第三部分:实现系统
原文:Part III. Implementing Systems
译者:飞龙
协议:CC BY-NC-SA 4.0
一旦您分析并设计了您的系统,就该是实现计划的时候了。在某些情况下,实现可能意味着购买现成的解决方案。第十一章提供了谷歌在决定构建定制软件解决方案时的思考过程的一个例子。
本书的第三部分着重于在软件开发生命周期的实现阶段集成安全性和可靠性。第十二章重申了框架将简化您的系统的观念。在测试过程中添加静态分析和模糊测试,正如第十三章所描述的那样,将加固代码。第十四章讨论了为什么您还应该投资于可验证的构建和进一步的控制——如果对手能够绕过它们达到您的生产环境,那么围绕编码、构建和测试的保障措施的效果将受到限制。
即使您的整个软件供应链对安全性和可靠性故障具有弹性,当问题出现时,您仍然需要分析您的系统。第十五章讨论了您必须在授予适当的调试访问权限和存储和访问日志的安全要求之间保持谨慎平衡。
第十一章:案例研究:设计、实现和维护公信 CA
原文:11. Case Study: Designing, Implementing, and Maintaining a Publicly Trusted CA
译者:飞龙
协议:CC BY-NC-SA 4.0
作者:Andy Warner、James Kasten、Rob Smits、Piotr Kucharski 和 Sergey Simakov
公信证书颁发机构的背景
公信证书颁发机构通过为传输层安全性(TLS)、S/MIME 等常见的分布式信任场景颁发证书,充当互联网传输层的信任锚点。它们是浏览器、操作系统和设备默认信任的 CA 集合。因此,编写和维护一个公信 CA 引发了许多安全性和可靠性考虑。
要成为公信并保持这一地位,CA 必须通过跨不同平台和用例的一系列标准。至少,公信 CA 必须接受诸如WebTrust和欧洲电信标准化协会(ETSI)等组织设定的标准的审计。公信 CA 还必须满足CA/Browser 论坛基线要求的目标。这些评估评估逻辑和物理安全控制、程序和实践,一个典型的公信 CA 每年至少花费四分之一的时间进行这些审计。此外,大多数浏览器和操作系统都有自己独特的要求,CA 必须在被默认信任之前满足这些要求。随着要求的变化,CA 需要适应并愿意进行流程或基础设施的变更。
你的组织很可能永远不需要构建一个公信 CA——大多数组织依赖第三方获取公共 TLS 证书、代码签名证书和其他需要用户广泛信任的证书。考虑到这一点,本案例研究的目标不是向您展示如何构建一个公信 CA,而是强调我们的一些发现可能与您环境中的项目产生共鸣。主要的收获包括以下内容:
-
我们选择的编程语言以及在处理第三方生成的数据时使用分段或容器使整体环境更加安全。
-
严格测试和加固代码——无论是我们自己生成的代码还是第三方代码——对于解决基本的可靠性和安全性问题至关重要。
-
当我们在设计中减少复杂性并用自动化替换手动步骤时,我们的基础设施变得更安全、更可靠。
-
了解我们的威胁模型使我们能够构建验证和恢复机制,使我们能够更好地提前为灾难做准备。
我们为什么需要一个公信 CA?
随着时间的推移,我们对公信 CA 的业务需求发生了变化。在谷歌早期,我们从第三方 CA 购买了所有的公共证书。这种方法存在三个固有问题,我们希望解决:
依赖第三方
业务需求需要高度的信任——例如,向客户提供云服务——这意味着我们需要对证书的发放和处理进行强有力的验证和控制。即使我们在 CA 生态系统中进行了强制性的审计,我们仍然不确定第三方是否能够达到高标准的安全性。公信 CA 中的显著安全漏洞巩固了我们对安全性的看法。
自动化的需求
谷歌拥有成千上万的公司拥有的域名,为全球用户提供服务。作为我们普遍的 TLS 工作的一部分(参见“示例:增加 HTTPS 使用率”),我们希望保护我们拥有的每个域,并经常更换证书。我们还希望为客户提供获取 TLS 证书的简便方法。自动获取新证书很困难,因为第三方公信 CA 通常没有可扩展的 API,或者提供的 SLA 低于我们的需求。因此,这些证书的请求过程很大程度上涉及容易出错的手动方法。
成本
考虑到谷歌想要为自己的网络属性和客户代表使用数百万个 TLS 证书,成本分析显示,与继续从第三方根 CA 获取证书相比,设计、实现和维护我们自己的 CA 将更具成本效益。
建设或购买决策
一旦谷歌决定要运营一个公信 CA,我们就必须决定是购买商业软件来运营 CA,还是编写我们自己的软件。最终,我们决定自己开发 CA 的核心部分,并在必要时集成开源和商业解决方案。在许多决定因素中,这个决定背后有一些主要的动机:
透明度和验证
CA 的商业解决方案通常没有我们对代码或供应链的审计能力,这是我们对于如此关键的基础设施所需的。尽管它与开源库集成并使用了一些第三方专有代码,但编写和测试我们自己的 CA 软件使我们对正在构建的系统更加有信心。
集成能力
我们希望通过与谷歌的安全关键基础设施集成,简化 CA 的实现和维护。例如,我们可以在Spanner中的配置文件中设置定期备份。
灵活性
更广泛的互联网社区正在开发新的倡议,以提高生态系统的安全性。证书透明度——一种监视和审计证书的方式——以及使用 DNS、HTTP 和其他方法进行域验证⁵是两个典型的例子。我们希望成为这类倡议的早期采用者,自定义 CA 是我们能够迅速增加这种灵活性的最佳选择。
设计、实现和维护考虑
为了保护我们的 CA,我们创建了一个三层分层架构,其中每一层负责发行过程的不同部分:证书请求解析、注册机构功能(路由和逻辑)和证书签发。每一层都由具有明确定义责任的微服务组成。我们还设计了一个双信任区域架构,其中不受信任的输入在不同的环境中处理关键操作。这种分割创建了精心定义的边界,促进了可理解性和审查的便利。该架构还使得发动攻击更加困难:由于组件的功能受到限制,攻击者如果获得对特定组件的访问权限,也将受到功能受限的限制。要获得额外的访问权限,攻击者必须绕过额外的审计点。
每个微服务都是以简单性作为关键原则进行设计和实现的。在 CA 的整个生命周期中,我们不断地以简单性为考量对每个组件进行重构。我们对代码(包括内部开发和第三方)和数据进行严格的测试和验证。当需要提高安全性时,我们还会对代码进行容器化。本节详细描述了我们通过良好的设计和实现选择来解决安全性和可靠性的方法。
编程语言选择
对于接受任意不受信任输入的系统部分的编程语言选择是设计的一个重要方面。最终,我们决定用 Go 和 C++的混合编写 CA,并根据其目的选择使用哪种语言来处理每个子组件。Go 和 C++都可以与经过充分测试的加密库进行互操作,表现出优异的性能,并拥有强大的生态系统框架和工具来实现常见任务。
由于 Go 是内存安全的,它在处理 CA 处理任意输入时具有一些额外的安全优势。例如,证书签名请求(CSR)代表 CA 的不受信任输入。CSR 可能来自我们内部系统中的一个,这可能相对安全,也可能来自互联网用户(甚至是恶意行为者)。代码中解析 DER(用于证书的编码格式)的代码存在与内存相关的漏洞的悠久历史,因此我们希望使用一种提供额外安全性的内存安全语言。Go符合要求。
C++不是内存安全的,但对于系统的关键子组件具有良好的互操作性,特别是对于谷歌核心基础设施的某些组件。为了保护这些代码,我们在安全区域中运行它,并在数据到达该区域之前验证所有数据。例如,对于 CSR 处理,我们在 Go 中解析请求,然后将其传递给 C++子系统进行相同的操作,然后比较结果。如果存在差异,则不进行处理。
此外,我们在所有 C++代码的提交前强制执行良好的安全实践和可读性,谷歌的集中式工具链实现了各种编译时和运行时缓解措施。这些包括以下内容:
W^X
通过复制 shellcode 并跳转到该内存来破坏mmap和PROT_EXEC的常见利用技巧。这种缓解措施不会造成 CPU 或内存性能损失。
Scudo Allocator
用户模式安全堆分配器。
SafeStack
一种安全缓解技术,可防范基于堆栈缓冲区溢出的攻击。
复杂性与可理解性
作为一种防御措施,我们明确选择实现 CA 的功能有限,与标准中提供的完整选项相比(参见“设计可理解的系统”)。我们的主要用例是为具有常用属性和扩展的标准 Web 服务颁发证书。我们对商业和开源 CA 软件选项的评估显示,它们试图适应我们不需要的奇特属性和扩展导致了系统的复杂性,使软件难以验证且更容易出错。因此,我们选择编写具有有限功能和更好可理解性的 CA,以便更容易审计预期的输入和输出。
我们不断努力简化 CA 的架构,使其更易于理解和维护。有一次,我们意识到我们的架构创建了太多不同的微服务,导致维护成本增加。虽然我们希望获得模块化服务和明确定义的边界的好处,但我们发现将系统的某些部分合并更简单。在另一种情况下,我们意识到我们对 RPC 调用的 ACL 检查是在每个实例中手动实现的,这为开发人员和审阅人员出现错误提供了机会。我们重构了代码库,以集中 ACL 检查并消除添加新的 RPC 而不使用 ACL 的可能性。
保护第三方和开源组件
我们的自定义 CA 依赖于第三方代码,即开源库和商业模块。我们需要验证、加固和容器化这些代码。作为第一步,我们专注于 CA 使用的几个众所周知且广泛使用的开源软件包。即使是在安全环境中广泛使用的开源软件包,也可能来自具有强大安全背景的个人或组织,也容易受到漏洞的影响。我们对每个软件包进行了深入的安全审查,并提交了修补程序以解决我们发现的问题。在可能的情况下,我们还将所有第三方和开源组件都提交到下一节详细介绍的测试制度中。
我们使用两个安全区域——一个用于处理不受信任的数据,另一个用于处理敏感操作——也为我们提供了一些分层保护,以防止错误或恶意插入到代码中。前面提到的 CSR 解析器依赖于开源 X.509 库,并作为 Borg 容器中不受信任区域的微服务运行。这为这段代码提供了额外的保护层。
我们还必须保护专有的第三方闭源代码。运行一个公开可信的 CA 需要使用硬件安全模块(HSM)——由商业供应商提供的专用加密处理器——作为保护 CA 密钥的保险库。我们希望为与 HSM 交互的供应商提供的代码提供额外的验证层。与许多供应商提供的解决方案一样,我们可以进行的测试种类有限。为了保护系统免受内存泄漏等问题的影响,我们采取了以下步骤:
-
我们构建了必须与 HSM 库进行交互的 CA 的部分,采取了防御性措施,因为我们知道输入或输出可能存在风险。
-
我们在nsjail中运行第三方代码,这是一个轻量级的进程隔离机制。
-
我们向供应商报告了我们发现的问题。
测试
为了保持项目的卫生,我们编写单元测试和集成测试(见第十三章)来覆盖各种场景。团队成员应在开发过程中编写这些测试,而同行评审则确保遵守这一做法。除了测试预期行为外,我们还测试负面情况。每隔几分钟,我们生成符合良好标准的测试证书签发条件,以及包含严重错误的条件。例如,我们明确测试了当未经授权的人员进行签发时,准确的错误消息是否会触发警报。拥有正面和负面测试条件的存储库使我们能够非常快速地对所有新的 CA 软件部署进行高可信度的端到端测试。
通过使用谷歌的集中式软件开发工具链,我们还获得了在提交前和构建后的集成自动代码测试的好处。正如在“将静态分析集成到开发人员工作流程中”中讨论的那样,谷歌所有的代码更改都经过 Tricorder,我们的静态分析平台的检查。我们还对 CA 的代码进行各种消毒剂的检查,如 AddressSanitizer(ASAN)和 ThreadSanitizer,以识别常见错误(见“动态程序分析”)。此外,我们对 CA 代码进行有针对性的模糊测试(见“模糊测试”)。
CA 密钥材料的弹性
CA 面临的最严重风险是 CA 密钥材料的盗窃或滥用。公开可信的 CA 的大多数强制性安全控制措施都是针对可能导致这种滥用的常见问题,包括使用 HSM 和严格的访问控制等标准建议。
我们将 CA 的根密钥材料离线保存,并用多层物理保护来保护它,每个访问层都需要两方授权。对于日常证书签发,我们使用在线可用的中间密钥,这是行业标准做法。由于让公众信任的 CA 被广泛纳入生态系统(即浏览器、电视和手机)的过程可能需要多年时间,因此在遭受损害后旋转密钥(参见“旋转签名密钥”)作为恢复工作的一部分并不是一个简单或及时的过程。因此,密钥材料的丢失或被盗可能会造成重大中断。为了防范这种情况,我们在生态系统中成熟了其他根密钥材料(通过将材料分发给使用加密连接的浏览器和其他客户端),这样我们就可以在必要时替换备用材料。
数据验证
除了密钥材料的丢失,签发错误是 CA 可能犯的最严重的错误。我们努力设计我们的系统,以确保人为判断不能影响验证或签发,这意味着我们可以将注意力集中在 CA 代码和基础设施的正确性和健壮性上。
持续验证(见“持续验证”)确保系统的行为符合预期。为了在 Google 的公众信任 CA 中实现这一概念,我们自动在签发过程的多个阶段通过 linter 运行证书。linter 检查错误模式,例如确保证书具有有效的生命周期或者subject:commonName具有有效的长度。一旦证书经过验证,我们将其输入到证书透明日志中,这允许公众进行持续验证。为了防范恶意签发,我们还使用多个独立的日志系统,通过逐个比较两个系统的条目来确保一致性。这些日志在到达日志存储库之前会被签名,以提供进一步的安全性和以备需要时进行后续验证。
结论
证书颁发机构是对安全性和可靠性有严格要求的基础设施的一个例子。使用本书中概述的最佳实践来实现基础设施可以带来长期的安全性和可靠性。这些原则应该是设计的一部分,但您也应该在系统成熟时使用它们来改进系统。
¹ TLS 的最新版本在RFC 8446中有描述。
² 安全/多用途互联网邮件扩展是一种加密电子邮件内容的常见方法。
³ 我们意识到许多组织确实构建和运营私有 CA,使用诸如微软的 AD 证书服务等常见解决方案。这些通常仅供内部使用。
⁴ DigiNotar 在遭受攻击者的侵害和滥用其 CA 后破产了。
⁵ 域验证指南的良好参考是CA/Browser Forum 基线要求。
⁶ Mitre CVE 数据库中包含了各种 DER 处理程序发现的数百个漏洞。
⁷ Borg 容器在 Verma, Abhishek 等人的 2015 年的论文“Large-Scale Cluster Management at Google with Borg.”中有描述。Proceedings of the 10th European Conference on Computer Systems: 1–17. doi:10.1145/2741948.2741964。
⁸ 例如,ZLint是一个用 Go 编写的 linter,用于验证证书的内容是否符合 RFC 5280 和 CA/Browser Forum 的要求。
第十二章:编写代码
原文:12. Writing Code
译者:飞龙
协议:CC BY-NC-SA 4.0
由 Michał Czapiński 和 Julian Bangert 撰写
与 Thomas Maufer 和 Kavita Guliani 合作
安全性和可靠性不能轻易地加入软件中,因此在软件设计的早期阶段就考虑它们是很重要的。在发布后添加这些功能是痛苦且不太有效的,可能需要您改变代码库的其他基本假设(有关此主题的更深入讨论,请参见第四章)。
减少安全性和可靠性问题的第一步,也是最重要的一步是教育开发人员。然而,即使是训练有素的工程师也会犯错——安全专家可能会编写不安全的代码,SRE 可能会忽略可靠性问题。在同时考虑构建安全和可靠系统所涉及的许多考虑因素和权衡是困难的,尤其是如果你还负责生产软件的话。
与其完全依赖开发人员审查代码的安全性和可靠性,不如让 SRE 和安全专家审查代码和软件设计。这种方法也是不完美的——手动代码审查不会发现每个问题,也不会每个安全问题都能被审查人员发现。审查人员也可能会受到自己的经验或兴趣的影响。例如,他们可能自然而然地倾向于寻找新的攻击类型、高级设计问题或加密协议中的有趣缺陷;相比之下,审查数百个 HTML 模板以查找跨站脚本(XSS)漏洞,或者检查应用程序中每个 RPC 的错误处理逻辑可能会被视为不那么令人兴奋。
虽然代码审查可能不会发现每个漏洞,但它们确实有其他好处。良好的审查文化鼓励开发人员以便于审查安全性和可靠性属性的方式构建他们的代码。本章讨论了使审查人员能够明显看到这些属性的策略,并将自动化整合到开发过程中。这些策略可以释放团队的带宽,让他们专注于其他问题,并建立安全和可靠性的文化(参见第二十一章)。
强制执行安全性和可靠性的框架
如第六章所讨论的,应用程序的安全性和可靠性依赖于特定领域的不变量。例如,如果应用程序的所有数据库查询仅由开发人员控制的代码组成,并通过查询参数绑定提供外部输入,那么该应用程序就可以防止 SQL 注入攻击。如果所有插入 HTML 表单的用户输入都经过适当转义或清理以删除任何可执行代码,Web 应用程序就可以防止 XSS 攻击。
理论上,您可以通过仔细编写维护这些不变量的应用程序代码来创建安全可靠的软件。然而,随着所需属性的数量和代码库的规模增长,这种方法几乎变得不可能。不合理地期望任何开发人员都是所有这些主题的专家,或者在编写或审查代码时始终保持警惕是不合理的。
如果需要人工审查每个更改,那么这些人将很难维护全局不变量,因为审查人员无法始终跟踪全局上下文。如果审查人员需要知道哪些函数参数是由调用者传递的用户输入,哪些参数只包含开发人员控制的可信值,他们还必须熟悉函数的所有传递调用者。审查人员不太可能能够长期保持这种状态。
更好的方法是在通用框架、语言和库中处理安全和可靠性。理想情况下,库只公开一个接口,使得使用常见安全漏洞类的代码编写变得不可能。多个应用程序可以使用每个库或框架。当领域专家修复问题时,他们会从框架支持的所有应用程序中删除它,从而使这种工程方法更好地扩展。与手动审查相比,使用集中的强化框架还可以减少未来漏洞的可能性。当然,没有框架可以防止所有安全漏洞,攻击者仍然有可能发现未预料到的攻击类别或发现框架实现中的错误。但是,如果您发现了新的漏洞,您可以在一个地方(或几个地方)解决它,而不是在整个代码库中。
举一个具体的例子:SQL 注入(SQLI)在常见安全漏洞的 OWASP](https://oreil.ly/TnBaK)和SANS列表中占据首要位置。根据我们的经验,当您使用像TrustedSqlString这样的强化数据库时(参见[“SQL 注入漏洞:TrustedSqlString”),这类漏洞就不再是问题。类型使这些假设变得明确,并且由编译器自动执行。
使用框架的好处
大多数应用程序都具有类似的安全构建块(身份验证和授权、日志记录、数据加密)和可靠性构建块(速率限制、负载平衡、重试逻辑)。为每个服务从头开始开发和维护这些构建块是昂贵的,并且会导致每个服务中不同错误的拼接。
框架实现了代码重用:开发人员只需定制特定的构建块,而不需要考虑影响给定功能或特性的所有安全和可靠性方面。例如,开发人员可以指定传入请求凭据中哪些信息对授权很重要,而无需担心这些信息的可信度——框架会验证可信度。同样,开发人员可以指定需要记录哪些数据,而无需担心存储或复制。框架还使传播更新更容易,因为您只需要在一个位置应用更新。
使用框架可以提高组织中所有开发人员的生产力,有助于建立安全和可靠文化(参见第二十一章)。对于一个团队的领域专家来说,设计和开发框架构建块要比每个团队单独实现安全和可靠特性更有效率。例如,如果安全团队处理加密,其他所有团队都会从他们的知识中受益。使用框架的开发人员无需担心其内部细节,而可以专注于应用程序的业务逻辑。
框架通过提供易于集成的工具进一步提高了生产力。例如,框架可以提供自动导出基本操作指标的工具,比如总请求数、按错误类型分解的失败请求数量,或者每个处理阶段的延迟。您可以使用这些数据生成自动化监控仪表板和服务的警报。框架还使与负载均衡基础设施集成更容易,因此服务可以自动将流量重定向到超载实例之外,或者在负载较重时启动新的服务实例。因此,基于框架构建的服务表现出更高的可靠性。
使用框架还可以通过清晰地将业务逻辑与常见功能分离,使对代码的推理变得容易。这使开发人员可以更有信心地对服务的安全性或可靠性做出断言。总的来说,框架可以降低复杂性——当跨多个服务的代码更加统一时,遵循常见的良好实践就更容易了。
开发自己的框架并不总是有意义。在许多情况下,最好的策略是重用现有的解决方案。例如,几乎任何安全专业人士都会建议您不要设计和实现自己的加密框架,而是可以使用像 Tink 这样的成熟和广泛使用的框架(在“示例:安全加密 API 和 Tink 加密框架”中讨论)。
在决定采用任何特定框架之前,评估其安全姿态是很重要的。我们还建议使用积极维护的框架,并不断更新您的代码依赖项,以纳入对您的代码依赖的任何代码的最新安全修复。
以下案例是一个实际示例,演示了框架的好处:在这种情况下,是用于创建 RPC 后端的框架。
示例:RPC 后端框架
大多数 RPC 后端遵循类似的结构。它们处理特定于请求的逻辑,并通常还执行以下操作:
-
日志记录
-
认证
-
授权
-
限流(速率限制)
我们建议使用一个可以隐藏这些构建块的实现细节的框架,而不是为每个单独的 RPC 后端重新实现这些功能。然后开发人员只需要定制每个步骤以适应其服务的需求。
图 12-1 展示了一个基于预定义拦截器的可能框架架构,这些拦截器负责前面提到的每个步骤。您还可以使用拦截器来执行自定义步骤。每个拦截器定义了在实际 RPC 逻辑执行之前和之后要执行的操作。每个阶段都可以报告错误条件,这会阻止进一步执行拦截器。但是,当发生这种情况时,已经调用的每个拦截器的之后步骤会以相反的顺序执行。拦截器之间的框架可以透明地执行其他操作,例如导出错误率或性能指标。这种架构导致了在每个阶段执行的逻辑的清晰分离,从而增加了简单性和可靠性。
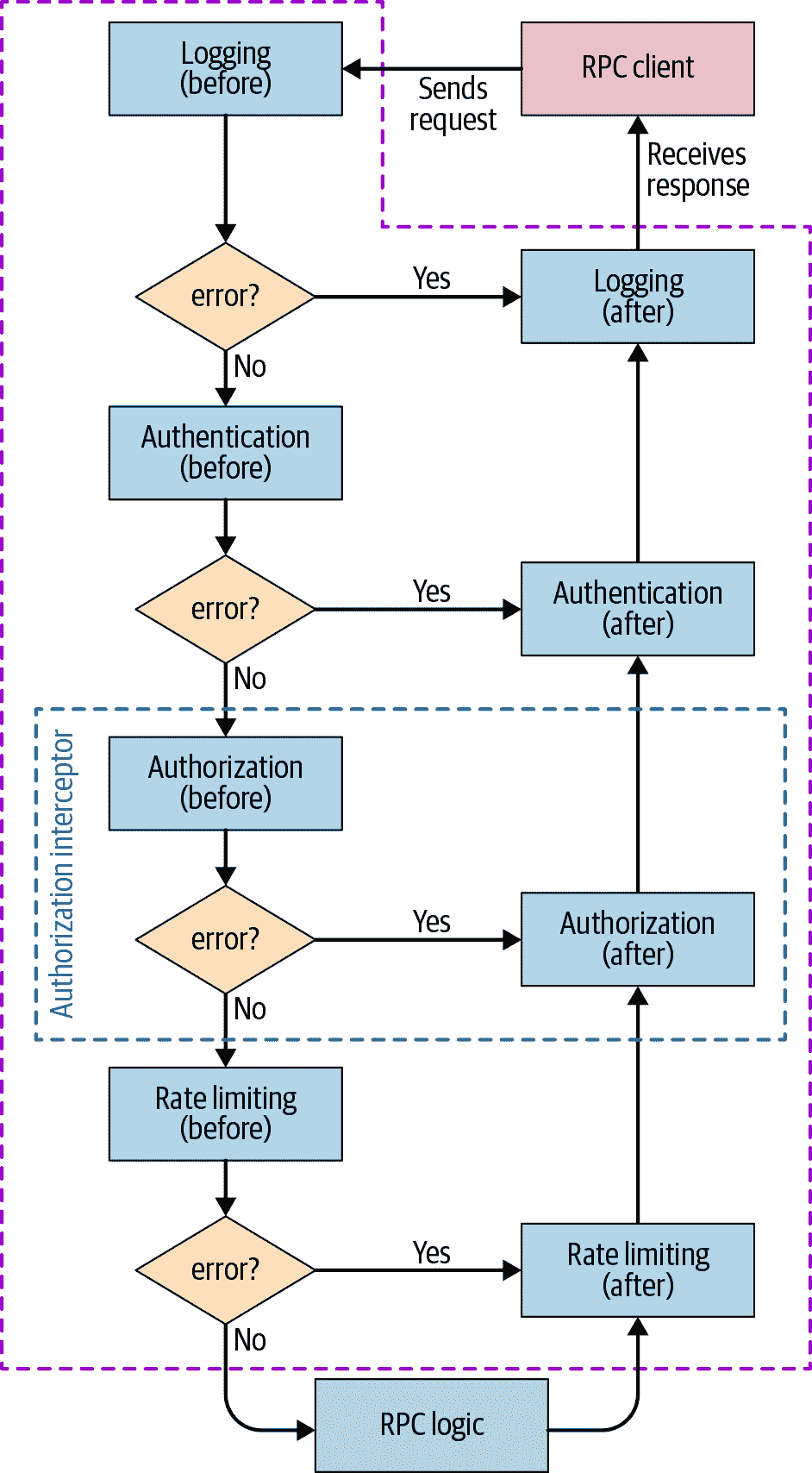
图 12-1:RPC 后端潜在框架中的控制流:典型步骤封装在预定义的拦截器中,授权作为示例突出显示
在这个例子中,日志拦截器的之前阶段可以记录调用,之后阶段可以记录操作的状态。现在,如果请求未经授权,RPC 逻辑不会执行,但是“权限被拒绝”的错误会被正确记录。之后,系统调用认证和日志拦截器的之后阶段(即使它们是空的),然后才将错误发送给客户端。
拦截器通过它们传递给彼此的上下文对象共享状态。例如,认证拦截器的之前阶段可以处理与证书处理相关的所有加密操作(注意从重用专门的加密库而不是重新实现一个来提高安全性)。然后系统将提取和验证的关于调用者的信息包装在一个方便的对象中,并将其添加到上下文中。随后的拦截器可以轻松访问此对象。
然后框架可以使用上下文对象来跟踪请求执行时间。如果在任何阶段明显地请求不会在截止日期之前完成,系统可以自动取消请求。通过快速通知客户端,还可以提高服务的可靠性,这也节省了资源。
一个好的框架还应该使您能够处理 RPC 后端的依赖关系,例如负责存储日志的另一个后端。您可以将这些注册为软依赖或硬依赖,框架可以不断监视它们的可用性。当它检测到硬依赖不可用时,框架可以停止服务,报告自身不可用,并自动将流量重定向到其他实例。
迟早,过载、网络问题或其他问题将导致依赖不可用。在许多情况下,重试请求是合理的,但要小心实现重试,以避免级联故障(类似于多米诺骨牌的倒塌)。¹最常见的解决方案是使用指数退避。²一个好的框架应该提供对这样的逻辑的支持,而不是要求开发人员为每个 RPC 调用实现逻辑。
一个优雅处理不可用依赖并重定向流量以避免过载服务或其依赖的框架自然地提高了服务本身和整个生态系统的可靠性。这些改进需要开发人员的最少参与。
示例代码片段
示例 12-1 到 12-3 演示了 RPC 后端开发人员与安全或可靠性框架合作的视角。这些示例使用 Go 并使用Google Protocol Buffers。
12-1 示例。初始类型定义(拦截器的前阶段可以修改上下文;例如,身份验证拦截器可以添加有关调用者的验证信息)
type Request struct {
Payload proto.Message
}
type Response struct {
Err error
Payload proto.Message
}
type Interceptor interface {
Before(context.Context, *Request) (context.Context, error)
After(context.Context, *Response) error
}
type CallInfo struct {
User string
Host string
...
