文章目录
- 大数据深度学习长短时记忆网络(LSTM):从理论到PyTorch实战演示
- 1. LSTM的背景
- 人工神经网络的进化
- 循环神经网络(RNN)的局限性
- LSTM的提出背景
- 2. LSTM的基础理论
- 2.1 LSTM的数学原理
- 遗忘门(Forget Gate)
- 输入门(Input Gate)
- 记忆单元(Cell State)
- 输出门(Output Gate)
- 2.2 LSTM的结构逻辑
- 遗忘门:决定丢弃的信息
- 输入门:选择性更新记忆单元
- 更新单元状态
- 输出门:决定输出的隐藏状态
- 门的相互作用
- 逻辑结构的实际应用
- 总结
- 2.3 LSTM与GRU的对比
- 1. 结构
- LSTM
- GRU
- 2. 数学表达
- LSTM
- GRU
- 3. 性能和应用
- 小结
- 3. LSTM在实际应用中的优势
- 处理长期依赖问题
- 遗忘门机制
- 梯度消失问题的缓解
- 广泛的应用领域
- 灵活的架构选项
- 成熟的开源实现
- 小结
- 4. LSTM的实战演示
- 4.1 使用PyTorch构建LSTM模型
- 定义LSTM模型
- 训练模型
- 评估和预测
- 5. LSTM总结
- 解决长期依赖问题
- 广泛的应用领域
- 灵活与强大
- 开源支持
- 持战与展望
- 总结反思
- 广泛的应用领域
- 灵活与强大
- 开源支持
- 持战与展望
- 总结反思
大数据深度学习长短时记忆网络(LSTM):从理论到PyTorch实战演示
本文深入探讨了长短时记忆网络(LSTM)的核心概念、结构与数学原理,对LSTM与GRU的差异进行了对比,并通过逻辑分析阐述了LSTM的工作原理。文章还详细演示了如何使用PyTorch构建和训练LSTM模型,并突出了LSTM在实际应用中的优势。
1. LSTM的背景
人工神经网络的进化
人工神经网络(ANN)的设计灵感来源于人类大脑中神经元的工作方式。自从第一个感知器模型(Perceptron)被提出以来,人工神经网络已经经历了多次的演变和优化。
- 前馈神经网络(Feedforward Neural Networks): 这是一种基本的神经网络,信息只在一个方向上流动,没有反馈或循环。
- 卷积神经网络(Convolutional Neural Networks, CNN): 专为处理具有类似网格结构的数据(如图像)而设计。
- 循环神经网络(Recurrent Neural Networks, RNN): 为了处理序列数据(如时间序列或自然语言)而引入,但在处理长序列时存在一些问题。
循环神经网络(RNN)的局限性
循环神经网络(RNN)是一种能够捕捉序列数据中时间依赖性的网络结构。但是,传统的RNN存在一些严重的问题:
