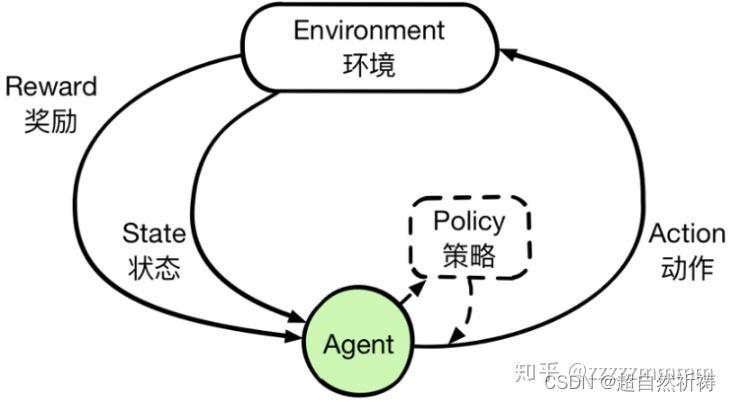
TcpConnection:封装的就是建立连接之后得到的用于通信的文件描述符,然后基于这个文件描述符,在发送数据的时候,需要把数据先写入到一块内存里边,然后再把这块内存里边的数据发送给客户端,除了发送数据,剩下的就是接收数据。接收数据,把收到的数据先存储到一块内存里边。也就意味着,无论是发送数据还是接收数据,都需要一块内存。并且这块内存是需要使用者自己去创建的。所以就可以把这块内存做封装成Buffer。

>>>>>>>>>>>>>>>>>>>>>>>>>>>>学习笔记>>>>>>>>>>>>>>>>>>>>>>>>>>>>
1.文件描述符与数据发送:
- 在发送数据时,需要先将数据写入内存缓冲区(buffer)。
- 内存缓冲区可以通过封装成一个Buffer结构体来实现
- Buffer结构体中包含一个指向内存的指针(data)、内存总大小(capacity)、读数据位置(readPos)和写数据位置(writePos)等成员
2.Buffer结构体及其成员说明:
- 指针:指向内存地址(data)
- 总大小:内存块的字节数(capacity)
- 读位置:当前读取数据的位置(readPos)
- 写位置:当前写入数据的位置(writePos)
3.Buffer API函数:
- 提供一系列API函数,以便对buffer中的内存进行操作
- 主要操作包括初始化buffer和进行读写操作
4.初始化Buffer:
- 需要为buffer申请指定大小的堆内存
- 使用malloc函数申请堆内存,并将内存地址返回给调用者
- 初始化buffer结构体中的成员,包括data指针、容量、读位置和写位置
- data指针需要指向一个有效的内存块,因此需要再次申请内存
- 使用memset函数将data指针指向的内存块初始化为零
- 返回buffer指针给调用者
>>>>>>>>>>>>>>>>>>>>>>>>>>>>Buffer的创建和销毁>>>>>>>>>>>>>>>>>>>>>>>>>>>>
- Buffer.h
struct Buffer {
// 指向内存的指针
char* data;
int capacity;
int readPos;
int writePos;
}(一)Buffer的初始化
// 初始化
struct Buffer* bufferInit(int size);// 初始化
struct Buffer* bufferInit(int size) {
struct Buffer* buffer = (struct Buffer*)malloc(sizeof(struct Buffer));
if(buffer!=NULL) {
buffer->data = (char*)malloc(sizeof(char) * size);
buffer->capacity = size;
buffer->readPos = buffer->writePos = 0;
memset(buffer->data, 0, size);
}
return buffer;
}(二)Buffer的销毁
// 销毁
void bufferDestroy(struct Buffer* buf);// 销毁
void bufferDestroy(struct Buffer* buf) {
if(buf!=NULL) {
if(buf->data!=NULL) { // buf->data指向有效的堆内存
free(buf->data); // 释放
}
}
free(buf);
}>>>>>>>>>>>>>>>>>>>>>>>>>>>>Buffer的扩容>>>>>>>>>>>>>>>>>>>>>>>>>>>
(一)readPos和writePos 相对位置发生变化的三种情况:
(1)Buffer初始时 - 未写入任何数据

(2)Buffer - 写入了部分数据

- 剩余的可写的内存容量 = 可写数据内存大小
// 得到剩余的可写的内存容量
int bufferWriteableSize(struct Buffer* buf);// 得到剩余的可写的内存容量
int bufferWriteableSize(struct Buffer* buf) {
return buf->capacity - buf->writePos;
}(3)Buffer - 写入了部分数据并读出了部分数据

- 计算已写数据内存(未读)的大小
// 已写数据内存(未读)的大小 --- 得到剩余的可读的内存容量
int bufferReadableSize(struct Buffer* buf);// 已写数据内存(未读)的大小 --- 得到剩余的可读的内存容量
int bufferReadableSize(struct Buffer* buf) {
return buf->writePos - buf->readPos;
}对于内存数据已读的区域的数据为无效数据,此处的无效指的是内存数据,由于数据已经被读了出来,故这里边的数据已经无效了。对于这个图来说,剩余的可用内存块一共有多大呢?
