论文标题:LAMM: Language-Assisted Multi-Modal Instruction-Tuning Dataset, Framework, and Benchmark
论文作者:Zhenfei Yin, Jiong Wang, Jianjian Cao, Zhelun Shi, Dingning Liu, Mukai Li, Lu Sheng, Lei Bai, Xiaoshui Huang, Zhiyong Wang, Jing Shao, Wanli Ouyang
作者单位:Shanghai Artificial Intelligence Laboratory, Beihang University, The University of Sydney, Fudan University, Dalian University of Technology
论文原文:https://arxiv.org/abs/2306.06687
论文出处:NeurIPS2023
论文被引:28(01/05/2024)
项目主页:https://openlamm.github.io/
论文代码:https://github.com/OpenGVLab/LAMM
Abstract
大型语言模型已成为实现通用AI智能体(Agent)的一种有前途的方法。蓬勃发展的开源 LLM 社区大大加速了通过自然语言处理支持人机对话交互的智能体的发展。然而,人类与世界的交互不仅仅局限于文本这种模态,其他模态(如视觉)也至关重要。最近关于多模态大型语言模型的工作,如 GPT-4V 和 Bard,已经证明了它们在处理视觉模态方面的有效性。然而,这些工作的透明度有限,不足以支持学术研究。据我们所知,LAMM 是该领域最早的开源项目之一,包括语言辅助多模态指令微调数据集,框架和基准。我们的目标是将 LAMM 打造成一个不断发展的生态系统,用于训练和评估 MLLM,重点是促进AI智能体能够弥合想法与执行之间的差距,从而实现无缝的人机交互。我们的主要贡献有三个方面:
- 1)提出了一个全面的数据集和基准,涵盖了2D和3D视觉的各种视觉任务。广泛的实验验证了我们的数据集和基准的有效性。
- 2)概述了为 MLLM 构建多模态指令微调数据集和基准的详细方法,从而使 MLLM 研究能够快速扩展到不同领域,任务和模态。
- 3)我们提供了一个主要但有潜力的 MLLM 训练框架,该框架针对模态扩展进行了优化。我们还提供了基线模型,综合实验观察和分析,以加速未来的研究。
我们的基线模型可在 24 个 A100 GPU 小时内完成训练,框架支持使用 V100 和 RTX3090 进行训练,这要归功于开源社区。
1 Introduction
人类通过视觉和语言等多模态信息与现实世界进行交互,因为每种模态都具有描述世界的独特能力,从而为我们构建世界模型(world model)提供了更丰富的信息。长期以来,开发能够处理此类多模态信息,从中学习和记忆世界知识,理解人类发出的开放世界指令以采取行动和完成复杂任务的AI智能体(Agent)一直是AI领域的核心愿望。
大型语言模型(LLM)在实现这一愿望方面取得了显著进展。ChatGPT 和 GPT-4 [1] 模型可以直接理解用户意图,并可推广到未知的现实世界任务中 [2]。LLM 已成为通用任务界面。几乎所有的自然语言理解和生成任务都可以转化为指令输入,从而使单个 LLM 能够对各种下游应用进行零样本泛化[3, 4, 5]。在开源模型领域,LLaMA 系列[6, 7]以其性能和透明度脱颖而出。在 LLaMA 生态系统的基础上,Alpaca[8] 和 Vicuna[9] 等模型采用了不同的策略,如利用各种机器生成的高质量指令遵循(instruction-following)样本来提高 LLM 的性能,并取得了令人印象深刻的成果。值得注意的是,这些研究都是纯文本的。虽然像 GPT-4V [10] 和 Bard [10] 这样的多模态大型语言模型(MLLM)在处理视觉输入方面表现出了非凡的能力,但遗憾的是,它们目前还不能在开源学术社区中使用。