}
12-2 示例。示例授权拦截器,只允许来自白名单用户的请求
type authzInterceptor struct {
allowedRoles map[string]bool
}
func (ai *authzInterceptor) Before(ctx context.Context, req *Request) (context.Context, error) {
// callInfo was populated by the framework.
callInfo, err := FromContext(ctx)
if err != nil { return ctx, err }
if ai.allowedRoles[callInfo.User] { return ctx, nil }
return ctx, fmt.Errorf("Unauthorized request from %q", callInfo.User)
}
func (*authzInterceptor) After(ctx context.Context, resp *Response) error {
return nil // Nothing left to do here after the RPC is handled.
}
12-3 示例。示例日志拦截器,记录每个传入请求(阶段前)然后记录所有失败的请求及其状态(阶段后);WithAttemptCount 是一个由框架提供的 RPC 调用选项,实现指数退避
type logInterceptor struct {
logger *LoggingBackendStub
}
func (*logInterceptor) Before(ctx context.Context,
req *Request) (context.Context, error) {
// callInfo was populated by the framework.
callInfo, err := FromContext(ctx)
if err != nil { return ctx, err }
logReq := &pb.LogRequest{
timestamp: time.Now().Unix(),
user: callInfo.User,
request: req.Payload,
}
resp, err := logger.Log(ctx, logReq, WithAttemptCount(3))
return ctx, err
}
func (*logInterceptor) After(ctx context.Context, resp *Response) error {
if resp.Err == nil { return nil }
logErrorReq := &pb.LogErrorRequest{
timestamp: time.Now().Unix(),
error: resp.Err.Error(),
}
resp, err := logger.LogError(ctx, logErrorReq, WithAttemptCount(3))
return err
}
常见安全漏洞
在大型代码库中,少数类占据了大部分安全漏洞,尽管不断努力教育开发人员并引入代码审查。OWASP 和 SANS 发布了常见漏洞类别的列表。表 12-1 列出了根据OWASP列出的前 10 个最常见的漏洞风险,以及在框架级别上缓解每个漏洞的一些潜在方法。
表 12-1。根据 OWASP 列出的前 10 个最常见的漏洞风险
| OWASP 前 10 大漏洞 | 框架加固措施 |
|---|---|
| [SQL]注入 | TrustedSQLString(请参阅下一节)。 |
| 损坏的身份验证 | 在将请求路由到应用程序之前,要求使用像 OAuth 这样经过充分测试的机制进行身份验证。(参见“示例:RPC 后端框架”。) |
| 敏感数据泄露 | 使用不同的类型(而不是字符串)来存储和处理信用卡号等敏感数据。这种方法可以限制序列化以防止泄漏并强制适当的加密。框架还可以强制执行透明的传输保护,如使用 LetsEncrypt 的 HTTPS。加密 API,如Tink,可以鼓励适当的秘密存储,例如从云密钥管理系统加载密钥,而不是从配置文件加载。 |
| XML 外部实体(XXE) | 使用未启用 XXE 的 XML 解析器;确保支持它的库中禁用这个风险特性。ᵃ |
| 破损的访问控制 | 这是一个棘手的问题,因为它通常是特定于应用程序的。使用一个要求每个请求处理程序或 RPC 具有明确定义的访问控制限制的框架。如果可能的话,将最终用户凭据传递到后端,并在后端强制执行访问控制策略。 |
| 安全配置错误 | 使用默认提供安全配置并限制或不允许风险配置选项的技术堆栈。例如,使用一个在生产中不打印错误信息的 Web 框架。使用一个标志来启用所有调试功能,并设置部署和监控基础设施以确保这个标志不对公共用户启用。Rails 中的environment标志就是这种方法的一个例子。 |
| 跨站脚本(XSS) | 使用 XSS 强化的模板系统(参见“预防 XSS:SafeHtml”)。 |
| 不安全的反序列化 | 使用专为处理不受信任输入而构建的反序列化库,例如Protocol Buffers。 |
| 使用已知漏洞的组件 | 选择受欢迎且积极维护的库。不要选择有未修复或缓慢修复安全问题历史的组件。另请参见“评估和构建框架的教训”。 |
| 日志记录和监控不足 | 不要依赖于临时日志记录,适当地记录和监控请求和其他事件在低级库中。有关示例,请参见前一节中描述的日志拦截器。 |
| ᵃ有关更多信息,请参见XXE 预防备忘单。 |
SQL 注入漏洞:TrustedSqlString
SQL 注入是一种常见的安全漏洞类别。当不可信的字符串片段被插入到 SQL 查询中时,攻击者可能会注入数据库命令。以下是一个简单的密码重置网页表单:
db.query("UPDATE users SET pw_hash = '" + request["pw_hash"]
+ "' WHERE reset_token = '" + request.params["reset_token"] + "'")
在这种情况下,用户的请求被定向到一个具有与其帐户特定的不可猜测的reset_token的后端。然而,由于字符串连接,恶意用户可以制作一个带有额外 SQL 命令(例如' or username='admin)的自定义reset_token并将其注入到后端。结果可能会重置不同用户的密码哈希—在这种情况下是管理员帐户。
在更复杂的代码库中,SQL 注入漏洞可能更难以发现。数据库引擎可以通过提供绑定参数和预编译语句来帮助您防止 SQL 注入漏洞:
Query q = db.createQuery(
"UPDATE users SET pw_hash = @hash WHERE token = @token");
q.setParameter("hash", request.params["hash"]);
q.setParameter("token", request.params["token"]);
db.query(q);
然而,仅仅建立一个使用预编译语句的准则并不能导致可扩展的安全流程。您需要教育每个开发人员遵守这个规则,并且安全审查人员需要审查所有应用程序代码,以确保一致使用预编译语句。相反,您可以设计数据库 API,使用户输入和 SQL 的混合在设计上变得不可能。例如,您可以创建一个名为TrustedSqlString的单独类型,并通过构造强制执行所有 SQL 查询字符串都是由开发人员控制的输入创建的。在 Go 中,您可以实现该类型如下:
struct Query {
sql strings.Builder;
}
type stringLiteral string;
*// Only call this function with string literal parameters.*
func (q *Query) AppendLiteral(literal stringLiteral) {
q.sql.writeString(literal);
}
*// q.AppendLiteral("foo") will work, q.AppendLiteral(foo) will not*
该实现通过构造保证了q.sql的内容完全是从您的源代码中存在的字符串字面量连接而成的,用户无法提供字符串字面量。为了在规模上强制执行这个合同,您可以使用一种特定于语言的机制,确保AppendLiteral只能与字符串字面量一起调用。例如:
在 Go
使用包私有类型别名(stringLiteral)。包外的代码不能引用此别名;但是,字符串字面量会被隐式转换为这种类型。
在 Java
使用Error Prone代码检查器,它为参数提供了@CompileTimeConstant注释。
在 C++中
使用依赖于字符串中每个字符值的模板构造函数。
您可以在其他语言中找到类似的机制。
您无法仅使用编译时常量构建某些功能,比如设计为由拥有数据的用户提供任意 SQL 查询的数据分析应用程序。为了处理复杂的用例,在 Google,我们允许通过安全工程师的批准绕过类型限制的方法。例如,我们的数据库 API 有一个单独的包unsafequery,它导出一个独特的unsafequery.String类型,可以从任意字符串构造并附加到 SQL 查询中。只有很小一部分查询使用了未经检查的 API。对于数百到数千名活跃开发人员,审核不安全的 SQL 查询的新用途和其他受限 API 模式的负担由一名(轮换的)工程师兼职处理。参见“评估和构建框架的教训”以了解审核豁免的其他好处。
防止 XSS:SafeHtml
我们在前一节中描述的基于类型的安全方法并不特定于 SQL 注入。Google 使用更复杂的相同设计的版本来减少 Web 应用程序中的跨站脚本漏洞。³
在核心上,XSS 漏洞发生在 Web 应用程序在没有适当清理的情况下呈现不可信的输入时。例如,一个应用程序可能会将一个受攻击者控制的$address值插入到 HTML 片段中,如<div>$address</div>,然后显示给另一个用户。攻击者可以将$address设置为<script>exfiltrate_user_data();</script>并在另一个用户页面的上下文中执行任意代码。
HTML 没有绑定查询参数的等价物。相反,不可信的值必须在插入到 HTML 页面之前得到适当的清理或转义。此外,不同的 HTML 属性和元素具有不同的语义,因此应用程序开发人员必须根据它们出现的上下文来不同对待值。例如,攻击者控制的 URL 可以使用javascript:方案来执行代码。
类型系统可以通过为不同上下文中的值引入不同的类型来捕获这些要求,例如,SafeHtml用于表示 HTML 元素的内容,SafeUrl用于安全导航到的 URL。每种类型都是一个(不可变的)字符串包装器;构造函数负责维护每种类型的合同。构造函数构成了负责确保应用程序安全属性的受信任代码库。
Google 为不同的用例创建了不同的构建器库。可以使用构建器方法构造单个 HTML 元素,该方法要求每个属性值都具有正确的类型,并且对于元素内容使用SafeHtml。具有严格上下文转义的模板系统可以保证更复杂的 HTML 的SafeHtml合同。该系统执行以下操作:
-
解析模板中的部分 HTML
-
确定每个替换点的上下文
-
要么要求程序传递正确类型的值,要么正确转义或清理不受信任的字符串值
例如,如果您有以下 Closure 模板:
{template .foo kind="html"}<script src="{$url}"></script>{/template}
尝试使用$url的字符串值将失败:
templateRendered.setMapData(ImmutableMap.of("url", some_variable));
相反,开发人员必须提供TrustedResourceUrl值,例如:
templateRenderer.setMapData(
ImmutableMap.of("x", TrustedResourceUrl.fromConstant("/script.js"))
).render();
如果 HTML 来自不受信任的来源,您不希望将其嵌入到应用程序的 Web UI 中,因为这样做会导致易受攻击的 XSS 漏洞。相反,您可以使用 HTML 清理器解析 HTML 并执行运行时检查,以确定每个值是否符合其合同。清理器会删除不符合其合同的元素,或者无法在运行时检查合同的元素。您还可以使用清理器与不使用安全类型的其他系统进行交互,因为许多 HTML 片段在清理过程中保持不变。
不同的 HTML 构建库针对不同的开发人员生产力和代码可读性权衡。但是,它们都强制执行相同的合同,并且应该同样值得信赖(除了它们受信任的实现中的任何错误)。实际上,为了减少谷歌的维护负担,我们从声明性配置文件中为各种语言代码生成构建器函数。该文件列出了 HTML 元素和每个属性值的所需合同。我们的一些 HTML 清理器和模板系统使用相同的配置文件。
在Closure Templates中提供了成熟的开源安全类型实现,目前正在进行引入基于类型的安全性的工作,作为 Web 标准。
评估和构建框架的教训
前几节讨论了如何构建库以建立安全性和可靠性属性。但是,并非所有这样的属性都可以通过 API 设计优雅地表达,有些情况下甚至无法轻松更改 API,例如与 Web 浏览器公开的标准化 DOM API 交互时。
相反,您可以引入编译时检查,以防止开发人员使用风险 API。流行编译器的插件,如 Java 的Error Prone和 TypeScript 的Tsetse,可以禁止危险的代码模式。
我们的经验表明,编译器错误提供了即时和可操作的反馈。在代码审查时运行的工具(如 linter)或在代码审查时提供的反馈要晚得多。到代码发送进行审查时,开发人员通常已经有了一个完成的、可工作的代码单元。在开发过程的这么晚阶段得知需要进行一些重新架构才能使用严格类型的 API 可能会令人沮丧。
向开发人员提供编译器错误或更快的反馈机制(如 IDE 插件,可以标出有问题的代码)要容易得多。通常,开发人员会快速解决编译问题,并且已经必须修复其他编译器诊断,如拼写错误和语法错误。因为开发人员已经在处理受影响的特定代码行,他们有完整的上下文,所以进行更改更容易,例如将字符串的类型更改为SafeHtml。
通过建议自动修复,甚至可以进一步改善开发人员的体验,这些自动修复可以作为安全解决方案的起点。例如,当检测到对 SQL 查询函数的调用时,可以自动插入对TrustedSqlBuilder.fromConstant的调用,其中包含查询参数。即使生成的代码不能完全编译(也许是因为查询是字符串变量而不是常量),开发人员也知道该怎么做,无需通过找到正确的函数、添加正确的导入声明等来烦恼 API 的机械细节。
根据我们的经验,只要反馈周期快,修复每个模式相对容易,开发人员就会更愿意接受固有安全的 API,即使我们无法证明他们的代码是不安全的,或者他们在使用不安全的 API 编写安全代码时做得很好。我们的经验与现有的研究文献形成对比,后者侧重于降低误报和漏报率。(4)
我们发现,专注于这些速率通常会导致复杂的检查器,需要更长时间才能发现问题。例如,一个检查可能需要分析复杂应用程序中的整个程序数据流。通常很难解释如何从静态分析检测到的问题中删除问题,因为检查器的工作方式比简单的语法属性要难得多。理解一个发现需要和在 GDB(GNU 调试器)中追踪错误一样多的工作。另一方面,在编写新代码时在编译时修复类型安全错误通常并不比修复微不足道的类型错误困难得多。
简单、安全、可靠的常见任务库
构建一个安全的库,涵盖所有可能的用例并可靠地处理每个用例可能非常具有挑战性。例如,一个在 HTML 模板系统上工作的应用程序开发人员可能会编写以下模板:
<a onclick="showUserProfile('{{username}}');">Show profile</a>">
为了防止 XSS 攻击,如果“用户名”受攻击者控制,模板系统必须嵌套三种不同的上下文层:单引号字符串,JavaScript 内部,HTML 元素属性内部。创建一个可以处理所有可能的边缘情况组合的模板系统是复杂的,并且使用该系统不会简单。在其他领域,这个问题可能变得更加复杂。例如,业务需求可能会规定谁可以执行动作,谁不能。除非您的授权库像通用编程语言一样具有表达力(并且难以分析),您可能无法满足所有开发人员的需求。
相反,您可以从一个简单的、小型的库开始,只涵盖常见用例,但更容易正确使用。简单的库更容易解释、文档化和使用。这些特性减少了开发人员的摩擦,并可能帮助您说服其他开发人员采用安全设计的库。在某些情况下,提供针对不同用例进行优化的不同库可能是有意义的。例如,您可能既有用于复杂页面的 HTML 模板系统,也有用于短片段的构建器库。
您可以通过专家审查的方式满足其他用例,访问一个不受限制的、风险的库,绕过安全保证。如果您看到类似的重复请求,您可以在固有安全的库中支持该功能。正如我们在“SQL 注入漏洞:TrustedSqlString”中观察到的,审查负载通常是可以管理的。
由于审查请求的数量相对较少,安全审查人员可以深入查看代码并提出广泛的改进建议——审查往往是独特的用例,这保持了审查人员的积极性,并防止了由于重复和疲劳而导致的错误。豁免也作为一个反馈机制:如果开发人员反复需要豁免某个用例,库作者应该考虑为该用例构建一个库。
推出策略
我们的经验表明,对安全属性使用类型对于新代码非常有用。事实上,使用安全类型的谷歌内部广泛使用的一个 Web 框架创建的应用程序,报告的 XSS 漏洞要少得多(少两个数量级)比没有使用安全类型编写的应用程序,尽管进行了仔细的代码审查。少数报告的漏洞是由于应用程序的组件没有使用安全类型造成的。
将现有代码调整为使用安全类型更具挑战性。即使您从头开始创建一个全新的代码库,您也需要一个迁移遗留代码的策略——您可能会发现您想要保护的新的安全性和可靠性问题类别,或者您可能需要完善现有的合同。
我们已经尝试了几种重构现有代码的策略;我们在下面的小节中讨论了我们最成功的两种方法。这些策略要求您能够访问和修改应用程序的整个源代码。Google 的大部分源代码都存储在一个单一的存储库中⁵,并具有用于制作、构建、测试和提交更改的集中式流程。代码审查人员还会强制执行常见的可读性和代码组织标准,这减少了改变陌生代码库的复杂性。在其他环境中,大规模的重构可能更具挑战性。获得广泛的一致意见有助于每个代码所有者都愿意接受对他们源代码的更改,这有助于建立一个安全可靠的文化。
注意
Google 公司的全公司风格指南融入了语言可读性的概念:工程师理解给定语言的 Google 最佳实践和编码风格的认证。可读性确保了代码质量的基线。工程师必须在他们正在使用的语言中具有可读性,或者从具有可读性的人那里获得代码审查。对于特别复杂或至关重要的代码,面对面的代码审查可能是改进代码库质量最有效和高效的方式。
增量推出
一次性修复整个代码库通常是不可行的。不同的组件可能在不同的存储库中,对多个应用程序进行更改的编写、审查、测试和提交通常是脆弱且容易出错的。相反,在 Google,我们最初豁免遗留代码的执行,并逐个解决现有不安全 API 的使用者。
例如,如果您已经有一个带有doQuery(String sql)函数的数据库 API,您可以引入一个重载,doQuery(TrustedSqlString sql),并将不安全版本限制为现有的调用者。使用 Error Prone 框架,您可以添加一个@RestrictedApi(whitelistAnnotation={LegacyUnsafeStringQueryAllowed.class})注解,并将@LegacyUnsafeStringQueryAllowed注解添加到所有现有的调用者。
然后,通过引入Git hooks来分析每个提交,您可以防止新代码使用基于字符串的过载。或者,您可以限制不安全 API 的可见性——例如,Bazel 可见性白名单将允许用户仅在安全团队成员批准拉取请求(PR)时调用 API。如果您的代码库正在积极开发,它将自然地向安全 API 迁移。在达到只有少部分调用者使用已弃用的基于字符串的 API 的时候,您可以手动清理剩余部分。在那时,您的代码将因设计而免疫 SQL 注入。
遗留转换
将所有的豁免机制整合到一个在源代码中明显的函数中通常也是值得的。例如,您可以创建一个函数,它接受任意字符串并返回一个安全类型。您可以使用这个函数来替换所有对字符串类型的 API 的调用,使其更精确地调用。通常,类型会比使用它们的函数少得多。与限制和监控许多遗留 API 的移除(例如,每个消耗 URL 的 DOM API)不同,您只需要删除每种类型的一个遗留转换函数。
简单导致安全可靠的代码
在实际情况下,尽量保持代码简洁和简单。关于这个主题有很多出版物,⁶所以这里我们专注于两个轻量级的故事,这些故事发表在Google 测试博客上。这两个故事都强调了避免快速增加代码库复杂性的策略。
避免多级嵌套
多层嵌套是一种常见的反模式,可能导致简单的错误。如果错误出现在最常见的代码路径中,它很可能会被单元测试捕获。但是,单元测试并不总是检查多层嵌套代码中的错误处理路径。错误可能导致可靠性降低(例如,如果服务在错误处理不当时崩溃)或安全漏洞(如错误处理授权检查错误)。
您能在图 12-2 的代码中发现错误吗?这两个版本是等价的。⁷

图 12-2:在多层嵌套代码中,错误通常更难发现
“错误编码”和“未经授权”的错误被交换了。在重构版本中更容易看到这个错误,因为检查发生在处理错误时。
消除 YAGNI 气味
有时,开发人员通过添加可能在将来有用的功能“以防万一”来过度设计解决方案。这违反了YAGNI(你不会需要它)原则,该原则建议仅实现您需要的代码。YAGNI 代码会增加不必要的复杂性,因为它需要进行文档化、测试和维护。考虑以下示例:⁸
class Mammal { ...
virtual Status Sleep(bool hibernate) = 0;
};
class Human : public Mammal { ...
virtual Status Sleep(bool hibernate) {
age += hibernate ? kSevenMonths : kSevenHours;
return OK;
}
};
Human::Sleep代码必须处理hibernate为true的情况,即使所有调用者应始终传递false。此外,调用者必须处理返回的状态,即使该状态应始终为OK。因此,在您需要除Human之外的其他类之前,此代码可以简化为以下内容:
class Human { ...
void Sleep() { age += kSevenHours; }
};
如果开发人员对未来功能的可能需求做出的假设实际上是正确的,他们可以通过遵循增量开发和设计原则轻松地稍后添加该功能。在我们的例子中,基于几个现有类进行概括时,将更容易创建具有更好公共 API 的Mammal接口。
总之,避免 YAGNI 代码会提高可靠性,简化代码会减少安全漏洞,减少出错的机会,并减少开发人员维护未使用代码的时间。
偿还技术债务
开发人员通常会使用 TODO 或 FIXME 注释标记需要进一步关注的地方。短期内,这种习惯可以加快最关键功能的交付速度,并允许团队满足早期的截止日期,但也会产生技术债务。不过,只要您有清晰的流程(并分配时间)来偿还这样的债务,这并不一定是一种坏习惯。
技术债务可能包括对异常情况的错误处理以及将不必要的复杂逻辑引入代码(通常编写以解决其他技术债务领域的问题)。任何一种行为都可能引入安全漏洞和可靠性问题,这些问题在测试期间很少被检测到(因为罕见情况的覆盖不足),因此成为生产环境的一部分。
您可以以许多方式处理技术债务。例如:
-
保持具有代码健康度指标的仪表板。这些可以是简单的仪表板,显示测试覆盖率或 TODO 的数量和平均年龄,也可以是包括圈复杂度或可维护性指数等指标的更复杂的仪表板。
-
使用诸如 linter 之类的分析工具来检测常见的代码缺陷,例如死代码、不必要的依赖关系或特定于语言的陷阱。通常,这些工具还可以自动修复您的代码。
-
当代码健康度指标下降到预定义阈值以下或自动检测到的问题数量过高时创建通知。
此外,重要的是要保持一个拥抱并专注于良好代码健康的团队文化。领导可以通过多种方式支持这种文化。例如,您可以安排定期的修复周,在这些周内,开发人员专注于改善代码健康和修复未解决的错误,而不是添加新功能。您还可以通过奖金或其他形式的认可来支持团队内对代码健康的持续贡献。
重构
重构是保持代码库清洁和简单的最有效方法。即使健康的代码库偶尔也需要在扩展现有功能集、更改后端等情况下进行重构。
重构在处理旧的、继承的代码库时特别有用。重构的第一步是测量代码覆盖率,并将覆盖率提高到足够的水平。⁹一般来说,覆盖率越高,对重构的安全性的信心就越高。不幸的是,即使测试覆盖率达到 100%,也不能保证成功,因为测试可能没有意义。您可以通过其他类型的测试来解决这个问题,例如fuzzing,这在第十三章中有介绍。
注意
无论重构背后的原因是什么,您都应始终遵循一个黄金法则:永远不要在单个提交到代码存储库中混合重构和功能更改。重构更改通常很重要,可能难以理解。如果提交还包括功能更改,那么作者或审阅者可能会忽略错误的风险更高。
重构技术的完整概述超出了本书的范围。有关此主题的更多信息,请参阅 Martin Fowler 的优秀著作¹⁰以及 Wright 等人提供的自动化大规模重构工具的讨论(2013 年),¹¹ Wasserman(2013 年),¹²和 Potvin 和 Levenberg(2016 年)。
默认安全性和可靠性
除了使用具有强大保证的框架外,您还可以使用其他几种技术来自动改善应用程序的安全性和可靠性姿态,以及团队文化的姿态,您将在第二十一章中了解更多。
选择正确的工具
选择语言、框架和库是一项复杂的任务,通常受多种因素的影响,例如:
-
与现有代码库的集成
-
库的可用性
-
开发团队的技能或偏好
要意识到语言选择对项目安全性和可靠性的巨大影响。
使用内存安全语言
在 2019 年 2 月的以色列 BlueHat 大会上,微软的 Matt Miller 声称,大约 70%的安全漏洞都是由内存安全问题引起的。¹³这个统计数据在过去至少 12 年中一直保持一致。
在 2016 年的一次演讲中,来自 Google 的 Nick Kralevich 报告称,Android 中 85%的所有错误(包括内核和其他组件中的错误)都是由内存管理错误引起的(第 54 页)。¹⁴ Kralevich 得出结论:“我们需要转向内存安全语言。”通过使用具有更高级内存管理的任何语言(如 Java 或 Go)而不是具有更多内存分配困难的语言(如 C/C++),您可以默认避免这整类安全(和可靠性)漏洞。或者,您可以使用代码消毒剂来检测大多数内存管理陷阱(请参阅“消毒您的代码”)。
使用强类型和静态类型检查
在强类型语言中,“每当对象从调用函数传递到被调用函数时,其类型必须与被调用函数中声明的类型兼容。”没有这个要求的语言被称为弱类型或松散类型。您可以在编译期间(静态类型检查)或运行时(动态类型检查)执行类型检查。
强类型和静态类型检查的好处在于在大型代码库中与多个开发人员合作时特别明显,因为您可以在编译时强制执行不变量,并消除各种错误,而不是在运行时。这导致在生产环境中更可靠的系统,更少的安全问题和更高性能的代码。
相比之下,在使用动态类型检查时(例如在 Python 中),除非代码具有 100%的测试覆盖率,否则您几乎无法推断代码的任何信息——这在原则上很好,但在实践中很少见。在弱类型语言中,推理代码变得更加困难,通常会导致意外行为。例如,在 JavaScript 中,每个文字默认都被视为字符串:[9, 8, 10].sort() -> [10, 8, 9]。在这两种情况下,由于不变量在编译时未被强制执行,您只能在测试期间捕获错误。因此,您更容易在生产环境中而不是在开发过程中检测到可靠性和安全性问题,特别是在较少频繁使用的代码路径中。
如果要使用默认具有动态类型检查或弱类型的语言,我们建议使用以下扩展来提高代码的可靠性。这些扩展提供了对更严格类型检查的支持,您可以逐步将它们添加到现有的代码库中:
-
Pytype for Python
-
TypeScript for JavaScript
使用强类型
使用未类型化的基元(例如字符串或整数)可能会导致以下问题:
-
向函数传递概念上无效的参数
-
不需要的隐式类型转换
-
难以理解的类型层次结构
-
令人困惑的测量单位
第一种情况——向函数传递概念上无效的参数——发生在函数参数的原始类型没有足够的上下文,并且在调用时变得令人困惑。例如:
-
对于函数
AddUserToGroup(string, string),不清楚组名是作为第一个参数还是第二个参数提供的。 -
在
Rectangle(3.14, 5.67)构造函数调用中,高度和宽度的顺序是什么? -
Circle(double)是否期望半径还是直径?