- 剩余的可写的内存容量 = 内存数据已读大小 + 可写数据内存大小
但这个是理论值,因为这两块内存不是连续的,故即使空间够存储,但是不连续的存放会导致读写麻烦。此时的解决方案是:移动内存实现合并内存
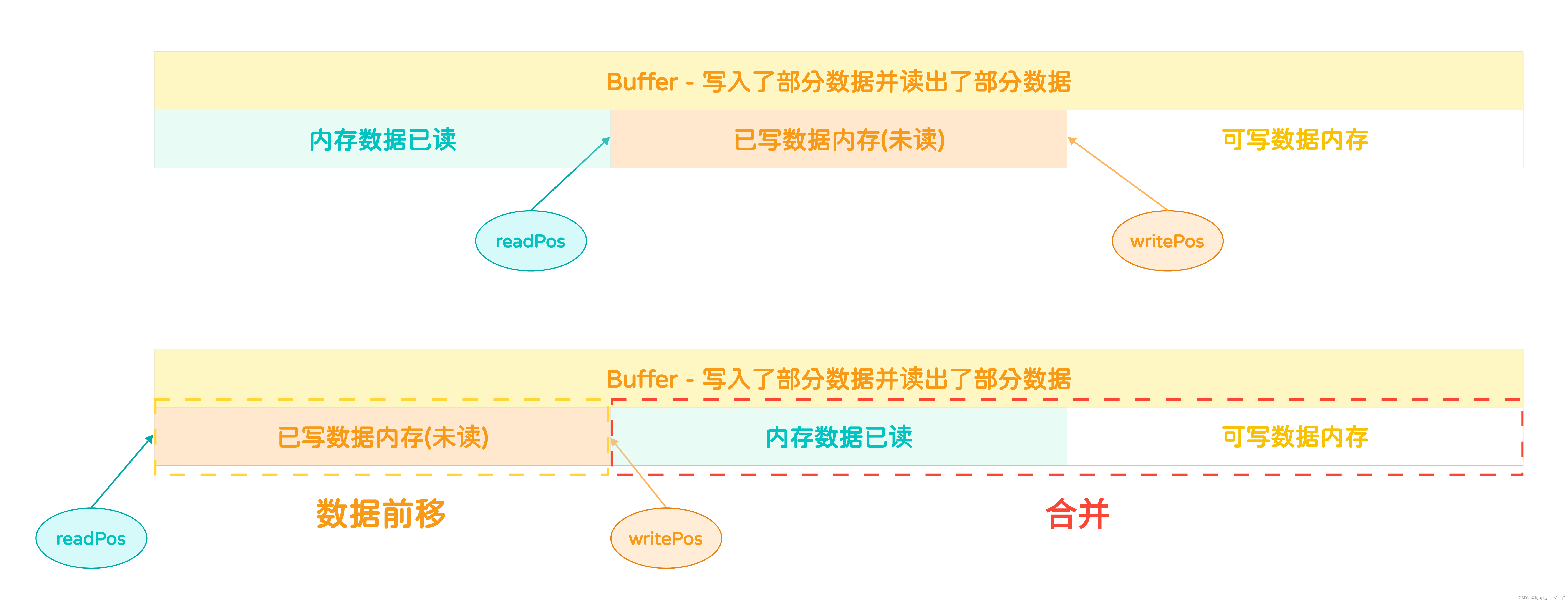
(1)先获取已写数据内存(未读)这块内存的大小,将值赋给readableSize
// 得到已写但未读的内存大小
int readableSize = bufferReadableSize(buf);(2)然后把这块内存的数据拷贝到前面去,这就实现了合并
// 移动内存实现合并
memcpy(buf->data, buf->data + buf->readPos, readableSize);(3)更新位置
// 更新位置
buf->readPos = 0;
buf->writePos = readableSize;(二)Buffer扩容
当往buffer中写入数据时,如果剩余的内存不足以容纳新的数据,需要进行扩容。有三种情况需要考虑:
- 剩余的可写的内存容量够用- 不需要扩容
- 内存需要合并才够用 - 不需要扩容
- 内存不够用 - 需要扩容
// 扩容
void bufferExtendRoom(struct Buffer* buf, int size);// 扩容
void bufferExtendRoom(struct Buffer* buf, int size) {
// 1.内存够用 - 不需要扩容
if(bufferWriteableSize(buf)>= size) {
return;
}
// 2.内存需要合并才够用 - 不需要扩容
// 剩余的可写的内存 + 已读的内存 >= size
else if(bufferWriteableSize(buf) + bufferReadableSize(buf) >= size) {
// 得到已写但未读的内存大小
int readableSize = bufferReadableSize(buf);
// 移动内存实现合并
memcpy(buf->data, buf->data + buf->readPos, readableSize);
// 更新位置
buf->readPos = 0;
buf->writePos = readableSize;
}
// 3.内存不够用 - 需要扩容
else{
void* temp = realloc(buf->data, buf->capacity + size);
if(temp ==NULL) {
return;// 失败了
}
memset(temp + buf->capacity, 0, size);// 只需要对拓展出来的大小为size的内存块进行初始化就可以了
// 更新数据
buf->data = temp;
buf->capacity += size;
}
}>>>>>>>>>>>>>>>>>>>>>>>>>>>>往Buffer里写入数据>>>>>>>>>>>>>>>>>>>>>>>>>>>
(1)直接写
// 写内存 1.直接写
int bufferAppendData(struct Buffer* buf, const char* data, int size);
