针对未入行、刚入行、工作好几年依然不停切换择业方向、长期技术无法突破的人。
1 技术栈
一切的开始其实是对编程的兴趣,兴趣指引你跨过所有障碍。
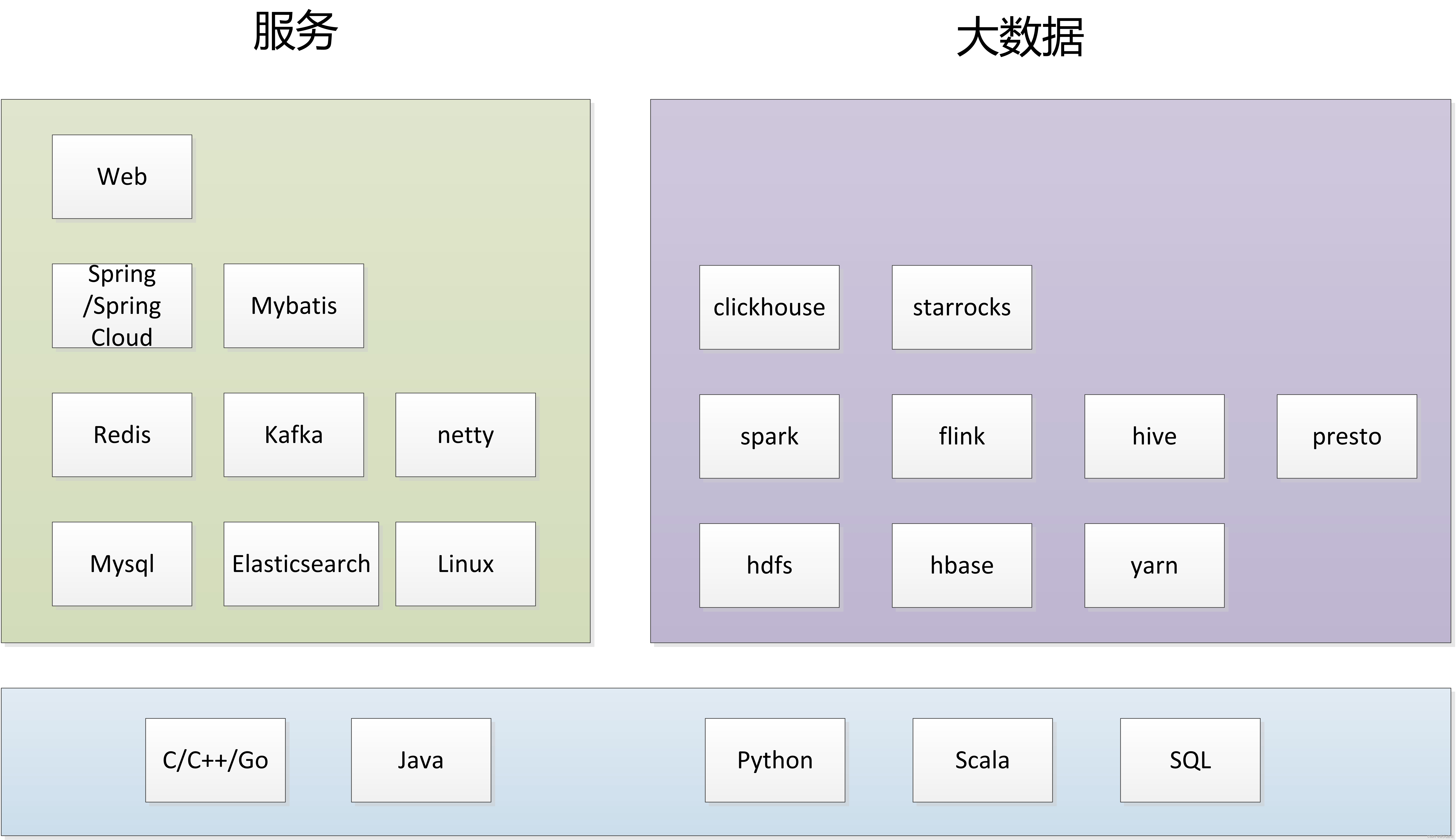
编程语言是基础,编程语言之上,发展为两个主要方向,服务和大数据。
2 编程语言
C/C++:一般的教学从C/C++开始,非常难学,经常能吓跑一帮计算机入门者。尤其是指针,看似计算机的指令灵魂,让一些初学者敬而远之。C/C++对学生时期最大的用处是锻炼算法题,然并没有什么成果,主要是C/C++可以上手磨炼的项目不多。C/C++基本都是和linux打交道。C/C++更进一步是Go,现在逐渐流行。
Java:java是主流。Java可以编写业务系统软件,比如一个web系统。一个程序员真正对程序感兴趣可能就是独立能写一个网站,后端各种数据处理使用java完成。Java负责数据访问处理,在java之上利用spring框架的能力,读写存储mysql、缓存redis、消息kafka,提供restful接口,加上html+css+js前端,形成一个网站的闭环。Java提供的项目非常丰富,唾手可得。
Python:相比java的大而全,python则是小而美。python的入门比java更容易,甚至不需要花费大力气就能用。如果学习编程语言有捷径,那么请从python开始。python也可以做小网站;python擅长数据处理,不需要java各种封装。所以在大数据处理,首推python,使用python运行sql语句,python打通大数据各个组件降低使用成本。Python也是算法的首选。
Scala:只有会java之后再考虑学scala。Scala最后也是编译为.class文件,所以scala和java是相通的。Scala的兴盛,得益于spark和flink都是使用scala和java语言编写。
Sql:其貌不扬,大学其实是从mysql的sql语法学起,简单容易懂。记住,程序即数据处理。而数据处理的最好的语言是sql,并不是java、python等等等。数据的最好载体是表。所有数据最稳妥的保存是落表,做服务保存业务数据到mysql表,做大数据保存到hive表等。在大数据,sql对应为hive sql,spark sql,flink sql,presto sql,clickhouse sql,starrocks sql等。Sql在所有数据处理都是相通的。
在大数据领域,java是大刀,python是匕首,配合使用。

3 服务
一切皆服务。何为服务?提供一个功能,一个接口,一款APP产品等都可以理解为服务,机器和人的交互即服务。
服务是起点。对于入行的人来说,首先会开发一个功能,牛叉的会独自开发一个网站综合大量功能,对一个软件有了全面的掌握。此时,会涉及到多方面的功能,存储(IO)、计算(CPU)、网络(接口/请求)。流量上来,需要考虑存储和计算之间的缓冲,引入了缓存;大量数据无法及时处理完,排队处理,引入了排队即队列等。为了更好快速开发大型软件,需要一个框架把所有的软件整合起来,spring生态成为大集成者。
Mysql:mysql是存储的基础。所有的工业级系统的存储基本使用mysql,除了银行一类。mysql有严格的事务保证,数据非常可靠。而且在分布式主从、分库分表都已非常成熟。mysql的sql语法、运维是必须的。
Elasticsearch:Elasticsearch是文件搜索系统。除超大厂自研一套搜索引擎系统,一般的业务系统使用Elasticsearch基本能满足业务的需求实现。Elasticsearch也是对存储的文件搜索。
Linux:做服务无法绕开linux,要跑的程序最终都部署到linux,现在基本都是虚拟化,k8s已是主流。linux常用的命令必知必会。
Redis:redis是所有业务系统的缓存标准。彪悍的缓存架构和分布式能力。redis基于C/C++实现,非常巧妙的数据结构与算法,基本是大学C++版本《数据结构与算法》的完美阐释。如果当时老师拿redis来教,我想我当时不至于昏昏欲睡。
Kafka:kafka是唯一在服务和大数据都吃香的组件。排队在日常生活无处不在,吃饭排队、进站排队等,这些场景在软件实现上也是一样。kafka一边写入一边读出,它的优势是高可靠又非常廉价,数据落盘。尤其是日志数据,服务的程序产生大量的日志数据,通过kafka同步,大数据组件把kafka的数据消费保留到表用于分析。
Netty:netty是网络通信的组件,如果不是专门开发linux通信软件基本不涉及。通常的web开发走restful接口简化大量底层细节了。
Spring/Spring Cloud:服务领域的灵魂是Spring生态,spring通过把依赖变为注入IoC,面向切面AOP两大特性发家。逐步发展到Spring Cloud,微服务,即一个独立的功能成为一个服务,一个进程程序,并且从单程序到分布式,性能、高可用。spring cloud和各种组件mysql、redis、kafka等一网打尽适配兼容,成为大一统。学会spring cloud,服务领域基本就有了全貌了。
Mybatis:mybatis是一个ORM框架,提供sql配置化的写法,把sql从代码里抽离出来。其实,如果不是太复杂的sql,spring也足够用。
Web:最终是要做一个系统的,网站、小程序、APP,提供restful接口。最快是copy一个简单的网站改改,学会部署,修改js、css、html为自己想要的样子。

服务的日常工作,不停做系统,一个接着一个做,没有新系统就重构旧系统。高并发、高性能、高可用的三高系统,活是永远做不完的。
进入服务行业,会独立做网站、小程序、APP,是非常亮眼的。
4 大数据
大数据相比服务,就纯粹得多。服务是一条条数据处理,大数据是一批批数据处理。服务是0到1,大数据是1到N。
hdfs:大数据从hadoop发展而来,hadoop的存储是hdfs,是大数据生态一切的基础。以一大块一大块数据存储提高效率。
hbase:hbase也是hadoop的一块,服务的缓存是redis首选,大数据的kv以hbase首选,当然有一些组件也不错比如kudu。hbase是列式存储,支持“缓存”,在大数据领域使用redis则太昂贵太浪费了,hbase刚好。
yarn:大数据的计算和服务的计算最大的区别是计算资源的管控,服务的计算是在某一个进程完成,大数据的计算是在多个一样的进程中完成,“迭代”,多次分分合合完成。yarn负责管控大数据集群的CPU和内存,把这些资源划分为一个个小单元,按需使用。
spark:hadoop一开始的计算框架是Map-Reduce,其实就是拆分-合并。spark中其实有借鉴部分思想,不过spark更快,提出了一系列算子,spark SQL编程,把大数据的计算框架使用难度降低太多!spark也提出了流式计算spark streaming,其实是微批。hadoop MR是批处理,spark超越了它,但留下了“批”的本质。
flink:flink是实时流式处理,一统实时流计算,在此之前storm,jstorm,spark streaming逐渐退出。flink同时支持批处理,但在离线场景,spark依然不可替代。
hive:hive是最好用的大数据组件了,没有之一。因为hive基本不出问题,而且hive sql做离线数仓非常容易,集中了大量的数仓、分析人员。不需要多高的技术,会sql就行。是进入大数据领域最容易的门槛。因为其他的组件都要去懂大数据组件的代码!
presto:hive适合跑离线任务,但hive有一个缺点是慢,慢得难以忍受,一般会使用spark sql代替hive sql去加速离线任务。对于实时分析,spark启动有成本,依然很慢,presto就来代替spark做实时分析,而且查询数据非常快。
clickhouse:不管离线和实时的数据报表,最终要提供给上层管理者使用而且速度要够快。clickhouse是多维查询引擎,一张大宽表,任意group by快速出数。在大数据领域,除非数据量非常少mysql是可以替代,一般不会考虑mysql,数据量过千万mysql基本无用武之地。大数据的查询引擎偏写入和查询,对事务型修改不严格甚至不支持,自然不需要mysql的特性。
starrocks:starrocks是多维查询引擎号称完胜clickhouse,starrocks在多表join,并发QPS、分布式扩展性都全面超越。

5 跨行
从服务转大数据,或者从大数据转服务是否能转?
做服务,要求编码能力,而且要有相应的业务系统实战开发经验,刚毕业入行容易,但是久而久之反而不易,做服务比较烧脑,年轻时首选。大数据本来要求的编码能力要比服务低,而且数据处理和写业务逻辑差别还是很大,从大数据转服务是不易的。
从服务转大数据呢?大数据有数据平台,其实要求有阅读大数据组件源码的能力,spark、flink、kafka这些都少不了。比单纯做业务系统更多的是要求对大数据组件原理的理解、使用、调优。
在所有的开发相关工作中最轻松的是哪方面呢?自然是数仓开发,整天写SQL。如果是从软件架构的人看数据仓库的设计会感觉很乱,少了一点“架构”的的感觉。也有可能是工作内容使然。
数据仓库从离线转为部分需要实时,增加了编码能力的要求,也是数仓人员的转变之路。