文档可以纠正歧义,但开发人员仍然可能犯错。如果我们尽了责任,单元测试可以捕捉到大多数这些错误,但有些错误可能只在运行时出现。
使用强类型时,您可以在编译时捕捉到这些错误。回到我们之前的例子,所需的调用将如下所示:
-
Add(User("alice"), Group("root-users")) -
Rectangle(Width(3.14), Height(5.67)) -
Circle(Radius(1.23))
其中User、Group、Width、Height和Radius是围绕字符串或双精度基元的强类型包装器。这种方法不太容易出错,并使代码更具自我说明性——在这种情况下,在第一个示例中,只需调用函数Add即可。
在第二种情况下,隐式类型转换可能导致以下情况:
-
从较大的整数类型转换为较小的整数类型时的截断
-
从较大的浮点类型转换为较小的浮点类型时的精度损失
-
意外对象创建
在某些情况下,编译器将报告前两个问题(例如,在 C++中使用{}直接初始化语法时),但许多实例可能会被忽视。使用强类型可以保护您的代码免受编译器无法捕获的此类错误。
现在让我们考虑难以理解的类型层次结构的情况:
class Bar { public: Bar(bool is_safe) {...} }; void Foo(const Bar& bar) {...} Foo(false); *// Likely OK, but is the developer aware a Bar object was created?* Foo(5); *// Will create Bar(is_safe := true), but likely by accident.* Foo(NULL); *// Will create Bar(is_safe := false), again likely by accident.*
这里的三个调用将编译并执行,但操作的结果是否符合开发人员的期望呢?默认情况下,C++编译器会尝试隐式转换(强制)参数以匹配函数参数类型。在这种情况下,编译器将尝试匹配类型Bar,它恰好有一个接受bool类型参数的单值构造函数。大多数 C++类型会隐式转换为bool。
构造函数中的隐式转换有时是有意的(例如,将浮点值转换为std::complex类时),但在大多数情况下可能是危险的。为了防止危险的结果,至少要使单值构造函数显式——例如,explicit Bar(bool is_safe)。请注意,最后一次调用将导致编译错误,因为使用nullptr而不是NULL,因为没有到bool的隐式转换。
最后,单位混淆是错误的无尽源泉。这些错误可能被描述如下:
无害的
例如,设置一个 30 秒的定时器而不是 30 分钟,因为程序员不知道Timer(30)使用的单位。
危险的
例如,加拿大航空的“吉姆利滑翔机”飞机在地勤人员计算所需的燃料时使用的是磅而不是千克,导致它只有所需燃料的一半。
昂贵的
例如,科学家们失去了价值 1.25 亿美元的火星气候轨道飞行器,因为两个独立的工程团队使用了不同的测量单位(英制与公制)。
与以前一样,强类型是解决此问题的一种方法:它们可以封装单位,并且只表示抽象概念,如时间戳、持续时间或重量。这些类型通常实现以下功能:
明智的操作
例如,添加两个时间戳通常不是一个有用的操作,但是减去它们会返回一个对许多用例有用的持续时间。类似地,添加两个持续时间或重量也是有用的。
单位转换
例如,Timestamp::ToUnix, Duration::ToHours, Weight::ToKilograms。
一些语言本身提供这样的抽象:例如 Go 中的time包和即将到来的 C++20 标准中的chrono库。其他语言可能需要专门的实现。
Fluent C++博客对 C++中强类型的应用和示例实现进行了更多讨论。
净化您的代码
自动验证代码是否遇到任何典型的内存管理或并发陷阱非常有用。您可以将这些检查作为每个更改列表的预提交操作运行,也可以作为持续构建和测试自动化工具的一部分运行。要检查的陷阱列表取决于语言。本节介绍了 C++和 Go 的一些解决方案。
C++:Valgrind 或 Google Sanitizers
C++允许进行低级内存管理。正如我们之前提到的,内存管理错误是安全问题的主要原因,并且可能导致以下故障场景:
-
读取未分配的内存(
new之前或delete之后) -
读取超出分配内存范围的内容(缓冲区溢出攻击场景)
-
读取未初始化的内存
-
当系统丢失已分配内存的地址或不及时释放未使用的内存时,会发生内存泄漏
Valgrind是一个流行的框架,允许开发人员捕捉这些类型的错误,即使单元测试没有捕捉到它们。Valgrind 的好处在于提供了一个解释用户二进制的虚拟机,因此用户无需重新编译代码即可使用它。Valgrind 工具Helgrind还可以检测常见的同步错误,例如:
-
对 POSIX pthreads API 的误用(例如,解锁未锁定的互斥锁,或者由另一个线程持有的互斥锁)
-
由于锁定顺序问题而产生的潜在死锁
-
由于访问内存而未进行充分锁定或同步而引起的数据竞争
或者,Google Sanitizers 套件提供了各种组件,可以检测 Valgrind 的 Callgrind(缓存和分支预测分析器)可以检测到的所有相同问题:
-
AddressSanitizer (ASan)检测内存错误(缓冲区溢出,释放后使用,不正确的初始化顺序)。
-
LeakSanitizer (LSan)检测内存泄漏。
-
MemorySanitizer (MSan)检测系统是否正在读取未初始化的内存。
-
ThreadSanitizer (TSan)检测数据竞争和死锁。
-
UndefinedBehaviorSanitizer (UBSan)检测具有未定义行为的情况(使用未对齐的指针;有符号整数溢出;转换到、从或在浮点类型之间溢出目标)。
Google Sanitizers 套件的主要优势是速度:它比 Valgrind 快高达 10 倍。像CLion这样的流行 IDE 还提供了与 Google Sanitizers 的一流集成。下一章将更详细地介绍 sanitizers 和其他动态程序分析工具。
Go:竞争检测器
虽然 Go 旨在禁止 C++典型的内存损坏问题,但仍可能受到数据竞争条件的影响。Go 竞争检测器可以检测这些条件。
结论
本章介绍了几个指导开发人员设计和实现更安全可靠代码的原则。特别是,我们建议使用框架作为一种强大的策略,因为它们重用了已被证明对于代码的敏感区域(身份验证、授权、日志记录、速率限制和分布式系统中的通信)的建设块:框架还倾向于提高开发人员的生产力,无论是编写框架的人还是使用框架的人,并使对代码的推理变得更加容易。编写安全可靠代码的其他策略包括追求简单性,选择合适的工具,使用强类型而不是原始类型,并持续对代码进行消毒。
在编写软件时,额外投入精力改善安全性和可靠性将在长期内得到回报,并减少您在部署应用程序后需要花费的审查应用程序或修复问题的工作量。
¹ 有关级联故障的更多信息,请参见SRE 书的第 22 章。
² 也在SRE 书的第 22 章中有描述。
³ 有关该系统的更多详细信息,请参见 Kern, Christoph. 2014. “保护纠缠不清的网络。” ACM 通讯 57(9): 38–47. https://oreil.ly/drZss.
⁴ 请参见 Bessey, Al 等人。2010. “数十亿行代码之后:使用静态分析在现实世界中查找错误。” ACM 通讯 53(2): 66–75. doi:10.1145/1646353.1646374.
⁵ Potvin, Rachel, and Josh Levenberg. 2016. “为什么 Google 将数十亿行代码存储在单个存储库中。” ACM 通讯 59(7): 78–87. doi:10.1145/2854146.
⁶ 例如,Ousterhout, John. 2018. 软件设计哲学. Palo Alto, CA: Yaknyam Press.
⁷ 来源:Karpilovsky, Elliott. 2017. “代码健康:减少嵌套,减少复杂性。” https://oreil.ly/PO1QR.
⁸ 来源:Eaddy, Marc. 2017. “代码健康:消除 YAGNI 气味。” https://oreil.ly/NYr7y.
⁹ 有很多代码覆盖工具可供选择。有关概述,请参阅Stackify 上的列表。
¹⁰ Fowler, Martin. 2019 年。 重构:改善现有代码的设计。马萨诸塞州波士顿:Addison-Wesley。
¹¹ Wright, Hyrum 等。 2013 年。 “使用 Clang 进行大规模自动重构。” 软件维护国际会议第 29 届论文集:548–551。 doi:10.1109/ICSM.2013.93。
¹² Wasserman, Louis. 2013 年。 “可扩展的基于示例的重构与 Refaster。” 2013 年重构工具 ACM 研讨会论文集:25–28 doi:10.1145/2541348.2541355。
¹³ Miller, Matt. 2019 年。 “软件漏洞缓解领域的趋势、挑战和战略转变。” BlueHat IL。 https://goo.gl/vKM7uQ。
¹⁴ Kralevich, Nick. 2016 年。 “防御的艺术:漏洞如何塑造 Android 中的安全功能和缓解措施。” BlackHat。 https://oreil.ly/16rCq。
¹⁵ Liskov, Barbara 和 Stephen Zilles。 1974 年。 “使用抽象数据类型进行编程。” ACM SIGPLAN 非常高级语言研讨会论文集:50–59。 doi:10.1145/800233.807045。
¹⁶ 有关 JavaScript 和 Ruby 中更多的惊喜,请参见Gary Bernhardt 在 CodeMash 2012 的闪电演讲。
¹⁷ 参见 Eaddy, Mark. 2017 年。 “代码健康:对基元着迷?” https://oreil.ly/0DvJI。
第十三章:测试代码
原文:13. Testing Code
译者:飞龙
协议:CC BY-NC-SA 4.0
作者:Phil Ames 和 Franjo Ivančić
作者:Vera Haas 和 Jen Barnason
无论开发软件的工程师多么小心,都不可避免地会出现一些错误和被忽视的边缘情况。意外的输入组合可能会触发数据损坏或导致像 SRE 书的第 22 章中的“死亡查询”示例中的可用性问题。编码错误可能会导致安全问题,如缓冲区溢出和跨站脚本漏洞。简而言之,在现实世界中,软件容易出现许多故障。
本章讨论的技术在软件开发的不同阶段和环境中具有各种成本效益概况。例如,模糊测试——向系统发送随机请求——可以帮助您在安全性和可靠性方面加固系统。这种技术可能有助于捕捉信息泄漏,并通过暴露服务于大量边缘情况来减少服务错误。要识别无法轻松快速修补的系统中的潜在错误,您可能需要进行彻底的前期测试。
单元测试
单元测试可以通过在发布之前找出个别软件组件中的各种错误来提高系统安全性和可靠性。这种技术涉及将软件组件分解为没有外部依赖关系的更小、自包含的“单元”,然后对每个单元进行测试。单元测试由编写测试的工程师选择的不同输入来执行给定单元的代码组成。许多语言都有流行的单元测试框架;基于xUnit架构的系统非常常见。
遵循 xUnit 范例的框架允许通用的设置和拆卸代码与每个单独的测试方法一起执行。这些框架还定义了各个测试框架组件的角色和职责,有助于标准化测试结果格式。这样,其他系统就可以详细了解到底出了什么问题。流行的例子包括 Java 的 JUnit,C++的 GoogleTest,Golang 的 go2xunit,以及 Python 中内置的unittest模块。
示例 13-1 是使用 GoogleTest 框架编写的简单单元测试。
示例 13-1。使用 GoogleTest 框架编写检查提供的参数是否为质数的函数的单元测试
TEST(IsPrimeTest, Trivial) {
EXPECT_FALSE(IsPrime(0));
EXPECT_FALSE(IsPrime(1));
EXPECT_TRUE(IsPrime(2));
EXPECT_TRUE(IsPrime(3));
}
单元测试通常作为工程工作流程的一部分在本地运行,以便在开发人员提交更改到代码库之前为他们提供快速反馈。在持续集成/持续交付(CI/CD)流水线中,单元测试通常在提交合并到存储库的主干分支之前运行。这种做法旨在防止破坏其他团队依赖的行为的代码更改。
编写有效的单元测试
单元测试的质量和全面性可以显著影响软件的健壮性。单元测试应该快速可靠,以便工程师立即得到反馈,了解更改是否破坏了预期的行为。通过编写和维护单元测试,您可以确保工程师在添加新功能和代码时不会破坏相关测试覆盖的现有行为。如第九章所讨论的,您的测试还应该是隔离的——如果测试无法在隔离的环境中重复产生相同的结果,您就不能完全依赖测试结果。
考虑一个管理团队在给定数据中心或区域可以使用的存储字节数的系统。假设该系统允许团队在数据中心有可用的未分配字节时请求额外的配额。一个简单的单元测试可能涉及验证在由虚构团队部分占用的虚构集群中请求配额的情况,拒绝超出可用存储容量的请求。以安全为重点的单元测试可能检查涉及负字节数的请求是如何处理的,或者代码如何处理容量溢出,例如导致接近用于表示它们的变量类型的限制的大型转移。另一个单元测试可能检查系统在发送恶意或格式不正确的输入时是否返回适当的错误消息。
经常有用的是使用不同的参数或环境数据对相同的代码进行测试,例如我们示例中的初始起始配额使用情况。为了最小化重复的代码量,单元测试框架或语言通常提供一种以不同参数调用相同测试的方法。这种方法有助于减少重复的样板代码,从而使重构工作变得不那么乏味。
何时编写单元测试
一个常见的策略是在编写代码后不久编写测试,使用测试来验证代码的预期性能。这些测试通常与新代码一起提交,并且通常包括工程师手动检查的情况。例如,我们的示例存储管理应用程序可能要求“只有拥有服务的组的计费管理员才能请求更多的配额。”您可以将这种要求转化为几个单元测试。
在进行代码审查的组织中,同行审查者可以再次检查测试,以确保它们足够健壮,以维护代码库的质量。例如,审阅者可能会注意到,尽管新的测试伴随着变化,但即使删除或停用新代码,测试也可能通过。如果审阅者可以在新代码中用if (false)或if (true)替换类似if (condition_1 || condition_2)的语句,并且没有新的测试失败,那么测试可能已经忽略了重要的测试用例。有关 Google 自动化这种突变测试的经验的更多信息,请参见 Petrović和 Ivanković(2018)。^([2](ch13.html#ch13fn2))
测试驱动开发(TDD)方法鼓励工程师根据已建立的需求和预期行为在编写代码之前编写单元测试,而不是在编写代码之后编写测试。在测试新功能或错误修复时,测试将在行为完全实现之前失败。一旦功能实现并且测试通过,工程师就会进入下一个功能,然后该过程重复。
对于没有使用 TDD 模型构建的现有项目,通常会根据错误报告或积极努力增加对系统的信心来慢慢整合和改进测试覆盖率。但即使您实现了全面覆盖,您的项目也不一定是无错误的。未知的边缘情况或稀疏实现的错误处理仍可能导致不正确的行为。
您还可以根据内部手动测试或代码审查工作编写单元测试。您可能会在标准开发和审查实践中编写这些测试,或者在像发布前的安全审查这样的里程碑期间编写。新的单元测试可以验证建议的错误修复是否按预期工作,并且以后的重构不会重新引入相同的错误。如果代码难以理解并且潜在的错误会影响安全性,例如在编写具有复杂权限模型的系统中的访问控制检查时,这种类型的测试尤为重要。
注意
为了尽可能涵盖多种情景,你通常会花费更多时间编写测试而不是编写被测试的代码,特别是在处理非平凡系统时。这额外的时间从长远来看是值得的,因为早期测试会产生质量更高的代码库,减少需要调试的边缘情况。
单元测试如何影响代码
为了改进测试的全面性,你可能需要设计新的代码来包含测试规定,或者重构旧代码使其更易于测试。通常,重构涉及提供拦截对外部系统的调用的方法。利用这种内省能力,你可以以各种方式测试代码,例如验证代码调用拦截器的次数是否正确,或者使用正确的参数。
考虑一下如何测试一段代码,当满足某些条件时在远程问题跟踪器中打开票证。每次单元测试运行时创建一个真实的票证会产生不必要的噪音。更糟糕的是,如果问题跟踪系统不可用,这种测试策略可能会随机失败,违反了快速、可靠测试结果的目标。
要重构这段代码,你可以删除对问题跟踪服务的直接调用,并用一个抽象来替换这些调用,例如一个IssueTrackerService对象的接口。用于测试的实现可以在接收到“创建问题”等调用时记录数据,测试可以检查元数据以做出通过或失败的结论。相比之下,生产实现将连接到远程系统并调用公开的 API 方法。
这种重构大大减少了依赖于现实世界系统的测试的“不稳定性”。因为它们依赖于不能保证的行为,比如外部依赖性,或者从某些容器类型中检索项目时元素的顺序,不稳定的测试通常更像是一种麻烦而不是帮助。尽量在出现不稳定的测试时进行修复;否则,开发人员可能会养成在提交更改时忽略测试结果的习惯。
注意
这些抽象及其相应的实现被称为模拟、存根或伪装。工程师有时会将这些词用法混淆,尽管这些概念在实现复杂性和功能上有所不同,因此确保你的组织中的每个人都使用一致的词汇是很重要的。如果你进行代码审查或使用风格指南,你可以通过提供团队可以对齐的定义来帮助减少混淆。
很容易陷入过度抽象的陷阱,测试断言关于函数调用顺序或它们的参数的机械事实。过度抽象的测试通常并不提供太多价值,因为它们往往“测试”语言的控制流实现,而不是你关心的系统的行为。
如果每次方法更改时都必须完全重写测试,你可能需要重新考虑测试,甚至是系统本身的架构。为了避免不断重写测试,你可以考虑要求熟悉服务的工程师为任何非平凡的测试需求提供合适的虚拟实现。这种解决方案对于负责系统的团队和测试代码的工程师都是有利的:拥有抽象的团队可以确保它跟踪服务的功能集随着其发展的变化,而使用抽象的团队现在有了一个更真实的组件用于测试。
集成测试
集成测试超越了单个单元和抽象,用真实的实现替换了抽象的假或存根实现,如数据库或网络服务。因此,集成测试涵盖了更完整的代码路径。由于你必须初始化和配置这些其他依赖项,集成测试可能比单元测试更慢、更不稳定——执行测试时,这种方法会将网络延迟等真实世界变量纳入其中,因为服务端到端地进行通信。当你从测试代码的单个低级单元转移到测试它们在组合在一起时的交互方式时,最终结果是对系统行为符合预期的更高程度的信心。
集成测试采用不同的形式,这取决于它们所涉及的依赖项的复杂性。当集成测试需要的依赖相对简单时,集成测试可能看起来像一个设置了一些共享依赖项(例如,处于预配置状态的数据库)的基类,其他测试从中继承。随着服务复杂性的增加,集成测试可能变得更加复杂,需要监督系统来编排依赖项的初始化或设置,以支持测试。谷歌有专门致力于基础设施的团队,为常见的基础设施服务提供标准化的集成测试设置。对于使用像Jenkins这样的持续构建和交付系统的组织,集成测试可以根据代码库的大小和项目中可用测试的数量,与单元测试一起运行,或者单独运行。
注意
在构建集成测试时,请牢记第五章中讨论的原则:确保测试的数据和系统访问要求不会引入安全风险。诱人的做法是将实际数据库镜像到测试环境中,因为数据库提供了丰富的真实数据,但你应该避免这种反模式,因为它们可能包含敏感数据,将对使用这些数据库运行测试的任何人都可用。这种实现与最小特权原则不一致,可能会带来安全风险。相反,你可以使用非敏感的测试数据来填充这些系统。这种方法还可以轻松地将测试环境清除到已知的干净状态,减少集成测试不稳定性的可能性。
编写有效的集成测试
与单元测试一样,集成测试可能受到代码中设计选择的影响。继续我们之前关于问题跟踪器的例子,一个单元测试模拟可能只是断言该方法被调用以向远程服务提交一个问题。而集成测试更可能使用一个真实的客户端库。与其在生产中创建虚假的错误,集成测试会与 QA 端点进行通信。测试用例将使用触发对 QA 实例的调用的输入来执行应用逻辑。监督逻辑随后可以查询 QA 实例,以验证从端到端的角度成功地进行了外部可见的操作。
了解为什么集成测试失败,而所有单元测试都通过可能需要大量的时间和精力。在集成测试的关键逻辑交汇处进行良好的日志记录可以帮助你调试和理解故障发生的位置。还要记住,因为集成测试超越了单个单元,检查组件之间的交互,它们只能告诉你有关这些单元在其他场景中是否符合你的期望的有限信息。这是在开发生命周期中使用每种类型的测试的许多原因之一,因为一种测试通常不能替代另一种。
深入探讨:动态程序分析
程序分析允许用户执行许多有用的操作,例如性能分析、检查与安全相关的正确性、代码覆盖报告和死代码消除。正如本章后面讨论的那样,您可以静态地执行程序分析来研究软件而不执行它。在这里,我们关注动态方法。动态程序分析通过运行程序来分析软件,可能在虚拟化或模拟环境中,用于除了测试之外的目的。
性能分析器(用于发现程序中的性能问题)和代码覆盖报告生成器是最常见的动态分析类型。上一章介绍了动态程序分析工具Valgrind,它提供了一个虚拟机和各种工具来解释二进制代码,并检查执行是否存在各种常见的错误。本节重点介绍依赖于编译器支持(通常称为instrumentation)来检测与内存相关的错误的动态分析方法。
编译器和动态程序分析工具允许您配置仪器化,以收集编译器生成的二进制文件的运行时统计信息,例如性能分析信息、代码覆盖信息和基于配置的优化。当二进制文件执行时,编译器插入额外的指令和回调到后端运行时库,以显示和收集相关信息。在这里,我们关注 C/C++程序的安全相关内存误用错误。
Google Sanitizers 套件提供了基于编译的动态分析工具。它们最初作为LLVM编译器基础设施的一部分开发,用于捕获常见的编程错误,并且现在也得到了 GCC 和其他编译器的支持。例如,AddressSanitizer (ASan)可以在 C/C++程序中找到许多常见的与内存相关的错误,比如越界内存访问。其他流行的 sanitizers 包括以下内容:
UndefinedBehaviorSanitizer
执行未定义行为的运行时标记
ThreadSanitizer
检测竞争条件
MemorySanitizer
检测未初始化内存的读取
LeakSanitizer
检测内存泄漏和其他类型的泄漏
随着新的硬件功能允许对内存地址进行标记,有提案利用这些新功能进一步提高 ASan 的性能。
ASan 通过构建程序分析的自定义仪器化二进制文件来提供快速性能。在编译过程中,ASan 添加了某些指令,以便调用提供的 sanitizer 运行时。运行时维护有关程序执行的元数据,例如哪些内存地址是有效的访问。ASan 使用影子内存来记录给定字节对程序访问是否安全,并使用编译器插入的指令在程序尝试读取或写入该字节时检查影子内存。它还提供自定义内存分配和释放(malloc和free)实现。例如,malloc函数在返回请求的内存区域之前立即分配额外的内存。这创建了一个缓冲内存区域,使 ASan 能够轻松报告关于溢出和下溢的精确信息。为此,ASan 将这些区域(也称为red zones)标记为poisoned。同样,ASan 将已释放的内存标记为poisoned,使您能够轻松捕获使用后释放的错误。
以下示例说明了使用 Clang 编译器运行 ASan 的简单过程。shell 命令对具有使用后释放错误的特定输入文件进行插装和运行。当读取先前释放的内存区域的内存地址时,将发生使用后释放错误。安全漏洞可以利用这种类型的访问作为构建块。选项-fsanitize=address打开 ASan 插装:
$ cat -n use-after-free.c
1 #include <stdlib.h>
2 int main() {
3 char *x = (char*)calloc(10, sizeof(char));
4 free(x);
5 return x[5];
6 }
$ clang -fsanitize=address -O1 -fno-omit-frame-pointer -g use-after-free.c
编译完成后,当执行生成的二进制文件时,我们可以看到 ASan 生成的错误报告。(为了简洁起见,我们省略了完整的 ASan 错误消息。)请注意,ASan 允许错误报告指示源文件信息,例如行号,使用 LLVM 符号化程序,如 Clang 文档中的“符号化报告”部分所述。正如您在输出报告中所看到的,ASan 发现了一个 1 字节的使用后释放读取访问(已强调)。错误消息包括原始分配、释放和随后的非法使用的信息:
% ./a.out
=================================================================
==142161==ERROR: AddressSanitizer: heap-use-after-free on address 0x602000000015
at pc 0x00000050b550 bp 0x7ffc5a603f70 sp 0x7ffc5a603f68
READ of size 1 at 0x602000000015 thread T0
#0 0x50b54f in main use-after-free.c:5:10
#1 0x7f89ddd6452a in __libc_start_main
#2 0x41c049 in _start
0x602000000015 is located 5 bytes inside of 10-byte region [0x602000000010,0x60200000001a)
freed by thread T0 here:
#0 0x4d14e8 in free
#1 0x50b51f in main use-after-free.c:4:3
#2 0x7f89ddd6452a in __libc_start_main
previously allocated by thread T0 here:
#0 0x4d18a8 in calloc
#1 0x50b514 in main use-after-free.c:3:20
#2 0x7f89ddd6452a in __libc_start_main
SUMMARY: AddressSanitizer: heap-use-after-free use-after-free.c:5:10 in main
[...]
==142161==ABORTING
深入探讨:模糊测试
模糊测试(通常称为模糊测试)是一种补充先前提到的测试策略的技术。模糊测试涉及使用模糊引擎(或模糊器)生成大量候选输入,然后通过模糊驱动程序传递给模糊目标(处理输入的代码)。然后,模糊器分析系统如何处理输入。各种软件处理的复杂输入都是模糊测试的热门目标,例如文件解析器、压缩算法实现、网络协议实现和音频编解码器。
您还可以使用模糊测试来评估相同功能的不同实现。例如,如果您正在考虑从库 A 迁移到库 B,模糊器可以生成输入,将其传递给每个库进行处理,并比较结果。模糊器可以将任何不匹配的结果报告为“崩溃”,这有助于工程师确定可能导致微妙行为变化的原因。这种在不同输出上崩溃的操作通常作为模糊驱动程序的一部分实现,如在 OpenSSL 的BigNum 模糊器中所见。⁵
由于模糊测试可能会无限期地执行,因此不太可能阻止每次提交都要进行扩展测试的结果。这意味着当模糊器发现错误时,该错误可能已经被检入。理想情况下,其他测试或分析策略将首先防止错误发生,因此模糊测试通过生成工程师可能没有考虑到的测试用例来作为补充。作为额外的好处,另一个单元测试可以使用在模糊目标中识别错误的生成输入样本,以确保后续更改不会使修复退化。
模糊引擎的工作原理
模糊引擎的复杂性和精密度可以有所不同。在光谱的低端,一种通常称为愚蠢模糊的技术简单地从随机数生成器中读取字节,并将它们传递给模糊目标,以寻找错误。通过与编译器工具链的集成,模糊引擎变得越来越智能。它们现在可以利用先前讨论的编译器插装功能生成更有趣和有意义的样本。在工业实践中,使用尽可能多的模糊引擎集成到构建工具链中,并监视代码覆盖的百分比等指标被认为是一种良好的做法。如果代码覆盖在某个点停滞不前,通常值得调查为什么模糊器无法到达其他区域。
一些模糊引擎接受来自规范或语法的有趣关键字字典,这些规范或语法来自规范良好的协议、语言和格式(如 HTTP、SQL 和 JSON)。 模糊引擎可以生成可能被测试程序接受的输入,因为如果输入包含非法关键字,则生成的解析器代码可能会简单地拒绝输入。 提供字典可以增加通过模糊测试达到实际想要测试的代码的可能性。 否则,您可能最终会执行基于无效标记拒绝输入的代码,并且永远找不到任何有趣的错误。
像Peach Fuzzer这样的模糊引擎允许模糊驱动程序作者以编程方式定义输入的格式和字段之间的预期关系,因此模糊引擎可以生成违反这些关系的测试用例。 模糊引擎通常还接受一组示例输入文件,称为种子语料库,这些文件代表了被模糊化的代码所期望的内容。 然后,模糊引擎会改变这些种子输入,以及执行任何其他支持的输入生成策略。 一些软件包包含示例文件(例如音频库的 MP3 文件或图像处理的 JPEG 文件)作为其现有测试套件的一部分 - 这些示例文件非常适合作为种子语料库的候选文件。 否则,您可以从真实世界或手动生成的文件中策划种子语料库。 安全研究人员还会发布流行文件格式的种子语料库,例如以下提供的种子语料库:
-
OSS-Fuzz
-
模糊项目
-
美国模糊洛普(AFL)
近年来,编译器工具链的改进已经在使更智能的模糊引擎方面取得了重大进展。 对于 C/C++,例如 LLVM Clang 等编译器可以对代码进行仪器化(如前所述),以允许模糊引擎观察处理特定样本输入时执行的代码。 当模糊引擎找到新的代码路径时,它会保留触发代码路径的样本,并使用它们来生成未来的样本。 其他语言或模糊引擎可能需要特定的编译器 - 例如AFL的 afl-gcc 或go-fuzz 引擎的 go-fuzz-build,以正确跟踪执行路径以增加代码覆盖率。
当模糊引擎生成触发经过消毒处理的代码路径中的崩溃的输入时,它会记录输入以及从程序中提取的元数据,这些元数据包括诸如堆栈跟踪(指示触发崩溃的代码行)或进程在那个时间的内存布局等信息。 此信息为工程师提供了有关崩溃原因的详细信息,这有助于他们了解其性质、准备修复或优先处理错误。 例如,当组织考虑如何为不同类型的问题设置优先级时,内存读取访问违规可能被认为比写入访问违规不太重要。 这种优先级有助于建立安全和可靠的文化(参见第二十一章)。
当模糊引擎触发潜在错误时,程序对其做出反应的方式取决于各种各样的情况。 如果遇到错误会触发一致和明确定义的事件,例如接收信号或在发生内存损坏或未定义行为时执行特定函数,那么模糊引擎最有效地检测错误。 这些函数可以在系统达到特定错误状态时明确地向模糊引擎发出信号。 之前提到的许多消毒剂都是这样工作的。
一些模糊引擎还允许您为处理特定生成的输入设置一个上限时间。例如,如果死锁或无限循环导致输入超过时间限制,模糊器将把样本归类为“崩溃”。它还保存该样本以供进一步调查,以便开发团队可以防止可能导致服务不可用的 DoS 问题。
通过使用正确的模糊驱动程序和消毒剂,可以相对快速地识别导致 Web 服务器泄漏内存(包括包含 TLS 证书或 Cookie 的内存)的 Heartbleed 漏洞(CVE-2014-0160)。Google 的fuzzer-test-suite GitHub 存储库包含一个演示成功识别该漏洞的 Dockerfile 示例。以下是 Heartbleed 漏洞的 ASan 报告摘录,由消毒剂编译器插件插入的__asan_memcpy函数调用触发(重点添加):
==19==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x629000009748 at pc
0x0000004e59c9 bp 0x7ffe3a541360 sp 0x7ffe3a540b10
READ of size 65535 at 0x629000009748 thread T0
#0 0x4e59c8 in __asan_memcpy /tmp/final/llvm.src/projects/compiler-rt/lib/asan/asan_interceptors_memintrinsics.cc:23:3
#1 0x522e88 in tls1_process_heartbeat /root/heartbleed/BUILD/ssl/t1_lib.c:2586:3
#2 0x58f94d in ssl3_read_bytes /root/heartbleed/BUILD/ssl/s3_pkt.c:1092:4
#3 0x59418a in ssl3_get_message /root/heartbleed/BUILD/ssl/s3_both.c:457:7
#4 0x55f3c7 in ssl3_get_client_hello /root/heartbleed/BUILD/ssl/s3_srvr.c:941:4
#5 0x55b429 in ssl3_accept /root/heartbleed/BUILD/ssl/s3_srvr.c:357:9
#6 0x51664d in LLVMFuzzerTestOneInput /root/FTS/openssl-1.0.1f/target.cc:34:3
[...]
