一. 爬虫的方式:
主要有2种方式:
①Scrapy+Xpath (API 静态 爬取-直接post get)
②selenium+Xpath (点击 动态 爬取-模拟)
Scrapy+Xpath
XPath 是 Scrapy 中常用的一种解析器,可以帮助爬虫定位和提取 HTML 或 XML 文档中的数据。
Scrapy 中使用 XPath 的方式和普通的 Python 程序基本一致。我们需要首先导入 scrapy 的 Selector 类和 scrapy 的 Request 类,然后使用 Selector 类来解析 Response 对象,并使用 XPath 表达式来定位和提取数据。
详细讲解可以参考:Scrapy爬虫学习笔记之二(Xpath的用法) - 知乎
selenium+Xpath
Selenium 是为了解决 requests 无法直接执行 JavaScript 代码的问题。本质是通过驱动浏览器,完全模拟浏览器的操作,输入、点击、下拉等。
安装:pip install selenium
使用需要下载浏览器驱动,并且驱动要跟浏览器版本对应
chrome浏览器版本在114之前
浏览器版本在114之前,可以进入以下网址http://chromedriver.storage.googleapis.com/index.html,直接下载相应的文件
chrome浏览器版本在115以上
以下版本皆为chromedriver版本
例如:version : 119.0.6045.21,你电脑的浏览器版本为其他版本,如118.0.5952.2,只需要把链接中的版本号替换成这个编号即可
| 平台 | 下载地址 |
| linux64 | http:// https://edgedl.me.gvt1.com/edgedl/chrome/chrome-for-testing/119.0.6045.21/linux64/chromedriver-linux64.zip |
| mac-arm64 | https://edgedl.me.gvt1.com/edgedl/chrome/chrome-for-testing/119.0.6045.21/mac-arm64/chromedriver-mac-arm64.zip |
| mac-x64 | https://edgedl.me.gvt1.com/edgedl/chrome/chrome-for-testing/119.0.6045.21/mac-x64/chromedriver-mac-x64.zip |