int bufferAppendString(struct Buffer* buf, const char* data); // 写内存 1.直接写
int bufferAppendData(struct Buffer* buf, const char* data, int size) {
// 判断传入的buf是否为空,data指针指向的是否为有效内存,以及数据大小是否大于零
if(buf == NULL || data == NULL || size <= 0) {
return -1;
}
// 扩容(试探性的)
bufferExtendRoom(buf,size);
// 数据拷贝
memcpy(buf->data + buf->writePos, data, size);
// 更新写位置
buf->writePos += size;
return 0;
}
int bufferAppendString(struct Buffer* buf, const char* data) {
int size = strlen(data);
int ret = bufferAppendData(buf, data, size);
return ret;
}实现bufferAppendData函数重点:
1. 实现写内存函数时,需要判断传入的buf是否为空,data指针指向的是否为有效内存,以及数据大小是否大于零
2. 在写数据之前,需要进行内存扩容(试探性的,可能剩余的可写容量就够写入那就不必扩容)
3. 写数据时,需要从上次写入的writePos位置开始
4. 数据写入完成后,需要更新writePos的位置
总结:在实现bufferAppendData函数时,需要考虑如何处理内存的写入和接收数据的情况。在写数据之前,可能需要进行内存扩容以确保有足够的空间。写数据时,需要从上次写入的writePos位置开始。完成写入后,需要再次更新writePos的位置。
(2)接收套接字数据
#include <sys/uio.h>
ssize_t readv(int fd, const struct iovec *iov, int iovcnt);
struct iovec {
void *iov_base; /* Starting address */
size_t iov_len; /* Number of bytes to transfer */
};
功能:readv函数从文件描述符(包括TCP Socket)中读取数据,并将读取的数据存储到指定的多个缓冲区中。
-> 成功时返回接收的字节数,失败时返回-1
filedes 传递接收数据的文件(套接字)描述符
iov 包含数据保存位置和大小的iovec结构体数组的地址值
iovcnt 第二个参数中数组的长度
fd:要读取数据的文件描述符,可以是TCP Socket。
iov:存储读取数据的多个缓冲区的数组。
iovcnt:缓冲区数组的长度。
返回值:成功时返回实际读取的字节数,失败时返回-1,并设置errno变量来指示错误的原因。
read/recv/readv 在接收数据的时候,
- read/recv 只能指定一个数组
- readv 能指定多个数组(也就是说第一个用完,用第二个...)
