数。然而,用于二元分类的BERT基础模型的最后一层仅包含大约1,500个参数。此外,BERT基础模型的最后两层占据了60,000个参数——仅占总模型大小的大约0.6%。
根据我们的目标任务和目标领域与模型预训练的数据集的相似性,我们的实际效果会有所不同。但在实践中,微调所有层几乎总是能带来更优秀的建模性能。
因此,当优化建模性能时,使用预训练LLM的黄金标准是更新所有层(这里称为微调 II)。从概念上讲,微调 II 与微调 I 非常相似。唯一的区别是我们不冻结预训练LLM的参数,而是同样对它们进行微调:
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased",
num_labels=2 # suppose target task is a binary classification task
)
# don't freeze layers
# for param in model.parameters():
# param.requires_grad = False
# finetune model
lightning_model = LightningModel(model)
trainer = L.Trainer(
max_epochs=3,
...
)
trainer.fit(
model=lightning_model,
train_dataloaders=train_loader,
val_dataloaders=val_loader)
# evaluate model
trainer.test(lightning_model, dataloaders=test_loader)如果你对一些真实世界的结果感兴趣,上面的代码片段被用来训练一个电影评论分类器,使用的是预训练的DistilBERT基础模型:
- 基于特征的方法与逻辑回归:83%的测试准确率
- 微调 I,更新最后2层:87%的准确率
- 微调 II,更新所有层:92%的准确率。
这些结果与一般的经验法则相一致:微调更多层通常会带来更好的性能,但代价也更高。
5. 参数高效微调
在前面的部分中,我们了解到微调更多层通常会带来更好
的结果。现在,上述实验是基于DistilBERT模型进行的,这是一个相对较小的模型。如果我们想微调更大的模型,比如那些刚好能够适应GPU内存的最新生成型LLM呢?当然,我们可以使用上述的基于特征或微调 I 方法。但假设我们想获得与微调 II 类似的建模质量?
多年来,研究人员开发了几种技术,在只需要训练少量参数的同时,能够对LLM进行高性能的微调。这些方法通常被称为参数高效微调技术(PEFT)。
以下是一些最广泛使用的PEFT技术的总结。
最近引起巨大反响的一种PEFT技术是LLaMA-Adapter,它是为Meta的流行LLaMA模型提出的——然而,尽管LLaMA-Adapter是在LLaMA的背景下提出的,但这个想法是与模型无关的。
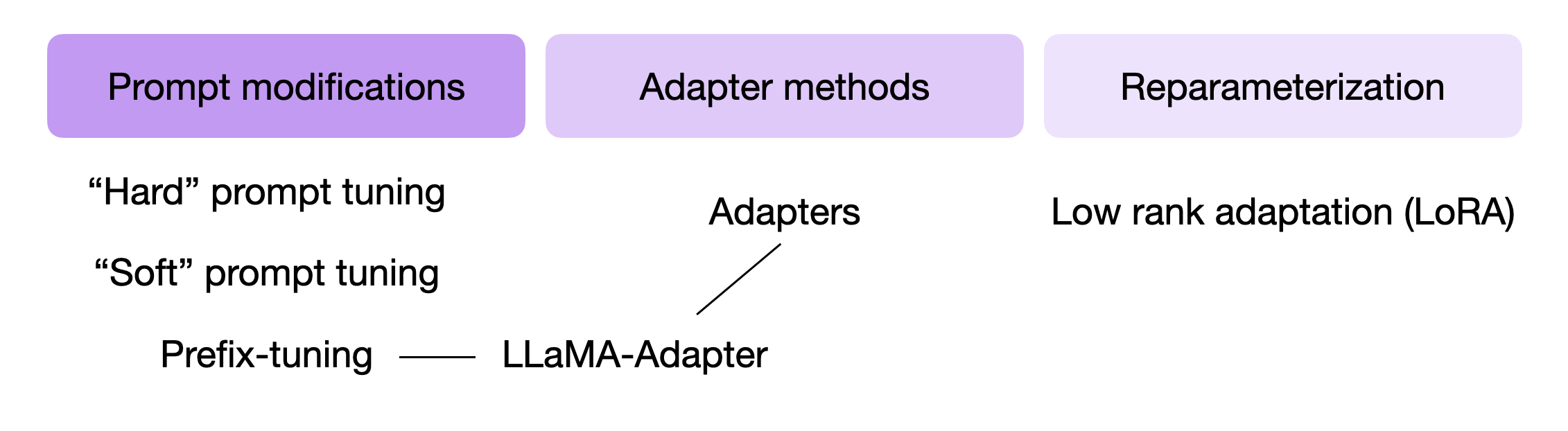
要理解LLaMA-Adapter是如何工作的,我们需要稍微回顾一下两种相关技术,即Prefix Tuning(前缀调整)和Adapter——LLaMA-Adapter结合并扩展了这两种想法。
因此,在本文的剩余部分中,我们将讨论各种提示修改的概念,以理解前缀调整和Adapter方法,然后我们将更仔细地看一下LLaMA-Adapter。