0x629000009748 is located 0 bytes to the right of 17736-byte region [0x629000005200,
0x629000009748)
allocated by thread T0 here:
#0 0x4e68e3 in __interceptor_malloc /tmp/final/llvm.src/projects/compiler-rt/lib/asan/asan_malloc_linux.cc:88:3
#1 0x5c42cb in CRYPTO_malloc /root/heartbleed/BUILD/crypto/mem.c:308:8
#2 0x5956c9 in freelist_extract /root/heartbleed/BUILD/ssl/s3_both.c:708:12
#3 0x5956c9 in ssl3_setup_read_buffer /root/heartbleed/BUILD/ssl/s3_both.c:770
#4 0x595cac in ssl3_setup_buffers /root/heartbleed/BUILD/ssl/s3_both.c:827:7
#5 0x55bff4 in ssl3_accept /root/heartbleed/BUILD/ssl/s3_srvr.c:292:9
#6 0x51664d in LLVMFuzzerTestOneInput /root/FTS/openssl-1.0.1f/target.cc:34:3
[...]
输出的第一部分描述了问题的类型(在本例中是“堆缓冲区溢出”——具体来说是读取访问违规)和一个易于阅读的符号化堆栈跟踪,指向读取超出分配的缓冲区大小的代码行。第二部分包含了有关附近内存区域的元数据,以及如何分配这些元数据,以帮助工程师分析问题并了解进程如何达到无效状态。
编译器和消毒剂仪器使这种分析成为可能。然而,这种仪器有限:当软件的某些部分是手写汇编以提高性能时,使用消毒剂进行模糊处理效果不佳。编译器无法对汇编代码进行仪器化,因为消毒剂插件在更高层操作。因此,未被仪器化的手写汇编代码可能会导致误报或未检测到的错误。
完全不使用消毒剂进行模糊处理是可能的,但会降低您检测无效程序状态和分析崩溃时可用的元数据的能力。例如,如果您不使用消毒剂,为了使模糊处理产生任何有用的信息,程序必须遇到“未定义行为”场景,然后将此错误状态通知外部模糊引擎(通常是通过崩溃或退出)。否则,未定义的行为将继续未被检测。同样,如果您不使用 ASan 或类似的仪器,您的模糊器可能无法识别内存已被损坏但未被使用以导致操作系统终止进程的状态。
如果您正在使用仅以二进制形式提供的库,编译器仪器化就不是一个选择。一些模糊引擎,如 American Fuzzy Lop,还与处理器模拟器(如 QEMU)集成,以在 CPU 级别仪器化有趣的指令。这种集成可能是一个吸引人的选择,用于模糊化需要模糊化的仅以二进制形式提供的库,但会降低速度。这种方法允许模糊引擎了解生成的输入可能触发的代码路径,但与使用编译器添加的消毒剂指令构建的源代码构建一样,它不提供太多的错误检测帮助。
许多现代模糊引擎,如libFuzzer、AFL和Honggfuzz,使用先前描述的技术的某种组合,或这些技术的变体。可以构建一个单一的模糊驱动程序,可以与多个模糊引擎一起使用。在使用多个模糊引擎时,最好确保定期将每个引擎生成的有趣输入样本移回其他模糊引擎配置为使用的种子语料库中。一个引擎可能成功地接受另一个引擎生成的输入,对其进行变异,并触发崩溃。
编写有效的模糊驱动程序
为了使这些模糊概念更具体,我们将更详细地介绍使用 LLVM 的 libFuzzer 引擎提供的框架编写模糊驱动程序的步骤,该引擎包含在 Clang 编译器中。这个特定的框架很方便,因为其他模糊引擎(如 Honggfuzz 和 AFL)也可以使用 libFuzzer 入口点。作为模糊器作者,使用这个框架意味着您只需要编写一个实现函数原型的驱动程序:
int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size);
随后的模糊引擎将生成字节序列并调用您的驱动程序,该驱动程序可以将输入传递给您想要测试的代码。
模糊引擎的目标是通过驱动尽快执行模糊目标,并生成尽可能多的独特和有趣的输入。为了实现可重现的崩溃和快速模糊,请尽量避免在模糊驱动程序中出现以下情况:
-
非确定性行为,比如依赖随机数生成器或特定的多线程行为。
-
慢操作,如控制台日志记录或磁盘 I/O。相反,考虑创建“模糊器友好”的构建,禁用这些慢操作,或者使用基于内存的文件系统。
-
故意崩溃。模糊测试的理念是找到你没有意图发生的崩溃。模糊引擎无法区分故意的崩溃。
这些属性对于本章描述的其他类型的测试也可能是理想的。
您还应该避免任何对手可以在生成的输入样本中“修复”的专门完整性检查(如 CRC32 或消息摘要)。模糊引擎不太可能生成有效的校验和,并在没有专门逻辑的情况下通过完整性检查。一个常见的约定是使用编译器预处理器标志,如-DFUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION,以启用这种模糊器友好的行为,并帮助通过模糊测试识别出的崩溃。
一个示例模糊器
本节遵循编写一个名为Knusperli的简单开源 C++库的模糊器的步骤。Knusperli 是一个 JPEG 解码器,如果它对用户上传的内容进行编码或处理来自网络的图像(包括潜在的恶意图像),可能会看到各种各样的输入。
Knusperli 还为我们提供了一个方便的接口来进行模糊测试:一个接受字节序列(JPEG)和大小参数的函数,以及一个控制解析图像的哪些部分的参数。对于不提供这样直接接口的软件,您可以使用辅助库,如FuzzedDataProvider,来帮助将字节序列转换为目标接口的有用值。我们的示例模糊驱动程序针对这个函数。
bool ReadJpeg(const uint8_t* data, const size_t len, JpegReadMode mode,
JPEGData* jpg);
Knusperli 使用Bazel 构建系统。通过修改*.bazelrc*文件,您可以创建一个方便的快捷方式来使用各种消毒剂构建目标,并直接构建基于 libFuzzer 的模糊器。以下是 ASan 的示例:
$ cat ~/.bazelrc
build:asan --copt -fsanitize=address --copt -O1 --copt -g -c dbg
build:asan --linkopt -fsanitize=address --copt -O1 --copt -g -c dbg
build:asan --copt -fno-omit-frame-pointer --copt -O1 --copt -g -c dbg
在这一点上,您应该能够构建启用了 ASan 的工具版本:
$ CC=clang-6.0 CXX=clang++-6.0 bazel build --config=asan :knusperli
您还可以为我们即将编写的模糊器在BUILD文件中添加规则:
cc_binary(
name = "fuzzer",
srcs = [
"jpeg_decoder_fuzzer.cc",
],
deps = [
":jpeg_data_decoder",
":jpeg_data_reader",
],
linkopts = ["-fsanitize=address,fuzzer"],
)
示例 13-2 展示了模糊驱动程序的简单尝试可能是什么样子。
示例 13-2. jpeg_decoder_fuzzer.cc
1 #include <cstddef>
2 #include <cstdint>
3 #include "jpeg_data_decoder.h"
4 #include "jpeg_data_reader.h"
5
6 extern "C" int LLVMFuzzerTestOneInput(const uint8_t *data, size_t sz) {
7 knusperli::JPEGData jpg;
8 knusperli::ReadJpeg(data, sz, knusperli::JPEG_READ_HEADER, &jpg);
9 return 0;
10 }
我们可以使用以下命令构建和运行模糊驱动程序:
$ CC=clang-6.0 CXX=clang++-6.0 bazel build --config=asan :fuzzer
$ mkdir synthetic_corpus
$ ASAN_SYMBOLIZER_PATH=/usr/lib/llvm-6.0/bin/llvm-symbolizer bazel-bin/fuzzer \
-max_total_time 300 -print_final_stats synthetic_corpus/
上述命令在使用空输入语料库的情况下运行模糊器五分钟。LibFuzzer 将有趣的生成样本放在*synthetic_corpus/*目录中,以便在未来的模糊会话中使用。您将收到以下结果:
[...]
INFO: 0 files found in synthetic_corpus/
INFO: -max_len is not provided; libFuzzer will not generate inputs larger than
4096 bytes
INFO: A corpus is not provided, starting from an empty corpus
#2 INITED cov: 110 ft: 111 corp: 1/1b exec/s: 0 rss: 36Mb
[...]
#3138182 DONE cov: 151 ft: 418 corp: 30/4340b exec/s: 10425 rss: 463Mb
[...]
Done 3138182 runs in 301 second(s)
stat::number_of_executed_units: 3138182
stat::average_exec_per_sec: 10425
stat::new_units_added: 608
stat::slowest_unit_time_sec: 0
stat::peak_rss_mb: 463
添加 JPEG 文件(例如,在广播电视上看到的彩条图案)到种子语料库中也会带来改进。这个单一的种子输入带来了执行的代码块的>10%的改进(cov指标):
#2 INITED cov: 169 ft: 170 corp: 1/8632b exec/s: 0 rss: 37Mb
为了进一步达到更多的代码,我们可以使用不同的值来设置JpegReadMode参数。有效值如下:
enum JpegReadMode {
JPEG_READ_HEADER, *// only basic headers*
JPEG_READ_TABLES, *// headers and tables (quant, Huffman, ...)*
JPEG_READ_ALL, *// everything*
};
与编写三种不同的模糊器不同,我们可以对输入的子集进行哈希处理,并使用该结果在单个模糊器中执行不同组合的库特性。要小心使用足够的输入来创建多样化的哈希输出。如果文件格式要求输入的前N个字节都看起来相同,那么在决定哪些字节会影响设置哪些选项时,请至少使用比N多一个的字节。
其他方法包括使用先前提到的FuzzedDataProvider来分割输入,或者将输入的前几个字节专门用于设置库参数。然后,剩余的字节作为输入传递给模糊目标。与对输入进行哈希处理可能会导致不同的配置,如果单个输入位发生变化,那么将输入拆分的替代方法允许模糊引擎更好地跟踪所选选项与代码行为方式之间的关系。要注意这些不同方法如何影响潜在现有种子输入的可用性。在这种情况下,想象一下,通过决定依赖前几个输入字节来设置库的选项,您可以创建一个新的伪格式。结果,除非您首先对文件进行预处理以添加初始参数,否则您将不再能够轻松地使用世界上所有现有的 JPEG 文件作为可能的种子输入。
为了探索将库配置为生成输入样本的函数的想法,我们将使用输入的前 64 个字节中设置的位数来选择JpegReadMode,如示例 13-3 所示。
示例 13-3。通过拆分输入进行模糊
#include <cstddef>
#include <cstdint>
#include "jpeg_data_decoder.h"
#include "jpeg_data_reader.h"
const unsigned int kInspectBytes = 64;
const unsigned int kInspectBlocks = kInspectBytes / sizeof(unsigned int);
extern "C" int LLVMFuzzerTestOneInput(const uint8_t *data, size_t sz) {
knusperli::JPEGData jpg;
knusperli::JpegReadMode rm;
unsigned int bits = 0;
if (sz <= kInspectBytes) { *// Bail on too-small inputs.*
return 0;
}
for (unsigned int block = 0; block < kInspectBlocks; block++) {
bits +=
__builtin_popcount(reinterpret_cast<const unsigned int *>(data)[block]);
}
rm = static_cast<knusperli::JpegReadMode>(bits %
(knusperli::JPEG_READ_ALL + 1));
knusperli::ReadJpeg(data, sz, rm, &jpg);
return 0;
}
当将彩色条作为唯一的输入语料库使用五分钟时,这个模糊器给出了以下结果:
#851071 DONE cov: 196 ft: 559 corp: 51/29Kb exec/s: 2827 rss: 812Mb
[...]
Done 851071 runs in 301 second(s)
stat::number_of_executed_units: 851071
stat::average_exec_per_sec: 2827
stat::new_units_added: 1120
stat::slowest_unit_time_sec: 0
stat::peak_rss_mb: 812
每秒执行次数下降了,因为更改使库的更多特性生效,导致这个模糊驱动器达到了更多代码(由上升的cov指标表示)。如果您在没有任何超时限制的情况下运行模糊器,它将继续无限期地生成输入,直到代码触发了一个消毒器错误条件。在那时,您将看到一个类似于之前显示的 Heartbleed 漏洞的报告。然后,您可以进行代码更改,重新构建,并运行您使用保存的工件构建的模糊器二进制文件,以重现崩溃或验证代码更改是否会修复问题。
持续模糊
一旦您编写了一些模糊器,定期在代码库上运行它们可以为工程师提供宝贵的反馈循环。持续构建管道可以在您的代码库中生成每日构建的模糊器,以供运行模糊器、收集崩溃信息并在问题跟踪器中提交错误。工程团队可以利用结果来专注于识别漏洞或消除导致服务未达到 SLO 的根本原因。
示例:ClusterFuzz 和 OSSFuzz
ClusterFuzz是由 Google 发布的可扩展模糊基础设施的开源实现。它管理运行模糊任务的虚拟机池,并提供一个 Web 界面来查看有关模糊器的信息。ClusterFuzz 不构建模糊器,而是期望持续构建/集成管道将模糊器推送到 Google Cloud Storage 存储桶。它还提供诸如语料库管理、崩溃去重和崩溃的生命周期管理等服务。ClusterFuzz 用于崩溃去重的启发式是基于崩溃时程序的状态。通过保留导致崩溃的样本,ClusterFuzz 还可以定期重新测试这些问题,以确定它们是否仍然重现,并在最新版本的模糊器不再在有问题的样本上崩溃时自动关闭问题。
ClusterFuzz 网络界面显示了您可以使用的指标,以了解给定模糊器的性能如何。可用的指标取决于构建流水线中集成的模糊引擎导出的内容(截至 2020 年初,ClusterFuzz 支持 libFuzzer 和 AFL)。ClusterFuzz 文档提供了从使用 Clang 代码覆盖支持构建的模糊器中提取代码覆盖信息的说明,然后将该信息转换为可以存储在 Google Cloud Storage 存储桶中并在前端显示的格式。使用此功能来探索上一节中编写的模糊器覆盖的代码将是确定输入语料库或模糊驱动程序的其他改进的下一个良好步骤。
OSS-Fuzz将现代模糊技术与托管在谷歌云平台上的可扩展分布式 ClusterFuzz 执行相结合。它发现安全漏洞和稳定性问题,并直接向开发人员报告——自 2016 年 12 月推出以来的五个月内,OSS-Fuzz 已经发现了一千多个错误,自那时以来,它已经发现了成千上万个错误。
一旦项目与 OSS-Fuzz 集成,该工具就会使用持续和自动化测试,在修改的代码引入上游存储库后的几小时内发现问题,而不会影响任何用户。在谷歌,通过统一和自动化我们的模糊工具,我们已经将我们的流程整合到基于 OSS-Fuzz 的单个工作流程中。这些集成的 OSS 项目还受益于谷歌内部工具和外部模糊工具的审查。我们的集成方法增加了代码覆盖率,并更快地发现错误,改善了谷歌项目和开源生态系统的安全状况。
深入探讨:静态程序分析
静态分析是一种分析和理解计算机程序的方法,它通过检查其源代码而不执行或运行它们。静态分析器解析源代码并构建适合自动化分析的程序的内部表示。这种方法可以在源代码中发现潜在的错误,最好是在代码被检入或部署到生产环境之前。许多工具可用于各种语言,以及用于跨语言分析的工具。
静态分析工具在分析深度与分析源代码成本之间做出不同的权衡。例如,最浅的分析器执行简单的文本或基于抽象语法树(AST)的模式匹配。其他技术依赖于对程序的基于状态的语义构造进行推理,并基于程序的控制流和数据流进行推理。
工具还针对分析误报(错误警告)和漏报(遗漏警告)之间的不同分析权衡。权衡是不可避免的,部分原因是静态分析的基本限制:静态验证任何程序都是一个不可判定的问题——也就是说,不可能开发出一个能够确定任何给定程序是否会执行而不违反任何给定属性的算法。
鉴于这一约束,工具提供商专注于在开发的各个阶段为开发人员生成有用的信号。根据静态分析引擎的集成点,对于分析速度和预期分析反馈的不同权衡是可以接受的。例如,集成在代码审查系统中的静态分析工具可能只针对新开发的源代码,并会发出专注于非常可能的问题的精确警告。另一方面,正在进行最终的预部署发布分析的源代码(例如,用于航空电子软件或具有潜在政府认证要求的医疗设备软件等领域)可能需要更正式和更严格的分析。⁶
以下部分介绍了针对开发过程不同阶段的各种需求而调整的静态分析技术。我们重点介绍了自动化代码检查工具、基于抽象解释的工具(有时这个过程被称为深度静态分析)以及更消耗资源的方法,比如形式化方法。我们还讨论了如何将静态分析器集成到开发人员的工作流程中。
自动化代码检查工具
自动化代码检查工具针对语言特性和使用规则对源代码进行了句法分析。这些工具通常被称为linters,通常不对程序的复杂行为进行建模,比如过程间数据流。由于它们执行的分析相对较浅,这些工具很容易扩展到任意大小的代码——它们通常可以在大约相同的时间内完成源代码分析,就像编译代码一样。代码检查工具也很容易扩展——您可以简单地添加涵盖许多类型错误的新规则,特别是与语言特性相关的错误。
在过去几年中,代码检查工具已经专注于风格和可读性的改变,因为这些代码改进建议被开发人员高度接受。许多组织默认强制执行风格和格式检查,以便在大型开发团队中维护一个更易管理的统一代码库。这些组织还定期运行检查,以揭示潜在的代码异味和高度可能的错误。
以下示例侧重于执行一种特定类型的分析的工具——AST 模式匹配。 AST是程序源代码的树形表示,基于编程语言的句法结构。编译器通常将给定的源代码输入文件解析为这样的表示,并在编译过程中操纵该表示。例如,AST 可能包含一个表示if-then-else结构的节点,该节点有三个子节点:一个节点用于if语句的条件,一个节点表示then分支的子树,另一个节点表示else分支的子树。
Error Prone用于 Java,Clang-Tidy用于 C/C++在 Google 的项目中被广泛使用。这两种分析器都允许工程师添加自定义检查。例如,截至 2018 年初,已有 162 位作者提交了 733 个 Error Prone 检查。对于某些类型的错误,Error Prone 和 Clang-Tidy 都可以提出建议的修复方案。一些编译器(如 Clang 和 MSVC)还支持社区开发的C++核心指南。借助指南支持库(GSL)的帮助,这些指南可以防止 C++程序中的许多常见错误。
AST 模式匹配工具允许用户通过编写对解析 AST 的规则来添加新的检查。例如,考虑absl-string-find-startsWith Clang-Tidy 警告。该工具试图改进使用 C++ string::find API检查字符串前缀匹配的代码的可读性和性能:Clang-Tidy 建议改用ABSL提供的StartsWith API。为了执行其分析,该工具创建了一个 AST 子树模式,比较了 C++ string::find API 的输出与整数值 0。Clang-Tidy 基础设施提供了在被分析程序的 AST 表示中找到 AST 子树模式的工具。
考虑以下代码片段:
std::string s = "...";
if (s.find("Hello World") == 0) { /* do something */ }
absl-string-find-startsWith Clang-Tidy 警告标记了这段代码,并建议以以下方式更改代码:
std::string s = "...";
if (absl::StartsWith(s, "Hello World")) { /* do something */ }
为了提出修复建议,Clang-Tidy(从概念上讲)提供了根据模式转换 AST 子树的能力。图 13-1 的左侧显示了 AST 模式匹配。(为了清晰起见,AST 子树进行了简化。)如果工具在源代码的解析 AST 树中找到匹配的 AST 子树,它会通知开发人员。AST 节点还包含行和列信息,这使得 AST 模式匹配器能够向开发人员报告特定的警告。

图 13-1. AST 模式匹配和替换建议
除了性能和可读性检查外,Clang-Tidy 还提供了许多常见的错误模式检查。考虑在以下输入文件上运行 Clang-Tidy:⁷
$ cat -n sizeof.c
1 #include <string.h>
2 const char* kMessage = "Hello World!";
3 int main() {
4 char buf[128];
5 memcpy(buf, kMessage, sizeof(kMessage));
6 return 0;
7 }
$ clang-tidy sizeof.c
[...]
Running without flags.
1 warning generated.
sizeof.c:5:32: warning: 'memcpy' call operates on objects of type 'const char'
while the size is based on a different type 'const char *'
[clang-diagnostic-sizeof-pointer-memaccess]
memcpy(buf, kMessage, sizeof(kMessage));
^
sizeof.c:5:32: note: did you mean to provide an explicit length?
memcpy(buf, kMessage, sizeof(kMessage));
$ cat -n sizeof2.c
1 #include <string.h>
2 const char kMessage[] = "Hello World!";
3 int main() {
4 char buf[128];
5 memcpy(buf, kMessage, sizeof(kMessage));
6 return 0;
7 }
$ clang-tidy sizeof2.c
[...]
Running without flags.
这两个输入文件只在kMessage的类型声明上有所不同。当kMessage被定义为指向初始化内存的指针时,sizeof(kMessage)返回指针类型的大小。因此,Clang-Tidy 产生了clang-diagnostic-sizeof-pointer-memaccess警告。另一方面,当kMessage的类型为const char[]时,sizeof(kMessage)操作返回适当的预期长度,Clang-Tidy 不会产生警告。
对于某些模式检查,除了报告警告外,Clang-Tidy 还可以建议代码修复。前面提到的absl-string-find-startsWith Clang-Tidy 警告建议就是这样一个例子。图 13-1 的右侧显示了适当的 AST 级别替换。当这样的建议可用时,您可以告诉 Clang-Tidy 自动将它们应用到输入文件中,使用--fix命令行选项。
您还可以使用自动应用的建议来使用 Clang-Tidy 的modernize修复更新代码库。考虑以下命令序列,其中展示了modernize-use-nullptr模式。该序列查找了用于指针赋值或比较的零常量的实例,并将它们更改为使用nullptr。为了运行所有modernize检查,我们使用 Clang-Tidy 选项--checks=modernize-*;然后--fix将建议应用到输入文件。在命令序列的末尾,我们通过打印转换后的文件来突出显示这四个更改(已强调):
$ cat -n nullptr.cc
1 #define NULL 0x0
2
3 int *ret_ptr() {
4 return 0;
5 }
6
7 int main() {
8 char *a = NULL;
9 char *b = 0;
10 char c = 0;
11 int *d = ret_ptr();
12 return d == NULL ? 0 : 1;
13 }
$ clang-tidy nullptr.cc -checks=modernize-* --fix
[...]
Running without flags.
4 warnings generated.
nullptr.cc:4:10: warning: use nullptr [modernize-use-nullptr]
return 0;
^
nullptr
nullptr.cc:4:10: note: FIX-IT applied suggested code changes
return 0;
^
nullptr.cc:8:13: warning: use nullptr [modernize-use-nullptr]
char *a = NULL;
^
nullptr
nullptr.cc:8:13: note: FIX-IT applied suggested code changes
char *a = NULL;
^
nullptr.cc:9:13: warning: use nullptr [modernize-use-nullptr]
char *b = 0;
^
nullptr
nullptr.cc:9:13: note: FIX-IT applied suggested code changes
char *b = 0;
^
nullptr.cc:12:15: warning: use nullptr [modernize-use-nullptr]
return d == NULL ? 0 : 1;
^
nullptr
nullptr.cc:12:15: note: FIX-IT applied suggested code changes
return d == NULL ? 0 : 1;
^
clang-tidy applied 4 of 4 suggested fixes.
