文章目录
- 灾备方案概述、备份解决方案介绍
- 容灾解决方案介绍
- 华为云容灾解决方案概览
- 云容灾服务
- 云硬盘高可用服务 (VHA)
- VHA组网结构
- VHA逻辑组网架构
- VHA管理组件介绍
- VHA服务实现原理
- 云服务器高可用服务(CSHA)
- CSHA物理组网架构
- CSHA逻辑组网架构
- CSHA服务组件间调用关系
- 关键技术 - 存储双活
- 申请云服务器高可用CSHA的业务流
- 云服务器高可用CSHA故障恢复的业务流
- 云服务器高可用实例创建原理
- 故障切换实现原理
- 故障切换实现原理
- 重保护实现原理
- 关键技术 - 自动故障切换
- 云服务器容灾服务(CSDR)
- CSDR物理组网架构
- CSDR逻辑组网架构
- CSDR实现原理
- CSDR管理组件交互流程
- CSDR容灾测试切换原理流程
- CSDR计划性迁移原理流程
- CSDR云服务器故障切换原理流程
- 灾备方案架构介绍
- 云容灾架构总览
- 云容灾架构总览
- 本地高可用方案架构
- 同城双活方案架构
- 方案一:ECS+中间件(APIC/MQS/DCS)+数据库(跨AZ)
- 方案二:CCE+中间件(APIC/MQS/DCS)+数据库+GSLB[可选](跨AZ)
- 方案三:ECS/CCE+数据库+GSLB(跨Region)
- 同城云主机容灾方案架构
- 异地应用容灾方案
- 异地云主机容灾方案架构
- 云主机容灾+异地备份方案架构
- 云主机N:1容灾参考架构
- 云主机两地三中心容灾方案架构 - CSHA+CSDR
- 管理组件灾备方案介绍
- 管理组件跨AZ高可用
- 管理组件跨AZ高可用技术实现 - 单AZ向双AZ演进
- 管理组件跨Region容灾
- 管理组件两地三中心容灾
- 管理面跨AZ网络设计说明
- 管理面跨Region容灾网络设计说明
- 高阶云服务容灾简介
- 华为云Stack支持高阶云服务容灾
- 典型高阶服务实现原理 - OBS跨AZ容灾
- 典型高阶服务实现原理 - 跨Region复制技术实现
- 关键技术实现
- 跨Region复制技术实现
- 学习推荐
灾备方案概述、备份解决方案介绍
看下面这篇文章
容灾解决方案介绍
华为云容灾解决方案概览
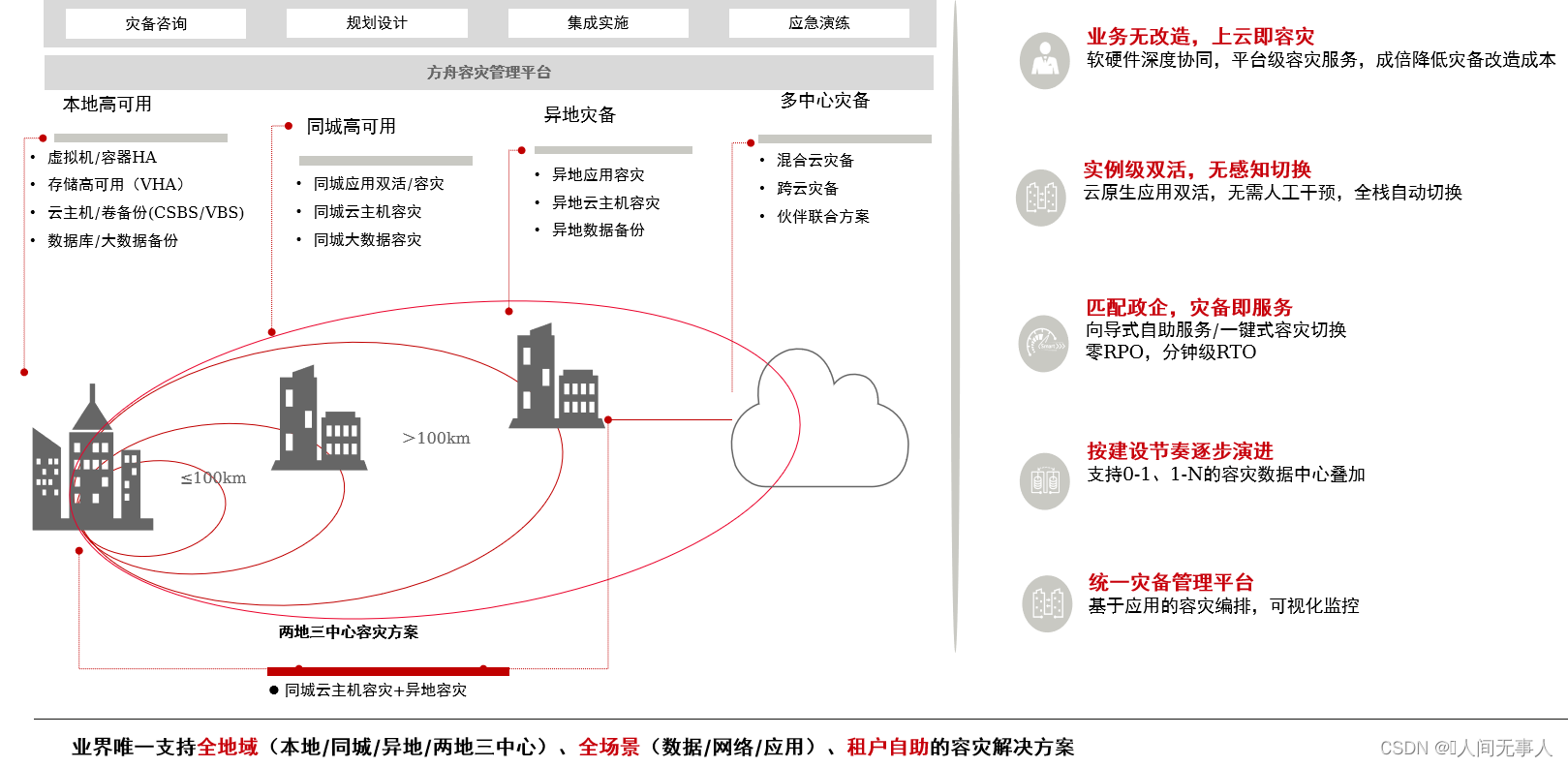
云容灾服务
- VHA(Volume High Availability),即云硬盘高可用服务,为弹性云服务器和裸金属服务器中的云硬盘提供本地存储双活保护。当单套存储设备发生故障时,数据零丢失,业务不中断
- CSHA(Cloud Server High Availability),即云服务器高可用服务,为云服务器提供同城数据中心间的高可用保护。当生产中心发生灾难时,被保护的云服务器能够自动或手动切换到灾备中心
- CSDR(Cloud Server Disaster Recovery),即云服务器容灾服务,为ECS和BMS提供异地容灾保护。当生产中心发生灾难时,可在异地灾备中心恢复受保护的ECS/BMS
云硬盘高可用服务 (VHA)
VHA(Volume High Availability),即云硬盘高可用服务,为弹性云服务器和裸金属服务器中的云硬盘提供本地存储双活保护。当单套存储设备发生故障时,数据零丢失,业务不中断
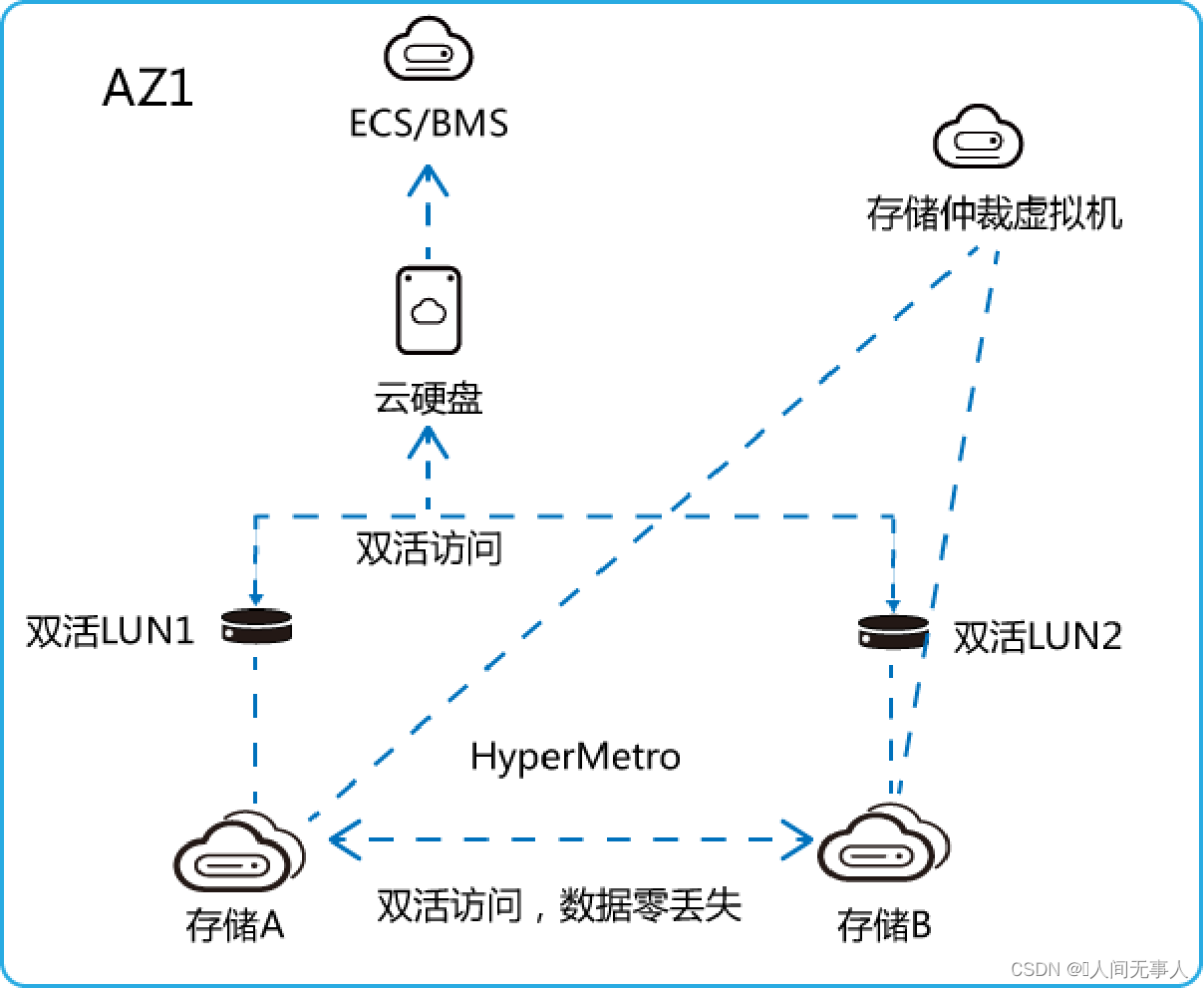
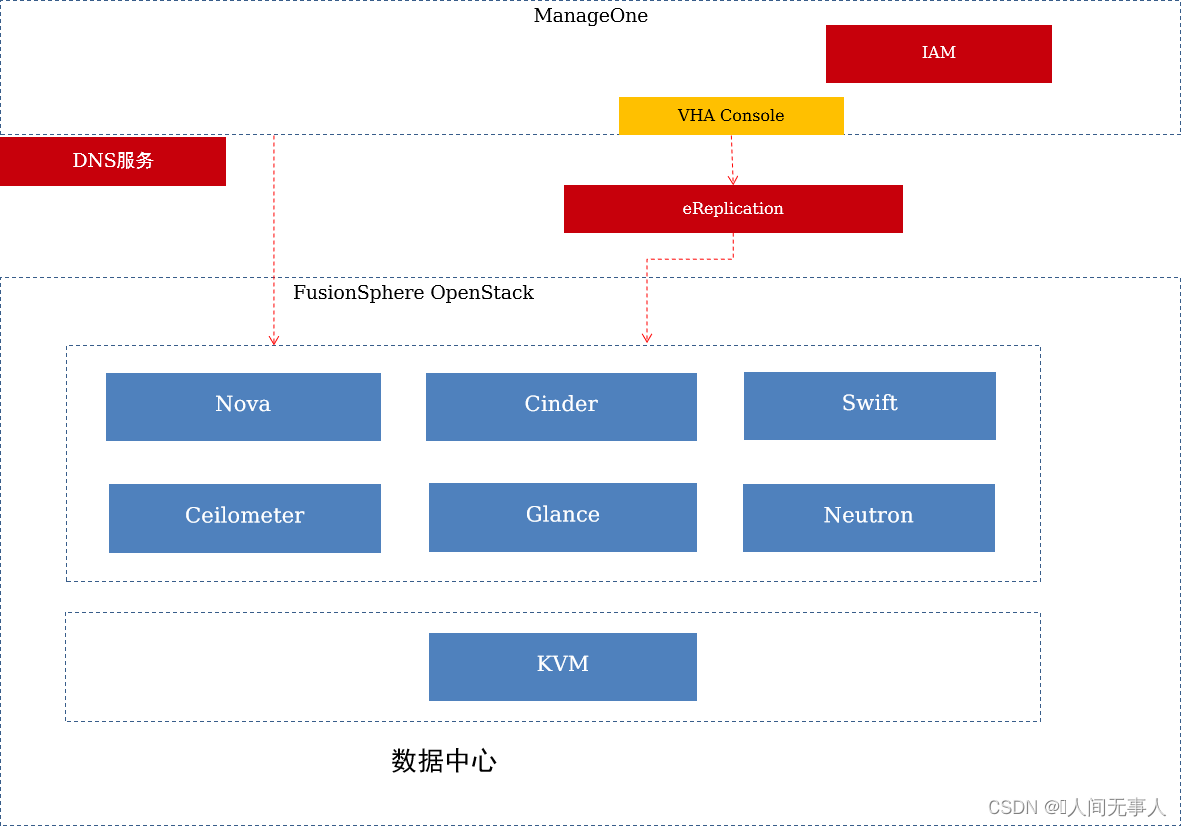
VHA组网结构
- VHA组网结构
- FusionSphere OpenStack Controller:
- OpenStack管理节点
- ManageOne:
- 华为云Stack统一运维管理平台
- BCManager eReplication:
- 作为VHA服务器,接收VHA管理控制台的请求
- FusionSphere OpenStack Controller:
- 华为HyperMetro双活特性有如下特点:
- 免网关双活方案:组网简单,容易部署;减少一个故障点,可靠性更高;避免了网关设备额外引入的时延(约0.5ms),性能更好。
- Active-Active双活:两套存储都支持业务读写,上层应用系统可充分应用该能力实现业务负载分担、负载均衡。数据实时同步,任意存储故障,数据零丢失,业务不中断。
- FastWrite特性:正常的SCSI写流程中,写请求有“写分配(Write Alloc)”和“写数据(Write Data)”两次交互,一个写请求需要在站点间往返两次才能完成。Fastwrite特性优化存储传输协议,提前在目标端预留接收写请求的缓存空间,省掉“写分配”环节,只要1次交互。该特性将存储之间数据同步时延缩短一半,提升了整体双活方案性能。
- 链路质量自适应: HyperMetro特性会根据各数据链路质量,自动在链路之间均衡负载。系统会动态监控链路质量,动态调整两条链路的负载分担比例,以尽量降低重传率,提升网络性能表现。
VHA逻辑组网架构
- 基于存储双活:核心能力,单个存储故障,数据不丢失,业务不中断,提升存储可靠性;复制过程中不影响云服务器计算性能;华为HyperMetro双活特性有如下特点:
- 免网关双活方案
- Active-Active双活
- FastWrite特性
- 链路质量自适应
- 数据零拷贝特性
- 跨站点坏块修复
- 华为HyperMetro双活特性有如下特点:
- 跨站点坏块修复:硬盘在使用过程中可能因为异常掉电等情况出现坏块,如果是可修复错误但是本端已经无法修复时,HyperMetro将自动从远端存储获取数据,修复本地数据盘的坏块,进一步提高系统的可靠性。
- 数据零拷贝特性:在双活镜像数据的初始同步或者恢复过程中的增量同步过程中,差异数据块通常有大量的零数据块,无需逐块复制。HyperMetro通过硬件芯片,对数据拷贝源端进行快速识别,找出零数据,在拷贝过程中,对全零数据特殊标识,只传输一个较小的特殊页面到对端,不再全量传输。该技术可有效减少同步数据量,减少带宽消耗,缩短同步时间。
VHA管理组件介绍
| 组件 | 作用 | 典型部署原则 |
|---|---|---|
| VHA Console | 提供VHA服务控制台 | 部署在ManageOne静态服务器 |
| BCManager eReplication | 作为VHA服务器,接收VHA管理控制台的请求 | 部署在Global层,虚拟化部署在OpenStack管理节点 |
| 生产存储 | 用于存放业务数据的存储设备。支持OceanStor V3/V5和Dorado V3 | 部署在POD/AZ,DC内每AZ至少部署2套,并配置双活关系 |
VHA服务实现原理
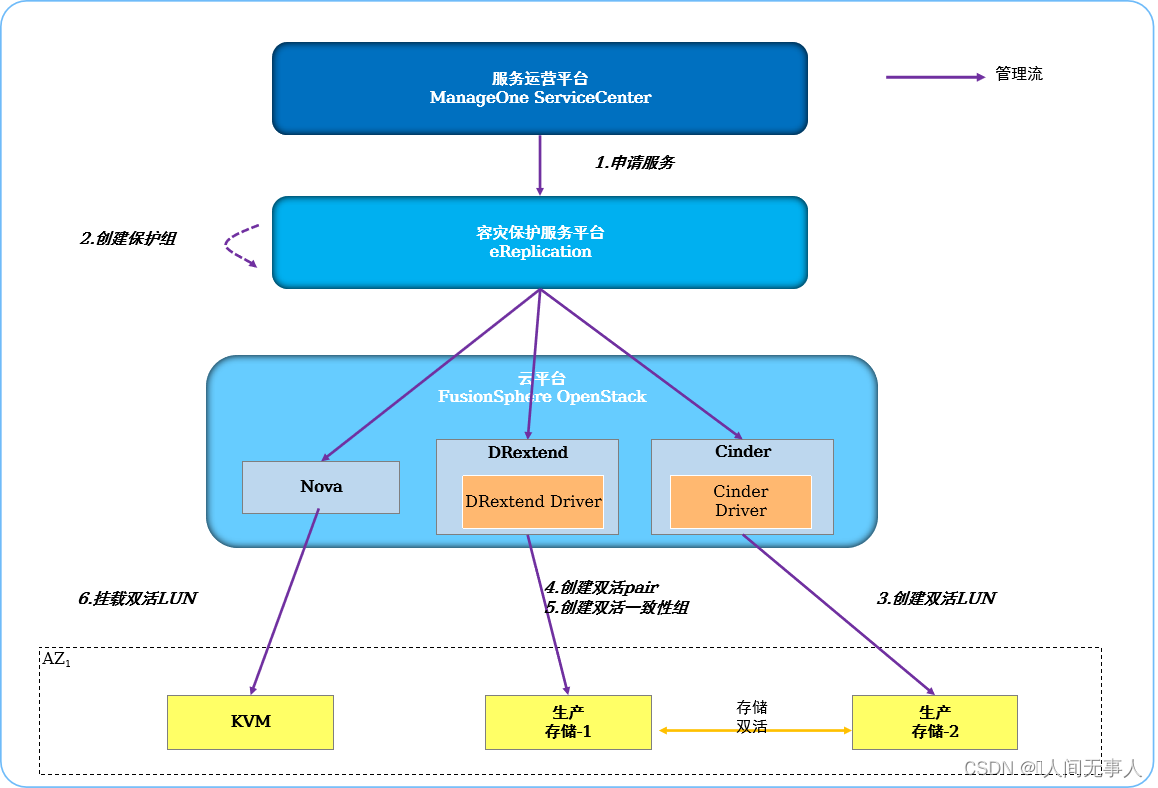
- VHA服务实现原理
- 1·VDC业务员申请VHA实例
- 2·BCManager eReplication收到创建容灾保护任务后,调用Nova API查询ECS/BMS所挂载的卷
- 3·BCManager eReplication调用Cinder API在对应的双活存储设备上创建双活从卷
- 4·BCManager eReplication调用DRExtend API创建主卷和从卷之间的双活Pair。将服务实例中所有的双活Pair加入到双活一致性组
- 5·BCManager eReplication调用Nova API,将创建的双活LUN挂载给ECS/BMS
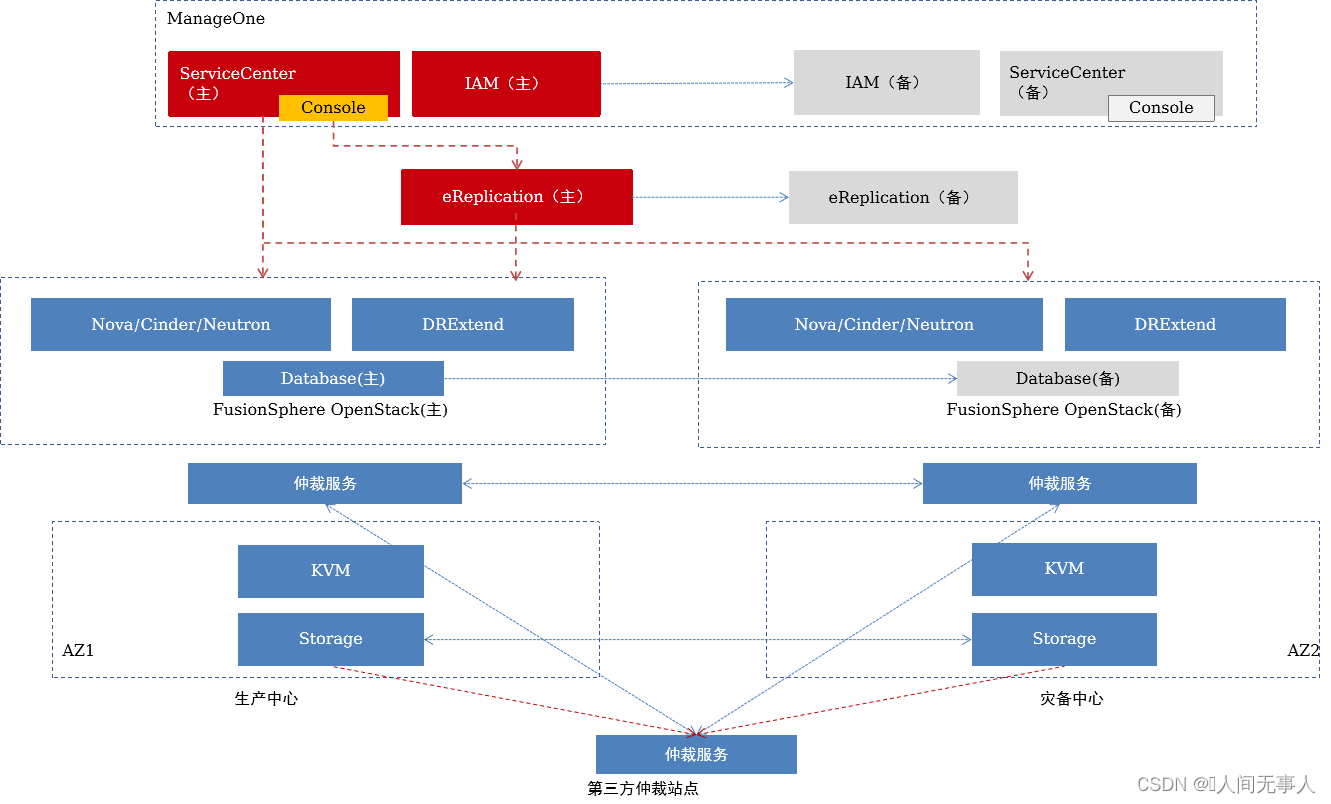
云服务器高可用服务(CSHA)
云服务器高可用服务(Cloud Server High Availability)为云服务器提供同城数据中心间的高可用保护。当生产中心发生灾难时,被保护的云服务器能够自动或手动切换到灾备中心
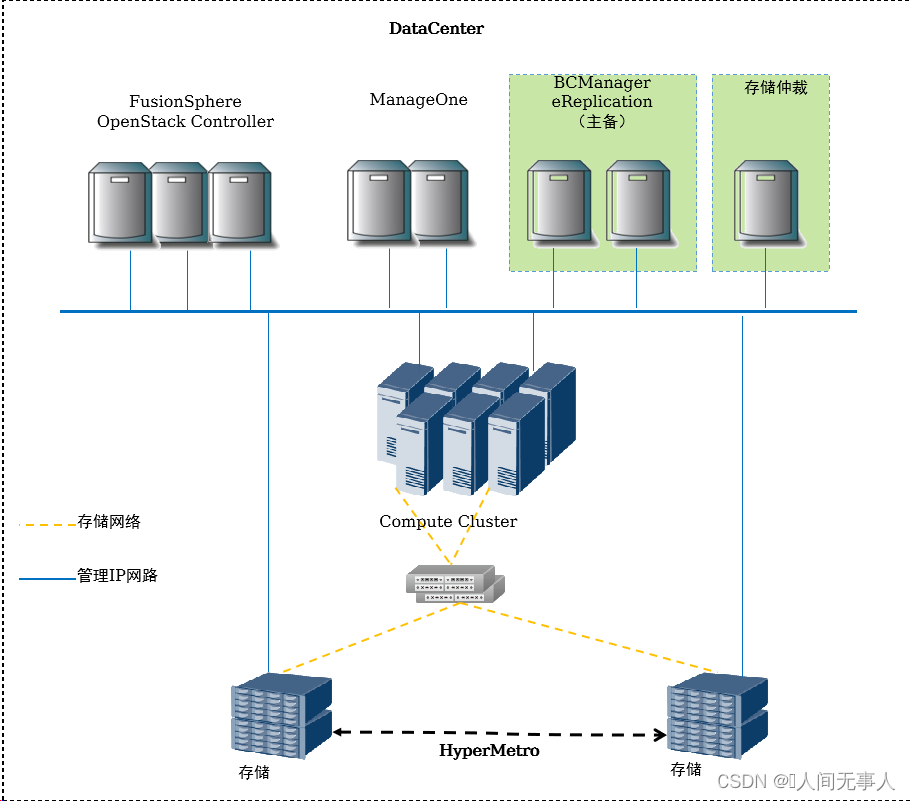
CSHA物理组网架构
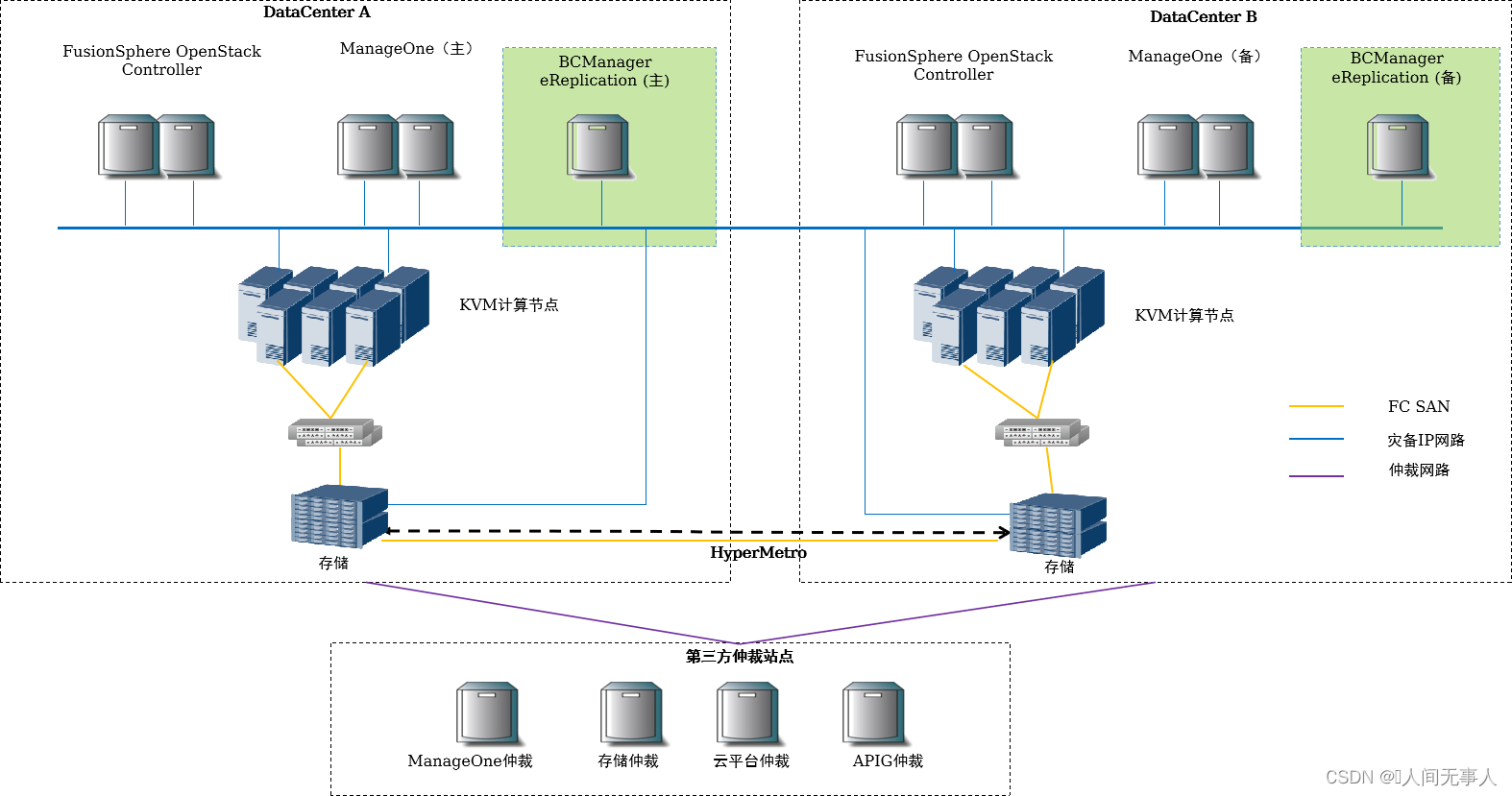
- FusionSphere OpenStack Controller:OpenStack管理节点
- ManageOne:华为云Stack统一运维管理平台
- BCManager eReplication:作为VHA服务器,接收VHA管理控制台的请求
- CSHA存储仲裁服务:CSHA存储仲裁服务为存储阵列HyperMetro双活,提供分裂时的仲裁检测服务。
- 部署方式:部署在Region层,部署在第三站点,支持物理服务器部署,也支持FusionCompute虚拟机部署
