起因
python 读文件报错。这个报错不是来自open而是read函数(请看最后部分)。
原因:文件编码不一致。
比如文件本身编码为 gb2312,而 python默认以 utf-8 编码打开,报错。
解决
初级:以通用的 utf-8 编码打开。
with open(file_path, 'r', encoding=‘utf-8’) as file:
code = file.read()
问题:文件本身编码非 utf-8 能够解析的编码,比如gbk,就无法打开了。
中级:先读取文件编码,然后用该编码打开
with open(file_path, 'rb') as file:
content = file.read()
encoding = chardet.detect(content)['encoding']
print("编码为:" + encoding)
with open(file_path, 'r', encoding=encoding) as file:
content = file.read()
问题:当文件本身已经存在部分乱码时,无法打开。
高级:ignore:忽略无法解码或编码的字符,直接跳过。
try:
with open(file_path, 'rb') as file:
content = file.read()
encoding = chardet.detect(content)['encoding']
with open(file_path, 'r', encoding=encoding, errors='ignore') as file:
content = file.read()
except Exception as e:
logging.error(e)
解释:
errors参数解释
errors是一个可选字符串,用于指定如何处理编码和解码错误——不能在二进制模式中使用。
errors 常用的参数值:
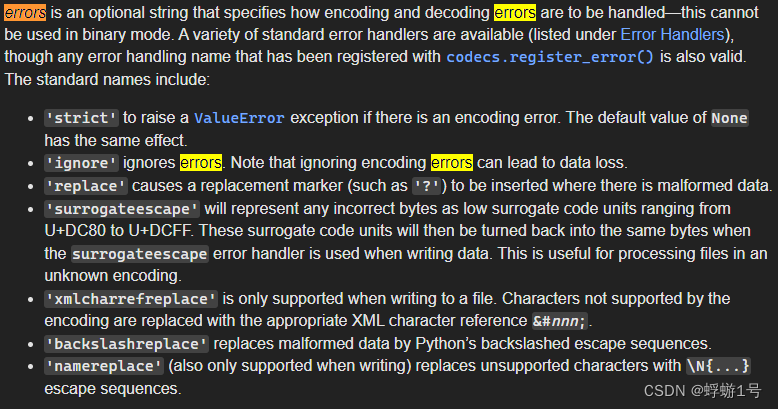
strict:当遇到无法解码或编码的字符时,抛出 ValueError 异常。也是默认值。(解释:UnicodeDecodeError 实际是 read()函数报的错,不是open函数报的)
ignore:忽略无法解码或编码的字符,直接跳过,会缺失这部分内容。
replace:将畸形数据替换为指定字符(比如问号’?')。