$ cat -n nullptr.cc
1 #define NULL 0x0
2
3 int *ret_ptr() {
4 return nullptr;
5 }
6
7 int main() {
8 char *a = nullptr;
9 char *b = nullptr;
10 char c = 0;
11 int *d = ret_ptr();
12 return d == nullptr ? 0 : 1;
13 }
其他语言也有类似的自动化代码检查工具。例如,GoVet分析 Go 源代码中常见的可疑结构,Pylint分析 Python 代码,Error Prone 为 Java 程序提供分析和自动修复能力。以下示例简要演示了通过 Bazel 构建规则运行 Error Prone(已强调)。在 Java 中,对Short类型的变量i进行减法操作i-1会返回int类型的值。因此,remove操作不可能成功:
$ cat -n ShortSet.java
1 import java.util.Set;
2 import java.util.HashSet;
3
4 public class ShortSet {
5 public static void main (String[] args) {
6 Set<Short> s = new HashSet<>();
7 for (short i = 0; i < 100; i++) {
8 s.add(i);
9 s.remove(i - 1);
10 }
11 System.out.println(s.size());
12 }
13 }
$ bazel build :hello
ERROR: example/myproject/BUILD:29:1: Java compilation in rule '//example/myproject:hello'
ShortSet.java:9: error: [CollectionIncompatibleType] Argument 'i - 1' should not be
passed to this method;
its type int is not compatible with its collection's type argument Short
s.remove(i - 1);
^
(see http://errorprone.info/bugpattern/CollectionIncompatibleType)
1 error
将静态分析集成到开发者工作流程中
尽早在开发周期中运行相对快速的静态分析工具被认为是良好的行业实践。早期发现错误很重要,因为如果将它们推送到源代码存储库或部署给用户,修复它们的成本会大大增加。
将静态分析工具集成到 CI/CD 流水线中的门槛很低,对工程师的生产力可能会产生很高的积极影响。例如,开发人员可以收到有关如何修复空指针解除引用的错误和建议。如果他们无法推送他们的代码,他们就不会忘记修复问题并意外地导致系统崩溃或暴露信息,这有助于建立安全和可靠的文化(见第二十一章)。
为此,谷歌开发了 Tricorder 程序分析平台⁸和 Tricorder 的开源版本Shipshape。Tricorder 每天对大约 50,000 个代码审查更改进行静态分析。该平台运行许多类型的程序分析工具,并在代码审查期间向开发人员显示警告,当时他们习惯于评估建议。这些工具旨在提供易于理解和易于修复的代码发现,用户感知的误报率低(最多为 10%)。
Tricorder 旨在允许用户运行许多不同的程序分析工具。截至 2018 年初,该平台包括 146 个分析器,涵盖 30 多种源语言。其中大多数分析器是由谷歌开发人员贡献的。一般来说,通常可用的静态分析工具并不是非常复杂。Tricorder 运行的大多数检查器都是自动化的代码检查工具。这些工具针对各种语言,检查是否符合编码风格指南,并查找错误。如前所述,Error Prone 和 Clang-Tidy 在某些情况下可以提供建议的修复方法。代码作者随后可以通过点击按钮应用修复。
图 13-2 显示了给定 Java 输入文件的 Tricorder 分析结果的屏幕截图,呈现给代码审查人员。结果显示了两个警告,一个来自 Java linter,一个来自 Error Prone。Tricorder 通过允许代码审查人员通过“无用”链接对出现的警告提供反馈来衡量用户感知的误报率。Tricorder 团队使用这些信号来禁用个别检查。代码审查人员还可以向代码作者发送“请修复”个别警告的请求。
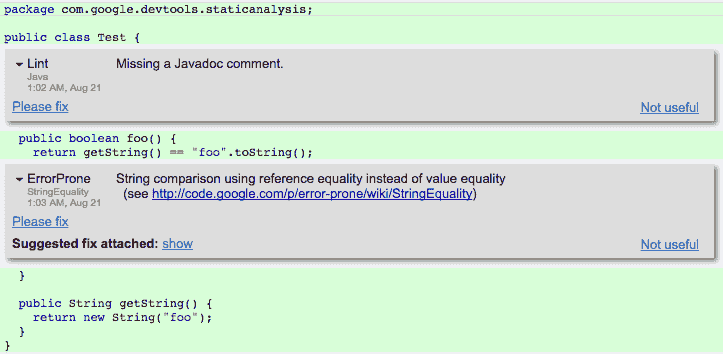
图 13-2:通过 Tricorder 提供的代码审查期间的静态分析结果的屏幕截图
图 13-3 显示了在代码审查期间由 Error Prone 建议的自动应用的代码更改。
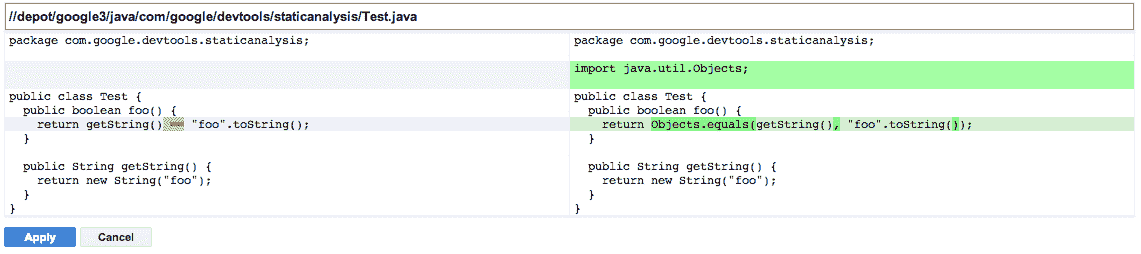
图 13-3:来自图 13-2 的 Error Prone 警告的预览修复视图的屏幕截图
抽象解释
基于抽象解释的工具静态地执行程序行为的语义分析。这种技术已成功用于验证关键安全软件,如飞行控制软件。考虑一个简单的例子,一个程序生成 10 个最小的正偶数。在正常执行期间,程序生成整数值 2、4、6、8、10、12、14、16、18 和 20。为了允许对这样一个程序进行高效的静态分析,我们希望使用一个紧凑的表示来总结所有可能的值,覆盖所有观察到的值。使用所谓的区间或范围域,我们可以代表所有观察到的值,使用抽象区间值[2, 20]。区间域允许静态分析器通过简单地记住最低和最高可能的值来高效地推理所有程序执行。
为了确保我们捕捉到所有可能的程序行为,重要的是用抽象表示覆盖所有观察到的值。然而,这种方法也引入了可能导致不精确或错误警告的近似。例如,如果我们想要保证实际程序永远不会产生值 11,使用整数域的分析将导致一个错误的阳性。
利用抽象解释的静态分析器通常为每个程序点计算一个抽象值。为此,它们依赖于程序的控制流图(CFG)表示。CFG 在编译器优化和静态分析程序中通常被使用。CFG 中的每个节点代表程序中的一个基本块,对应于按顺序执行的程序语句序列。也就是说,在这个语句序列中没有跳转,也没有跳转目标在序列中间。CFG 中的边代表程序中的控制流,其中跳转发生在程序内部的控制流(例如,由于if语句或循环结构)或由于函数调用的程序间的控制流。请注意,CFG 表示也被覆盖引导的模糊器(之前讨论过)使用。例如,libFuzzer 跟踪在模糊过程中覆盖的基本块和边。模糊器使用这些信息来决定是否考虑将输入用于未来的变异。
基于抽象解释的工具执行关于程序中数据流和控制流的语义分析,通常跨越函数调用。因此,它们的运行时间比之前讨论的自动化代码检查工具要长得多。虽然你可以将自动化代码检查工具集成到交互式开发环境中,比如代码编辑器,但抽象解释通常不会被类似地集成。相反,开发人员可能会偶尔(比如每晚)在提交的代码上运行基于抽象解释的工具,或者在差异设置中进行代码审查,分析只有改变的代码,同时重用未改变的代码的分析事实。
许多工具依赖于抽象解释来处理各种语言和属性。例如,Frama-C 工具允许您查找 C 语言程序中的常见运行时错误和断言违规,包括缓冲区溢出、由于悬空或空指针导致的分段错误以及除零。正如之前讨论的那样,这些类型的错误,特别是与内存相关的错误,可能具有安全影响。Infer 工具推理程序执行的内存和指针更改,并可以在 Java、C 和其他语言中找到悬空指针等错误。AbsInt 工具可以对实时系统中任务的最坏执行时间进行分析。应用安全改进(ASI)程序对上传到 Google Play 商店的每个 Android 应用进行复杂的过程间分析,以确保安全性。如果发现漏洞,ASI 会标记漏洞并提出解决问题的建议。图 13-4 显示了一个样本安全警报。截至 2019 年初,该程序已导致 Play 商店中超过 300,000 个应用开发者修复了超过 100 万个应用。

图 13-4:应用安全改进警报
形式化方法
形式化方法允许用户指定对软件或硬件系统感兴趣的属性。其中大多数是所谓的安全属性,指定某种不良行为不应该被观察到。例如,“不良行为”可以包括程序中的断言。其他包括活性属性,允许用户指定期望的结果,例如提交的打印作业最终由打印机处理。形式化方法的用户可以验证特定系统或模型的这些属性,甚至使用基于正确构造的方法开发这些系统。正如“分析不变量”中所强调的,基于形式化方法的方法通常具有相对较高的前期成本。这部分是因为这些方法需要对系统要求和感兴趣的属性进行先验描述。这些要求必须以数学严谨和形式化的方式进行规定。
基于形式化方法的技术已成功整合到硬件设计和验证工具中。¹¹在硬件设计中,使用电子设计自动化(EDA)供应商提供的形式化或半形式化工具现在是标准做法。这些技术也已成功应用于专门领域的软件,如安全关键系统或加密协议分析。例如,基于形式化方法的方法不断分析计算机网络通信中 TLS 使用的加密协议。¹²
结论
测试软件的安全性和可靠性是一个广泛的话题,我们只是触及了表面。本章介绍的测试策略,结合编写安全代码的实践(参见第十二章),对帮助谷歌团队可靠扩展、最小化停机时间和安全问题起到了关键作用。从开发的最早阶段就考虑可测试性,并在整个开发生命周期中进行全面测试是非常重要的。
在这一点上,我们要强调将所有这些测试和分析方法完全整合到您的工程工作流程和 CI/CD 流水线中的价值。通过在整个代码库中一致地结合和定期使用这些技术,您可以更快地识别错误。您还将提高在部署应用程序时检测或预防错误的能力,这是下一章将涵盖的主题。
-
1 我们建议查看SRE 书的第十七章,以获得一个以可靠性为重点的视角。
-
2 Petrović,Goran 和 Marko Ivanković。2018 年。“Google 的突变测试现状。” 第 40 届国际软件工程大会论文集:163-171。doi:10.1145/3183519.3183521。
-
3 有关在 Google 遇到的常见单元测试陷阱的更多讨论,请参阅 Wright,Hyrum 和 Titus Winters。2015 年。“你所有的测试都很糟糕:来自前线的故事。” CppCon 2015。https://oreil.ly/idleN。
-
4 请参阅SRE 工作手册的第二章。
-
5 模糊目标比较 OpenSSL 内部两个模块化指数实现的结果,如果结果有任何不同,将会失败。
-
6 例如,参见 Bozzano,Marco 等人。2017 年。“航空航天系统的形式方法。”在从架构分析视角设计物理系统,由 Shin Nakajima,Jean-Pierre Talpin,Masumi Toyoshima 和 Huafeng Yu 编辑。新加坡:Springer。
-
7 您可以使用标准软件包管理器安装 Clang-Tidy。通常称为 clang-tidy。
-
8 请参阅 Sadowski,Caitlin 等人。2018 年。“在 Google 构建静态分析工具的经验教训。” ACM 通讯 61(4):58-66。doi:10.1145/3188720。
-
9 请参阅 Cousot,Patrick 和 Radhia Cousot。1976 年。“程序动态属性的静态确定。” 第 2 届国际编程研讨会论文集:106-130。https://oreil.ly/4xLgB。
-
10 Souyris,Jean 等人。2009 年。“航空电子软件产品的形式验证。” 第 2 届形式方法世界会议论文集:532-546。doi:10.1007/978-3-642-05089-3_34。
-
11 例如,参见 Kern,Christoph 和 Mark R. Greenstreet。1999 年。“硬件设计中的形式验证:一项调查。” ACM 电子系统设计交易 4(2):123-193。doi:10.1145/307988.307989。另请参见 Hunt Jr.等人。2017 年。“使用 ACL2 进行工业硬件和软件验证。” 皇家学会哲学交易 A 数学物理和工程科学 375(2104):20150399。doi:10.1098/rsta.2015.0399。
-
12 请参阅 Chudnov,Andrey 等人。2018 年。“Amazon s2n 的持续形式验证。” 第 30 届国际计算机辅助验证会议论文集:430-446。doi:10.1007/978-3-319-96142-2_26。
第十四章:部署代码
原文:14. Deploying Code
译者:飞龙
协议:CC BY-NC-SA 4.0
作者:Jeremiah Spradlin 和 Mark Lodato
与 Sergey Simakov 和 Roxana Loza
在编写和测试代码时,前几章讨论了如何考虑安全性和可靠性。然而,直到代码构建和部署之后,该代码才会产生真正的影响。因此,对构建和部署过程的所有元素仔细考虑安全性和可靠性非常重要。仅通过检查构件本身很难确定部署的构件是否安全。软件供应链各个阶段的控制可以增加您对软件构件安全性的信心。例如,代码审查可以减少错误的机会,并阻止对手进行恶意更改,自动化测试可以增加您对代码操作正确性的信心。
围绕源代码、构建和测试基础设施构建的控制具有有限的效果,如果对手可以通过直接部署到您的系统来绕过它们。因此,系统应拒绝不是来自正确软件供应链的部署。为了满足这一要求,供应链中的每个步骤都必须能够提供其已正确执行的证据。
概念和术语
我们使用术语软件供应链来描述编写、构建、测试和部署软件系统的过程。这些步骤包括版本控制系统(VCS)、持续集成(CI)流水线和持续交付(CD)流水线的典型责任。
尽管实现细节在公司和团队之间有所不同,但大多数组织都有一个类似于图 14-1 的流程:
-
代码必须检入版本控制系统。
-
然后从检入的版本构建代码。
-
一旦构建完成,二进制文件必须经过测试。
-
然后将代码部署到某个环境中,进行配置和执行。

图 14-1:典型软件供应链的高层视图
即使您的供应链比这个模型更复杂,您通常也可以将其分解为这些基本构建块。图 14-2 显示了典型部署流水线如何执行这些步骤的具体示例。
您应该设计软件供应链以减轻对系统的威胁。本章重点介绍了如何减轻内部人员(或恶意攻击者冒充内部人员)在第二章中定义的威胁,而不考虑内部人员是否具有恶意意图。例如,一个善意的工程师可能无意中构建了包含未经审查和未提交更改的代码,或者外部攻击者可能尝试使用受损工程师帐户的权限部署带有后门的二进制文件。我们同样考虑这两种情况。
在本章中,我们对软件供应链的步骤进行了广泛定义。
构建是将输入构件转换为输出构件的任何过程,其中构件是任何数据片段,例如文件、软件包、Git 提交或虚拟机(VM)镜像。测试是构建的特殊情况,其中输出构件是一些逻辑结果,通常是“通过”或“失败”,而不是文件或可执行文件。
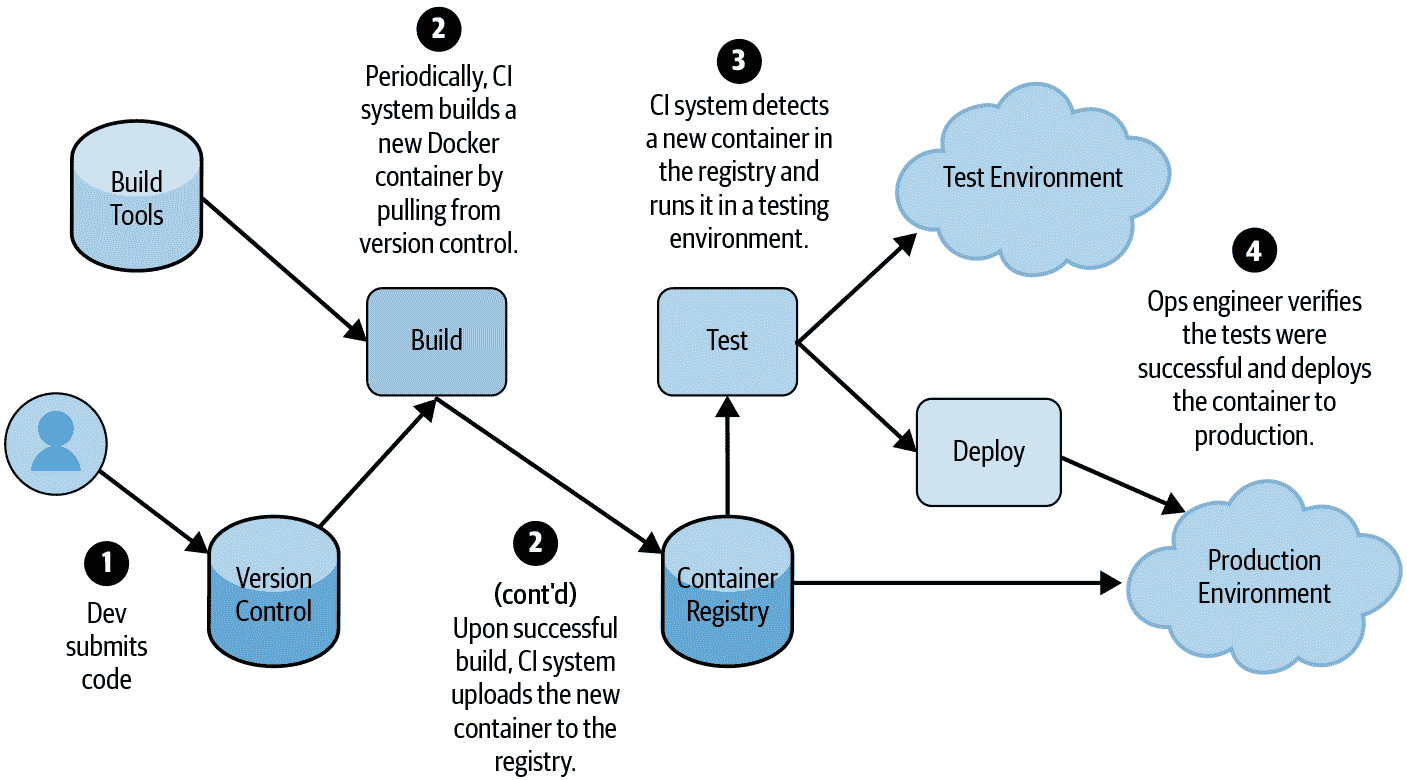
图 14-2:典型的云托管基于容器的服务部署
构建可以链接在一起,并且一个构件可以经历多次测试。例如,发布过程可能首先从源代码“构建”二进制文件,然后从二进制文件“构建”Docker 镜像,然后通过在开发环境中运行 Docker 镜像来“测试”Docker 镜像。
部署是将某个构件分配到某个环境的任何过程。您可以将以下每个过程视为部署:
-
推送代码:
-
发布命令以导致服务器下载并运行新的二进制文件
-
更新 Kubernetes 部署对象以使用新的 Docker 镜像
-
启动虚拟机或物理机,加载初始软件或固件
-
更新配置:
-
运行 SQL 命令来更改数据库模式
-
更新 Kubernetes 部署对象以更改命令行标志
-
发布一个包或其他数据,将被其他用户使用:
-
上传 deb 包到 apt 仓库
-
上传 Docker 镜像到容器注册表
-
上传 APK 到 Google Play 商店
本章不包括部署后更改。
威胁模型
在加固软件供应链以缓解威胁之前,您必须确定您的对手。在本讨论中,我们将考虑以下三种对手类型。根据您的系统和组织,您的对手清单可能会有所不同:
-
可能犯错误的良性内部人员
-
试图获得比其角色允许的更多访问权限的恶意内部人员
-
外部攻击者入侵一个或多个内部人员的机器或帐户
第二章描述了攻击者的配置文件,并提供了针对内部风险建模的指导。
接下来,您必须像攻击者一样思考,尝试识别对手可以颠覆软件供应链以威胁您系统的所有方式。以下是一些常见威胁的例子;您应该根据您组织的具体威胁来调整这个清单。为了简单起见,我们使用术语工程师来指代良性内部人员,恶意对手来指代恶意内部人员和外部攻击者:
-
工程师提交了一个意外引入系统漏洞的更改。
-
恶意对手提交了一个启用后门或引入系统其他有意漏洞的更改。
-
工程师意外地从包含未经审查的更改的本地修改版本的代码构建。
-
工程师部署了一个带有有害配置的二进制文件。例如,更改启用了仅用于测试的生产调试功能。
-
恶意对手部署了一个修改过的二进制文件到生产环境,开始窃取客户凭据。
-
恶意对手修改了云存储桶的 ACL,允许他们窃取数据。
-
恶意对手窃取用于签署软件的完整性密钥。
-
工程师部署了一个带有已知漏洞的旧版本代码。
-
CI 系统配置错误,允许从任意源代码库构建请求。因此,恶意对手可以从包含恶意代码的源代码库构建。
-
恶意对手上传一个自定义的构建脚本到 CI 系统,窃取签名密钥。然后对手使用该密钥对恶意二进制文件进行签名和部署。
-
恶意对手欺骗 CD 系统使用带有后门的编译器或构建工具来生成恶意二进制文件。
一旦您编制了一个潜在对手和威胁的全面清单,您可以将您已经采取的缓解措施与您识别出的威胁进行映射。您还应该记录当前缓解策略的任何限制。这个练习将为您的系统中潜在风险提供一个全面的图片。没有相应缓解措施的威胁,或者现有缓解措施存在重大限制的威胁,都是需要改进的领域。
最佳实践
以下最佳实践可以帮助您缓解威胁,在您的威胁模型中填补任何安全漏洞,并持续改进您的软件供应链的安全性。
需要代码审查
代码审查是在提交或部署更改之前,让第二个人(或几个人)审查源代码的更改的做法。除了提高代码安全性外,代码审查还为软件项目提供了多种好处:它们促进知识共享和教育,灌输编码规范,提高代码可读性,减少错误,所有这些有助于建立安全和可靠的文化(有关这个想法的更多信息,请参见第二十一章)。
从安全的角度来看,代码审查是一种多方授权的形式,这意味着没有个人有权利单独提交更改。正如第五章中所描述的,多方授权提供了许多安全好处。
要成功实现,代码审查必须是强制性的。如果对手可以选择退出审查,那么他们将不会被阻止!审查还必须足够全面,以捕捉问题。审阅者必须理解任何更改的细节及其对系统的影响,或者向作者询问澄清问题,否则该过程可能会变得形式化。
许多公开可用的工具允许您实现强制性的代码审查。例如,您可以配置 GitHub、GitLab 或 BitBucket,要求每个拉取/合并请求都需要一定数量的批准。或者,您可以使用独立的审查系统,如 Gerrit 或 Phabricator,结合一个配置为只接受来自该审查系统的推送的源代码库。
从安全的角度来看,代码审查在安全方面存在一些限制,正如第十二章中所述。因此,最好将其作为“深度防御”安全措施之一,与自动化测试(在第十三章中描述)和第十二章中的建议一起实现。
依赖自动化
理想情况下,自动化系统应该执行软件供应链中的大部分步骤。自动化提供了许多优势。它可以为构建、测试和部署软件提供一致、可重复的流程。将人类从循环中移除有助于防止错误并减少劳动。当您在一个封闭的系统上运行软件供应链自动化时,您可以使系统免受恶意对手的颠覆。
考虑一个假设的场景,工程师根据需要在他们的工作站上手动构建“生产”二进制文件。这种情况会产生许多引入错误的机会。工程师可能会意外地从错误的代码版本构建,或者包含未经审查或未经测试的代码更改。同时,恶意对手,包括已经攻破工程师机器的外部攻击者,可能会故意用恶意版本覆盖本地构建的二进制文件。自动化可以防止这两种结果。
以安全的方式添加自动化可能会有些棘手,因为自动化系统本身可能会引入其他安全漏洞。为了避免最常见的漏洞类别,我们建议至少采取以下措施:
将所有构建、测试和部署步骤移至自动化系统。
至少,您应该编写所有步骤的脚本。这样可以让人类和自动化执行相同的步骤以保持一致性。您可以使用 CI/CD 系统(如Jenkins)来实现这一目的。考虑制定一个要求所有新项目都需要自动化的政策,因为将自动化应用到现有系统中通常是具有挑战性的。
软件供应链的所有配置更改都需要同行审查。
通常,将配置视为代码(如前所述)是实现这一目标的最佳方式。通过要求审查,您大大减少了出错和错误的机会,并增加了恶意攻击的成本。
锁定自动化系统,防止管理员或用户篡改。
这是最具挑战性的一步,实现细节超出了本章的范围。简而言之,考虑管理员可以在没有审查的情况下进行更改的所有路径——例如,通过直接配置 CI/CD 管道或使用 SSH 在机器上运行命令进行更改。对于每条路径,考虑采取措施以防止未经同行审查的访问。
有关锁定自动化构建系统的进一步建议,请参阅“可验证构建”。
自动化是双赢,减少了繁重的工作,同时增加了可靠性和安全性。尽可能依赖自动化!
验证构件,而不仅仅是人
如果对手可以绕过源、构建和测试基础设施的控制,直接部署到生产环境,那么这些控制的效果就会受到限制。仅仅验证谁发起了部署是不够的,因为该行为者可能会犯错误,或者可能是有意部署了恶意更改。相反,部署环境应该验证正在部署的内容。
部署环境应该要求证明部署过程的每个自动化步骤都已发生。除非有其他缓解控制检查该操作,否则人类不应能够绕过自动化。例如,如果您在 Google Kubernetes Engine(GKE)上运行,您可以使用二进制授权默认接受仅由您的 CI/CD 系统签名的镜像,并监视 Kubernetes 集群审计日志,以获取有人使用紧急功能部署不符合规定的镜像时的通知。
这种方法的一个局限性是,它假设您设置的所有组件都是安全的:即 CI/CD 系统仅接受允许在生产环境中使用的源的构建请求,如果使用签名密钥,则只能由 CI/CD 系统访问,等等。“高级缓解策略”描述了一种更健壮的方法,直接验证所需属性,减少了隐含的假设。
将配置视为代码
服务的配置对于安全性和可靠性同样至关重要。因此,关于代码版本控制和更改审查的所有最佳实践也适用于配置。将配置视为代码,要求在部署之前对配置更改进行检入、审查和测试,就像对任何其他更改一样。
举个例子:假设您的前端服务器有一个配置选项来指定后端。如果有人将您的生产前端指向后端的测试版本,那么您将面临严重的安全和可靠性问题。
或者,作为一个更实际的例子,考虑一个使用 Kubernetes 并将配置存储在版本控制下的YAML文件的系统。部署过程调用kubectl二进制文件并传递 YAML 文件,部署经过批准的配置。限制部署过程仅使用“经过批准”的 YAML——来自版本控制并需要同行审查的 YAML——使得误配置服务变得更加困难。
您可以重复使用本章推荐的所有控件和最佳实践,以保护您服务的配置。重用这些方法通常比其他方法更容易,后者通常需要完全独立的多方授权系统来保护部署后的配置更改。
版本控制和审查配置的做法并不像代码版本控制和审查那样普遍。即使实现了配置即代码的组织通常也不会对配置应用代码级别的严格要求。例如,工程师通常知道他们不应该从本地修改的源代码构建生产版本的二进制文件。这些工程师可能在未将更改保存到版本控制并征求审查的情况下部署配置更改。
实现配置即代码需要改变你的文化、工具和流程。在文化上,你需要重视审查流程。在技术上,你需要工具,允许你轻松比较提议的更改(即diff,grep),并提供在紧急情况下手动覆盖更改的能力。
防范威胁模型
现在我们已经定义了一些最佳实践,我们可以将这些流程映射到我们之前确定的威胁上。在评估这些流程与您特定的威胁模型相关时,问问自己:所有最佳实践都是必要的吗?它们是否足以缓解所有威胁?表 14-1 列出了示例威胁,以及它们对应的缓解措施和这些缓解措施的潜在限制。
表 14-1. 示例威胁、缓解措施和缓解措施的潜在限制
| 威胁 | 缓解 | 限制 |
|---|---|---|
| 一个工程师提交了一个意外引入系统漏洞的更改。 | 代码审查加自动化测试(见第十三章)。这种方法显著减少了错误的机会。 | |
| 一个恶意的对手提交了一个改变,使系统启用了后门或引入了其他有意的漏洞。 | 代码审查。这种做法增加了攻击的成本和检测的机会——对手必须仔细制定更改以通过代码审查。 | 不能防止串通或外部攻击者能够 compromise 多个内部账户。 |
一个工程师意外地从包含未经审查的更改的本地修改版本的代码构建。一个自动化的 CI/CD 系统总是从正确的源代码库中拉取执行构建。
一个工程师部署了一个有害的配置。例如,更改启用了仅用于测试的生产环境中的调试功能。将配置视为源代码,并要求进行相同级别的同行审查。并非所有配置都可以被视为“代码”。
一个恶意的对手部署了一个修改后的二进制文件到生产环境,开始窃取客户凭据。生产环境需要证明 CI/CD 系统构建了二进制文件。CI/CD 系统配置为只从正确的源代码库中拉取源代码。对手可能会想出如何绕过这一要求,使用紧急部署 breakglass 程序。充分的日志记录和审计可以缓解这种可能性。
一个恶意的对手修改了云存储桶的 ACL,使他们能够窃取数据。考虑资源 ACL 作为配置。云存储桶只允许部署过程进行配置更改,因此人类无法进行更改。不能防止串通或外部攻击者能够 compromise 多个内部账户。
一个恶意的对手窃取了用于签署软件的完整性密钥。将完整性密钥存储在一个密钥管理系统中,该系统配置为只允许 CI/CD 系统访问密钥,并支持密钥轮换。有关更多信息,请参见第九章。有关构建特定的建议,请参见“高级缓解策略”。
图 14-3 显示了一个更新的软件供应链,其中包括前面表中列出的威胁和缓解措施。

图 14-3:典型的软件供应链-对手不应能够绕过流程
我们尚未将几个威胁与最佳实践中的缓解措施相匹配:
-
工程师部署了一个带有已知漏洞的旧版本代码。
-
CI 系统配置错误,允许从任意源代码仓库构建请求。因此,恶意对手可以从包含恶意代码的源代码仓库构建。
-
一个恶意对手上传了一个自定义的构建脚本到 CI 系统,用于窃取签名密钥。然后对手使用该密钥对恶意二进制文件进行签名和部署。
-
一个恶意对手欺骗 CD 系统使用一个带有后门的编译器或构建工具来生成恶意二进制文件。
为了解决这些威胁,您需要实现更多的控制,我们将在下一节中介绍。只有您才能决定是否值得为您特定的组织解决这些威胁。
深入探讨:高级缓解策略
您可能需要复杂的缓解措施来解决软件供应链中一些更高级的威胁。因为本节中的建议在行业内尚未成为标准,您可能需要构建一些自定义基础设施来采用这些建议。这些建议最适合规模大和/或特别安全敏感的组织,对于暴露于内部风险较低的小型组织可能没有意义。
二进制来源
每次构建都应该生成描述给定二进制工件是如何构建的“二进制来源”:输入、转换和执行构建的实体。
为了解释原因,考虑以下激励性例子。假设您正在调查一个安全事件,并且看到在特定时间窗口内发生了部署。您想确定部署是否与该事件有关。逆向工程二进制将成本过高。检查源代码将更容易得多,最好是查看版本控制中的更改。但是您如何知道二进制来自哪个源代码?