- 存储HyperMetro:支持租户针对一个或一组云服务器的所有卷进行一致性存储双活保护。单个存储故障,数据不丢失(RPO=0),提升存储可靠性;复制过程中不影响云服务器计算性能;无需感知VM内应用。支持的存储类型包括:Dorado V3/V6、OceanStor V3/V5,及FusionStorage Block
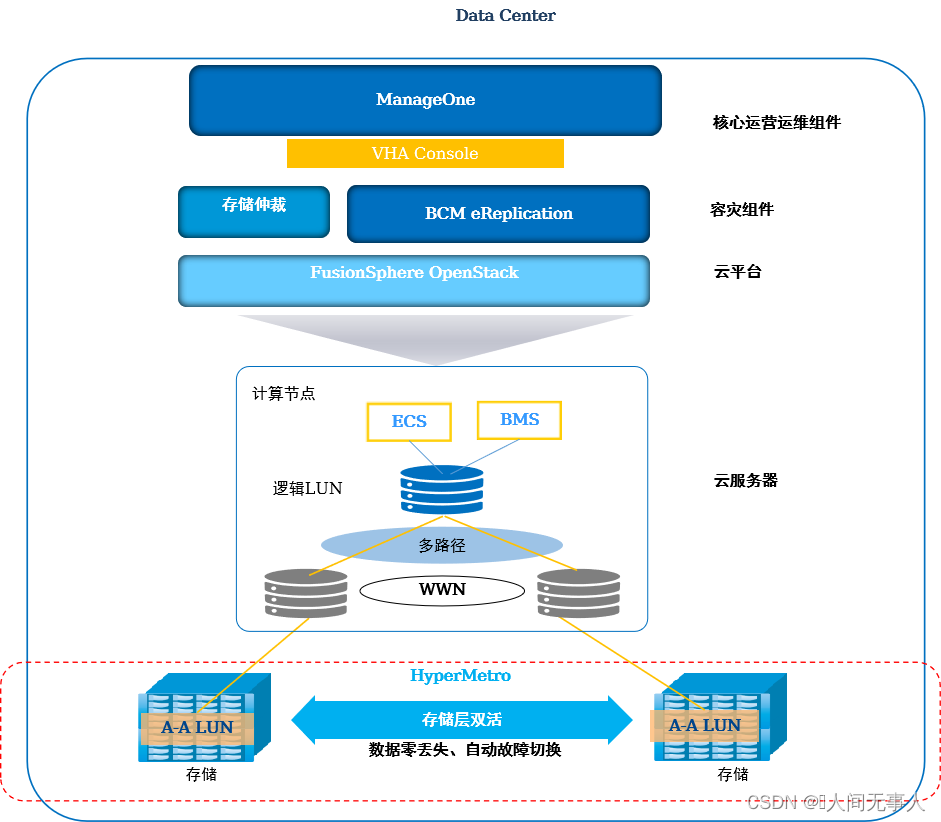
CSHA逻辑组网架构
-
规划阶段
- 只能对同一个Region内两个AZ间的云服务器提供高可用服务
- 不支持接管异构云服务器之后再实现云服务器高可用
- 云服务器高可用服务不支持为PCI直通网卡的云服务器提供容灾保护
-
服务申请阶段
- 单个云服务器或多个云服务器的云硬盘需要位于同一个存储设备。挂载同一共享盘的云服务器必须在同一CSHA服务中
- 同一云服务器,云服务器高可用服务和云服务器容灾服务只能二选一
- 只能管理云服务器,不能管理云服务器虚拟机中的应用
- 一个云服务器只能加入一个云服务器高可用服务实例
- 加入同一个CSHA服务实例中的多个云服务器必须属于同一个AZ
- 不允许删除和变更云高可用服务保护下的生产云服务器和容灾云服务器。变更包含变更属性和规格
- 不支持选择云服务器的部分云硬盘进行容灾保护。为高可用云服务器绑定新的云硬盘后,需要手工为云硬盘添加高可用保护
-
创建CSHA实例流程(申请后,后台自动完成):
- BCManager eReplication收到容灾保护创建任务后,首先它调用计算接口查询源端(Primary Cloud DC)VM所挂载的Volume数量,过滤出未构建双活保护的云服务器,并确定构建了双活关系的存储设备,然后BCManager eReplication 再调用计算管理接口与存储管理接口在对应的备端(Second Cloud DC)存储上创建与源端对应规格的云服务器、Volume数量和大小的存储LUN,最后BCManager eReplication调用存储容灾接口通过在源端云平台上和存储上创建双活Pair和双活一致性组的关系,形成云服务器的跨AZ的高可用关系
-
自动切换逻辑:
- 某个站点故障时:管理组件跨AZ高可用, OpenStack、ManageOne IAM、eReplication根据仲裁判断完成组件高可用切换(见管理组件跨AZ高可用)
- 自动切换模式下,eReplication根据以下三个条件,均满足时,开始切换对应的CSHA保护组实例,启动容灾VM:
- 云平台仲裁服务,显示某个AZ所在站点故障
- CSHA的生产VM所在AZ内所有主机均故障
- CSHA的容灾端阵列,HyperMetro复制状态为故障状态
- 容灾VM启动时间>=10分钟(基于20VM),并与VM数量成正比
CSHA服务组件间调用关系
关键技术 - 存储双活
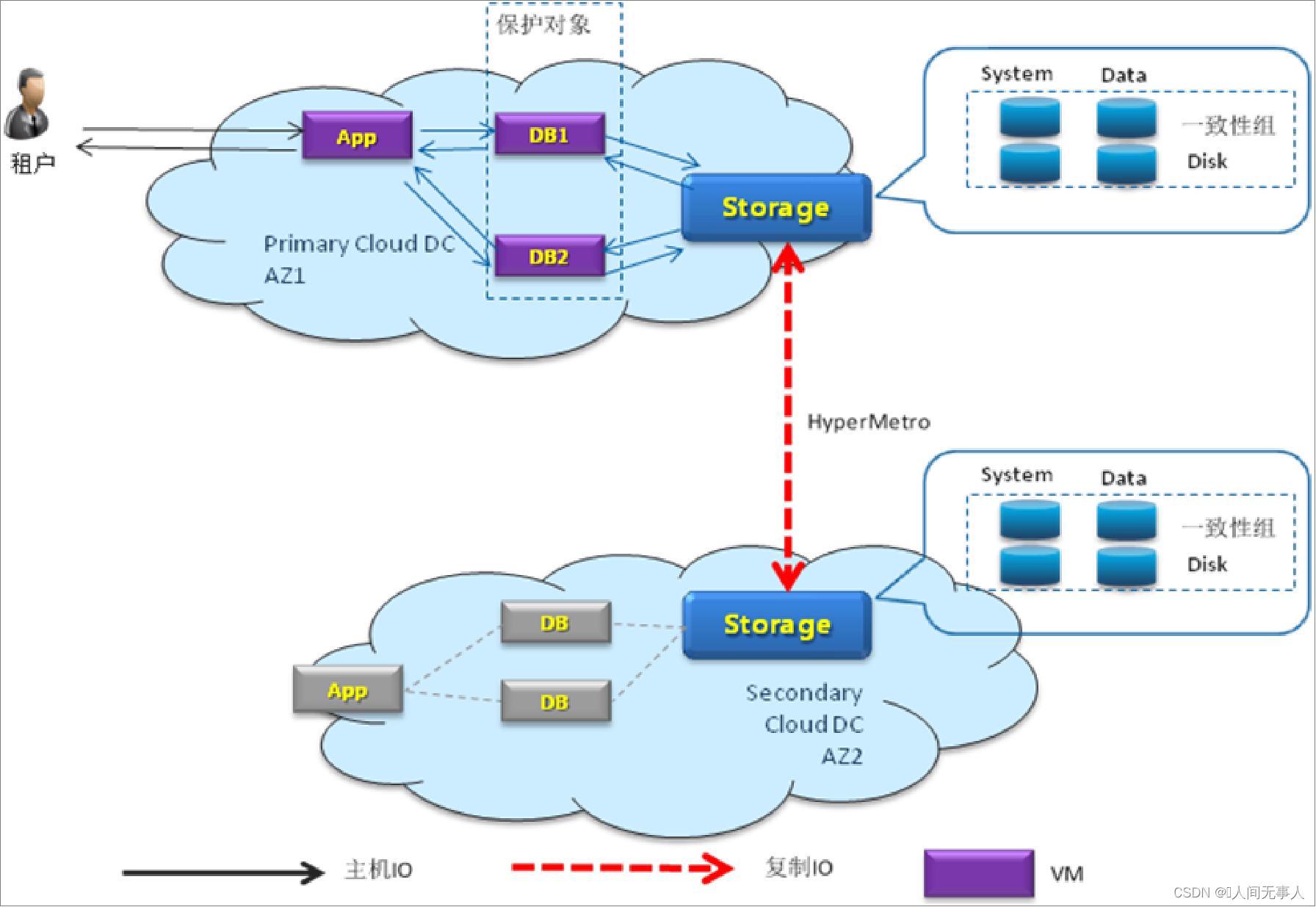
- 存储双活原理
-
在云数据中心,App和DB都运行于云服务器VM里,租户访问App,App生成的数据存储在DB里,通过云服务器VM将IO保存在存储设备中。在存储双活过程中,租户通过App将IO下发到DB,DB将IO下发到AZ1与AZ2的两台存储上,然后返回给主机,实现数据的实时镜像
-
在正常场景下,生产、容灾LUN均同时挂载于生产云主机;而容灾云主机不挂卷,因此不能启动
-
申请云服务器高可用CSHA的业务流
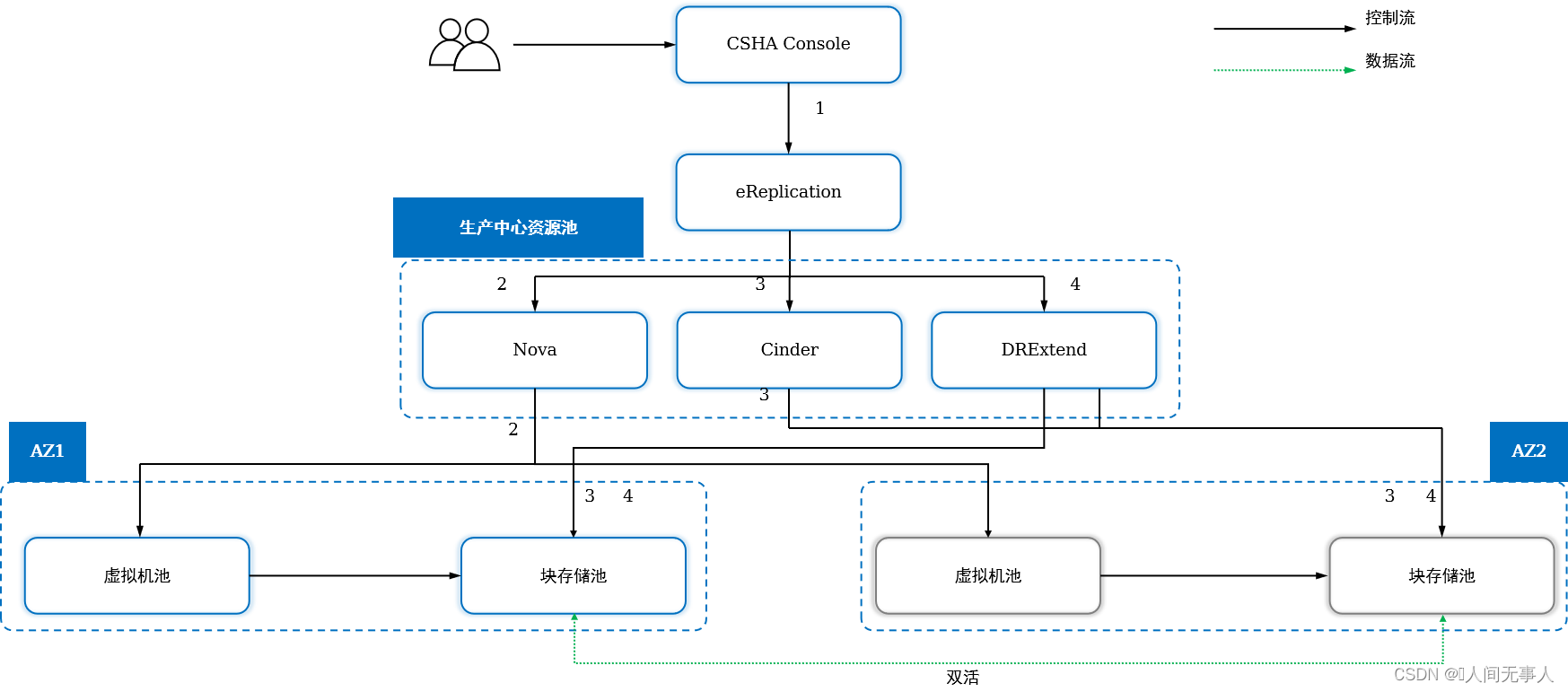
- 流程
-
- VDC业务员申请云服务器高可用服务实例。
-
- BCManager eReplication收到创建容灾保护任务后,调用Nova API查询AZ1云服务器所挂载的卷的数量。
-
- BCManager eReplication调用Cinder API在对应的双活存储设备上创建双活从卷,查询AZ1云服务器所挂载的卷的容量,并获取对应的存储设备信息。
-
- BCManager eReplication调用DRExtend API创建主卷和从卷之间的双活Pair。将服务实例中所有的双活Pair加入到双活一致性组。
-
- BCManager eReplication调用Nova API,将AZ2云服务器的系统卷卸载。
-
- BCManager eReplication调用Cinder API,将AZ2云服务器的系统卷删除。
-
云服务器高可用CSHA故障恢复的业务流
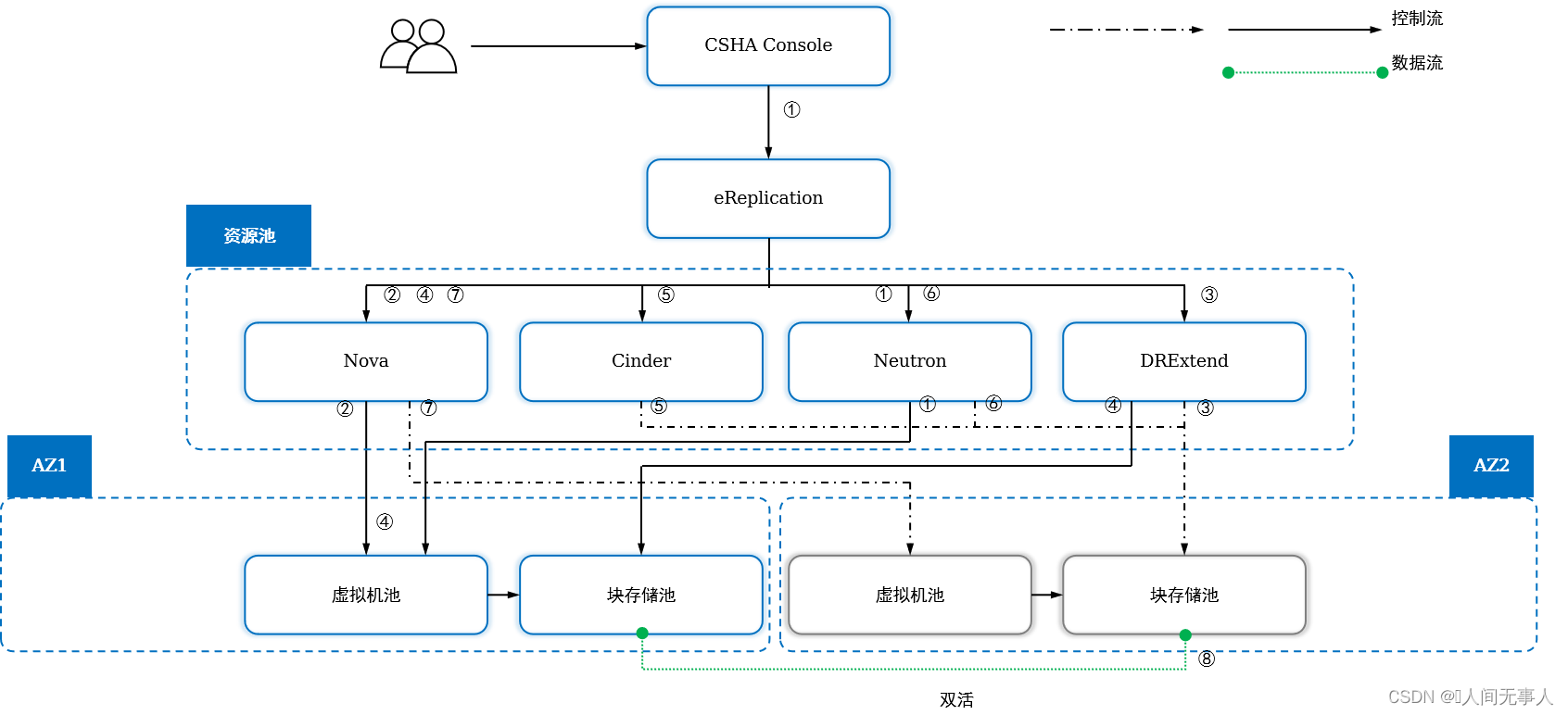
- Region Type I/ Type II场景下,网卡切换功能默认状态为关闭。故障恢复业务流不需要执行Neutron API卸载网卡和重新挂载网卡的动作。
-
- BCManager eReplication调用Neutron API卸载生产云服务器的网卡。
-
- BCManager eReplication调用Nova API关闭生产服务器。
-
- BCManager eReplication调用DRExtend API执行一致性组故障切换。
-
- BCManager eReplication调用Nova API配置容灾云服务器,解除容灾云服务器的占位标签。
-
- BCManager eReplication调用Cinder API把容灾云服务器的卷,挂载给容灾云服务器。
-
- BCManager eReplication调用Neutron将卸载的网卡重新挂载到容灾云服务器。
-
- BCManager eReplication调用Nova API启动容灾云服务器。
-
- BCManager eReplication重建保护组。
-
云服务器高可用实例创建原理
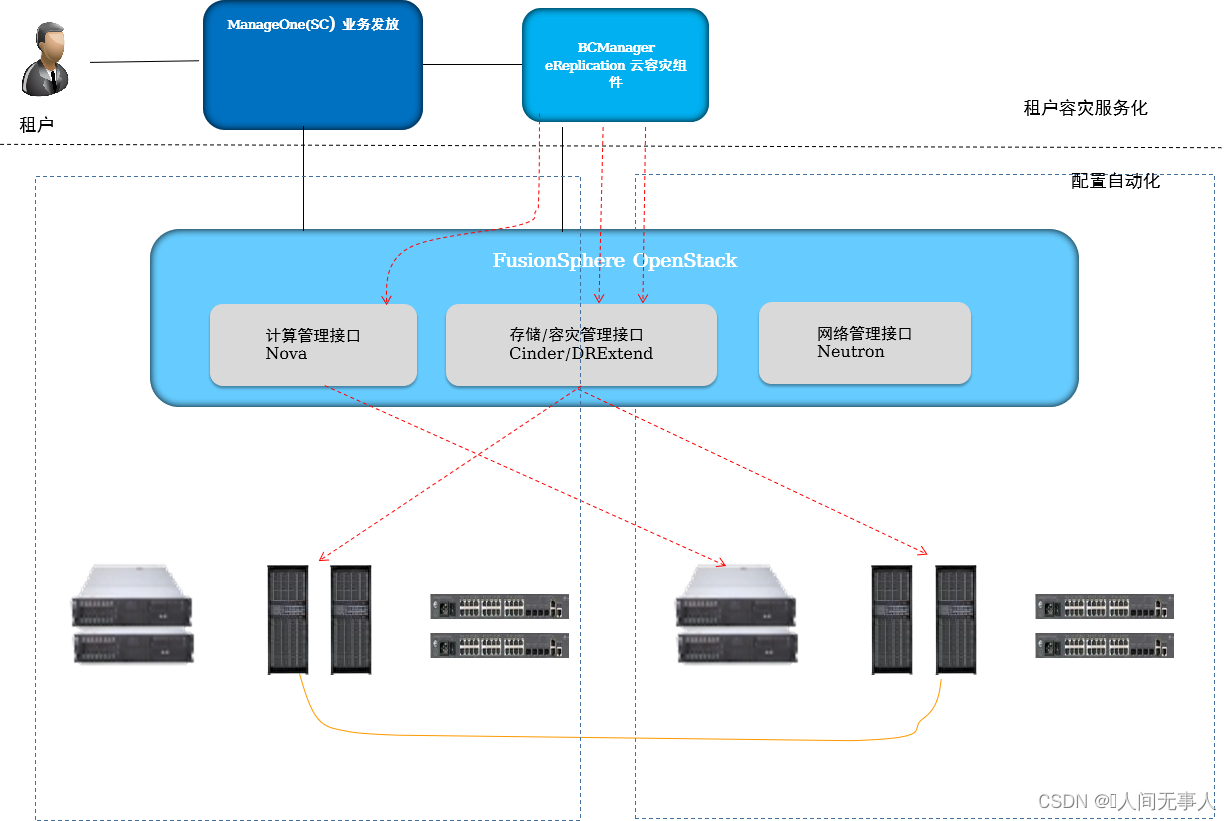
- 云服务器高可用实例创建
- 1·租户申请云服务器高可用实例
- 2·ManageOne下发实例创建命令到BCM
- 3·检查生产端以及容灾端的计算以及存储资源
- 4·检查生产云服务器
- 5·检查容灾云服务器
- 6·分配存储资源
- 7·创建容灾端卷
- 8·设置容灾端云服务器以及生产端云服务器容灾标签
- 9·执行初始数据同步
- 计划性迁移实现
- 1·租户向容灾维护管理员申请计划性迁移
- 2·容灾维护管理员下发计划性迁移命令
- 3·关闭、锁定生产端云服务器
- 4·卸载、锁定生产端主机卷
- 5·DRExtend暂停双活一致性组
- 6·BCM调用Nova,取消容灾端云服务器锁定状态,取消保留从卷,将主、从卷挂载到容灾云服务器
- 7·解锁、启动容灾云服务器
- 8·将生产端云服务器设置为占位云服务器,调换生产以及容灾云服务器的容灾标签,并创建双活容灾关系
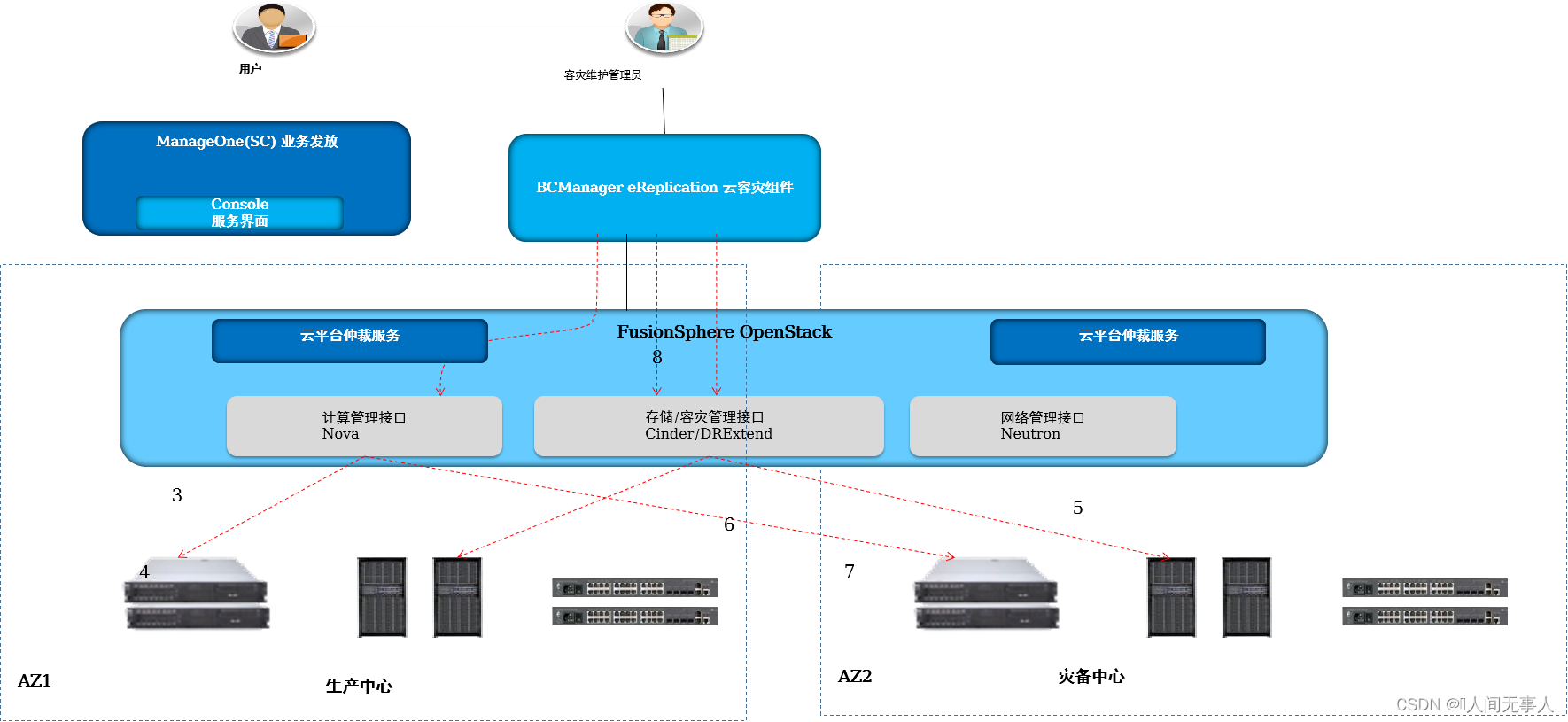
故障切换实现原理
- 故障切换实现
- 1·DC故障,云平台仲裁服务判断站点故障
- 2·BCM查询仲裁结果,并做切换前检查
- 3·检查生产端计算、存储复制链路状态
- 4·检查生产端服务器集群状态
- 5·暂停存储双活
- 6·挂载从卷
- 7·解锁、启动容灾云服务器
- 8·将生产端云服务器设置为占位云服务器,调换生产以及容灾云服务器的容灾标签,并创建双活容灾关系
故障切换实现原理
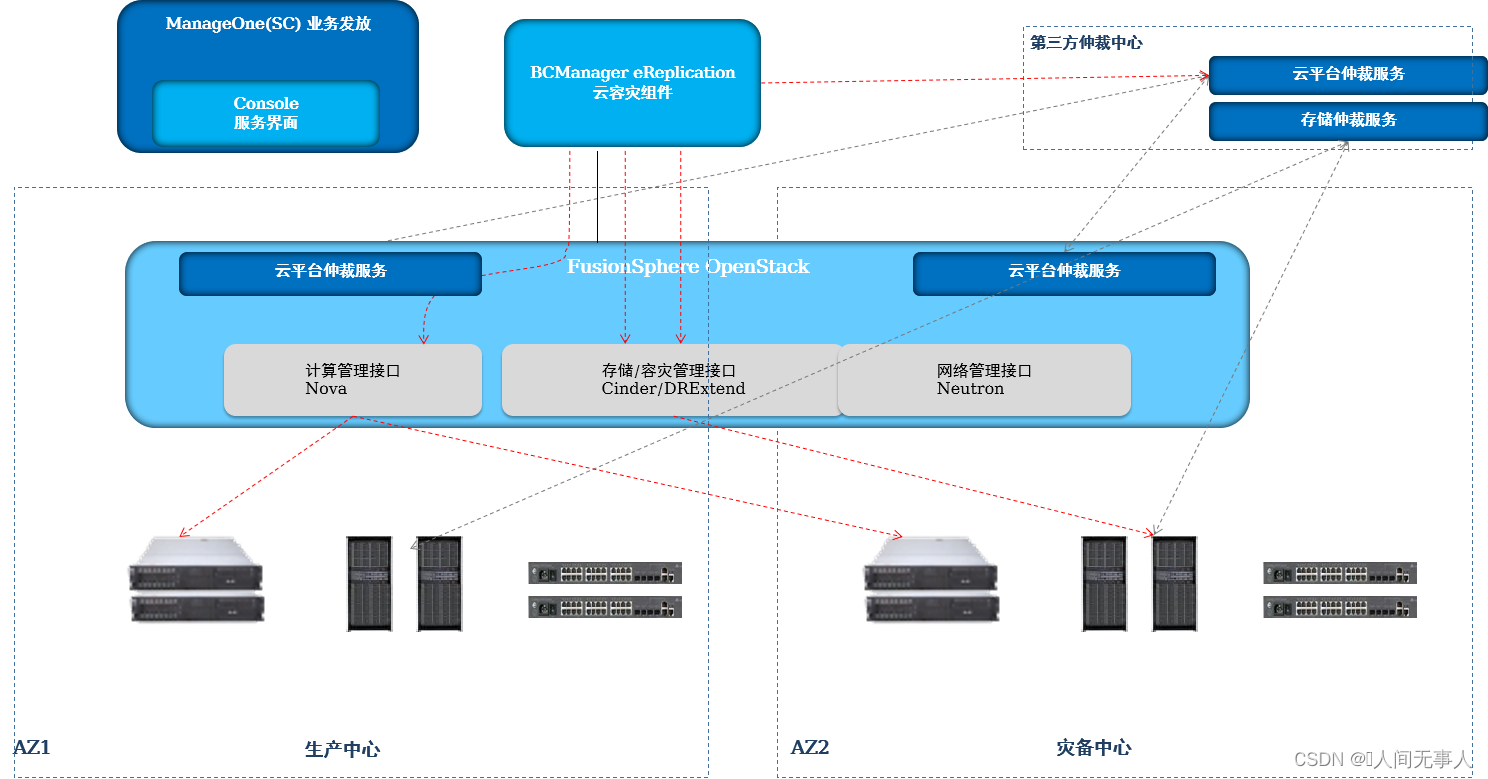
- 故障切换实现
- 1·DC故障,云平台仲裁服务判断站点故障
- 2·BCM查询仲裁结果,并做切换前检查
- 3·检查生产端计算、存储复制链路状态
- 4·检查生产端服务器集群状态
- 5·暂停存储双活
- 6·挂载从卷
- 7·解锁、启动容灾云服务器
- 8·将生产端云服务器设置为占位云服务器,调换生产以及容灾云服务器的容灾标签,并创建双活容灾关系
重保护实现原理
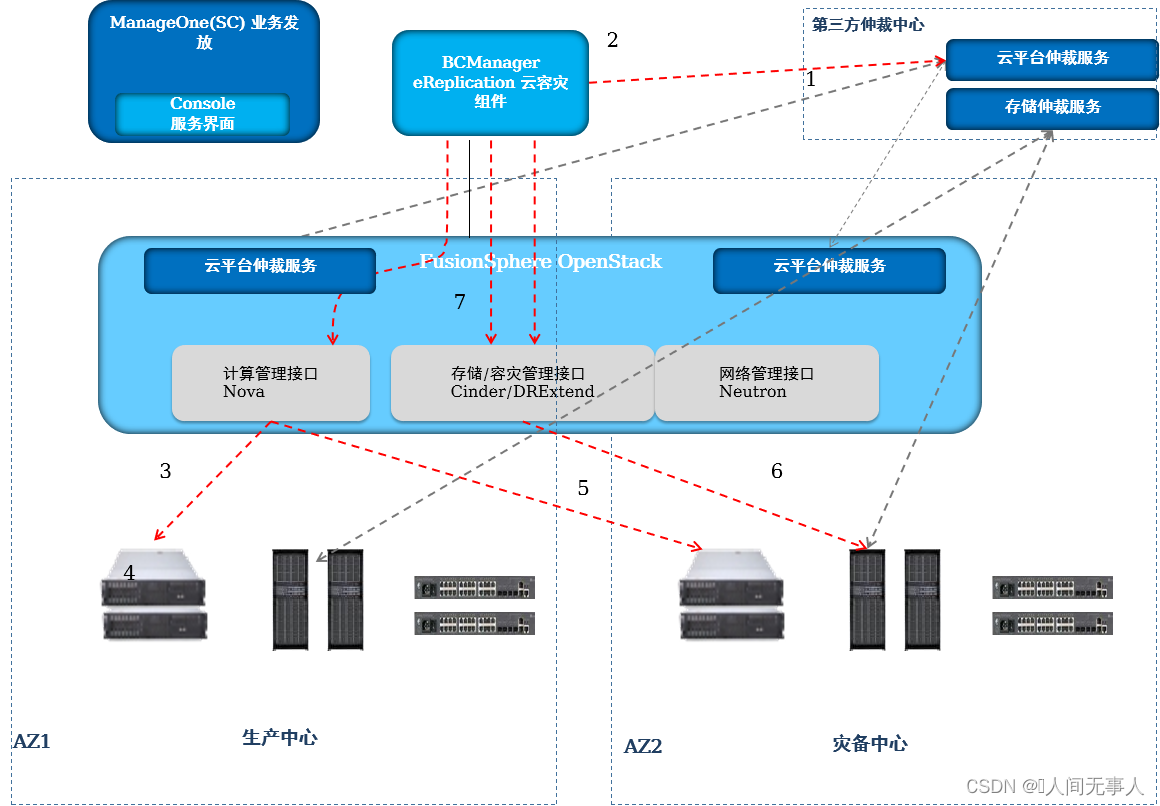
- 重保护实现原理
- 1·DC故障,云平台仲裁服务判断站点故障
- 2·BCM查询仲裁结果,并做切换前检查
- 3·检查生产端计算、存储复制链路状态
- 4·检查生产端服务器集群状态
- 5·暂停存储双活
- 6·挂载从卷
- 7·解锁、启动容灾云服务器
- 8·将生产端云服务器设置为占位云服务器,调换生产以及容灾云服务器的容灾标签,并创建双活容灾关系
关键技术 - 自动故障切换
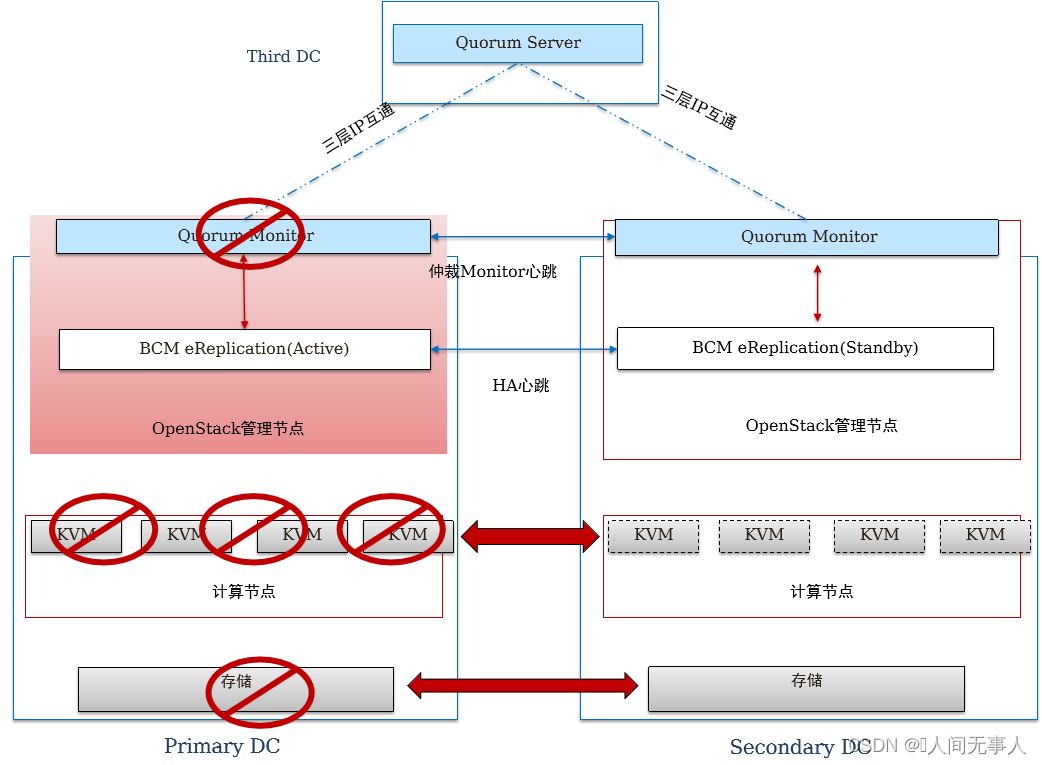
- 自动故障切换原理
-
1、灾备组件BCManager eReplication实时监控站点间仲裁状态,若某一站点仲裁全部故障,则会触发BCManager eReplication对整站点的状态检查
