一、基础备份
1.创建一个文件用来存储备份数据
2.备份指令
$CurrentDate = Get-Date -Format "yyyy-MM-dd"
$OutputDirectory = "D:\PgsqData\pg_base\$CurrentDate"
$Command = "./pg_basebackup -h 127.0.0.1 -U postgres -Ft -Pv -Xf -z -Z5 -D $OutputDirectory"
Invoke-Expression -Command $Command3.备份成功之后会在你创建的文件夹生成一个压缩包
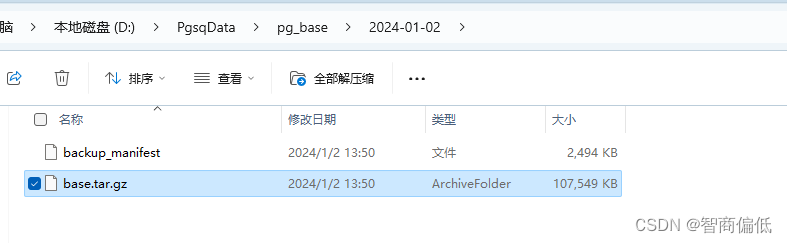 4.恢复操作。关闭pgsql服务,并将原pg的数据文件更改一个名字,将生成的文件解压到原pg数据文件夹
4.恢复操作。关闭pgsql服务,并将原pg的数据文件更改一个名字,将生成的文件解压到原pg数据文件夹
$PGDATA = "C:\Program Files\PostgreSQL\14\data"
./pg_ctl stop -D $PGDATA
提示:备份的文件权限比较高,数据库启动不了,要将所有备份的文件给进行授权,给User用户完全的权限。
重启数据库就可以启动了,此方法也可以用做数据库的迁移,只需要把压缩包解压到新的数据库下面就可以了。
二、归档备份:最后时间
上面的方式简单是简单,但是每次备份都要重新备份整个库,库大的情况下,太过于浪费时间,推荐使用增量备份,每天进行一次归档保存,恢复的时候,只需要把基础数据恢复一次,然后逐次恢复归档数据就可以了。
红色字体为说明,可看可不看
归档备份的原理:PostgreSQL在执行写入操作时,对数据文件的任何修改信息,首先会写入WAL日志,然后才会对数据文件做物理修改。如果数据库服务器掉电或意外宕机,则PostgreSQL重新启动后首先会读取WAL日志,然后根据日志对数据进行恢复。一般来说,通过数据库的全量备份(基础备份)配合WAL日志,是可以将数据库恢复到任意时间点的。
WAL日志的文件个数不是无限增长的,当增长到第N个(N=wal_keep_segments+1)文件时,PostgreSQL会从头开始循环覆盖已生成的WAL日志文件。在恢复时,如果需要的WAL日志文件已经被覆盖,则恢复必然会失败。因此,用户需要根据业务情况来定时对WAL日志文件进行归档。
在恢复数据时,如果使用很久以前的全量备份和归档日志进行恢复,由于需要恢复的WAL日志文件非常多,所以恢复时间会很长。为了解决这个问题,用户应该定期对数据库重新做全量备份,这样在每次恢复时需要恢复的WAL日志文件就比较少,可以缩短恢复过程。
1.开启WAL归档
WAL归档实质上是把在线的WAL日志文件备份出来。在PostgreSQL中配置归档的方法是:设置archive_command参数(其值可以是一个shell命令或一个复杂的shell脚本),并把WAL日志文件复制到其他地方。在postgresql.conf文件中需要修改3个配置项,具体步骤如下。
#归档备份的级别
#wal_level = replica
#启动归档
#archive_mode = on
#设置归档位置
#archive_command = 'copy "%p" D:\\PgsqData\\pg_archive\\"%f"'1.在配置文件种开启上述三个指令之后,然后做一个测试,假设数据库发生故障。需要用基础备份和归档进行恢复。
create table test (id integer);
insert into test values(generate_series(1,10));//在这个位置对基础数据进行备份,此时备份数据库中的数据只有10个
insert into test values(generate_series(1,10));//再加入十个数据,然后进行手动归档
select pg_switch_wal(); //手动触发一次归档,在手动
解释:在插入第一次10条数据后,进行数据库的备份,此时备份数据库只有前十个,插入第二次10个数据的时候,假设在之后的执行过程中,数据库发生错误,靠基础备份和归档文件恢复到最近的时间点。
2.然后重复上面的第四步,先进行基础数据恢复,在数据恢复之后,只有最开始的10条数据,现在启动时间点恢复,做两个配置。
restore_command = 'copy D:\\PgsqData\\pg_archive\\%f %p' //归档文件目录
recovery_target_timeline = 'latest' //最后的时间线3.删除pg_wal里面的数据
4.创建recovery.signal文件,这个文件是提示pg做恢复操作。
5.重新启动服务就可以了。