- 梯度消失问题(Vanishing Gradient Problem): 当处理长序列时,RNN在反向传播时梯度可能会接近零,导致训练缓慢甚至无法学习。
- 梯度爆炸问题(Exploding Gradient Problem): 与梯度消失问题相反,梯度可能会变得非常大,导致训练不稳定。
- 长依赖性问题: RNN难以捕捉序列中相隔较远的依赖关系。
由于这些问题,传统的RNN在许多应用中表现不佳,尤其是在处理长序列数据时。
LSTM的提出背景
长短时记忆网络(LSTM)是一种特殊类型的RNN,由Hochreiter和Schmidhuber于1997年提出,目的是解决传统RNN的问题。
- 解决梯度消失问题: 通过引入“记忆单元”,LSTM能够在长序列中保持信息的流动。
- 捕捉长依赖性: LSTM结构允许网络捕捉和理解长序列中的复杂依赖关系。
- 广泛应用: 由于其强大的性能和灵活性,LSTM已经被广泛应用于许多序列学习任务,如语音识别、机器翻译和时间序列分析等。
LSTM的提出不仅解决了RNN的核心问题,还开启了许多先前无法解决的复杂序列学习任务的新篇章。
2. LSTM的基础理论
2.1 LSTM的数学原理
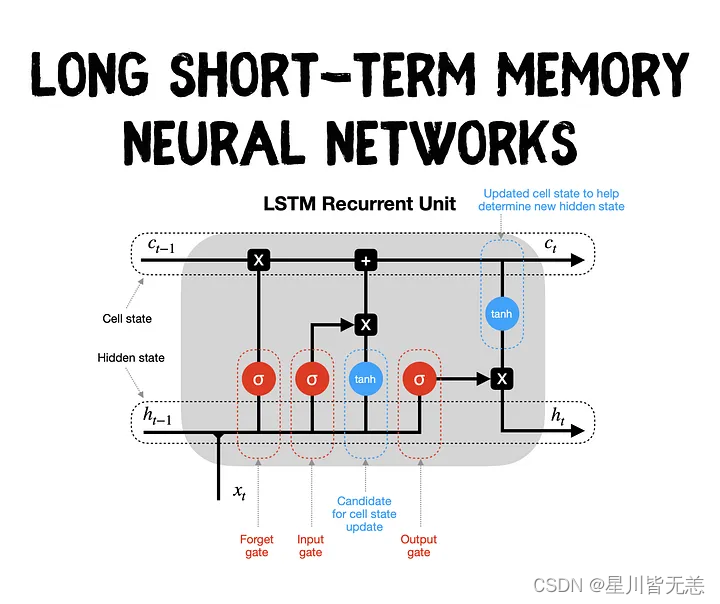
长短时记忆网络(LSTM)是一种特殊的循环神经网络,它通过引入一种称为“记忆单元”的结构来克服传统RNN的缺点。下面是LSTM的主要组件和它们的功能描述。
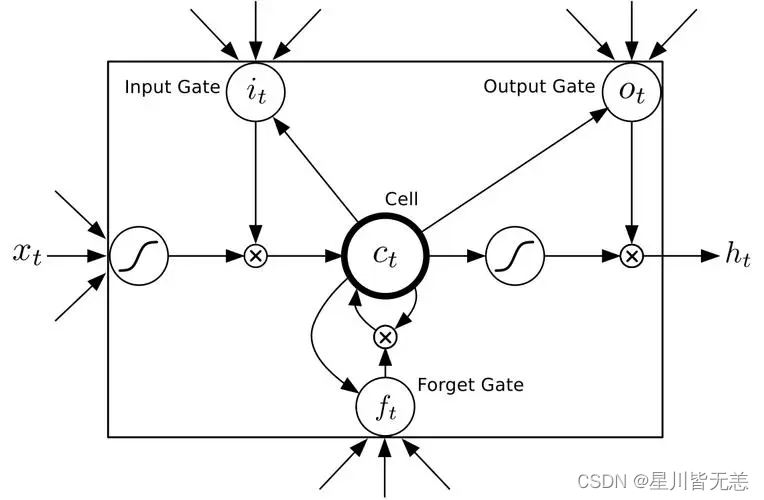
遗忘门(Forget Gate)
遗忘门的作用是决定哪些信息从记忆单元中遗忘。它使用sigmoid激活函数,可以输出在0到1之间的值,表示保留信息的比例。
[
f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f)
]
其中,(f_t)是遗忘门的输出,(\sigma)是sigmoid激活函数,(W_f)和(b_f)是权重和偏置,(h_{t-1})是上一个时间步的隐藏状态,(x_t)是当前输入。
输入门(Input Gate)
输入门决定了哪些新信息将被存储在记忆单元中。它包括两部分:sigmoid激活函数用来决定更新的部分,和tanh激活函数来生成候选值。
[
i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i)
]
[
\tilde{C}t = \tanh(W_C \cdot [h, x_t] + b_C)
]
记忆单元(Cell State)
记忆单元是LSTM的核心,它能够在时间序列中长时间保留信息。通过遗忘门和输入门的相互作用,记忆单元能够学习如何选择性地记住或忘记信息。
[
C_t = f_t \cdot C_{t-1} + i_t \cdot \tilde{C}_t
]
输出门(Output Gate)
输出门决定了下一个隐藏状态(也即下一个时间步的输出)。首先,输出门使用sigmoid激活函数来决定记忆单元的哪些部分将输出,然后这个值与记忆单元的tanh激活的值相乘得到最终输出。
[
o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o)
]
[
h_t = o_t \cdot \tanh(C_t)
]
LSTM通过这些精心设计的门和记忆单元实现了对信息的精确控制,使其能够捕捉序列中的复杂依赖关系和长期依赖,从而大大超越了传统RNN的性能。
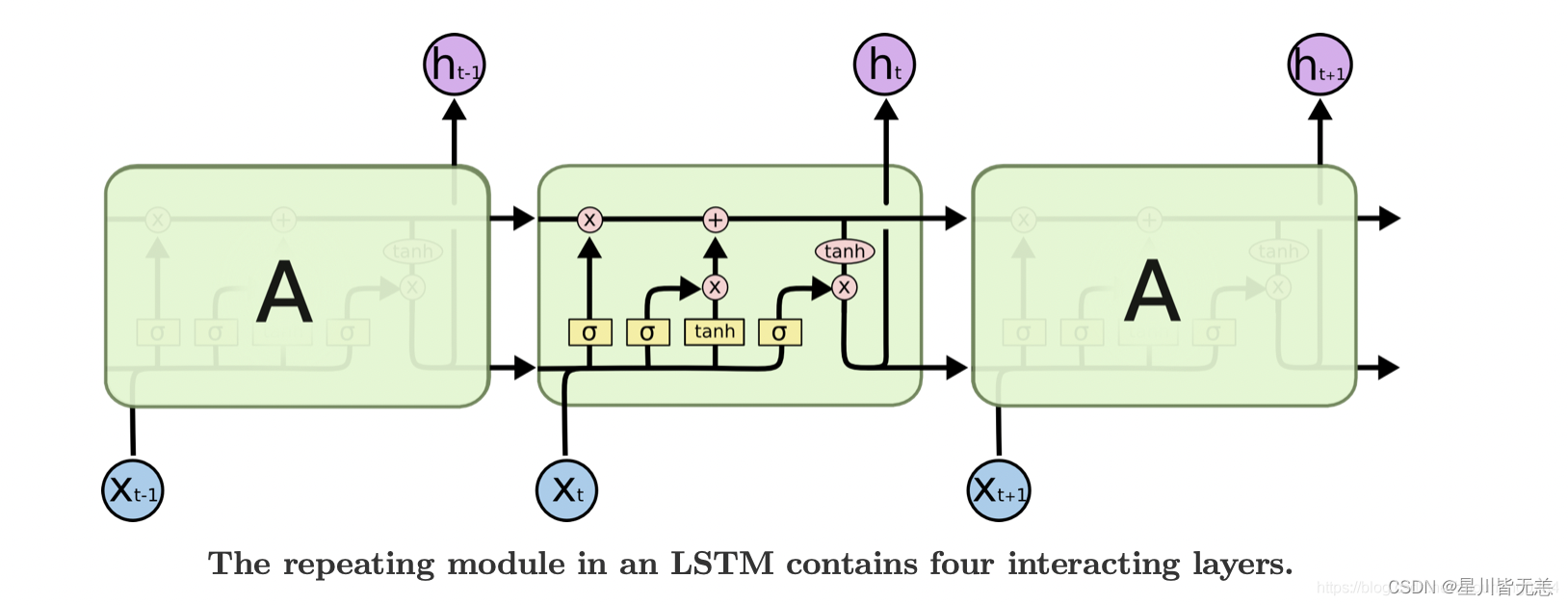
2.2 LSTM的结构逻辑
长短时记忆网络(LSTM)是一种特殊的循环神经网络(RNN),专门设计用于解决长期依赖问题。这些网络在时间序列数据上的性能优越,让我们深入了解其逻辑结构和运作方式。
遗忘门:决定丢弃的信息
遗忘门决定了哪些信息从单元状态中丢弃。它考虑了当前输入和前一隐藏状态,并通过sigmoid函数输出0到1之间的值。
输入门:选择性更新记忆单元
输入门决定了哪些新信息将存储在单元状态中。它由两部分组成:
- 选择性更新:使用sigmoid函数确定要更新的部分。
- 候选层:使用tanh函数产生新的候选值,可能添加到状态中。
更新单元状态
通过结合遗忘门的输出和输入门的输出,可以计算新的单元状态。旧状态的某些部分会被遗忘,新的候选值会被添加。
输出门:决定输出的隐藏状态
输出门决定了从单元状态中读取多少信息来输出。这个输出将用于下一个时间步的LSTM单元,并可以用于网络的预测。
门的相互作用
- 遗忘门: 负责控制哪些信息从单元状态中遗忘。
- 输入门: 确定哪些新信息被存储。
- 输出门: 控制从单元状态到隐藏状态的哪些信息流动。
这些门的交互允许LSTM以选择性的方式在不同时间步长的间隔中保持或丢弃信息。
逻辑结构的实际应用
LSTM的逻辑结构使其在许多实际应用中非常有用,尤其是在需要捕捉时间序列中长期依赖关系的任务中。例如,在自然语言处理、语音识别和时间序列预测等领域,LSTM已经被证明是一种强大的模型。
总结
LSTM的逻辑结构通过其独特的门控机制为处理具有复杂依赖关系的序列数据提供了强大的手段。其对信息流的精细控制和长期记忆的能力使其成为许多序列建模任务的理想选择。了解LSTM的这些逻辑概念有助于更好地理解其工作原理,并有效地将其应用于实际问题。
2.3 LSTM与GRU的对比
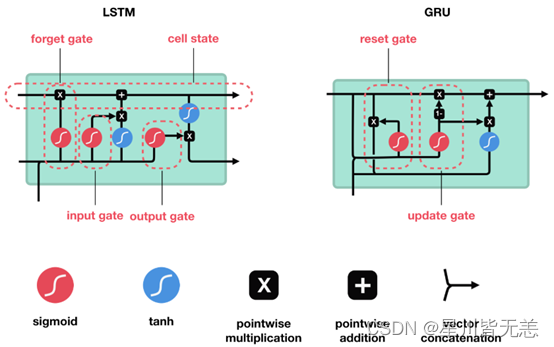
长短时记忆网络(LSTM)和门控循环单元(GRU)都是循环神经网络(RNN)的变体,被广泛用于序列建模任务。虽然它们有许多相似之处,但也有一些关键差异。
1. 结构
LSTM
LSTM包括三个门:输入门、遗忘门和输出门,以及一个记忆单元。这些组件共同控制信息在时间序列中的流动。
