Java虚拟机之运行时数据区
简述
Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域。这些区域有各自的用途,以及创建和销毁的时间,有的区域随着虚拟机进行启动而一直存在,有些区域则是依赖用户线程的启动和结束而建立和销毁。
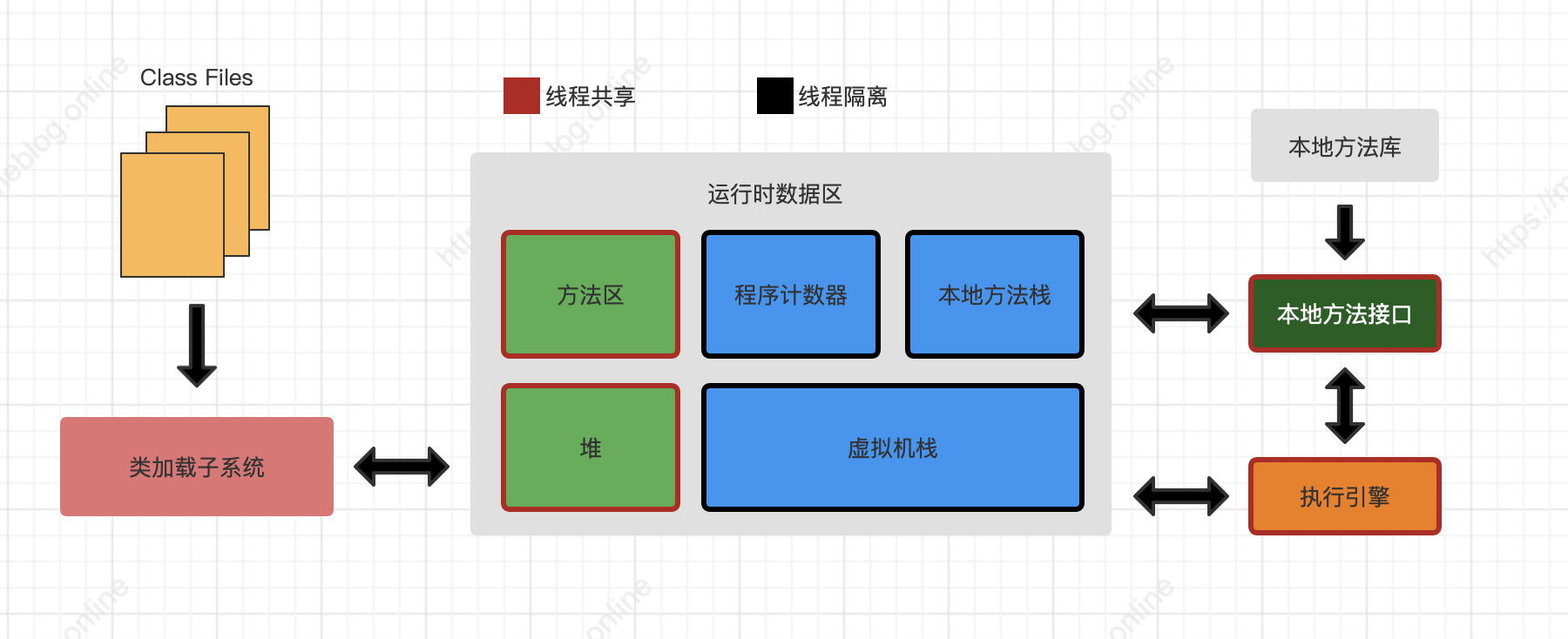
一. 程序计数器
程序计数器是一块较小的内存空间,它可以看作的当前线程所执行的字节码行号指示器。
1.1. 作用
Java虚拟机中字节码解释器工作时时通过改变这个计数器的值来选取下一条需要执行的字节码指令,它是程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都需要它。
1.2. 特点
程序计数器有下面两个特点:
- 线程私有(为了线程切换之后可以恢复到正确的位置,每个线程都需要一个独立的程序计数器,各个线程之间互不影响,独立存储);
- 不存在内存溢出(这个确实是Java虚拟机规范中没有规定任何
OutOfMemoryError情况的区域);
1.3. 注意点
程序计数器在遇到Java方法和本地方法的时候情况不一样:
- 如果正在执行的是一个
Java方法,计数器记录的是正在执行的虚拟机字节码指令的地址; - 如果正在执行的是本地方法,计数器的值是空(
undefind);
二. Java虚拟机栈
2.1. 定义
虚拟机栈描述的是Java方法执行的线程内存模型:每个方法执行的时候,Java虚拟机都会同步创建一个栈帧(栈帧用来存储局部变量表、操作数栈、动态连接、方法出口等信息)。每个方法被调用直至执行完毕的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。
每个线程只能有一个活动栈帧,对应着当前正在执行的那个方法
2.2. 特点
Java虚拟机栈有下面的特点:
- 线程私有,和线程的生命周期一致;
- 这个区域存在两类异常情况:
- 线程请求的栈深度大于虚拟机所允许的深度(递归操作),抛出
StackOverflowError异常; - 如果Java虚拟机栈容量可以动态扩容,当无法申请到足够的内存会抛出
OutOfMermoryError异常;
- 线程请求的栈深度大于虚拟机所允许的深度(递归操作),抛出
2.3. 注意点
关于Java虚拟机栈我们需要注意下面几点内容:
- 垃圾回收不涉及栈内存;
- 并不是栈内存分配的越大越好(栈内存越大线程数量越少),可以通过
-Xss size指定栈内存大小(Linux/MacOS默认是1024KB); - 方法内的局部变量(没有逃离方法作用域)是线程安全的;
三. 本地方法栈
3.1. 定义
本地方法栈和虚拟机栈所发挥的作用相似,区别在于虚拟机栈是虚拟机执行Java方法,本地方法栈执行的本地方法是用native标识的非Java方法,例如Object对象中的一些方法:
public final native Class<?> getClass();
public native int hashCode();
