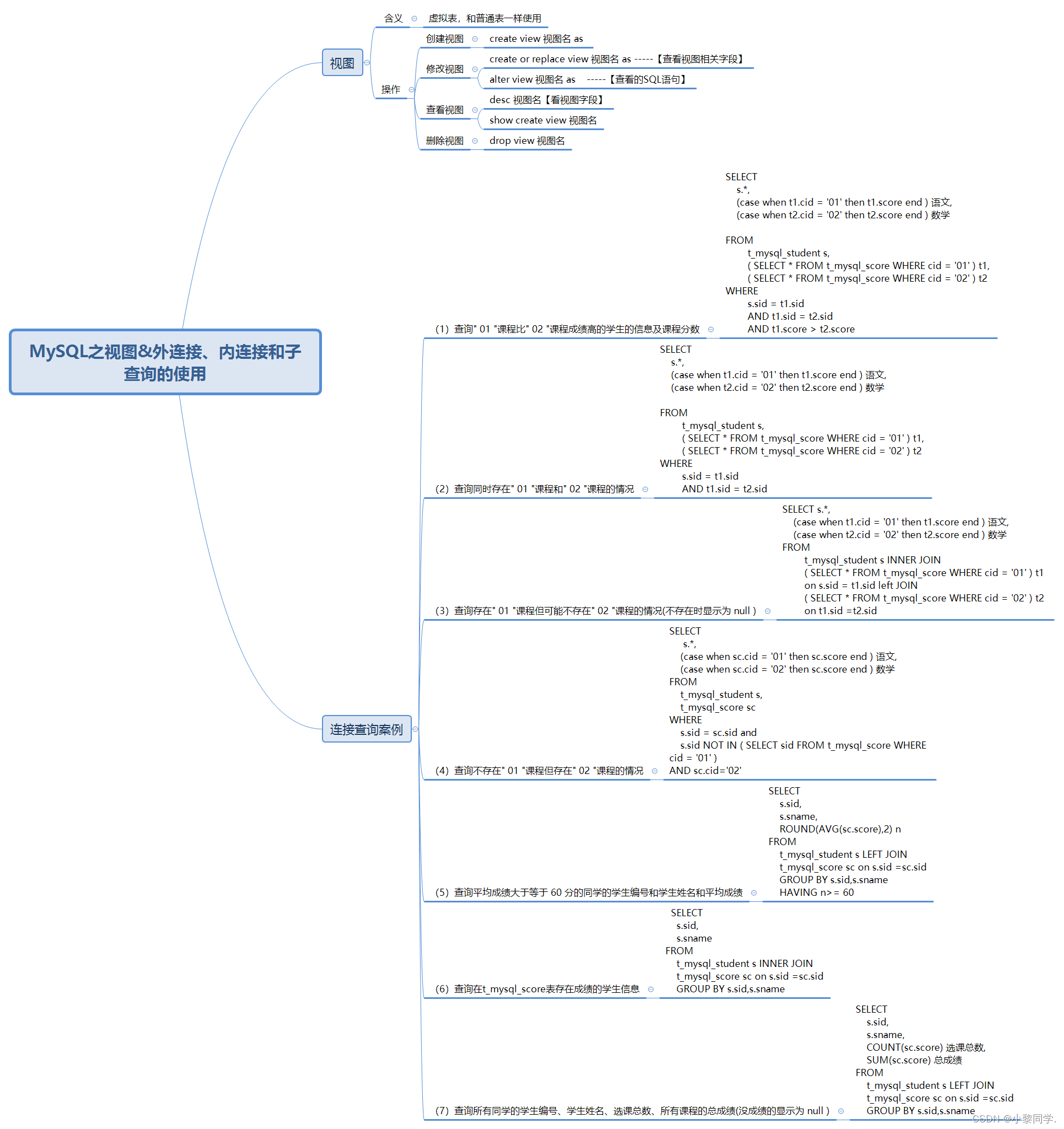
目录
一、视图
1.1、概念:
1.2、场景:
1.3、用视图的意义
1.2、创建(增加)视图
1.3、修改视图
1.4、删除视图
1.5、查看视图
编辑
二、索引
2.1、概念
2.2、优缺点
优点:
缺点:
2.3、应用场景
2.4、会失效
2.5、分类:
2.6、语法
创建索引的语法
三、复杂SQL语句
3.1、用处
3.2、内联(inner join/ join)
概念:
应用场景:
3.3、外联(left join\right join或full outer join)
概念:
分类:
应用场景:
3.3、子查询
概念:
面试题
3.4、案例(运用两种方式实现)
sql文件获取:
导入sql文件
代码演示
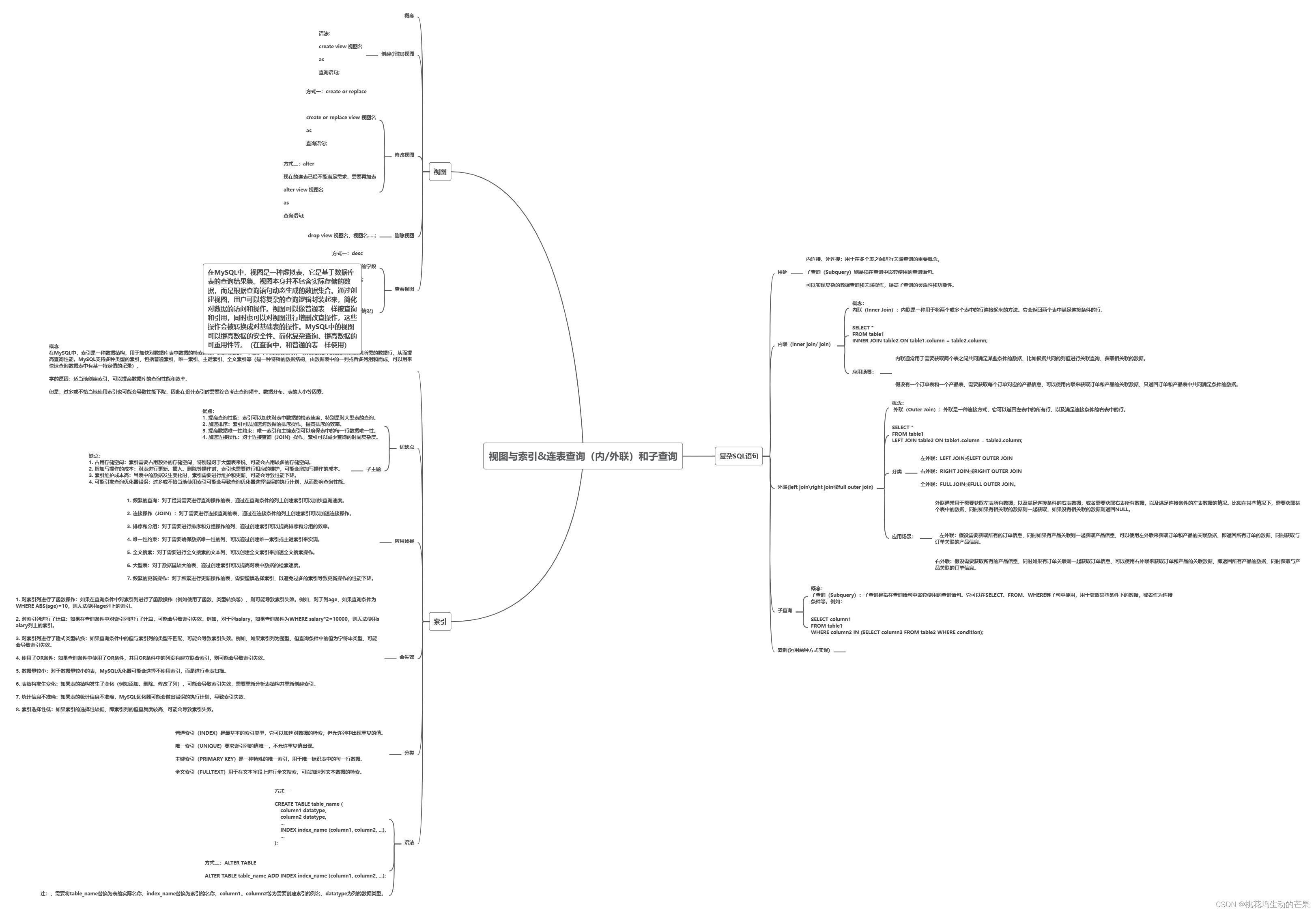
四、思维导图总结
一、视图
1.1、概念:
在MySQL中,视图是一种虚拟表,它是基于数据库表的查询结果集。视图本身并不包含实际存储的数据,而是根据查询语句动态生成的数据集合。通过创建视图,用户可以将复杂的查询逻辑封装起来,简化对数据的访问和操作。视图可以像普通表一样被查询和引用,同时也可以对视图进行增删改查操作,这些操作会被转换成对基础表的操作。MySQL中的视图可以提高数据的安全性、简化复杂查询、提高数据的可重用性等。(在查询中,和普通的表一样使用)
1.2、场景:
开发会用到视图,而我们实施要查看视图的里面有那些属性
1.3、用视图的意义
用在多表联查中,把复杂查询变简单
没有用视图的效果:每一次都要写这么长的语句很麻烦
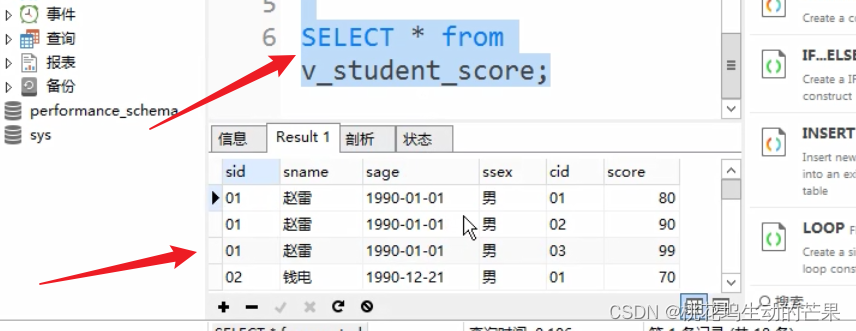
用了视图的效果:简单