GRU
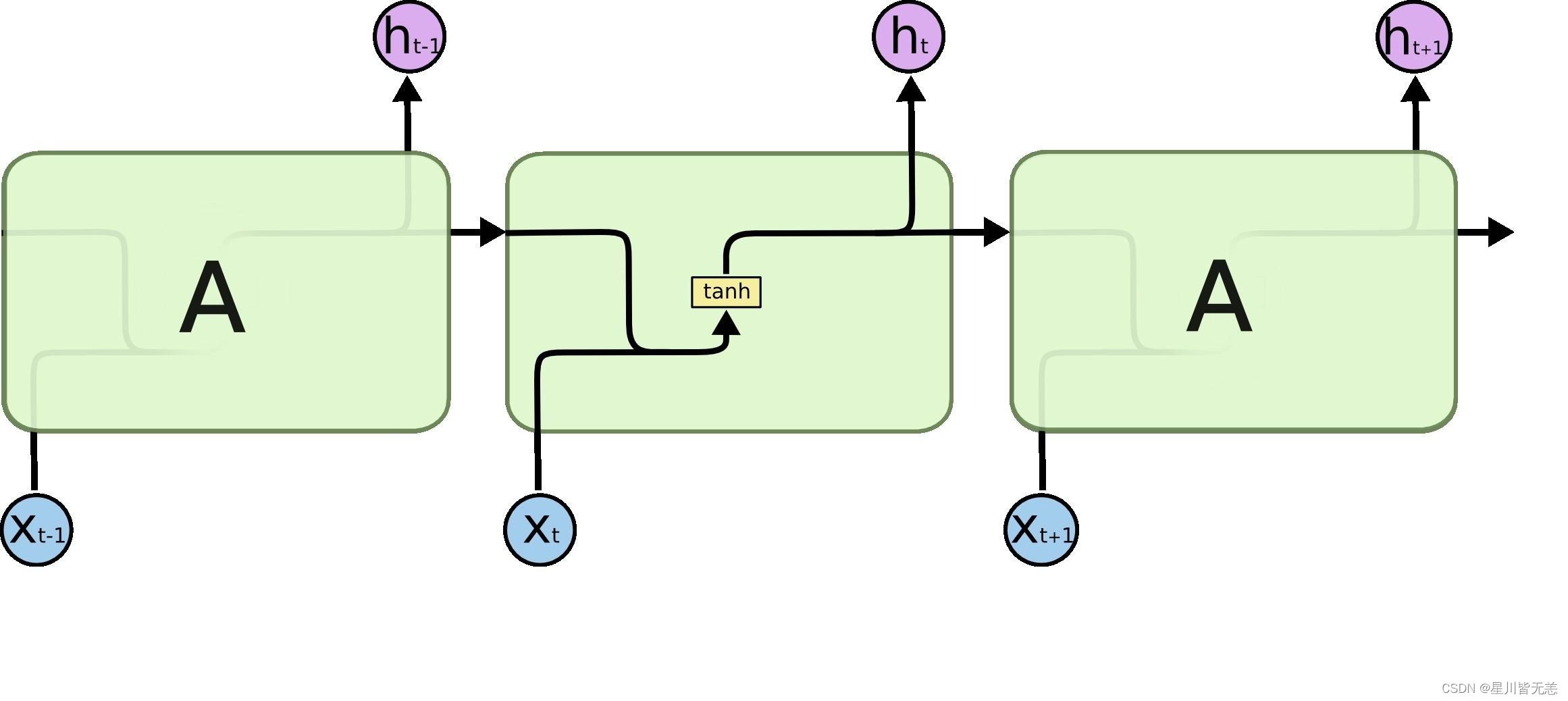
GRU有两个门:更新门和重置门。它合并了LSTM的记忆单元和隐藏状态,并简化了结构。
2. 数学表达
LSTM
LSTM的数学表达包括以下方程:
[
\begin{align*}
f_t & = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f)
i_t & = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i)
\tilde{C}*t & = \tanh(W_C \cdot [h*, x_t] + b_C)
C_t & = f_t \cdot C_{t-1} + i_t \cdot \tilde{C}*t
o_t & = \sigma(W_o \cdot [h*, x_t] + b_o)
h_t & = o_t \cdot \tanh(C_t)
\end{align*}
]
GRU
GRU的数学表达如下:
[
\begin{align*}
z_t & = \sigma(W_z \cdot [h_{t-1}, x_t] + b_z)
r_t & = \sigma(W_r \cdot [h_{t-1}, x_t] + b_r)
n_t & = \tanh(W_n \cdot [r_t \cdot h_{t-1}, x_t] + b_n)
h_t & = (1 - z_t) \cdot n_t + z_t \cdot h_{t-1}
\end{align*}
]
3. 性能和应用
- 复杂性: LSTM具有更复杂的结构和更多的参数,因此通常需要更多的计算资源。GRU则更简单和高效。
- 记忆能力: LSTM的额外“记忆单元”可以提供更精细的信息控制,可能更适合处理更复杂的序列依赖性。
- 训练速度和效果: 由于GRU的结构较简单,它可能在某些任务上训练得更快。但LSTM可能在具有复杂长期依赖的任务上表现更好。
小结
LSTM和GRU虽然都是有效的序列模型,但它们在结构、复杂性和应用性能方面有所不同。选择哪一个通常取决于具体任务和数据。LSTM提供了更精细的控制,而GRU可能更高效和快速。实际应用中可能需要针对具体问题进行实验以确定最佳选择。
3. LSTM在实际应用中的优势

长短时记忆网络(LSTM)是循环神经网络(RNN)的一种扩展,特别适用于序列建模和时间序列分析。LSTM的设计独具匠心,提供了一系列的优势来解决实际问题。
处理长期依赖问题
LSTM的关键优势之一是能够捕捉输入数据中的长期依赖关系。这使其在理解和建模具有复杂时间动态的问题上具有强大的能力。
遗忘门机制
通过遗忘门机制,LSTM能够学习丢弃与当前任务无关的信息,这对于分离重要特征和减少噪音干扰非常有用。