-
2、以每个CSHA实例为单位,依次检查各实例所在存储的复制链路状态及AZ下全部计算节点的状态,若全部为故障状态,则判定为整站点故障,触发自动切换;否则判定为局部故障,不触发自动切换
-
局部故障场景下,用户可通过手动故障切换的方式把业务虚拟机切换到容灾站点
-
云服务器容灾服务(CSDR)
云服务器容灾服务(CSDR,Cloud Server Disaster Recovery)为ECS和BMS提供异地容灾保护。当生产中心发生灾难时,可在异地灾备中心恢复受保护的ECS/BMS
此外,弹性云服务器和裸金属服务器还可以配置本地存储双活保护,当生产中心单套存储设备发生故障时,数据零丢失,业务不中断
CSDR物理组网架构
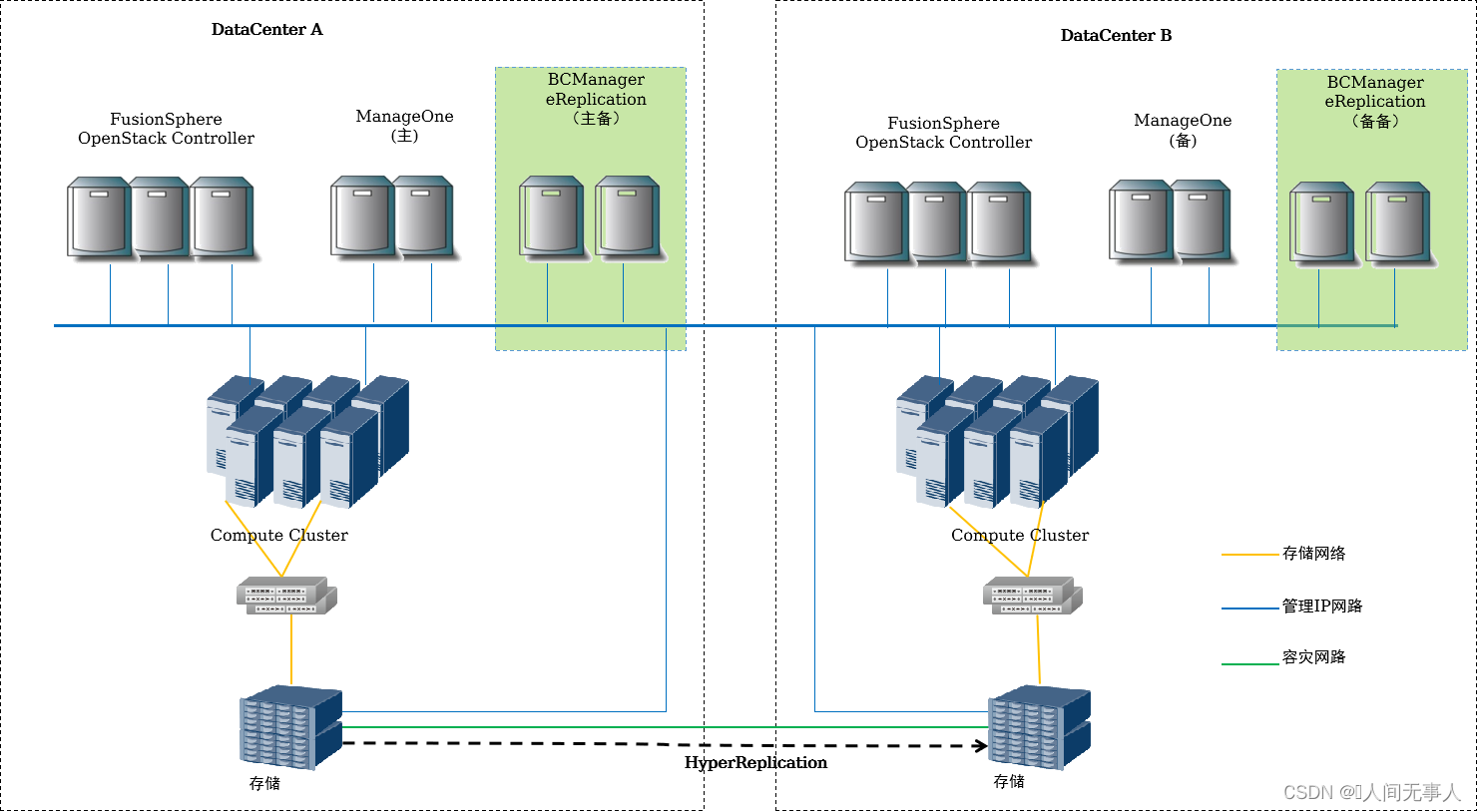
- BCManager eReplication组件,采用虚拟机部署;CSDR Console已合并到ManageOne中,不需单独部署虚拟机。
- 对于Global管理组件需部署跨Region主备容灾。
- 对于生产Region和容灾Region间的存储需配置远程复制。支持的存储类型包括:OceanStor V3/V5、Dorado V3/V6、FusionStorage Block。
- 若要部署存储环形容灾,则需要至少三套存储:即生产AZ部署两套存储,异地容灾AZ部署一套存储。支持的存储类型包括:OceanStor V3/V5、Dorado V3/V6,不支持FusionStorage Block。
- 场景说明:
- 同步复制要求:建议距离<100公里,RTT<2ms(存在数据库容灾时建议<1ms)
- 异步复制要求:建议距离<3000公里,RTT<100ms
- FusionStorage场景说明:一套FusionStorage只支持与另外一套配置异步复制,暂不支持多对一。也即针对Region数量大于2个的N:1容灾场景,容灾Region需相应的配置多套存储,并规划多个AZ,分别与各生产Region内的生产存储配置容灾关系。
- 环形容灾(本地存储双活+异地复制)说明:生产AZ部署两套存储,异地容灾AZ部署一套存储,三套存储配置环形容灾。数据中心内存储双活,单个存储故障,数据不丢失,业务不中断;数据中心间仅支持存储异步复制(最小复制周期为5分钟),不支持同步复制。复制过程不影响云服务器计算性能。
CSDR逻辑组网架构
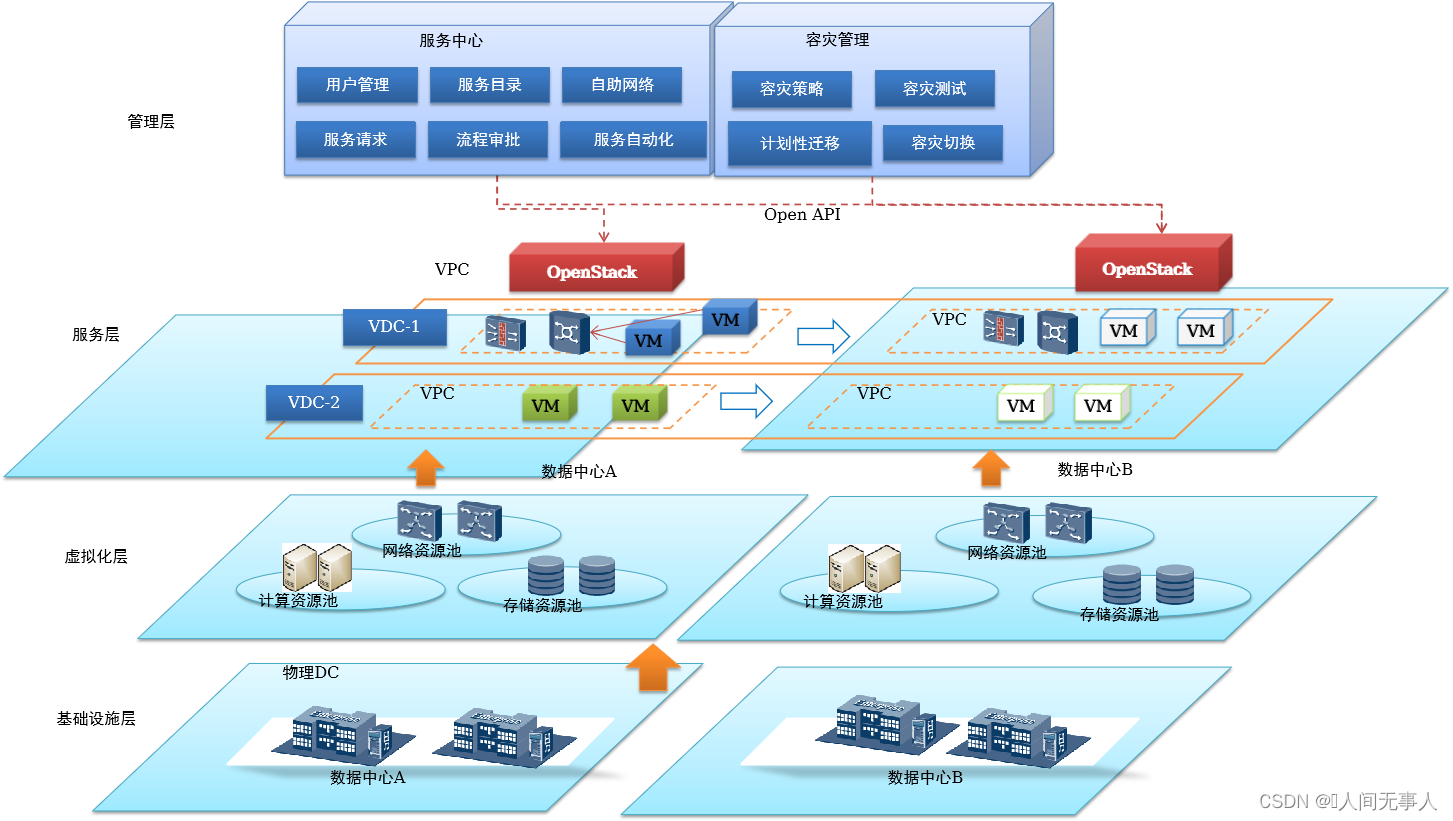
- 基础架构层
- 物理数据中心的计算、存储、网络资源。虚拟化层。
- 实现计算、存储、网络虚拟化资源池,由华为FusionSphere统一管理。
- 服务层
- 融合各个物理DC的统一资源池,形成跨DC的全局统一资源池,基于该资源池提供按需分配的资源服务:
- VDC服务:基于VDC的形式,将全局统一资源池内的计算、存储、网络资源灵活分配给不同租户,不同部门或业务域,用户等同于获得了一个独立的DC。VDC内的资源可以跨多个可用域(AZ)及Region,当VDC内某个可用域及Region的计算资源故障,其他可用域与Region的计算资源不受影响。
- VDC内云服务:VDC内部,基于服务的形式,管理员可以将VDC内资源分配给VDC用户。服务类型包括云服务器、云磁盘、云服务器容灾、弹性IP等服务。
- 管理层
- ManageOne为服务层提供的服务提供运营管理,包括服务目录管理、服务申请、服务实例管理、用户管理和灾备服务管理等。
- 容灾管理(BCManager eReplication)为容灾提供一键式管理功能,包括容灾创建、容灾测试、计划性迁移和一键式灾难切换。
CSDR实现原理
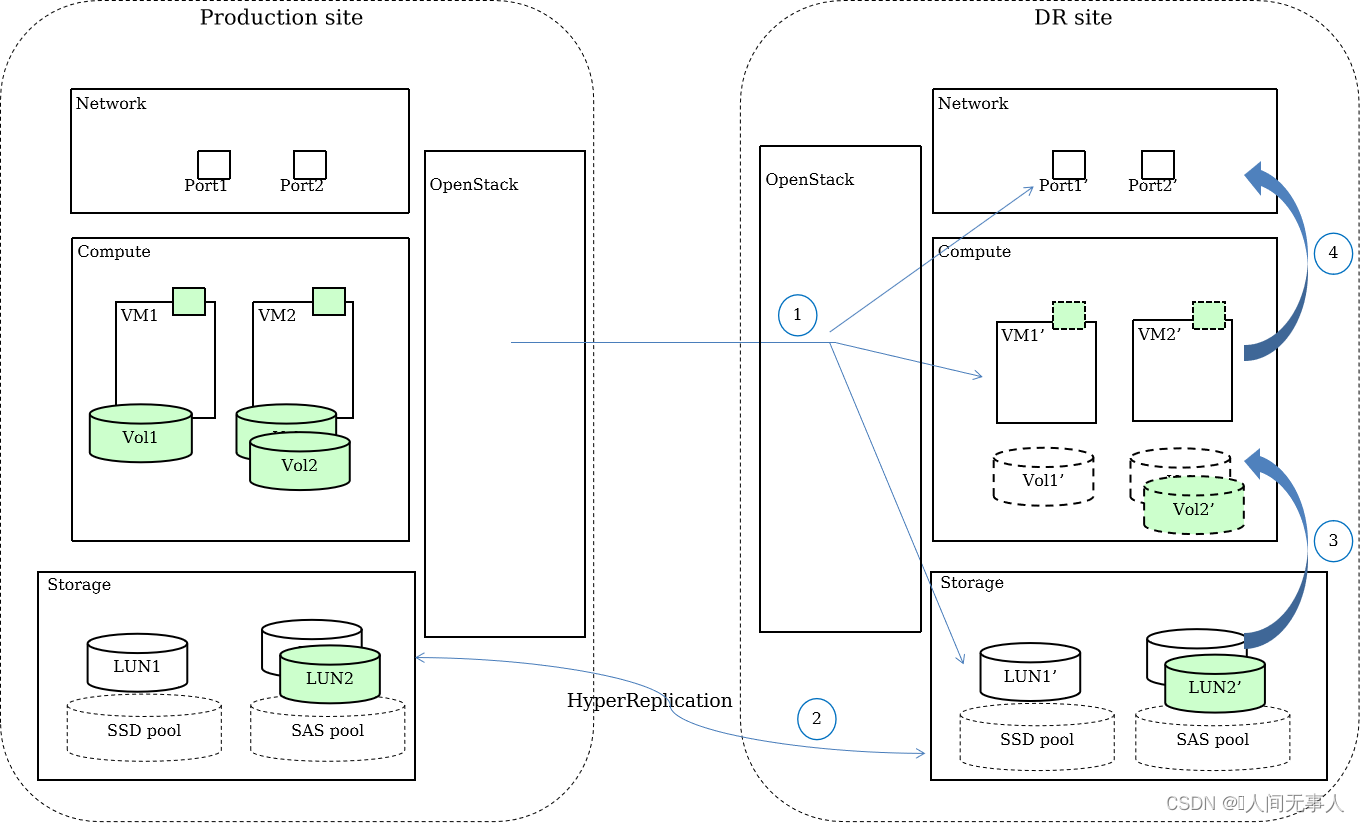
- 根据生产中心网络、计算、存储等资源类型及容灾要求,在灾备中心配置相同或相似的网络、计算、存储资源。当生产云服务器需要配置容灾保护时,系统在灾备中心创建对应的云服务器,网络和磁盘资源。
- 根据生产中心和灾备中心的磁盘对应信息,在存储层创建远程复制,实现数据的同步或者异步的容灾保护。
- 当生产中心因为各种故障和灾难的发生,无法继续提供云服务器访问,通过启用被保护的磁盘挂接给灾备云服务器,启用灾备数据。
- 启动灾备站点的网卡,挂载给灾备云主机,完成灾难恢复。
CSDR管理组件交互流程
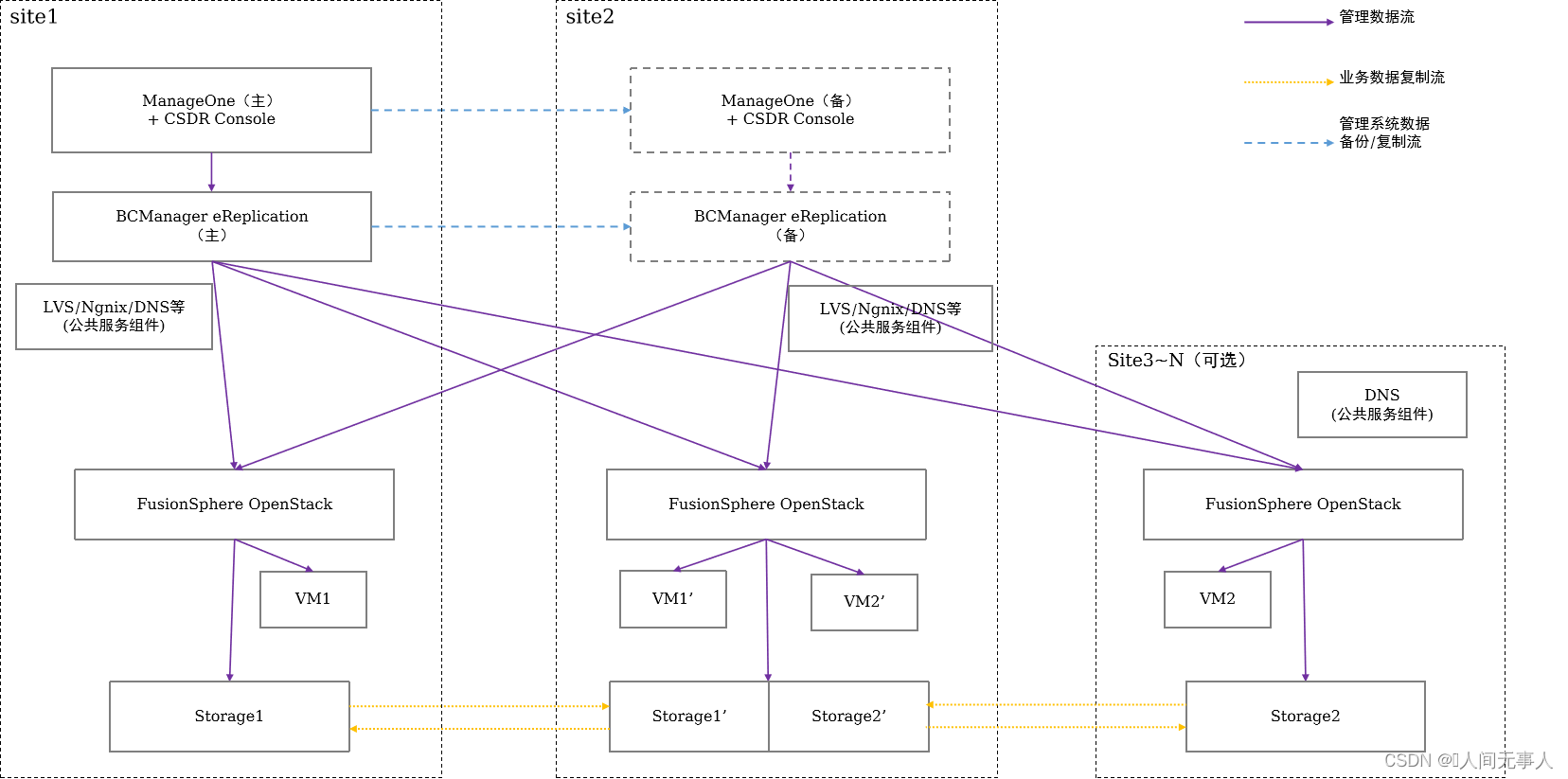
- 组件交互说明:
- ManageOne与CSDR Console通过下发指令到OceanStor BCManager eReplication调用不同数据中心的OpenStack相关组件进行业务服务(包括ECS、EVS等)的创建
- 业务数据流量存储于底层存储设备中,不同数据中心通过HyperReplication将业务数据进行复制
管理面跨Region容灾:一键式切换主备管理面,业务灵活接管,支持主备互换
- 存储复制:
- CSDR场景,支持同步复制(RPO=0)与异步复制(企业SAN最小复制周期为5分钟);
- VHA+CSDR场景,基于存储环形容灾,数据中心内存储双活,单个存储故障,数据不丢失,业务不中断;数据中心间存储异步复制(最小复制周期为5分钟)
- 复制过程不影响云服务器计算性能,不感知VM内应用,支持的存储类型包括:OceanStor V3/V5, Dorado V3、 Dorado V6(异步复制)及FusionStorage Block (仅异步复制,不支持VHA)
CSDR容灾测试切换原理流程
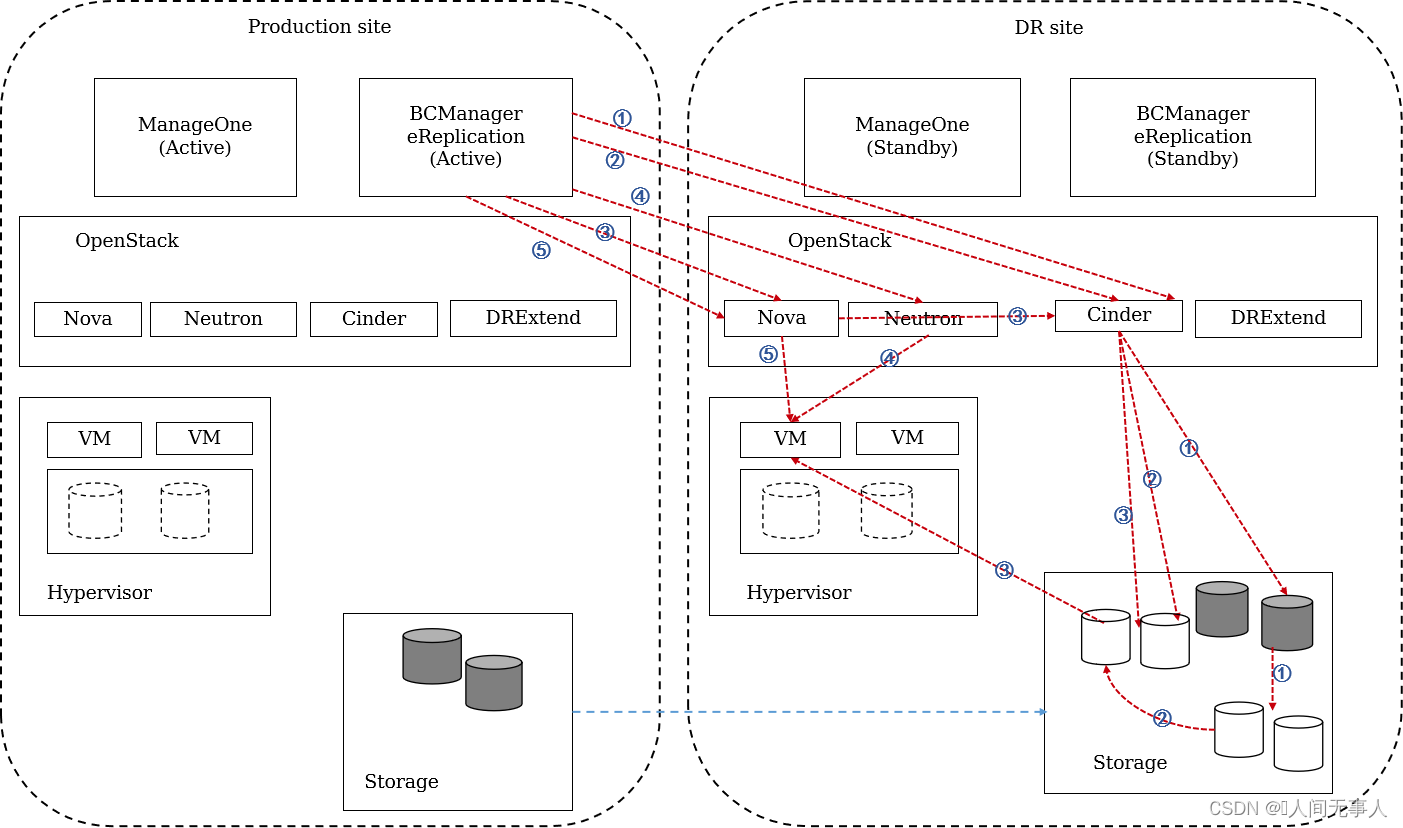
- 容灾系统测试流程如下:
- 在租户点击容灾测试时,可以选择是否同步数据。如果选择了同步数据,数据同步完成之后才会执行如下操作:
- ① eReplication调用OpenStack Cinder接口为服务实例中的所有占位卷逐个创建快照。Cinder driver调用存储执行LUN的未激活快照,阵列上完成未激活snapshot操作后,一致性激活创建的所有快照。
- ② eReplication调用OpenStack Cinder接口根据快照创建克隆卷,driver调用存储完成克隆卷的创建。
- ③ eReplication将克隆卷挂载给占位(容灾)云服务器,调用OpenStack Nova接口实现挂卷操作。
- ④ eReplication调用OpenStack Neutron接口禁用虚拟机中的容灾恢复网络,启用租户配置的测试网络。
- ⑤ eReplication调用Nova接口启动云服务器并接入测试网络。
CSDR计划性迁移原理流程
-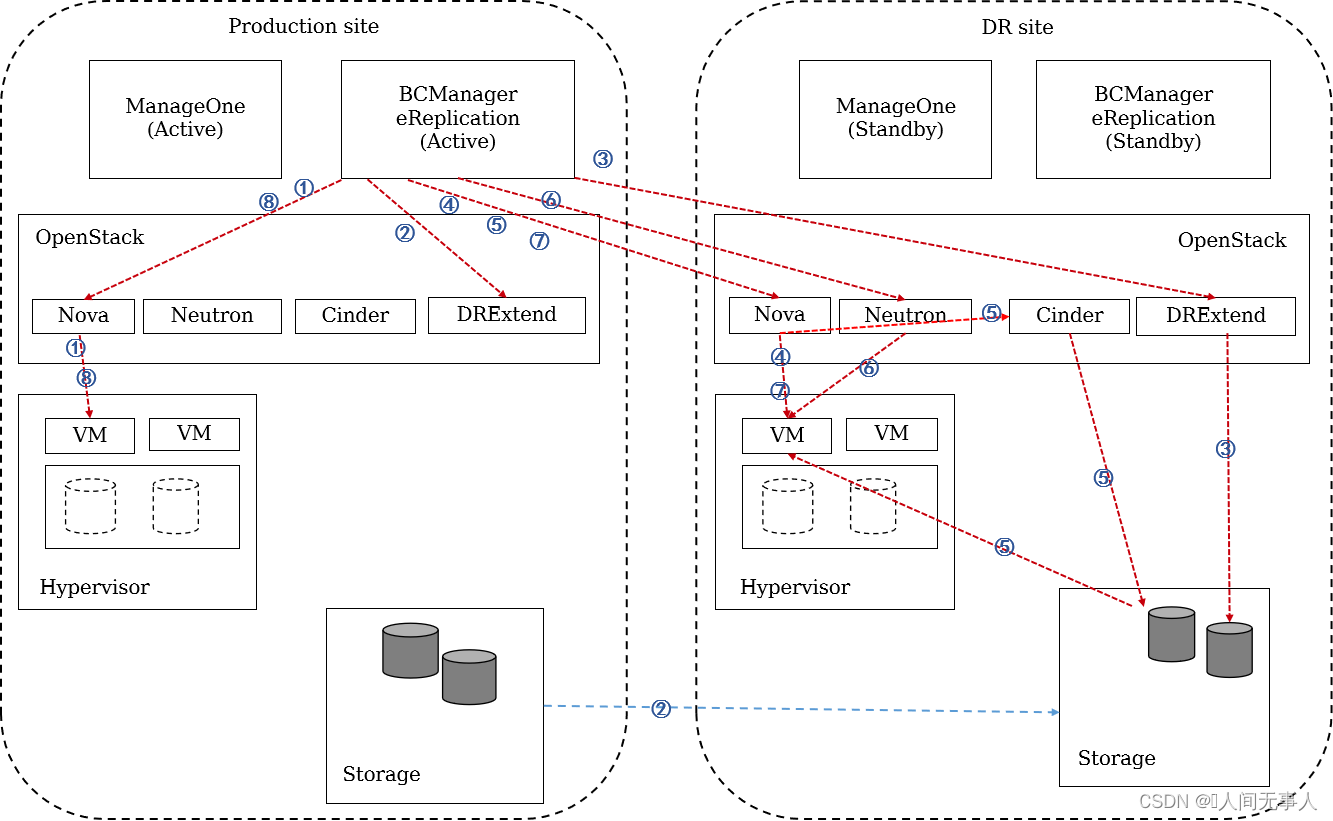
- 计划性迁移由管理员登录BCManager eReplication来进行操作,计划性迁移流程如下:
- ① eReplication调用生产中心OpenStack Nova接口停止生产云服务器,Nova Driver调用虚拟化平台完成云服务器关机。
- ② eReplication调用生产中心的OpenStack DRextend接口启动存储复制。
- ③ eReplication调用灾备中心OpenStack DRextend接口启用灾备卷资源,DRextend Driver调用存储执行备端读写操作。
- ④ eReplication调用灾备中心OpenStack Nova接口设置占位虚机为正常虚机。
- ⑤ eReplication调用灾备中心OpenStack Nova将备端磁盘挂接给云服务器,Nova通过Cinder驱动完成存储的LUN映射和挂接。
- ⑥ eReplication调用灾备OpenStack Neutron禁用测试网络,启用容灾恢复网络。
- ⑦ eReplication调用灾备OpenStack Nova执行云服务器启动并接入容灾网络。
- ⑧ eReplication 调用生产中心的OpenStack Nova 执行卸载原生产云服务器的卷,并锁定原生产云服务器。
- 计划性迁移之后需要管理员进行重保护,重保护的流程如下:
- ① eReplication调用原生产中心Nova接口关闭原生产虚拟机,并卸载原生产卷。
- ② eReplication调用原生产中心的Nova接口锁定原生产虚拟机。
- ③ eReplication调用DRextend接口配置阵列主从切换,启动数据同步。
CSDR云服务器故障切换原理流程
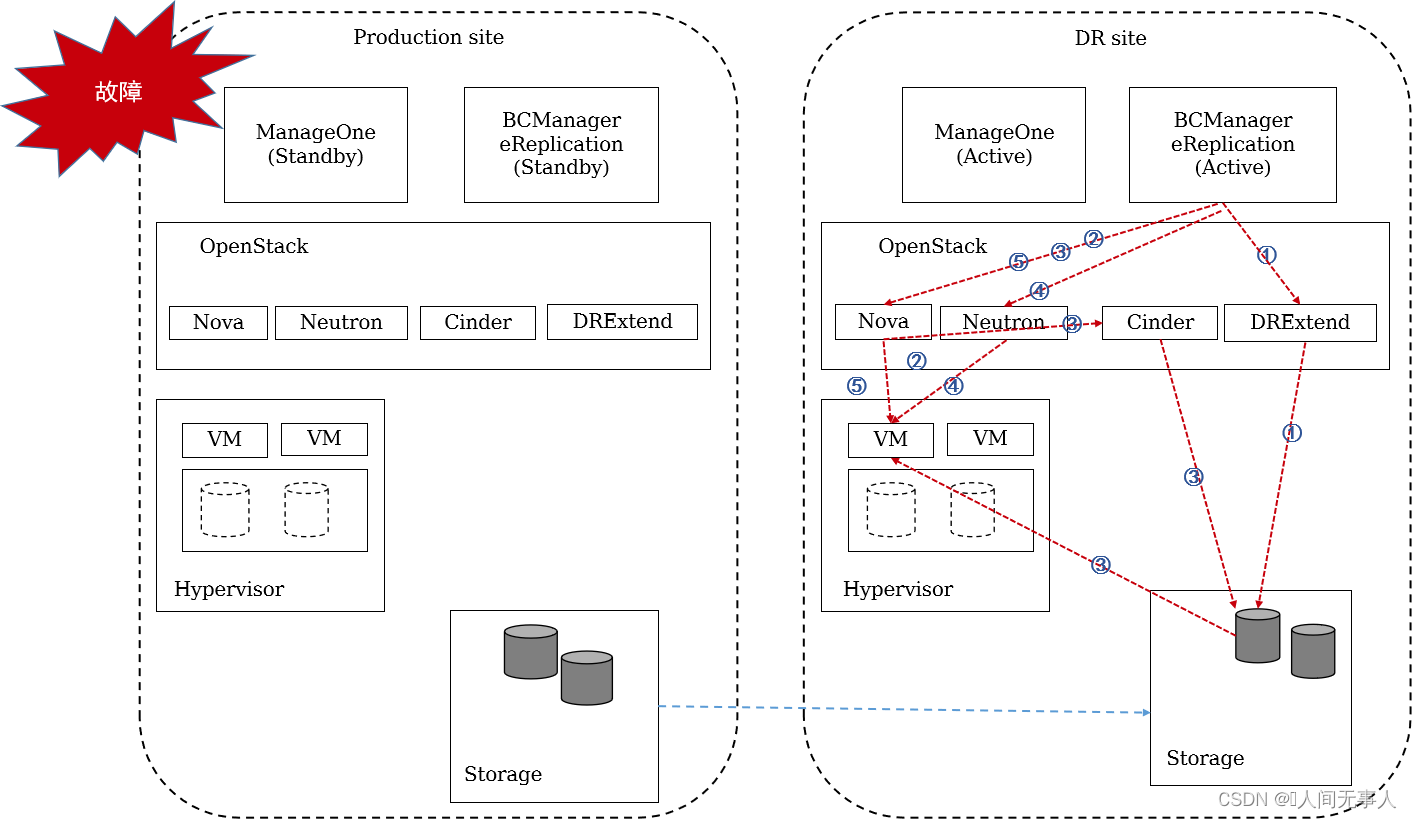
