前言
最近我朋友公司有个需求场景:查询千万级数据量并写入txt文件的程序优化需求。
朋友找到我对程序进行优化, 不然饭碗不保......💦
下面就分享一下解决这个优化问题的过程和思路,并总结一下,在以后不要在踩同样的坑。
现象描述
在查询千万级数据量并生成txt文件,出现以下2个问题
1. 由于数据量巨大,直接导致JVM的堆内存满, 程序出现假死状态,频繁的full GC, 同时服务器CPU 100%
2. 程序出现假死,在服务器上执行 jstack [pid] 查看JVM堆栈信息,提示无法建立。
遇到此问题,首先想到的是可以加大JVM的堆内存,可以避免程序假死。这也只是临时解决办法,还得从代码和数据库上下手。
🎉开启优化之路V1.0
经过程序分析:
程序并没有使用Stream流式查询,而且也没有采用分批查询,分批写入txt的文件。
于是乎,改写代码为流式查询,优化如下:(以下代码是经过脱敏处理)
改写DataMapper文件:
@SelectProvider(type = DataMapperProvider.class, method = "getDatasStreamByCode")
@Options(resultSetType = ResultSetType.FORWARD_ONLY, fetchSize = 10000) // 配置流失查询
@ResultType(LinkedHashMap.class)
void getDatasStreamByCode(String code, ResultHandler<LinkedHashMap> handler);改写service文件:
// 按行写入txt
StringBuffer sb = new StringBuffer();
dataMapper.getDatasStreamByCode(code, resultContext -> {
// 获取到10000条
LinkedHashMap<String, String> dataList = (LinkedHashMap<String, String>) resultContext.getResultObject();
// 业务处理
.....
// 分批写入文件
});按照上面改写之后的程序,发给我朋友去上线之后,确实能提升一定的效果。
过了一段时间之后,我朋友找到我之后,还是出现了同样的问题。
