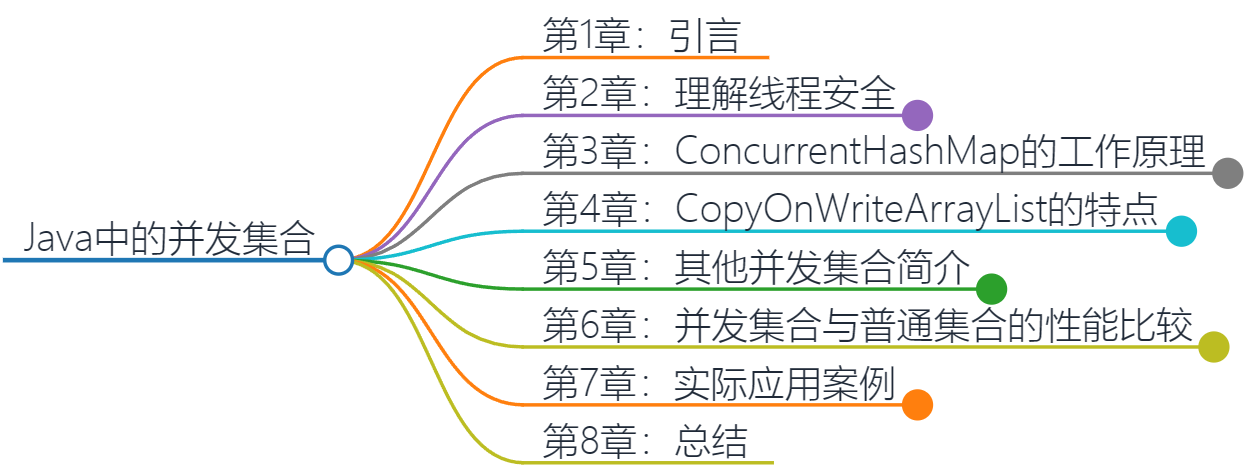
第1章:引言
大家好,我是小黑,在这篇博客中,咱们将一起深入探索Java中的并发集合。多线程编程是一个不可或缺的部分,它能让程序运行得更快,处理更多的任务。但同时,多线程也带来了一些挑战,尤其是在数据共享和同步方面。为了解决这些挑战,Java提供了一系列的并发集合,这些集合为处理并发数据访问提供了优雅而强大的解决方案。
在单线程程序中,数据结构的设计往往较为简单,因为只有一个线程在任何时刻访问数据。但在多线程环境下,情况就完全不同了。如果多个线程同时对同一个数据结构进行读写,就可能引起数据不一致甚至程序崩溃的问题。因此,确保数据结构在并发访问下的安全,就变得非常关键了。
而这正是Java并发集合登场的地方。这些集合被设计为在多线程环境中提供线程安全,同时尽可能地提高性能。咱们将在接下来的章节中详细了解它们是如何做到这一点的。
第2章:理解线程安全
谈到线程安全,咱们首先要明白什么是线程安全。简单来说,如果一个方法或类在多线程环境中能够正确地处理多个线程的并发访问,那么它就被认为是线程安全的。这听起来简单,但实际实现起来可没那么容易。
在Java中,线程安全主要涉及到三个核心概念:原子性、可见性和有序性。原子性是指一个操作是不可中断的,即使在多线程同时执行的情况下。可见性确保一个线程对共享变量的修改对其他线程是可见的。有序性则是指代码的执行顺序,确保程序执行的结果按照代码预定的顺序来进行。
举个简单的例子,让咱们来看看非线程安全的情况。假设有一个简单的计数器:
public class Counter {
private int count = 0;
public void increment() {
count++;
}
public int getCount() {
return count;
}
}
这个计数器在单线程环境下运行得很好。但在多线程环境下,就可能出现问题。如果两个线程同时调用increment()方法,它们可能同时读取同一个count值,然后各自增加1,最后写回count。这就导致了一个增加操作丢失了,因为两个线程读取的是同一个值。
为了解决这个问题,咱们可以使用synchronized关键字,让increment方法变成线程安全的:
public class SafeCounter {
private int count = 0;
public synchronized void increment() {
count++;
}
public int getCount() {
return count;
}
}
通过加入synchronized,咱们确保了每次只有一个线程能进入这个方法。这样就可以确保count的值在多线程环境下是准确无误的了。但是,使用synchronized也会带来性能上的开销,因为它会导致线程阻塞。
第3章:ConcurrentHashMap的工作原理
ConcurrentHashMap是HashMap的线程安全版本,但它的内部实现和普通的HashMap大相径庭。在HashMap中,所有操作几乎都是围绕着一个核心数组进行的,这个数组存储了键值对。但在多线程环境下,HashMap就显得力不从心了。比如,当两个线程同时尝试修改HashMap时,就可能导致数据冲突或者状态不一致。
这时,ConcurrentHashMap的设计就派上用场了。它通过将数据分段来降低锁的竞争。在ConcurrentHashMap中,数据被分成多个段(Segment),每个段就像一个独立的HashMap,它们有自己的锁。当多个线程访问不同段的数据时,它们可以同时进行,从而大大提高了并发性能。
来看看简单的代码示例:
import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMapExample {
public static void main(String[] args) {
ConcurrentHashMap<String, String> map = new ConcurrentHashMap<>();
map.put("一", "壹");
map.put("二", "贰");
map.put("三", "叁");
// 使用forEach遍历
map.forEach((key, value) -> System.out.println(key + " = " + value));
}
}
这个例子中,咱们创建了一个ConcurrentHashMap,并往里面添加了几个键值对。使用forEach方法遍历这个映射时,它可以安全地处理并发修改,这是HashMap所不具备的。
另一个关键特性是ConcurrentHashMap的读操作通常不需要加锁。因为大多数读操作(如get)都不会改变映射的结构,所以它们可以安全地并发执行,这也是ConcurrentHashMap高效的原因之一。
但ConcurrentHashMap并不是万能的。虽然它在大多数并发场景下表现出色,但在极端高并发的情况下,比如多个线程频繁更新同一个段,仍然可能会遇到性能瓶颈。因此,了解其内部工作原理对于合理使用它来说至关重要。
第4章:CopyOnWriteArrayList的特点
CopyOnWriteArrayList的核心思想是,每当我们尝试修改这个列表(比如添加或删除元素)时,它都会先复制一份数据,然后在这份新数据上进行修改操作。修改完成后,它会将原来的数据替换成新的数据。这样的机制确保了当有线程正在遍历列表时,其他线程对列表的修改不会影响到正在进行的遍历操作,从而实现了线程安全。
来看一段示例代码:
import java.util.Iterator;
import java.util.concurrent.CopyOnWriteArrayList;
public class CopyOnWriteArrayListExample {
public static void main(String[] args) {
CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>();
list.add("苹果");
list.add("香蕉");
list.add("橙子");
// 开启一个线程修改列表
new Thread(() -> {
list.add("葡萄");
list.remove("香蕉");
}).start();
// 同时遍历列表
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}

在这个例子中,即使在遍历列表的同时有另一个线程在进行修改操作,遍历操作也不会受到影响,因为它遍历的是原来未被修改的列表副本。
然而,CopyOnWriteArrayList也有其缺点。最明显的就是,每次修改操作都需要复制整个列表,这在列表很大时会非常消耗内存和CPU资源。此外,由于复制操作本身需要时间,所以写操作的响应时间可能会比普通ArrayList长。
尽管如此,CopyOnWriteArrayList在特定场景下仍然是一个非常有用的工具。它特别适合于那些读操作远多于写操作的场景。例如,一个经常被多个线程读取但很少修改的配置列表,就非常适合使用CopyOnWriteArrayList。
第5章:其他并发集合简介
除了ConcurrentHashMap和CopyOnWriteArrayList,还有许多其他的并发集合类。它们各有特点,适用于不同的并发场景。
让咱们先看看ConcurrentLinkedQueue。这是一个基于链接节点的无界线程安全队列。它使用了非阻塞算法,使得并发操作更加高效。这个队列适合用在生产者-消费者的场景中,比如任务队列。
import java.util.concurrent.ConcurrentLinkedQueue;
public class ConcurrentLinkedQueueExample {
public static void main(String[] args) {
ConcurrentLinkedQueue<String> queue = new ConcurrentLinkedQueue<>();
queue.offer("任务一");
queue.offer("任务二");
// 取出并移除队列的头部元素
String task = queue.poll();
System.out.println("处理了: " + task);
}
}
接下来是ConcurrentSkipListMap,这是一个基于跳表的并发映射。它的工作原理类似于跳表,提供了一种高效的并行查找算法。这个映射的一个重要特点是它的键是有序的,这使得它在需要有序访问的并发应用中非常有用。
import java.util.concurrent.ConcurrentSkipListMap;
public class ConcurrentSkipListMapExample {
public static void main(String[] args) {
ConcurrentSkipListMap<Integer, String> map = new ConcurrentSkipListMap<>();
map.put(3, "三");
map.put(1, "一");
map.put(2, "二");
// 遍历映射
map.forEach((key, value) -> System.out.println(key + " = " + value));
}
}

然后,让咱们来谈谈CopyOnWriteArraySet。这个集合基于CopyOnWriteArrayList实现,提供了一个线程安全的集合实现。由于它是基于数组的,所以在进行遍历操作时特别有效。但和CopyOnWriteArrayList一样,由于每次修改都涉及数组的复制,所以在数据量大时写操作会比较耗费资源。
