1.GoogLeNet简介
GoogLeNet是谷歌推出的基于Inception模块深度卷积神经网络结构。L和N大写还是为了致敬LeNet。在随后的两年中一直在改进,形成了Inception V2、Inception V3、Inception V4等版本。GoogLeNet(Inception-V1),在ImageNet 2014年图像分类竞赛以top-5误差6.7%获得冠军(亚军为VGG)。

一般来说,提升网络性能最直接的办法就是增加网络深度和宽度,但一味地增加,会带来诸多问题:
1)参数太多,如果训练数据集有限,很容易产生过拟合;
2)网络越大、参数越多,计算复杂度越大,难以应用;
3)网络越深,容易出现梯度弥散问题(梯度越往后穿越容易消失),难以优化模型。
VGG虽然效果不错但参数量太大了,Inception希望在增加网络深度和宽度的同时减少参数,为了减少参数,自然就想到将全连接变成稀疏连接。Inception模块对传统的串行堆叠CNN充分分解、解耦,引入并行结构和不同尺寸的卷积核,对视觉信息多尺度并行分开处理再融合汇总。
2.Inception-V1
论文地址:Going Deeper with Convolutions (arxiv.org)
2.1 Inception-V1模块
如同VGG一样,网络特征提取部分主要有多个的Inception模块所组成。原生的Inception模块如下,对于输入将1×1,3×3,5×5卷积和池化全部都用上各自分别处理得到不同尺度下的特征图,并使他们得到相同大小的尺寸,最终再堆叠在一起
-
1x1卷积核:适用于捕获的微小的局部信息和纹理特征
-
3x3卷积核:适用于捕获的局部信息和纹理特征。
-
5x5卷积核:更大的卷积核能够捕获更广范围的特征,对于较大的结构或模式有更好的感知能力。虽然5x5卷积核相对于3x3来说计算开销更大,但它能够更好地捕获图像中更广泛的特征。
-
池化操作:通过最大池化或平均池化,可以在一定程度上保留重要特征并减小特征图的尺寸。
为了使不同的操作得到相同大小的尺寸,参数如下
- 1×1卷积核,padding=0,stride=1
- 3×3卷积核,padding=1,stride=1
- 5×5卷积核,padding=2,stride=1

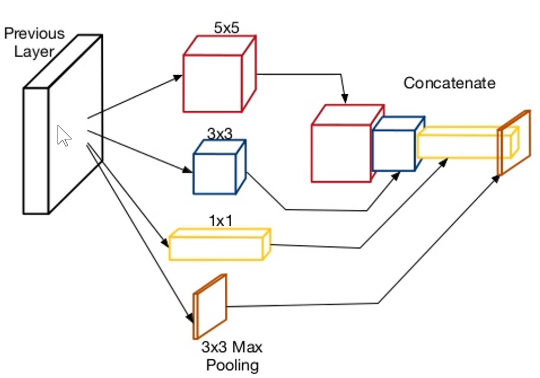
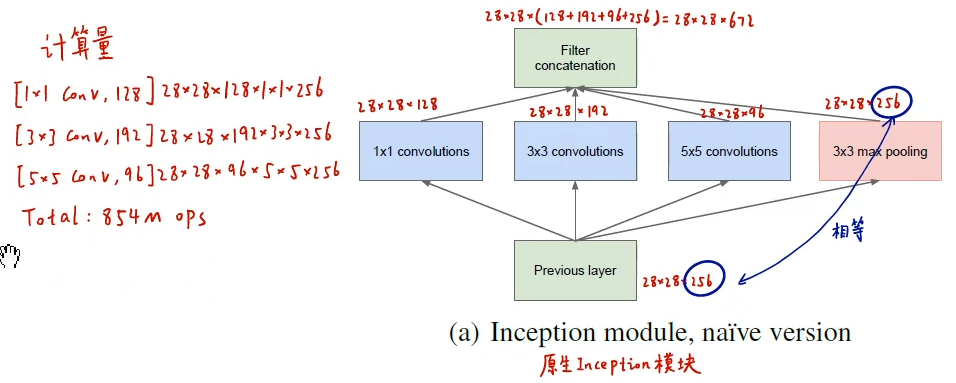
但是这个结构存在很多问题,是不能够直接使用的。首要问题就是参数太多,计算量太大,特征图厚度太大即通道数太多,越往后随着通道数增加这种情况会愈发严重。为了解决这个问题,作者在其中加入了1X1的卷积核,先降低维度减少通道数,改进后的Inception结构如下图