- 当生产中心故障,eReplication将不需要调度生产中心OpenStack进行停机操作,直接操作灾备中心的OpenStack进行灾备云服务器恢复。由管理员登录BCManager eReplication来进行操作,容灾切换流程如下:
- ① eReplication调用灾备中心OpenStack DRextend接口启用灾备卷资源,DRextend Driver调用存储执行备端读写操作。
- ② eReplication调用灾备中心OpenStack Nova接口设置占位虚拟机为正常虚拟机。
- ③ eReplication调用灾备中心OpenStack Nova将备端云硬盘挂接给云服务器,Nova通过Cinder驱动完成存储的LUN映射和挂载。
- ④ eReplication调用灾备中心OpenStack Neutron禁用测试网络,启用容灾恢复网络。
- ⑤ eReplication调用灾备OpenStack Nova执行云服务器启动并接入容灾网络。
- 容灾切换之后,如果生产站点修复,需要管理员进行重保护,重保护的流程如下:
- ① eReplication调用原生产中心的Nova接口关闭原生产虚拟机,并卸载原生产卷。
- ② eReplication调用原生产中心的Nova接口锁定原生产虚拟机。
- ③ eReplication调用DRextend接口配置阵列主从切换,启动数据同步。
灾备方案架构介绍
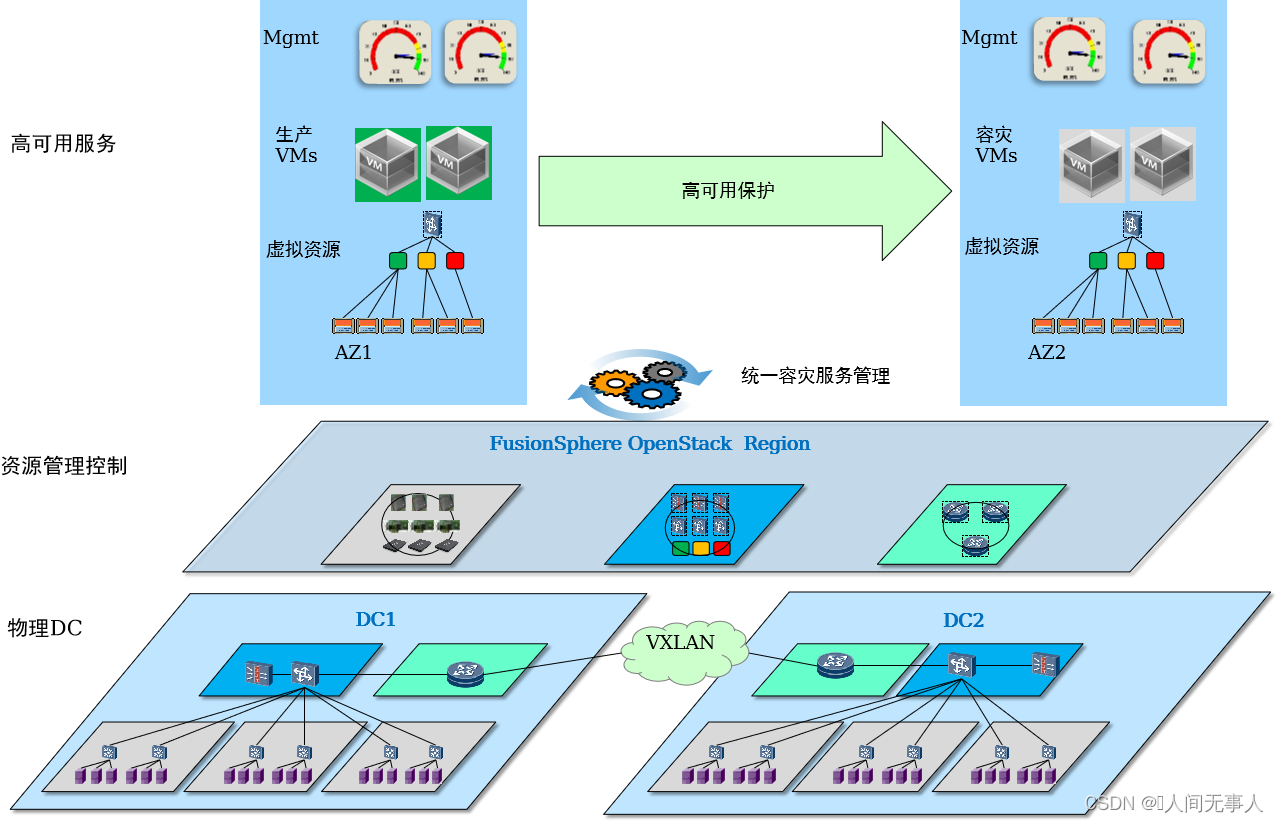
云容灾架构总览
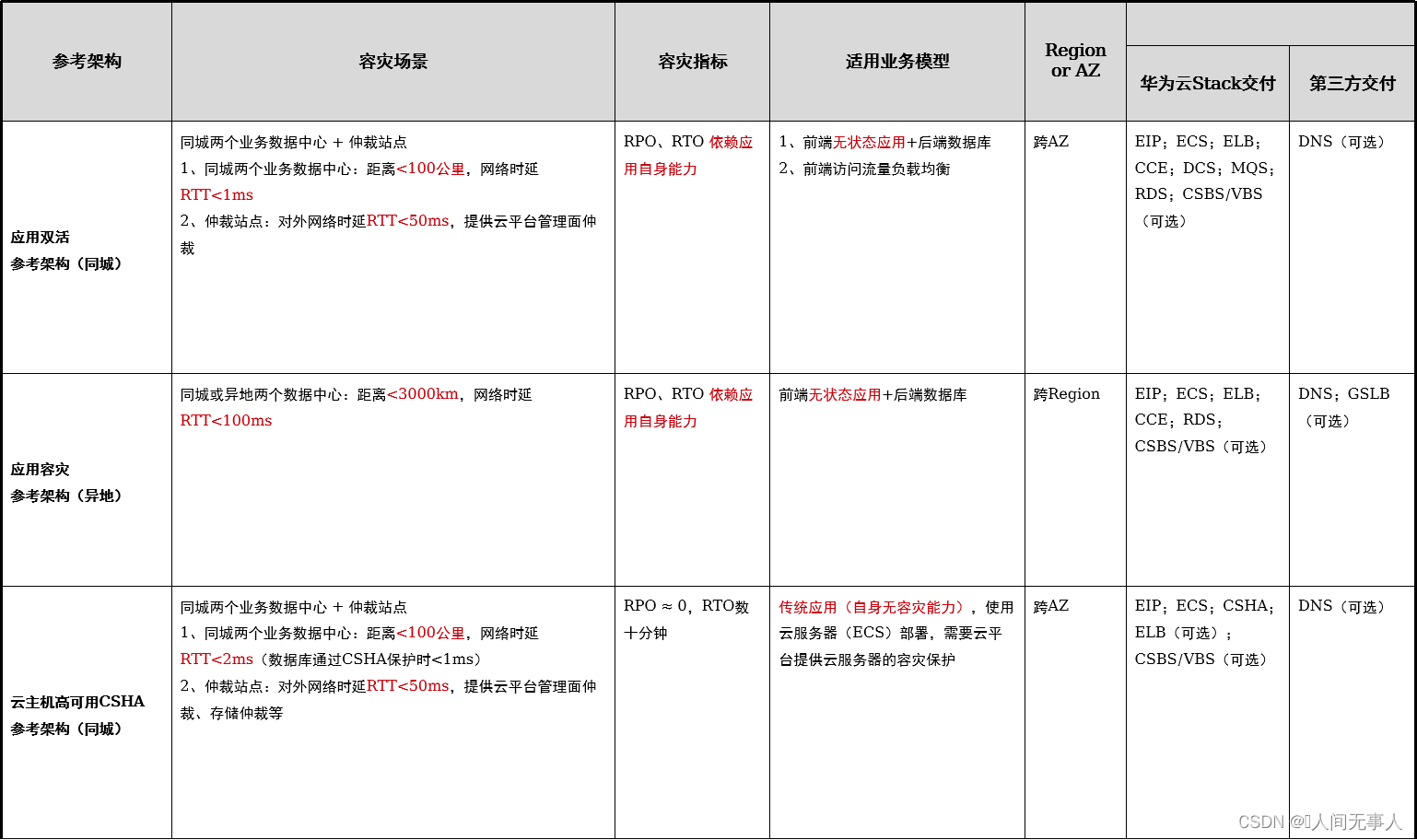
- 云容灾架构总览
- 应用双活
- 应用容灾
- 云主机高可用CSHA
云容灾架构总览
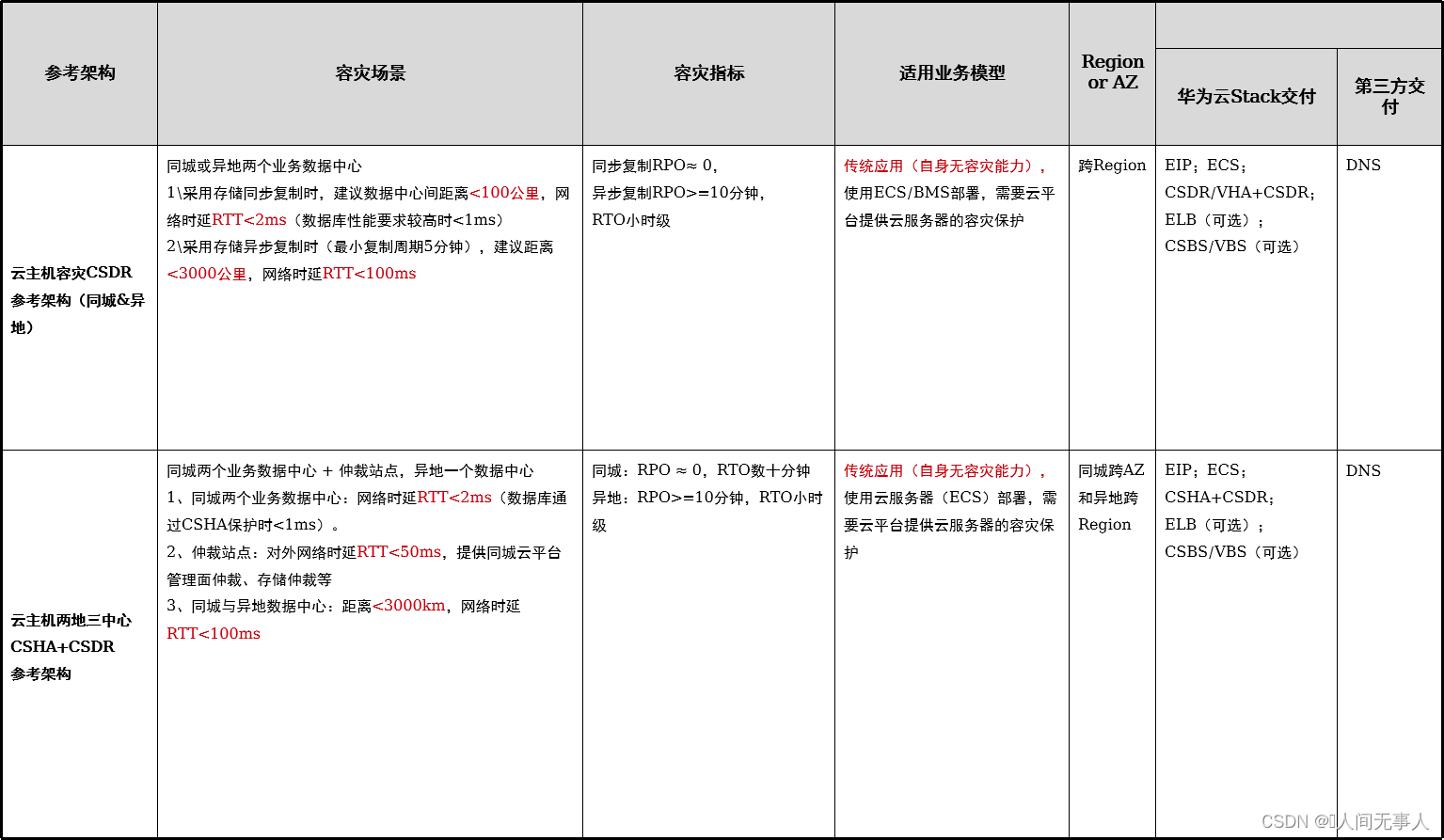
- 云容灾架构总览
- 云主机容灾CSDR
- 云主机两地三中心
- CSHA+CSDR
本地高可用方案架构
-
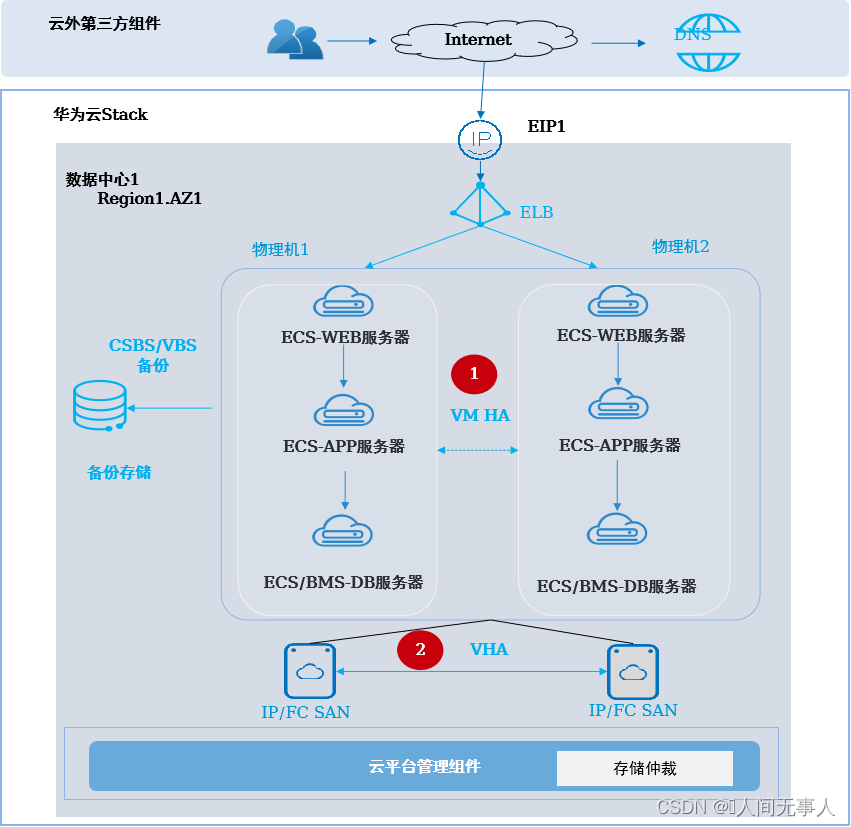
架构概述
- 适用场景:
- 客户仅有1个数据中心,需要对云主机、云硬盘或应用集群进行高可用保护,个别物理设备如物理机或存储故障时能快速恢复业务,数据不丢失,业务基本不感知
- 云硬盘高可用服务(VHA)适用于金融、医疗、社保、政务等对可靠性要求更高的场景,为ECS/BMS的系统卷和数据卷创建本地存储双活保护。当整个存储或部分存储池故障时,通过VHA服务保护的ECS/BMS,数据不丢失,业务不受影响
- 架构说明:
- 本地数据中心部署一个Region,默认含1个AZ,两套SAN存储建立HyperMetro双活关系,并部署VHA服务。存储仲裁默认部署到云平台管理面
- 一套业务系统反亲和部署部署到不同物理机,应用层使用ELB负载均衡。数据库主备集群部署,可采用ECS或BMS服务部署。外部通过EIP或DNS访问业务系统
- 通过对云服务器/云硬盘备份,防止应用集群因感染病毒、数据误删除造成损害
- 故障恢复:
- 当单个存储发生故障时:VHA服务自动激活另一套存储接管业务,数据不丢失,业务不感知
- 当单个物理机发生宕机时:云平台识别到物理机宕机,将故障物理机挂载的存储释放给主机组内其他物理机挂载,虚拟机通过VM HA能力自动在主机组内其他物理机上拉起
- 适用场景:
-
方案亮点
- 存储双活:单个存储故障,数据不丢失,故障切换无需人工干预,业务不中断;
- 业务不感知:数据复制过程中不影响云服务器计算性能;
- 云主机存储双活管理:租户自助即可完成ECS存储双活保护。
-
约束限制
- VM HA能力要求云平台管理面运行正常,BMS不支持VM HA。
- VHA仅支持集中式SAN存储,不支持分布式FusionStorage存储。
- 申请加入同一个VHA服务实例的ECS/BMS,所关联的所有云硬盘必须源自同一套配置了本地存储双活容灾的生产存储上。创建容灾实例时,要求BMS处于开机状态。
- 不支持选择ECS的部分云硬盘进行容灾保护。在VHA实例中移除ECS部分云硬盘的存储双活保护,要求该云硬盘先解除挂载,否则禁止移除。不支持对BMS本地盘进行VHA保护。
- 为已配置容灾保护的ECS/BMS挂载新的云硬盘后,需要手工(不支持自动)为新挂载的云硬盘添加容灾保护。
- 挂载同一共享盘的多个ECS/BMS必须添加到同一个VHA保护实例。
- BMS场景:仅支持为挂载给BMS的云硬盘创建VHA保护,不支持为BMS的本地盘(如系统盘安装在本地盘)创建保护。
同城双活方案架构
方案一:ECS+中间件(APIC/MQS/DCS)+数据库(跨AZ)
- 同城云原生应用双活方案一:ECS+中间件(APIC/MQS/DCS)+数据库(跨AZ)
架构概述- 适用场景:
- 客户有三个数据中心,分别为两个业务数据中心、一个仲裁站点,构建应用双活场景,单个业务数据中心故障不影响业务
- 适用于部署架构为前端无状态应用集群(ECS部署)+中间件+后端关系型数据库的业务系统
- 架构说明:
- 同城两个数据中心部署为一个Region的两个AZ,网络二层互通,网络出口跨数据中心主备。仲裁站点部署在独立数据中心,为云平台提供故障切换的仲裁服务,仲裁站点与两个业务数据中心三层互通
- 一套业务系统跨DC集群部署,应用层使用ELB负载均衡,分别使用DCS/MQS提供缓存和消息服务,数据库使用RDS服务跨AZ主备/双活部署。生产中心和容灾中心的应用集群通过VPC-Peering、EIP或专线访问生产数据库;外部通过EIP或DNS访问业务系统
- 适用场景:
- 当数据中心1发生灾难时:
- 网络出口自动主备切换,使EIP保持不变,外部访问方式不受影响。
- 云平台管理组件自动切换至数据中心2运行,接管整个云平台。
- 应用层无状态,无需切换。中间件DCS/MQS自动切换,数据库手工/自动完成故障切换,数据库访问方式不受影响。
- 外部用户最终通过EIP1访问,流量经数据中心2网络出口到达ELB,ELB自动将负载分发到数据中心2的应用层服务器,然后访问数据中心2的数据库节点。
- 方案亮点:
- 接入层自动切换:网络出口故障自动切换,对外IP地址不变;ELB高可用,应用云内跨DC负载均衡;
- 应用层双活(ECS):两个DC可同时对外提供业务应用接入能力,ECS/ROMA-Factory(ServiceStage) 单个DC故障不影响业务使用;
- 中间件跨AZ高可用: ROMA-Connect(APIC/MQS)/DCS/ServiceStage跨AZ高可用,故障后访问方式保持不变;
- 数据层跨AZ高可用:数据库RDS/OpenGauss提供主库读写,主备数据库数据实时复制,自动切换;
- 云管平台高可用:云管平台跨DC高可用部署,单个DC故障自动切换;
方案二:CCE+中间件(APIC/MQS/DCS)+数据库+GSLB[可选](跨AZ)
- 同城云原生双活方案二:CCE+中间件(APIC/MQS/DCS)+数据库+GSLB[可选](跨AZ)
架构概述- 适用场景:
- 客户有三个数据中心,分别为两个业务数据中心、一个仲裁站点,构建应用双活,单个业务数据中心故障不影响业务访问
- 适用于部署架构为前端无状态应用集群(CCE部署)+中间件+后端关系型数据库的创新业务系统
- 架构说明:
- 同城两个数据中心部署为一个Region的两个AZ,网络二层互通,网络出口跨数据中心主备。仲裁站点部署在独立数据中心,为云平台提供故障切换的仲裁服务,仲裁站点与两个业务数据中心三层互通
- 一套业务系统模块分别在两个数据中心集群部署,应用层使用ELB负载均衡,分别使用DCS/MQS提供缓存和消息服务 。数据库使用RDS/openGauss服务跨AZ主备部署。生产中心和容灾中心的应用集群通过VPC-Peering、EIP或专线访问生产数据库;外部通过DNS或GSLB访问业务系统
- 适用场景:
方案三:ECS/CCE+数据库+GSLB(跨Region)
- 同城云原生双活方案三:ECS/CCE+数据库+GSLB(跨Region)
架构概述- 适用场景:
- 适用于网络时延RTT<2ms范围的两个数据中心构建应用双活,生产中心故障时,业务系统可快速切换到灾备中心运行。
- 适用于部署架构为前端无状态应用集群(CCE/ECS部署)+后端数据库的业务系统
客户当前只有单个数据中心,需要平滑进行多数据中心的容灾演进
- 架构说明:
- 两个数据中心部署为两个Region,分别为生产中心和灾备中心,网络三层互通;在每个Region各部署一套完整的业务系统,通过ELB实现数据中心内应用集群的负载均衡,应用层无状态;生产中心应用集群通过VPC-Peering、EIP或专线访问生产数据库,容灾中心应用集群通过EIP或专线访问生产数据库;数据库跨Region主备部署,数据通过DRS服务单向异步复制;外部部署DNS或GSLB负载均衡到生产中心的EIP1或灾备中心的EIP2供外部用户访问