6. 前缀调整和提示调整
最初的Prompt Tuning(提示调整)概念是指通过改变输入提示来获得更好建模结果的技术。例如,假设我们有兴趣将一个英语句子翻译成德语。我们可以用不同的方式询问模型,如下所示。
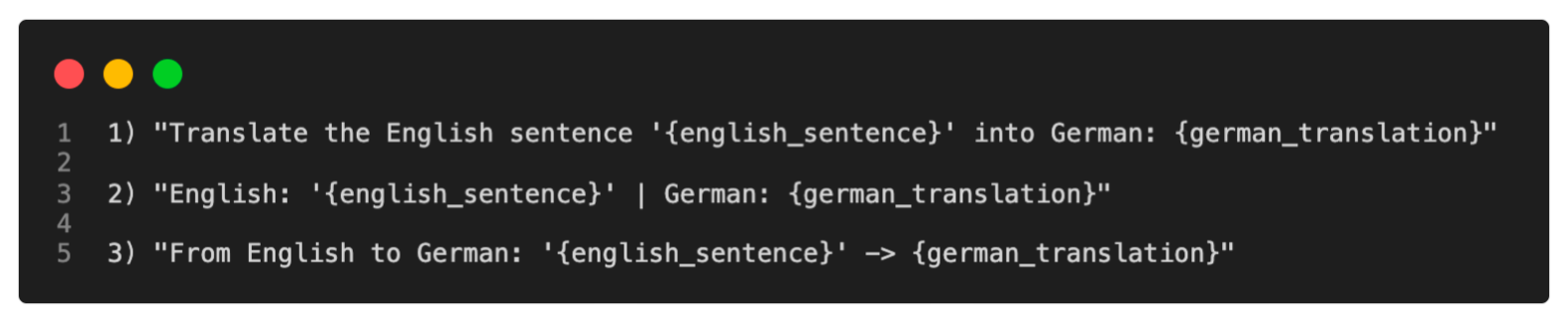
上面示例中所展示的概念被称为硬提示调整,因为我们直接改变了不可微分的离散输入令牌。
与硬提示调整相对的是软提示调整,它将输入令牌的嵌入与可通过反向传播进行优化的可训练张量连接起来,以提高目标任务的建模性能。
提示调整的一种特定形式是前缀调整。前缀调整的思想是在每个Transformer块中添加一个可训练张量,而不是仅在输入嵌入中,就像软提示调整那样。下图展示了普通Transformer块和添加了前缀的Transformer块之间的区别。
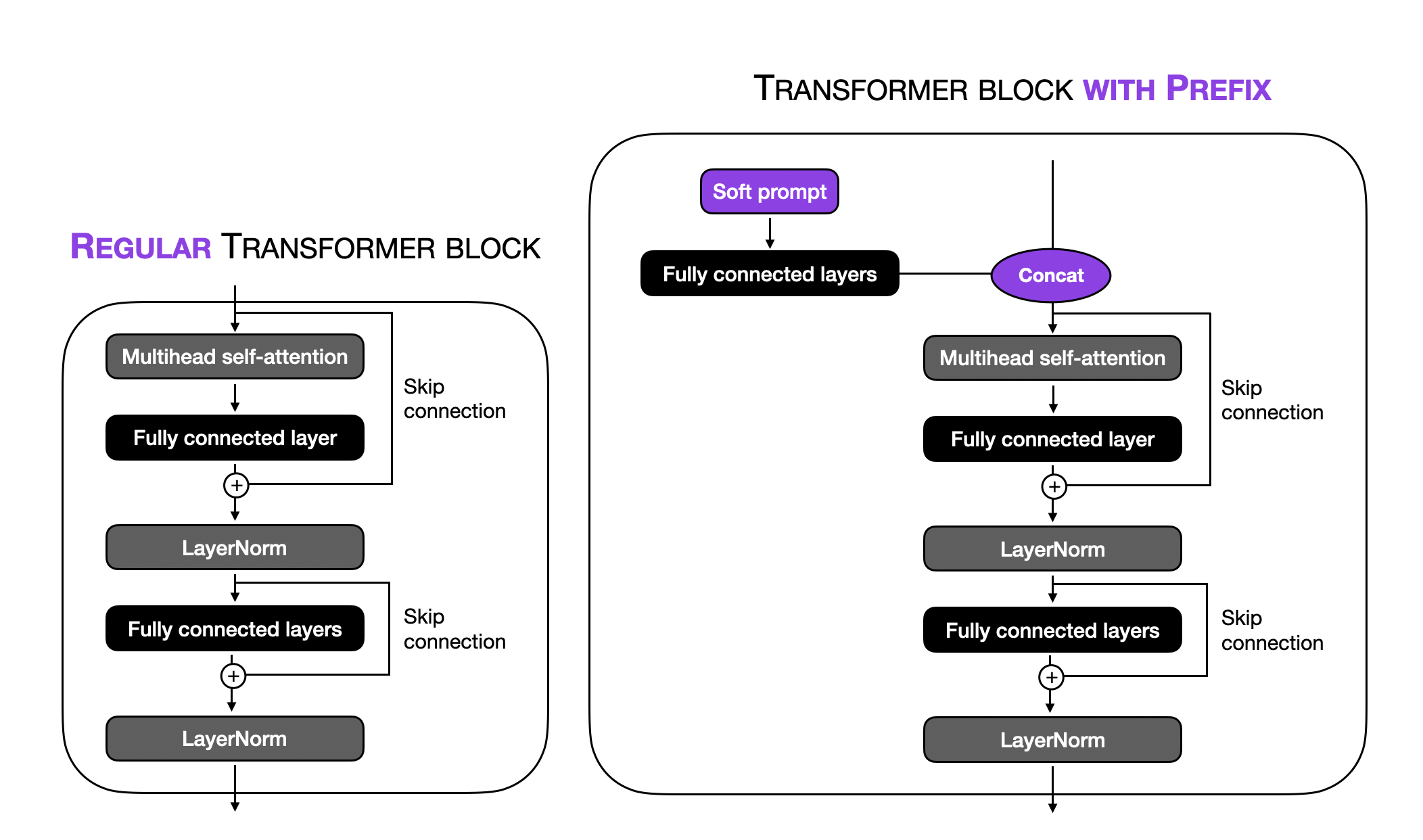
请注意,在上图中,“全连接层”指的是一个小型多层感知器(两个全连接层之间有一个非线性激活函数)。这些全连接层将软提示嵌入到与Transformer块输入相同维度的特征空间中,以确保连接的兼容性。
使用(Python)伪代码,我们可以如下展示普通Transformer块和添加了前缀的Transformer块之间的区别:
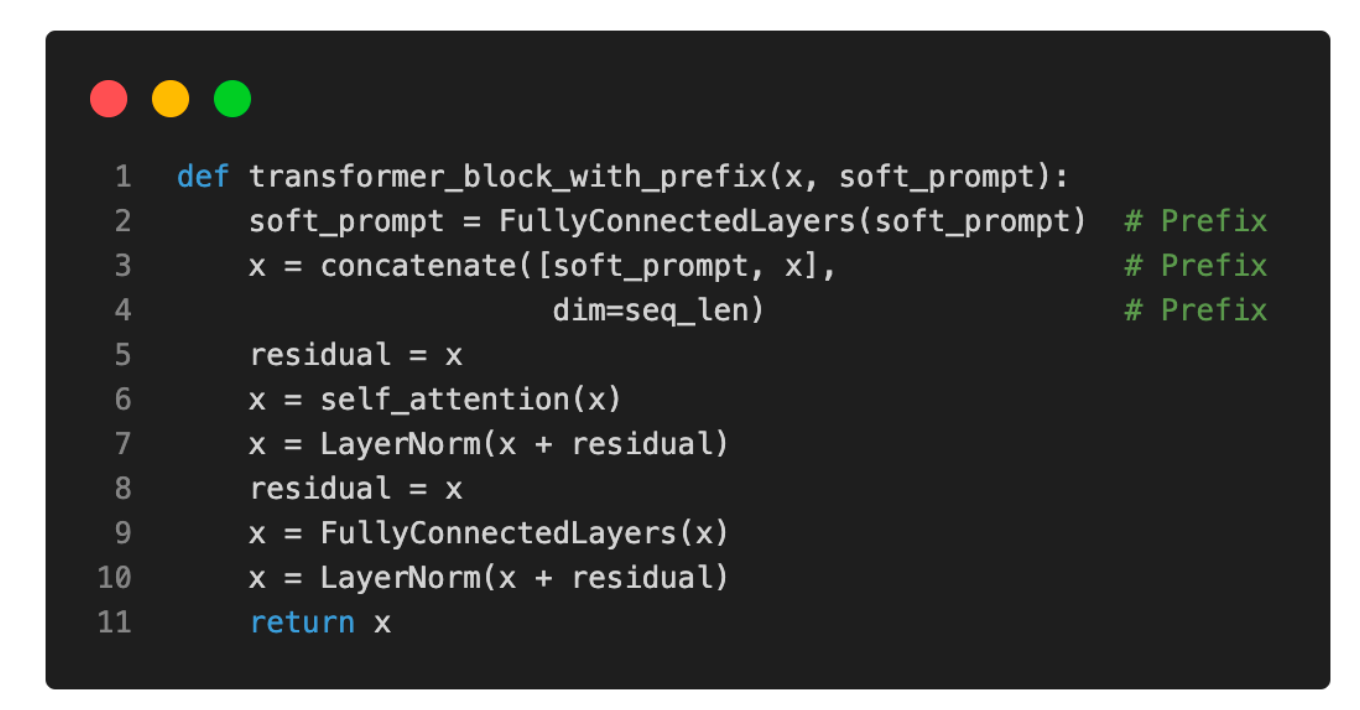
根据原始的前缀调整论文,前缀调整在仅需训练0.1%的参数的情况下,就能达到与微调所有层相当的建模性能——这些实验是基于GPT-2模型进行的。此外,在许多情况下,前缀调整甚至优于所有层的微调,这很可能是因为涉及的参数更少,有助于减少对较小目标数据集的过拟合。
