来源:投稿 作者:小灰灰
编辑:学姐
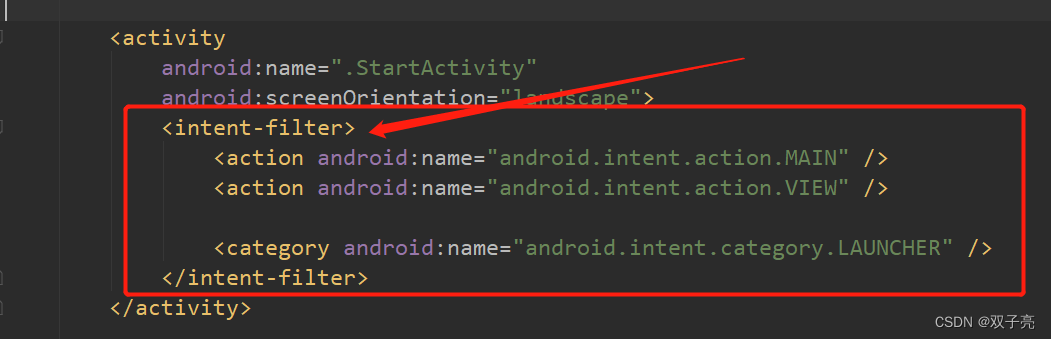
PCA主成分分析算法
PCA的使用范围
PCA(principal Component Analysis),即主成分分析方法,是一种使用最广泛的数据压缩算法。
在PCA中,数据从原来的坐标系转换到新的坐标系,由数据本身决定。
使用的用途很广,在人脸识别中(EigenFace,deepid),三维人脸重建中的(3DMM模型),想用数据降维时,通过PCA降维可以发现更便于人类理解的特征;同时也可以用于去燥等等。
问题

假设有一张图片是128*128 大小的图片,那我们就可以当成n=128*128, 也就是将矩阵拉成一维的,也就是X是一批数据组成的集合,那么PCA就是通过每一个点刻画这样一种分布,因为原本的X是复杂的。那么就需要找到一个主向量。
2.1 先计算协方差的特征值和特征向量
我们有40个人,每个人10张图片,也就是总共400张图片。图片大小为112*92。
现在我们要对这400张图片进行求特征值与特征向量。

img_list = []
for i in range(1,41):
for j in range(1,11):
file = "ORL/s%d/%d.bmp" % (i,j)
img = cv2.imread(file,cv2.IMREAD_GRAYSCALE)
img = img.astype(np.float32)/255.0
img_list.append(img)
imgs = np.zeros([400,10304],dtype=np.float32)
这是从ORL中读取数据。
for i in range(0,400):
imgs[i,:] = img_list[i].reshape(92*112)
plt.imshow(imgs) # 显示图片
plt.show()
plt.savefig('lena_new_sz.png')
然后将这些数据保存到lena_new_sz.png文件中。

imgs = np.zeros([400,10304],dtype=np.float32)
for i in range(0,400):
imgs[i,:] = img_list[i].reshape(-1)
# plt.imshow(imgs) # 显示图片
# plt.show()
# plt.savefig('lena_new_sz.png')
imgs_mean = imgs.sum(axis=0)/400.0 #求平均值
np.savetxt('mean.txt',imgs_mean,fmt="%.5f")
imgs_mean就是平均脸

我们将这个平均脸显示出来是:

进行均值归一化。
imgs = imgs - imgs_mean
#conv = imgs.transpose(1,0).dot(imgs)计算协方差矩阵,就是conv
conv = imgs.dot(imgs.transpose(1,0))
print(conv.shape)#(10304, 10304)对协方差矩阵求特征值eig_value,特征向量eig_vector
eig_value,eig_vector = np.linalg.eig(conv)
print(eig_value.shape,eig_vector.shape)#(10304,) (10304, 10304)算完之后,转完32的浮点数,保存文本和二进数。
eig_value = eig_value.astype(np.float32)
eig_vector = eig_vector.astype(np.float32)
eig_vector = imgs.transpose(1,0).dot(eig_vector)
np.savetxt('eig_vetor400.txt',eig_vector,fmt="%.5f")
np.savetxt('eig_value400.txt',eig_value,fmt="%.5f")
eig_vector.tofile('eig_vector400.bin')
特征向量

特征值
2.2 重构出人脸
通过评价脸,特征值,和特征向量将图片显示出来
imgs_mean = np.loadtxt('mean.txt')
eig_vector = np.fromfile('eig_vector.bin',dtype = np.float32)
eig_vector = eig_vector.reshape(10304,-1)
u = eig_vector[:,:256]
for i in range(0,256):
face = u[:,i] + imgs_mean
face = face * 255
face[face<0] = 0
face[face>255]=255
face = face.astype(np.uint8).reshape(112,-1)
cv2.imwrite('eigface/%s.bmp'%i,face)
可得出,我们取出了前256个特征。显示出这些的特征脸。

我们将上面的特征脸重构出人脸。
for i in range(1,41):
for j in range(1,11):
file = "ORL/s%d/%d.bmp" % (i,j)
img = cv2.imread(file,cv2.IMREAD_GRAYSCALE)
img = img.astype(np.float32)/255.0
img = img.reshape(-1)
img = img - imgs_mean
prj = img.dot(u)
np.savetxt('features/%s_%s.txt'%(i,j),prj,fmt="%.5f")
cons = u.dot(prj)
cons = cons + imgs_mean
cons = cons*255
cons[cons<0]=0
cons[cons>255]=255
cons = cons.astype(np.uint8).reshape(112,-1)
cv2.imwrite('construct/%s_%s.bmp'%(i,j),cons)

重构出来的图片

相对应于原始的人脸
因为我们取了256个特征值,如果是400,那么将会更接近于原始图片。
机器学习干货+论文资料👇点击卡片关注获取