因此,我们提出了 LAMM,包括语言辅助多模态指令微调数据集,框架和基准。作为 MLLM 领域最早的开源项目之一,我们的目标是将 LAMM 打造成一个蓬勃发展的生态系统,用于训练和评估 MLLM,并进一步增强我们培养多模态AI智能体(Agent)的能力,使其能够弥合想法与执行之间的差距,促进人类与AI机器之间的无缝互动。在这项工作中,LLMs 充当通用任务界面(interface),由预先训练好的多模态编码器和语言指令提供视觉标记(visual tokens)输入。LLM 强大的建模能力与统一的优化目标相结合,有助于使模型与各种模态对齐(align)。这种设计使 LAMM 有别于视觉基础模型[11, 12],在视觉基础模型中,每个模型都针对特定任务进行了微调;也有别于多模态视觉语言基础模型,后者只能用作视觉任务的预训练模型,或拥有有限的零样本能力[13];还有别于在 tag-of-war problems 中的多任务基础模型[14]。
我们提出了一个新颖的指令微调数据集,它将 MLLM 的研究扩展到了图像和点云(point cloud)。我们的数据集强调细粒度信息和事实知识。此外,我们还首次尝试了 MLLMs 基准,该基准在各种计算机视觉任务中对现有开源模型进行了全面评估,并采用了专门为多模态语言模型设计的两种新评估策略。我们进行了 200 多项实验,就 MLLM 的能力和局限性提供了广泛的结果和宝贵的意见。此外,我们还建立了一个可扩展的框架,便于将多模态语言模型扩展到其他模态。我们的基线模型在与图像相关的下游任务中超越了现有的多模态语言模型,证明了我们的框架和数据集的有效性。最重要的是,我们已经开源了用于训练和评估多模态语言模型的完整代码库,涵盖图像和点云的指令微调数据集,使用我们的数据集和框架通过不同设置训练的各种基线模型,以促进多模态语言模型开放研究社区的发展。
Dataset
包括一个图像指令微调数据集和一个点云指令微调数据集,前者包含 186,098 个图像语言指令-响应对,后者包含 10,262 个点云语言指令-响应对。受 LLaVA [15] 和 GPT-4V [10] 的启发,我们从公开可用的数据集中收集图像和点云,并使用 GPT-API 通过 self-instruction [16] 方法,根据这些数据集的原始标签生成指令和响应。由此产生的数据集具有三个吸引人的特性:
- 1)为了强调细粒度和密集信息,我们添加了更多视觉信息,如视觉关系和细粒度类别,作为 GPT-API 的输入。
- 2)我们在基准测试中发现,现有的 MLLM 可能难以理解视觉任务指令。为此,我们设计了一种将视觉任务注释转换为指令-响应对(instruction-response pairs)的方法,从而增强了 MLLM 对视觉任务指令的理解和泛化。
- 3)考虑到 LLMs 容易对事实知识产生幻觉,我们的数据集还包含了常识性知识问答对,将 Bamboo[17] 数据集中的分层知识图谱标签系统和相应的维基百科描述结合在一起。
Benchmark
我们评估了 9 项常见的图像任务,共使用了 11 个数据集,超过 62,439 个样本;评估了 3 项常见的点云任务,共使用了 3 个数据集,超过 12,788 个数据样本;而现有的工作只提供了微调和评估特定数据集(如 ScienceQA)的量化结果,大多数工作只进行了演示或用户研究。
- 1)我们首次尝试为 MLLM 建立基准。我们进行了一次全面的基准测试,以量化现有多模态语言模型在各种计算机视觉任务上的零样本和微调性能,并将它们与这些任务的最先进方法进行比较,包括分类,物体检测,姿势估计,视觉问答,人脸分类,光学字符识别,物体计数等。
- 2)我们还尝试了两种专门为 MLLM 设计的新型评估策略。具体来说,对于文本生成的语言性能,我们建立了基于 GPT-API 的评分逻辑。而对于涉及定位点与查询图像之间交互的任务,如物体检测和姿态估计,我们提出了一种物体定位(object-locating)评估方法。
Framework
为了验证数据集的有效性,我们提出了一个主要但有潜力的 MLLM 训练框架。为了避免因引入多种模态而造成模态冲突,我们在框架设计中为不同模态区分了编码器,投影器和 LLM 微调模块。同时,通过添加其他模态的编码器和解码器,我们的框架可以灵活地扩展到更多模态和任务,如视频理解,图像合成等。我们提供了使用该框架在我们的基准上训练的基线模型的结果,并提出了加速未来研究的各种意见。
2 Related Work
Multimodal Large Language Model.
随着大型语言模型(LLM)(如 ChatGPT,GPT-4 [1] 等)的快速发展,许多研究设法探索在 LLM 的基础上融入其他模态,这些研究可分为两个视角。
- 1)系统设计视角:
- Visual ChatGPT [18] 和 MMREACT [19] 通过处理用户查询调用各种视觉基础模型,在视觉基础模型的帮助下研究 ChatGPT 的视觉角色。
- ViperGPT [20] 指示 LLM 将视觉查询解析为由 Python 代码表达的可解释步骤。
- HuggingGPT [21] 通过在 Huggingface 上集成更多专家模型,将其框架扩展到更多模态。
- 2)端到端可训练模型视角: 另一种方法是将不同模态的模型连接成端到端可训练模型,也称为多模态大语言模型。
- Flamingo [22] 为语言和视觉建模提出了一个统一的架构。
- BLIP-2 [23] 则引入了一个 Query Transformer 来连接从图像到文本模态的信息。
- Kosmos [4] 和 PaLM-E [24] 在网络规模的多模态语料库上建立了端到端的可训练框架。
- 通过开源的 LLaMA[6],Mini-GPT4[25]只优化了一个可训练的投影矩阵,它将预训练的 BLIP-2 视觉编码器和大型语言模型连接起来。
- LLaVA[15] 和 mPLUG-OwL[26] 也对 LLM 进行了微调。
- 除了仅将视觉信息作为输入输入到 LLM 之外,LLaMA-Adapter [27],Multi-modal GPT [28] 和 Otter [29] 也将多模态信息与 LLM 的中间特征整合在一起。
Instruction Tuning.
指令微调(Instruction tuning)[30] 是一种为提高大型语言模型遵循指令的能力和增强下游任务性能而提出的方法。
- 指令微调模型,如 InstructGPT [31],OPT-IML [32],Alpaca [8],与它们的基础模型相比,已经显示出很好的改进效果。
- 现有的指令微调数据集主要来自学术数据集(如 FLAN [30]),从 ChatGPT 使用中收集的chatbot数据(如 ShareGPT),或使用 self-instruct [16]方法构建的数据集(如 Alpaca)。
- 除了纯文本教学调整数据集,Multi-Instruct [33] 涵盖了 47 种多模态任务。
- Mini-GPT4 [25] 通过将图像文本数据集和手写指令模板组合在一起,构建了指令遵循数据集。
- LLaVA[15]将图像描述和边界框作为 COCO 图像的上下文输入 GPT-4,从而获得 150K 指令数据。
- Otter[29]从多模态 MMC4 数据集[34]中建立了此类指令微调数据集,并通过将相似指令分组的方式将上下文中的示例纳入指令微调。
3 Dataset

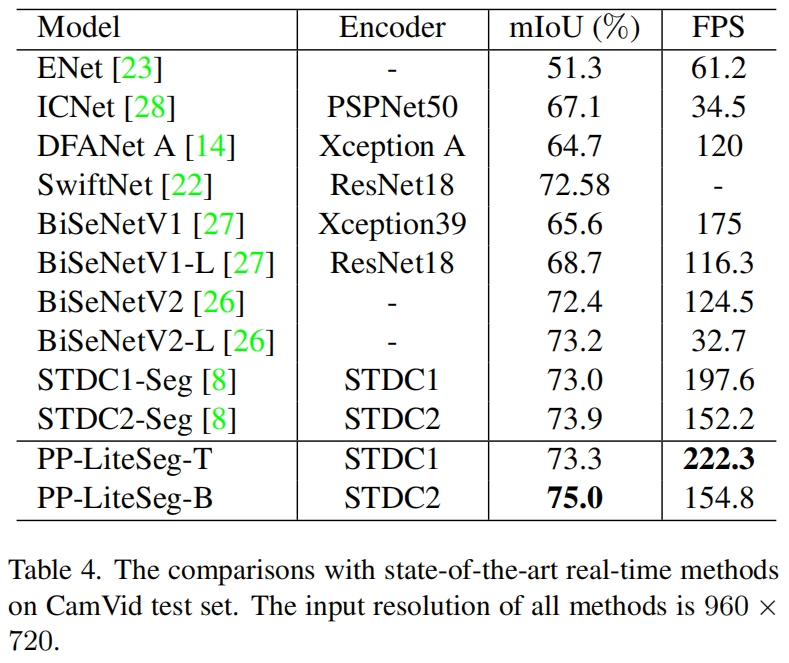