- 适用场景:
- 管理面:
- 手工修改外部DNS,配置灾备ManageOne运营面/运维面等portal的域名解析。
- 手工将云平台管理组件一键式切换至灾备中心运行,接管整个云平台。
- 业务面:
- 数据库手工完成故障切换,容灾中心应用集群需要修改数据库IP地址为容灾中心数据库IP地址。中间件不切换。
- 外部用户访问方式不变,通过DNS/GSLB导向EIP2访问,流量经容灾中心网络出口到达ELB,ELB自动将负载分发到数据中心2的应用层服务器,然后访问数据中心2的数据库节点。
生产数据中心恢复后,数据库通过DRS反向同步增量数据。
- 方案亮点
- 自动切换:接入层通过GLSB设备跨DC负载均衡切换,应用对外访问方式不变;
- 应用层双活:两个DC可同时对外提供业务应用接入能力,单个DC故障不影响业务使用;
- 数据库主备:RDS/DRS或openGauss或DCS数据库主备部署,数据实时复制;
- 云管平台主备容灾:云管平台一键式手工切换, 恢复时间分钟级(约15分钟),不影响业务;
- 演进平滑:支持单DC到多DC的平滑演进。
同城云主机容灾方案架构
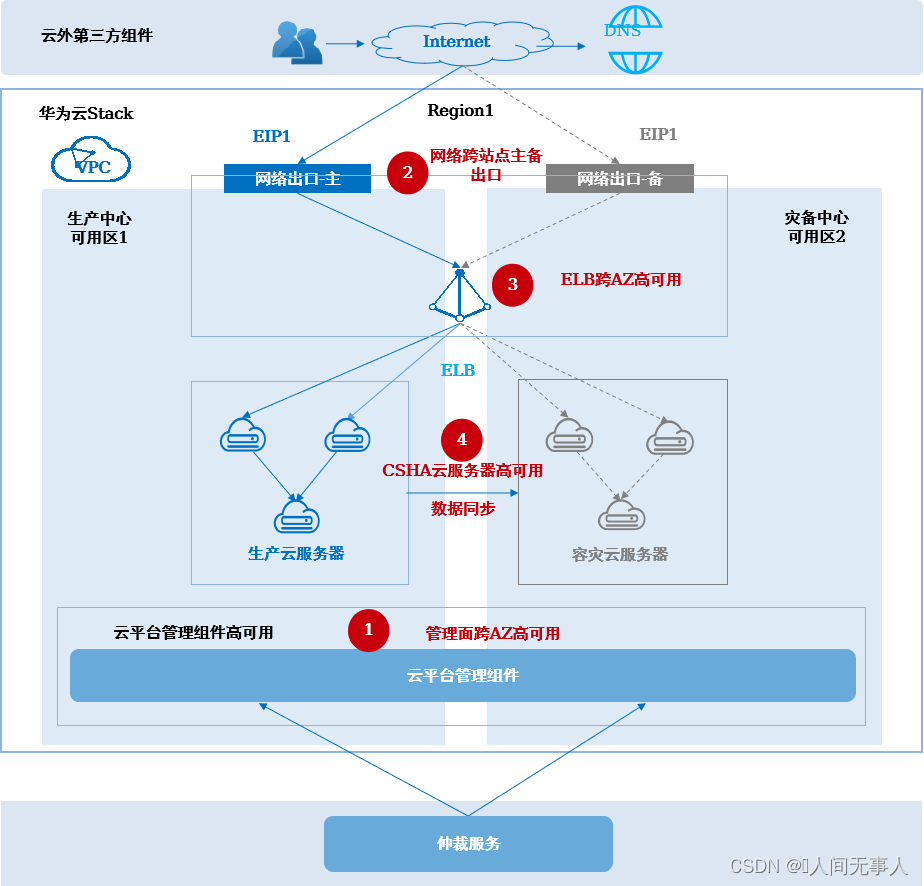
- 架构概述
- 适用场景:
- 适用于客户有三个数据中心,生产中心、灾备中心、仲裁站点,构建云主机高可用容灾的场景,用于生产中心故障时云主机的故障切换
- 适用于WEB+APP+DB无法拆分的有状态应用,全部用云服务器(ECS)部署,业务系统自身无容灾能力,需要云平台提供云服务器的容灾保护。
- 可应对设备故障和数据中心故障;计划内停机,例如:计划性停电、日常运维等
- RPO ≈ 0,RTO数十分钟
- 架构说明:
- 两个数据中心部署为一个Region两个AZ,分别为生产中心和灾备中心,网络跨AZ二层互通、网络出口跨AZ主备;第三个数据中心作为仲裁站点,为云平台、存储提供故障切换的仲裁服务,仲裁站点与生产中心、灾备中心三层互通
- 业务系统部署在生产中心ECS上,通过CSHA容灾实例保护。通过ELB实现应用集群跨数据中心的负载均衡,外部DNS解析配置生产中心的EIP1供外部用户访问
- 适用场景:
- 当生产中心发生灾难时:
- 网络出口自动主备切换,EIP保持不变,外部访问方式不受影响。
- 云平台管理组件自动切换至灾备中心运行,接管整个云平台。
- 手工/自动将CSHA保护的云服务器切换到灾备中心运行,切换后云服务器私网IP和EIP不变。
- 方案亮点:
- 应用主备容灾:主数据中心对外提供业务,单个数据中心故障自动/手动拉起容灾云服务器;
- 负载均衡:应用云内跨DC负载均衡,秒级自动切换,对外EIP不变;
- 数据库主备:数据库跟随云主机同存储直接同步复制到容灾端,数据库服务器可自动/手动拉起;
- 存储双活:跨数据中心存储双活,单中心存储故障业务无感知,数据同步复制;
- 云管平台高可用:云管平台跨DC高可用部署,单个DC故障分钟级自动切换;
异地应用容灾方案
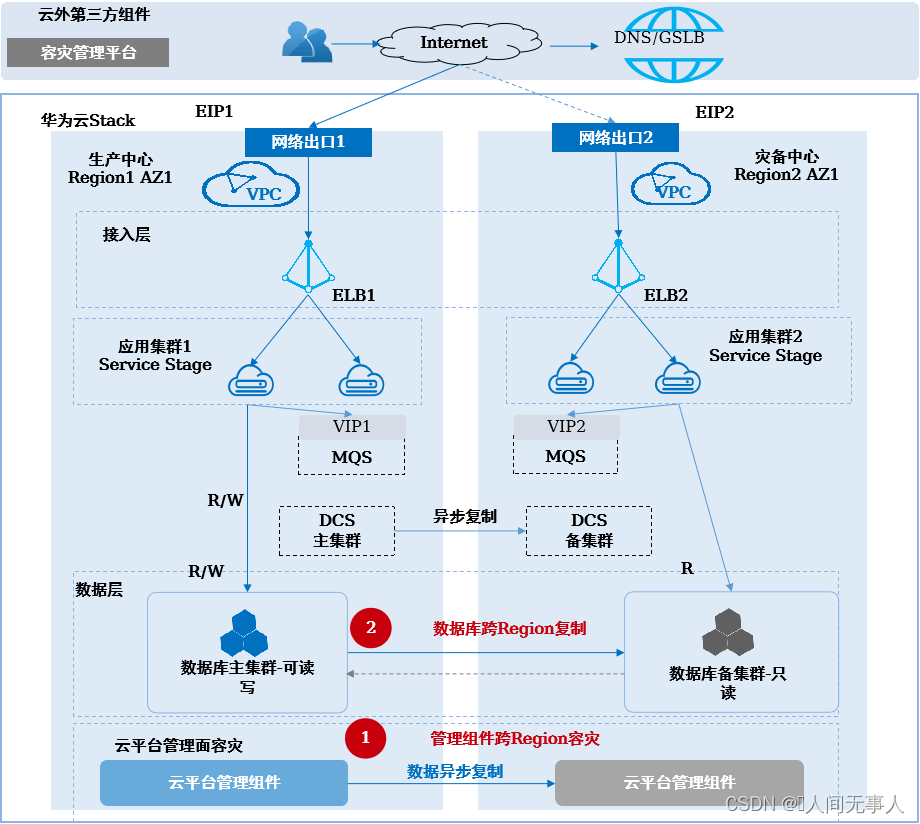
-
架构概述
- 适用场景:
- 适用于网络时延RTT<100ms范围的两个数据中心构建应用容灾,生产中心故障时,业务系统可快速切换到灾备中心运行
- 适用于部署架构为前端无状态应用集群+后端数据库的业务系统
- 客户当前只有单个数据中心,需要平滑进行多数据中心的容灾演进
- 架构说明:
- 两个数据中心部署为两个Region,分别为生产中心和灾备中心,网络三层互通;在每个Region各部署一套完整的业务系统,通过ELB实现数据中心内应用集群的负载均衡,数据库跨Region主备部署,数据单向异步复制;外部DNS配置生产中心的EIP1供外部用户访问
- 通过对云服务器/云硬盘备份,防止应用集群因感染病毒、数据误删除造成损害。通过数据库备份,防止数据库出现逻辑错误
- 适用场景:
-
当生产中心发生灾难时:
- 手工切换灾备中心数据库为读写模式。
- 手工将DNS中域名解析修改为灾备中心的EIP2,恢复业务访问。
- 手工修改外部DNS,配置灾备中心ManageOne运营面/运维面等portal的域名解析。
- 手工将云平台管理组件一键式切换至灾备中心运行,接管整个云平台。
-
方案亮点:
- 应用主备容灾:生产DC对外提供业务,单个数据中心故障手工切换业务至容灾DC;
- 数据库主备容灾:RDS/DRS或openGauss或DCS数据库集群主备部署,数据异步复制;
- 云管平台主备容灾:云管平台一键式手工切换, 恢复时间分钟级(约15分钟),不影响业务;
- 演进平滑:支持单DC到多DC的平滑演进。
异地云主机容灾方案架构
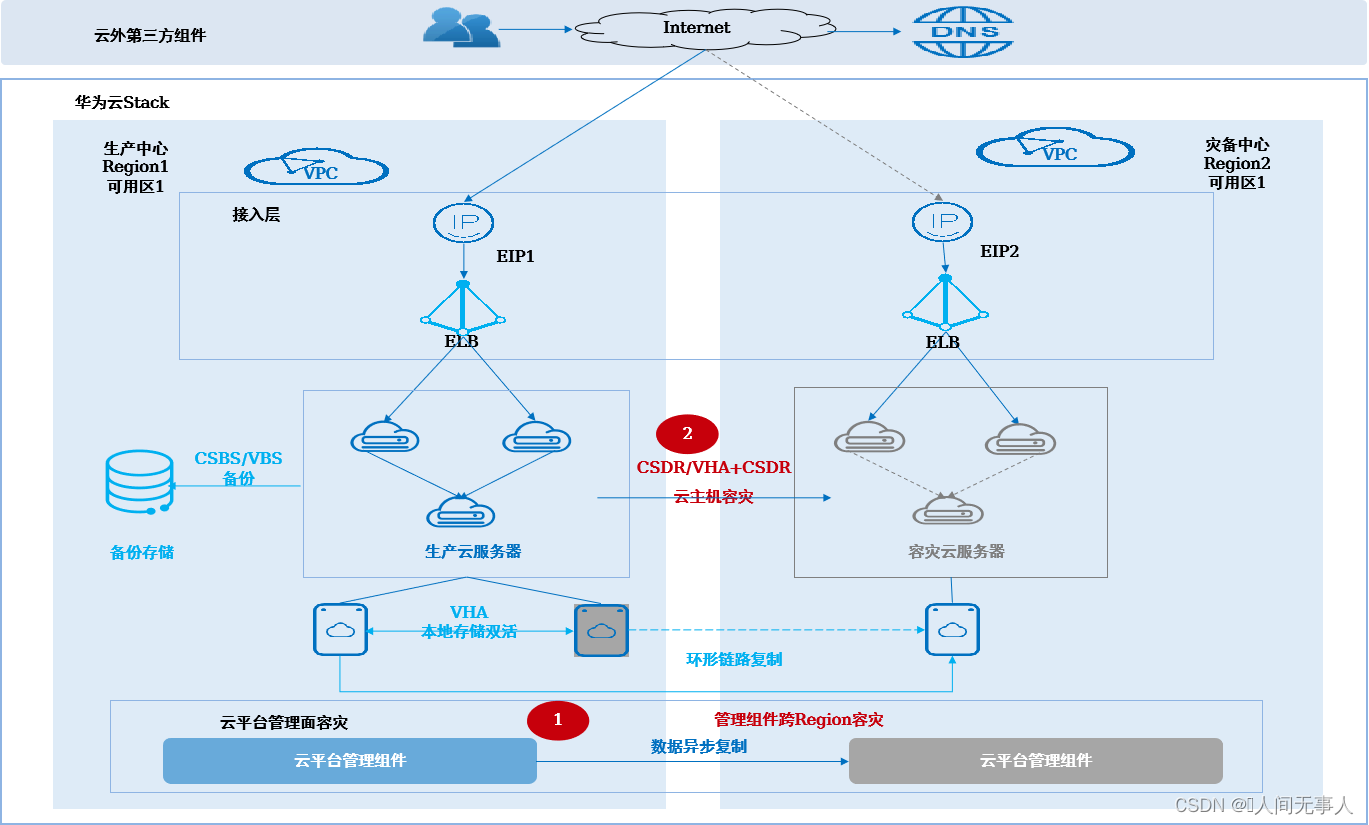
- 异地云主机容灾解决方案(CSDR&VHA+CSDR)
架构概述- 适用场景:
- 适用于在两个数据中心,构建云平台主备容灾的场景,用于生产中心故障时云主机的故障切换
- 适用于WEB+APP+DB无法拆分的有状态应用,全部用云服务器(ECS)部署,业务系统自身无容灾能力,需要云平台提供云服务器的容灾保护。
- 可应对设备故障、数据中心故障、区域性灾难;计划内停机,例如:计划性停电、日常运维等
- 同步复制RPO ≈ 0 ,异步复制RPO>=10分钟,RTO小时级
- 架构说明:
- 两个数据中心部署为两个Region,分别为生产中心和灾备中心,网络三层互通;业务系统部署在生产中心,通过CSDR或VHA+CSDR容灾实例保护。通过ELB实现数据中心内应用集群的负载均衡,外部DNS配置生产中心的EIP1供用户访问
- 适用场景:
- 当生产中心发生灾难时:
- 手工修改外部DNS,配置灾备中心ManageOne运营面/运维面等portal的域名解析。
- 手工将云平台管理组件一键式切换至灾备中心运行,接管整个云平台。
- 手工将CSDR或VHA+CSDR保护的云主机切换到灾备中心运行。
- 手工修改外部DNS配置为EIP2,将外部访问流量切换至灾备中心。
- (可选)当生产中心单套业务存储故障时:通过VHA服务保护的ECS数据不丢失,业务不中断。
方案亮点:- 应用主备容灾:生产DC对外提供业务,单个数据中心故障手工切换业务至容灾DC;
- 异地存储主备复制:存储数据同步/异步复制;
- 本地存储双活:单个存储故障,数据不丢失,故障切换无需人工干预,业务不中断;(可选)
- 云管平台主备容灾:云管平台一键式手工切换, 恢复时间分钟级(约15分钟),不影响业务;
- 演进平滑:支持单DC到多DC的平滑演进。
云主机容灾+异地备份方案架构
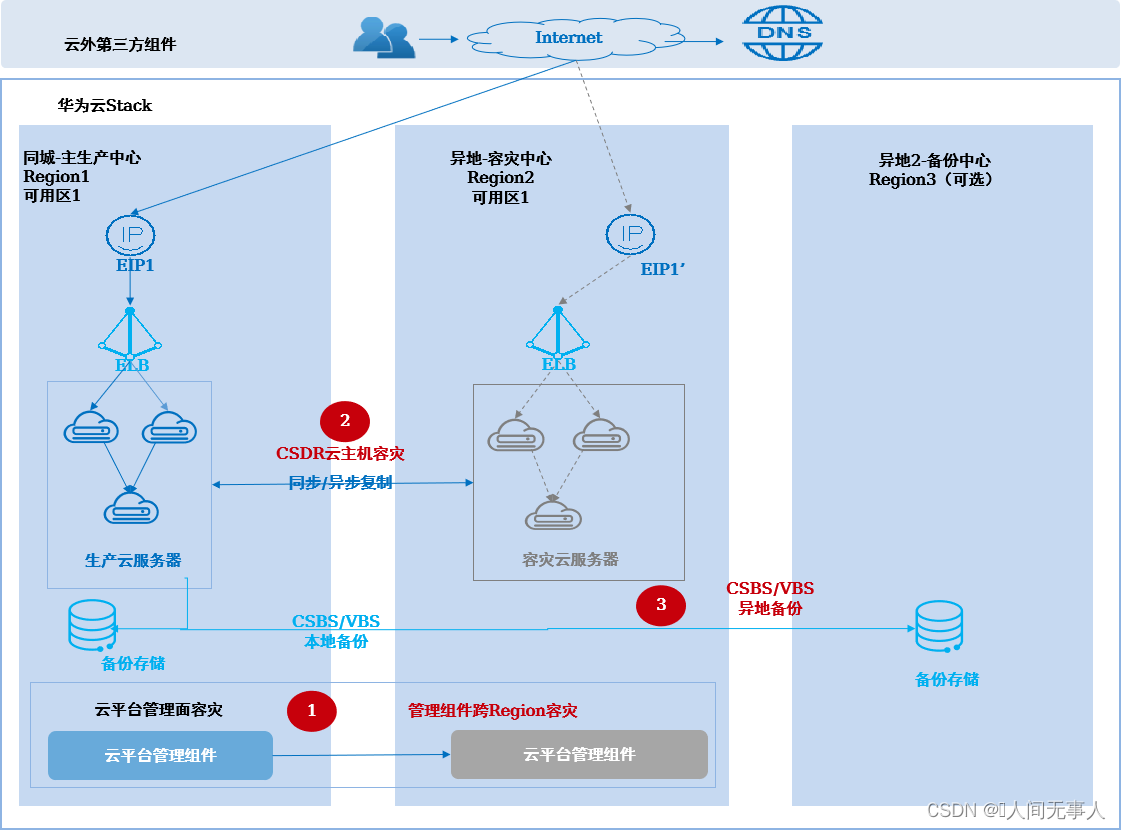
-
架构概述
- 适用场景:
- 适用于在两个或三个数据中心,构建云平台主备容灾的场景,用于生产中心故障时云主机的故障切换
- 适用于WEB+APP+DB无法拆分的有状态应用,全部用云服务器(ECS)部署,业务系统自身无容灾能力,需要云平台提供云服务器的容灾保护。
- 可应对设备故障、数据中心故障、区域性灾难;计划内停机,例如:计划性停电、日常运维等
同步复制RPO ≈ 0 ,异步备份RPO小时级以上,RTO小时级
- 架构说明:
- 生产和容灾数据中心部署两个Region,分别为生产Region和灾备Region,两个Region网络三层互通,业务系统部署在生产中心,通过CSDR容灾实例保护。通过ELB实现数据中心内应用集群的负载均衡,外部DNS配置生产中心的EIP1供用户访问
- 异地备份中心可部署Region或者放置存储用于数据备份,如果异地备份中心需要部署Region发放业务,需要部署Region由主备MO统一纳管,可发放ECS或恢复备份数据。(可选)
- 适用场景:
-
当生产中心发生灾难时:
- 手工修改DNS,配置灾备中心ManageOne运营面/运维面等portal的域名解析。
- 手工将云平台管理组件一键式切换至灾备中心运行,接管整个云平台。
- 手工将CSDR保护的云主机切换到灾备中心运行。
- 手工修改外部DNS配置为EIP2,将外部访问流量切换至灾备中心。
-
方案亮点:
- 应用主备容灾:生产DC对外提供业务,单个数据中心故障手工切换业务至容灾DC;
- 本地存储双活:单个存储故障,数据不丢失,故障切换无需人工干预,业务不中断;(可选)
- 异地数据复制:业务数据通过存储同步/异步复制到容灾站点;