3.2. 注意点
Java虚拟机规范对本地方法栈的语言、使用方法和数据结构没有做任何强制规范。HotSpot虚拟机将本地方法栈和虚拟机栈合并。本地方法栈和虚拟机栈一样会抛出相同的异常:
- 线程请求的栈深度大于虚拟机所允许的深度:
StackOverflowError异常; - 栈扩展失败抛出
OutOfMermoryError异常;
四. Java堆
4.1. 定义
Java堆是虚拟机所管理的内存中最大的一块。Java堆是被所有线程共享的一块内存区域,在虚拟机启动时创建;这块区域唯一的目的是存放对象实例(new关键字)。
4.2. 特点
Java的特点归纳:
-
存放实例化对象和数组
-
有垃圾回收机制
-
线程共享
-
堆无法扩容(
-Xmx(最大)/-Xms(最小)设置堆大小)会抛出OutOfMermoryError异常;
五. 方法区
5.1. 定义
方法区是线程共享区域,在虚拟机启动时闯将,它用于存储已被虚拟机加载的类型信息、常量、静态变量、即时编译后的代码缓冲等数据。如果方法区无法满足新的内存分配需求时,将抛出OutOfMemoryError异常。
方法区可以使用 -XX:MaxMetaspaceSize 标志设置最大元空间大小,默认值为 unlimited,这意味着它只受系统内存的限制;该调整标志定义元空间的初始大小如果未指定此标志,则 Metaspace 将根据运行时的应用程序需求动态地重新调整大小。
5.2. 永久代和元空间
逻辑上是堆的一部分,但是不同jvm实现对于方法区的实现不一样。Hotspot在JDK1.8之前是使用永久代实现,1.8之后使用元空间实现。
永久代使用Hotspot虚拟机设计团队选择把收集器的分代设计扩展到了方法区(也可以是使用永久代实现方法区),但是这样过设计更容造成Java内存溢出。可以通过参数-XX:MaxPermSize来设置方法区的大小。
元空间就是使用本地内存来实现的方法区。
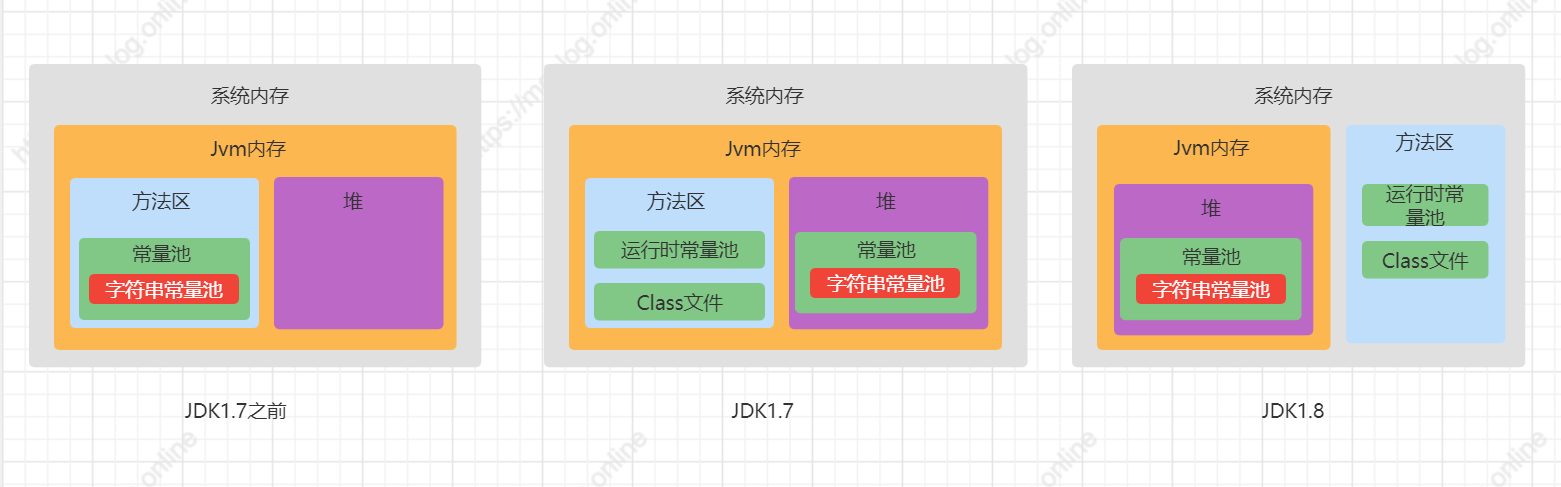
变化:
- 在
JDK1.7前,运行时常量池和字符串常量池是存放在方法区中,HotSpot对方法区的实现称为永久代; - 在
JDK1.7中,字符串常量池从方法区移到堆中,运行时常量池保留在方法区中; - 在
JDK1.8中,HotSpot移除永久代,使用元空间代替,此时字符串常量池保留在堆中,运行时常量池保留在方法区中,只是实现不一样了,JVM内存变成了直接内存;
5.3. 注意点
方法区和Java堆一样不需要连续的内存、可以选择固定大小和可扩展之外,设置可以不实现垃圾回收机制。
虽然方法区的垃圾收集行为较少,但是也是很有必要。这个区域主要的回收目标是针对常量池的回收和对类型的卸载。
5.4. 运行时常量池
运行时常量池是方法区的一部分。Class文件中除了有类的版本、字段、方法、接口等描述类信息之外,还有一项信息是常量池(Constant Pool Table),用来存放编译期生成的各种字面量和符号的引用。
运行时常量池相具有动态性,Java语言并不要求一定只有编译期才能产生,运行期间也可以将新的常量放入池中,例如String类的intern()方法。