图1:我们的数据集概述,演示了使用GPT-API构建指令微调数据集的过程。通过设计不同的系统消息,上下文学习对和查询,我们创建了涵盖几乎所有2D和3D视觉高级视觉任务的数据集。数据集包括四个不同的组:n轮日常对话,n轮事实知识对话,1轮详细描述和1轮视觉对话。值得注意的是,对于视觉任务的引入,我们只使用GPT-API生成指令响应模板,而没有直接生成对话数据。最后,下面给出了数据集的一些示例,包括2D和3D场景及其相应的指令-响应对。
我们介绍了一个全面的多模态指令微调数据集,其中包括来自公开数据集的各种视觉任务的图像和点云,以及基于 GPT-API 和self-instruct方法的高质量指令和响应[16]。具体来说,我们的数据集包含 186K 个语言-图像指令-响应对和 10K 个语言-3D 指令-响应对。图 1 是数据集的构建过程概览。我们提供了如何构建多模态指令微调数据集的详细信息,以促进我们工作的复制和进一步发展。我们在附录中展示了样本数据的其他演示,并提供了完整的提示方法。
我们设计了 4 种多模态指令-响应对(instruction-response pairs):
- 1)C1:n 轮日常对话,侧重于多模态日常对话。
- 2)C2:n 轮事实知识对话,针对需要进行事实知识推理的对话。
- 3)C3:1 轮详细的描述,旨在阐述文本中的图像和 3D 场景。
- 4)C4:1 轮视觉任务对话,将视觉任务转化为指令-响应对,旨在提高对视觉任务的泛化能力。
我们在数据集中纳入了各种2D和3D视觉任务,例如直接与自然语言兼容的图像描述,场景图识别和 VQA,以及输出标签,边界框,数字和单词列表的分类,检测,计数和 OCR。请注意,点云指令微调数据集不包括 C2:n 轮事实知识对话类别的数据。这是由于目前缺乏公开可用的包含事实知识的定义明确的标注系统的3D数据集。在我们的数据集中,指令-响应对来自 8 个图像数据集和 4 个点云数据集,如图 1 所示。
前三种类型的指令-响应对是通过向 GPT-API 输入一些特殊设计的提示(Prompt)来生成的,即系统信息,上下文学习对和查询:
- 1)系统信息用于告知 GPT-API 有关任务的定义和要求。
- 2)人工注释若干情境学习对,以确保以类似方式生成其余指令-响应对。
- 3)查询包括对图像描述,物体的边界框,物体之间的关系,Bamboo 标签系统中的事实知识及其维基百科描述的全面注释。
最后一类指令-响应对也应用了系统信息和上下文学习对,但使用 GPT-API 来生成指令-响应对模板池。这样,许多视觉任务(如物体/关键点检测,OCR,计数等)的ground truth注释都可以插入到这些模板中,从而更容易转换成可靠的语言响应,而不是上述基于查询的转换。
4 Benchmark
与 LLaVA [15],MiniGPT4 [25] 和 mPLUG-owl [26] 只提供演示和用户研究来定性评估其 MLLM 的性能不同,我们提出了首个 MLLM 基准,用于评估 MLLM 在各种2D和3D视觉任务中的定量性能。它包括一个推理管道和一组评估指标。具体来说,2D视觉任务基准评估了 9 项常见的图像任务,共使用了 11 个数据集,超过 62,439 个样本。3D视觉任务基准利用 3 个数据集和超过 12,788 个数据样本,评估了 3 项常见的点云任务。
Inference Pipeline.
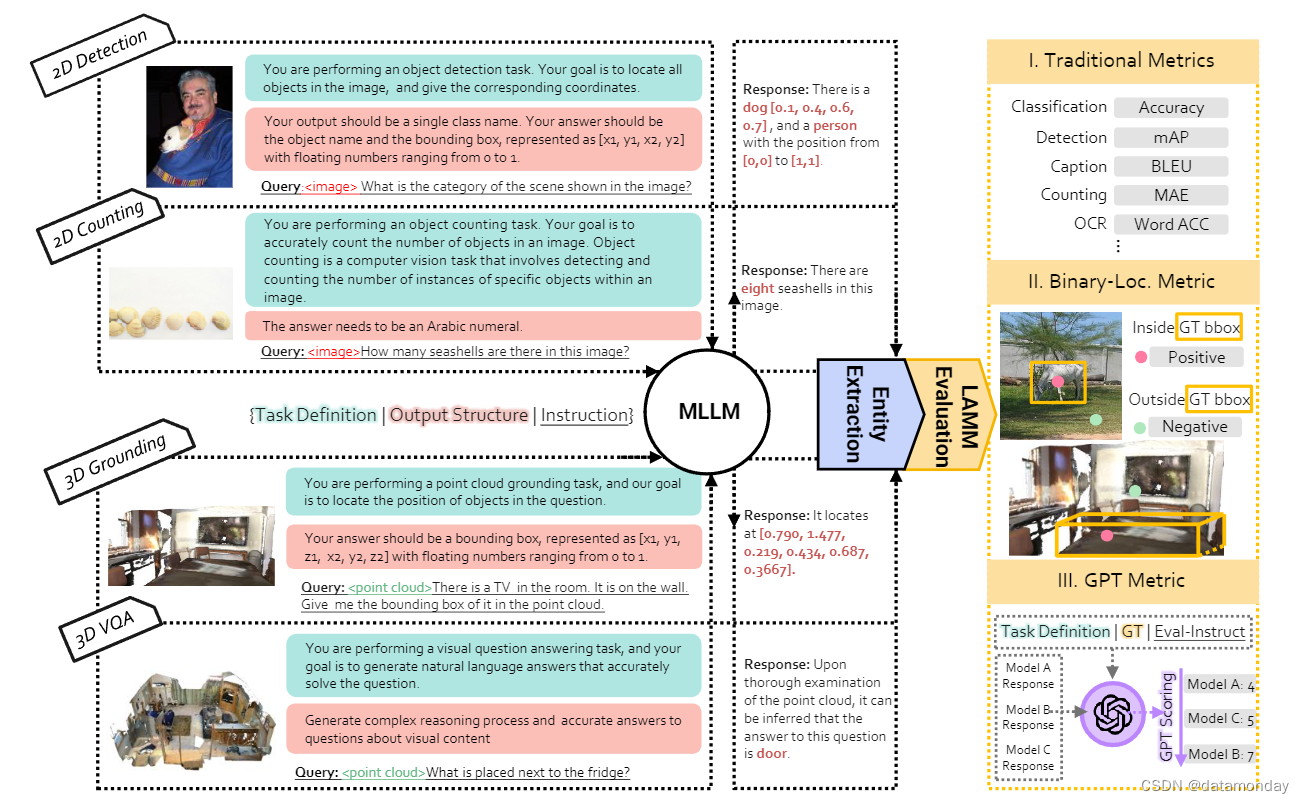
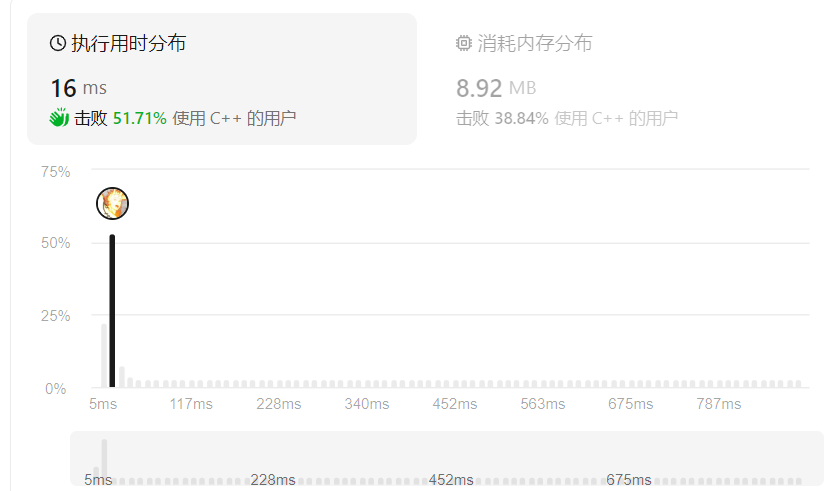
图 2:我们的基准概述。它包括 2D 和 3D 管道,涵盖多个计算机视觉任务。对于每项任务,我们都会提供任务定义、输出结构和一组问题作为 MLLM 模型的指令。然后对输出进行实体提取,以提取关键答案。LAMM 评估用于评价模型的性能,其中包括传统指标,二进制定位指标和 GPT 指标。
它包括处理输入指令和提取输出实体的方式,以确保 MLLM 能够产生合理的响应,并得到公正的评估。我们构建推理指令(Inference Instruction)是为了帮助模型更好地理解它所执行的任务和所需的输出结构,目的是提高基准测试过程的稳定性和可靠性。推理指令包括任务定义,输出结构和通常使用的查询问题,如图 2 所示。受思维链提示方法[35]的启发,我们还提示 MLLM 在得到最终答案后进行复杂推理,从而获得更可靠的答案。然后,我们使用自然语言工具包(NLTK)和正则表达式匹配从输出文本中提取实体。这些实体就是结果。
Evaluation Metrics.