三、归档备份:基于时间点恢复
1.模拟一个误删操作,创建表数据,插入数据,记录当前时间点,一分钟后删除,更新归档文件。
2.删除data文件,把备份数据copy进来,继续上述流程,修改配置文件,其他操作还是和上面一样的。
recovery_target_time = '2024-01-03 14:44:25.180169+08' # the time stamp up to which recovery will proceed
3.通过时间点恢复的文件没有插入的功能,但是通过时间线恢复的就有插入功能,按道理来说应该是一样的。
如果不能插入,执行一下就可以了
select pg_wal_replay_resume()提示一下,在进行时间点还原的时候,要把原data替换掉,不能直接根据归档文件还原,具体原因等我搞懂,我再更新。看到的一个解释是这么说的PostgreSQL 只能向后恢复, 而不能前恢复。因此PostgreSQL恢复时,必须要搭配基础备份实施。
四、时间点恢复与时间线历史文件
时间线历史文件在第二次及后续 PITR 过程中起着重要作用。通过尝试第二次恢复,我们将探索如何使用它。同样,假设你在12:15:00时间点又犯了一个错误,错误发生在时间线ID为2的数据库集簇上
模拟操作,找到数据库data文件,完成备份之后,会在归档文件中生成如下文件。
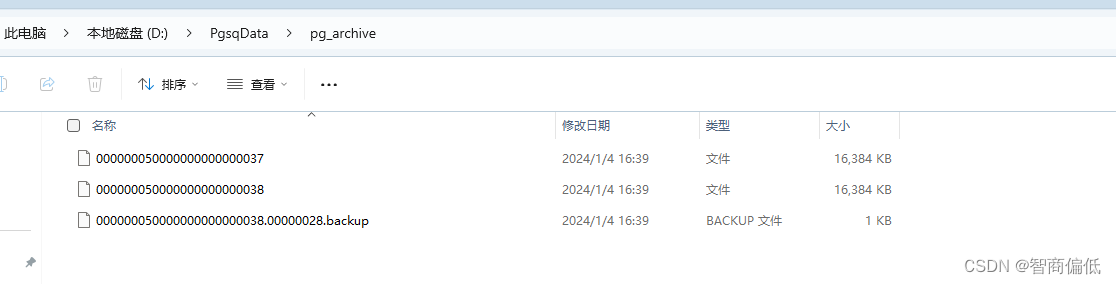
执行以下sql,生成新表
create table test3 (id integer);
insert into test3 values(generate_series(1,10));
select *from test3
select pg_switch_wal();此时归档文件变成下面这样
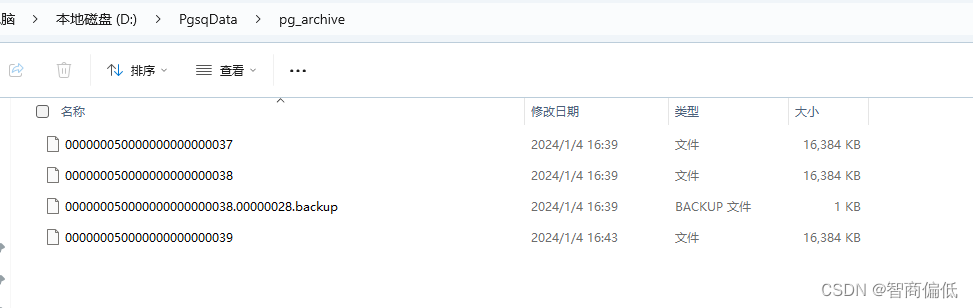
假设在后面操作的时候数据库发生崩溃,将数据恢复到test3 ,重复上面恢复数据的流程。
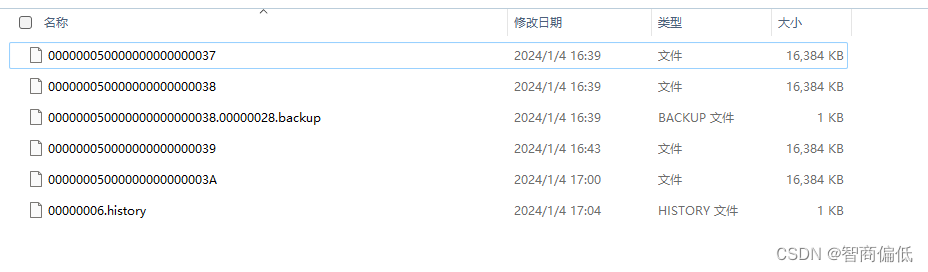
第一次恢复,因为是从归档进行恢复,删除pg_wal里的所有数据。开启数据库,查询到表里面有test3,说明第一次恢复成功,恢复成功,归档文件会生成一个.history结尾的文件
第二次恢复,在恢复之后的数据里面接着插入一个表
create table test4 (id integer);
insert into test4 values(generate_series(1,10));
select *from test4
select pg_switch_wal();假设在后面操作的时候数据库发生崩溃,将数据恢复到test3 ,重复上面恢复数据的流程。先移除data,再解压备份。
第二次恢复成功之后,生成一个新的.history文件。
第二天恢复,这是在所有流程绝对合法的情况下进行,假设第一天过完了,我们保存了第一天的归档,从第二天开始出现了错误,因为备份的文件不在一个文件夹,第一天没有用完的wal第二天接着用,所以在恢复的时候应该把所有wal文件都集中到一个文件夹里面,这样新的同名文件会自动覆盖,应该怎么恢复呢。
create table test7 (id integer);
insert into test7 values(generate_series(1,10));
select *from test7
select pg_switch_wal();猜测,在没有开启归档文件的情况下,数据误删之后,可以通过data里面pg_wal数据进行恢复吗。
如果有基础备份的情况下,并且pg_wal里面的归档没有被自动更新的情况下,可以恢复。
五、主从库设计
存储数据库副本的每个节点被称为副本。每一次对数据库的写入操作都需要传播到所有副本上,否则副本就会包含不一样的数据。最常见的解决方案是基于领导者的复制,也称为主动/被动或主/从复制。其中,副本之一被指定为领导者,也称为主库或首要。当客户端要向数据库写入时,它必须将请求发送给领导者,领导者会将新数据写入其本地存储。其他副本被称为追随者,也称为只读副本、从库、次要或热备。
这种原生复制功能是基于日志传输实现的,是一种通用的复制技术:主库不断发送WAL数据,而每个备库接受WAL数据,并立即重放日志。
· 流复制的启动
· 如何实施流复制
· 管理多个备库
· 备库的故障检测
实践出真知,现在我们安装两个数据库
主库192.168.1.12 5433
从库192.168.1.6 5433
主库开启配置
主库添加一个用于复制的用户replica
CREATE ROLE replica REPLICATION LOGIN PASSWORD '123456';主库添加白名单