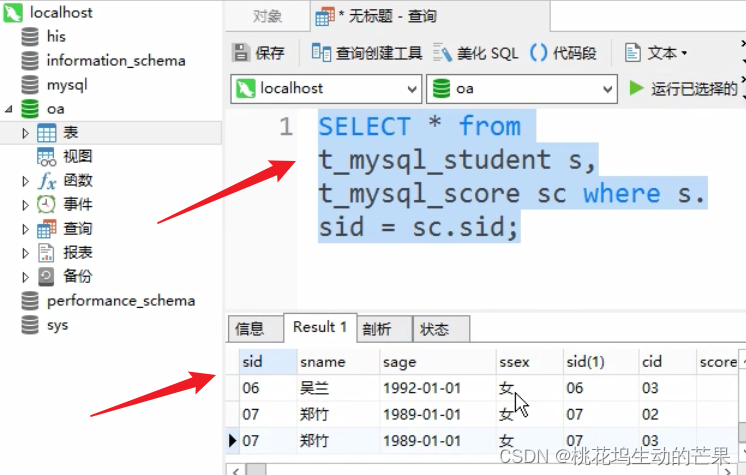
注:duplicate column重复列,会导致创建不成功
1.2、创建(增加)视图
语法:
create view 视图名
as
查询语句;
1.3、修改视图
语法:两种方式
方式一:create or replace
create or replace view 视图名
as
查询语句;
方式二:alter
现在的连表已经不能满足需求,需要再加表
alter view 视图名
as
查询语句;
1.4、删除视图
drop view 视图名,视图名.....;
1.5、查看视图
语法:两种方式
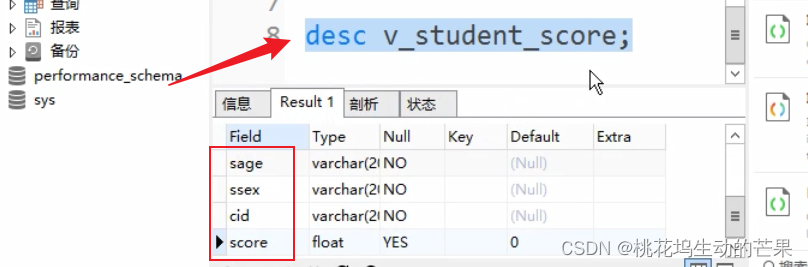
方式一:desc
查看视图里面的字段
desc 视图名;
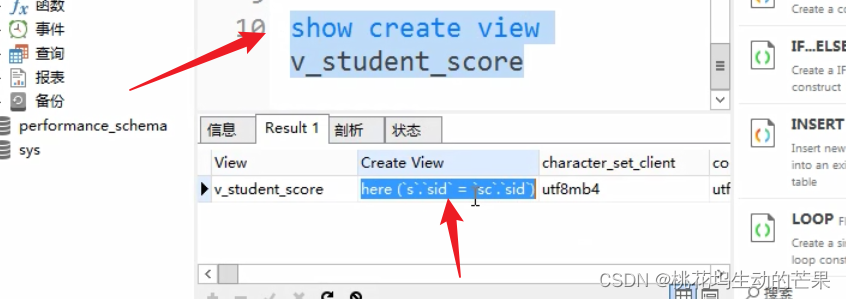
方式一:show create
查看视图的sql语句(用于别人创建的视图然后查看情况)
show create view 视图名;
查出结果再把它复制,粘贴出来,就可以看见语句了
二、索引
2.1、概念
在MySQL中,索引是一种数据结构,用于加快对数据库表中数据的检索速度。通过在表的一个或多个列上创建索引,可以使数据库系统更快地找到所需的数据行,从而提高查询性能。MySQL支持多种类型的索引,包括普通索引、唯一索引、主键索引、全文索引等(是一种特殊的数据结构,由数据表中的一列或者多列组和而成,可以用来快速查询数据表中有某一特定值的记录)。
学的原因:适当地创建索引,可以提高数据库的查询性能和效率。
但是,过多或不恰当地使用索引也可能会导致性能下降,因此在设计索引时需要综合考虑查询频率、数据分布、表的大小等因素。