- 异地备份:数据备份到异地;在异地2建设Region时,可在异地恢复业务。
- 云管平台主备容灾:云管平台一键式手工切换, 恢复时间分钟级(约15分钟),不影响业务;
- 演进平滑:支持单DC到多DC的平滑演进。
- 小时级以上:数小时至一天
- 小时级:数小时
云主机N:1容灾参考架构
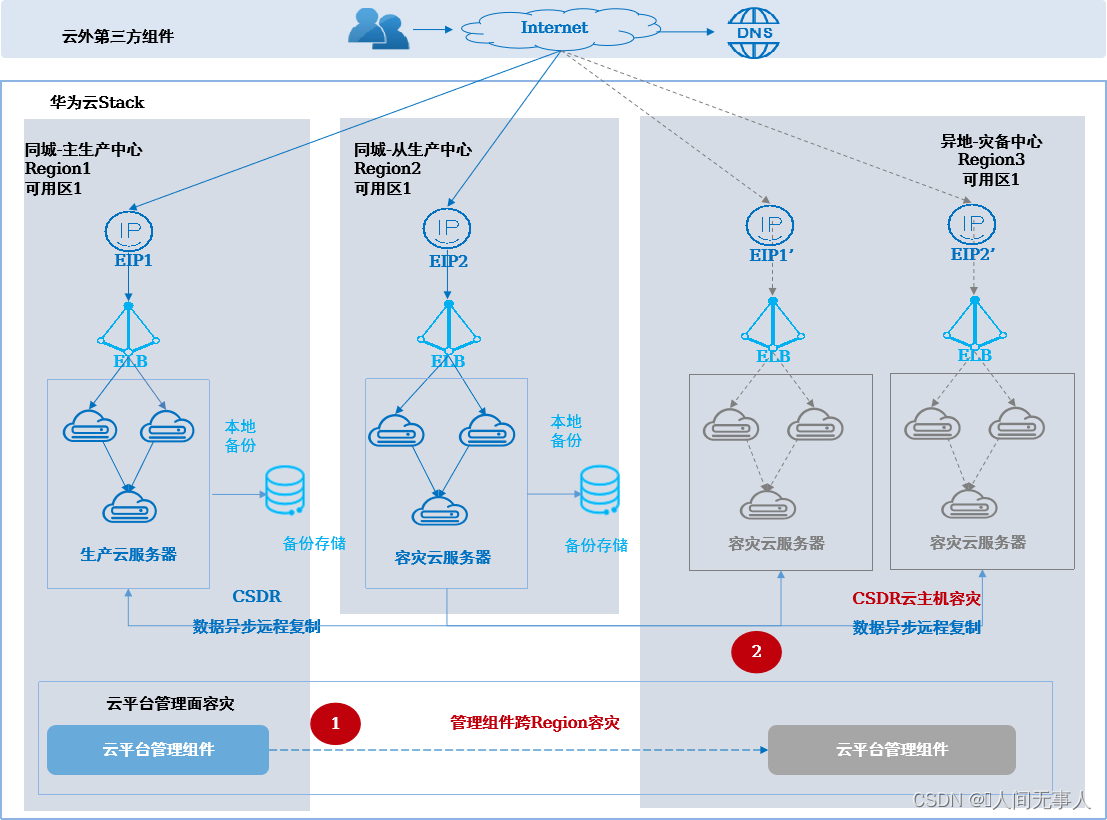
-
架构概述
- 适用场景:
- 适用于在有三个或以上数据中心的场景构建云主机两地三中心容灾,或多个数据中心数据需要容灾到同一个备数据中心,用于整站点故障时云主机的容灾切换。可应对设备故障和数据中心故障;计划内停机,例如:计划性停电、日常运维等
- 适用于同城由客户应用层面实现双活,异地采用云平台提供的容灾保护能力
- 适用于WEB+APP+DB无法拆分的有状态应用,全部用云服务器(ECS)部署,业务系统自身无容灾能力,需要云平台提供云服务器的容灾保护。
- 客户当前只有单个数据中心,需要平滑进行多数据中心的容灾演进
- 架构说明:
- 同城两个数据中心作为主、从生产中心,规划为Region1、Region2,异地数据中心作为灾备中心,规划为Region3
- 业务部署在生产中心,通过ELB实现应用集群的负载均衡和故障切换,通过CSDR容灾实例保护,实现云服务器从生产中心到灾备中心的容灾保护
- 适用场景:
-
当生产中心(Region1)故障时:
- 手工修改外部DNS,配置灾备中心ManageOne运营面/运维面等portal的域名解析。
- 云平台管理组件手工一键式切换至同城灾备中心运行,接管整个云平台。
- 手工将受保护的云服务器切换到灾备中心运行;
- 手工修改外部DNS配置为EIP1’,将外部访问流量切换至灾备中心。
- 当生产中心(Region2)故障时:
- 手工将受保护的云服务器切换到灾备中心运行;
- 手工修改外部DNS配置为EIP2’,将外部访问流量切换至灾备中心。
-
方案亮点:
- 应用主备容灾:生产DC对外提供业务,单个数据中心故障手工切换业务至容灾DC;
- 多对一容灾:统一的容灾站点,实现多个DC容灾到一个专用容灾DC;
- 异地数据复制:业务数据通过存储同步/异步复制到容灾站点;
- 云管平台主备容灾:云管平台一键式手工切换, 恢复时间分钟级(约15分钟),不影响业务;
演进平滑:支持单DC到多DC的平滑演进。
云主机两地三中心容灾方案架构 - CSHA+CSDR
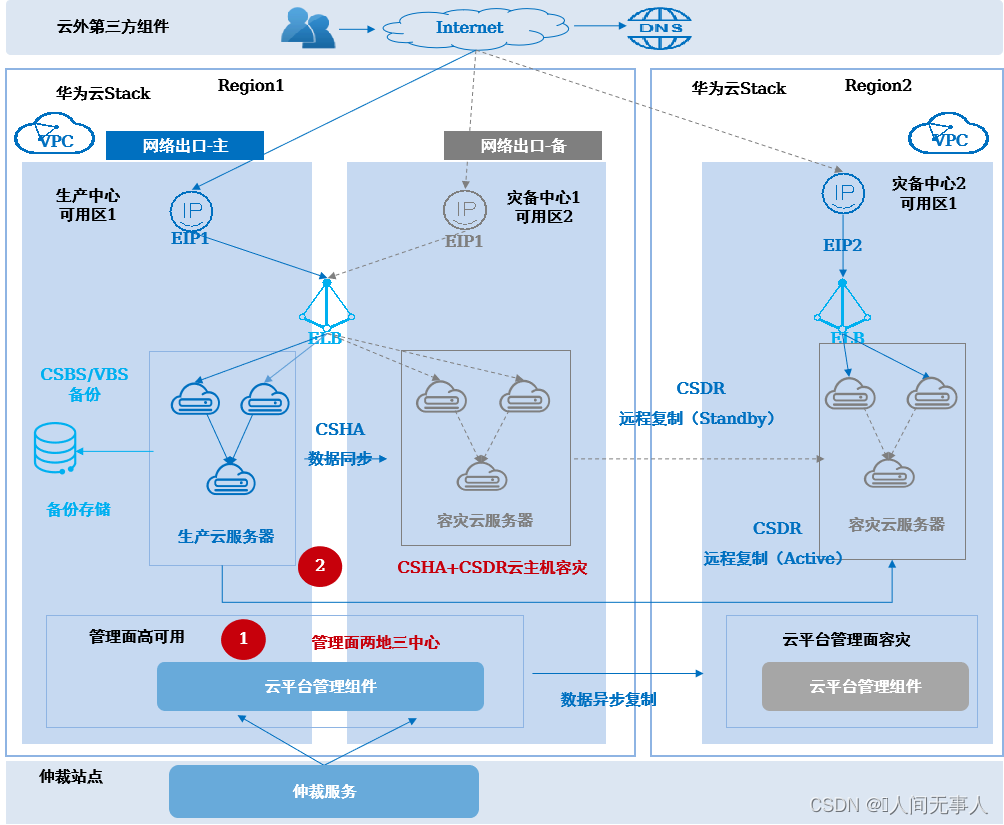
-
架构概述
- 适用场景:
- 适用于在同城有三个数据中心,在异地有一个数据中心,且同城两个数据中心网络时延RTT<2ms(数据库通过CSHA保护时<1ms)与异地数据中心网络时延RTT<100ms ,构建云主机两地三中心容灾的场景,用于整站点故障时云主机的容灾切换
- 适用于WEB+APP+DB无法拆分的有状态应用,全部用云服务器(ECS)部署,业务系统自身无容灾能力,需要云平台提供云服务器的容灾保护
- 可应对设备故障和数据中心故障;计划内停机,例如:计划性停电、日常运维等
- 架构说明:
- 同城三个数据中心,部署为一个Region的两个AZ,分别为生产中心、灾备中心1、仲裁站点,AZ之间网络二层互通、网络出口跨AZ主备;异地数据中心部署为一个Region,作为灾备中心2
- 业务部署在生产中心,通过ELB实现应用集群的负载均衡和故障切换,通过CSHA+CSDR容灾实例保护,实现云服务器从生产中心到灾备中心1的同城高可用保护、从生产中心到灾备中心2的异地容灾保护
- 适用场景:
-
当生产中心故障时:
- 同城两个数据中心网络出口自动主备切换,使EIP保持不变,访问方式不受影响。
- 云平台管理组件自动切换至同城灾备中心1运行,接管整个云平台。
- 手工/自动将受保护的云服务器切换到灾备中心1运行,切换后云服务器私网IP保持不变,应用间访问不受影响;
- 当同城两个数据中心均故障时:
- 手工将云平台管理组件一键式切换至灾备中心2运行,接管整个云平台。
- 手工将受保护的云服务器切换到异地灾备中心2。
- 手工修改外部DNS配置为EIP2,将外部访问流量切换至灾备中心2。
-
方案亮点:
- 两地三中心容灾:主数据中心对外提供业务,主数据中心故障自动/手动拉起同城容灾云服务器;同城双中心故障,可手动拉起异地容灾云服务器;
- 负载均衡:应用云内跨DC负载均衡,秒级自动切换,同城对外EIP不变;
- 存储跨数据中心双活:同城单中心存储故障业务无感知,数据同步复制;
- 异地数据复制:业务数据通过存储同步/异步的方式从同城站点复制到容灾站点;
- 云管平台两地三中心:云管平台同城跨DC高可用部署,单个DC故障分钟级自动切换;异地容灾,一键式分钟级拉起。
管理组件灾备方案介绍
管理组件跨AZ高可用
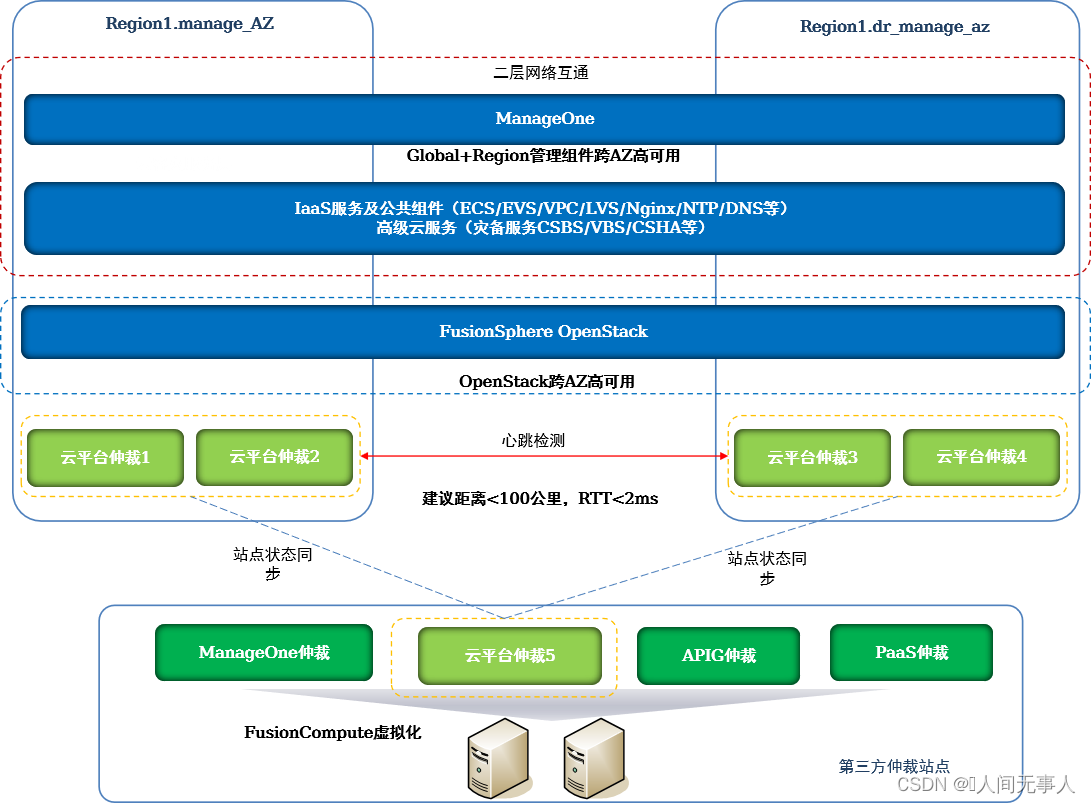
-
云平台仲裁服务的仲裁逻辑
- 云平台仲裁服务:基于生产、容灾两个AZ间心跳探测,判断生产、容灾两个站点的存活状态:机房故障、脑裂,并通过云平台仲裁内etcd分布式集群进行数据同步,为其他管理组件提供切换判断依据
- 云服务及OpenStack组件:站点间链路中断后,管理组件查询云平台仲裁服务获取站点健康状态,并判断本站点内备用组件是否需要升主提供业务
- 某个站点故障:位于存活站点内的备用节点升主,自动接管业务
- 站点间链路故障:根据预配置的优先站点规则,位于优先站点内的管理节点自动接管业务
- 组件恢复时间约10分钟;切换过程中无法进行业务发放和运营、运维操作
-
管理组件跨AZ高可用,为云平台提供Global及Region管理组件同城容灾保护(Region内跨两个AZ)。当生产中心发生灾难时,可自动在灾备中心恢复管理系统,从而继续提供运营运维服务。
-
ManageOne(含IAM/ SC/ OC等)、云服务Console、BCManager eReplication、ECS/EVS/VPC等云服务后端及OpenStack管理节点等,一套系统跨AZ拉远部署并自动数据同步
-
对于IAM、BCManager eReplication、OpenStack等影响业务恢复的关键组件,对接云平台仲裁/IAM仲裁,以便在一个站点故障时可在另一个站点快速自动恢复并提供管理功能。
-
对于ManageOne(除IAM外)在故障时需手工切换,其管理功能的恢复不影响业务的恢复。
管理组件跨AZ高可用技术实现 - 单AZ向双AZ演进
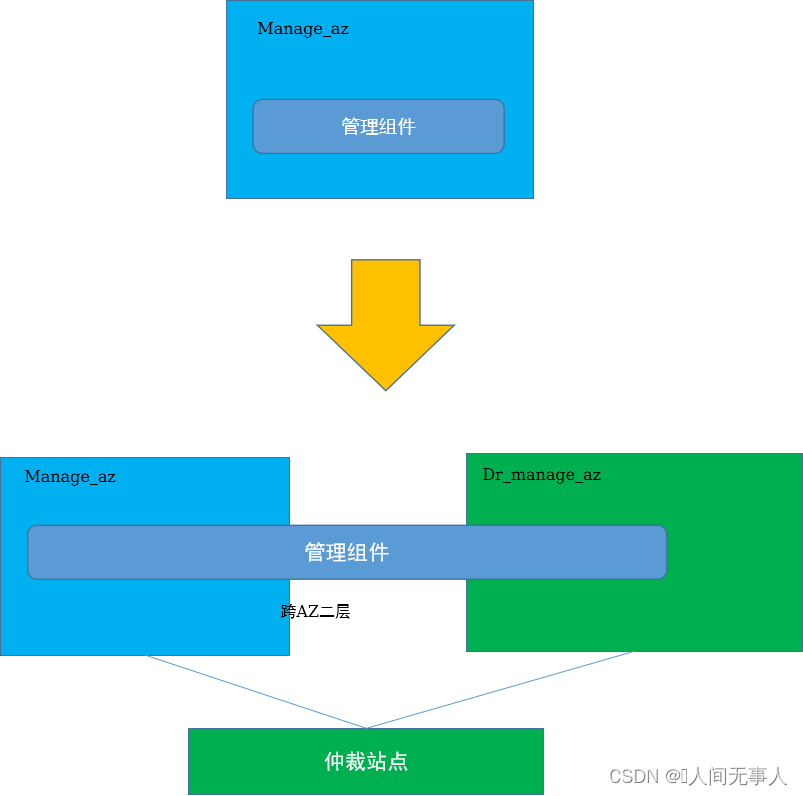
-
改造过程
- 改造前检查:调研系统现状,检查是否满足改造要求
- 改造过程:
- 网络改造:网络现状信息收集、跨AZ网络规划及网络改造
- 仲裁节点安装:在第三方仲裁站点部署FusionCompute并创建仲裁虚拟机
- 管理面跨AZ高可用改造:使用HCSD执行管理面跨AZ高可用改造工程,完成OpenStack及云服务的单AZ到双AZ改造
- ManageOne跨AZ高可用改造:使用华为云Stack Update执行ManageOne跨AZ高可用改造工程,完成ManageOne的单AZ到双AZ改造
- 扩容AZ:使用HCSD执行新增AZ工程,完成容灾AZ的安装及跨AZ主备出口的扩容
- 改造后处理:清理改造后多余的资源及修改部分配置信息
- 改造后验证:改造成功后继续观察和验证各业务功能是否正常
-
面向场景
- 客户已在一个机房内部署华为云Stack 8.0.3或以后版本,需要进行单AZ到双AZ演进。
- 华为云Stack需要先升级到8.1.1或最新版本,再进行演进改造。
-
约束条件:
-
支持的服务范围:只支持ManageOne 、OpenStack底座及部分IaaS基础服务,不支持高阶服务、APIG、VHA、SFS、安全服务、HiCloud服务、OCC服务、eSight。
不支持改造为两地三中心:只支持从无容灾演进到跨AZ容灾,不支持由跨Region容灾演进到两地三中心容灾。 -
不支持管理跨网段改造:只支持Internal_Base、External_OM、DMZ_Service、Storage_Data、Provision同VLAN、同子网二层改造,不支持跨子网不同网段改造。
-
要求管理网段存在空闲的连续IP地址:需要局部连续的External_OM平面地址至少40个,B2B场景需要局部连续的DMZ_Service平面地址至少3个,不支持非连续地址改造。
-
外部IP地址变化:ManageOne改造后对外IP地址发生变化,改造完成后需要修改外部DNS对应的IP或主机域名IP。
-
改造前手工检查:不支持改造前自动化容量(CPU/内存/可用IP地址数量)检查,需要在改造前人工检查,若资源(如IP地址等)不足,不能进行改造。