最后,为了澄清在推理过程中软提示的使用:在学习了软提示后,我们必须在执行微调模型的特定任务时,将其作为前缀提供。这允许模型针对那个特定任务定制其响应。此外,我们可以有多个软提示,每个对应一个不同的任务,并在推理期间提供适当的前缀,以实现特定任务的最佳结果。
7. Adapter
原始的Adapter方法与上述的前缀调整有些相关,因为它们也在每个Transformer块中添加额外的参数。然而,Adapter方法并不是在输入嵌入前添加前缀,而是在两个位置添加Adapter层,如下图所示。

对于喜欢(Python)伪代码的读者,Adapter层可以写成如下:
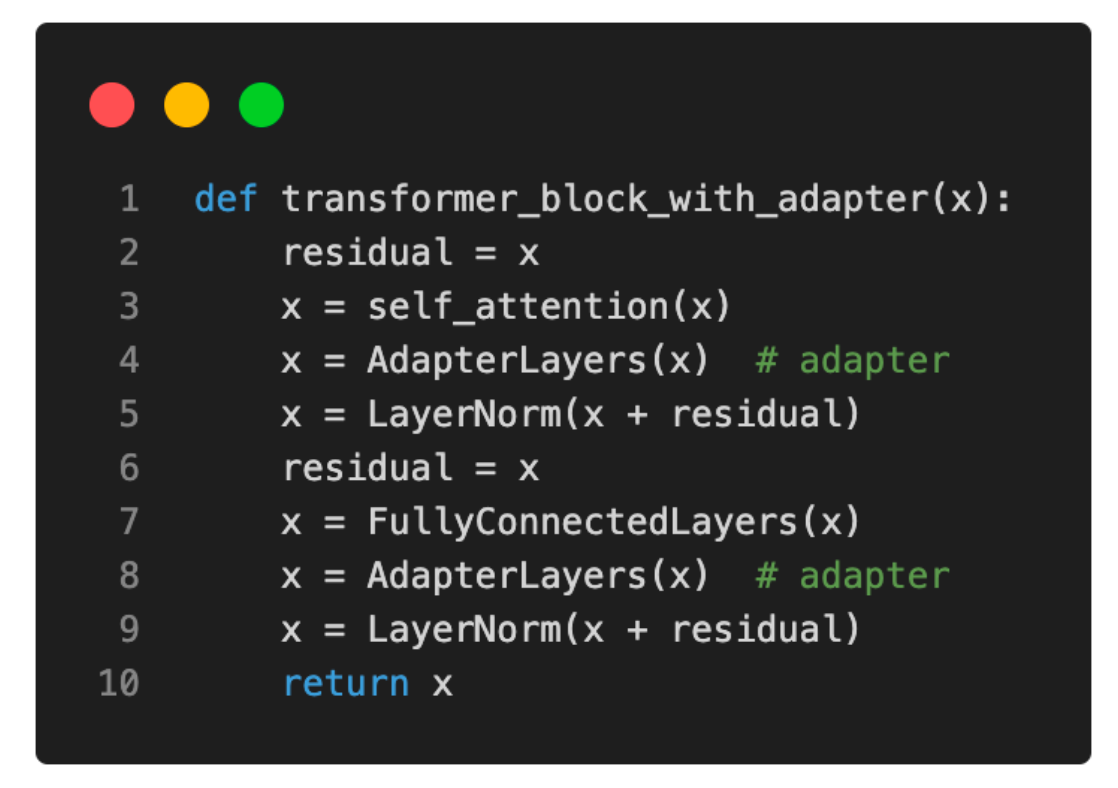
请注意,Adapter的全连接层通常相对较小,并具有类似于自动编码器的瓶颈结构。每个Adapter块的第一个全连接层将输入投射到低维表示上。第二个全连接层将输入重新投射回输入维度。这如何做到参数高效呢?例如,假设第一个全连接层将1024维的输入投射到24维,第二个全连接层再将其投射回1024维。这意味着我们引入了1024 x 24 + 24 x 1024 = 49,152个权重参数。相比之下,单个全连接层将1024维输入重新投射到1024维空间中,将拥有1024 x 1024 = 1,048,576个参数。
根据原始Adapter论文,使用Adapter方法训练的BERT模型达到了与完全微调的BERT模型相当的建模性能,同时仅需要训练3.6%的参数。
