计算机下围棋的问题描述请见上篇:机器学习:手撕 AlphaGo(一)-CSDN博客
3. MCTS 算法介绍
MCTS(Monte Carlo Tree Search) 算法的中文名称叫做蒙特卡洛树搜 索。第一次接触这个算法时,便惊叹于它精巧的设计。而且这个算法在 AlphaGo 的设计中,有着不可替代的作用。图 3-7 是 MCTS 算法的常见迭代图,分为 selection,expansion,simulation,backpropagation 四个部分,我们这节讲这幅图里的故事。
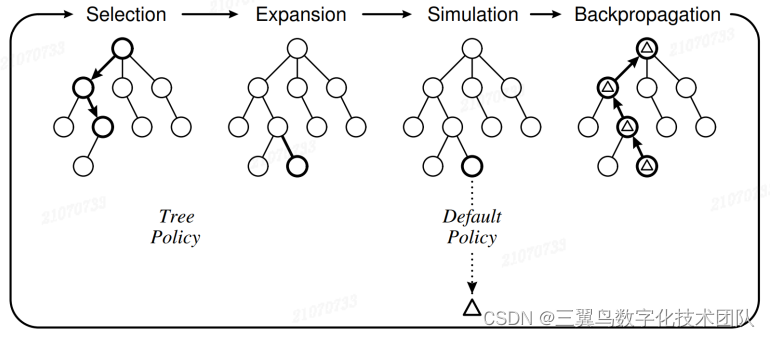
图 3-7: MCTS 概览
3.1 深度有限的 v(s) 估计
它的思想: 根据小节 2.3.4 介绍的求解 的方法,在计算节点 s 的值
时,只向下考虑探索固定深度 d 层的节点,如果探索的最深节点 s 不 是叶子节点 (即不能判断出胜负),则通过人工设计的评估函数
来估计 节点 s 的值
。评估函数
的设计很讲究技巧,一般会抽取一个状态 s 的明显特征。但在早期人工设计出来的评估函数
和真实的值函数
会差距很大。我们知道在小节 2.3.4 介绍的最优的 search 策略是在节点真实 值函数
下得到, 如果评估函数
和真实函数
差距很大,那么在 深度有限的策略下,进行围棋 Tree 的搜索,将不能保证搜索结果的全局最优,结果可能会很差。
在该想法实际执行时,黑子和白子都通过摇色子(均匀分布)的方式选择子节点进行探索,所以输出的子节点完全是随机的。然后每个节点的值函数 是子节点值函数
的期望:

与之对比,在精确求解值函数 时,按照黑子取极大值,白子取极小值方式,这里取而代之用所有子节点值的期望方式。参考图 3-8 感受下具体的计算方式。
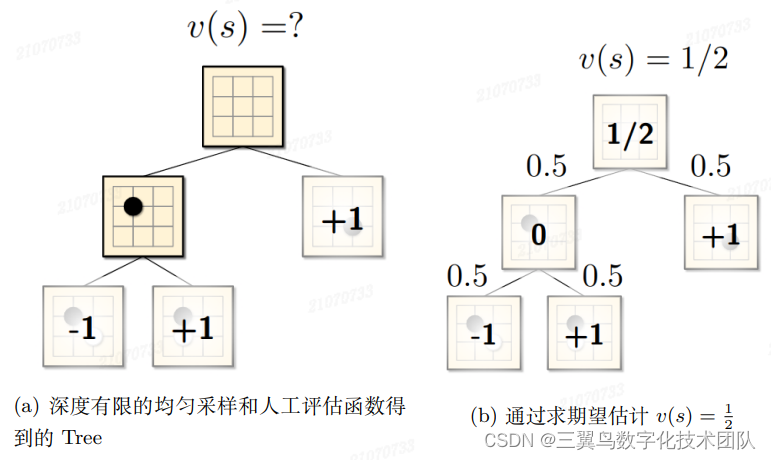
图 3-8: 通过均匀采样估计节点 s 的值
这种方式的优点,减少了搜索的深度,降低了计算的节点数,使 Tree search 的思想可以应用到围棋上。但这种近似方法有个严重的不足: 估算的 节点值函数 与真实的值函数
的计算方式不同,值相差很远,或者说二者没有关系,同理参照
值,在 Tree 上搜索时,得到的节点也 不是最优策略。MCTS 算法在继承它“减少搜索深度”思想的基础上,使估 计的值
与真实的
更接近。接下来我们看看这个算法如何做到的。
3.2 MCTS: Selection
完整的围棋 Tree 很大,被我们计算的节点只有一部分。所以把我们计 算过的节点组成的 Tree, 叫做“已知 Tree”。selection 就是针对“已知 Tree” 上的节点进行搜索,比如当前棋局盘面处于节点 s,而且 s 是“已知 Tree” 的一个节点,那么对于黑子来说下一步的行棋动作可以在 s 的子节点中选 一个值 最大的节点对应的位置。
![]()
同理对于白子来说,下一步的行棋动作可以在 s 的子节点中选一个值 最小的节点对应的位置:
![]()