梯度消失问题的缓解
传统的RNN易受梯度消失问题的影响,LSTM通过引入门机制和细胞状态来缓解这个问题。这提高了网络的训练稳定性和效率。
广泛的应用领域
LSTM已被成功应用于许多不同的任务和领域,包括:
- 自然语言处理: 如机器翻译,情感分析等。
- 语音识别: 用于理解和转录人类语音。
- 股票市场预测: 通过捕捉市场的时间趋势来预测股票价格。
- 医疗诊断: 分析患者的历史医疗记录来进行早期预警和诊断。
灵活的架构选项
LSTM可以与其他深度学习组件(如卷积神经网络或注意力机制)相结合,以创建复杂且强大的模型。
成熟的开源实现
现有许多深度学习框架,如TensorFlow和PyTorch,都提供了LSTM的高质量实现,这为研究人员和工程师提供了方便。
小结
LSTM网络在许多方面表现出色,特别是在处理具有复杂依赖关系的序列数据方面。其能够捕捉长期依赖,缓解梯度消失问题,和广泛的应用潜力使其成为许多实际问题的理想解决方案。随着深度学习技术的不断进步,LSTM可能会继续在新的应用场景和挑战中展示其强大的实用价值。
4. LSTM的实战演示
4.1 使用PyTorch构建LSTM模型

LSTM在PyTorch中的实现相对直观和简单。下面,我们将演示如何使用PyTorch构建一个LSTM模型,以便于对时间序列数据进行预测。
定义LSTM模型
我们首先定义一个LSTM类,该类使用PyTorch的nn.Module作为基类。
import torch.nn as nn
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super(LSTMModel, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out, _ = self.lstm(x) # LSTM层
out = self.fc(out[:, -1, :]) # 全连接层
return out
input_size: 输入特征的大小。hidden_size: 隐藏状态的大小。num_layers: LSTM层数。output_size: 输出的大小。
训练模型
接下来,我们定义训练循环来训练模型。
import torch.optim as optim
# 定义超参数
input_size = 10
hidden_size = 64
num_layers = 1
output_size = 1
learning_rate = 0.001
epochs = 100
# 创建模型实例
model = LSTMModel(input_size, hidden_size, num_layers, output_size)
# 定义损失函数和优化器
loss_function = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 训练循环
