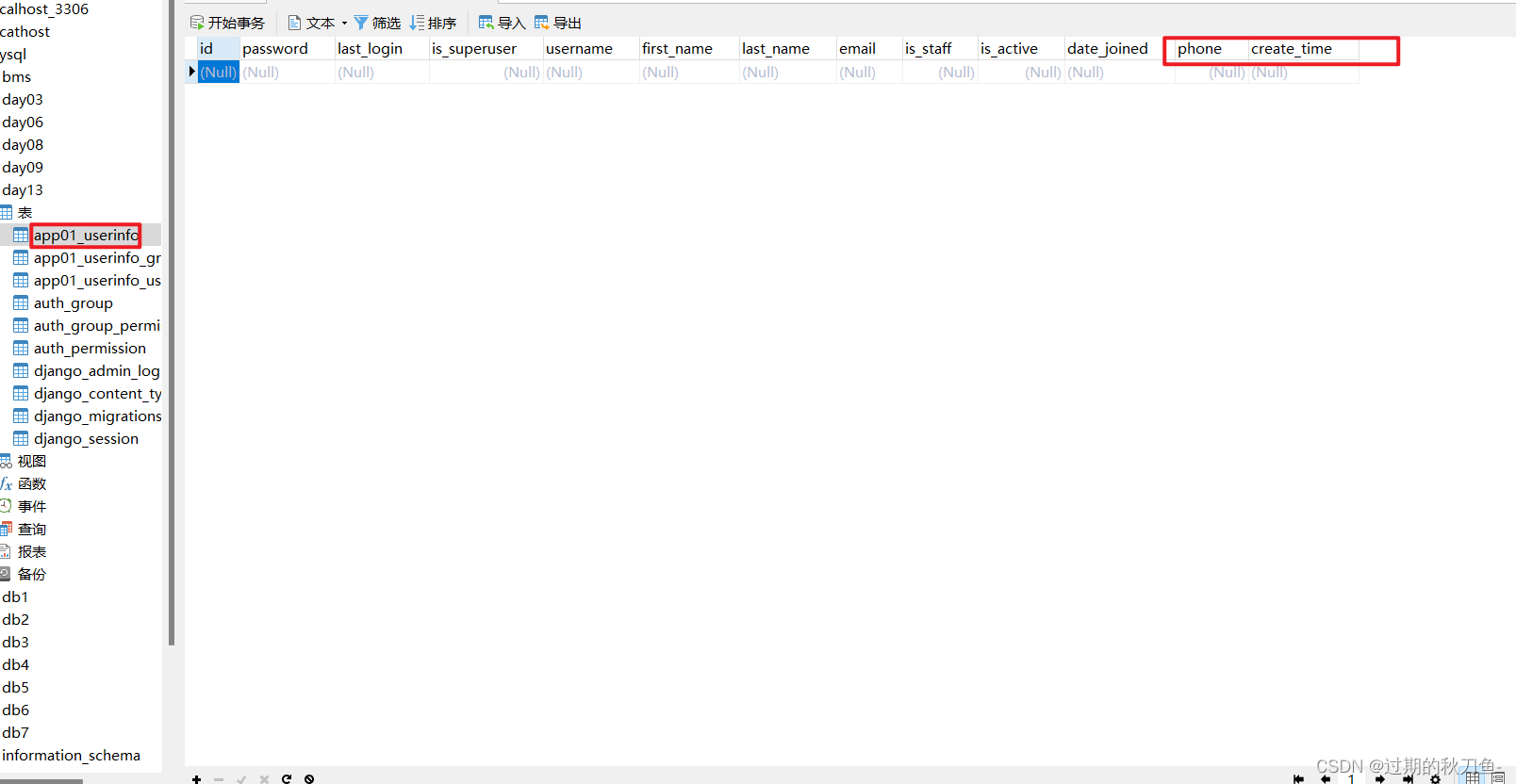
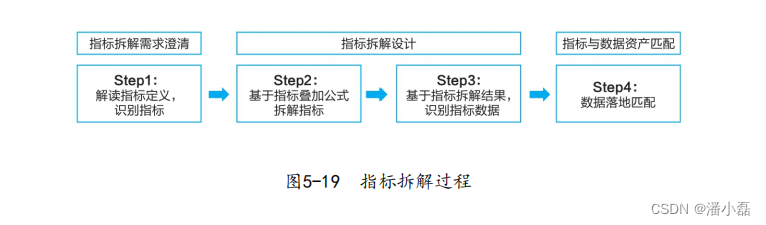
DL_class
学堂在线《深度学习》实验课代码+报告(其中实验1和实验6有配套PPT),授课老师为胡晓林老师。课程链接:https://www.xuetangx.com/training/DP080910033751/619488?channel=i.area.manual_search。
持续更新中。
所有代码为作者所写,并非最后的“标准答案”,只有实验6被扣了1分,其余皆是满分。仓库链接:https://github.com/W-caner/DL_classs。 此外,欢迎关注我的CSDN:https://blog.csdn.net/Can__er?type=blog。
部分数据集由于过大无法上传,我会在博客中给出下载链接。如果对代码有疑问,有更好的思路等,也非常欢迎在评论区与我交流~
实验4:脑部 MRI 图像分割
跑通程序
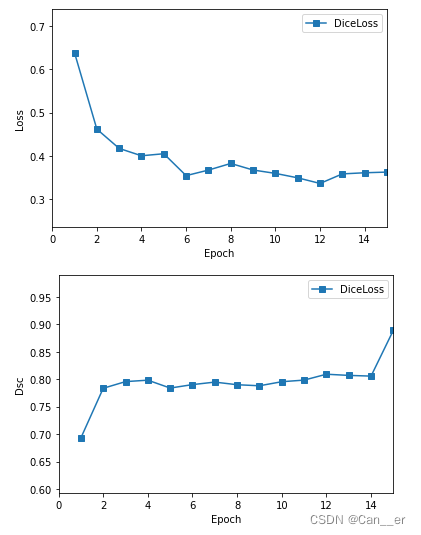
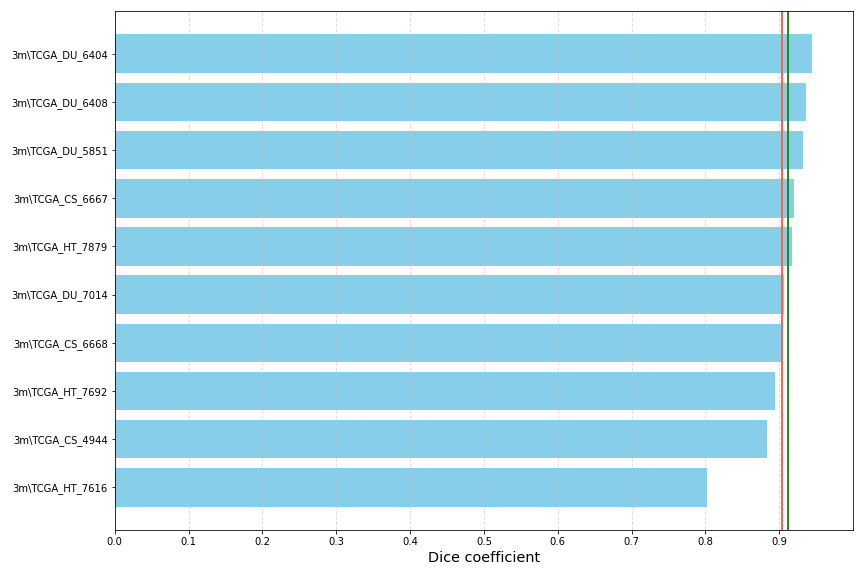