即使您不预期需要这些类型的安全调查,您也需要基于来源的二进制来源来制定基于来源的部署策略,如本节后面所讨论的。
二进制来源中应包含的内容
您应该在来源中包含的确切信息取决于您的系统内置的假设和最终需要来源的消费者的信息。为了实现丰富的部署策略并允许临时分析,我们建议以下来源字段:
真实性(必需)
暗示了构建的隐式信息,例如产生它的系统以及您为何可以信任来源。这通常是通过使用加密签名来保护二进制来源的其他字段来实现的。¹¹
输出(必需)
适用于此二进制来源的输出工件。通常,每个输出都由工件内容的加密哈希标识。
输入
构建中的内容。此字段允许验证者将源代码的属性与工件的属性进行关联。它应包括以下内容:
来源
构建的“主”输入工件,例如顶层构建命令运行的源代码树。例如:“来自https://github.com/mysql/mysql-server的 Git 提交270f...ce6d”¹²或“文件foo.tar.gz的 SHA-256 内容78c5...6649。”
依赖
构建所需的所有其他工件,如库、构建工具和编译器,这些工件在源代码中没有完全指定。这些输入都可能影响构建的完整性。
命令
用于启动构建的命令。例如:“bazel build //main:hello-world”。理想情况下,该字段应结构化以允许自动化分析,因此我们的示例可能变为“{"bazel": {"command": "build", "target": "//main:hello_world"}}”。
环境
需要重现构建的任何其他信息,例如架构细节或环境变量。
输入元数据
在某些情况下,构建者可能会读取有关下游系统将发现有用的输入的元数据。例如,构建者可能包括源提交的时间戳,然后策略评估系统在部署时使用。
调试信息
任何不必要用于安全性但可能对调试有用的额外信息,例如构建运行的机器。
版本控制
构建时间戳和溯源格式版本号通常很有用,以便进行将来的更改,例如使旧构建无效或更改格式而不易受到回滚攻击。
您可以省略隐含或由源代码本身覆盖的字段。例如,Debian 的溯源格式省略了构建命令,因为该命令始终是dpkg-buildpackage。
输入工件通常应列出标识符(例如 URI)和版本(例如加密哈希)。通常使用标识符来验证构建的真实性,例如验证代码是否来自正确的源代码库。版本对于各种目的都很有用,例如临时分析、确保可重现的构建以及验证链式构建步骤,其中步骤i的输出是步骤i+1 的输入。
注意攻击面。您需要验证构建系统未检查的任何内容(因此由签名隐含)或包含在源代码中(因此经过同行审查)的内容。如果启动构建的用户可以指定任意编译器标志,则验证器必须验证这些标志。例如,GCC 的-D标志允许用户覆盖任意符号,因此也可以完全更改二进制文件的行为。同样,如果用户可以指定自定义编译器,则验证器必须确保使用了“正确”的编译器。一般来说,构建过程可以执行的验证越多,越好。
有关二进制溯源的一个很好的例子,请参见 Debian 的deb-buildinfo格式。有关更一般的建议,请参见可重现构建项目的文档。要签名和编码此信息的标准方法,请考虑JSON Web Tokens(JWT)。
基于溯源的部署策略
“验证工件,而不仅仅是人”建议官方构建自动化流水线应该验证正在部署的内容。如何验证流水线配置正确?如果您想为某些部署环境提供特定的保证,而这些保证不适用于其他环境,该怎么办?
您可以使用明确的部署策略来描述每个部署环境的预期属性,以解决这些问题。然后,部署环境可以将这些策略与部署到它们的工件的二进制溯源进行匹配。
这种方法比纯粹基于签名的方法有几个优点:
-
它减少了软件供应链中隐含的假设数量,使分析和确保正确性变得更容易。
-
它澄清了软件供应链中每个步骤的合同,减少了配置错误的可能性。
-
它允许您在每个构建步骤中使用单个签名密钥,而不是每个部署环境,因为现在您可以使用二进制溯源进行部署决策。
例如,假设您有一个微服务架构,并希望保证每个微服务只能从提交到该微服务源存储库的代码构建。使用代码签名,您需要每个源存储库一个密钥,并且 CI/CD 系统需要根据源存储库选择正确的签名密钥。这种方法的缺点是很难验证 CI/CD 系统的配置是否符合这些要求。
使用基于溯源的部署策略,CI/CD 系统生成了二进制溯源,说明了源存储库,总是由单一密钥签名。每个微服务的部署策略列出了允许的源存储库。与代码签名相比,正确性的验证要容易得多,因为部署策略在一个地方描述了每个微服务的属性。
部署策略中列出的规则应该减轻对系统的威胁。参考您为系统创建的威胁模型。您可以定义哪些规则来减轻这些威胁?例如,以下是一些您可能想要实现的示例规则:
-
源代码已提交到版本控制并经过同行审查。
-
源代码来自特定位置,比如特定的构建目标和存储库。
-
构建是通过官方的 CI/CD 流水线进行的(参见“可验证构建”)。
-
测试已通过。
-
二进制文件在此部署环境中明确允许。例如,不要在生产环境中允许“测试”二进制文件。
-
代码或构建的版本足够新。¹³
-
代码不包含已知的漏洞,如最近的安全扫描所报告的。¹⁴
in-toto 框架提供了实现溯源策略的一个标准。
实现政策决策
如果您为基于溯源的部署策略实现自己的引擎,请记住需要三个步骤:
-
验证溯源的真实性。这一步还隐式地验证了溯源的完整性,防止对手篡改或伪造它。通常,这意味着验证溯源是否由特定密钥进行了加密签名。
-
验证溯源是否适用于构件。这一步还隐式地验证了构件的完整性,确保对手不能将一个“好”的溯源应用于一个“坏”的构件。通常,这意味着比较构件的加密哈希与溯源有效负载中找到的值。
-
验证溯源是否符合所有策略规则。
这个过程的最简单的例子是一个规则,要求构件必须由特定密钥签名。这个单一的检查实现了所有三个步骤:它验证了签名本身是否有效,构件是否适用于签名,以及签名是否存在。
让我们考虑一个更复杂的例子:“Docker 镜像必须从 GitHub 存储库mysql/mysql-server构建。”假设您的构建系统使用密钥*K[B]*以 JWT 格式签署构建溯源。在这种情况下,令牌有效负载的模式将如下所示,其中主题sub是RFC 6920 URI:
{
"sub": "ni:///sha-256;...",
"input": {"source_uri": "..."}
}
要评估构件是否符合此规则,引擎需要验证以下内容:
-
JWT 签名使用密钥*K[B]*进行验证。
-
sub匹配了构件的 SHA-256 哈希。 -
input.source_uri正好是"https://github.com/mysql/mysql-server"。
可验证构建
我们称构建为可验证的,如果构建产生的二进制溯源是可信的。¹⁵ 可验证性取决于观察者。您是否信任特定的构建系统取决于您的威胁模型以及构建系统如何融入您组织更大的安全故事。
考虑以下非功能性需求示例是否适合你的组织,¹⁶并添加符合你特定需求的任何需求:
-
如果单个开发者的工作站受到损害,二进制出处或输出物品的完整性不会受到损害。
-
对手无法在不被察觉的情况下篡改出处或输出物品。
-
一个构建不能影响另一个构建的完整性,无论是并行运行还是串行运行。
-
构建不能产生包含错误信息的出处。例如,出处不应该声称一个物品是从 Git 提交
abc...def构建的,而实际上是来自123...456。 -
非管理员不能配置用户定义的构建步骤,比如 Makefile 或 Jenkins Groovy 脚本,以违反此列表中的任何要求。
-
在构建后至少N个月内,所有源物品的快照都可以用于潜在的调查。
-
构建是可复现的(参见“隔离的、可复现的或可验证的?”)。即使在可验证的构建架构中没有要求,这种方法也可能是可取的。例如,在发现安全事件或漏洞后,可复现的构建可能有助于独立重新验证物品的二进制出处。
可验证的构建架构
可验证构建系统的目的是增加验证者对构建系统产生的二进制出处的信任。无论可验证性的具体要求如何,都有三种主要的架构可供选择:
可信的构建服务
验证者要求原始构建是由验证者信任的构建服务执行的。通常,这意味着可信的构建服务用只有该服务才能访问的密钥对二进制出处进行签名。
这种方法的优点是只需要构建一次,不需要可复现性(参见“隔离的、可复现的或可验证的?”)。Google 在内部构建中使用这种模型。
你自己进行的重建
验证者在飞行中重现构建,以验证二进制出处。例如,如果二进制出处声称来自 Git 提交abc...def,验证者会获取该 Git 提交,重新运行二进制出处中列出的构建命令,并检查输出是否与问题物品完全相同。有关可复现性的更多信息,请参见下面的侧边栏。
虽然这种方法可能一开始看起来很吸引人,因为你信任自己,但它并不具备可扩展性。构建通常需要几分钟甚至几小时,而部署决策通常需要在毫秒内做出。这还要求构建是完全可复现的,这并不总是切实可行;有关更多信息,请参见侧边栏。
重建服务
验证者要求“重建者”中的一些“重建者”已经重现了构建并证明了二进制出处的真实性。这是前两种选项的混合体。在实践中,这种方法通常意味着每个重建者监视一个软件包存储库,主动重建每个新版本,并将结果存储在某个数据库中。然后,验证者在N个不同的数据库中查找条目,这些条目以问题物品的加密哈希为键。当中央管理模式不可行或不可取时,像Debian这样的开源项目使用这种模型。
实现可验证的构建
无论可验证的构建服务是“可信的构建服务”还是“重建服务”,都应该牢记一些重要的设计考虑。
基本上,几乎所有的 CI/CD 系统都按照图 14-4 中的步骤运行:服务接收请求,获取任何必要的输入,执行构建,并将输出写入存储系统。
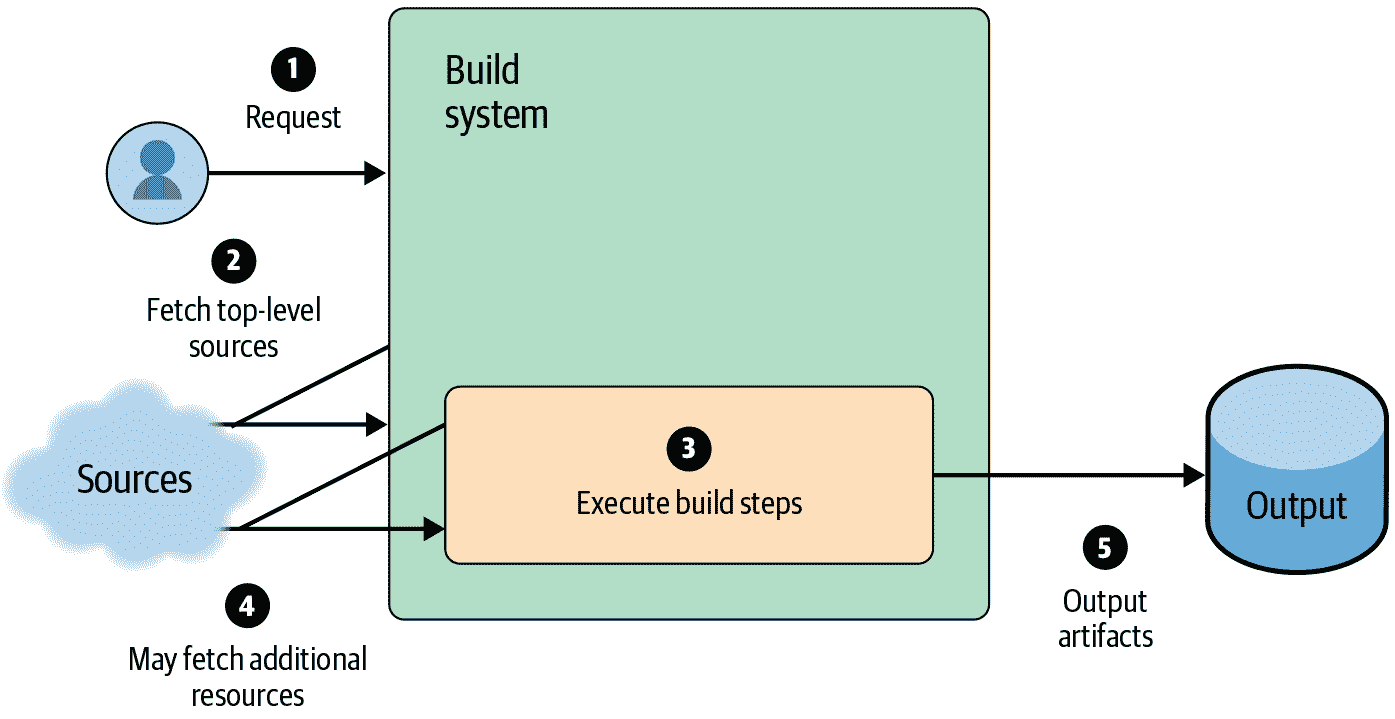
图 14-4:一个基本的 CI/CD 系统
有了这样的系统,您可以相对容易地向输出添加签名的来源,如图 14-5 所示。对于一个采用“中央构建服务”模型的小型组织来说,这个额外的签名步骤可能足以解决安全问题。
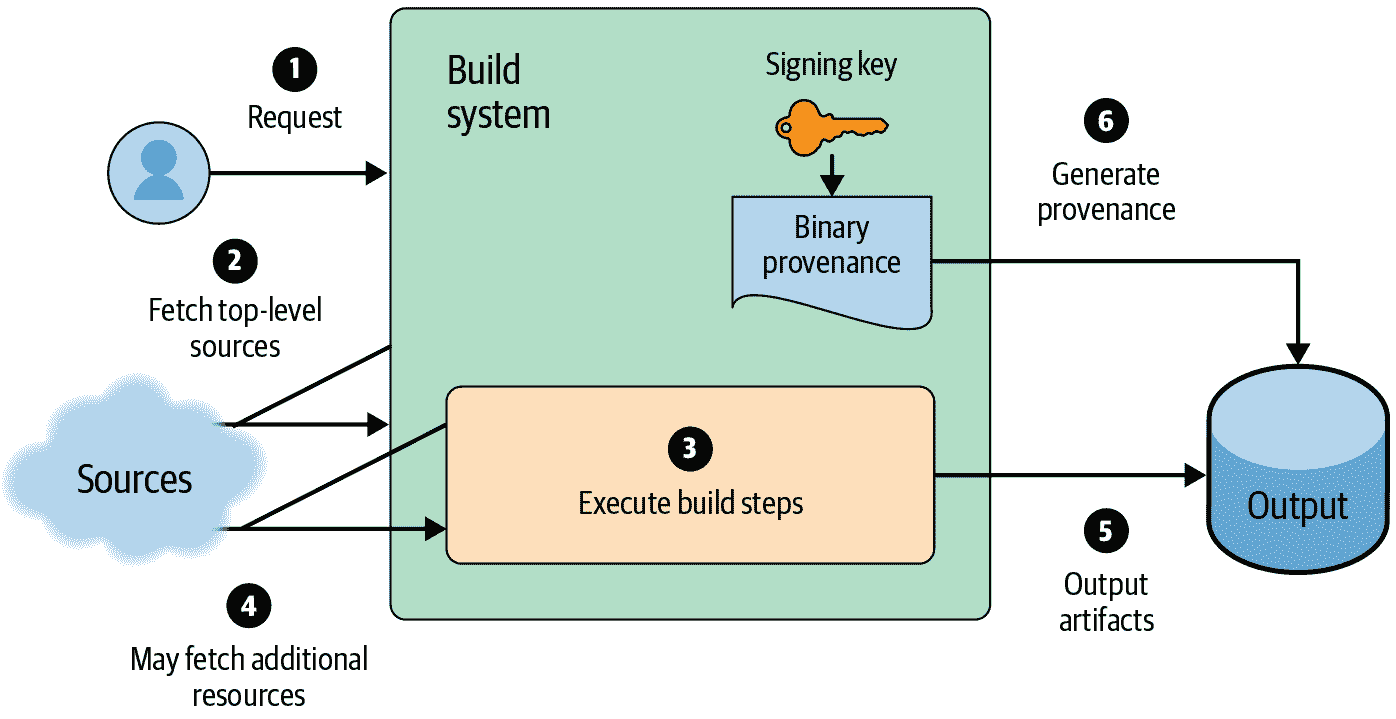
图 14-5:向现有的 CI/CD 系统添加签名
随着您的组织规模的增长和您有更多的资源投入到安全中,您可能希望解决另外两个安全风险:不受信任的输入和未经身份验证的输入。
不受信任的输入
对手可能使用构建的输入来颠覆构建过程。许多构建服务允许非管理员用户定义在构建过程中执行的任意命令,例如通过 Jenkinsfile、travis.yml、Makefile 或BUILD。从安全的角度来看,这种功能实际上是“远程代码执行(RCE)设计”。在特权环境中运行的恶意构建命令可以执行以下操作:
-
窃取签名密钥。
-
在来源中插入错误信息。
-
修改系统状态,影响后续构建。
-
操纵另一个同时进行的构建。
即使用户不被允许定义自己的步骤,编译是一个非常复杂的操作,提供了充分的机会进行 RCE 漏洞。
您可以通过特权分离来减轻这种威胁。使用一个受信任的编排器进程来设置初始的已知良好状态,启动构建,并在构建完成时创建签名的来源。可选地,编排器可以获取输入以解决下一小节中描述的威胁。所有用户定义的构建命令应在另一个环境中执行,该环境无法访问签名密钥或任何其他特权。您可以通过各种方式创建这个环境,例如通过与编排器相同的机器上的沙盒,或者在单独的机器上运行。
未经身份验证的输入
即使用户和构建步骤是可信的,大多数构建都依赖于其他工件。任何这样的依赖都是对手可能潜在颠覆构建的表面。例如,如果构建系统在没有 TLS 的情况下通过 HTTP 获取依赖项,攻击者可以进行中间人攻击以修改传输中的依赖项。
因此,我们建议使用隔离构建(参见“隔离的、可重现的或可验证的?”)。构建过程应该提前声明所有输入,只有编排器应该获取这些输入。隔离构建大大提高了在来源中列出的输入是正确的信心。
一旦您考虑了不受信任和未经身份验证的输入,您的系统就类似于图 14-6。这样的模型比图 14-5 中的简单模型更抵抗攻击。
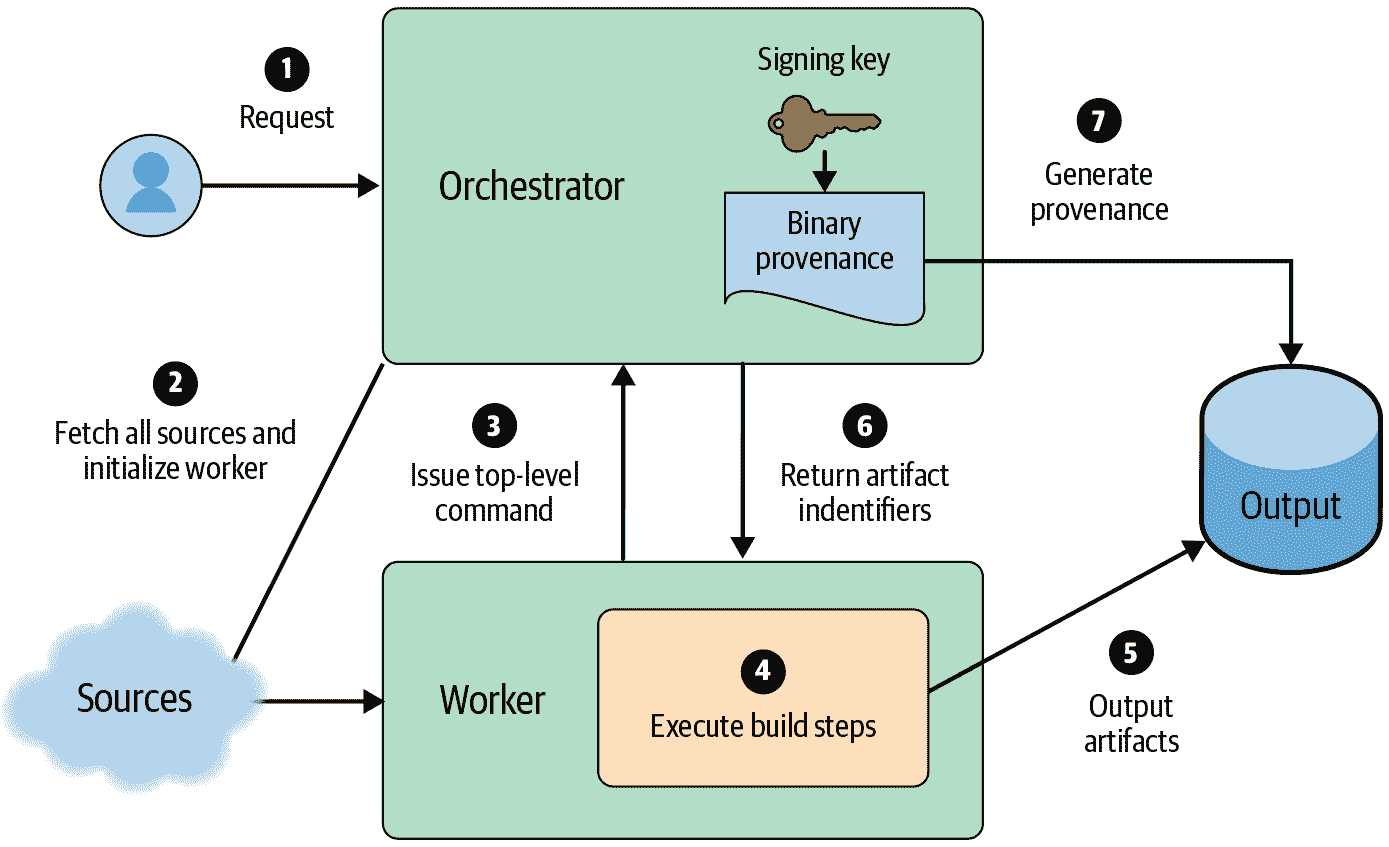
图 14-6:解决不受信任和未经身份验证输入风险的“理想”CI/CD 设计
部署阻塞点
要“验证工件,而不仅仅是人”,部署决策必须发生在部署环境内的适当阻塞点。在这种情况下,“阻塞点”是所有部署请求必须流经的点。对手可以绕过不在阻塞点发生的部署决策。
以 Kubernetes 为例,设置部署瓶颈,如图 14-7 所示。假设您想要验证特定 Kubernetes 集群中所有部署到 pod 的部署。主节点将成为一个良好的瓶颈,因为所有部署都应该通过它进行。为了使其成为一个合适的瓶颈,配置工作节点只接受来自主节点的请求。这样,对手就无法直接部署到工作节点。
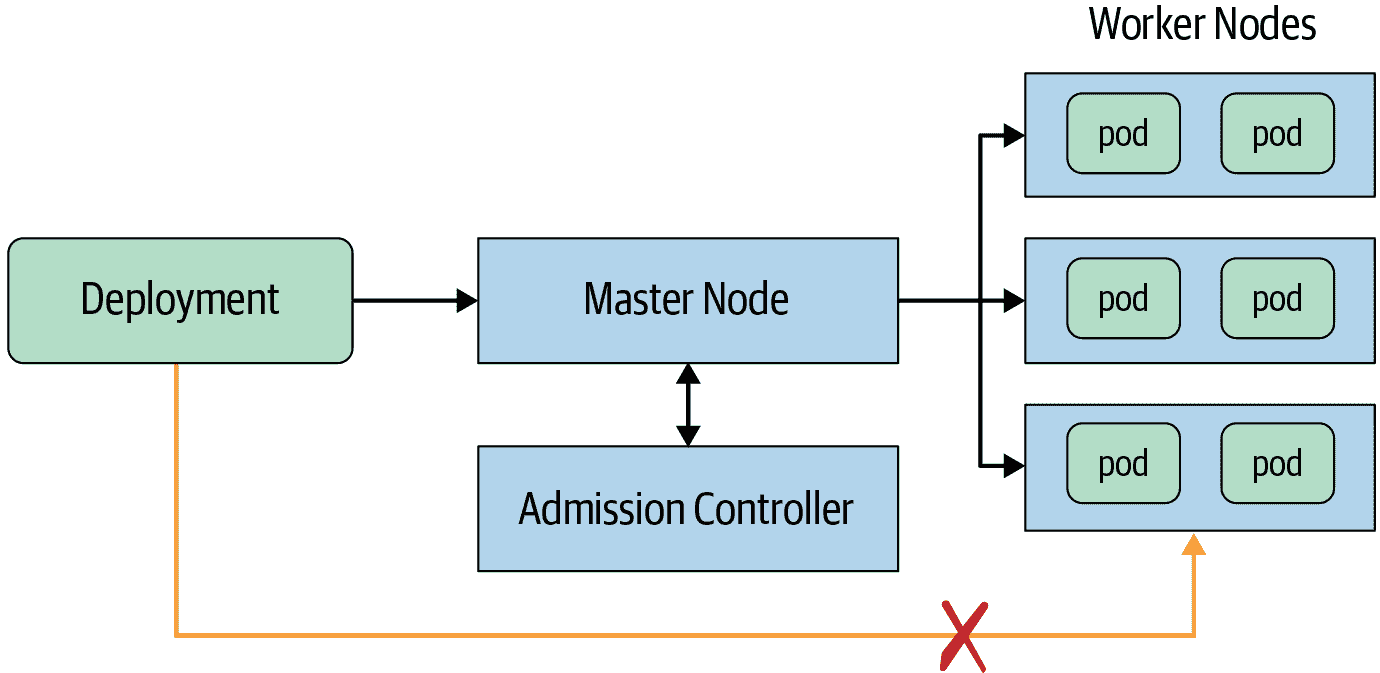
图 14-7:Kubernetes 架构-所有部署必须通过主节点
理想情况下,瓶颈执行策略决策,可以直接执行,也可以通过 RPC 执行。Kubernetes 为此目的提供了准入控制器webhook。如果您使用 Google Kubernetes Engine,二进制授权提供了一个托管的准入控制器和许多其他功能。即使您不使用 Kubernetes,您也可以修改“准入”点以执行部署决策。
或者,您可以在瓶颈前放置一个“代理”,并在代理中执行策略决策,如图 14-8 所示。这种方法需要配置您的“准入”点,只允许通过代理访问。否则,对手可以通过直接与准入点通信来绕过代理。
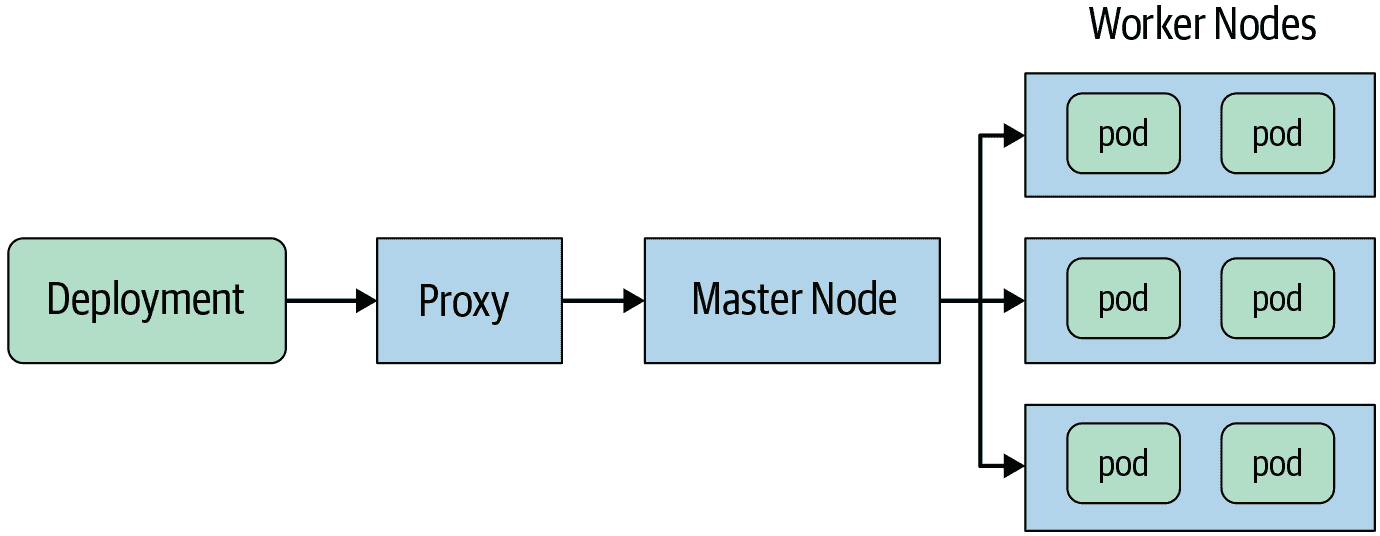
图 14-8:使用代理进行策略决策的替代架构
部署后验证
即使在部署时执行部署策略或签名检查时,记录和部署后验证几乎总是可取的,原因如下:
-
策略可能会更改,在这种情况下,验证引擎必须重新评估系统中现有的部署,以确保它们仍然符合新的策略。这在首次启用策略时尤为重要。
-
由于决策服务不可用,请求可能已被允许继续进行。这种故障开放设计通常是必要的,以确保服务的可用性,特别是在首次推出执行功能时。
-
在紧急情况下,操作员可能使用了紧急开关机制来绕过决策,如下一节所述。
-
用户需要一种方法,在提交之前测试潜在的策略更改,以确保现有状态不会违反新版本的策略。
-
出于类似于“故障开放”用例的原因,用户可能还希望有一种干预运行模式,在部署时系统始终允许请求,但监控会发现潜在问题。
-
调查人员可能需要在事故发生后出于取证目的获取信息。
执行决策点必须记录足够的信息,以便验证器在部署后评估策略。²⁰通常需要记录完整的请求,但并不总是足够的-如果策略评估需要一些其他状态,则日志必须包括该额外状态。例如,当我们为 Borg 实现部署后验证时遇到了这个问题:因为“作业”请求包括对现有“分配”和“包”引用,我们必须连接三个日志来源-作业,分配和包-以获取做出决策所需的完整状态。²¹
实用建议
多年来,在各种情境中实现可验证的构建和部署策略时,我们学到了一些经验教训。这些经验教训大多与实际技术选择无关,而更多地与如何部署可靠、易于调试和易于理解的更改有关。本节包含一些建议,希望您会发现有用。
逐步进行
提供高度安全、可靠和一致的软件供应链可能需要您进行许多更改,从编写构建步骤到实现构建来源,再到实现配置即代码。协调所有这些更改可能很困难。这些控件中的错误或缺失功能也可能对工程生产力构成重大风险。在最坏的情况下,这些控件中的错误可能导致服务中断。
如果您一次专注于保护供应链的一个特定方面,可能会更成功。这样,您可以最大程度地减少中断风险,同时还可以帮助同事学习新的工作流程。
提供可操作的错误消息
当部署被拒绝时,错误消息必须清楚地解释出了什么问题以及如何解决。例如,如果工件被拒绝是因为从错误的源 URI 构建的,解决方法可以是更新策略以允许该 URI,或者从正确的 URI 重新构建。您的策略决策引擎应该给用户提供可操作的反馈,提供这样的建议。简单地说“不符合策略”可能会让用户感到困惑和手足无措。
在设计架构和策略语言时,请考虑这些用户旅程。一些设计选择会使为用户提供可操作的反馈变得非常困难,因此请尽早发现这些问题。例如,我们早期的策略语言原型提供了许多表达策略的灵活性,但阻止我们提供可操作的错误消息。我们最终放弃了这种方法,转而采用了一种非常有限的语言,可以提供更好的错误消息。
确保来源清晰
谷歌的可验证构建系统最初将二进制来源异步上传到数据库。然后在部署时,策略引擎使用工件的哈希作为键在数据库中查找来源。
虽然这种方法大多运行良好,但我们遇到了一个主要问题:用户可以多次构建工件,导致相同哈希的多个条目。考虑空文件的情况:我们有数百万条与空文件的哈希相关的来源记录,因为许多不同的构建生成了空文件作为其输出的一部分。为了验证这样的文件,我们的系统必须检查任何来源记录是否符合策略。这反过来又导致了两个问题:
-
当我们未能找到通过记录时,我们无法提供可操作的错误消息。例如,我们不得不说,“源 URI 是X,但策略应该是Y”,而不是“这 497,129 条记录中没有一条符合策略”。这是糟糕的用户体验。
-
验证时间与返回的记录数量成正比。这导致我们的延迟 SLO 超出了 100 毫秒数倍!