运行时常量池是方法区的一部分,自然受到方法区内存的限制,当常量池内存无法扩容将抛出OutOfMemoryError异常。
5.5. 静态常量池、运行时常量池和字符串常量池
在方法区中有几个概念容易混淆,下面逐一看一下。
Java文件编译之后,没有被加载的class文件的数据被称为静态常量池;但是经过Jvm把class文件装入内存、加载到方法区后,常量池就会变成运行时常量池。对应的符号引用在程序加载或者运行的时候会被转变为被加载到方法区的代码的直接引用,在Jvm调用这个方法的时候,就可以根据这个直接引用找到方法在方法区的位置,然后去执行。**字符串常量池(StringTable)**又是运行时常量池中的一小部分,字符串常量池不同的JDK版本位置有所不同。
5.6. 其他常量池
Java中基本类型的包装类的大部分都在堆中实现了常量池技术(也可以称为对象池)。
其中包括Byte、Short、Integer、Long、Character和Boolean;但是不包括Float、Double。
注意:Byte、Short、Integer、Long、Character这种整型包装类并不是所值都会用到对象池,只有在[-128,127]之间才可以使用。
这点我们可以在源码种看到:
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
六. 直接内存
直接内存并不属于虚拟机运行时数据区的一部分。但是这部分确是被频繁使用,而且也可能导致OutOfMemoryError异常。
本机的直接内存的分配是不受到Java堆的大小的限制,但是受到本机总内存大小以及处理器寻址空间的限制,如果动态扩展失败会抛出OutOfMemoryError异常。
七. 字符串常量池
这里我们重点看一下字符串常量池相关知识。
7.1. 字符串的创建
我们创建字符串的方式有下面两种:直接赋值和new创建
7.1.1. 直接赋值
直接赋值的方式,返回的是字符串常量池中的对象引用。我们先看下面的代码。
String a = "hello world";
在执行这一行代码的时候,Jvm会先去常量池判断是否存在相同对象,如果有,则直接返回常量池中的引用,否则需要在常量池中创建一个对象,在返回该对象的引用。
7.1.2. new创建
使用new方法创建会在堆中和字符串常量池(StringTable)创建对象,但是默认返回堆中对象的引用。
String a = new String("hello world");
此段代码执行的时候是这样的,Jvm会先去StringTable中查看是否存在字符串hello world,当不存在的时候会现在字符串常量池中创建一个字符串对象,再去堆中创建一个对象,否则仅在堆中创建对象;这里需要注意new方法创建的字符串都是返回的是堆对象的引用。
7.1.3. 实例
看下下面的例子:
String a = "hello";:“hello”可以在编译器可以确定,此时会先检测字符串常量池中是否存在,存在的话变量a指向已存在的“hello”的地址引用,否则会添加“hello”到字符串常量池中,并返回其地址引用;String b = new String("world");:使用new String创建,会将world存储到字符串常量池中,然后在堆中创建对象返回其堆对象地址的引用String c = "Like" + "Code";:使用字符串拼接,会直接存储“LikeCode”字符串在常量池中返回其地址引用;String d = a + "Tom";:使用字符串拼接(StringBuilder的append),因为a是一个引用,所已无法放入字符串常量池,但是“Tom”可以放入字符串常量池,最终d拿到的是StringBuilder之后的堆中对象的引用;String e = new String("Write") + "Article";:用new String拼接不能再编译期确定,但会将“Write”和“Article”两个字符串存入常量池中,并在堆中创建对象,但是字符串常量不会存放“WriteArticle”这个字符串,除非执行intern方法;String f = new String("Zhang") + new String("San");:用new String拼接不能再编译期确定,但会将“Zhang”和“San”两个字符串存入常量池中,并在堆中创建对象,但是字符串常量不会存放“ZhangSan”这个字符串,除非执行intern方法;
7.2. 字符串拼接
字符串拼接,在低版本的JDK中使用的是StringBuilder进行appand之后在toString,在JDK9之后的版本使用StringConcatFactory.makeConcatWithConstants。
String a = "hello ";
String b = "world";
String c = a + b; // StringBuidler的append方法
String d = a + "Java"; // StringBuidler的append方法
7.3. intern()方法
这个方法也很重要,存在于class文件中的常量池,被Jvm载入后,是可以进行扩充的,intern方法是为了在扩充常量池的一个方法。
当我们调用这个方法后,Jvm会查找常量池中是否有相同的字符串常量,有的话返回其引用,没有的话就将这个字符串对象的引用地址添加到字符串常量池中并返回。
7.3.1. 常量池中不存在字符串
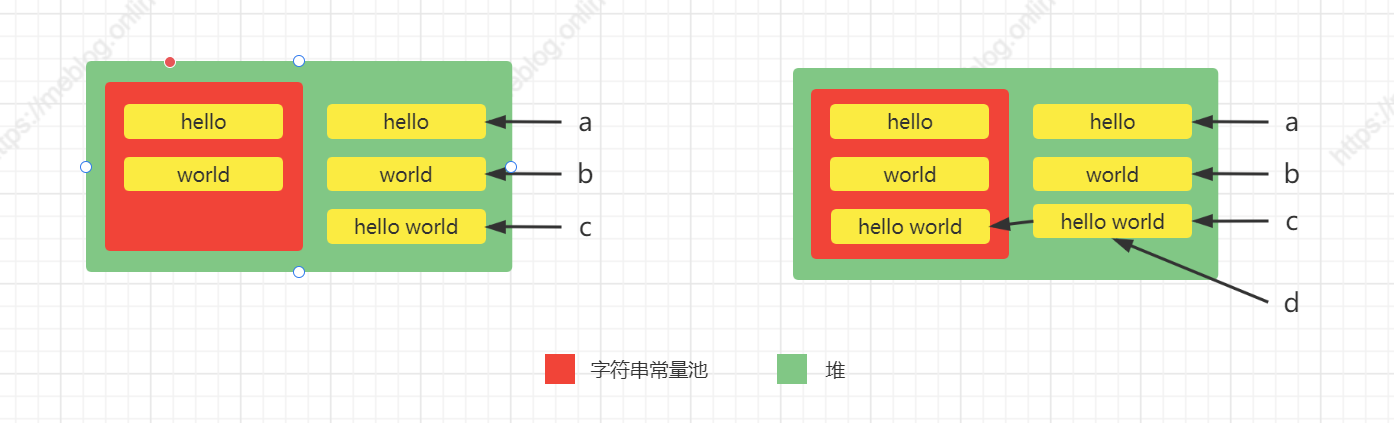
下面我们看个例子:
// 第一部分
String a = new String("hello ");
String b = new String("world");
String c = a + b
// 第二部分
String d = c.intern();
System.out.println(d == c); // true
System.out.println(d == "hello world"); // true
System.out.println(c == "hello world"); // true