1×1卷积核想法来源于《NetWork in NetWork》一文,它在这里的作用如下:
- 降维,减少参数量和运算量
- 增加模型深度,提高非线性表达能力,因为1×1卷积会多一次激活
2.2 辅助分类器
为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度(辅助分类器)。辅助分类器是将中间某一层的输出用作分类,并按一个较小的权重(0.3)加到最终分类结果中,这样相当于做了模型融合,同时给网络增加了反向传播的梯度信号,也提供了额外的正则化,对于整个网络的训练不仅提高了模型的准确性还极大的减少了参数的数量。

两个辅助分类器的输入分别来自Inception(4a)和Inception(4d)。
- 辅助分类器的第一层是一个平均池化下采样层,池化核大小为5x5,stride=3
- 第二层是卷积层,卷积核大小为1x1,stride=1,卷积核个数是128
- 第三层是全连接层,节点个数是1024
- 0.7的dropout
- 第四层是全连接层,节点个数是1000(对应分类的类别个数)
2.3 全局平均池化
在特征提取完后不再简单使用Flatten而是使用全局平均池化
2.4 整个网络的结构

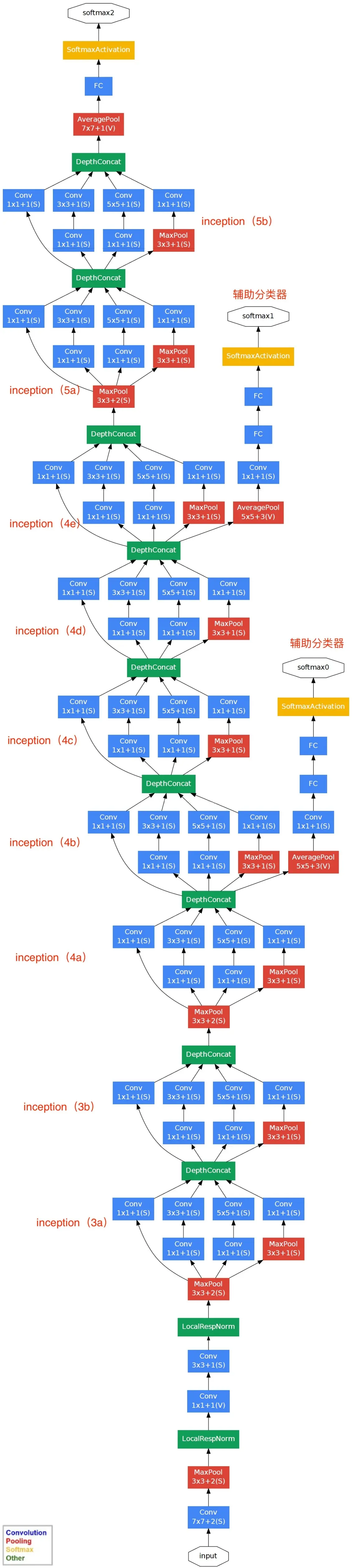
2.5 Inception-V1在Pytorch中使用
GoogLeNet — Torchvision 0.16 documentation (pytorch.org)
比起前面的LeNet,AlexNet,VGG等,Inception搭建起来比较麻烦,推荐使用Pytorch官方实现的,还附带在ImageNet上的预训练权重。与原论文有一小点点不同
model = models.googlenet()
# model = models.googlenet(weights='DEFAULT')
print(model)![]()
卷积后使用了batch-normalization批量归一化,可以加快收敛速度

辅助分类器第一层使用的是最大池化而不是平均池化

此外最后全局的dropout概率是0.2而不是0.4
3.Inception-V2,V3
Inception-V2,V3来自同一篇论文Rethinking the Inception Architecture for Computer Vision (arxiv.org)
nception V2再达到Inception V1的准确率时快了14倍,并且模型在收敛时准确率的上限更高
3.1 卷积分解
Inception-V2有四种不同的模块,均降低了计算量与参数和更多的非线性变换
1.Modele A
在Inception-V1的基础上使用2个3×3卷积代替一个5×5卷积,来源于VGG