在文件 /var/lib/pgsql/13/data/pg_hba.conf 下添加:
host all all 192.168.0.1/24 trust
# 允许从库通过replica用户连接主库
host replication replica 192.168.0.101/32 md
主库创建归档目录
mkdir /var/lib/pgsql/13/archivelog
主库设置,开启归档
/var/lib/pgsql/13/data/postgresql.conf
listen_addresses = '*'
port = 5432
max_connections = 100
max_wal_size = 1GB
min_wal_size = 80MB
log_timezone = 'Asia/Shanghai'
archive_mode = on
archive_command = 'test ! -f /var/lib/pgsql/13/archivelog/%f && cp %p /var/lib/pgsql/13/archivelog/%f'
wal_level = replica
max_wal_senders = 10
wal_sender_timeout = 60s
配置完重启主库
systemctl restart postgresql-13.service
从库配置
同步主库的data目录
# 删除从库的data目录
rm -rf /var/lib/pgsql/13/data
# 同步主库的data目录,pg_basebackup是PostgreSQL自带的基础备份工具
pg_basebackup -h 192.168.0.100 -U replica -D /var/lib/pgsql/13/data -X stream -P

修改data目录的权限
chmod -R 700 /var/lib/pgsql/13/data
创建文件standby.signal(版本11开始)
/var/lib/pgsql/13/data/standby.signal
(pg版本11后已经废除recovery.conf)
# 表示该节点是从库
standby_mode = on
修改从库的postgresql.conf文件
primary_conninfo = 'host=192.168.0.100 port=5432 user=replica password=123456'
hot_standby = on
max_standby_streaming_delay = 30s
wal_receiver_status_interval = 10s
hot_standby_feedback = on
重启从库
systemctl restart postgresql-13.service
验证主库从库时候同步成功
主库查询
postgres=# select * from pg_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start |
backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority |
sync_state | reply_time
-------+----------+---------+------------------+---------------+-----------------+-------------+-------------------------------+-
-------------+-----------+-----------+-----------+-----------+------------+-----------+-----------+------------+---------------+-
-----------+-------------------------------
21228 | 16384 | replica | walreceiver | 192.168.0.101 | | 39558 | 2022-03-22 23:16:39.903294+08 |
490 | streaming | 0/C000A58 | 0/C000A58 | 0/C000A58 | 0/C000A58 | | | | 0 |
async | 2022-03-22 23:19:00.131093+08
(1 row)







![[redis] redis主从复制,哨兵模式和集群](https://img-blog.csdnimg.cn/direct/303ccb08b29b476aa539b8be3ae2d94d.png)