| win32 | https://edgedl.me.gvt1.com/edgedl/chrome/chrome-for-testing/119.0.6045.21/win32/chromedriver-win32.zip |
| win64 | https://edgedl.me.gvt1.com/edgedl/chrome/chrome-for-testing/119.0.6045.21/win64/chromedriver-win64.zip |
Chromedriver 插件安装教程
参考:稳扎稳打学爬虫09—chromedriver下载与安装方法-CSDN博客
下面简单使用模拟百度搜索:
import time
from selenium import webdriver
bro = webdriver.Chrome(executable_path='./chromedriver.exe') # 得到一个谷歌浏览器对象,并指定使用那个驱动
bro.implicitly_wait(5) # 隐士等待:找一个控件,如果控件没有加载出来,就等待5S,只需要写着一句,以后所有控件都按照这个操作来
bro.get('https://www.baidu.com') # 在地址栏里输入百度
input_k = bro.find_element_by_id('kw') # 找到百度输入框对应的控件
input_k.send_keys('火灾火焰') # 框里面输入python
sou = bro.find_element_by_id('su') # 找到搜索按钮
sou.click() # 点击搜索按钮
time.sleep(3)
bro.close() # 关闭浏览器
selenium详细用法参考:https://www.cnblogs.com/XiaoYang-sir/p/15173174.html
二. selenium+xpath
利用selenium获取元素定位方法,爬取百度图片
通过定位获取完整爬取图片的超链接信息,鼠标放置百度页面右键=》检测
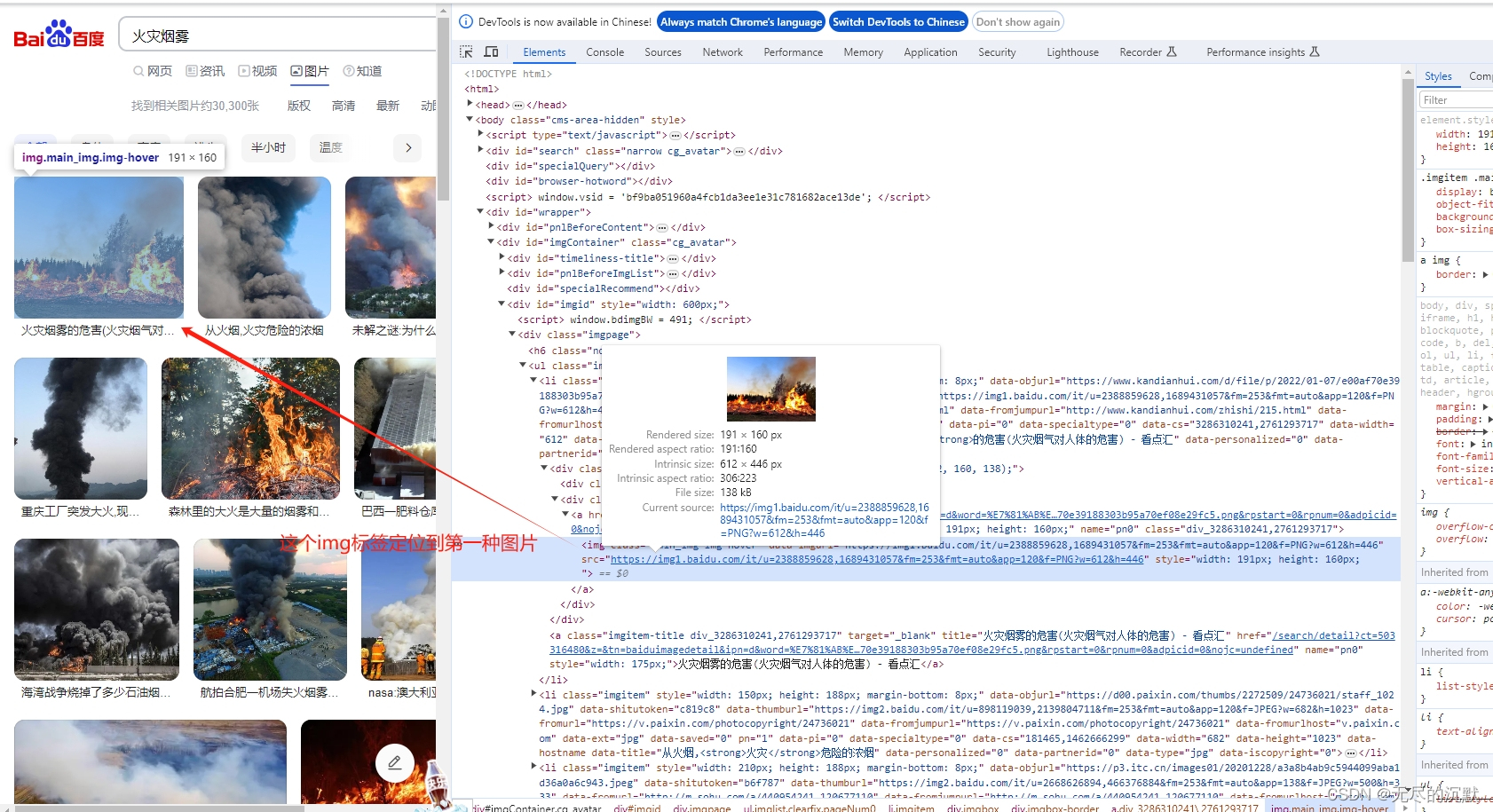
完整爬取代码
'''
注释:
@author is leilei
百度图片爬虫,采用selenium模拟鼠标点击形式
1. 将要搜索的文本表示成list
2. 打开百度图片官网,输入文本,搜索
3. 逐条下载对应的图片
注:
本代码支持断点续爬!