改进后的Inception模块如下
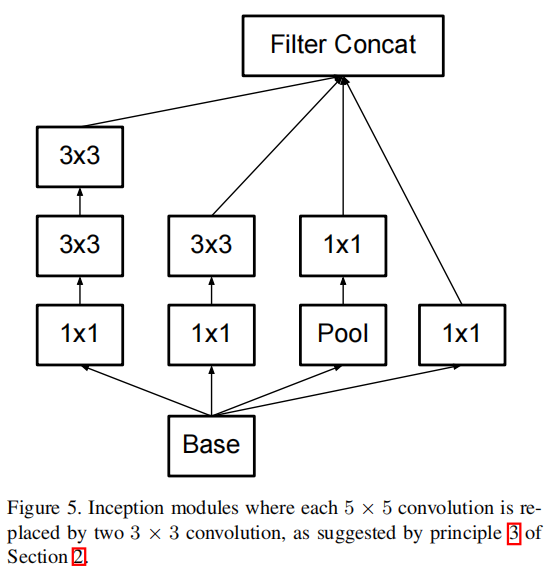
2. Modele B
将对称的conv计算分解为非对称的conv计算,空间可分离卷积
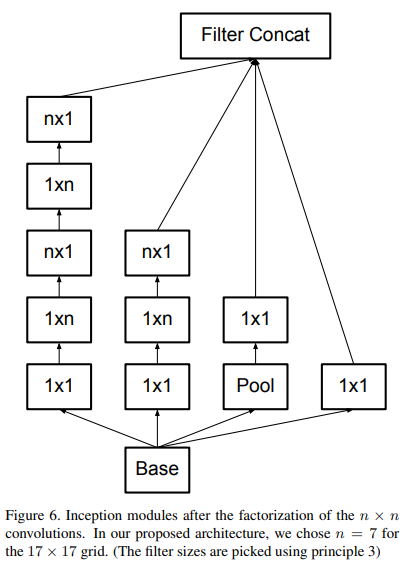
3.Module C
扩增通道数。作者在实际中发现这种结构不适合较早的层,这一个结构在最后面
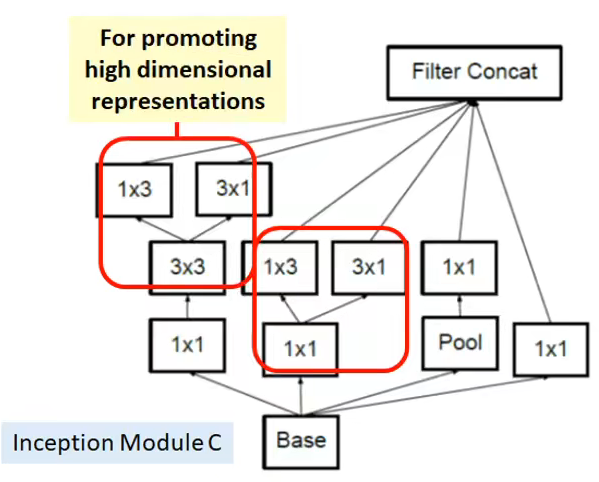
4.Grid Size Reduction
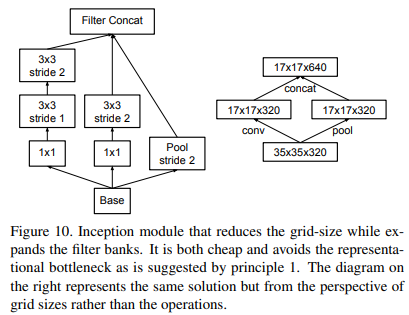
不再直接使用max pooling层进行下采样,因为这样导致信息损失较大。一个可行方案是先进行卷积增加特征channel数量,然后进行pooling,但是计算量较大。所以作者设计了另外一种方案,即两个并行的分支,如图11 所示,一个是pooling层,另外一个卷积层,最后将两者结果concat在一起。
3.2 去除了浅层的辅助分类器
作者发现辅助分类器并没有更快的帮助模型收敛,否定了之前的结论,而且删掉第一个辅助分类器对网络没什么影响
3.3 去除LRN
VGG论文已经提出这个东西用处不大
3.4 引入BN
卷积后批量归一化
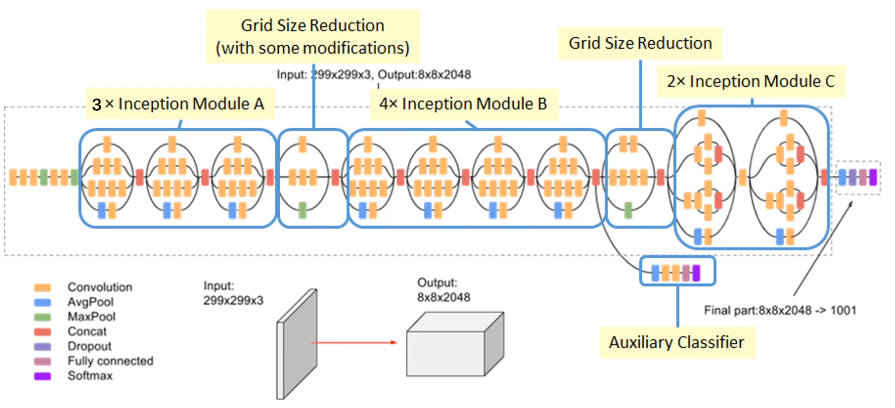
3.5 整个网络结构

