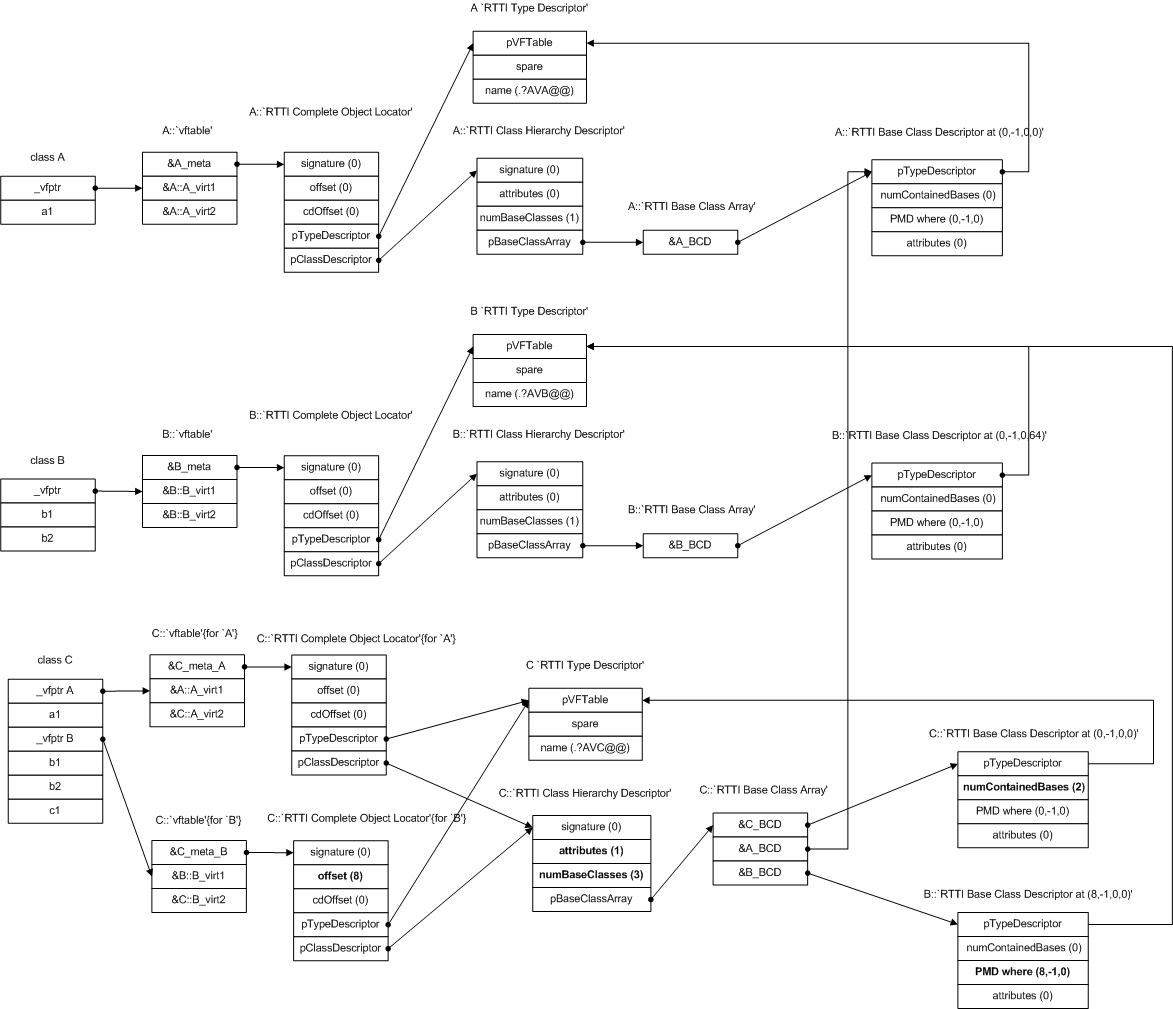
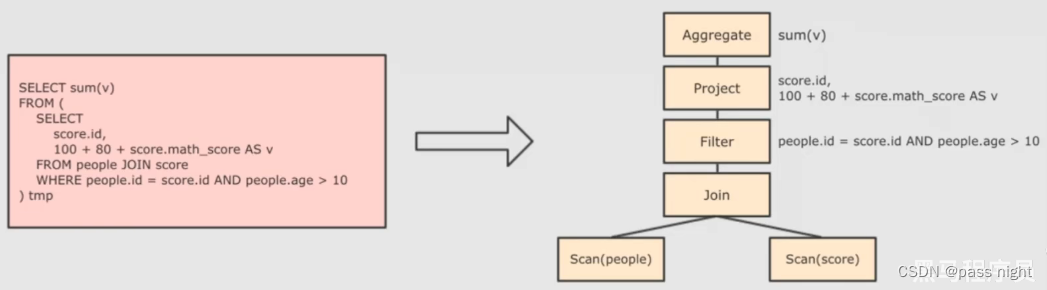
前言:Self-Attention是 Transformer 的重点,因此需要详细了解一下 Self-Attention 的内部逻辑。
一、什么是自注意力机制?