步骤:
-
第一部分:
a和b两个变量都会在堆在创建对象,并将hello和world分别放到字符串常量池中;- 变量
c是使用StringBuidler的append方法将a和b变量字符串组合后new对象放入堆中,并返回堆中对象引用,但是因为a和b是字符串引用在编译期无法确定所以不会放入字符串常量池中;
-
第二部分:
- 这里使用
ntern方法,因为变量c在堆中hello world在字符串常量池中不存在,所以会将hello world放入常量池中,并返回堆中对象的引用,此时d和c指向的是同一个对象。 - 所以当
d变量和c变量比较的时候是true; d == "hello world"比较的时候,d变量指向的堆中c对象的引用,而常量池中的hello world也会返回c对象的引用,结果是true;c == "hello world"同上;
- 这里使用
内存结果如下:
7.3.2. 常量池中存在字符串
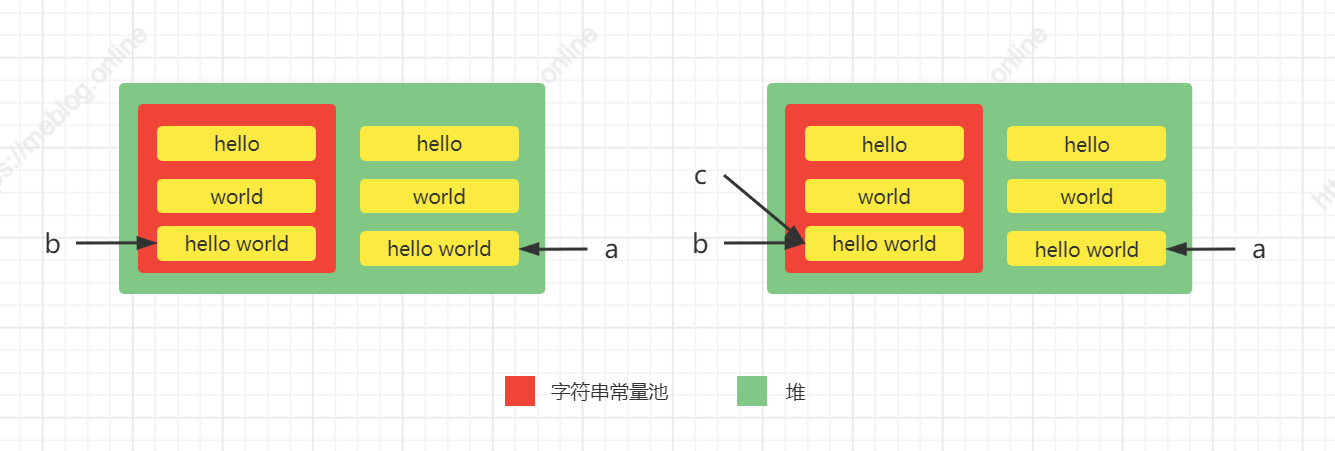
再看一个例子:
String a = new String("hello ") + new String("world");
String b = "hello world";
String c = a.intern();
System.out.println(a == b); // false
System.out.println(a == c); // false
System.out.println(c == b); // true
步骤:
new String("hello ")和new String("world")两个变量都会在堆在创建对象,并将hello和world分别放到字符串常量池中;变量a是使用StringBuidler的append方法将hello和world变量字符串组合后堆中创建对象并返回对象引用;- 变量
b是将hello world的放入字符串常量池中返回其在常量池中的引用 - 执行
a.intern()时,此时常量池中已经存在hello world了,这是返回的是常量池中hello world的引用; a == b此时变量a持有的是堆中对象的引用,变量b持有的字符串常量池中引用,所有a != b;a == c此时变量c持有的是字符串常量池中hello world的引用,所以a != c;c == b原理如上;
内存结果如下:
7.4. 垃圾回收
字符串常量池也是可以被回收的,下面我们通过一些参数配置观察一下!
| 参数 | 注释 |
|---|---|
-Xmx10m | 堆空间大小 |
-XX:+PrintStringTableStatistics | 打印串池统计信息 |
-XX:+PrintGCDetails | 打印GC日志详情 |
-verbose:gc | 打印GC日志 |
完整参数:-Xmx10m -XX:+PrintStringTableStatistics -XX:+PrintGCDetails -verbose:gc

示例代码:
public class Example {