import java.util.concurrent.CopyOnWriteArraySet;
public class CopyOnWriteArraySetExample {
public static void main(String[] args) {
CopyOnWriteArraySet<String> set = new CopyOnWriteArraySet<>();
set.add("苹果");
set.add("香蕉");
// 遍历集合
set.forEach(System.out::println);
}
}
最后是BlockingQueue系列,比如ArrayBlockingQueue和LinkedBlockingQueue。这些是支持阻塞操作的队列,非常适合用在生产者-消费者场景中,尤其是当生产者和消费者的处理速率不一致时。
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
public class ArrayBlockingQueueExample {
public static void main(String[] args) throws InterruptedException {
BlockingQueue<String> queue = new ArrayBlockingQueue<>(3);
queue.put("苹果");
queue.put("香蕉");
// 从队列中取出一个元素
String fruit = queue.take();
System.out.println("消费了: " + fruit);
}
}
这些并发集合类,每一种都有其独特的适用场景。理解它们的内部工作原理和适用场景,对于设计高效且稳定的并发程序至关重要。在Java的并发工具箱中,它们就像是不同功能的工具,咱们可以根据不同的需求选择合适的工具,打造出既强大又灵活的并发应用。
第6章:并发集合与普通集合的性能比较
在多线程环境下,线程安全是一个大问题。常规的集合类,比如ArrayList和HashMap,在设计时并没有考虑多线程并发访问的情况,因此它们在并发环境下可能会出现问题。为了解决这个问题,Java提供了并发集合,如ConcurrentHashMap和CopyOnWriteArrayList。这些集合通过内部机制保证了在多线程环境下的线程安全。
但线程安全并不是免费的,它通常会伴随着性能上的折衷。比如,ConcurrentHashMap为了实现线程安全,使用了分段锁的机制,这虽然比单一锁(比如在整个HashMap上加锁)有更好的并发性能,但在高并发情况下仍然可能成为瓶颈。同样,CopyOnWriteArrayList在写操作时需要复制整个数组,这在数据量大时会导致显著的性能开销。
让我们通过一些代码来具体了解这些差异。首先,看看非线程安全的ArrayList在并发环境下的表现:
import java.util.ArrayList;
import java.util.List;
public class ArrayListExample {
public static void main(String[] args) throws InterruptedException {
List<String> list = new ArrayList<>();
Thread thread1 = new Thread(() -> addItems(list, "线程一"));
Thread thread2 = new Thread(() -> addItems(list, "线程二"));
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println("列表大小:" + list.size());
}
private static void addItems(List<String> list, String threadName) {
for (int i = 0; i < 1000; i++) {
list.add(threadName + " - 元素" + i);
}
}
}
这个例子中,两个线程同时向ArrayList中添加元素,最终的结果可能会出现异常,因为ArrayList不是线程安全的。
相比之下,让我们看看CopyOnWriteArrayList的表现:
import java.util.concurrent.CopyOnWriteArrayList;
public class CopyOnWriteArrayListExample {
public static void main(String[] args) throws InterruptedException {
CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>();
Thread thread1 = new Thread(() -> addItems(list, "线程一"));
Thread thread2 = new Thread(() -> addItems(list, "线程二"));
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println("列表大小:" + list.size());
}
private static void addItems(CopyOnWriteArrayList<String> list, String threadName) {
for (int i = 0; i < 1000; i++) {
list.add(threadName + " - 元素" + i);
}
}
}
在这个例子中,使用了CopyOnWriteArrayList,即使在多线程环境下,列表的大小也是预期的2000,没有出现问题。
所以,选择哪种集合类取决于具体的应用场景。如果是单线程环境,或者是只读操作,普通集合类通常有更好的性能。但在多线程环境下,尤其是需要处理并发写操作时,选择并发集合则更为安全和高效。
理解不同集合类的特点和适用场景,可以帮助咱们更好地设计和优化程序。在多线程编程中,正确的工具选择是至关重要的,它不仅关系到程序的正确性,也直接影响到性能和响应速度。
第7章:应用案例
案例一:网站访问统计
想象一下,有一个网站,需要实时统计每个页面的访问量。这里,ConcurrentHashMap就能大显身手了。由于网站的访问量巨大,且多线程同时访问和更新数据,使用普通的HashMap可能会导致并发问题。而ConcurrentHashMap可以安全高效地处理并发数据更新。
import java.util.concurrent.ConcurrentHashMap;
public class WebStatistics {
private final ConcurrentHashMap<String, Long> pageVisitCounts = new ConcurrentHashMap<>();
public void visitPage(String pageUrl) {
pageVisitCounts.compute(pageUrl, (key, count) -> count == null ? 1 : count + 1);
}
public Long getPageVisitCount(String pageUrl) {
return pageVisitCounts.getOrDefault(pageUrl, 0L);
}
}
在这个例子中,每当一个页面被访问时,visitPage方法就会被调用,并且相应页面的计数器就会递增。使用ConcurrentHashMap确保了即使在高并发的访问下,统计数据也是准确的。
案例二:日志处理系统
在一个日志处理系统中,可能需要一个线程安全的队列来存储待处理的日志消息。这时,BlockingQueue(如LinkedBlockingQueue)是一个理想的选择。它可以安全地在生产者线程(生成日志)和消费者线程(处理日志)之间传递数据。
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class LogProcessor {
private final BlockingQueue<String> logQueue = new LinkedBlockingQueue<>();
public void produceLog(String log) {
logQueue.offer(log);
}
public void consumeAndProcessLog() throws InterruptedException {
String log = logQueue.take();
System.out.println("处理日志: " + log);
}
}
在这个系统中,produceLog方法将日志消息放入队列,而consumeAndProcessLog方法则从队列中取出并处理这些消息。LinkedBlockingQueue确保了在高并发环境下的线程安全和高效性。
第8章:总结
ConcurrentHashMap通过分段锁的设计实现了高效的并发访问;CopyOnWriteArrayList和CopyOnWriteArraySet在读多写少的场景中通过写时复制的策略提供了高性能的读操作;而ConcurrentLinkedQueue和ConcurrentSkipListMap等其他并发集合则提供了特定场景下的高效解决方案。