评估指标集包括传统指标,二进制定位指标和 GPT 指标。传统度量标准是来自所列2D和3D视觉任务的特定任务度量标准,是评估 MLLM 如何处理视觉任务的最严格度量标准。在二进制定位度量中,模型需要通过 “output the position of the object” 指令输出识别物体的近似位置,如果输出结果在物体的ground truth边界框内,则认为输出结果为真。这是比较 MLLM 模型定位能力的直接指标。为了评估 MLLM 模型的理解和答题能力,我们利用 GPT 指标来评估答案与ground truth的相关性和准确性。具体来说,我们通过图 2 中描述的指令,促使 GPT 为每个模型生成的输出结果打分。评分标准基于准确性,相关性,流畅性,逻辑连贯性和信息丰富度。
Evaluation Settings.
所有2D和3D视觉任务都能以零样本的方式进行评估,即测试数据与 MLLM 的训练数据没有交集。此外,我们还评估了 MLLM 在多个主流任务测试数据集上的微调能力,如2D任务中的检测,分类和 VQA,以及3D任务中的检测,grounding和 VQA。
5 Experiments and Results
5.1 Framework
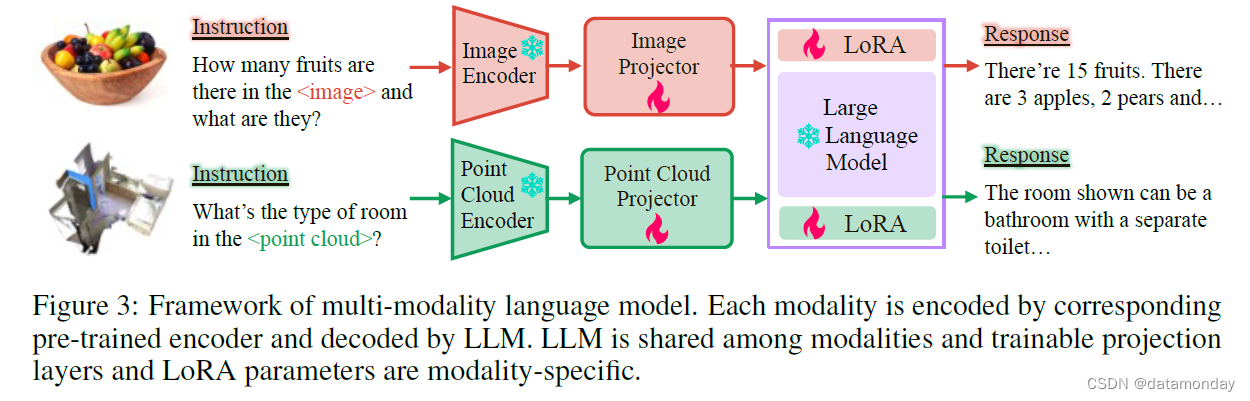
基线 MLLM 的整体框架如图 3 所示。每种模态(图像或点云)都由相应的编码器处理,然后由可训练的投影层将其特征投影到与文本嵌入相同的特征空间。指令由 SentencePiece Tokenizer[36]直接被 token 化,然后将视觉和文本标记连接起来,输入 LLM 模型。为了有效地对 LLM 进行微调,我们在自注意层的所有投影层中添加了 LoRA [37] 参数。不同视觉模态的 LoRA 参数不共享。多模态标记由共享的 LLM 模型和相应的 LoRA 参数解码。如图 3 所示,在训练过程中只对特征投影器和 LoRA 参数进行了优化。我们使用 Vicuna-13B [9] 作为 LLM。LoRA 模块的 rank 设置为 32。我们使用 4 个 A100 GPU 以一阶段端到端方式训练包括投影层和 LoRA 模块在内的所有参数。
输入图像的大小调整为 224×224,并分割成 256 个图块。我们使用 CLIP [38] 预先训练的 ViT-L/14,并使用转换器层输出的图像 patch 特征作为图像表示。我们采用 FrozenCLIP [39] 的设计对点云进行编码,其中点云由 PointNet++ [40] 标记为 256 个标记,并由 CLIP 预训练的 ViT-L/14 进一步编码。
5.2 Results on Traditional Metrics
Zero-shot Setting on 2D Vision Tasks.