2.6 InceptionV3
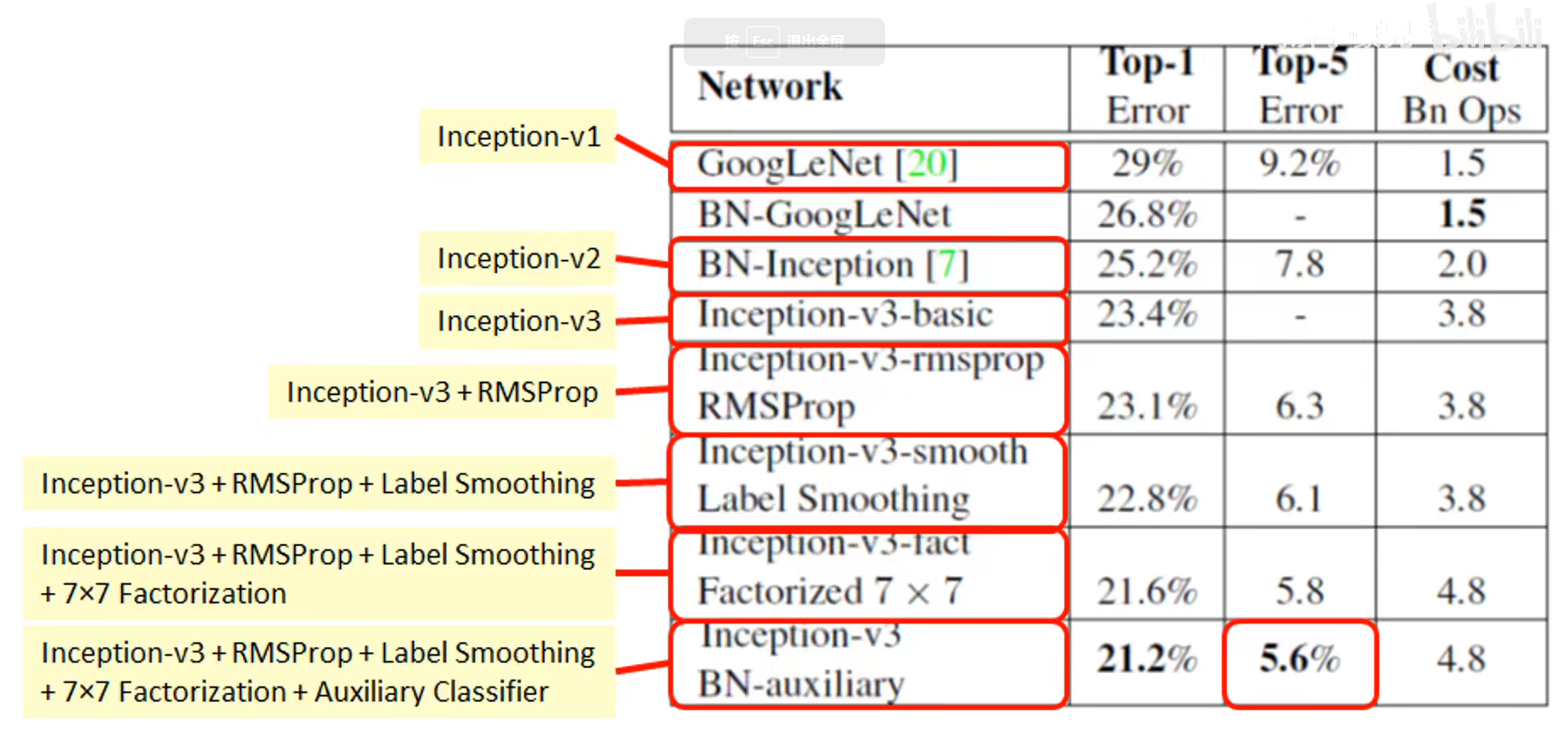
Inception v3 整合了前面 Inception v2 中提到的所有升级,还使用了:
- RMSProp 优化器;
- Factorized 7x7 卷积;
- 辅助分类器使用了 BN;
- 标签平滑(添加到损失公式的一种正则化项,旨在阻止网络对某一类别过分自信,即阻止过拟合)。
2.7 InceptionV3 在Pytorch中使用
model = models.inception_v3()
print(model)注意InceptionV3输入尺寸是299×299
4.InceptionV4,Inception -ResNet
Inception v4 和 Inception -ResNet 在同一篇论文中提出https://arxiv.org/abs/1602.07261 Inception -ResNet使用了ResNet提出的残差连接,
1.Inception-v4
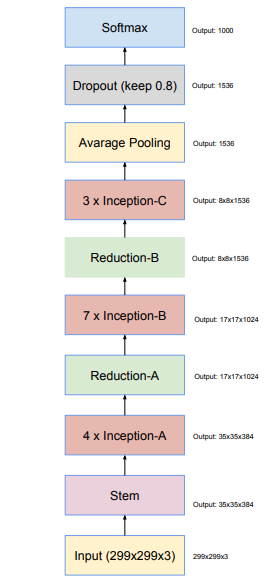
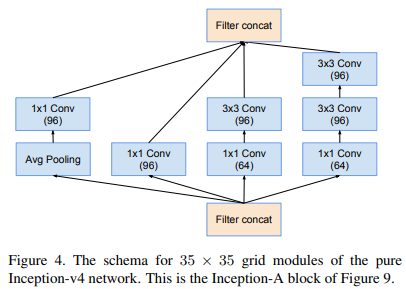
Inception-v4整个网络结构如下,使用了三种不同的InceptionA,B,C和两种下采样模块,其中Stem结构如左图。去掉了所有的辅助分类器,输入大小同样的为299×299×3。

