最近,一直跟别人讲大语言模型带来的AIGC是巨变,涉及了多个领域,并且谈了我们工作和生活中可以利用的地方,以及预测2024年大语言模型将在哪些领域爆发。这时,老板过来了,就聊,问,谈到Transformer结构,结果讲了半天愣是没讲清。
赶紧抽点时间整理出来!敲一遍才理解深。
🎬个人简介:一个全栈工程师的升级之路!
📋个人专栏:漫谈LLMs带来的AIGC浪潮
🎀CSDN主页 发狂的小花
🌄人生秘诀:学习的本质就是极致重复!
目录
一、引言
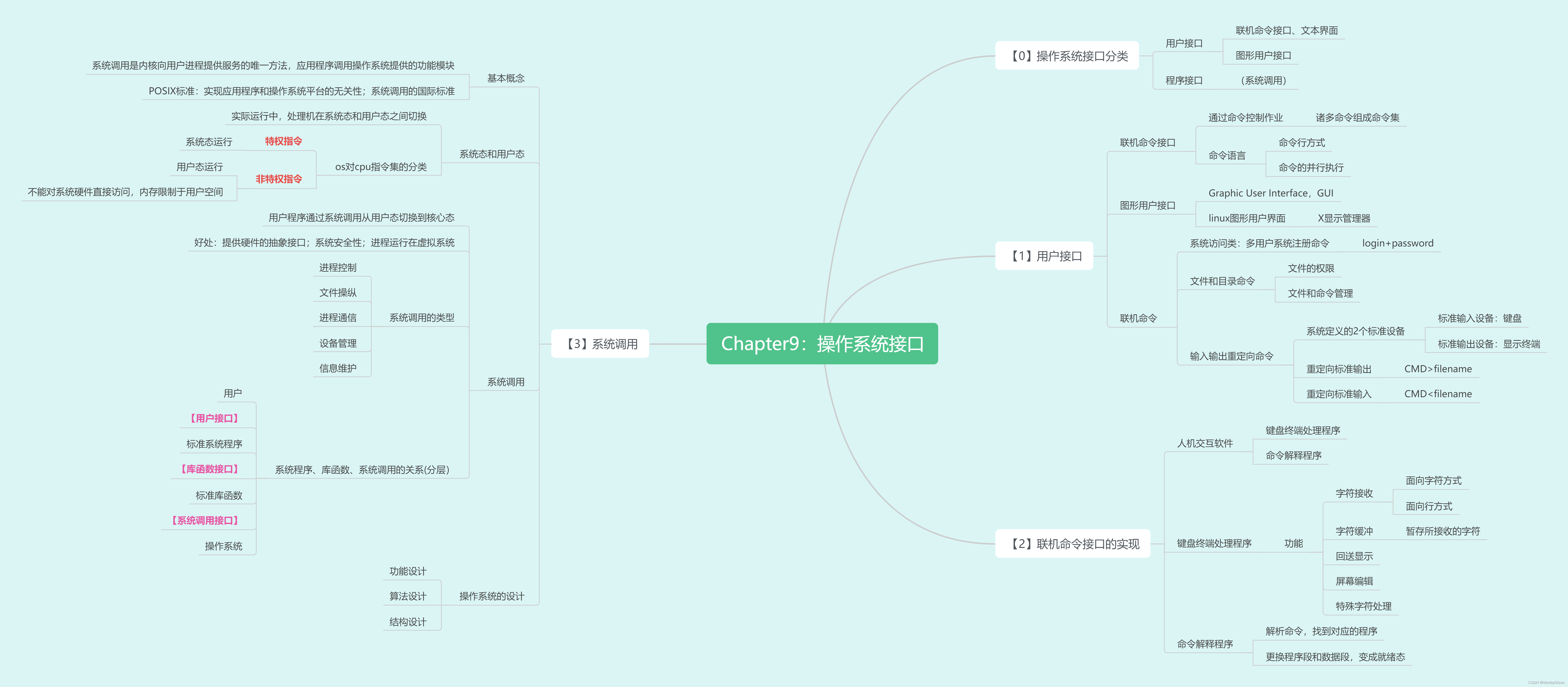
1 Transformer概述
2 发展历程及现状
二、Transformer基本原理
1 编码器-解码器架构
2 自注意力机制
3 残差连接与层归一化
三、Transformer核心组件详解
1 多头自注意力机制
2 前馈神经网络
3 编码器与解码器堆叠
4 掩蔽技术
四、输入输出处理及训练技巧
1 输入序列处理
2 输出序列处理
3 训练目标与优化方法
4 过拟合与正则化策略
五、Transformer在各领域应用举例
1 自然语言处理(NLP)
2 计算机视觉(CV)
3 语音识别(ASR)
4 其他领域应用
六、性能评估与对比分析
1 模型性能评估指标
2 与其他模型对比分析
3 优缺点总结及改进方向
一、引言
Google 2017年论文Attention is all you need提出了Transformer模型,完全基于Attention mechanism,抛弃了传统的CNN和RNN。
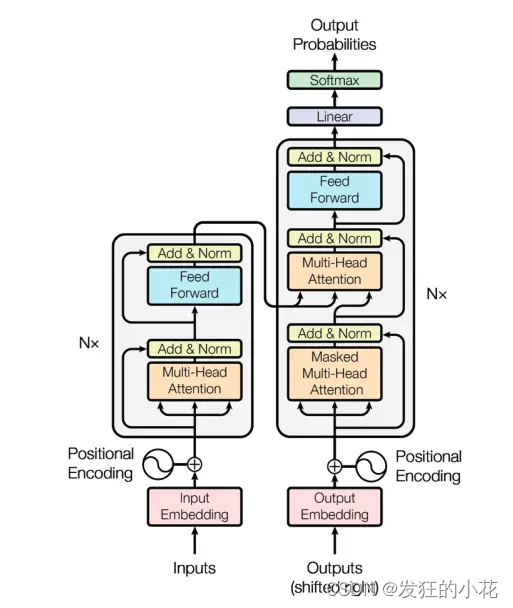
1 Transformer概述
Transformer是一种基于深度学习的模型架构,主要用于处理序列数据,如自然语言文本。
它采用了自注意力机制和位置编码来捕捉输入序列中的长期依赖关系。
Transformer模型由编码器和解码器两部分组成,分别用于处理输入序列和生成输出序列。
2 发展历程及现状
Transformer最初由Vaswani等人在2017年提出,用于机器翻译任务。
随着研究的深入,Transformer在多个NLP任务中都取得了显著的性能提升,如文本分类、情感分析、问答等。
目前,Transformer已成为NLP领域的主流模型架构之一,并不断有新的改进和优化出现。
二、Transformer基本原理
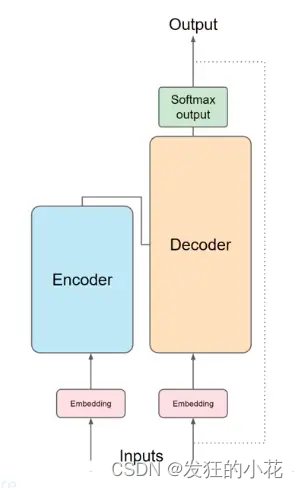
1 编码器-解码器架构
(1)编码器
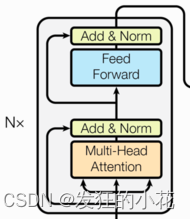
由多个相同的层堆叠而成,每一层都包含一个多头自注意力机制和一个前馈神经网络。编码器负责将输入序列转换为一种高级别的特征表示。
(2)解码器
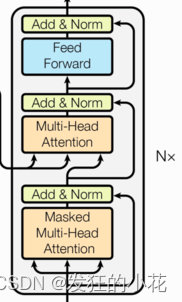