听到这个消息,我始终觉得不应该啊,这难道又被百度忽悠了。这骨头有这么难啃吗?🎨
🎃开启优化之路V2.0
经过分析,发现问题所在:
1. Mysql执行还是把查询结果全部传输到应用端进行缓存,再按批给到程序处理。此操作还是会造成JVM堆不够用。
2. Mysql非常特殊, 默认是关闭了流式查询,需要在JdbcUrl上增加useCursorFetch=true参数。
3. Mysql如果在JdbcUrl增加useCursorFetch=true, 但是程序执行的时候,报Mysql的临时表空间满 异常。
现在有个问题摆在面前 不加useCursorFetch参数,JVM堆内存会满。加了useCursorFetch参数,Mysql临时表空间会满。
这个和大部分网上答案描述不符合呢。那该如何破局呢?
站在表象是解决不了问题的,不得不深入源码分析,看看底层设计,发现是否有什么关键点被遗漏忽视掉。
追根溯源
源码分析大致思路,根据useCursorFetch这个关键字入手,从github上下载Mysql驱动包的源码分析。
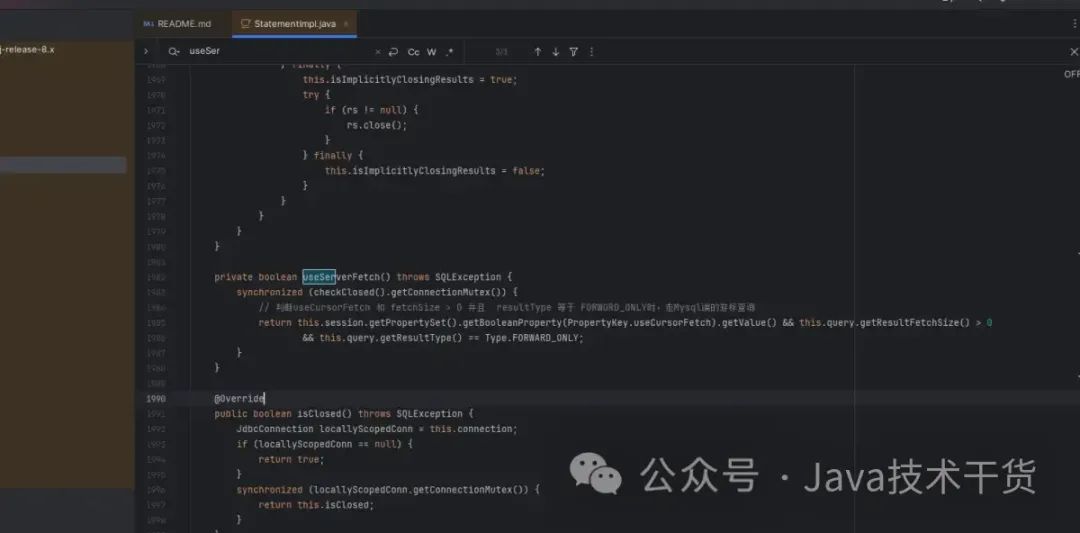
1. 从Mysql驱动源码入手 最主要的类StatementImpl 执行查询逻辑都在此方法。
关键路径1:com.mysql.cj.jdbc.StatementImpl#useServerFetch
关键路径2:com.mysql.cj.jdbc.StatementImpl#createStreamingResultSet
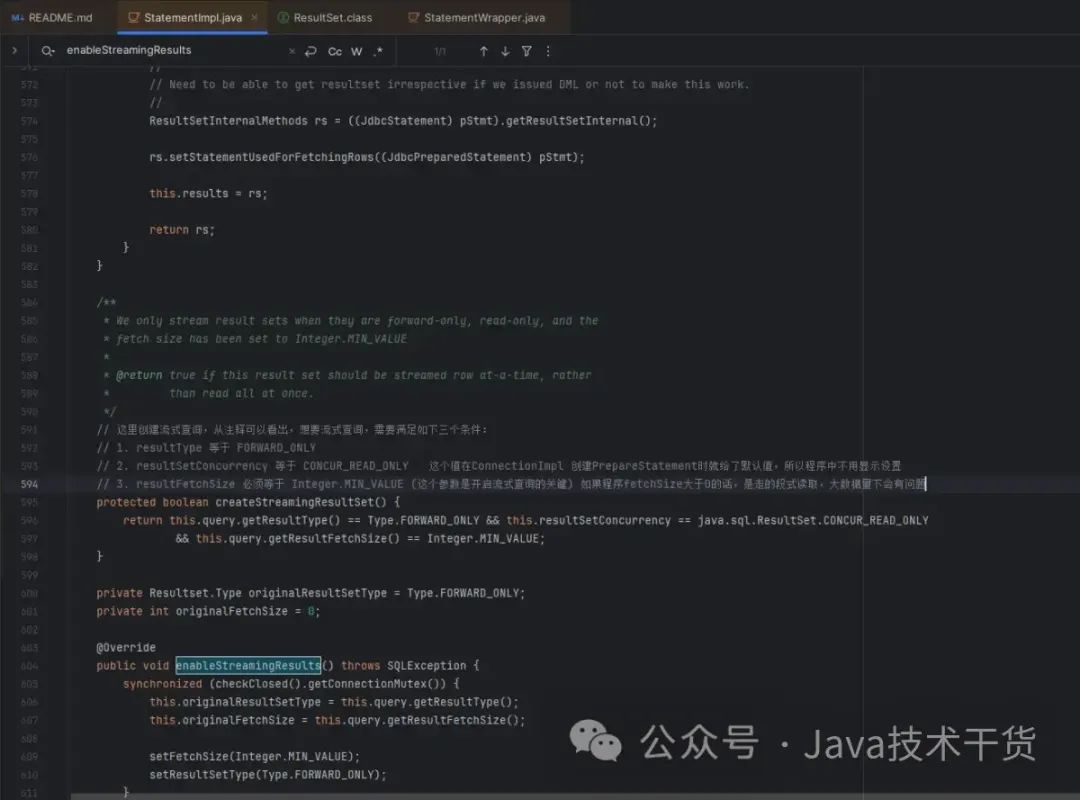
从上面两个地方可以大致总结如下:
查询分类:
1. 普通查询 (默认不开启)
2. 分段式查询 (useCursorFetch=true && resultType == FORWARD_ONLY && fetchSize > 0)
3. 流式查询 (useCursorFetch=true && resultType == FORWARD_ONLY && fetchSize = Integer.MIN_VALUE)
解决之道
从上面分析可以总结出,采用流式查询更加适合当前业务, 而分段式查询这种也是我们新手经常犯的小失误哈。
需要把fetchSize=10000修改成fetchSize=Integer.MIN_VALUE, 这个才是真正意义上的流式查询方式。