现在,问题是Adapter方法与前缀调整相比如何。根据原始的前缀调整论文,当微调模型总参数的0.1%时,Adapter方法的表现略低于前缀调整方法。然而,当Adapter方法用于微调模型参数的3%时,该方法与微调0.1%模型参数的前缀调整方法不相上下。因此,我们可能会得出结论,前缀调整方法是这两种中更高效的一种。
8. LLaMA-Adapter:扩展前缀调整和Adapter
在前缀调整和原始Adapter方法的思想基础上,研究人员最近提出了LLaMA-Adapter,这是一种针对Meta的流行GPT替代品LLaMA的参数高效微调方法。
与前缀调整类似,LLaMA-Adapter方法在嵌入输入之前添加了可调节的提示张量。值得注意的是,在LLaMA-Adapter方法中,前缀是在嵌入表中学习和维护的,而不是外部提供的。模型中的每个Transformer块都有自己独特的学习前缀,允许在不同模型层中进行更有针对性的调整。
此外,LLaMA-Adapter引入了一个零初始化的注意力机制,结合门控。这种所谓的零初始化注意力和门控背后的动机是,Adapter和前缀调整可能通过引入随机初始化的张量(前缀提示或Adapter层)来扰乱预训练LLM的语言知识,导致微调不稳定和在初始训练阶段高损失值。
与前缀调整和原始Adapter方法相比,LLaMA-Adapter的另一个区别是,它仅在最顶层的L个Transformer层中添加了可学习的适应提示,而不是在所有Transformer层中。作者认为,这种方法能够更有效地调整语言表示,专注于更高层次的语义信息。
虽然LLaMAAdapter方法的基本思想与前缀调整相关(添加可调节的软提示),但在实现上有一些额外的、微妙的区别。例如,只有自注意力输入的键和值序列通过可调节的软提示进行修改。然后,根据门控因子(在训练开始时设置为零),决定是否使用经过前缀修改的注意力。以下视觉化展示了这一概念。