2.2、优缺点
优点:
1. 提高查询性能:索引可以加快对表中数据的检索速度,特别是对大型表的查询。
2. 加速排序:索引可以加速对数据的排序操作,提高排序的效率。
3. 提高数据唯一性约束:唯一索引和主键索引可以确保表中的每一行数据唯一性。
4. 加速连接操作:对于连接查询(JOIN)操作,索引可以减少查询的时间复杂度。
缺点:
1. 占用存储空间:索引需要占用额外的存储空间,特别是对于大型表来说,可能会占用较多的存储空间。
2. 增加写操作的成本:对表进行更新、插入、删除等操作时,索引也需要进行相应的维护,可能会增加写操作的成本。
3. 索引维护成本高:当表中的数据发生变化时,索引需要进行维护和更新,可能会导致性能下降。
4. 可能引发查询优化器错误:过多或不恰当地使用索引可能会导致查询优化器选择错误的执行计划,从而影响查询性能。
2.3、应用场景
1. 频繁的查询:对于经常需要进行查询操作的表,通过在查询条件的列上创建索引可以加快查询速度。
2. 连接操作(JOIN):对于需要进行连接查询的表,通过在连接条件的列上创建索引可以加速连接操作。
3. 排序和分组:对于需要进行排序和分组操作的列,通过创建索引可以提高排序和分组的效率。
4. 唯一性约束:对于需要确保数据唯一性的列,可以通过创建唯一索引或主键索引来实现。
5. 全文搜索:对于需要进行全文搜索的文本列,可以创建全文索引来加速全文搜索操作。
6. 大型表:对于数据量较大的表,通过创建索引可以提高对表中数据的检索速度。
7. 频繁的更新操作:对于频繁进行更新操作的表,需要谨慎选择索引,以避免过多的索引导致更新操作的性能下降。
2.4、会失效