-
不支持改造过程中自动回退:当改造过程出现异常时,需要修复异常后继续进行改造。
-
约束条件:
- APIG不支持单AZ到双AZ演进,当单AZ故障时,APIG服务故障,导致服务构建器功能将受到影响。
- 只支持从华为云Stack 8.0.3及以后版本升级到最新版本后进行改造,不支持对从华为云Stack 8.0.3以前版本升级上来的版本进行改造。
- 只支持ManageOne 12节点形态部署场景,不支持ManageOne 15节点形态(包括G/R解耦场景、标准10W规模部署场景及由3W到10W扩容改造后的场景);IAM独立场景不支持改造。
- Global全局业务规模小于100PM时,需要先扩容到100PM或以上。
- 已配置网络多出口时不支持改造。
- 其他约束继承管理面跨AZ高可用的约束,如不支持Global解耦场景。
管理组件跨Region容灾
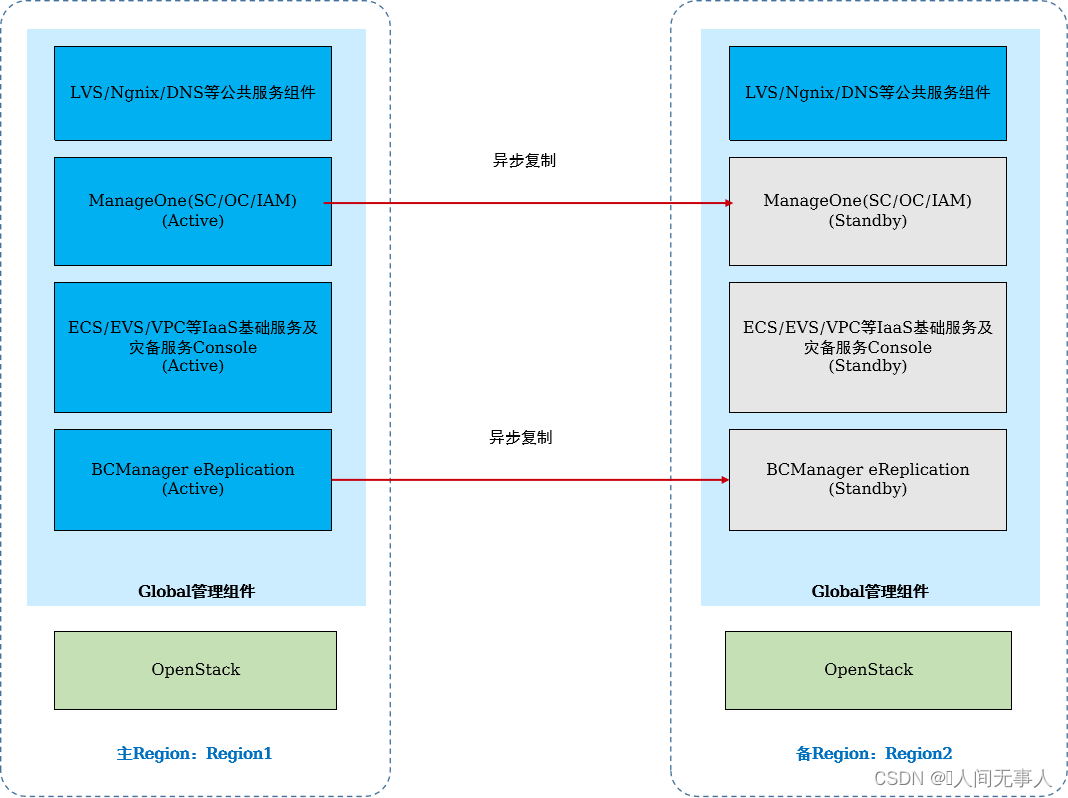
-
管理组件跨Region容灾部署
- Global管理组件(ManageOne、云服务Console等):在主备Region中各部署一套ManageOne、云服务Console等Global管理组件。在主Region故障时,需管理员手工恢复并启用备Region上的Global管理组件
- ManageOne与BCManager eReplication(可选:涉及云容灾服务时部署):数据库异步远程复制方式实现容灾
- 公共服务组件:LVS、Ngnix、内部DNS(内部DNS仅用于ManageOne与云服务、云服务与OpenStack等组件间交互的DNS解析。不对外提供DNS服务)等公共服务组件在主备Region均独立部署一套,彼此间无复制关系。主备ManageOne分别与其所在Region的LVS、Ngnix对接
OpenStack等Region级组件:每个Region独立部署,管理各自的本地资源。不具备跨Region的容灾能力,单Region故障后,仅影响该故障的Region - 管理组件演进到跨Region容灾部署:支持后期在新增Region或已有Region上扩增部署Global管理组件,演进到管理组件跨Region。
- 当前支持跨Region容灾的Global管理组件有:ManageOne、IaaS基础服务Console及公共服务支撑组件、CSBS/VBS服务Console、BCManager eReplication等
-
管理组件跨Region容灾,为云平台提供Global管理组件(不含OpenStack等region级管理组件)异地容灾保护(跨两个region)。当生产中心发生灾难时,可在异地灾备中心恢复管理系统,从而给未发生灾难的数据中心继续提供运营运维服务。
-
Global管理组件容灾切换:当灾难发生时,管理员启用备Region的Global管理组件,而备ManageOne对接备Region内的LVS、Ngnix。存在如下两个方案:
- 方案1:若客户配置外部DNS,在外部DNS中需配置LVS等组件的域名及IP信息。切换后,仅需刷新客户的外部DNS配置,就可访问备站点的LVS。
- 方案2:若客户未配置外部DNS,则各个需访问LVS的客户端的HOST文件中需配置LVS域名及IP信息,各客户端均需刷新HOSTS中的LVS配置。
管理组件两地三中心容灾
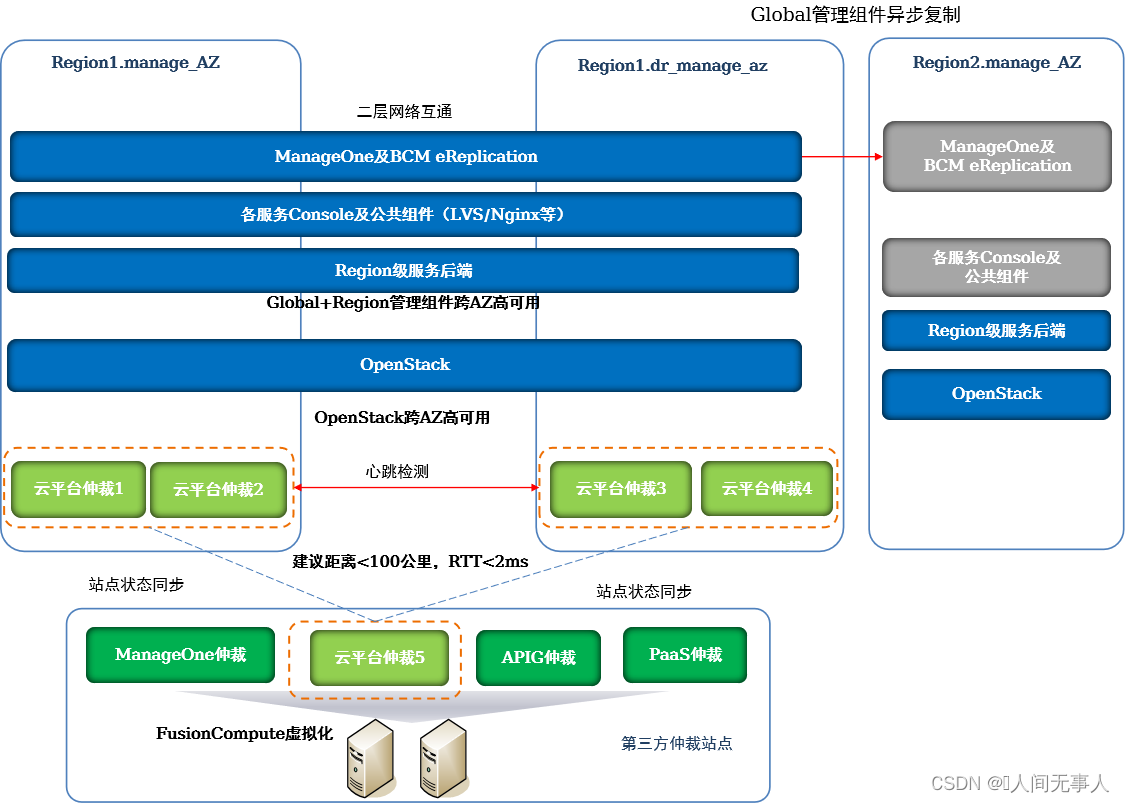
-
管理组件两地三中心容灾部署
- 主Region管理组件跨AZ高可用部署。
- 备Region的Global管理组件部署在一个站点,与管理组件跨Region容灾中的备Region部署类似
- OpenStack、Region级服务后端等Region级组件每个Region独立部署,管理各自的本地资源。不具备跨Region的容灾能力,单Region故障后,仅影响该故障的Region
- 当前支持两地三中心容灾的Global管理组件有:ManageOne、IaaS基础服务及公共服务支撑组件、CSBS/VBS服务Console、BCManager eReplication等
-
管理组件两地三中心容灾,为云平台提供Global及Region管理组件同城容灾保护(Region内跨两个AZ),及Global管理组件(不含OpenStack等region级管理组件)异地容灾保护(跨两个region)。当生产中心发生灾难时,可自动在同城灾备中心恢复管理系统;在同城两个站点均发生灾难时,可在异地灾备中心恢复管理系统,从而给未发生灾难的数据中心继续提供运营运维服务。
-
ManageOne(含IAM/ SC/ OC等)、云服务Console、BCManager eReplication、ECS/EVS/VPC等云服务后端及OpenStack管理节点等,一套系统跨AZ拉远部署并自动数据同步
-
对于IAM、BCManager eReplication、OpenStack等影响业务恢复的关键组件,对接云平台仲裁/IAM仲裁,以便在一个站点故障时可在另一个站点快速自动恢复并提供管理功能。
-
对于ManageOne(除IAM外)在故障时需手工切换,其管理功能的恢复不影响业务的恢复。
管理面跨AZ网络设计说明
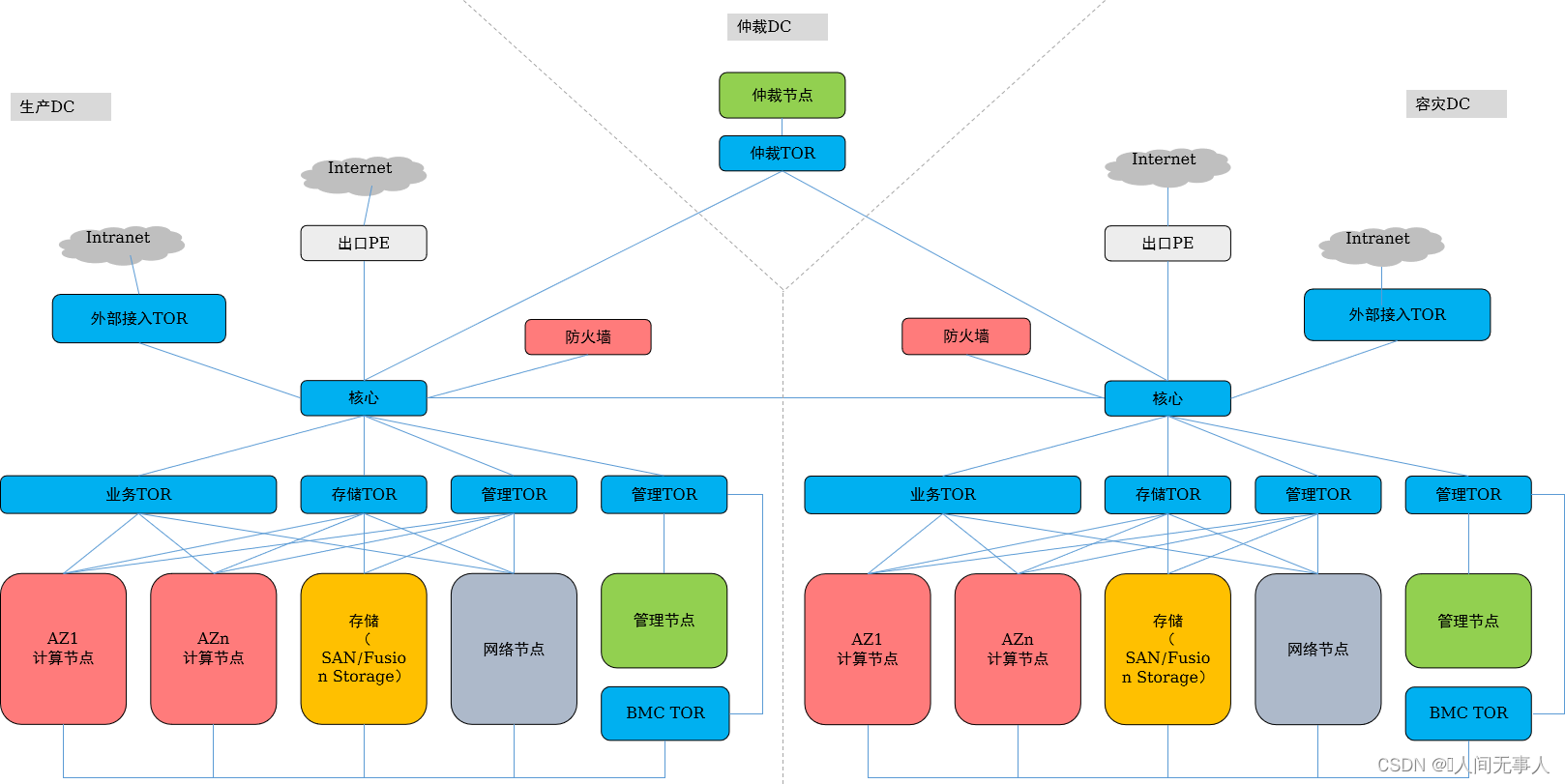
- 1)管理面跨AZ高可用场景下,对应的是一套OpenStack,拉远部署在两个站点,每个站点需要各自的管理节点,管理平面二层拉远。
- 2)核心交换机之间推荐采用直连,用于管理面二层互通、业务区一个VPC内的VM跨两个站点。
- 3)管理接入交换机仅作为二层接入,核心交换机作为管理网的三层网关,配置VRRP。在核心交换机上配置了三层网关的网络平面均需要配置VRRP,包含External_OM、DMZ_Service、Management_Storage_Data、External_Relay_Network、Internal_Base、Tunnel_Bearing、Internet等。
- 4)Type I场景,单核心组网支持计算节点的2网口、4网口和6网口部署。在多出口场景下,每个物理出口需要配置各自的网络节点(每套网络节点2节点起配),每个出口的网络节点业务没有关系,是两套独立的网络集群,网络服务相关的网络平面每个出口都需要单独规划,且保证网络不冲突;在主备出口场景下,只部署一套网络集群,一套网络集群拉远部署在两个站点。
- 5)第三方仲裁站点,建议通过专线直连到两个站点的核心交换机。第三方仲裁站点到生产站点、第三方仲裁站点到灾备站点之间,需要分别发布云平台仲裁服务节点的主机路由。云服务、ManageOne、FusionSphere OpenStack都需要访问第三方仲裁站点。
- 6)企业内部接入中仅L3GW支持主备网关的CSHA能力,L2BR不支持主备网关能力。
管理面跨Region容灾网络设计说明
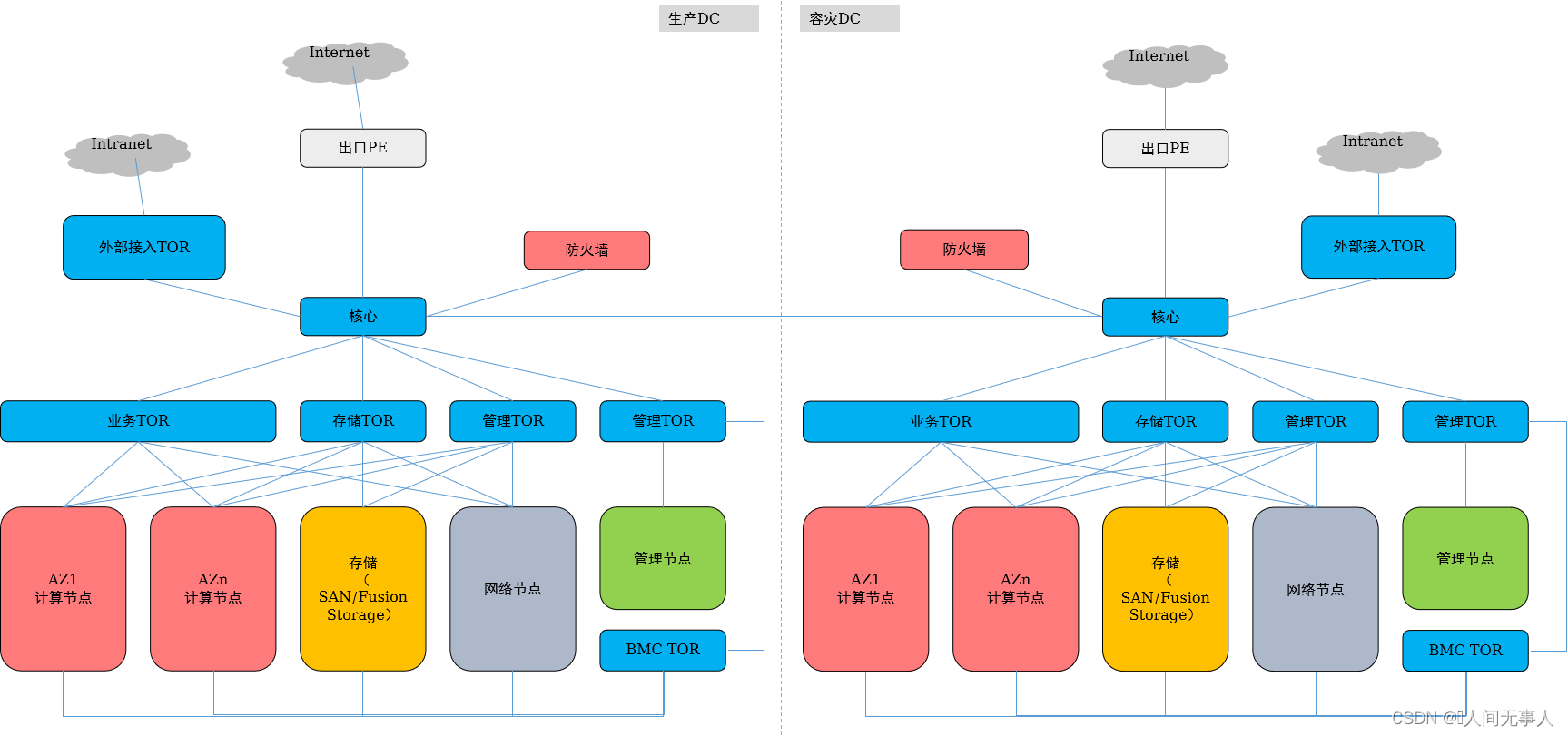
- 1)两个Region的核心交换机之间需要连线。主Region的管理网络(External_OM、DMZ_Service)需要与备Region区的管理网络External_OM、DMZ_service平面互通。其他主备Global区与Region区的互通要求请参考IaaS场景Region区与Global区管理平面互通要求和技术中台和AI数据中台场景Region区与Global区管理平面互通要求。
- 2)两个Region间的Manage VRF和Manage VRF、DMZ VRF和DMZ VRF之间互通的流量分别通过核心交换机Manage VRF和DMZ VRF之间互联的三层口互通,不过防火墙。Region间Manage VRF和DMZ VRF跨VRF互通的流量需要在Global Region的边界防火墙上配置安全策略,实现跨VRF的互通。
- 3)部署管理面跨Region容灾或CSDR,则主备Region需部署ManageOne主备容灾;CSDR要求生产和容灾Region的存储复制面需要打通;
- 4)两个业务核心之间是否需要其他业务流量互通(除了CSDR场景下的存储复制互通),比如EIP,IPSec-VPN或者路由直通等互通,按照具体项目要求实现。
- 5)CSDR场景,存储复制网络的网关配置在业务核心的InterConnection VRF,两个Region的存储复制流量互通不需要过防火墙。两个Region的InterConnetion VRF的网络互通不需要过防火墙。
- 6)多region组网支持高阶服务,CSDR服务与高阶服务无关。