'''
import os
import uuid
import time
import random
import urllib
import urllib.request
from selenium import webdriver
from selenium.webdriver.common.keys import Keys # 键盘类
#爬取的种类图片
NameList=['火灾火焰', '火灾烟雾']
def send_param_to_baidu(name, browser):
'''
:param name: str
:param browser: webdriver.Chrome 实际应该是全局变量的
:return: 将要输入的 关键字 输入百度图片
'''
# 采用id进行xpath选择,id一般唯一
inputs = browser.find_element_by_xpath('//input[@id="kw"]')
inputs.clear()
inputs.send_keys(name)
time.sleep(1)
inputs.send_keys(Keys.ENTER)
time.sleep(1)
return
'''
写Python爬虫的时候,没过多久Python就会报错,然后停止采集。总是没办法从头到尾把数据采集下来。
每一下次报错我都要去找原因,比如我要采集的标签里面没有URL,URL为空就会报错,
或者页面没有URL也会报错。于是我是用try…except语句跳过错误,但是还是会遇到其他问题,
就是try…except语句只能跳过一次错误,第二次错误就会失效。所以采用了下面这种mistaken方法处理异常。
'''
def mistaken():
try:
print('*****出现异常错误,跳过此次循环,爬取无内容*****')
######采集代码##########
print('——————————接下来继续运行——————————')
except:
mistaken()
def download_baidu_images(save_path, img_num, browser):
''' 此函数应在
:param save_path: 下载路径 str
:param img_num: 下载图片数量 int
:param name: 爬取种类的名字
:param browser: webdriver.Chrome
:return:
'''
if not os.path.exists(save_path):
os.makedirs(save_path)
##下面是打开第一张图片,然后在此界面中点击左右切换图片
# // *[ @ id = "imgid"]/div[1]/ul/li[1]/div/div[2]/a/img
#如果这里报错,其中下面这里的定位地址,需要根据百度你爬取的图片的位置进行相应的修改
img_link = browser.find_element_by_xpath(' //*[@id = "imgid"]/div[1]/ul/li[1]/div/div[2]/a/img')
img_link.click()
# 切换窗口
windows = browser.window_handles
browser.switch_to.window(windows[-1]) #切换到图像界面
# time.sleep(3)
time.sleep(random.random())
for i in range(img_num):
img_link_ = browser.find_element_by_xpath('//div/img[@class="currentImg"]')
src_link = img_link_.get_attribute('src')
print(src_link)
# 保存图片,使用urlib
img_name = uuid.uuid4()
# urllib.request.urlretrieve(src_link, os.path.join(save_path, str(img_name) + '.jpg'))
# 上述一行代码直接去访问资源会报403错误,排查发现可能是服务器开启了反爬虫,针对这种情况添加headers浏览器头,模拟人工访问网站行为:
opener = urllib.request.build_opener()
# 构建请求头列表每次随机选择一个
ua_list = ['Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:102.0) Gecko/20100101 Firefox/102.0',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.114 Safari/537.36 Edg/103.0.1264.62',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0',
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.81 Safari/537.36 SE 2.X MetaSr 1.0'
]
opener.addheaders = [('User-Agent', random.choice(ua_list))]
urllib.request.install_opener(opener)
#为了不中断程序完整爬取,所以处理爬虫的过程中出现资源请求不到的错误404 或者403的错误,只需要跳过这些错误继续执行
try:
urllib.request.urlretrieve(src_link, os.path.join(save_path, str(img_name) + '.jpg'))
except Exception as e:
print(e)
mistaken()
# 如果网站反爬虫级别特别高的,还需要切换代理ip:使用urllib模块设置代理IP是比较简单的,首先需要创建ProxyHandler对象,其参数为字典类型的代理IP,键名为协议类型(如HTTP或者HTTPS),值为代理链接。然后利用ProxyHandler对象与buildopener()
# 方法构建一个新的opener对象,最后再发送网络请求即可。
# 创建代理IP
# proxy_handler = urllib.request.ProxyHandler({
# 'https': '58.220.95.114:10053'
# })
# # 创建opener对象
# opener = urllib.request.build_opener(proxy_handler)
# 关闭图像界面,并切换到外观界面
time.sleep(random.random())
# 点击下一张图片
browser.find_element_by_xpath('//span[@class="img-next"]').click()
time.sleep(random.random())
# 关闭当前窗口,并选择之前的窗口
browser.close()
browser.switch_to.window(windows[0])
return
def main(names, save_root, img_num=[1000, ], continue_num=0, is_open_chrome=True):
'''
:param names: list str
:param save_root: str
:param img_num: int list or int
:param continue_num: int 断点续爬开始索引,从哪一个种类继续爬取
:param is_open_chrome: 爬虫是否打开浏览器爬取图像 bool default=False
:return:
'''
options = webdriver.ChromeOptions()
# 设置是否打开浏览器
if not is_open_chrome:
options.add_argument('--headless') # 不打开浏览器