同样由多个相同的层堆叠而成,但在解码器中还包含了一个编码器-解码器注意力机制,用于关注输入序列的不同部分。解码器负责根据编码器的输出和已生成的输出序列来生成下一个输出词元。
2 自注意力机制
(1)注意力分数
通过计算输入序列中每个词元与其他词元之间的相似度来得到。这些分数决定了在生成当前词元的表示时,应该给予输入序列中其他词元多少关注。
(2)多头注意力
采用多个不同的注意力头来分别计算注意力分数,然后将它们的输出合并起来。这有助于模型捕捉到输入序列中不同方面的信息。
(3)位置编码
公式:
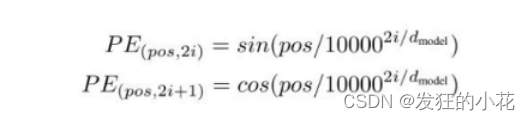
位置编码的作用:由于Transformer模型本身不具有处理序列数据的能力,因此需要引入位置编码来提供每个词元在序列中的位置信息。
位置编码的实现:可以采用正弦和余弦函数的线性变换来实现,这样可以保证对于任意长度的序列,都可以生成唯一的位置编码。
3 残差连接与层归一化
(1)残差连接
在Transformer模型的每一层中,都采用了残差连接来避免梯度消失问题。残差连接将输入序列直接加到该层的输出上,有助于模型学习到输入序列的恒等映射。
(2)层归一化
在残差连接之后,采用了层归一化来对每一层的输出进行归一化处理。这有助于加速模型的训练收敛,并提高模型的泛化能力。
三、Transformer核心组件详解
1 多头自注意力机制
(1)注意力机制
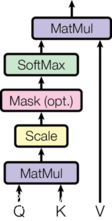
Transformer采用自注意力机制,通过计算序列中每个元素与其他元素的关联程度,得到每个元素的表示向量。
(2)多头注意力
为了捕捉不同子空间中的信息,Transformer采用多头注意力机制,将输入序列映射到多个不同的表示子空间中,每个子空间都独立计算注意力权重。
(3)权重归一化
在计算多头注意力时,需要对不同头的注意力权重进行归一化处理,以保证权重之和为1。
2 前馈神经网络
(1)逐位置前馈网络
Transformer中的前馈神经网络是逐位置的,即每个位置上的元素都独立地经过一个相同的前馈神经网络。
(2)非线性激活函数
前馈神经网络中采用了非线性激活函数,如ReLU或GELU,以增加模型的非线性表达能力。
(3)参数共享
在不同层的前馈神经网络中,参数是共享的,这有助于减少模型参数数量并提高训练效率。
3 编码器与解码器堆叠
(1)编码器堆叠
Transformer中编码器由多个相同的层堆叠而成,每个层都包含一个多头自注意力机制和一个前馈神经网络。编码器的输出是一组编码向量,表示输入序列的上下文信息。
(2)解码器堆叠
解码器同样由多个相同的层堆叠而成,每个层除了包含多头自注意力机制和前馈神经网络外,还包括一个编码器-解码器注意力机制,用于将编码器的输出作为上下文信息融入解码过程。