我们还遇到了与数据库的异步上传问题。上传可能会悄无声息地失败,这种情况下我们的策略引擎会拒绝部署。与此同时,用户不明白为什么被拒绝。我们本可以通过使上传同步来解决这个问题,但这种解决方案会使我们的构建系统不太可靠。
因此,我们强烈建议使来源清晰。在可能的情况下,避免使用数据库,而是内联传播来源与工件。这样做可以使整个系统更可靠,延迟更低,更易于调试。例如,使用 Kubernetes 的系统可以添加一个传递给 Admission Controller webhook 的注释。
创建明确的策略
与我们推荐的工件来源的方法类似,适用于特定部署的策略应该是明确的。我们建议设计系统,以便任何给定的部署只适用一个策略。考虑另一种选择:如果有两个策略适用,那么两个策略都需要通过吗,还是只需要一个策略通过?最好完全避免这个问题。如果您想在整个组织中应用全局策略,可以将其作为元策略实现:实现一个检查,以确保所有个体策略符合一些全局标准。
包括部署 breakglass
在紧急情况下,可能需要绕过部署策略。例如,工程师可能需要重新配置前端以将流量从失败的后端转移,相应的配置即代码更改可能需要通过常规 CI/CD 管道部署太长时间。绕过策略的 breakglass 机制可以让工程师快速解决故障,并促进安全和可靠性的文化(见第二十一章)。
由于对手可能利用 breakglass 机制,所有 breakglass 部署必须迅速引发警报并进行审计。为了使审计变得实用,breakglass 事件应该是罕见的——如果事件太多,可能无法区分恶意活动和合法使用。
重新审视威胁模型的安全防护
现在我们可以将高级缓解措施映射到以前未解决的威胁,如表 14-2 所示。
表 14-2. 复杂威胁示例的高级缓解措施
| 威胁 | 缓解 |
|---|---|
| 工程师部署了一个存在已知漏洞的旧版本代码。 | 部署策略要求代码在过去的N天内进行了安全漏洞扫描。 |
| CI 系统配置错误,允许从任意源代码库构建请求。结果,恶意对手可以从包含恶意代码的源代码库构建。 | CI 系统生成描述其拉取源代码库的二进制来源。生产环境强制执行部署策略,要求来源证明部署的工件来自批准的源代码库。 |
| 恶意对手向 CI 系统上传自定义构建脚本,窃取签名密钥。然后对手使用该密钥签名和部署恶意二进制文件。 | 可验证构建系统分离权限,以便运行自定义构建脚本的组件无法访问签名密钥。 |
| 恶意对手欺骗 CD 系统使用带有后门的编译器或构建工具生成恶意二进制文件。 | 严格构建要求开发人员在源代码中明确指定编译器和构建工具的选择。这个选择像所有其他代码一样经过同行评审。 |
通过在软件供应链周围采取适当的安全控制,您可以缓解甚至是高级和复杂的威胁。
结论
本章的建议可以帮助您加强软件供应链对各种内部威胁的防范。代码审查和自动化是防止错误和增加恶意行为攻击成本的基本策略。代码作为配置将这些好处扩展到传统上受到比代码更少关注的配置。同时,基于工件的部署控制,特别是涉及二进制来源和可验证构建的控制,可以提供对复杂对手的保护,并允许您随着组织的增长而扩展。
7.这些建议有助于确保您编写和测试的代码(遵循第十二章和第十三章的原则)实际上是部署在生产环境中的代码。然而,尽管您已经尽力,您的代码可能并不总是按预期行为。当发生这种情况时,您可以使用下一章介绍的一些调试策略。
18.(1)代码审查也适用于对配置文件的更改;请参阅“将配置视为代码”。
11.(2)Sadowski, Caitlin 等人。2018 年。“现代代码审查:谷歌的案例研究。”第 40 届国际软件工程大会论文集:181-190。doi:10.1145/3183519.3183525。
2.(3)当与配置即代码和本章描述的部署策略结合时,代码审查构成了任意系统的多方授权系统的基础。
1.(4)有关代码审查者的责任,请参阅“审查文化”。
3.(5)步骤的“链”不一定需要完全自动。例如,通常可以接受人类能够启动构建或部署步骤。但是,人类不应该能够以任何有意义的方式影响该步骤的行为。
16.(6)尽管如此,这样的授权检查对于最小特权原则仍然是必要的(请参阅第五章)。
10.(7)紧急开关机制可以绕过策略,允许工程师快速解决故障。请参阅“紧急开关”。
4.(8)这个概念在SRE 书籍第八章和 SRE workbook 的第十四章和第十五章中有更详细的讨论。所有这些章节中的建议都适用于这里。
12.(9)YAML 是 Kubernetes 使用的配置语言。
5.(10)您必须记录和审计这些手动覆盖,以防对手使用手动覆盖作为攻击向量。
15.(11)请注意,真实性意味着完整性。
6.(12)Git 提交 ID 是提供整个源代码树完整性的加密哈希。
8.(13)有关回滚到有漏洞版本的讨论,请参阅“最低可接受的安全版本号”。
13.(14)例如,您可能需要证明Cloud Security Scanner在运行此特定代码版本的测试实例时未发现任何结果。
14.(15)请记住,纯签名仍然算作“二进制来源”,如前一节所述。
17.(16)请参阅“设计目标和要求”。
9.(17)例如,SRE 书籍将“hermetic”和“reproducible”这两个术语互换使用。Reproducible Builds 项目将“reproducible”定义为本章定义的方式,但有时也会将“reproducible”重载为“可验证”。
¹⁸ 作为一个反例,考虑一个构建过程,在构建过程中获取依赖的最新版本,但在其他方面产生相同的输出。只要两次构建大致同时发生,这个过程就是可重现的,但不是完全隔离的。
¹⁹ 实际上,必须有一种方式将软件部署到节点本身——引导加载程序、操作系统、Kubernetes 软件等等——而且该部署机制必须有自己的策略执行,这很可能是与用于 pod 的实现完全不同的实现。
²⁰ 理想情况下,日志是非常可靠和防篡改的,即使在停机或系统受到威胁的情况下也是如此。例如,假设 Kubernetes 主节点在日志后端不可用时接收到一个请求。主节点可以暂时将日志保存到本地磁盘。如果机器在日志后端恢复之前死机了怎么办?或者如果机器的空间用完了怎么办?这是一个具有挑战性的领域,我们仍在开发解决方案。
²¹ Borg 分配(简称 分配)是机器上一组保留的资源,其中可以在容器中运行一个或多个 Linux 进程集。软件包包含 Borg 作业的二进制文件和数据文件。有关 Borg 的完整描述,请参见 Verma, Abhishek 等人 2015 年的文章《Google 的 Borg 大规模集群管理》。第 10 届欧洲计算机系统会议论文集:1–17。doi:10.1145/2741948.2741964。
第十五章:调查系统
原文:https://google.github.io/building-secure-and-reliable-systems/raw/ch14.html
译者:飞龙
协议:CC BY-NC-SA 4.0
Pete Nuttall、Matt Linton 和 David Seidman
与 Vera Haas、Julie Saracino 和 Amaya Booker
在理想的世界中,我们都会构建完美的系统,我们的用户只会怀有最好的意图。然而,在现实中,您会遇到错误,并需要进行安全调查。当您观察生产中运行的系统时,您会确定需要改进的地方,以及可以简化和优化流程的地方。所有这些任务都需要调试和调查技术,以及适当的系统访问。
然而,即使是只读调试访问也会带来滥用的风险。为了解决这一风险,您需要适当的安全机制。您还需要在开发人员和运营人员的调试需求与存储和访问敏感数据的安全要求之间取得谨慎的平衡。
注
在本章中,我们使用术语调试器来指代调试软件问题的人类,而不是GDB(GNU 调试器)或类似的工具。除非另有说明,我们使用“我们”一词来指代本章的作者,而不是整个谷歌公司。
从调试到调查
“我完全意识到,我余生的很大一部分时间将花在查找自己程序中的错误上。”
——Maurice Wilkes,《计算机先驱的回忆录》(麻省理工学院出版社,1985 年)
调试声誉不佳。错误总是在最糟糕的时候出现。很难估计错误何时会被修复,或者何时系统会“足够好”让许多人使用。对大多数人来说,编写新代码比调试现有程序更有趣。调试可能被认为是没有回报的。然而,它是必要的,当通过学习新的事实和工具的视角来看待时,你甚至可能会发现这种实践是令人愉快的。根据我们的经验,调试也使我们成为更好的程序员,并提醒我们有时我们并不像我们认为的那么聪明。
示例:临时文件
考虑以下停机事件,我们(作者)在两年前调试过。[1]调查开始时,我们收到了一个警报,称Spanner 数据库的存储配额即将用完。我们经历了调试过程,问自己以下问题:
- 是什么导致数据库存储空间不足?
快速分诊表明,问题是由谷歌庞大的分布式文件系统Colossus中创建了许多小文件积累导致的,这可能是由用户请求流量的变化触发的。
- 是什么在创建所有这些小文件?
我们查看了服务指标,显示这些文件是 Spanner 服务器内存不足导致的。根据正常行为,最近的写入(更新)被缓存在内存中;当服务器内存不足时,它将数据刷新到 Colossus 上的文件中。不幸的是,Spanner 区中的每台服务器只有少量内存来容纳更新。因此,与其刷新可管理数量的较大、压缩的文件,[2]每台服务器都会刷新许多小文件到 Colossus。
- 内存使用在哪里?
每个服务器都作为一个 Borg 任务(在容器中)运行,这限制了可用的内存。[3]为了确定内核内存的使用位置,我们直接在生产机器上发出了slabtop命令。我们确定目录条目(dentry)缓存是内存的最大使用者。
- 为什么 dentry 缓存这么大?
我们做出了一个合理的猜测,即 Spanner 数据库服务器正在创建和删除大量临时文件——每次刷新操作都会有一些。每次刷新操作都会增加 dentry 缓存的大小,使问题变得更糟。
- 我们如何确认我们的假设?
为了验证这个理论,我们在 Borg 上创建并运行了一个程序,通过在循环中创建和删除文件来复现这个错误。几百万个文件后,dentry 缓存已经使用了容器中的所有内存,证实了假设。
- 这是一个内核 bug 吗?
我们研究了 Linux 内核的预期行为,并确定内核缓存了文件的不存在——一些构建系统需要这个特性来确保可接受的性能。在正常操作中,当容器满时,内核会从 dentry 缓存中驱逐条目。然而,由于 Spanner 服务器反复刷新更新,容器从未变得足够满以触发驱逐。我们通过指定临时文件不需要被缓存来解决了这个问题。
这里描述的调试过程展示了我们在本章讨论的许多概念。然而,这个故事最重要的收获是我们调试了这个问题—而你也可以!解决和修复问题并不需要任何魔法;它只需要缓慢和有条理的调查。要分解我们调查的特征:
-
在系统显示出退化迹象后,我们使用现有的日志和监控基础设施调试了这个问题。
-
我们能够调试这个问题,即使它发生在内核空间和调试人员以前没有见过的代码中。
-
我们在这次停机之前从未注意到这个问题,尽管它可能已经存在了几年。
-
系统的任何部分都没有损坏。所有部分都按预期工作。
-
Spanner 服务器的开发人员惊讶地发现,临时文件在文件被删除后仍然可以消耗内存。
-
我们能够通过使用内核开发人员提供的工具来调试内核的内存使用情况。尽管我们以前从未使用过这些工具,但由于我们在调试技术上接受了培训并且有丰富的实践经验,我们能够相对快速地取得进展。
-
我们最初误诊了错误为用户错误。只有在检查了我们的数据后,我们才改变了主意。
-
通过提出假设,然后创建一种测试我们理论的方法,我们在引入系统更改之前确认了根本原因。
调试技术
本节分享了一些系统化调试技术。(4) 调试是一种可以学习和实践的技能。SRE 书的第十二章提供了成功调试的两个要求:
-
了解系统应该如何工作。
-
要有系统性:收集数据,假设原因,测试理论。
第一个要求更加棘手。以一个由单个开发人员构建的系统为例,突然离开公司,带走了对系统的所有了解。系统可能会继续工作数月,但有一天它神秘地崩溃了,没有人能够修复它。接下来的一些建议可能有所帮助,但事先了解系统是没有真正替代品的(参见第六章)。
区分马和斑马
当你听到马蹄声时,你首先想到的是马还是斑马?教师有时会向学习如何分诊和诊断疾病的医学生提出这个问题。这是一个提醒,大多数疾病是常见的——大多数马蹄声是由马引起的,而不是斑马。你可以想象为什么这对医学生是有帮助的建议:他们不想假设症状会导致罕见疾病,而实际上这种情况是常见的,而且很容易治疗。
相比之下,经验丰富的工程师在足够大的规模下会观察到常见的和罕见的事件。构建计算机系统的人可以(也必须)努力完全消除所有问题。随着系统规模的增长,运营商随着时间消除了常见问题,罕见问题出现得更频繁。引用Bryan Cantrill的话:“随着时间的推移,马被找到了;只有斑马留下了。”
考虑一种非常罕见的内存损坏问题:位翻转引起的内存损坏。现代纠错内存模块每年遇到无法纠正的位翻转的概率不到 1%⁵。一位工程师调试一个意外的崩溃可能不会想到,“我打赌这是由于内存芯片中极不可能的电气故障引起的!”然而,在非常大的规模下,这些罕见事件变得确定。一个假设的云服务使用 25,000 台机器,可能使用 400,000 个 RAM 芯片的内存。考虑到每个芯片每年发生无法纠正错误的风险不到 0.1%,服务的规模可能导致每年发生 400 次。运行云服务的人可能每天都会观察到内存故障。
调试这些罕见事件可能具有挑战性,但通过正确类型的数据是可以实现的。举个例子,谷歌的硬件工程师曾经注意到某些 RAM 芯片的故障率远远超出预期。资产数据使他们能够追踪故障 DIMM(内存模块)的来源,并且他们能够将这些模块追溯到单个供应商。经过大量的调试和调查,工程师们确定了根本原因:在生产 DIMM 的单个工厂的无尘室中发生了环境故障。这个问题是一个“斑马”——一个只在规模上可见的罕见错误。
随着服务的增长,今天的奇怪异常错误可能会成为明年的常见错误。在 2000 年,谷歌对内存硬件损坏感到惊讶。如今,这样的硬件故障是常见的,我们通过端到端的完整性检查和其他可靠性措施来计划处理它们。
近年来,我们遇到了一些其他罕见事件:
-
两个网络搜索请求散列到相同的 64 位缓存密钥,导致一个请求的结果被用来替代另一个请求。
-
C++将
int64转换为int(只有 32 位),导致在 2³²个请求后出现问题(有关此错误的更多信息,请参见“清理代码”)。 -
分布式再平衡算法中的一个错误只有在代码同时在数百台服务器上运行时才会触发。
-
有人让负载测试运行了一个星期,导致性能逐渐下降。我们最终确定机器逐渐出现了内存分配问题,导致了性能下降。我们发现了这个罕见的错误,因为一个通常寿命较短的测试运行时间比正常情况下长得多。
-
调查缓慢的 C++测试表明,动态链接器的加载时间与加载的共享库数量呈超线性关系:在加载了 10,000 个共享库时,启动运行
main可能需要几分钟。
在处理较小、较新的系统时,预计会出现常见的错误。在处理较老、较大和相对稳定的系统时,预计会出现罕见的错误——操作员可能已经观察到并修复了随时间出现的常见错误。问题更有可能在系统的新部分出现。
为调试和调查留出时间
安全调查(稍后讨论)和调试通常需要很长时间,需要连续数小时的工作。前一节中描述的临时文件情况需要 5 到 10 小时的调试。在运行重大事件时,通过将调试人员和调查人员与逐分钟的响应隔离开来,为他们提供专注的空间。
调试奖励缓慢、系统的、持久的方法,人们在这种方法中会反复检查他们的工作和假设,并愿意深入挖掘。临时文件问题也提供了调试的一个负面例子:最初的第一响应者最初诊断停机是由用户流量引起的,并将系统行为不佳归咎于用户。当时,团队处于运营超载状态,并因非紧急页面而感到疲劳。
注意
SRE 工作手册的第十七章讨论了减少运营超载。SRE 书的第十一章建议每班次将工单和寻呼器数量控制在两个以下,以便工程师有时间深入研究问题。
记录你的观察和期望
写下你所看到的。另外,写下你的理论,即使你已经拒绝了它们。这样做有几个优点:
-
这为调查引入了结构,并帮助你记住调查过程中所采取的步骤。当你开始调试时,你不知道解决问题需要多长时间——解决可能需要五分钟或五个月。
-
另一个调试器可以阅读你的笔记,了解你观察到的情况,并快速参与或接管调查。你的笔记可以帮助队友避免重复工作,并可能激发其他人想到新的调查途径。有关这个主题的更多信息,请参见SRE 书的第十二章中的“负面结果是魔术”。
-
在潜在的安全问题的情况下,保留每次访问和调查步骤的日志可能是有帮助的。以后,你可能需要证明(有时是在法庭上)哪些行动是攻击者执行的,哪些是调查人员执行的。
在你写下你观察到的内容之后,写下你期望观察到的内容以及原因。错误经常隐藏在你对系统的心理模型和实际实现之间的空间中。在临时文件的例子中,开发人员假设删除文件会删除所有对它的引用。
了解你的系统的正常情况
通常,调试人员开始调试实际上是预期的系统行为。以下是我们经验中的一些例子:
-
一个名为
abort的二进制文件在其shutdown代码的末尾。新开发人员在日志中看到了abort调用,并开始调试该调用,没有注意到有趣的故障实际上是shutdown调用的原因。 -
当 Chrome 网页浏览器启动时,它会尝试解析三个随机域名(比如
cegzaukxwefark.local)以确定网络是否在非法篡改 DNS。甚至 Google 自己的调查团队也曾将这些 DNS 解析误认为是恶意软件试图解析命令和控制服务器主机名。
调试器经常需要过滤掉这些正常事件,即使这些事件看起来与问题相关或可疑。安全调查人员面临的额外问题是持续的背景噪音和可能试图隐藏行动的积极对手。你通常需要过滤掉常规的嘈杂活动,比如自动 SSH 登录暴力破解、用户输错密码导致的认证错误以及端口扫描,然后才能观察到更严重的问题。
了解正常系统行为的一种方法是在你不怀疑有任何问题时建立系统行为的基线。如果你已经有了问题,你可以通过检查问题发生之前的历史日志来推断你的基线。
例如,在第一章中,我们描述了由于对通用日志库的更改而导致的全球 YouTube 中断。这个更改导致服务器耗尽内存(OOM)并失败。由于该库在 Google 内部被广泛使用,我们在事后调查中质疑这次中断是否影响了所有其他 Borg 任务的 OOM 数量。虽然日志表明那天我们有很多 OOM 条件,但我们能够将这些数据与前两周的数据基线进行比较,结果显示 Google 每天都有很多 OOM 条件。尽管这个错误很严重,但它并没有对 Borg 任务的 OOM 指标产生实质性影响。
注意不要将最佳实践的偏差标准化。通常,错误会随着时间变成“正常行为”,您不再注意到它们。例如,我们曾经在一台服务器上工作,其堆内存碎片化达到了约 10%。经过多年的断言,约 10%是预期的,因此是可以接受的损失量,我们检查了碎片化配置文件,很快发现了节省内存的重大机会。
运营超载和警报疲劳可能导致您产生盲点,并因此标准化偏差。为了解决标准化偏差,我们积极倾听团队中的新人,并为了促进新的视角,我们轮换人员参与值班轮换和响应团队——编写文档和向他人解释系统的过程也可能促使您质疑自己对系统的了解程度。此外,我们使用红队(见第二十章)来测试我们的盲点。
重现错误
如果可能的话,尝试在生产环境之外重现错误。这种方法有两个主要优点:
-
您不会影响为实际用户提供服务的系统,因此可以随意使系统崩溃并损坏数据。
-
因为您没有暴露任何敏感数据,所以您可以在不引起数据安全问题的情况下让许多人参与调查。您还可以启用与实际用户数据不适当的操作和额外日志记录等功能。
有时,在生产环境之外进行调试是不可行的。也许错误只会在规模上触发,或者您无法隔离其触发器。临时文件示例就是这样一种情况:我们无法通过完整的服务堆栈重现错误。
隔离问题
如果您能重现问题,下一步是隔离问题,理想情况下是将问题隔离到仍然出现问题的代码最小子集。您可以通过禁用组件或临时注释子程序来做到这一点,直到问题显现出来。
在临时文件示例中,一旦我们观察到所有服务器上的内存管理表现出异常,我们就不再需要在每台受影响的机器上调试所有组件。再举一个例子,考虑一个单独的服务器(在一个大型系统集群中)突然开始引入高延迟或错误。这种情况是对您的监控、日志和其他可观察性系统的标准测试:您能否快速找到系统中众多服务器中的一个坏服务器?有关更多信息,请参见“卡住时该怎么办”。
您还可以在代码内部隔离问题。举一个具体的例子,我们最近调查了一个具有非常有限内存预算的程序的内存使用情况。特别是,我们检查了线程堆栈的内存映射。尽管我们的心理模型假设所有线程具有相同的堆栈大小,但令我们惊讶的是,我们发现不同的线程堆栈有许多不同的大小。一些堆栈非常大,有可能消耗大量内存预算。最初的调试范围包括内核、glibc、Google 的线程库以及所有启动线程的代码。基于 glibc 的pthread_create的一个简单示例创建了相同大小的线程堆栈,因此我们可以排除内核和 glibc 作为不同大小的来源。然后我们检查了启动线程的代码,发现许多库只是随机选择了线程大小,解释了大小的变化。这种理解使我们能够通过专注于少数具有大堆栈的线程来节省内存。
谨慎对待相关性与因果关系
有时调试器会假设同时开始的两个事件或表现出类似症状的事件具有相同的根本原因。然而,相关性并不总是意味着因果关系。两个平凡的问题可能同时发生,但有不同的根本原因。
有些相关性是微不足道的。例如,延迟增加可能导致用户请求减少,仅仅是因为用户等待系统响应的时间更长。如果一个团队反复发现事后看来微不足道的相关性,可能是因为他们对系统应该如何工作的理解存在差距。在临时文件的例子中,如果你知道删除文件失败会导致磁盘满,你就不会对这种相关性感到惊讶。
然而,我们的经验表明,调查相关性通常是有用的,特别是在停机开始时发生的相关性。通过思考,“X出问题了,Y出问题了,Z出问题了;这三者之间有什么共同点?”你可以找到可能的原因。我们还在基于相关性的工具上取得了一些成功。例如,我们部署了一个系统,可以自动将机器问题与机器上运行的 Borg 任务进行相关联。因此,我们经常可以确定一个可疑的 Borg 任务导致了广泛的问题。这种自动化工具产生的相关性比人类观察更有效、统计学上更强大,而且更快。
错误也可能在部署过程中显现——参见SRE 书中的第十二章。在简单的情况下,正在部署的新代码可能存在问题,但部署也可能触发旧系统中的潜在错误。在这些情况下,调试可能错误地集中在正在部署的新代码上,而不是潜在的问题。系统性的调查——确定发生了什么,以及为什么——在这些情况下是有帮助的。我们曾经见过的一个例子是,旧代码的性能比新代码差得多,这导致了对整个系统的意外限制。当其性能改善时,系统的其他部分反而过载。停机与新部署相关联,但部署并不是根本原因。
用实际数据测试你的假设
在调试时,很容易在实际查看系统之前就对问题的根本原因进行推测。在处理性能问题时,这种倾向会引入盲点,因为问题通常出现在调试人员长时间没有查看的代码中。例如,有一次我们在调试一个运行缓慢的 Web 服务器。我们假设问题出在后端,但分析器显示,将每一点可能的输入记录到磁盘,然后调用sync导致了大量的延迟。只有当我们放下最初的假设并深入研究系统时,我们才发现了这一点。
可观察性是通过检查系统的输出来确定系统正在做什么的属性。像Dapper和Zipkin这样的追踪解决方案对这种调试非常有用。调试会话从基本问题开始,比如,“你能找到一个慢的 Dapper 跟踪吗?”⁶
注意
对于初学者来说,确定最适合工作的工具,甚至了解存在哪些工具可能是具有挑战性的。Brendan Gregg 的《系统性能》(Prentice Hall,2013)提供了全面的工具和技术介绍,是性能调试的绝佳参考。
重新阅读文档
考虑来自Python 文档的以下指导:
比较运算符之间没有暗示的关系。
x==y的真实性并不意味着x!=y是假的。因此,在定义__eq__()时,应该同时定义__ne__(),以便运算符的行为符合预期。
最近,谷歌团队花了大量时间调试内部仪表板优化。当他们陷入困境时,团队重新阅读了文档,并发现了一个明确的警告消息,解释了为什么优化从未起作用。人们习惯了仪表板的性能缓慢,他们没有注意到优化完全无效。⁷最初,这个错误似乎很显著;团队认为这是 Python 本身的问题。在他们找到警告消息后,他们确定这不是斑马,而是马——他们的代码从未起作用。
练习!