在伪代码中,我们可以将其表达如下:
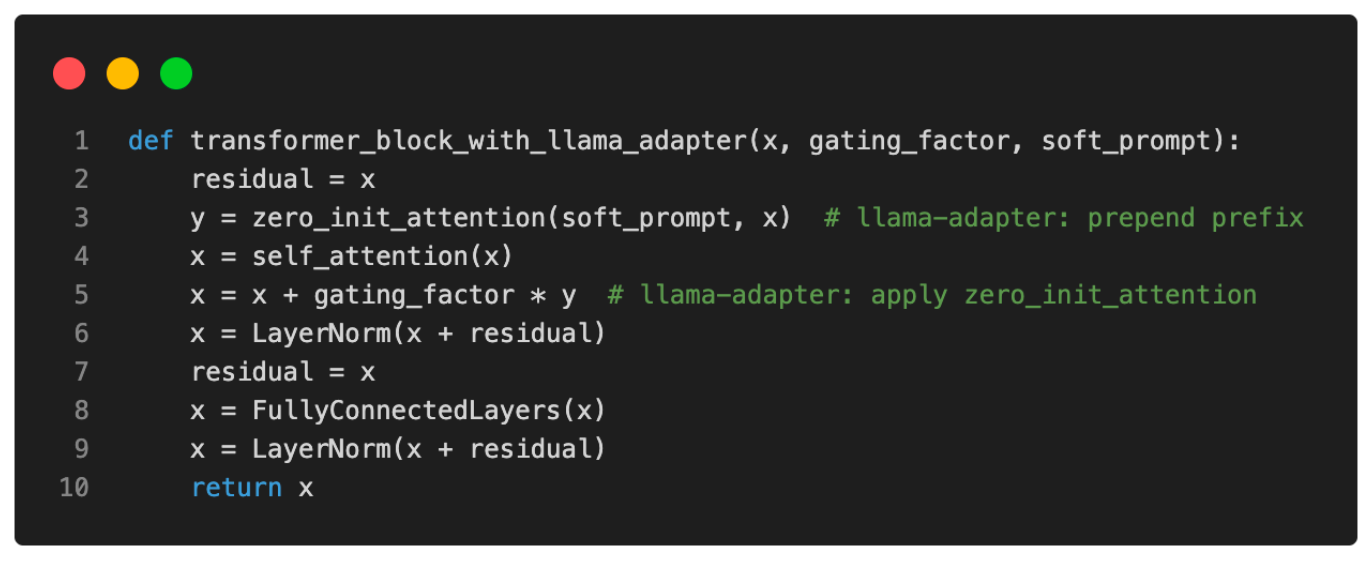
简而言之,LLaMA-Adapter与常规前缀调整的区别在于LLaMA-Adapter仅修改顶层(即前几个)Transformer块,并引入了门控机制以稳定训练。尽管研究人员特别对LLaMA进行了实验,但他们提出的Adapter方法是一种通用方法,也可以应用于其他类型的LLM(如GPT)。
使用LLaMA-Adapter方法,研究人员能够在仅1小时内(使用八个A100 GPU)对一个包含52k指令对的数据集上微调7亿参数的LLaMA模型。此外,在这项研究中比较的所有其他模型中,经过微调的LLaMA-Adapter模型在问答任务上表现最佳,而只需要微调1.2M参数(Adapter层)。
9. 结论
微调预训练的大型语言模型(LLM)是一种有效的方法,可以使这些模型适应特定的业务需求并与目标领域数据对齐。这一过程涉及使用与所需领域相关的较小数据集调整模型参数,使模型能够学习领域特定的知识和词汇。
然而,由于LLM“大”,在Transformer模型中更新多个层可能非常昂贵,因此研究人员开始开发参数高效的替代方案。
在本文中,我们讨论了几种参数高效的替代常规LLM微调机制的方法。特别是,我们介绍了通过前缀调整添加可调节软提示和插入额外Adapter层。
最后,我们讨论了最近流行的LLaMA-Adapter方法,该方法添加了可调节软提示并引入了额外的门控机制以稳定训练。
原文链接:链接