1. 对索引列进行了函数操作:如果在查询条件中对索引列进行了函数操作(例如使用了函数、类型转换等),则可能导致索引失效。例如,对于列age,如果查询条件为WHERE ABS(age)=10,则无法使用age列上的索引。
2. 对索引列进行了计算:如果在查询条件中对索引列进行了计算,可能会导致索引失效。例如,对于列salary,如果查询条件为WHERE salary*2=10000,则无法使用salary列上的索引。
3. 对索引列进行了隐式类型转换:如果查询条件中的值与索引列的类型不匹配,可能会导致索引失效。例如,如果索引列为整型,但查询条件中的值为字符串类型,可能会导致索引失效。
4. 使用了OR条件:如果查询条件中使用了OR条件,并且OR条件中的列没有建立联合索引,则可能会导致索引失效。
5. 数据量较小:对于数据量较小的表,MySQL优化器可能会选择不使用索引,而是进行全表扫描。
6. 表结构发生变化:如果表的结构发生了变化(例如添加、删除、修改了列),可能会导致索引失效,需要重新分析表结构并重新创建索引。
7. 统计信息不准确:如果表的统计信息不准确,MySQL优化器可能会做出错误的执行计划,导致索引失效。
8. 索引选择性低:如果索引的选择性较低,即索引列的值重复度较高,可能会导致索引失效。
2.5、分类:
普通索引(INDEX)是最基本的索引类型,它可以加速对数据的检索,但允许列中出现重复的值。
唯一索引(UNIQUE)要求索引列的值唯一,不允许重复值出现。
主键索引(PRIMARY KEY)是一种特殊的唯一索引,用于唯一标识表中的每一行数据。
全文索引(FULLTEXT)用于在文本字段上进行全文搜索,可以加速对文本数据的检索。
2.6、语法
创建索引的语法
方式一
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
...
INDEX index_name (column1, column2, ...),
...
);
方式二:ALTER TABLE
ALTER TABLE table_name ADD INDEX index_name (column1, column2, ...);
注:,需要将table_name替换为表的实际名称,index_name替换为索引的名称,column1、column2等为需要创建索引的列名,datatype为列的数据类型。
三、复杂SQL语句
3.1、用处
内连接、外连接:用于在多个表之间进行关联查询的重要概念,
子查询(Subquery)则是指在查询中嵌套使用的查询语句。
可以实现复杂的数据查询和关联操作,提高了查询的灵活性和功能性。
3.2、内联(inner join/ join)
概念:
内联(Inner Join):内联是一种用于将两个或多个表中的行连接起来的方法。它会返回两个表中满足连接条件的行。
SELECT *
FROM table1
INNER JOIN table2 ON table1.column = table2.column;
应用场景:
内联通常用于需要获取两个表之间共同满足某些条件的数据,比如根据共同的列值进行关联查询,获取相关联的数据。
假设有一个订单表和一个产品表,需要获取每个订单对应的产品信息,可以使用内联来获取订单和产品的关联数据,只返回订单和产品表中共同满足条件的数据。
3.3、外联(left join\right join或full outer join)
概念:
外联(Outer Join):外联是一种连接方式,它可以返回左表中的所有行,以及满足连接条件的右表中的行。
SELECT *
FROM table1
LEFT JOIN table2 ON table1.column = table2.column;
分类:
左外联:LEFT JOIN或LEFT OUTER JOIN
右外联:RIGHT JOIN或RIGHT OUTER JOIN
全外联:FULL JOIN或FULL OUTER JOIN。
应用场景:
外联通常用于需要获取左表所有数据,以及满足连接条件的右表数据,或者需要获取右表所有数据,以及满足连接条件的左表数据的情况。比如在某些情况下,需要获取某个表中的数据,同时如果有相关联的数据则一起获取,如果没有相关联的数据则返回NULL。
左外联:假设需要获取所有的订单信息,同时如果有产品关联则一起获取产品信息,可以使用左外联来获取订单和产品的关联数据,即返回所有订单的数据,同时获取与订单关联的产品信息。
右外联:假设需要获取所有的产品信息,同时如果有订单关联则一起获取订单信息,可以使用右外联来获取订单和产品的关联数据,即返回所有产品的数据,同时获取与产品关联的订单信息。
3.3、子查询
概念:
子查询(Subquery):子查询是指在查询语句中嵌套使用的查询语句。它可以在SELECT、FROM、WHERE等子句中使用,用于获取某些条件下的数据,或者作为连接条件等。例如:
SELECT column1
FROM table1
WHERE column2 IN (SELECT column3 FROM table2 WHERE condition);
面试题
1. 聚集索引(Clustered Index):
是一种索引结构,它对表中的数据行进行排序,并在叶子节点上存储实际的数据。换句话说,聚集索引决定了表中数据的物理存储顺序。
主键通常会被自动创建为聚集索引,这意味着主键的值会决定数据行的物理存储顺序。
一个表只能有一个聚集索引,因此如果表已经有了聚集索引(通常是主键),则无法再创建其他的聚集索引。
2. 非聚集索引(Non-clustered Index):
非聚集索引是一种独立的索引结构,它在叶子节点上存储指向实际数据行的指针,而不是存储实际的数据。
非聚集索引的叶子节点包含了指向对应数据行的指针,而数据行的物理存储顺序由表的聚集索引决定。
一个表可以有多个非聚集索引,用于加速不同的查询。
3. 主键(Primary Key):
主键是用于唯一标识表中每一行数据的一列或一组列,它具有唯一性和非空性的约束。
主键通常会自动创建一个聚集索引,以便快速定位和检索特定的数据行。
主键的选择应该是唯一且稳定的,通常是表中的一个或多个列,用于唯一标识每一行数据。
总结:
聚集索引决定了数据行的物理存储顺序,通常是主键所对应的索引。
非聚集索引是独立的索引结构,它存储了指向数据行的指针,而数据行的物理存储顺序由聚集索引决定。
主键是用于唯一标识数据行的一列或一组列,通常会自动创建一个聚集索引。
3.4、案例(运用两种方式实现)
sql文件获取:
链接: https://pan.baidu.com/s/1jRhkpaENWOFvnNTy0CH9fw?pwd=iywj
提取码: iywj
复制这段内容后打开百度网盘手机App,操作更方便哦
导入sql文件
右键运行SQL文件
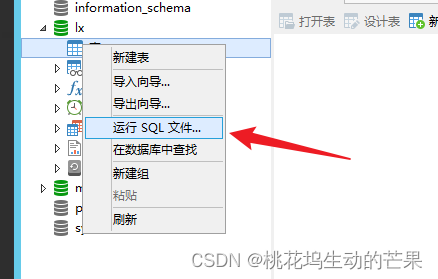
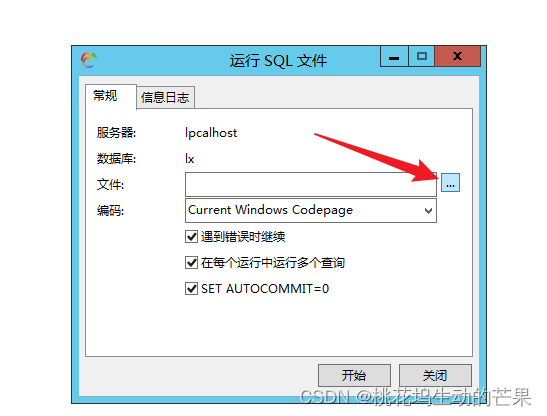
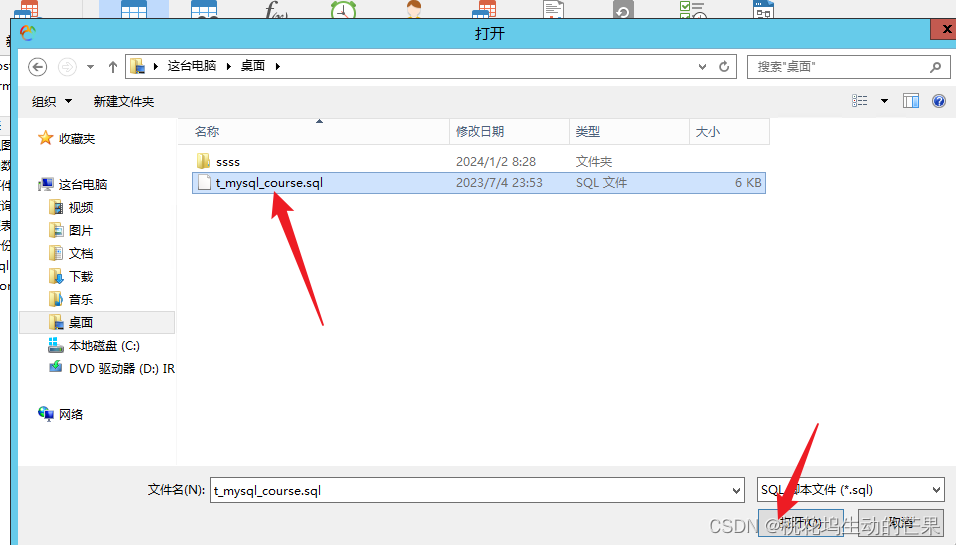
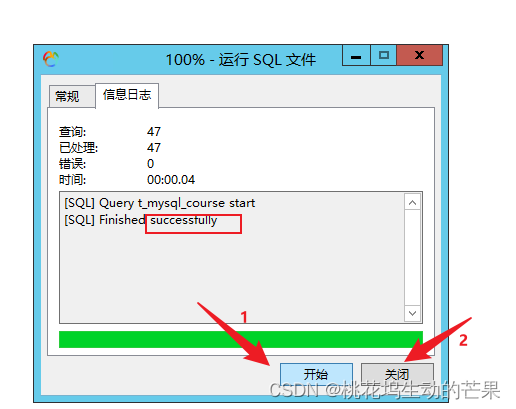
如果没有显示表就刷新
代码演示
行转列
没有转的:
转了的效果:
查看表的数据内容
SELECT * from t_mysql_score;
SELECT * from t_mysql_course;
SELECT * from t_mysql_teacher;
SELECT * from t_mysql_student;
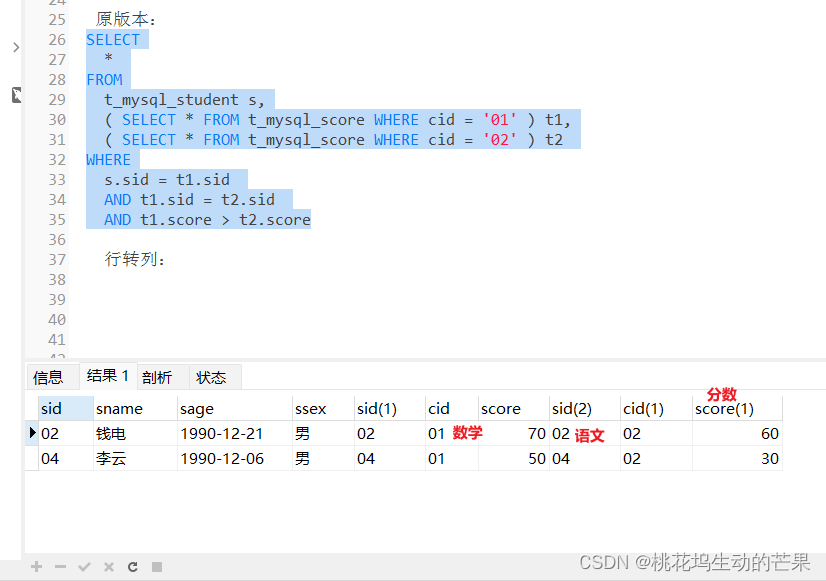
01)查询" 01 "课程比" 02 "课程成绩高的学生的信息及课程分数
用到的表:t_mysql_student和 t_mysql_course
连接方式:内联
分析: 01课程比02 课程成绩高,既要01又要02的数据才可以比较 01>02
select * from
t_mysql_student s,
第二张不同学生对应不同的成绩
(select * from t_mysql_score where cid='01')t1,
(select * from t_mysql_score where cid='02')t2
t1里面的学生id要与t2学生id相等,
where t1.sid=t2.sid and
再判断大小
t1.score>t2.score
把t1绑定到具体学生上去
s.sid=t1.sid
原版本:
SELECT
*
FROM
t_mysql_student s,
( SELECT * FROM t_mysql_score WHERE cid = '01' ) t1,
( SELECT * FROM t_mysql_score WHERE cid = '02' ) t2
WHERE
s.sid = t1.sid
AND t1.sid = t2.sid
AND t1.score > t2.score
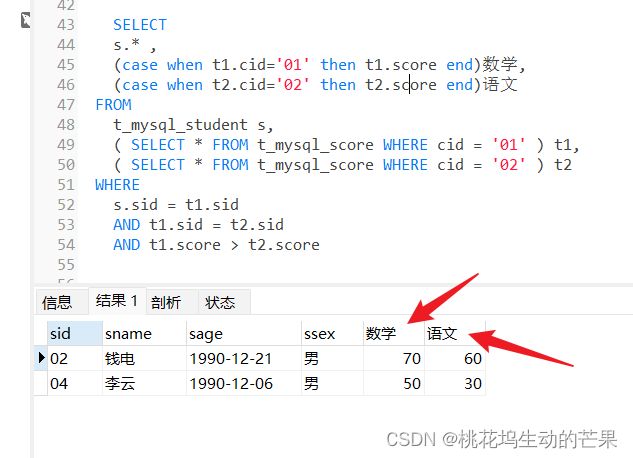
流程函数:行转列:太长了看着不舒服
分析:
s.* 所有学生信息
(case when t1.cid='01' then t1.score end)数学
当t1的cid为01的时候,取t1的分数为数学
SELECT
s.* ,
(case when t1.cid='01' then t1.score end)数学,
(case when t2.cid='02' then t2.score end)语文
FROM
t_mysql_student s,
( SELECT * FROM t_mysql_score WHERE cid = '01' ) t1,
( SELECT * FROM t_mysql_score WHERE cid = '02' ) t2
WHERE
s.sid = t1.sid
AND t1.sid = t2.sid
AND t1.score > t2.score
02)查询同时存在" 01 "课程和" 02 "课程的情况
分析:同时存在
连接方式:内联
原版本:
SELECT
*
FROM
t_mysql_student s,
( SELECT * FROM t_mysql_score WHERE cid = '01' ) t1,
( SELECT * FROM t_mysql_score WHERE cid = '02' ) t2
WHERE
s.sid = t1.sid
AND t1.sid = t2.sid
流程函数:行转列:
SELECT
s.* ,
(case when t1.cid='01' then t1.score end)数学,
(case when t2.cid='02' then t2.score end)语文
FROM
t_mysql_student s,
( SELECT * FROM t_mysql_score WHERE cid = '01' ) t1,
( SELECT * FROM t_mysql_score WHERE cid = '02' ) t2
WHERE
s.sid = t1.sid
AND t1.sid = t2.sid
03)查询存在" 01 "课程但可能不存在" 02 "课程的情况(不存在时显示为 null )
分析:以谁为主用外联,以01课程为主
连接方式:外联(可能不存在)、学生跟课程是内连接
原版本:
SELECT * from
( SELECT * FROM t_mysql_score WHERE cid = '01' ) t1
left join
( SELECT * FROM t_mysql_score WHERE cid = '02' ) t2
on t1.sid=t2.sid;
流程函数:行转列:
SELECT
s.* ,
(case when t1.cid='01' then t1.score end)数学,
(case when t2.cid='02' then t2.score end)语文
FROM
t_mysql_student s inner join
( SELECT * FROM t_mysql_score WHERE cid = '01' ) t1
on s.sid=t1.sid left join
( SELECT * FROM t_mysql_score WHERE cid = '02' ) t2
on t1.sid=t2.sid;
04)查询不存在" 01 "课程但存在" 02 "课程的情况
分析:找到存在01课程的再排除掉,再加条件是02的
由内到外
先查询学了01课程的学生
(select sid from t_mysql_score where cid ='01')
再查没学01的
select * from t_mysql_student s where s.sid not in
not in 不是
将学生表与课程表连接起来
s.sid=sc.sid
但是存在02课程的
连接方式:子查询
原版本:
SELECT
*
FROM
t_mysql_student s,
t_mysql_score sc
WHERE
s.sid=sc.sid and
s.sid NOT IN ( SELECT sid FROM t_mysql_score WHERE cid = '01' )
AND sc.cid='02'
流程函数:行转列:
SELECT
s.* ,
(case when sc.cid='01' then sc.score end)数学,
(case when sc.cid='02' then sc.score end)语文
FROM
t_mysql_student s,
t_mysql_score sc
WHERE
s.sid=sc.sid and
s.sid NOT IN ( SELECT sid FROM t_mysql_score WHERE cid = '01' )
AND sc.cid='02'
05)查询平均成绩大于等于 60 分的同学的学生编号和学生姓名和平均成绩
分析:要聚合函数,就要分组,不管学生有没有考试都要有姓名显示
连接方式:外联
SELECT
①学生编号和学生姓名
s.sid,
s.sname,
③平均成绩(先拿分数,再用函数,取别名给下面用)--- ROUND(,2)取两位小数
ROUND(avg(sc.score),2) n
FROM
t_mysql_student s LEFT JOIN
t_mysql_score sc
②外联,把表连接
on s.sid=sc.sid
④分组 ---因为出现了两个一样的人---找到对应字段
GROUP BY s.sid,s.sname
筛选取平均值
HAVING n>=60
SELECT
s.sid,
s.sname ,ROUND( avg( sc.score ), 2 ) n
FROM
t_mysql_student s LEFT JOIN
t_mysql_score sc ON s.sid = sc.sid
GROUP BY
s.sid,
s.sname
HAVING
n >= 60
06)查询在t_mysql_score表存在成绩的学生信息
分析:存在成绩的学生,如果用外联那不存在成绩也显示
连接方式:内联
原:
SELECT
*
FROM
t_mysql_student s inner JOIN
t_mysql_score sc ON s.sid = sc.sid
SELECT
s.sid,
s.sname
FROM
t_mysql_student s inner JOIN
t_mysql_score sc ON s.sid = sc.sid
GROUP BY
s.sid,
s.sname
07)查询所有同学的学生编号、学生姓名、选课总数、所有课程的总成绩(没成绩的显示为 null )
用:聚合函数,外联
SELECT
s.sid,
s.sname ,
count(sc.score) 选课总数,
sum(sc.score) 总成绩
FROM
t_mysql_student s left JOIN
t_mysql_score sc ON s.sid = sc.sid
GROUP BY
s.sid,
s.sname
08)查询「李」姓老师的数量
SELECT count(1) from t_mysql_teacher where tname like '李%';四、思维导图总结