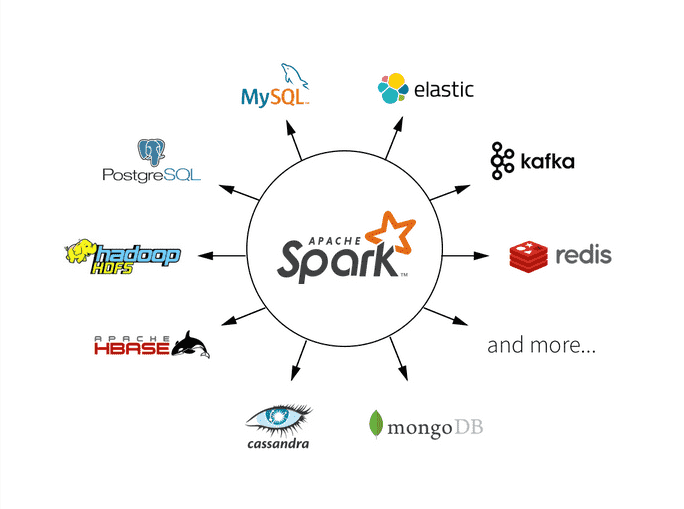
回归分析是统计学和机器学习中的一个重要分支,用于建立因变量与自变量之间的关系模型。在大数据领域,Apache Spark为回归分析提供了强大的工具和库,以处理大规模数据集。本文将深入探讨如何使用Spark进行回归分析以及如何进行特征工程,以提高模型性能。
Spark中的回归分析
回归分析是一种用于建立和解释因变量与自变量之间关系的统计方法。在Spark中,可以使用不同的回归算法,如线性回归、岭回归、Lasso回归等,来构建回归模型。
下面是一个示例,演示了如何使用Spark进行线性回归分析:
from pyspark.sql import SparkSession
from pyspark.ml.regression import LinearRegression
from pyspark.ml.evaluation import RegressionEvaluator
# 创建Spark会话
spark = SparkSession.builder.appName("LinearRegressionExample").getOrCreate()
# 读取训练数据
training_data = spark.read.format("libsvm").load("data/regression_data.txt")
# 创建线性回归模型
lr = LinearRegression(maxIter=10, regParam=0.3, elasticNetParam=0.8)
# 拟合模型
lr_model = lr.fit(training_data)
# 评估模型性能
evaluator = RegressionEvaluator(metricName="rmse")
predictions = lr_model.transform(training_data)
rmse = evaluator.evaluate(predictions)
print("Root Mean Squared Error (RMSE): %f" % rmse)
在上述示例中,首先创建了一个Spark会话,然后读取了训练数据。接下来,创建了一个线性回归模型,并使用训练数据拟合了模型。最后,使用均方根误差(RMSE)作为评估指标来评估模型的性能。
特征工程
特征工程是回归分析中的关键步骤之一。它涉及选择和提取与问题相关的特征,以便用于训练模型。在Spark中,可以使用特征提取、特征选择、特征生成等技术来进行特征工程。
以下是一些示例特征工程技术:
1. 特征提取
特征提取是从原始数据中提取有用信息的过程。在Spark中,可以使用TF-IDF、Word2Vec等技术来进行文本特征提取,使用PCA或LDA等技术来进行数值特征提取。
2. 特征选择
特征选择是从所有特征中选择最重要的特征的过程,以提高模型性能并减少计算成本。Spark提供了特征选择工具,例如Chi-squared选择器、递归特征消除等。
3. 特征生成
特征生成是通过组合、变换或聚合原始特征来创建新特征的过程。Spark提供了特征生成工具,例如多项式展开、交互特征生成等。
示例代码:岭回归
下面是一个示例代码片段,演示了如何使用Spark进行岭回归分析以及如何进行特征工程:
from pyspark.sql import SparkSession
from pyspark.ml.regression import Ridge
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.evaluation import RegressionEvaluator
# 创建Spark会话
spark = SparkSession.builder.appName("RidgeRegressionExample").getOrCreate()
# 读取训练数据
data = spark.read.csv("data/ridge_regression_data.csv", header=True, inferSchema=True)
# 特征工程:将特征列合并为一个向量列
feature_cols = data.columns[:-1]
assembler = VectorAssembler(inputCols=feature_cols, outputCol="features")
data = assembler.transform(data)
# 创建岭回归模型
ridge = Ridge(featuresCol="features", labelCol="label", maxIter=100, regParam=0.1)
# 拟合模型
ridge_model = ridge.fit(data)
# 评估模型性能
evaluator = RegressionEvaluator(metricName="rmse")
predictions = ridge_model.transform(data)
rmse = evaluator.evaluate(predictions)
print("Root Mean Squared Error (RMSE): %f" % rmse)
在这个示例中,首先读取了训练数据,并使用VectorAssembler将特征列合并为一个特征向量列。然后,创建了一个岭回归模型并拟合了数据。最后,使用RMSE作为评估指标来评估模型的性能。
数据准备与预处理
在进行回归分析之前,必须进行数据准备和预处理,以确保数据质量和一致性。
这通常包括以下步骤:
- 数据清洗:处理缺失值、异常值和重复值等数据质量问题。
- 特征缩放:将特征进行标准化或归一化,以确保它们在相同的尺度上。
- 数据拆分:将数据拆分为训练集和测试集,以评估模型的性能。
Spark提供了丰富的数据处理和预处理工具,如DataFrame的方法和pyspark.ml.feature库,以便执行这些任务。
模型选择与调优
在回归分析中,选择合适的模型和调优超参数是至关重要的。Spark提供了多种回归模型,如线性回归、岭回归、Lasso回归等。可以使用交叉验证和网格搜索等技术来选择最佳模型和超参数。
以下是一个示例:
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator
# 创建参数网格
param_grid = ParamGridBuilder() \
.addGrid(ridge.regParam, [0.1, 0.01, 0.001]) \
.addGrid(ridge.elasticNetParam, [0.0, 0.1, 0.2]) \
.build()
# 创建交叉验证器
cross_val = CrossValidator(estimator=ridge, estimatorParamMaps=param_grid, evaluator=evaluator, numFolds=5)
# 执行交叉验证
cv_model = cross_val.fit(data)
# 获取最佳模型
best_model = cv_model.bestModel
在上述示例中,使用了交叉验证和网格搜索来选择最佳的岭回归模型,并获得了最佳模型。
模型解释与可视化
理解模型的预测结果和特征的重要性对于回归分析非常重要。Spark提供了模型解释和可视化工具,如特征重要性的可视化和部分依赖图等,以解释模型的决策过程。
部署与生产
一旦选择了最佳回归模型,就可以将其部署到生产环境中,用于进行实际的回归预测。Spark提供了模型导出和部署的工具,以便将模型集成到应用程序中,并处理实时或批量数据。
总结
回归分析是数据科学中的一个重要任务,而Spark提供了丰富的工具和库,用于进行回归分析和特征工程。本文深入介绍了回归分析的基本步骤,包括模型选择与调优、数据准备与预处理、模型解释与可视化等方面。希望本文能够帮助大家更好地理解和应用Spark来解决回归分析问题。









![IDEA[Debug]简单说明](https://img-blog.csdnimg.cn/direct/3d60ea7538384460a52963eab1103b13.gif)