高阶云服务容灾简介
华为云Stack支持高阶云服务容灾
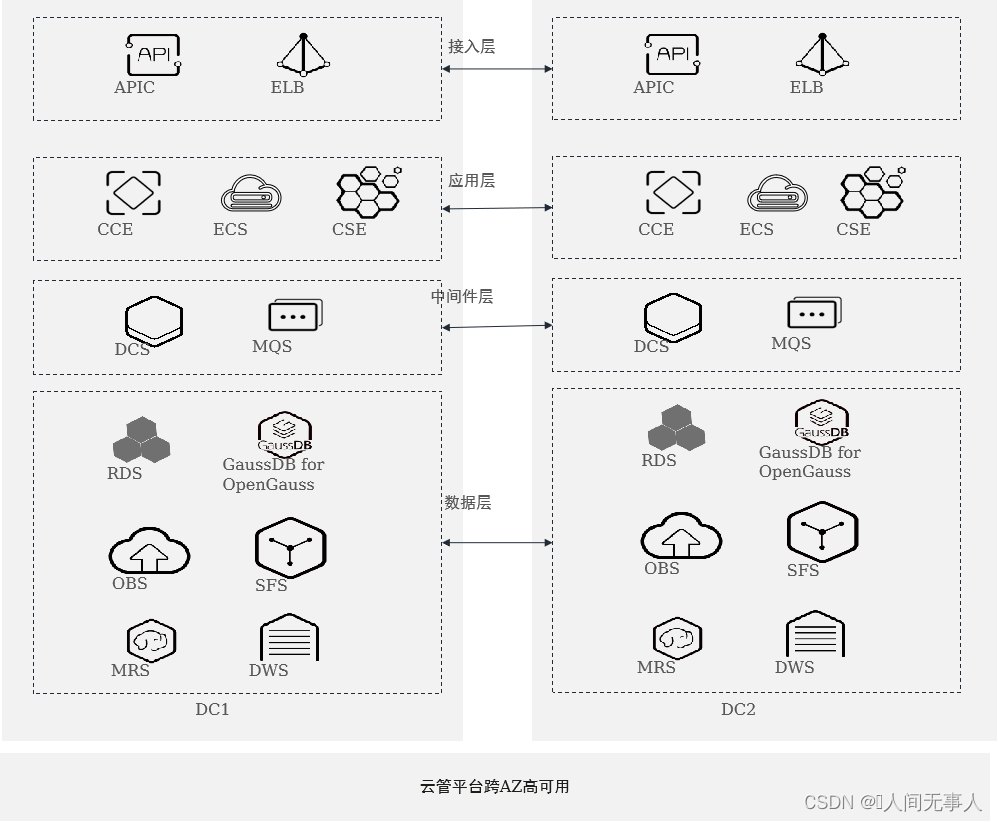
- 接入层双活:
- 网络出口故障自动切换,保持EIP不变
- ELB高可用,实现跨数据中心负载均衡
- APIC跨数据中心集群部署,自动切换
- 应用层双活:
- 应用层无状态部署,CCE/ECS跨AZ双活
- ServiceStage跨AZ双活部署
- 中间件层双活:
- DCS/MQS集群跨AZ主备部署,单边故障无需修改配置,访问方式保持不变
- 数据层容灾:
- MRS/DWS支持跨AZ双集群容灾
- 数据库跨AZ集群拉远部署,单边故障VIP不变
- SFS、OBS跨AZ高可用能力
- 云管平台跨AZ高可用:
- 云管平台高可用架构,无惧单边故障
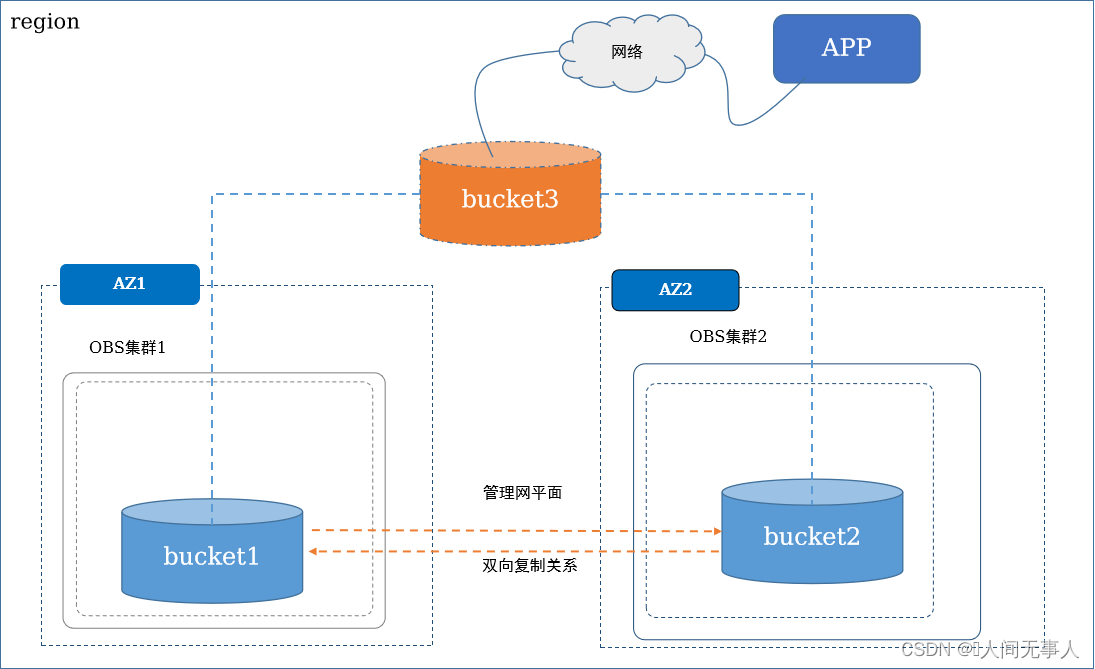
典型高阶服务实现原理 - OBS跨AZ容灾
- 关键技术实现
- OBS主要技术:
- 通过CCR(Cross Cluster Replication)技术,通过复制队列异步方式在OBS 2AZ的桶上实现数据同步,实现数据的持续保护( CDP Continuous Data Protection )
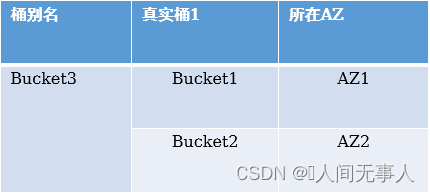
- 桶别名,OBS对没组跨AZ的桶可绑定一个桶别名,对外暴露桶别名,使用桶别名的OBS域名做业务访问,屏蔽了AZ故障桶名切换的变化
- 双向复制关系,数据复制要求从主集群复制到备集群。在主集群故障后,由管理员进行手工切换,主降备,备升主,对外继续提供服务。接收新的写IO,待备恢复后,新的数据可被持续复制,实现主备数据一致
- 创建OBS跨AZ容灾:
- 在AZ1的OBS和AZ2的OBS上分别创建bucket1和bucket2
- 配置bucket1->bucket2的CCR复制关系以及bucket2->bucket1的CCR复制关系
- 为bucket1和bucket2创建并绑定桶别名bucket3
- Client端APP使用bucket3桶域名做OBS访问,正常情况下客户访问bucket1进行读写,故障切换后可以从bucket2中进行数据读写
- OBS主要技术:
- OBS跨AZ容灾特性,底层实现是用了桶别名。一个桶别名可以绑定2个不同的真实桶,分别跨2个AZ。当通过桶别名域名访问时,请求会优先路由到默认AZ集群,如果不通则请求会路由到另一个AZ的集群上。AZ故障对用户不可见,访问方式固定为虚拟桶域名。
典型高阶服务实现原理 - 跨Region复制技术实现
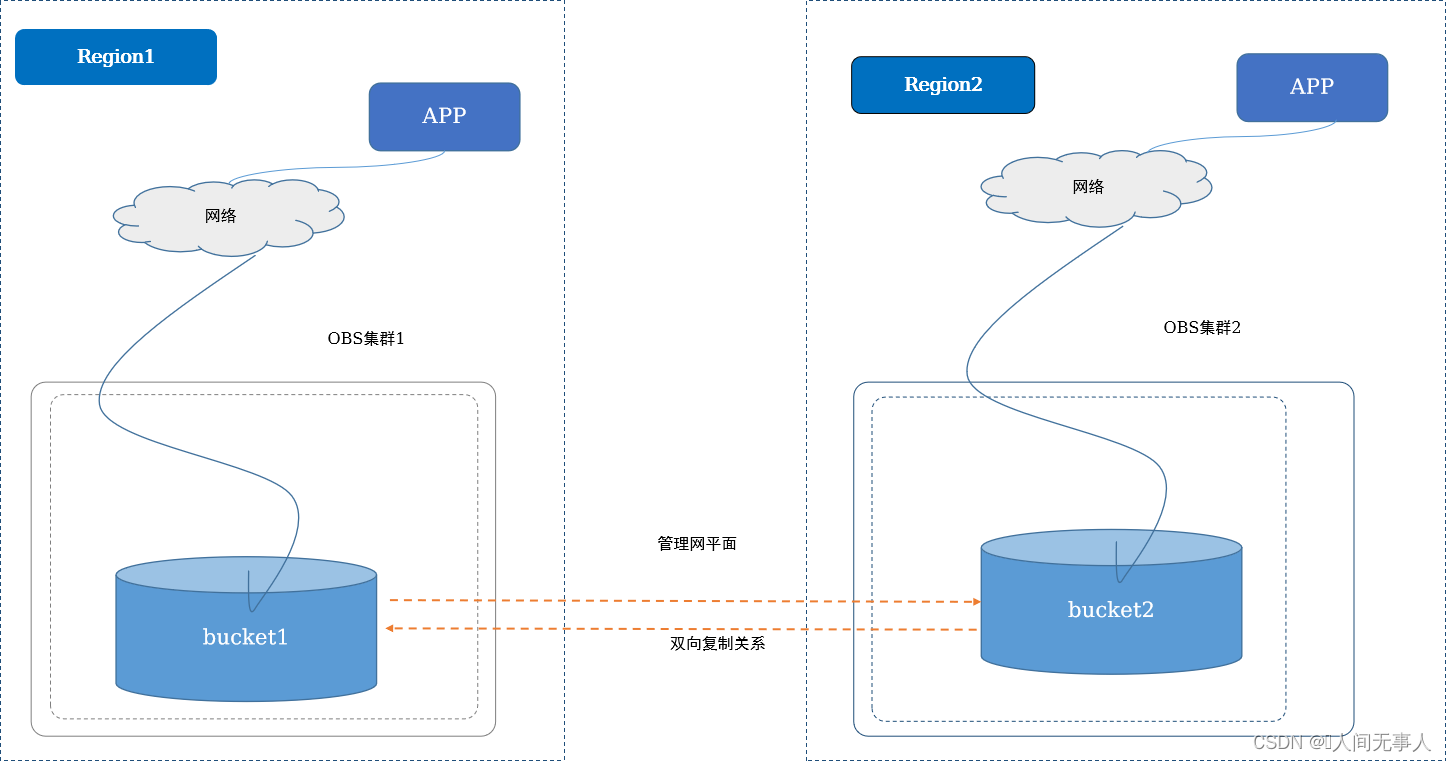
- OBS跨区域复制是指跨不同区域中的桶自动、异步地复制对象。通过激活跨区域复制,OBS可将新创建的对象、更新的对象从一个源桶复制到不同区域中的目标桶
- 异地容灾:源桶的对象上传后可以异步复制到目标桶,当源桶故障后,用户可以访问目标桶里的副本对象
- 就近访问:客户处于两个地理位置,为了最大限度缩短访问对象时的延迟,可以在地理位置与租户较近的区域中维护对象副本等
关键技术实现
- OBS主要技术:
- 复制策略:复制策略是桶级别的,支持复制桶内全部对象,或特定键名称前缀的对象子集,例如,可以将跨区域复制配置为仅复制具有键名称前缀“Tax/”的对象。这会使系统仅复制具有“Tax/doc1”或“Tax/doc2”等键的对象,但不复制具有“Legal/doc3”键的对象
- 复制的内容:对象内容、大小、最后修改时间、创建者、版本号、用户定义的元数据以及AC
- 数据传输安全:跨区域数据传输默认使用SSL加密保障数据安全
- 准实时复制:源对象上传成功后即刻启动复制,当源桶外部压力小于30%时,RPO<=15分钟(区域间带宽和时延不是瓶颈的情况下),同时可以通过QoS控制复制性能
- 双向复制关系:数据复制要求从主集群复制到备集群。在主集群故障后,由管理员进行手工切换,主降备,备升主,对外继续提供服务。接收新的写IO,待备恢复后,新的数据可被持续复制,实现主备数据一致
- 创建OBS跨Region复制:
- OBS在每个Region是独立的,有独立的Region域名,OBS提供跨Region的数据复制,外部应用APP在云内应该有独立部署,在单一Region故障后,不影响另一个Region正常提供OBS服务
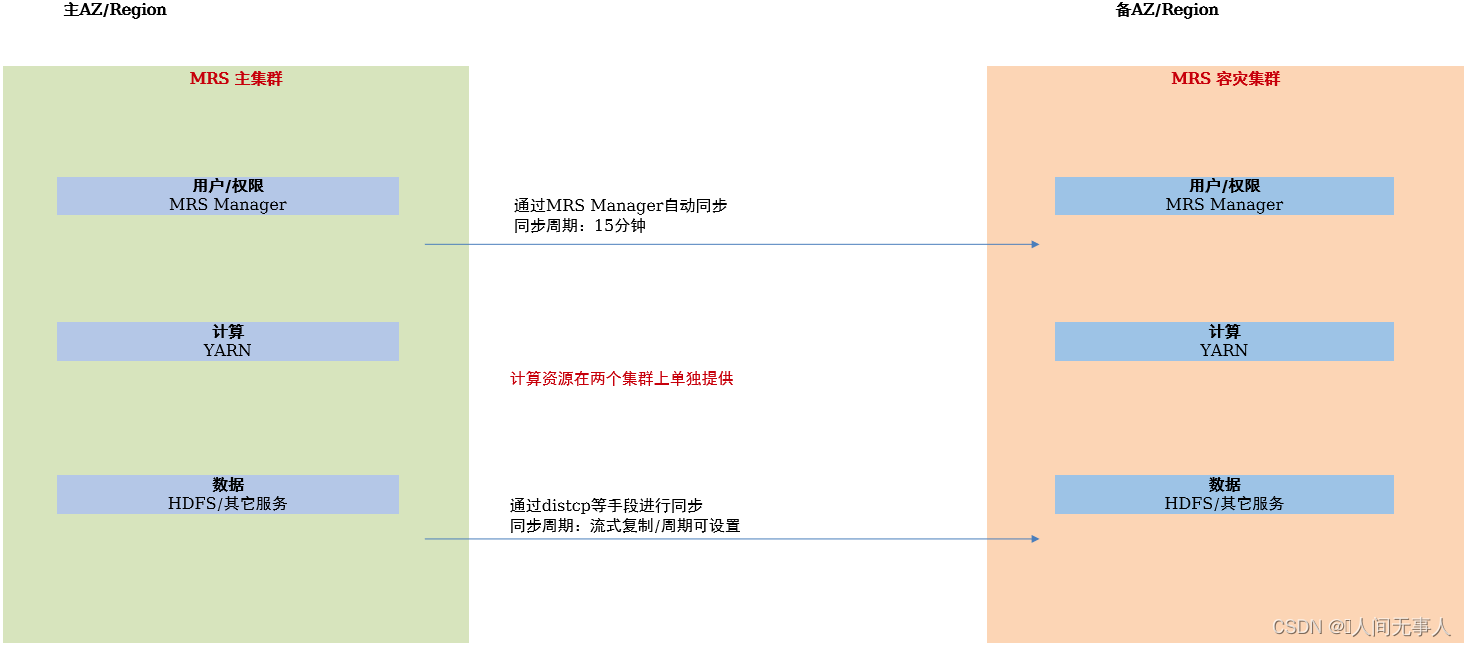
跨Region复制技术实现
-
MRS支持通过主备集群方式实现跨AZ/Region容灾,用于应对机房/城市级的重大灾难,可以实现小时级别的RPO和RTO
-
主集群/容灾集群:需要提前规划两个集群。正常使用时,主集群提供数据和计算资源,同时主集群将数据向容灾集群进行复制。当主集群发生灾难时,备集群可以替代主集群提供数据和计算资源。容灾集群主用时,支持数据从容灾集群向主集群进行同步。支持手工切换主用备用关系。不要求两个集群规模相等
-
周期性复制与流式复制:
- 周期性复制:周期性将数据向对端进行复制,周期可配置
- 流式复制:实时将数据的变化向对端同步,通过RPO指标衡量当前未同步内容
-
保护组与保护策略:支持按照要保护的数据设置保护组,一个保护组内可以包含多个服务(仅周期性)。支持基于保护组设置保护策略,例如要保护的数据、复制周期等。支持基于保护组进行启用和禁用,以及查看进度和历史日志
-
主要容灾操作:
- 配置容灾保护:指定主集群和容灾集群,以及相应服务之间的保护关系(配对)
- 保护组管理:创建保护组,启用和禁用保护组,查看保护组执行状态和历史
- 计划性迁移:即主动发起的“主备切换”,迁移前会确保数据充分同步
- 故障恢复:即主集群发生灾难后,备集群接管业务。此时不能保证数据充分同步
-
业务的迁移:MRS作为平台层,可以保证数据和计算资源的容灾。但在进行主备切换时,需要用户配合进行业务迁移,例如更换服务端IP地址等。不支持用户业务无感知的容灾切换
| 组件 | 复制方式 | 保护对象和复制原理 |
|---|---|---|
| HDFS | 周期性 | 支持对指定的目录进行容灾保护,使用distcp方式进行增量数据复制 |
| HBase | 流式 | 支持对用户业务表进行容灾保护,主集群的每个RegionSever实例将接收到的数据推送给备集群的HBase服务 |
| Hive | 周期性 | 支持指定要保护的表,利用Metastore服务的接口查询并同步表元数据,利用Hadoop的快照执行Distcp拷贝表数据 |
| Kafka | 流式 | 支持topic的容灾保护,基于MirrorMaker进行跨集群数据同步 |
| Elasticsearch | 流式 | 支持索引数据保护,通过快照+备集群订阅主集群增量操作来进行同步 |
| Redis | 流式 | 支持逻辑集群的保护,基于Redis主备实例间同步协议进行增量同步 |
| Flink | 周期性 | 支持应用数据保护,通过同步DBservice数据+HDFS快照完成数据保护 |
| ClickHouse | 流式 | 支持对分布式表/视图容灾保护,基于ZooKeeper跨集群同步操作日志,ClickHouse利用复制表副本同步能力完成数据容灾保护 |
| Hetu | 周期性 | 支持对本地Hive数据源信息和UDF函数的容灾保护,基于DBservice数据同步+HDFS,Hive容灾能力完成容灾保护 |
学习推荐
-
华为云Stack产品文档:
https://support.huawei.com/hedex/hdx.do?docid=DOC1100925285&path=PBI1-253383977/PBI1-23710112/PBI1-21431666/PBI1-253386765/PBI1-23864287 -
缩略语
| 缩略语 | 英文全称 | 解释 |
|---|---|---|
| DC | data center | 数据中心 |
| AZ | availability zone | 可用区,Region是最高等级的隔离,因为region是地理位置的隔离。AZ是比地理区域(region)低一级的隔离。 |
| NAS | network-attached storage | 网络存储,NAS被定义为一种特殊的专用数据存储服务器,包括存储器件(例如磁盘阵列、CD/DVD驱动器、磁带驱动器或可移动的存储介质)和内嵌系统软件,可提供跨平台文件共享功能。 |
| DNS | domain name server | 网域名称服务器,域名解析需要通过专门的域名解析服务器来完成,DNS就是进行域名解析的服务器。 |