调试技能只有经常使用才能保持新鲜。通过熟悉相关工具和日志,您可以加快调查的速度,并将我们在这里提供的提示保持在脑海中。定期练习调试还提供了机会来脚本化过程中常见和乏味的部分,例如自动化检查日志。要提高调试能力(或保持敏锐),请练习,并保留在调试会话期间编写的代码。
在谷歌,我们通过定期的大规模灾难恢复测试(称为 DiRT,或灾难恢复测试计划)⁸和安全渗透测试(见第十六章)来正式练习调试。规模较小的测试,涉及一两名工程师在一个小时内进行测试,更容易设置,但仍然非常有价值。
当你陷入困境时该怎么办
当您调查一个问题已经几天了,仍然不知道问题的原因时,您应该怎么办?也许它只在生产环境中表现出来,而且您无法在不影响实际用户的情况下重现错误。也许在缓解问题时,日志轮转时丢失了重要的调试信息。也许问题的性质阻止了有用的日志记录。我们曾经调试过一个问题,其中一个内存容器耗尽了 RAM,内核为容器中的所有进程发出了 SIGKILL,停止了所有日志记录。没有日志,我们无法调试这个问题。
在这些情况下的一个关键策略是改进调试过程。有时,使用开发事后总结的方法(如第十八章中所述)可能会提出前进的方法。许多系统已经投入生产多年甚至几十年,因此改进调试的努力几乎总是值得的。本节描述了改进调试方法的一些途径。
提高可观察性
有时,您需要查看一些代码在做什么。这段代码分支被使用了吗?这个函数被使用了吗?这个数据结构可能很大吗?这个后端在 99th 百分位数上很慢吗?这个查询使用了哪些后端?在这些情况下,您需要更好地了解系统。
在某些情况下,像添加更多结构化日志以提高可观察性的方法是直接的。我们曾经调查过一个系统,监控显示它服务了太多的 404 错误,⁹但是 Web 服务器没有记录这些错误。在为 Web 服务器添加额外的日志记录后,我们发现恶意软件试图从系统中获取错误文件。
其他调试改进需要严肃的工程努力。例如,调试像Bigtable这样的复杂系统需要复杂的仪器。Bigtable 主节点是 Bigtable 区域的中央协调器。它在 RAM 中存储服务器和平板的列表,并且几个互斥体保护这些关键部分。随着谷歌的 Bigtable 部署随着时间的推移而增长,Bigtable 主节点和这些互斥体成为了扩展瓶颈。为了更好地了解可能的问题,我们实现了一个包装器,围绕互斥体暴露诸如队列深度和互斥体持有时间等统计信息。
像 Dapper 和 Zipkin 这样的追踪解决方案对于这种复杂的调试非常有用。例如,假设您有一个 RPC 树,前端调用一个服务器,服务器调用另一个服务器,依此类推。每个 RPC 树在根处分配了一个唯一的 ID。然后,每个服务器记录有关其接收的 RPC、发送的 RPC 等的跟踪。Dapper 集中收集所有跟踪,并通过 ID 将它们连接起来。这样,调试器可以看到用户请求所触及的所有后端。我们发现 Dapper 对于理解分布式系统中的延迟至关重要。同样,Google 在几乎每个二进制文件中嵌入了一个简单的 Web 服务器,以便提供对每个二进制文件行为的可见性。该服务器具有调试端点,提供计数器、所有运行线程的符号化转储、正在进行的 RPC 等。有关更多信息,请参阅 Henderson(2017)。
注意
可观察性并不是了解系统的替代品。它也不是调试时批判性思维的替代品(遗憾!)。我们经常发现自己在疯狂地添加更多日志记录和计数器,以便了解系统正在做什么,但只有当我们退后一步并思考问题时,真正发生的情况才会变得清晰。
可观察性是一个庞大且快速发展的主题,它不仅对调试有用。如果您是一个开发资源有限的较小组织,可以考虑使用开源系统或购买第三方可观察性解决方案。
休息一下
与问题保持一定的距离往往会在回到问题时带来新的见解。如果您一直在进行调试并遇到停顿,请休息一下:喝点水,出去走走,锻炼一下,或者读一本书。有时候,好好睡一觉后,bug 会显露出来。我们的法医调查团队的一位资深工程师在团队的实验室里放了一把大提琴。当他真正陷入问题时,他通常会退到实验室 20 分钟左右来演奏;然后他重新充满活力和专注。另一位调查员随时保持一把吉他,其他人在桌子上保留着素描和涂鸦本,这样他们在需要进行心智调整时可以画画或制作一个愚蠢的动画 GIF 与团队分享。
还要确保保持良好的团队沟通。当您离开一会儿休息时,让团队知道您需要休息并且正在遵循最佳实践。记录调查的进展和您陷入困境的原因也是有帮助的。这样做可以使另一位调查员更容易接手您的工作,也可以让您回到离开的地方。第十七章有关于保持士气的更多建议。
清理代码
有时您怀疑代码块中存在 bug,但却看不到它。在这种情况下,试图通用地提高代码质量可能会有所帮助。正如本章前面提到的,我们曾经调试过一段代码,它在 2³²个请求后在生产环境中失败,因为 C++将int64转换为int(仅 32 位)并截断了它。尽管编译器可以使用-Wconversion警告您有关此类转换,但我们没有使用该警告,因为我们的代码有许多良性转换。清理代码使我们能够使用编译器警告来检测更多可能的 bug,并防止与转换相关的新 bug。
以下是一些清理的其他提示:
-
提高单元测试覆盖率。针对您怀疑可能存在 bug 的函数,或者具有出现 bug 的记录的函数。 (有关更多信息,请参见第十三章。)
-
对于并发程序,请使用消毒剂(参见“消毒您的代码”)和注释互斥锁。
-
改善错误处理。通常,围绕错误添加一些更多的上下文就足以暴露问题。
删除它!
有时候错误隐藏在传统系统中,特别是如果开发人员没有时间熟悉或保持熟悉代码库,或者维护已经中断。传统系统也可能受到损害或产生新的错误。与其调试或加固传统系统,不如考虑删除它。
删除传统系统也可以改善您的安全姿态。例如,有一位作者曾经通过谷歌的漏洞奖励计划(如第二十章中所述)被一位安全研究人员联系,后者在我们团队的一个传统系统中发现了一个安全问题。团队之前已经将该系统隔离到自己的网络中,但已经有一段时间没有升级该系统了。团队的新成员甚至不知道传统系统的存在。为了解决研究人员的发现,我们决定删除该系统。我们不再需要它提供的大部分功能,并且我们能够用一个更简单的现代系统来替换它。
注意
在重写传统系统时要慎重。问问自己,为什么您重写的系统会比传统系统做得更好。有时候,您可能想重写一个系统,因为添加新代码很有趣,而调试旧代码很乏味。替换系统有更好的理由:有时候系统的需求会发生变化,只需少量工作,您就可以删除旧系统。或者,也许您从第一个系统中学到了一些东西,并且可以将这些知识融入到第二个系统中,使其变得更好。
当事情开始出错时停下来
许多错误很难找到,因为错误源和其影响在系统中可能相距甚远。我们最近遇到了一个问题,网络设备正在破坏数百台机器的内部 DNS 响应。例如,程序将对机器exa1进行 DNS 查找,但收到的是exa2的地址。我们的两个系统对这个错误有不同的响应:
-
一个系统,一个档案服务,会连接到
exa2,错误的机器。然而,系统随后检查连接的机器是否是预期的机器。由于机器名称不匹配,档案服务作业失败。 -
另一个收集机器指标的系统会从错误的机器
exa2收集指标。然后,系统会在exa1上触发修复。我们只有在一名技术人员指出他们被要求修复一个没有五个磁盘的机器的第五个磁盘时才检测到这种行为。
在这两种响应中,我们更喜欢档案服务的行为。当系统中的问题及其影响相距甚远时,例如当网络导致应用程序级错误时,使应用程序失败可以防止下游影响(例如怀疑错误系统上的磁盘故障)。我们在第八章中更深入地讨论了是选择失败开放还是失败关闭的话题。
改进访问和授权控制,即使对于非敏感系统也是如此
“厨房里有太多厨师”是有可能的——也就是说,您可能会遇到许多人可能是错误源的调试情况,这使得难以隔离原因。我们曾经因为一个损坏的数据库行而导致了一次宕机,我们无法找到损坏数据的来源。为了消除有人可能会错误地写入生产数据库的可能性,我们最小化了具有访问权限的角色数量,并要求对任何人类访问进行理由说明。尽管数据并不敏感,但实现标准的安全系统帮助我们预防和调查未来的错误。幸运的是,我们还能够从备份中恢复该数据库行。
协作调试:一种教学方法
许多工程团队通过亲自(或通过视频会议)共同解决实际的实时问题来教授调试技术。除了保持经验丰富的调试者的技能更新外,协作调试还有助于为新团队成员建立心理安全感:他们有机会看到团队中最优秀的调试者遇到困难、后退或者有其他困难,这向他们表明,出错和遇到困难是可以接受的。有关安全教育的更多信息,请参见第二十一章。
我们发现以下规则优化了学习体验:
-
只有两个人可以打开笔记本电脑:
-
“驱动者”,执行其他人要求的操作
-
“笔记记录者”
-
每个行动都应由观众决定。只有驱动者和笔记记录者被允许使用计算机,但他们不确定采取的行动。这样,参与者不会独自进行调试,然后提出答案而不分享他们的思考过程和故障排除步骤。
团队共同确定要检查的一个或多个问题,但房间里没有人事先知道如何解决这些问题。每个人都可以要求驱动者执行一个操作来排除故障(例如,打开仪表板,查看日志,重新启动服务器等)。由于每个人都在场见证这些建议,每个人都可以了解参与者建议的工具和技术。即使是经验丰富的团队成员也会从这些练习中学到新东西。
正如 SRE 书的第 28 章所述,一些团队还使用“Wheel of Misfortune”模拟练习。这些练习可以是理论性的,通过口头解决问题的步骤,也可以是实际的,测试者在系统中引入故障。这些场景还涉及两种角色:
-
“测试者”,构建和呈现测试的人
-
“测试者”,试图解决问题,也许在队友的帮助下
一些团队更喜欢安全的分阶段练习环境,但实际的 Wheel of Misfortune 练习需要非常复杂的设置,而大多数系统总是有实时问题需要共同调试。无论采取何种方法,保持一个包容的学习环境非常重要,让每个人都感到安全,积极地做出贡献。
协作调试和 Wheel of Misfortune 练习是向团队介绍新技术和强化最佳实践的绝佳方式。人们可以看到这些技术在现实情况下的用处,通常是解决最棘手的问题。团队也可以一起练习调试问题,使他们在真正的危机发生时更加有效。
安全调查和调试的不同之处
我们期望每个工程师都能调试系统,但我们建议受过训练和有经验的安全和取证专家来调查系统的妥协。当“错误调查”和“安全问题”之间的界限不清晰时,两组专家团队之间有合作的机会。
错误调查通常在系统出现问题时开始。调查侧重于系统中发生了什么:发送了什么数据,这些数据发生了什么,服务如何开始与其意图相反。安全调查开始有点不同,并迅速转向问题,比如:提交了那份工作的用户在做什么?该用户还负责其他什么活动?我们的系统中有活跃的攻击者吗?攻击者接下来会做什么?简而言之,调试更加关注代码,而安全调查可能很快就会关注攻击背后的对手。
我们之前推荐的用于调试问题的步骤在安全调查期间可能也会适得其反。添加新代码、废弃系统等可能会产生意想不到的副作用。我们曾应对过许多事件,其中调试器删除了通常不属于系统的文件,希望解决错误行为,结果发现这些文件是攻击者引入的,因此提醒了调查。在一个案例中,攻击者甚至以删除整个系统的方式做出了回应!
一旦您怀疑发生了安全妥协,您的调查可能也会变得更加紧迫。系统被故意颠覆的可能性引发了一些看起来严肃而紧迫的问题。攻击者的目的是什么?还可能颠覆其他系统吗?您是否需要呼叫执法部门或监管机构?随着组织开始解决运营安全问题,安全调查的复杂性会逐渐增加(第十七章进一步讨论了这个话题)。其他团队的专家,如法律团队,可能会在您开始调查之前介入。简而言之,一旦您怀疑发生了安全妥协,现在是向安全专业人员寻求帮助的好时机。
决定何时停止调查并宣布发生了安全事件可能是一个困难的判断。许多工程师天生倾向于避免通过升级尚未被证明与安全相关的问题来“制造场面”,但继续调查直到证明可能是错误的举动。我们的建议是记住“马和斑马”的区别:绝大多数的错误实际上都是错误,而不是恶意行为。然而,同时也要警惕那些黑白相间的条纹迅速经过。
收集适当和有用的日志
在本质上,日志和系统崩溃转储都只是您可以收集的信息,以帮助您了解系统中发生了什么,并调查问题——无论是意外还是故意的。
在启动任何服务之前,重要的是考虑服务将代表用户存储的数据类型,以及访问数据的途径。假设任何导致数据或系统访问的行为都可能成为未来调查的范围,并且将需要对该行为进行审计。调查任何服务问题或安全问题都严重依赖于日志。
我们这里讨论的“日志”是指系统中结构化的、带有时间戳的记录。在调查过程中,分析人员可能还会严重依赖其他数据源,如核心转储、内存转储或堆栈跟踪。我们建议尽量像处理日志一样处理这些系统。结构化日志对许多不同的业务目的都很有用,比如按使用量计费。然而,我们这里关注的是为安全调查收集的结构化日志——你现在需要收集的信息,以便在未来出现问题时可以使用。
设计您的日志记录为不可变
您构建用于收集日志的系统应该是不可变的。当日志条目被写入时,应该很难对其进行更改(但不是不可能;参见“考虑隐私”),并且更改应该有一个不可变的审计跟踪。攻击者通常会在建立牢固立足后立即从所有日志源中擦除其在系统上的活动痕迹。对抗这种策略的一个常见最佳做法是将日志远程写入集中和分布式的日志服务器。这增加了攻击者的工作量:除了攻击原始系统外,他们还必须攻击远程日志服务器。务必仔细加固日志系统。
在现代计算机时代之前,特别关键的服务器直接记录到连接的线打印机上,就像图 15-1 中的那个,它会在生成记录时将日志记录到纸上。为了抹去它们的痕迹,远程攻击者需要有人物理上取下打印机上的纸并将其烧掉!

图 15-1:线打印机
考虑隐私
隐私保护功能的需求在系统设计中变得越来越重要。虽然隐私不是本书的重点,但在设计安全调查和调试日志时,您可能需要考虑当地法规和您组织的隐私政策。在这个话题上一定要与您组织内的隐私和法律同事进行咨询。以下是一些您可能想要讨论的话题:
日志深度
为了对任何调查最大限度地有用,日志需要尽可能完整。安全调查可能需要检查用户(或使用其帐户的攻击者)在系统内执行的每个操作,他们登录的主机以及事件发生的确切时间。就日志记录而言,达成组织政策上的一致意见,关于可以记录哪些信息是可以接受的,是很重要的,因为许多隐私保护技术都不鼓励在日志中保留敏感用户数据。
保留
对于某些调查,长时间保留日志可能是有益的。根据 2018 年的一项研究,大多数组织平均需要约200 天才能发现系统被入侵。谷歌的内部威胁调查依赖于可以追溯数年的操作系统安全日志。您组织内部关于保留日志的时间长度的讨论是很重要的。
访问和审计控制
我们推荐用于保护数据的许多控制措施也适用于日志。一定要像保护其他数据一样保护日志和元数据。请参阅第五章以获取相关策略。
数据匿名化或假名化
匿名化不必要的数据组件——无论是在写入时还是一段时间后——是一种越来越常见的隐私保护方法,用于处理日志。您甚至可以实现此功能,以便调查人员和调试人员无法确定给定用户是谁,但可以清楚地构建该用户在调试过程中的会话期间的时间线。匿名化很难做到。我们建议咨询隐私专家并阅读有关此话题的已发表文献。¹³
加密
您还可以使用数据的非对称加密来实现隐私保护的日志记录。这种加密方法非常适合保护日志数据:它使用一个非敏感的“公钥”,任何人都可以使用它来安全地写入数据,但需要一个秘密(私钥)来解密数据。像每日密钥对这样的设计选项可以让调试人员从最近的系统活动中获取小的日志数据子集,同时防止某人获取大量的日志数据。一定要仔细考虑如何存储密钥。
确定要保留哪些安全日志
尽管安全工程师通常更喜欢有太多的日志而不是太少的日志,但在记录和保留日志时要有所选择也是值得的。存储过多的日志可能会很昂贵(如“日志预算”中所讨论的),并且筛选过大的数据集可能会减慢调查人员的速度并使用大量资源。在本节中,我们讨论了一些您可能想要捕获和保留的日志类型。
操作系统日志
大多数现代操作系统都内置了日志记录功能。Windows 拥有 Windows 事件日志,而 Linux 和 Mac 拥有 syslog 和 auditd 日志。许多供应商提供的设备(如摄像头系统、环境控制和火警面板)也有标准操作系统,同时也会产生日志(如 Linux)在幕后。内置的日志框架对于调查非常有用,而且几乎不需要任何努力,因为它们通常默认启用或者很容易配置。一些机制,比如 auditd,出于性能原因默认情况下未启用,但在现实世界的使用中启用它们可能是可以接受的折衷方案。
主机代理
许多公司选择通过在工作站和服务器上安装主机入侵检测系统(HIDS)或主机代理来启用额外的日志记录功能。
现代(有时被称为“下一代”)主机代理使用旨在检测日益复杂威胁的创新技术。一些代理结合了系统和用户行为建模、机器学习和威胁情报,以识别以前未知的攻击。其他代理更专注于收集有关系统操作的额外数据,这对离线检测和调试活动很有用。一些代理,如OSQuery和GRR,提供了对系统的实时可见性。
主机代理总是会影响性能,并且经常成为最终用户和 IT 团队之间摩擦的源头。一般来说,代理可以收集的数据越多,其性能影响可能就越大,因为它需要更深入的平台集成和更多的主机处理。一些代理作为内核的一部分运行,而另一些作为用户空间应用程序运行。内核代理具有更多功能,因此通常更有效,但它们可能会因为要跟上操作系统功能变化而遭受可靠性和性能问题。作为应用程序运行的代理更容易安装和配置,并且往往具有较少的兼容性问题。主机代理的价值和性能差异很大,因此我们建议在使用之前对主机代理进行彻底评估。
应用程序日志
日志记录应用程序——无论是供应商提供的,如 SAP 和 Microsoft SharePoint,还是开源的,或者是自定义的——都会生成您可以收集和分析的日志。然后,您可以使用这些日志进行自定义检测,并增强调查数据。例如,我们使用来自 Google Drive 的应用程序日志来确定受损计算机是否下载了敏感数据。
在开发自定义应用程序时,安全专家和开发人员之间的合作可以确保应用程序记录安全相关的操作,例如数据写入、所有权或状态的更改以及与帐户相关的活动。正如我们在“提高可观察性”中提到的,为日志记录仪器化您的应用程序也可以促进调试,以解决其他情况下难以排查的安全和可靠性问题。
云日志
越来越多的组织正在将其业务或 IT 流程的部分转移到基于云的服务,从软件即服务(SaaS)应用程序中的数据到运行关键客户端工作负载的虚拟机。所有这些服务都呈现出独特的攻击面,并生成独特的日志。例如,攻击者可以破坏云项目的帐户凭据,部署新的容器到项目的 Kubernetes 集群,并使用这些容器从集群的可访问存储桶中窃取数据。云计算模型通常每天启动新实例,这使得在云中检测威胁变得动态和复杂。
在检测可疑活动时,云服务具有优势和劣势。使用诸如 Google 的 BigQuery 之类的服务,收集和存储大量日志数据甚至在云中直接运行检测规则都很容易且相对便宜。Google 云服务还提供了内置的日志记录解决方案,如Cloud Audit Logs和Stackdriver Logging。另一方面,由于有许多种云服务,很难识别、启用和集中所有您需要的日志。由于开发人员很容易在云中创建新的 IT 资产,许多公司发现很难识别所有基于云的资产。云服务提供商还可能预先确定对您可用的日志,并且这些选项可能无法配置。了解您的提供商日志记录的限制以及您潜在的盲点非常重要。
各种商业软件,通常本身就基于云,旨在检测针对云服务的攻击。大多数成熟的云提供商提供集成的威胁检测服务,例如 Google 的事件威胁检测。许多公司将这些内置服务与内部开发的检测规则或第三方产品结合使用。
云访问安全代理(CASBs)是一类显着的检测和预防技术。CASBs 作为终端用户和云服务之间的中介,以强制执行安全控制并提供日志记录。例如,CASB 可能会阻止用户上传某些类型的文件,或记录用户下载的每个文件。许多 CASB 具有警报检测功能,可向检测团队发出关于潜在恶意访问的警报。您还可以将 CASB 的日志集成到自定义检测规则中。
基于网络的日志记录和检测
自 20 世纪 90 年代末以来,捕获和检查网络数据包的网络入侵检测系统(NIDSs)和入侵预防系统(IPSs)已成为常见的检测和记录技术。IPSs 还可以阻止一些攻击。例如,它们可能捕获有关哪些 IP 地址交换了流量以及有关该流量的有限信息,例如数据包大小。一些 IPSs 可能具有根据可定制标准记录某些数据包的整个内容的能力,例如发送到高风险系统的数据包。其他人还可以实时检测恶意活动并向适当的团队发送警报。由于这些系统非常有用且成本较低,我们强烈建议几乎任何组织使用它们。但是,请仔细考虑谁能有效地处理它们产生的警报。
DNS 查询日志也是有用的基于网络的来源。DNS 日志使您能够查看公司中是否有任何计算机解析了主机名。例如,您可能想查看网络上是否有任何主机对已知恶意主机名执行了 DNS 查询,或者您可能想检查先前解析的域以识别攻击者控制的每台机器访问的域。安全运营团队还可能使用 DNS“陷阱”,虚假解析已知恶意域,以便攻击者无法有效使用。然后,检测系统往往在用户访问陷阱域时触发高优先级警报。
您还可以使用用于内部或出口流量的任何网络代理的日志。例如,您可以使用网络代理扫描网页以查找钓鱼或已知漏洞模式的指示器。在使用代理进行检测时,您还需要考虑员工隐私,并与法律团队讨论使用代理日志。一般来说,我们建议尽可能将检测调整到恶意内容,以最小化您在处理警报时遇到的员工数据量。
日志预算
调试和调查活动会消耗资源。我们曾经处理过的一个系统有 100TB 的日志,其中大部分从未被使用过。由于日志记录消耗了大量资源,并且在没有问题的情况下日志通常被监视得较少,因此很容易在日志记录和调试基础设施上投资不足。为了避免这种情况,我们强烈建议您提前预算日志记录,考虑您可能需要多少数据来解决服务问题或安全事件。
现代日志系统通常整合了关系型数据系统(例如 Elasticsearch 或 BigQuery),以便实时快速地查询数据。该系统的成本随着需要存储和索引的事件数量、需要处理和查询数据的机器数量以及所需的存储空间而增长。因此,在长时间保留数据时,有必要优先考虑来自相关数据源的日志以进行长期存储。这是一个重要的权衡决定:如果攻击者擅长隐藏自己的行踪,可能需要相当长的时间才能发现发生了事件。如果只存储一周的访问日志,可能根本无法调查入侵事件!
我们还建议以下投资策略用于面向安全的日志收集:
-
专注于具有良好信噪比的日志。例如,防火墙通常会阻止许多数据包,其中大部分是无害的。即使是被防火墙阻止的恶意数据包也可能不值得关注。收集这些被阻止的数据包的日志可能会消耗大量带宽和存储空间,但几乎没有任何好处。
-
尽可能压缩日志。因为大多数日志包含大量重复的元数据,压缩通常非常有效。
-
将存储分为“热”和“冷”。您可以将过去的日志转移到廉价的离线云存储(“冷存储”),同时保留与最近或已知事件相关的日志在本地服务器上以供立即使用(“热存储”)。同样,您可能会长时间存储压缩的原始日志,但只将最近的日志放入具有完整索引的昂贵关系型数据库中。
-
智能地轮换日志。通常,最好首先删除最旧的日志,但您可能希望保留最重要的日志类型更长时间。
强大、安全的调试访问
要调试问题,通常需要访问系统和它们存储的数据。恶意或受损的调试器能否看到敏感信息?安全系统的故障(记住:所有系统都会出现故障!)能否得到解决?您需要确保您的调试系统是可靠和安全的。
可靠性
日志记录是系统可能出现故障的另一种方式。例如,系统可能会因为磁盘空间不足而无法存储日志。在这种情况下,采取开放式失败会带来另一个权衡:这种方法可以使整个系统更具弹性,但攻击者可能会干扰您的日志记录机制。
计划应对可能需要调试或修复安全系统本身的情况。考虑必要的权衡,以确保您不会被系统锁定,但仍然可以保持安全。在这种情况下,您可能需要考虑在安全位置离线保存一组仅用于紧急情况的凭据,当使用时会触发高置信度的警报。例如,最近的一次Google 网络故障导致严重的数据包丢失。当响应者试图获取内部凭据时,认证系统无法连接到一个后端并且失败关闭。然而,紧急凭据使响应者能够进行身份验证并修复网络。
安全性
我们曾经使用的一个用于电话支持的系统允许管理员模拟用户并从他们的角度查看用户界面。作为调试工具,这个系统非常棒;您可以清楚快速地重现用户的问题。然而,这种类型的系统提供了滥用的可能性。从模拟到原始数据库访问的调试端点都需要得到保护。
对于许多事件,调试异常系统行为通常不需要访问用户数据。例如,在诊断 TCP 流量问题时,线上的速度和质量通常足以诊断问题。在传输数据时加密可以保护数据免受第三方可能的观察尝试。这有一个幸运的副作用,即在需要时允许更多的工程师访问数据包转储。然而,一个可能的错误是将元数据视为非敏感信息。恶意行为者仍然可以通过跟踪相关的访问模式(例如,在同一会话中注意到同一用户访问离婚律师和约会网站)从元数据中了解用户的很多信息。您应该仔细评估将元数据视为非敏感信息的风险。
此外,一些分析确实需要实际数据,例如,在数据库中查找频繁访问的记录,然后找出这些访问为什么是常见的。我们曾经调试过一个由单个帐户每小时接收数千封电子邮件引起的低级存储问题。"零信任网络"有关这些情况的访问控制的更多信息。
结论
调试和调查是管理系统的必要方面。重申本章的关键点:
-
调试是一种必不可少的活动,通过系统化的技术而不是猜测来取得结果。您可以通过实现工具或记录来提供对系统的可见性,从而使调试变得更加容易。练习调试以磨练您的技能。
-
安全调查与调试不同。它们涉及不同的人员、策略和风险。您的调查团队应包括经验丰富的安全专业人员。
-
集中式日志记录对于调试目的很有用,对于调查至关重要,并且通常对业务分析也很有用。
-
通过查看一些最近的调查,并问自己什么信息会帮助您调试问题或调查问题,来迭代。调试是一个持续改进的过程;您将定期添加数据源并寻找改进可观察性的方法。
-
设计安全性。您需要日志。调试工具需要访问系统和存储的数据。然而,随着您存储的数据量的增加,日志和调试端点都可能成为对手的目标。设计日志系统以收集您需要的信息,但也要求具有强大的权限、特权和政策来获取这些数据。
调试和安全调查通常依赖于突然的洞察力和运气,即使最好的调试工具有时也会不幸地被置于黑暗中。记住,机会青睐有准备的人:通过准备好日志和一个用于索引和调查它们的系统,您可以利用到来的机会。祝你好运!
¹尽管故障发生在一个大型分布式系统中,但维护较小和自包含系统的人会看到很多相似之处,例如,在涉及单个邮件服务器的故障中,其硬盘已经用完空间!
² Spanner 将数据存储为日志结构合并(LSM)树。有关此格式的详细信息,请参阅 Luo, Chen 和 Michael J. Carey. 2018 年的“基于 LSM 的存储技术:一项调查。”arXiv 预印本arXiv:1812.07527v3。
³有关 Borg 的更多信息,请参阅 Verma, Abhishek 等人 2015 年的“在 Google 使用 Borg 进行大规模集群管理。”第 10 届欧洲计算机系统会议论文集:1-17。doi:10.1145/2741948.2741964。
⁴ 您可能还对 Julia Evans 的博客文章“调试程序是什么样子?”感兴趣。
⁵ Schroeder, Bianca, Eduardo Pinheiro 和 Wolf-Dietrich Weber. 2009 年。《野外的 DRAM 错误:大规模实地研究》。ACM SIGMETRICS Performance Evaluation Review 37(1)。doi:10.1145/2492101.1555372。
⁶ 这些工具通常需要一些设置;我们将在“当你陷入困境时该怎么办”中进一步讨论它们。
⁷ 这是另一个规范偏差的例子,人们习惯于次优行为!
⁸ 请参阅 Krishnan, Kripa. 2012 年。《应对意外情况》。ACM Queue 10(9)。https://oreil.ly/xFPfT。
⁹ 404 是“文件未找到”的标准 HTTP 错误代码。
¹⁰ 亨德森,弗格斯。2017 年。《谷歌的软件工程》。arXiv 预印本arXiv:1702.01715v2。
¹¹ 要全面了解这个主题,请参阅 Cindy Sridharan 的“云原生时代的监控”博客文章。
¹² 请参阅 Julia Rozovsky 的博客文章“成功的谷歌团队的五个关键”和查尔斯·杜希格的纽约时报文章“谷歌从寻求打造完美团队的过程中学到了什么”。
¹³ 例如,参见 Ghiasvand, Siavash 和 Florina M. Ciorba. 2017 年。《用于隐私和存储收益的系统日志匿名化》。arXiv 预印本arXiv:1706.04337。另请参阅 Jan Lindquist 关于个人数据假名化以符合《通用数据保护条例》(GDPR)的规定。
¹⁴ 例如,参见 Joxean Koret 在 44CON 2014 年的演讲“破解杀毒软件”。