这是正常的围棋 Tree 的搜索过程,完全利用 (exploration)“已知 Tree”的信息。对于一颗完整的围棋 Tree 这个方法没问题,对于一颗只有完整围棋 Tree 局部的“已知 Tree”来说,为了发现更好的解,还需要引入探索(exploitation) 的能力,即适当的时候,选择一些非 极大或者极小的节点。ϵ − greedy 可以很好的平衡 search 过程中的利用和探索:
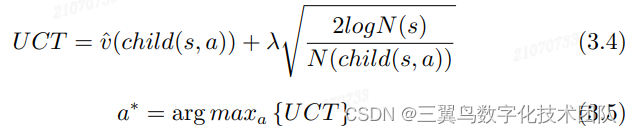
式 3.4 中 是 MCTS 中估计出来的节点值,用来近似围棋 Tree 中真正的值 v,
表示节点 s 被搜索到的次数,在一局(多局)对弈中节点 s 可能被搜 索多次,
表示在节点 s 下采取 a 动作对应的子节点被访问的 次数,λ 是一个实数平衡利用和探索之间的权重关系。当一个节点 s 被访问 的次数
很多,但它的某个子节点
访问次数很小,则更 容易选择这个访问次数小的子节点,从而达到探索未走过路径的目的。其实 这里也暗含一个假设:
越大的节点是好节点,好节点的所有子节点中,访问次数小的子节点可能也是一个好节点,所以要探索。
选择下一步的落子动作 常见的有两种策略。一种如式 3.5 在所有子节 点中选择最大 UCT 对应的动作; 另外一种方式如式 3.6 按照 UCT 权重对应 的分布采样一个新动作 a:
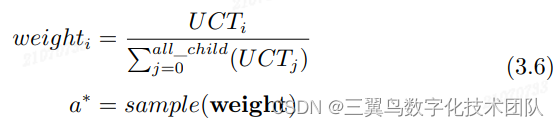
图 3-9 是 selection 的两个示例,用于加深理解。
3.3 MCTS: Expansion
“已知 Tree”最开始为空,然后在 MCTS 算法中长成一颗大 Tree, 那么 它是如何进行节点的分裂长成大 Tree 的呢?如果将“已知 Tree”上的所有 节点分类,可以分为 3 类:
-
a 类: 节点 s 在“已知 Tree”中,而且它所有子节点也在“已知 Tree” 中;
-
b 类: 节点 s 在“已知 Tree”中,而且它部分子节点在“已知 Tree”中, 存在一些子节点不在“已知 Tree”中;
-
c 类: 节点 s 在“已知 Tree”中,但它所有子节点都不在“已知 Tree” 中,c 类节点也是“已知 Tree”的叶子节点;
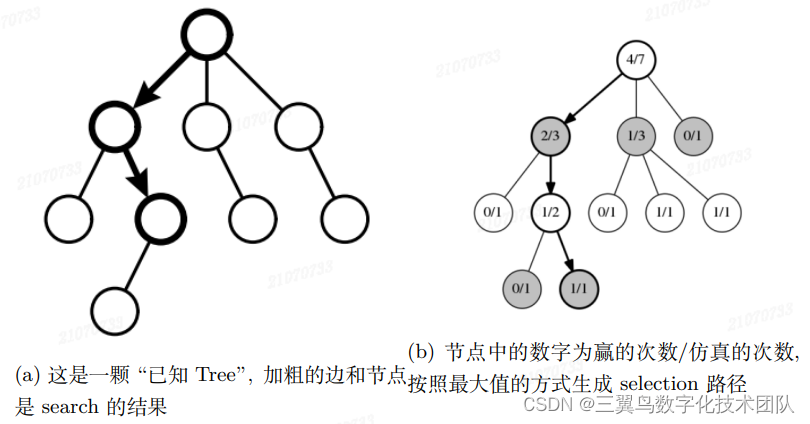
图 3-9: 图 3-7 对应的子图与一个 search 例子
在一棵“已知 Tree”上 search,如果遇到 a 类节点 s,已经不能为“已知 Tree”添加新的节点,只能继续按照公式 3.4 search 下一个动作。如果 search 到 b 类节点,随机选一个未在“已知 Tree”中的子节点作为新的叶子节点。 如果 search 到 c 类节点,与 b 类节点一样,随机选一个子节点加入到“已 知 Tree”中。我们可以确定“已知 Tree”新 Expansion 进来的子节点,均 是“已知 Tree”的叶子节点,而且新节点的选择方式除了随机添加外,也可 以设置其他策略,这里我们就不过多描述了。图 3-10 是 Expansion 的一个示 例, 帮助我们进一步理解。但“已知 Tree”的 b 类和 c 类节点 s 未必是完 整围棋 Tree 的叶子节点,即对弈还没有结束,那么这时该如何操作,才能估计新 Expansion 的叶子节点的值 ,进而输出下一步棋的位置呢?