Inception-A
Inception-B

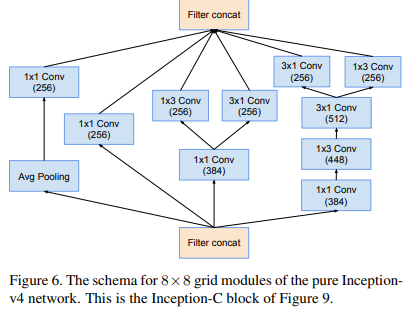
Inception-C
Reduction-A
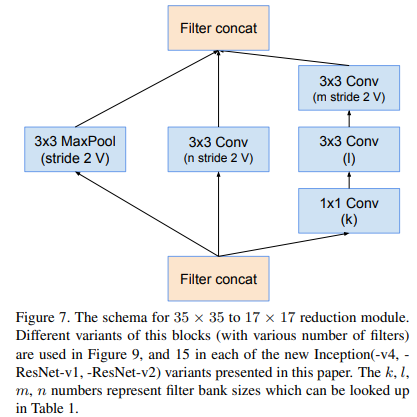
Reduction-B

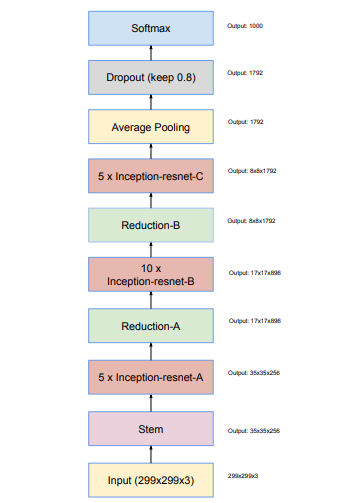
2.Inception -ResNet-V1
整体网络结构如如左图,stem部分如右图