# else:
# prefs = {"profile.managed_default_content_settings.images": 2} # 禁止图像加载
# options.add_experimental_option("prefs", prefs)
# 欺骗反爬虫,浏览器可以打开,但是没有内容
options.add_argument("--disable-blink-features=AutomationControlled")
browser = webdriver.Chrome(executable_path=r"D:\Anconda\envs\temp\Lib\site-packages\selenium\webdriver\chrome\chromedriver.exe",options=options)
browser.maximize_window()
browser.get(r'https://image.baidu.com/')
time.sleep(random.random())
assert type(names) == list, "names参数必须是字符串列表"
assert continue_num <= len(names), "中断续爬点需要小于爬虫任务数量"
if type(img_num) == int:
img_num = [img_num] * len(names)
print(img_num)
elif type(img_num) == list:
print("lsit:{}".format(img_num))
else:
print("None, img_num 必须是int list or int")
return
for i in range(continue_num, len(names)):
name = names[i]
save_path = os.path.join(save_root, str(names.index(name))) # 以索引作为文件夹名称
send_param_to_baidu(name, browser)
download_baidu_images(save_path=save_path, img_num=img_num[i],browser=browser)
# 全部关闭
browser.quit()
return
if __name__ == "__main__":
main(names=NameList,save_root=r'C:\Users\HUAWEI\Desktop\photo',img_num=[1000, 1000],continue_num=1)具体selenium的动态定位法:
参考链接: https://blog.csdn.net/u012206617/article/details/132451577?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_baidulandingword~default-0-132451577-blog-109838581.235^v40^pc_relevant_anti_vip&spm=1001.2101.3001.4242.1&utm_relevant_index=3
三. Scrapy+Xpath
需要使用 icrawler 包 [ps:直接pip install icrawler]
完整的代码1:
import os
from icrawler.builtin import BaiduImageCrawler
from icrawler.builtin import BingImageCrawler
#可以使用,使用icrawler包静态爬取图片
def check_path(path):
if not os.path.exists(path):
os.makedirs(path)
return path
def baidu_bing_crwal(key_words=['中国人'], max_nums=[1000], save_root=r'./'):
#看是否存在文件夹
check_path(save_root)
assert len(key_words)==len(max_nums), "关键词和数量必须一致"
# 2个一起爬虫
save_root1 = os.path.join(save_root, 'baidu')
# 百度爬虫
for i in range(len(key_words)):
print('-'*20)
image_save_root = os.path.join(save_root1, str(i))
if not os.path.exists(image_save_root):
os.makedirs(image_save_root)
storage = {'root_dir': image_save_root}
crawler = BaiduImageCrawler(storage=storage)
crawler.crawl(key_words[i], max_num=max_nums[i])
# bing爬虫
save_root2 = os.path.join(save_root, 'bing')
for i in range(len(key_words)):
print('-'*20)
image_save_root = os.path.join(save_root2, str(i))
if not os.path.exists(image_save_root):
os.makedirs(image_save_root)
storage = {'root_dir': image_save_root}
crawler = BingImageCrawler(storage=storage)
crawler.crawl(key_words[i], max_num=max_nums[i])
return
if __name__ == '__main__':
# baidu_bing_crwal(key_words=['生活垃圾', '化学垃圾',],
# max_nums=[1000, 1000],
# save_root=r'C:\Users\HUAWEI\Desktop\photo\da')
baidu_bing_crwal(key_words=['火灾火焰', '火灾烟雾'],
max_nums=[1000, 1000],
save_root=r'C:\Users\HUAWEI\Desktop\photo\da')其实简化的静态爬虫方式
完整的代码2:
'''
底层肯定是scrapy静态报文,谷歌引擎不可以,百度最快,bing速度有点慢!
直接pip install icrawler
若想搜索多个关键词,可以遍历for循环;同时icrawler也可对图像链接list、txt直接遍历:
UrlListCrawler
'''
from icrawler.builtin import GoogleImageCrawler
from icrawler.builtin import BaiduImageCrawler
from icrawler.builtin import BingImageCrawler
# storage字典格式'root_dir': 保存路径
# crawler = BaiduImageCrawler(storage={'root_dir': r'D:\temp\dog'})
crawler = BaiduImageCrawler(storage={'root_dir': r'C:\Users\HUAWEI\Desktop\photo'})
crawler.crawl(keyword='火焰', max_num=10)最后:爬取图片的任务完成了 ,☺☺☺
学习参考链接:python 爬虫_python爬虫断点续爬-CSDN博客
稳扎稳打学爬虫09—chromedriver下载与安装方法-CSDN博客
爬虫selenium获取百度任意图片_img_link = browser.find_elements_by_xpath('//li/di-CSDN博客Python爬虫:爬取百度图片(selenium模拟登录,详细注释)_百度图片 爬虫 find_elements-CSDN博客
爬虫selenium获取元素定位方法总结(动态获取元素)_selenium如何定位动态元素-CSDN博客