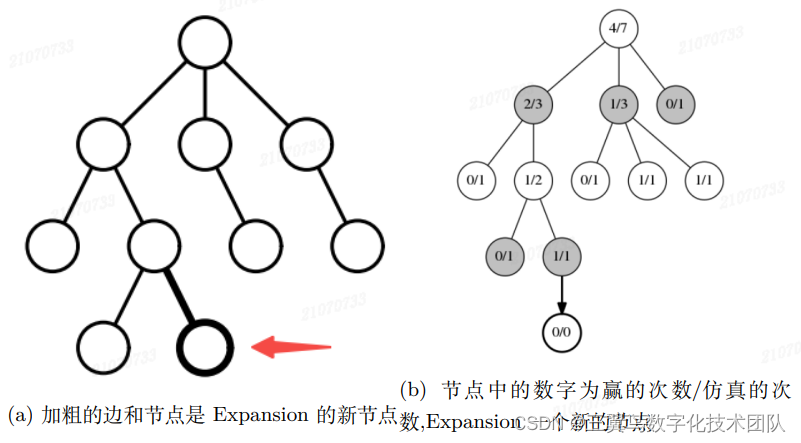
图 3-10: 图 3-7 对应的子图与一个 Expansion 例子
3.4 MCTS: Simulation
有的文献将这步也称作 Evaluation(评估)。Simulation 是从 Expansion 的新节点开始走到完整 Tree 的叶子节点 (游戏的终点) 的过程,从而达到快 速评估新节点值的目的,这个过程也叫做仿真。具体过程从 Expansion 的新 节点 s 开始,通过扔一个质地均匀的多面体骰子选择动作 a,从而得到下一 个子节点 ,不断地重复这个过程,直到走到完整 Tree 的叶子节 点,到达游戏的终点,记录游戏结果,完成一次仿真。像这种从 Expansion 的节点到完整 Tree 的叶子节点的仿真路径,需要大量生成。通过对仿真路 径的统计,计算 Expansion 新节点 s 的值
,常见的统计 Expansion 节点值的方法是: 计算仿真数据中赢的概率:

仿真数据越多,优点是 Expansion 的新节点估算的值 和节点的真实值
越接近,
是
的无偏估计,这由 Monte Carlo 采样定理保证。 这同时也解决章节 3.1 中手工评估函数的设计不足引入的缺点。但仿真数据 做的越多,中间消耗的计算资源、存储资源和时间资源等也越多,所以在 单步选择子节点时,策略越简单越好,比如这里介绍的“扔质地均匀的骰 子”是一种常用的简单策略。所以因为资源受限的问题,估计结果
不能无限逼近真实值
,估计结果的准确性和计算资源之间需要做一次权衡。图 3-11 是 Simulation 的一个示例, 帮助我们进一步理解。
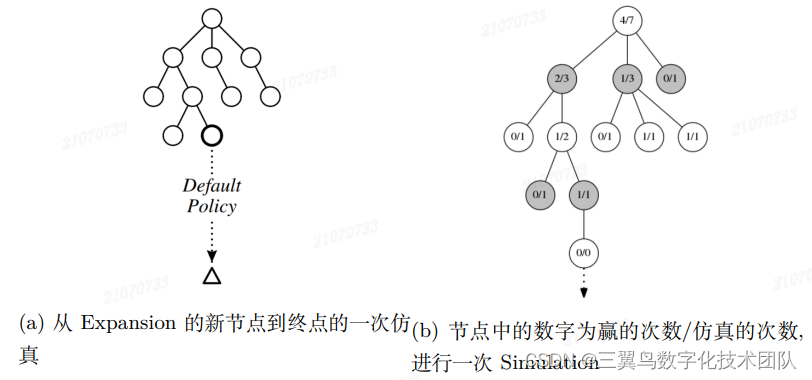
图 3-11: 图 3-7 对应的子图与一个 Simulation 的例子
3.5 MCTS: BackPropagation
对 Expansion 节点 s 的仿真,也等于间接对中 s 到 root 节点的 path(唯 一的一条节点路径) 上所有节点的仿真,所以在通过仿真的方式获取节点 s 的估计值 后,对 path 上其他节点也要做相应的值更新, 这就是 BackPropagation(值的回传)。BackPropagation 可以充分有效的利用每次仿真,使节点估计值
更加近似节点真实值
。

图 3-12: 图 3-7 对应的子图与一个 Back-Propagationn 的例子
具体更新过程如图 3-12b 所示,从扩展(Expansion)节点 s 到 root 节点 只有一条 path, 路径上所有节点的仿真总数 +1,即分母 +1。这是一颗游戏 Tree, 有黑白两种节点交替出现在不同层,图中的 Expansion 节点为白色,且仿真时,白色节点赢了,所以对于到 root 节点的 path 中,白色节点的分子 +1,黑色节点分子保持不变。