for epoch in range(epochs):
outputs = model(inputs)
optimizer.zero_grad()
loss = loss_function(outputs, targets)
loss.backward()
optimizer.step()
print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item()}')
这里,我们使用均方误差损失,并通过Adam优化器来训练模型。
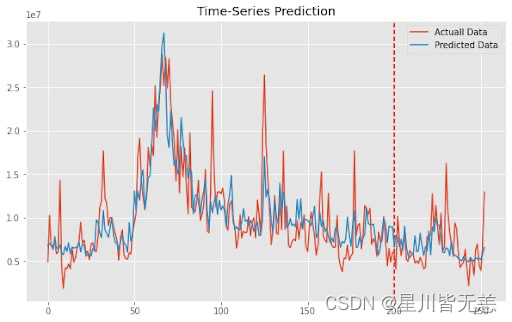
评估和预测
训练完成后,我们可以使用模型进行预测,并评估其在测试数据上的性能。
# 在测试数据上进行评估
model.eval()
with torch.no_grad():
predictions = model(test_inputs)
# ... 进一步评估预测 ...
5. LSTM总结
长短时记忆网络(LSTM)自从被提出以来,已经成为深度学习和人工智能领域的一个重要组成部分。以下是关于LSTM的一些关键要点的总结:
解决长期依赖问题
LSTM通过其独特的结构和门控机制,成功解决了传统RNNs在处理长期依赖时遇到的挑战。这使得LSTM在许多涉及序列数据的任务中都表现出色。
广泛的应用领域
从自然语言处理到金融预测,从音乐生成到医疗分析,LSTM的应用领域广泛且多样。
灵活与强大
LSTM不仅可以单独使用,还可以与其他神经网络架构(如CNN、Transformer等)结合,创造更强大、更灵活的模型。
开源支持
流行的深度学习框架如TensorFlow和PyTorch都提供了易于使用的LSTM实现,促进了研究和开发的便利性。
持战与展望
虽然LSTM非常强大,但也有其持战和局限性,例如计算开销和超参数调整。新的研究和技术进展可能会解决这些持战或提供替代方案,例如GRU等。
总结反思
广泛的应用领域
从自然语言处理到金融预测,从音乐生成到医疗分析,LSTM的应用领域广泛且多样。
灵活与强大
LSTM不仅可以单独使用,还可以与其他神经网络架构(如CNN、Transformer等)结合,创造更强大、更灵活的模型。
开源支持
流行的深度学习框架如TensorFlow和PyTorch都提供了易于使用的LSTM实现,促进了研究和开发的便利性。
持战与展望
虽然LSTM非常强大,但也有其持战和局限性,例如计算开销和超参数调整。新的研究和技术进展可能会解决这些持战或提供替代方案,例如GRU等。
总结反思
LSTM的出现推动了序列建模和时间序列分析的前沿发展,使我们能够解决以前难以处理的问题。作为深度学习工具箱中的一个关键组件,LSTM为学者、研究人员和工程师提供了强大的工具来解读和预测世界的复杂动态。