就上图为例,老实告诉我当你第一眼看到上图时,你的视线停留在哪个位置?对于我这种老二次元是在妹子身上,但是对于舰船迷来说,可能注意力就是在舰船上。同一张图片,不同的人观察注意到的可能是不同的地方,这就是人的注意力机制。attention 就是模仿人的注意力机制设计地。那么究竟是如何实现的呢?
二、自注意力机制结构
2.3 Self-Attention 结构
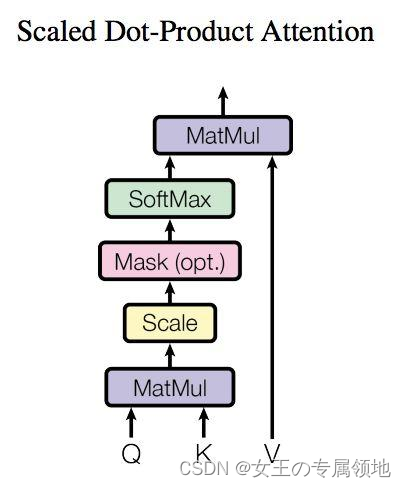
上图是 Self-Attention 的结构,在计算的时候需要用到矩阵Q(查询),K(键值),V(值)。在实际中,Self-Attention 接收的是输入(单词的表示向量x组成的矩阵X) 或者上一个 Encoder block 的输出。而Q,K,V正是通过 Self-Attention 的输入进行线性变换得到的。
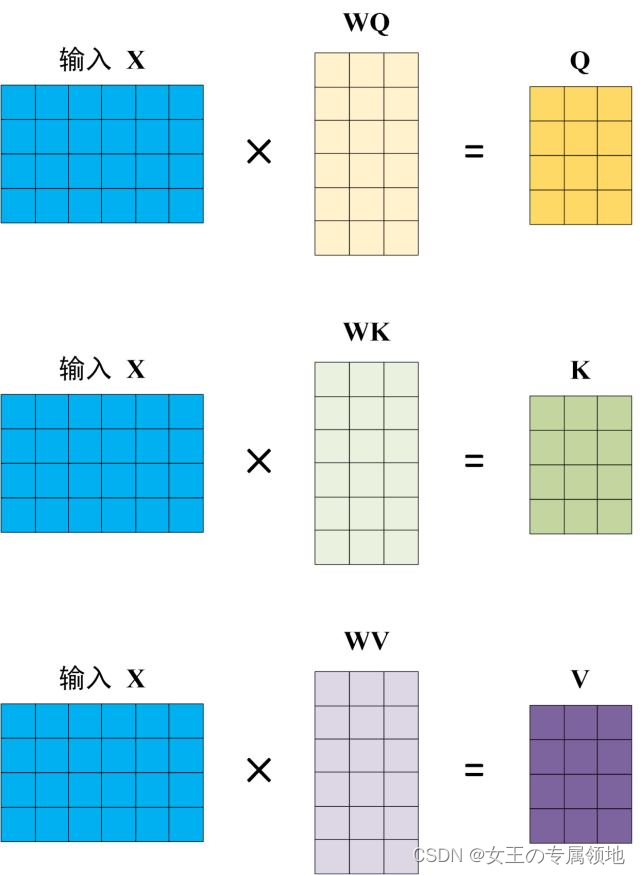
2.2 Q, K, V 的计算
Self-Attention 的输入用矩阵X进行表示,则可以使用线性变阵矩阵WQ,WK,WV计算得到Q,K,V。计算如下图所示,注意 X, Q, K, V 的每一行都表示一个单词。
2.3 Self-Attention 的输出
得到矩阵 Q, K, V之后就可以计算出 Self-Attention 的输出了,计算的公式如下: