目录
61.ReentrantReadWriteLock底层读写状态如何设计的?
62.读锁和写锁的最大数量是多少?
63.本地线程计数器ThreadLocalHoldCounter是用来做什么的?
64.写锁的获取与释放是怎么实现的?
65.读锁的获取与释放是怎么实现的?
66.什么是锁的升降级?
67.为什么HashTable慢?他的并发度是什么?那么ConcurrentHashMap并发度是什么?
68.ConcurrentHashMap在JDK1.7和JDK1.8中实现有什么差别?JDK1.8解决了JDK1.7中什么问题?
69.ConcurrentHashMap JDK1.7实现的原理是什么?
70.ConcurrentHashMap JDK1.7中Segment数(concurrencyLevel)默认值是多少?为何一旦初始化就不可再扩容?
61.ReentrantReadWriteLock底层读写状态如何设计的?
高16位为读锁,低16位为写锁。
62.读锁和写锁的最大数量是多少?
2的16次方减1。
63.本地线程计数器ThreadLocalHoldCounter是用来做什么的?
本地线程计数器,与对象绑定(线程->线程重入的次数)
64.写锁的获取与释放是怎么实现的?
tryAcquire/tryRelease
65.读锁的获取与释放是怎么实现的?
tryAcquireShared/tryReleaseShared
66.什么是锁的升降级?
ReentrantReadWriteLock为什么不支持锁升级?
ReentrantReadWriteLock不支持锁升级(把持读锁,获取写锁,最后释放读锁的过程)。目的也是保证数据可见性,如果读锁已经被多个线程获取,其中任意线程成功获取了写锁并更新了数据,则其更新对其他获取到读锁的线程是不可见的。
67.为什么HashTable慢?他的并发度是什么?那么ConcurrentHashMap并发度是什么?
HashTable之所以效率低下主要是因为其实现使用了synchronized关键字对put等操作进行加锁,而synchronized关键字加锁是对整个对象进行加锁,也就是说在进行put等修改Hash表的操作时,锁住了整个Hash表,从而使得其表现效率低下。
68.ConcurrentHashMap在JDK1.7和JDK1.8中实现有什么差别?JDK1.8解决了JDK1.7中什么问题?
ConcurrentHashMap JDK1.7:使用分段锁机制实现;
concurrentHashMap JDK1.8:则使用数组+链表+红黑树数据结构和CAS原子操作实现。
69.ConcurrentHashMap JDK1.7实现的原理是什么?
在JDK1.5~1.7版本,Java使用了分段锁机制实现concurrentHashMap。
简而言之,ConcurrentHashMap在对象中保存了一个Segment数组,即将整个Hash表划分为多个分段;而每个Segment元素,他通过继承ReentrantLock来进行加锁,所以每次需要加锁的操作锁住的是一个segment,猪样只要保证每个Segment是线程安全的,也就实现了全局的线程安全;这样,在执行put操作时首先根据hash算法定位到元素属于哪个Segment,然后对该Segment加锁即可。因此,ConcurrentHashMap在多线程并发编程中可是实现多线程put操作。
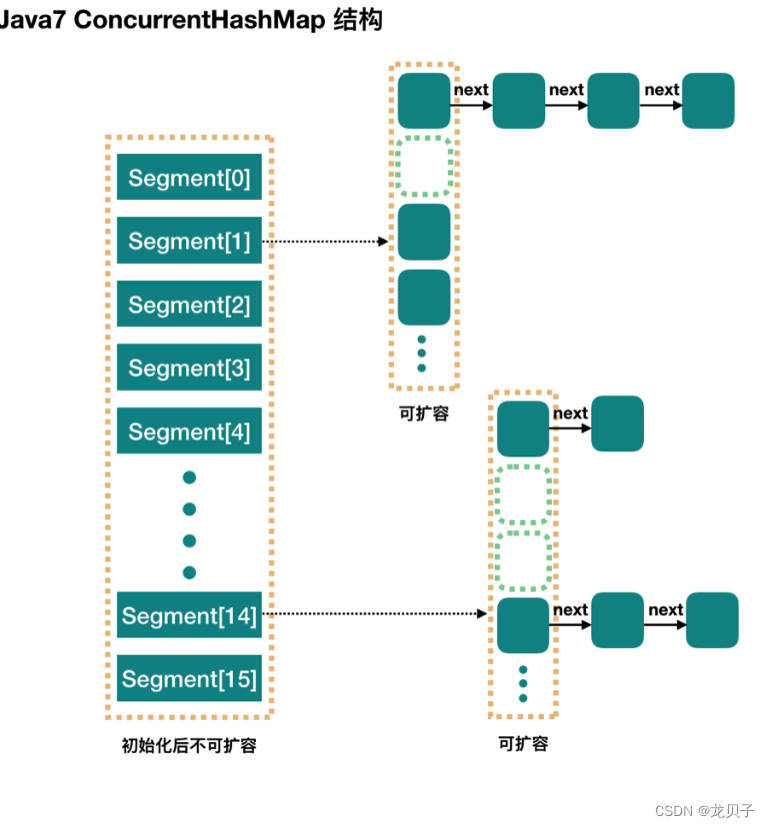
concurrentLevel:Segment数(并行级别,并发数)。默认是16,也就是说ConcurrentHashMap 有16个Segments,所以理论上,这个时候,最多可以同时支持16个线程并发写,只要他们的操作分别分布在不同的Segment上。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,他是不可以扩容的。
70.ConcurrentHashMap JDK1.7中Segment数(concurrencyLevel)默认值是多少?为何一旦初始化就不可再扩容?
默认16