public static void main(String[] args) {
String name = "hello world";
System.out.println(name);
}
}
运行之后输出的串池统计结果如下:
StringTable statistics:
Number of buckets : 60013 = 480104 bytes, avg 8.000
Number of entries : 1690 = 40560 bytes, avg 24.000
Number of literals : 1690 = 152448 bytes, avg 90.206
Total footprint : = 673112 bytes
接着循环往串池中写入字符串:
public class Example {
public static void main(String[] args) {
for (int i = 0; i < 3000; i++) {
new String("hello world" + i).intern();
}
}
}
此时会发生GC,串池中的字符个数减少:
[GC (Allocation Failure) [PSYoungGen: 2048K->488K(2560K)] 2048K->736K(9728K), 0.0007925 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
...
StringTable statistics:
Number of buckets : 60013 = 480104 bytes, avg 8.000
Number of entries : 2145 = 51480 bytes, avg 24.000
Number of literals : 2145 = 184960 bytes, avg 86.228
Total footprint : = 716544 bytes
Average bucket size : 0.036
Variance of bucket size : 0.036
Std. dev. of bucket size: 0.191
Maximum bucket size : 3
7.5. 调优处理
字串常量池是使用HashTable实现的(无法扩容),数据结构是数组+链表实现的。字符串hash值是key,地址是value,数组数量少(也可以说桶数量少),hash碰撞次数会增加,碰撞之后会使用链表处理hash冲突。Jvm中桶最小是1009,默认是60013。这里我们可以使用-XX:StringTableSize=1009进行配置。
可以到我另一篇文章中看哈希表:https://blog.csdn.net/yhflyl/article/details/121245579
下一篇见!

![[发送AT指令配置a7670C模块上网]](https://img-blog.csdnimg.cn/b17882066b34406d933745ba4929b626.png)