3.6 MCTS 算法用在围棋上的局限
对比章节 3.1 深度有限的估计方法和 MCTS 算法,我们应该明白 MCTS 算法如何在“减少搜索深度”的基础上,将节点 s 估计值 变为真实值 v 的 一个无偏估计。那么这个算法是完美的么?不完美。这个算法大量的计算和 时间花费在 Simulation 这一步,对于像围棋这种有时间限制的游戏,会严重 影响 MCTS 的输出效果。所以接下来的问题: 在围棋比赛中,选手思考时间 有限的情况下,如何修改 MCTS 算法,使它可以输出更好的解?DeepMind 团队给出的答案:用比赛前学习的方法来降低比赛中 Simulation 的依赖。
4. AlphaGo 算法介绍
根据章节 3.6 的局限分析,我们来看看 AlphaGo 是如何利用比赛前学习 的方法,使其降低对 Simulation 的依赖。回顾 MCTS 的过程,有两个关键的操作,一个是下一个动作 a 的选择, 另外一个是通过 Simulation 估计当前围棋状态的值。在 AlphaGo 中,通过一个 Policy Network 计算下一个动作 a 的分布,即输入一个节点状态 s,输出 。使用一个 Value Network 计算一个节点 s 的评估
,即当前这个盘面胜的概率。Policy Network 与 Value Network 均可以通过历史围棋对弈数据集进行学习。然后再结合 MCTS,从 而诞生打败李世石的 AlphaGo。
4.1 Policy Network 与 Value Network 的故事
在 2015 年左右,CNN,resnet 等可以提取到很好的图片特征,对图片 识别的效果有很大的进步,自然而然,是否可以训练一个网络下围棋呢?如 我们在章节 2.3 介绍,计算机下围棋主要有两个挑战,一个挑战是完整“围棋 Tree”太大,另一个挑战是很难判断一个围棋局面 (节点状态 s) 的好坏。最 初的想法希望直接训练两个神经网络 Policy Network 和 Value Network,输入都是局面状态 s,Policy Network 输出是下一步的落子位置 和 Value Network 输出是对 s 的评估结果,是一个实数。采用 KGS 专业五段以上棋 手的对弈记录作为数据集,大约有 16 万场带有胜负结果的对弈,约有 3000 万落子步骤
。
4.1.1 Policy Network 的故事
针对 Policy Network,最开始采用监督学习的思想, 预测下一步的落子位置,用最大似然(likelihood)和 SGD 的方法训练。使用 3000 万的落子数据对 作为训练数据,损失函数用 negtive log likelihood loss:
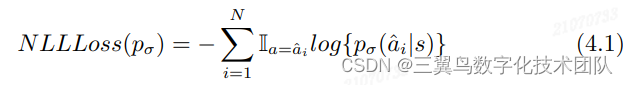
分别训练一个大的 12 层 CNN 模型 和一个小的线性逻辑回归模型
, 如图 4-13。
在实际训练时,手工从围棋盘面
中抽取 48 种特征,输入 CNN 网路,并且在在 50 块 GPU 上训练了 4 周左右,最终在达到 57% 的 精确度,比当时 state-of-art 44% 好很多。
在测试集的精度只有 24% , 但 它的优点是执行速度快,在 2us 内输出一步落子的位置,这个输出速度很快,比如我们要仿真 1 万局对弈,平均每局对弈 100 步,总体仿真时间只 需 2s。相对于大模型
,小模型
很适合做仿真采样, 而且
策略会比均匀随机采样好很多。
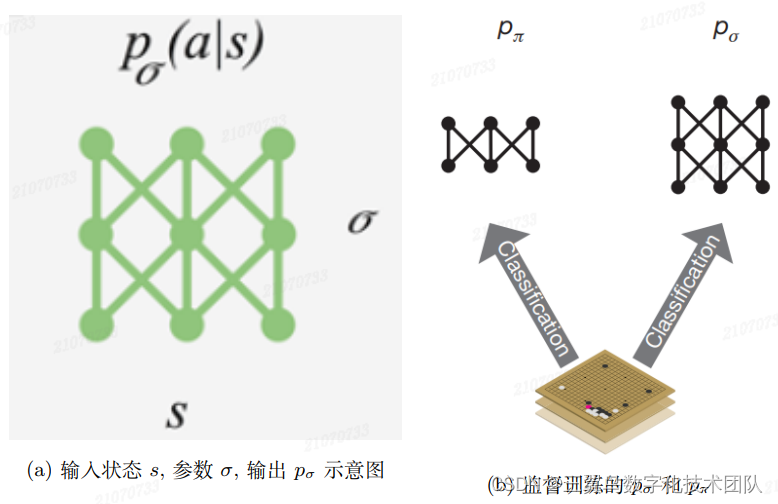
图 4-13: 监督训练 policy network
但监督学习的 Policy Network 并不完美,这会严重影响模型的围棋能力,模型两个明显的不足:
-
训练数据量小,虽然有 3000 万个数据对
,但只有 16 万场的对弈数据,这不足以训练一个大的神经网络;
-
围棋对弈是一个序列决策过程
,
和
不能提取序列决策的前后特征信息;
为了解决数据少的问题,用第一个监督学习的 进行自对弈,可以产生大量新的对弈棋局,从而解决数据不足的问题。强化学习学习中的 policy gradient(策略梯度) 可以很好的学习序列决策的任务。用监督学习得到的 CNN 模型
作为初始化参数,采用 policy gradient 的方法,在大量的数 据上训练,于是便产生了强化学习版的 Policy Network
,
的损失函数如下:
![]()
其中 是一场对弈结果;
是一场对弈数据,
是网络待学习参数。关于 policy gradient 更详细的介绍,大家可以查看其他同学的博客,这里我们先 理解 AlphaGo 的设计思路。强化学习训练的
与监督学习得到的
对弈时,有 80% 概率获胜,大约达到业余三段的水平。
4.1.2 Value Network 的故事
Value Network 是为了评估一个围棋上状态 s 的好坏,即输出黑子 (或者白子) 胜的概率。为了学习到更准确的 Value Network,采用强化学习训练的 进行自对弈,大约自对弈了 3000 万场,从每场对弈中随机抽取一 个状态
作为输入,对弈结果
为 label,采用 12 层的 CNN 作为模型的 主体结构,损失函数为 MSE:

50 个 GPU 训练 1 周,得到有史以来第一个准确的围棋状态评估函数 , 这在当时是不能想象的。但盘面评估函数 Value Network 怎么用呢?