(3)残差连接和层归一化
在编码器和解码器的每个层中,都采用了残差连接和层归一化技术,以加速模型训练并提高性能。
4 掩蔽技术
(1)填充掩蔽
在处理变长序列时,Transformer采用填充掩蔽技术,对填充位置进行掩蔽处理,以避免模型学习到填充位置的无效信息。
(2)序列掩蔽
在训练语言模型等任务时,Transformer采用序列掩蔽技术,将部分序列元素进行掩蔽处理,以预测被掩蔽的元素,从而提高模型的生成能力。
四、输入输出处理及训练技巧
1 输入序列处理
(1)嵌入层
将离散的单词或符号转换为固定维度的向量表示,通常采用预训练的词向量或随机初始化。
(2)位置编码
由于Transformer模型不具有循环或卷积结构,因此需要为输入序列中的每个位置添加位置编码以提供位置信息。
(3)批次处理
将多个输入序列组合成一个批次进行训练,以提高计算效率。
2 输出序列处理
(1)解码器输出
Transformer解码器输出一个序列的向量表示,通常通过线性层和softmax函数将其转换为预测单词的概率分布。
(2)序列生成
采用贪心搜索、集束搜索等策略从解码器输出中生成完整的输出序列。
3 训练目标与优化方法
(1)训练目标
通常采用交叉熵损失作为训练目标,衡量预测单词概率分布与真实单词标签之间的差距。
(2)优化方法
使用随机梯度下降(SGD)、Adam等优化算法对模型参数进行更新,以最小化训练目标。
4 过拟合与正则化策略
(1)Dropout
在模型的各个层中引入Dropout技术,随机将一部分神经元的输出置为零,以减少过拟合。
(2)权重衰减
在损失函数中添加权重衰减项,对模型参数进行L1或L2正则化,以降低模型复杂度。
(3)早停法
在验证集上监控模型性能,当性能不再提升时提前停止训练,以防止过拟合。
五、Transformer在各领域应用举例
1 自然语言处理(NLP)
(1)机器翻译
Transformer结构在机器翻译任务中取得了显著的效果,如谷歌的神经机器翻译系统就是基于Transformer实现的,它能够处理多种语言之间的翻译问题。
(2)文本生成
Transformer也可以用于文本生成任务,如摘要生成、对话生成等。通过训练Transformer模型,可以生成与输入文本相关的高质量文本。
(3)情感分析
Transformer在情感分析任务中也有广泛应用。它可以对文本进行深层次的语义理解,从而准确地判断文本的情感倾向。
2 计算机视觉(CV)
(1)图像分类
Transformer在计算机视觉领域的应用也逐渐增多,如用于图像分类的Vision Transformer(ViT)模型,通过将图像划分为多个小块并输入到Transformer中,实现了高效的图像分类。
(2)目标检测
Transformer也可以用于目标检测任务,如DETR模型就是基于Transformer实现的目标检测算法,它能够准确地检测出图像中的多个目标并给出相应的边界框。
(3)图像生成
Transformer在图像生成任务中也有应用,如GANs中的Transformer结构可以生成高质量的图像。
3 语音识别(ASR)
(1)语音转文字
Transformer在语音识别领域的应用主要是将语音信号转化为文字。通过训练Transformer模型,可以实现高精度的语音转文字任务。
(2)语音合成
Transformer也可以用于语音合成任务,如Tacotron等模型就是基于Transformer实现的语音合成算法,它们可以将文本转化为自然、流畅的语音。
4 其他领域应用
(1)推荐系统
Transformer在推荐系统中的应用也逐渐增多。通过利用Transformer对用户和物品的历史交互数据进行建模,可以实现个性化的推荐。
(2)音乐生成
Transformer也可以用于音乐生成任务。通过训练Transformer模型学习音乐的内在结构和规律,可以生成符合特定风格或要求的音乐作品。
六、性能评估与对比分析
1 模型性能评估指标
(1)准确率
模型预测正确的样本占总样本的比例,是评估分类模型最基本的指标。
(2)精确率
模型预测为正样本的实例中,真正为正样本的比例。
(3)召回率(Recall)
真正为正样本的实例中,被模型预测为正样本的比例。
(4)F1值
精确率和召回率的调和平均值,用于综合评估模型的性能。
(5)损失函数
衡量模型预测结果与真实结果之间的差距,是优化模型的重要参考。
2 与其他模型对比分析
(1)与RNN/LSTM对比
Transformer相比RNN/LSTM具有更好的并行计算能力和长距离依赖关系建模能力,因此在处理长序列数据时表现更优。
(2)与CNN对比
Transformer采用自注意力机制捕捉全局信息,而CNN则通过卷积操作捕捉局部信息。在处理图像、语音等具有局部特征的数据时,CNN表现较好;而在处理文本等具有全局依赖关系的数据时,Transformer更具优势。
(3)与BERT对比
BERT是基于Transformer的双向编码器模型,通过预训练方式提高了模型性能。与BERT相比,Transformer结构更为简单,训练速度更快,但在某些任务上可能表现不如BERT。
3 优缺点总结及改进方向
优点:Transformer结构具有并行计算能力强、长距离依赖关系建模能力好、自注意力机制可捕捉全局信息等优点。
缺点:Transformer在处理长序列数据时可能出现梯度消失或梯度爆炸问题;同时,由于其采用自注意力机制,计算复杂度较高。
🌈我的分享也就到此结束啦🌈
如果我的分享也能对你有帮助,那就太好了!
若有不足,还请大家多多指正,我们一起学习交流!
📢未来的富豪们:点赞👍→收藏⭐→关注🔍,如果能评论下就太惊喜了!
感谢大家的观看和支持!最后,☺祝愿大家每天有钱赚!!!欢迎关注、关注!