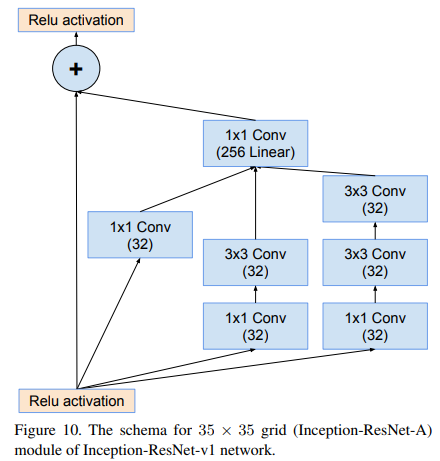
Inception-resnet-A
Inception-resnet-B

Inception-resnet-C

Reduction-A
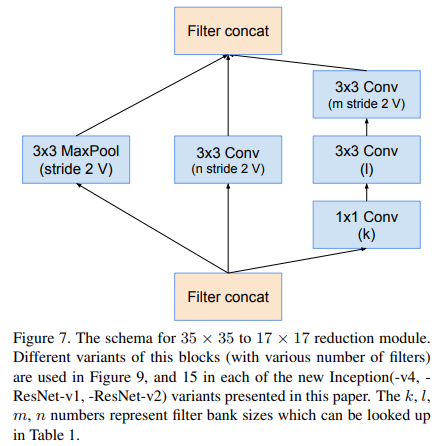
Reduction-B
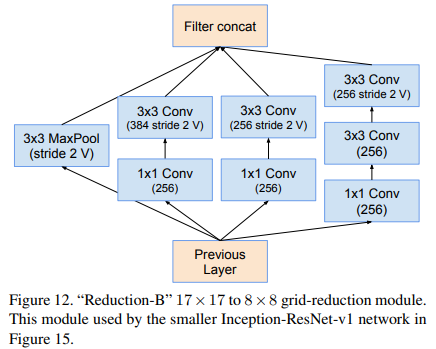
3.Inception -ResNet-V2
Inception -ResNet-V2网络结构和V1是一样的,V2参数更多
Inception-resnet-A

Inception-resnet-B

Inception-resnet-C

Reduction-A

Reduction-B
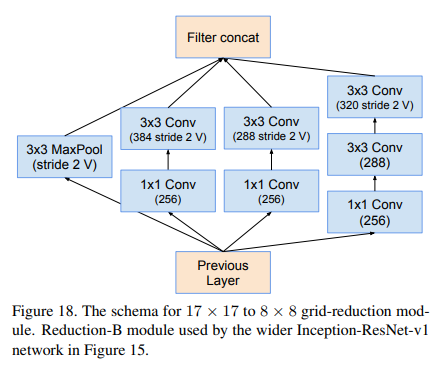
4.Reduction-A参数取值
对于V4,ResV1,ResV2他们的Reduction-A结构是一样的,但是几个卷积的通道数参数是不一样的

5.针对深网络结构设计的衰减因子
文中指出如果卷积核的数量超过 1000,则网络架构更深层的残差单元将导致网络崩溃。即使使用更小的学习率和额外的bn也无法解决。因此,为了增加稳定性,作者通过 0.1 的比例缩放残差激活值,在下图中的Activation Scaling。

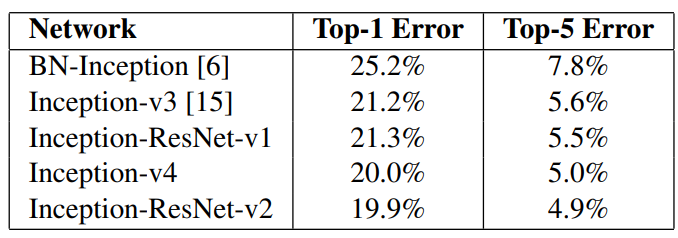
6.性能
1.带残差连接的Inception收敛速度会更快,最终精度差不多,带残差会略微高出一点点
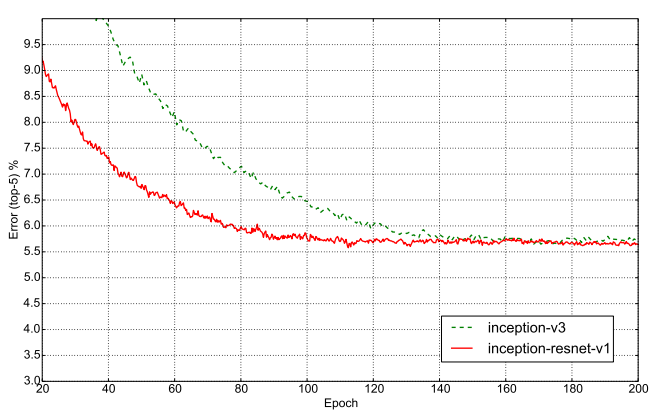

2.Inception-V3和Inception-ResNet-V1性能接近,Inception-V4和Inception-ResNet-V2性能接近,且由于参数更多,模型更复杂后两者优于前两者