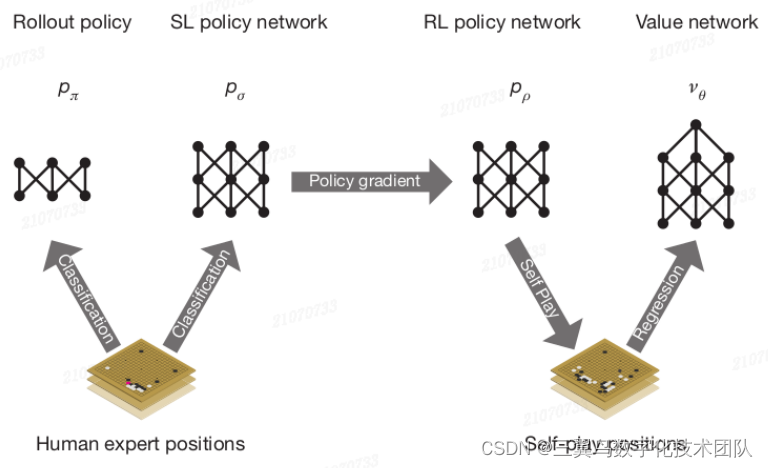
图 4-14: 从监督的 Policy Network 和
到 RL 版 Policy Network, 然后 再到 Value Network
的过程
到这里 Policy Network 与 Value Network 的故事讲完了,如图 4-14。但即使 RL 得到的 Policy Network 也只是业余 3 段的水平,还不足以打败专业选手。那么再此基础上 DeepMind 做了哪些操作,使 AlphaGo 的效果得到巨大的提升,从而击败人类呢?答案是在 Policy Network 与 Value Network 基础上,再结合 MCTS 的方法,便达到击败人类的水平。那么 Policy Network 与 Value Network 具体与 MCTS 怎么结合呢?带着么个问题,我们继续看下面的故事。
4.2 AlphaGo 中的 MCTS 的故事
如我们在章节 3 介绍,MCTS 算法会把大量的时间花费在 Simulation 上,从而在思考时间有限的围棋对弈中影响算法的输出效果。为了在有限的时 间内提升围棋的思考效果,我们需要提升 Monte Carlo 采样的效果,达到在有限的时间内使估计的节点值更准确,而且还要降低搜索的宽度,更合理的 “探索利用权衡”的设计等,如图 4-15。我们看看在 Policy Network 和 Value Network 的帮助下,如何解决 MCTS 思考时间有限的问题。
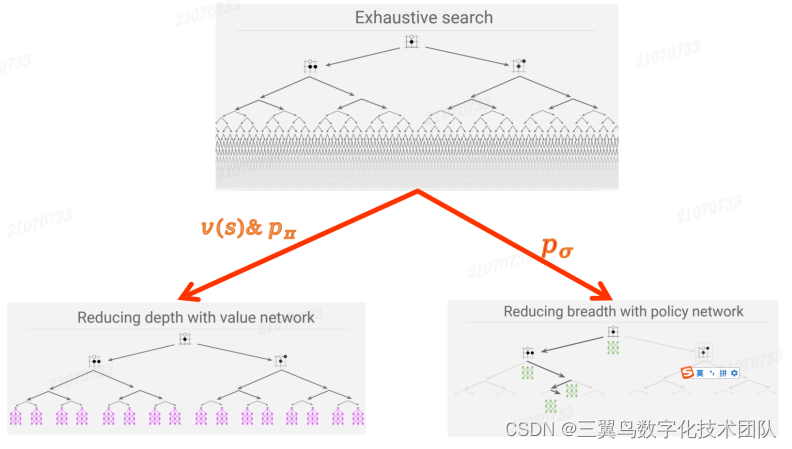
图 4-15: AlphaGo = MCTS + Policy Network + Value Network
Selection: 与原 MCST 相比,修改了动作选择式 3.4 和式 3.5 的计算方法, 具体选择下棋动作 的方式:
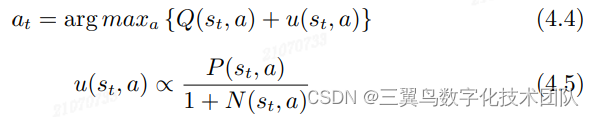
公式 4.4 和公式 4.5 参数含义如下:
-
表示在
状态下执行 a 动作得到下一个时刻的状态,即
的状态;
-
是节点
-
是节点
-
是节点
对于一个特定的节点 和动作 a,
的值是固定不变。所以刚开始时
比较小,对于
比较大的子节点,
的值相对较大,从 而达到探索
输出的高概率动作的目的。随着 search 轮数的增多,子节点
被选中的次数
变大,相应
变小,会更依赖
的值选择下一个动作,从而降低“探索”倾向,达到倾向“利用”的目的。 所以修改后的公式也有权衡“探索”和“利用”的功能。
Expansion: 在 MCTS 原算法中,如果 search 到叶子节点或者子节点 不全在“已知 Tree”的节点时,一定会 expansion 一个新叶子节点出来。在 AlphaGo 中,search 到叶子节点时也会 expansion 新的节点,但在遇到子节点不全在“已知 Tree”的节点时,可能会 expansion 新叶子节点,也可能不 expansion 新的叶子节点。这由于 计算所有的动作 a 的落子概率, 从而不论节点
的子节点是否在“已知 Tree”中,均可以计算出公式 4.5 的
,不在“已知 Tree”的子节点
的 Q = 0;在“已知 Tree” 中子节点
的
值为节点记录值,且
随着被 选中的次数增多而减小, 所以存在可能:
![]()
这时便会扩展一个新的节点。另外一种 expansion 策略,若“已知 Tree”中 节点 s, 被选中的次数大于阈值 T, 且节点 s 还存在子节点 不 在“已知 Tree”中,则 expansion 落子概率最大的子节点。这两种扩展策略 都可以达到减小搜索宽度的目的。
Simulation: 在原 MCTS 中,这步只有仿真。但在 AlphaGo 中,则使 用 和
达到仿真与盘面评估结合的目的:
![]()
公式 4.7 参数含义如下:
-
表示 expansion 新添加的叶子节点;
-
是 Value Network 对节点
-
是仿真数据得到的结果,采用 Policy Network 小模型 pπ 进行仿真;
-
是权衡
-
表示每次仿真得到的叶子节点的值;
相对于原 MCTS 的 Simulation,主要有两点改动: 第一点引入了围棋盘面 评估函数 ,而且这个评估函数效果很好;第二点在仿真时,用
替代均 匀分布,
由人类数据训练得到,与真实落子分布更接近,所以效果上要比均匀分布好,而且单步输出只有 2us, 适合作为仿真用。这些改动给计算 机围棋带来了显著的提升。
BackPropagation:AlphaGo 的 BackPropagation 与原 MCTS 的 BackPropagation 很像,更新每个节点的 :
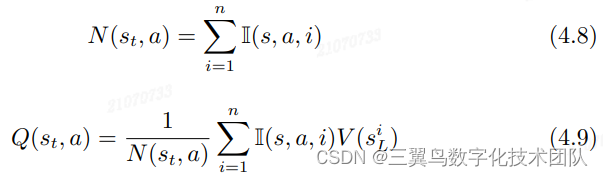
公式 4.8 和公式 4.9 的参数含义如下:
-
表示第
-
为示性函数,如果在“已知 Tree”第
,函数值为 1,否则函数值为 0;
-
为在进行了 n 次 MCTS 时,“已知 Tree”中节点
-
是经过 backpropagation 后,节点的值;
由公式 4.9 可以知道,每次仿真结束,会利用计算到的 更新第 i 搜索 路径上的所有节点的 Q 值。而且整个过程可以在集群中并行,在比赛时可 以加快“已知 Tree”的生成,减少搜索时间。
最后借助图 4-16 我们再来欣赏下,被 DeepMind 修改后的 MCTS 的全 过程。读到这里,我们应该了解这副图片中发生的故事细节了。
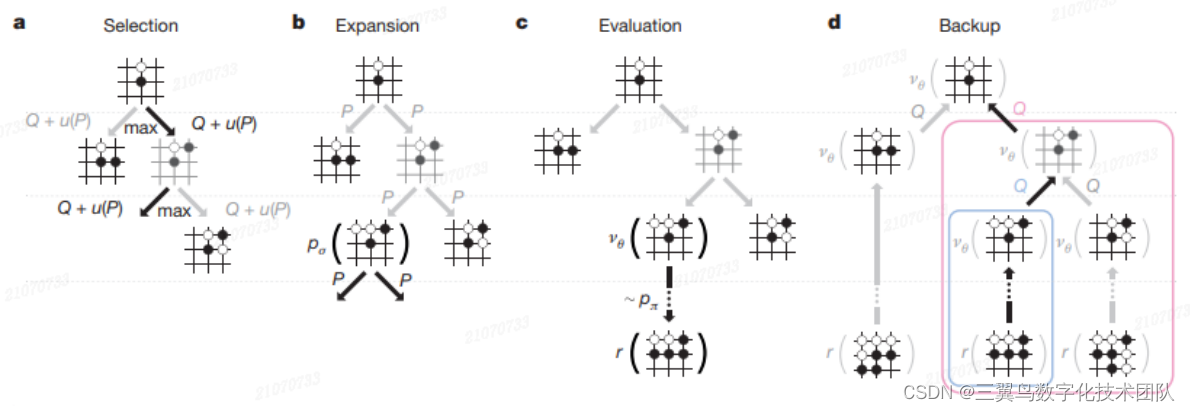
图 4-16: AlphaGo 的 MCTS 全过程
4.3 AlphaGo 中 RL 的思想
现在我们了解了 AlphaGo 的全部的设计脉络,知道了 AlphaGo = MCTS + Policy Network + Value Network 的具体含义。但可能心中会 有一些问题没消除:大家都说 AlphaGo 使用了 RL(强化学习) 我们撕 AlphaGo 的技术细节,似乎没有感觉到它使用了强化学习,那么 AlphaGo 在 哪些地方使用了 RL?又是如何使用的 RL 知识。这里说下我的浅显认知, 若有不对的地方请帮助指出来。
RL 建立在 MDP 模型上,MDP 有五元组 < S,P,A,r,γ >, 而且还有 policy 和策略
对应的值函数,值函数包括状态值函数
和动作值函数
,在 MDP 五元组信息完全已知情况下,希望求出最 优策略
和最优值函数
or
,这是 model- base(基于模型) 的求解。若 MDP 五元组中转移概率 P 未知或者奖励函数 r 未知, 不能 使用 Bellman 方程求解,则认为解决这样的 MDP 问题是 model-free(免模型)。可以将围棋问题建模为 MDP,而且又因为转移概率 P 未知,所以需 要 model-free 的方法求解。在 AlphaGo 中,求解 Policy Network
使用 了 RL 中策略梯度定理,即公式 4.2;AlphaGo 中的值函数
也和 RL 值函数一样: 表示从当前状态到终点状态的收益,所以求解方法中,可以使用 Monte Carlo 采样和时间差分等算法,这也是 RL 中的知识。自对弈应该对 应 RL 中的 Monte Carlo 采样。
4.4 AlphaGo 不完美的地方
基于 2015 年深度学习的发展,AlphaGo 有很多不太完美的地方。比较 明显的问题:AlphaGo 与 MCTS 结合后,Simulation 时,还需要小策略网络 进行仿真,没有完全消除深度上的搜索;提取围棋特征时,还有很多的手工特征,这点也很不完美。在 AlphaGo 面世后,后续相继出来了 resnet,BN 等深度学习的技术,这些新技术可以为深度学习带来很大的进步。于是这些不足和新技术,一起为 AlphGoZero 的诞生埋下伏笔。
