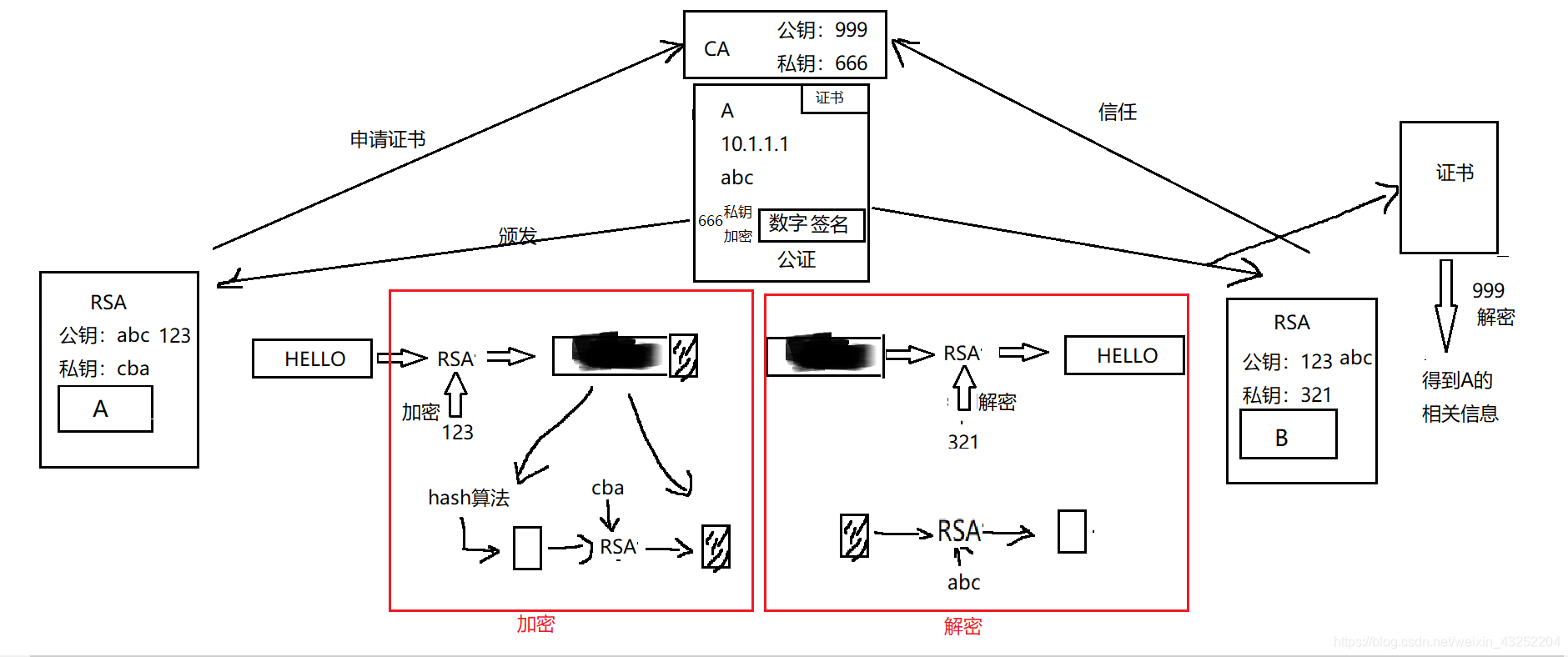
提示
- 该博客主要为个人学习,通过阅读官网手册整理而来(个人觉得阅读官网的英文文档非常有助于理解各个IP特性)。若有不对之处请参考参考文档,以官网参考文档为准。
- AArch64 memory management学习一共分为两章,这是第一章
1. 什么是memory management(内存管理)?
内存管理描述了如何控制对系统中内存的访问。每次OS(操作系统)或应用程序访问内存时,硬件都会执行内存管理。内存管理是一种为应用程序动态分配内存区域的方法。
1.1 为什么需要内存管理?
应用程序处理器被设计为运行一个丰富的操作系统,如Linux,并支持虚拟内存系统。在处理器上执行的软件只能看到虚拟地址,而处理器会将其转换为物理地址。这些物理地址被呈现给内存系统,并指向内存中的实际物理位置。
在AArch64架构中需要内存管理的几个主要原因:
-
虚拟内存: 内存管理支持虚拟内存技术,将逻辑地址空间映射到物理内存上。每个进程都有自己的虚拟地址空间,使得进程之间彼此隔离并且可以独立运行。内存管理负责将虚拟地址转换为对应的物理地址,以实现地址映射和访问控制。
-
内存分配与回收: 内存管理负责动态分配和回收内存资源。它跟踪哪些内存块已被分配给进程,并在进程不再需要时将其释放回可用内存池。这样可以避免内存浪费和耗尽,并确保内存资源的高效利用。
-
内存保护: 内存管理通过页表等机制,为每个进程或应用程序设置访问权限和保护机制。这样可以防止进程之间的互相干扰或访问其他进程的内存空间,从而提高系统的安全性和稳定性。
-
内存映射: 内存管理负责将外部设备(如显卡、网络接口等)的物理内存映射到系统内存空间中。这样,设备可以直接访问系统内存,实现高效的数据传输和交互。
-
页面置换: 内存管理通过页面置换算法,管理可用内存和磁盘之间的数据交换。当物理内存不足时,会使用页面置换机制将一些页从内存移到磁盘上,并将需要的页重新调入内存。这样可以扩大可用内存空间,满足更多进程的需求。
总之,AArch64架构中的内存管理在系统层面上负责有效地分配、保护和优化物理内存资源。它为每个进程提供独立的虚拟地址空间,管理内存分配和回收,确保内存保护和安全,支持设备内存映射,并通过页面置换机制增加系统的可用内存空间。这些功能都是为了提高系统的性能、稳定性和安全性。
2 虚拟地址和物理地址
使用虚拟地址的好处
- 允许管理软件,如操作系统(OS),来控制呈现给软件的内存视图
操作系统可以控制哪块内存是可见的,该内存是可见的虚拟地址,以及允许对该内存的访问。这允许操作系统使用sandbox应用程序(从另一个应用程序中隐藏一个应用程序的资源),并提供来自底层硬件的abstraction(该单词翻译出来反倒有点抽象)。总之,可以理解为,使用虚拟地址比直接访问物理地址更加容易管理。 - 操作系统可以将内存的多个碎片物理区域作为单一的连续虚拟地址空间呈现给应用程序
- 提高开发效率
虚拟地址也有利于软件开发人员,他们在编写应用程序时将不知道系统的真实物理内存地址。有了虚拟地址,软件开发人员就不需要关心物理内存了。
在实际发开中,每个应用程序都可以使用自己的虚拟地址集,这些地址将映射到物理系统中的不同位置。当操作系统在不同的应用程序之间切换时,它会重新编程映射关系。这意味着当前应用程序的虚拟地址将映射到内存中真实物理位置。
虚拟地址通过映射被转换为物理地址。虚拟地址和物理地址之间的映射存储在转换表(有时也称为页表)中,如下图所示:

转换表(Translation Tables)在内存中,由软件管理,通常是操作系统或管理程序。转换表不是静态的,这些表是根据软件更改而更新。这将更改虚拟地址和物理地址之间的映射。
3 地址空间
下图显示了在AArch64中的虚拟地址空间(以Armv8-A为例):

该表展示了三个虚拟地址空间
- Non-secure EL0 and EL1
- Non-secure EL2
- EL3
关于Secure,Non-secure. EL0~EL3将会放到Exception章节博客讲解
上述每个虚拟地址空间都是独立的,并且都有自己的设置和表。我们经常称这些设置和表为“translation regimes(转换机制)”。Secure EL0、Secure EL1和Secure EL2也有虚拟地址空间,但它们没有显示在图中。
在Armv8.4-A中添加了Secure EL2
因为存在多个虚拟地址空间,所以指定地址所在的地址空间很重要。例如,NS.EL2:0x8000是指在Non-secure EL2虚拟地址空间中的地址0x8000。
该图还显示了来自Non-secure EL0和Non-secure EL1的虚拟地址都经过了两组表(Guest OS Tables, Virtulization Tables)。这些表支持虚拟化,并允许hypervisor(管理程序?该单词翻译出来有点抽象,实际上就是一种模式,下面出现这个单词不在解释)虚拟化虚拟机(VM)所看到的物理内存。
Armv9-A支持上述针对Armv8-A的所有虚拟地址空间。Armv9-A引入了可选的领域管理扩展(Realm Management Extension,RME)。当实现RME时,还存在额外的转换机制:
- Realm EL1 and EL0
- Realm EL2 and EL0
- Realm EL2
关于RME将会放到RME章节博客讲解
在虚拟化中,我们将由操作系统(OS)控制的转换集(set of translations)称为阶段1(Stage 1)。阶段1的表将虚拟地址转换为中间物理地址(IPAs)。在阶段1中,操作系统(OS)认为IPAs是物理地址空间。然而,hypervisor控制着第二组转换,我们称之为阶段2(Stage 2)。这第二组将IPAs转换为物理地址。下图显示了这两组转换的工作原理:

虽然表格格式有一些细微的差异,但阶段1和阶段2的转换过程通常是相同的。
在Arm中,许多示例中都使用了地址0x8000。0x8000也是Arm链接器(armlink)链接的默认地址。这个地址来自一台早期的微型计算机,BBC Micro Model B,它有ROM(和sideways(横向?) RAM)在地址0x8000。BBC Micro Model B是由一家名为Acorn的公司制造的,该公司开发了Acorn RISC Machine(ARM),后来成为Arm。
3.1 物理地址
除了多个虚拟地址空间外,AArch64还具有多个物理地址空间(physical address spaces PAS):
- Non-secure PAS0
- Secure PAS
- Realm PAS (Armv9-A only)
- Root PAS (Armv9-A only)
虚拟地址可以映射到哪个物理地址空间决于处理器的当前安全状态(Security state)。下面的列表显示了安全状态及其对应的虚拟地址映射目标: - Non-secure state: 虚拟地址只能映射到非安全(Non-secure)的物理地址。
- Secure state: 虚拟地址可以映射到安全(Secure)的或非安全(Non-secure)的物理地址
- Realm state: 虚拟地址可以映射到Realm或非安全(Non-secure)的物理地址
- Root state: 虚拟地址可以映射到任何物理地址空间
当处于具有多个物理地址空间可见的安全状态时,转换表入口处(translation table
entries)控制使用哪个输出物理地址空间。下图显示了多个物理地址空间的映射:

3.2 地址大小
AArch64是一个64位的体系结构,但这并不意味着所有的地址都是64位的。
3.3 虚拟地址大小
虚拟地址以64位的格式存储。因此,加载指令(LDR)和存储指令(STR)中的地址总是在X寄存器中指定。但是,并非X寄存器中的所有地址都有效。
下图显示了AArch64中的虚拟地址空间的布局:

EL0/EL1虚拟地址空间有两个区域:内核空间和应用程序空间。这两个区域显示在图的左侧,顶部是内核空间(Kernel Space),以及底部的应用程序空间,它被标记为“用户空间(User Space)”。内核空间和用户空间有单独的转换表,这意味着它们的映射可以保持独立。
对于所有其他异常级别而言,在地址空间的底部有一个单独的区域。这个区域显示在图表的右侧,是一个没有内容的box(方框?)。
如果设置HCR_EL2.E2H=1,则将使能运行在EL2中的host OS(主机操作系统?)配置,以及运行在EL0中的应用配置。在这种情况下,EL2也有一个上区域和一个下区域(region)。
每个地址空间的区域大小达52位。然而,每个区域都可以独立地缩小到一个更小的尺寸。TCR_ELx寄存器中的TnSZ位控制着虚拟地址空间的大小。例如,下图显示了TCR_EL1控制EL0/EL1虚拟地址空间:

虚拟地址的大小编码计算公式:
virtual address size in bytes = 264 -TCR_ELx.TnSZ
虚拟地址的大小也可以表示为地址位的数量:
Number of address bits = 64 - TnSZ
因此,如果将TCR_EL1.T1SZ设置为32,则EL0/EL1虚拟地址空间中的内核区域的大小为232字节(0xFFFF_FFFF_0000_0000到0xFFFF_FFFF_FFFF_FFFF)。任何超出配置范围或范围的地址在访问时将产生异常。这种配置的优点是,我们只需要描述尽可能多的地址空间,这就节省了时间和空间。例如,假设OS内核需要1GB的地址空间(30位的地址大小)来实现其内核空间。如果操作系统将T1SZ设置为34,则只创建1GB的转换表入口处(translation table
entries),如64 - 34 = 30。
所有的Armv8-A实现都支持48位的虚拟地址。支持52位虚拟地址是可选的,并由ID_AA64MMFR2_EL1报告。但是,没有一个Arm Cortex-A处理器支持52位虚拟地址。
3.4 物理地址大小
物理地址的大小是IMPLEMENTATION DEFINED(实现定义)的,最多52位。ID_AA64MMFR0_EL1寄存器报告大小由处理器实现。对于Arm Cortex-A处理器,通常是40位或44位。
在Armv8.0-A中物理地址的最大是48位。在Armv8.2-A中被扩展到52位。
3.5 中间物理地址的大小
如果在转换表入口处(translation table entries)指定的输出地址大于实现的最大值,内存管理单元(MMU)将产生地址大小异常。
IPA空间的大小可以和虚拟地址空间相同的方式进行配置。VTCR_EL2.T0SZ控制大小。可以配置的最大大小与处理器支持的物理地址大小相同。这意味着你不能配置比所支持的物理地址空间更大的IPA空间。即中间物理地址大小必须小于等于物理地址大小。
3.6 地址空间标识符 - 使用已拥有的进程来标记翻译
许多现代操作系统(OS)的应用程序似乎都运行在同一个地址区域,这就是我们所描述的用户空间。在实践中,不同的应用程序需要不同的映射。这意味着,例如,VA 0x8000的翻译取决于当前正在运行的哪个应用程序。
理想情况下,我们希望不同应用程序的转换在转换查找缓冲区(Translation
Lookaside BuffersT, LBs)中共存,以防止在上下文切换上需要TLB失效。但是处理器如何知道要使用哪个版本的VA 0x8000翻译呢?在AArch64中,答案是地址空间标识符(Address Space Identifiers, ASIDs)。
对于EL0/EL1虚拟地址空间,可以使用转换表项的属性字段中的nG位将转换标记为全局(G)或非全局(nG)。例如,内核映射是全局转换,应用映射是非全局转换。全局转换应用于当前正在运行的任何应用程序。非全局转换仅适用于特定的应用程序。
非全局映射在TLBs中用ASID进行标记。在TLB查找中,将TLB入口中的ASID与当前选择的ASID进行比较。如果它们不匹配,则不使用TLB入口。下图显示了内核空间中没有ASID标记的全局映射和用户空间中带有ASID标记的非全局映射:

上图显示了多个应用程序的TLB入口允许在缓存中共存,并且ASID决定使用哪个入口。
ASID存储在两个TTBRn_EL1寄存器中的一个中。TTBR0_EL1通常用于用户空间。因此,单个寄存器更新可以同时更改ASID和它所指向的转换表。
在2023年,Arm引入了同时指定两个ASIDs的能力。从Armv9.5-A中,软件可以选择在两个TTBRn_EL1寄存器中使用ASID字段。TTBR0_EL1.ASID应用于虚拟地址空间的下部的地址和TTBR1_EL1.ASID到虚拟地址空间上部的地址。
ASID标记也可以在EL2中使用,通过设置HCR_EL2.E2H = 1
3.7 虚拟机标识符 - 使用所拥有的虚拟机(VM)来标记翻译
EL0/EL1的转换也可以用虚拟机标识符(VMID)进行标记。VMIDs允许来自不同VM的转换在缓存中共存。这类似于ASID转换来自不同应用程序的工作方式。在实际中,这意味着一些转换将同时被标记为VMID和ASID,并且两者都必须匹配才能使用TLB入口。
当安全状态支持虚拟化时,EL0/EL1转换总是用VMID标记,即使没有启用阶段2(Satge 2)转换也是如此。这意味着,如果您正在编写初始化代码而没有使用hypervisor(系统管理程序?),那么在设置Stage 1 MMU之前设置一个已知的VMID值是很重要的。
3.8 Common not Private
如果一个系统包含多个处理器,那么在一个处理器上使用的ASIDs和VMIDs在其他处理器上是否具有相同的含义?
对于Armv8.0-A,它们不必意味着相同的东西。这里没有要求软件在多个处理器上以相同的方式使用给定的ASID。例如,ASID 5可能被一个处理器上的计算器使用,可能被另一个处理器上的web浏览器使用。这意味着由一个处理器创建的TLB入口不能被另一个处理器使用。
在实践中,软件不太可能在不同的处理器之间使用不同的ASIDs。软件在给定系统中的所有处理器上以相同的方式使用ASIDs和VMIDs更为常见。因此,Armv8.2-A在转换表基寄存器(Translation Table
Base RegisterT,TBR)中引入了通用非私有(Common not Private,CnP)位。当设置了CnP位时,该软件允许在所有处理器上以相同的方式使用ASIDs和VMIDs,这允许由一个处理器创建的TLB入口被另一个处理器使用。
我们一直在谈论处理器,但是,从技术上讲,我们应该使用处理单元(Processing Element, PE)这个术语。PE是对实现Arm架构的任何机器的通用术语。这很重要,因为在处理器之间共享TLBs是困难的。但是在一个多线程处理器中,每个硬件线程都是一个PE,它更希望共享TLB入口。
参考文档
Learn the architecture - AArch64 memory management