使用原始程序简单训练了15个周期,绘制loss曲线和Dsc,然后进行预测,dice coefficient约为0.9,如下图所示:
效果提升
网络结构
我没有做出大的改变,在阅读文献的时候看到了一个UNet++,但没有实现成功。
损失函数
这里尝试了2种额外的损失函数:
-
第一个是增加了权重的交叉熵损失函数FocalLoss,为了解决“正负样本”或者“优劣样本”不均衡问题。代码为:
class FocalLoss(nn.Module): def __init__(self, weight=None, reduction='mean', gamma=0.25, eps=1e-7): super(FocalLoss, self).__init__() self.gamma = gamma self.eps = eps self.ce = nn.CrossEntropyLoss(weight=weight, reduction=reduction) def forward(self, y_pred, y_true): logp = self.ce(y_pred, torch.squeeze(y_true).long()) p = torch.exp(-logp) loss = (1 - p) ** self.gamma * logp return torch.Tensor(loss.mean())下图为比较结果,可以发现交叉熵在此处并没有比较好的表现,无论是收敛速度还是训练了15个周期的最终结果,所以舍弃。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XJ8wFC1z-1668653063845)(.\image-20220714194301321.png)]
-
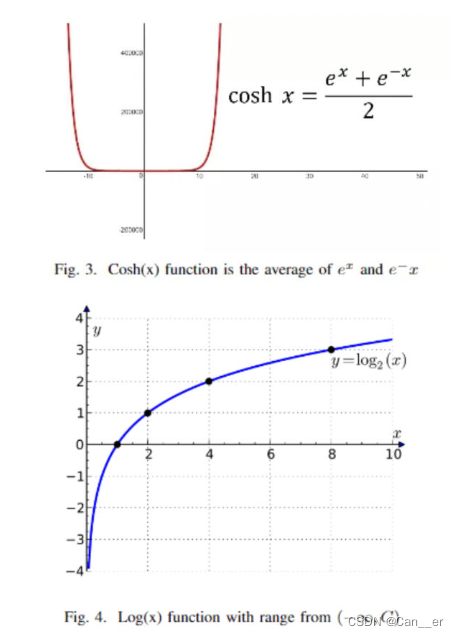
第二个是改进后的DiceLoss,参照了图像分割模型调优技巧,loss函数大盘点 - 知乎 (zhihu.com)一文中提出的损失函数。Dice系数是一种用于评估分割输出的度量标准。它也已修改为损失函数,因为它可以实现分割目标的数学表示。但是由于其非凸性,它多次都无法获得最佳结果。Lovsz-softmax损失旨在通过添加使用Lovsz扩展的平滑来解决非凸损失函数的问题。同时,Log-Cosh方法已广泛用于基于回归的问题中,以平滑曲线。作者将损失函数的公式改为
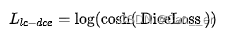 ,其中用到的函数示意图如下。
,其中用到的函数示意图如下。
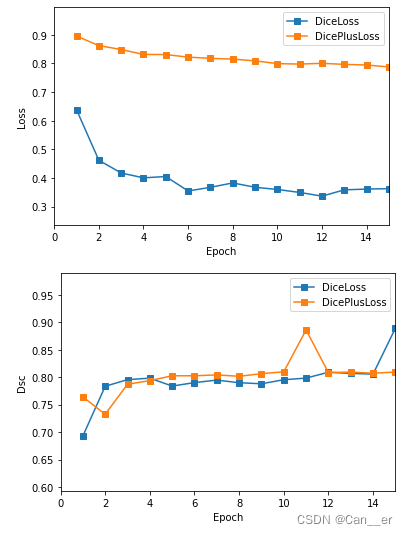