5. 结语
AlphaGo 的故事只是一个开始,后续诞生的 AlphaGo Zero,AlphaZero,MuZero 使技术一步步深度,并且让故事更加精彩。因为时间问题,针对 AlphaGo 后续的模型不能展开叙述,期望在下一个假期,将后续 3 个模型也补充进来。在探索过程中,难免存在理解狭义或者误解的地方,还请大家帮助指出。 今年(2023)中秋和国庆连在一起,一共有八天假期,用了七天的假期探索 AlphaGo 系列,并在此期间完成这篇博客。用这篇博客,作为今年这 个国庆假期的一个纪念。感谢家人在假期对我的支持,使我对整个技术脉络可以充分的探索和学习。
6. 参考文献
[1] Roger Grosse: CSC 311: Introduction to Machine Learning, https://www.cs.toronto.edu/~rgrosse/courses/csc311_ f20/slides/lec12.pdf
[2] DavidSilver: AlphaGo-tutorial-slides_ compressed, https://www.davidsilver.uk/wp-content/uploads/2020/03/AlphaGo-tutorial-slides_ compressed.pdf
[3] Mastering the game of Go with deep neural networks and tree search, https://storage.googleapis.com/deepmind-media/alphago/AlphaGoNaturePaper.pdf
[4] Mingsheng Long: Deep Learning http://ise.thss.tsinghua.edu.cn/ mlong/
[5] Browne, Cameron B. and Powley, Edward and Whitehouse, Daniel and Lucas, Simon M. and Cowling, Peter I. and Rohlfshagen, Philipp and Tavener, Stephen and Perez, Diego and Samothrakis, Spyridon and Colton, Simon: A Survey of Monte Carlo Tree Search Methods https://www.researchgate.net/publication/235985858_A_Survey_of_Monte_Carlo_Tree_Search_Methods
[6] Bryce Wiedenbeck:CS 63: Artificial Intelligence https://www.cs.swarthmore.edu/b̃ryce/cs63/s16/slides/2-15_MCTS.pdf
[7] jefft: Introduction to Monte Carlo Tree Search https://jeffbradberry.com/posts/2015/09/intro-to-monte-carlo-tree-search/
7. 团队介绍
「三翼鸟数字化技术平台-智慧设计团队」依托实体建模技术与人工智能技术打造面向家电的智能设计平台,为海尔特色的成套家电和智慧场景提供可视可触的虚拟现实体验。智慧设计团队提供全链路设计,涵盖概念化设计、深化设计、智能仿真、快速报价、模拟施工、快速出图、交易交付、设备检修等关键环节,为全屋家电设计提供一站式解决方案。