readv函数可以一次接收多个缓冲区中的数据,并在内核中减少了多次系统调用的开销。
// 写内存 2.接收套接字数据
int bufferSocketRead(struct Buffer* buf,int fd);- bufferSocketRead函数实现功能:当调用这个bufferSocketRead函数之后,一共接收到了多少个字节
- bufferSocketRead函数具体细节:在这个函数里边,通过malloc申请了一块临时的堆内存(tmpbuf),这个堆内存是用来接收套接字数据的。当buf里边的数组容量不够了,那么就使用这块临时内存来存储数据,还需要把tmpbuf这块堆内存里边的数据再次写入到buf中。当用完了之后,需要释放内存。
注意事项
- 使用者在调用readv函数时需要准备结构体的数组
- 在接收数据时,如果内存已满,数据将被写入下一个结构体中的内存
- 计算buf里边的数组中剩余的写操作内存
内存的扩展和拷贝
- 调用bufferAppendData函数来实现
// 写内存 2.接收套接字数据
int bufferSocketRead(struct Buffer* buf,int fd) {
struct iovec vec[2]; // 根据自己的实际需求来
// 初始化数组元素
int writeableSize = bufferWriteableSize(buf); // 得到剩余的可写的内存容量
// 0号数组里的指针指向buf里边的数组,记得 要加writePos,防止覆盖数据
vec[0].iov_base = buf->data + buf->writePos;
vec[0].iov_len = writeableSize;
char* tmpbuf = (char*)malloc(40960); // 申请40k堆内存
vec[1].iov_base = buf->data + buf->writePos;
vec[1].iov_len = 40960;
// 至此,结构体vec的两个元素分别初始化完之后就可以调用接收数据的函数了
int result = readv(fd, vec, 2);// 表示通过调用readv函数一共接收了多少个字节
if(result == -1) {
return -1;// 失败了
}
else if (result <= writeableSize) {
// 说明在接收数据的时候,全部的数据都被写入到vec[0]对应的数组里边去了,全部写入到
// buf对应的数组里边去了,直接移动writePos就好
buf->writePos += result;
}
else {
// 进入这里,说明buf里边的那块内存是不够用的,
// 所以数据就被写入到我们申请的40k堆内存里边,还需要把tmpbuf这块
// 堆内存里边的数据再次写入到buf中。
// 先进行内存的扩展,再进行内存的拷贝,可调用bufferAppendData函数
// 注意一个细节:在调用bufferAppendData函数之前,通过调用readv函数
// 把数据写进了buf,但是buf->writePos没有被更新,故在调用bufferAppendData函数
// 之前,需要先更新buf->writePos
buf->writePos = buf->capacity; // 需要先更新buf->writePos
bufferAppendData(buf, tmpbuf, result - writeableSize);
}
free(tmpbuf);
return result;
}>>总结: 在实现内存扩容函数时,需要考虑如何处理内存的写入和接收数据的情况。写数据之前可能需进行内存扩容,并从上次写入的writePos位置开始,完成写入后再次更新writePos的位置。
写内存的方式
- 直接写入:将数据存储到buf结构体对应的内存空间
- 基于套接字接收数据:使用readv等函数
写内存函数的考虑因素
- 判断指针指向的是否为有效内存
- 数据大小是否大于零
内存扩容的必要性
- 在写数据之前,需要进行内存扩容以确保有足够的空间
数据写入的过程
- 从上次写入的writePos位置开始
- 数据写入完成后,再次更新writePos的位置






![[VUE]1-创建vue工程](https://img-blog.csdnimg.cn/direct/50b80eff3a584e3da9ba731839a81687.png)