下图是对比未经过改进的损失函数和改进后的Loss与Dsc,可以发现Loss因为计算公式不同而存在差异,但改进和的Dsc有着较好的表现。最终也选择其作为损失函数。
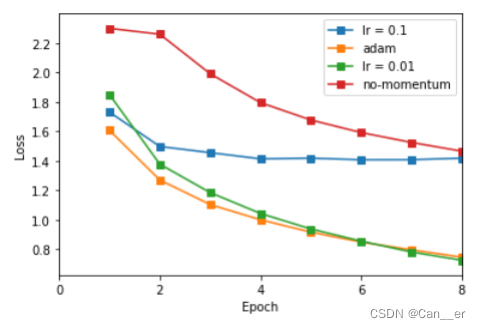
优化器
分别采用不含动量的优化器SGD,含动量(0.9)的优化器SGD,设置学习率为0.01至0.001,得到Loss结果如下,可以发现含动量的SGD比不含动量SGD有着更好表现,而adam有着最好的表现。这里我的标签打错了,lr的值应该是0.01和0.001。
最终效果
最后采用网络结构没有改变,损失函数为改进后的DiceLoss,学习率从0.01开始,每周期进行0.9的衰减,训练30个周期,得到的平均DSC为0.92。
此时应用该训练参数于训练集,发现6668出现了异常现象,但是平均效果得到了一点提高,还有明显的可优化情况。
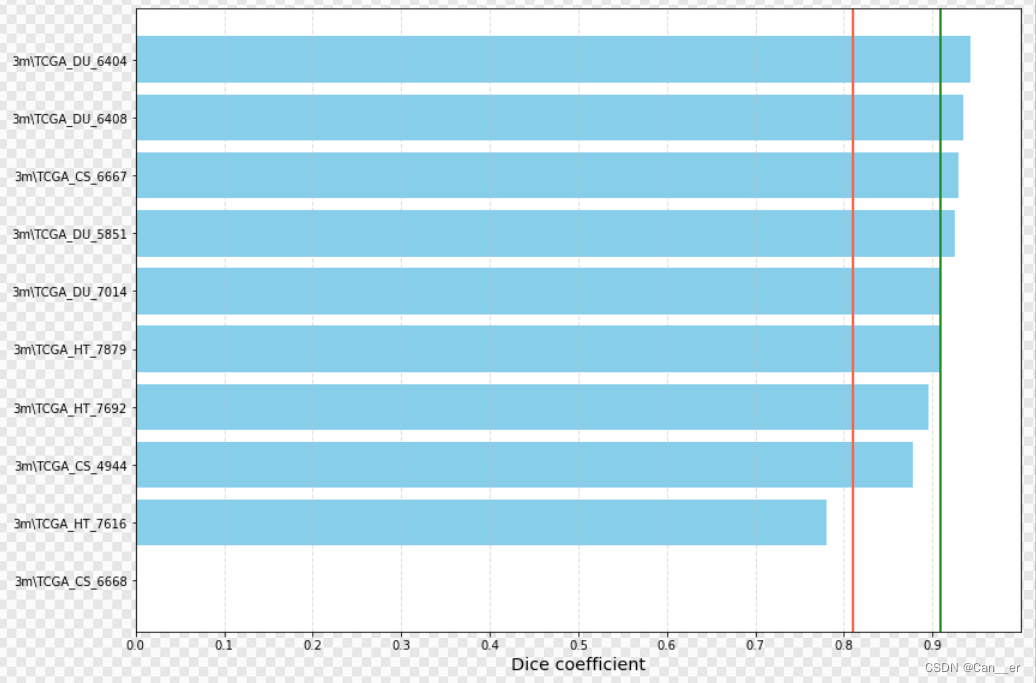
下面是截取的部分预测和真实情况示意图:
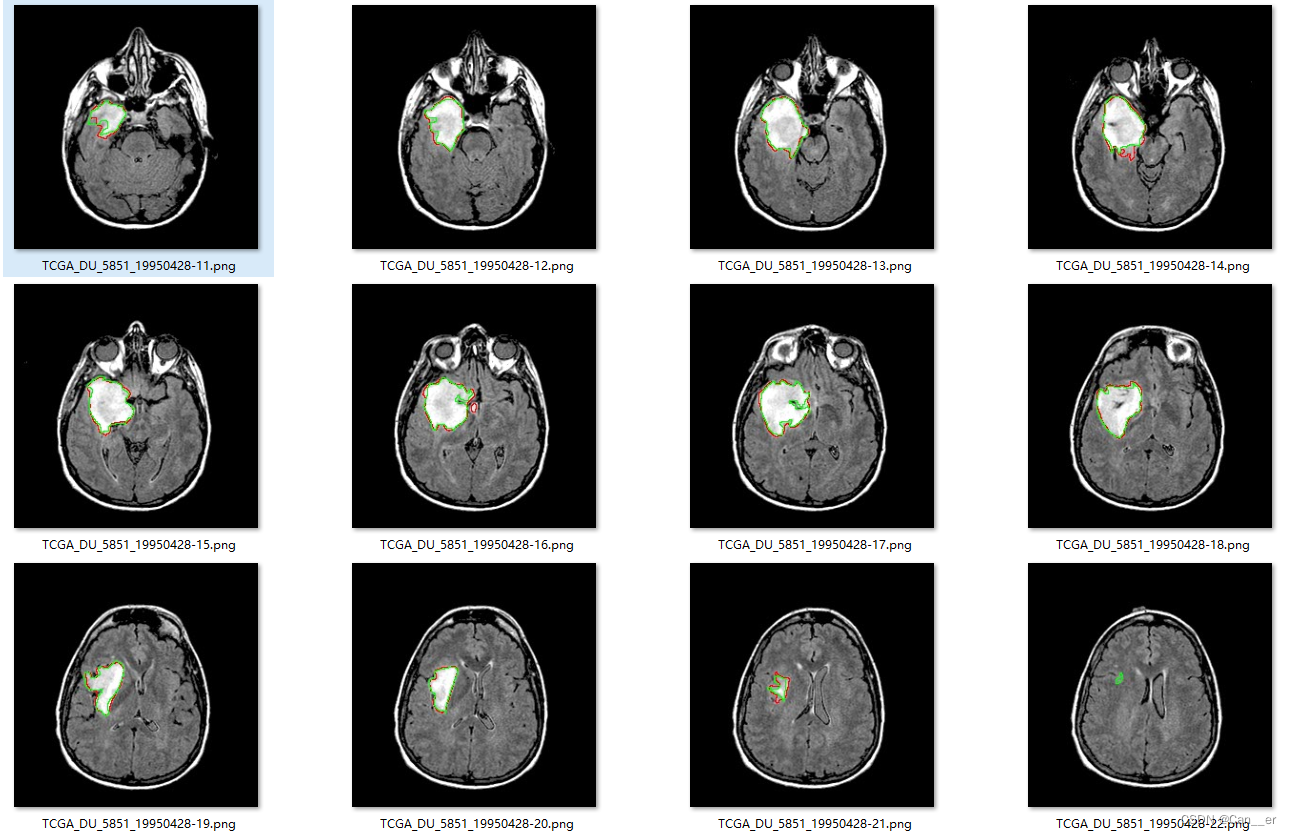
![[发送AT指令配置a7670C模块上网]](https://img-blog.csdnimg.cn/b17882066b34406d933745ba4929b626.png)