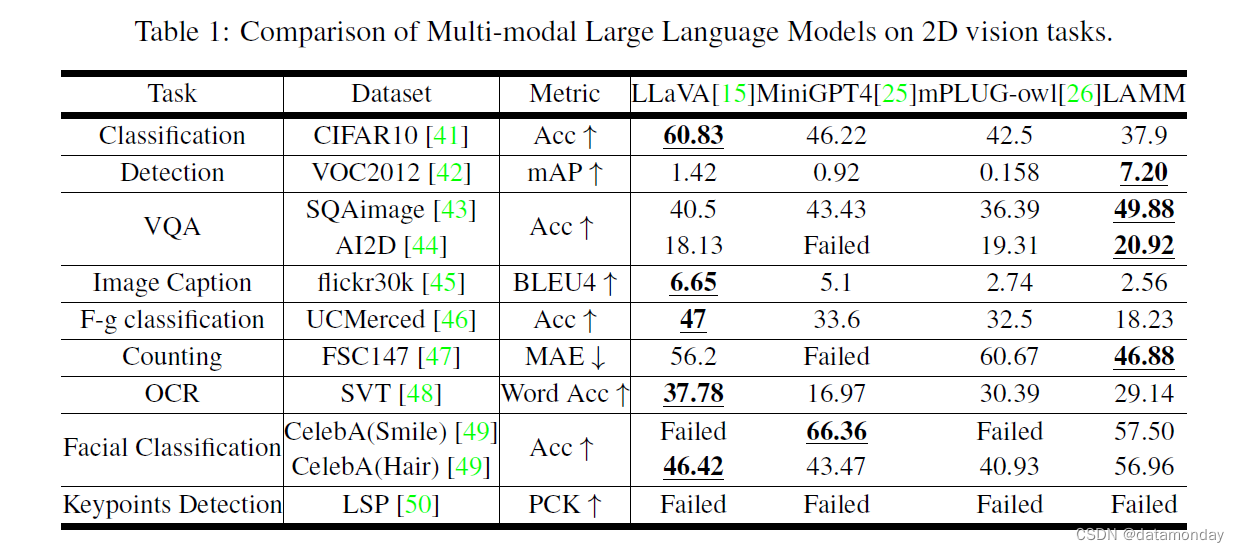
表 1 显示了 MLLM 在2D视觉任务中通过传统指标得出的结果。所有 MLLM 模型都是在零样本环境下进行测试的。虽然 MLLM 模型在识别开放词汇类,理解图像和回答问题方面表现出了一定的能力,但在涉及物体定位的任务中,包括物体检测,计数和关键点检测,它们的表现却很差。
定位感知任务(Localization-aware Tasks):在检测任务中,我们的基线模型表现出了更强的定位能力,但预测的边界框与ground truth边界框之间仍有明显差距,这表明 MLLM 在输出代表点的某些数字和推理空间信息方面存在弱点。在计数任务中,MLLM 模型预测的物体数量与ground truth之间存在明显差距。MiniGPT4 在这项任务中失败了,因为它无法为大多数数据提供具体数字。至于关键点检测任务,我们要求 MLLM 模型依次预测每个人类关键点的位置。然而,所有预测的位置都不在可接受的范围内。MLLM 在这项任务中表现出了明显的差距,这表明它们在准确预测关键点位置方面存在困难。
VQA 任务:与其他模型相比,我们的基线模型在图像理解和多选题回答方面具有一定的优势。需要注意的是,我们与之比较的 LLaVA 模型是在零样本设置下进行评估的。此外,我们将随机选择过程从 LLaVA 评估中移除,以获得更直接的评估结果。
图像描述任务:所有 MLLM 模型在图像图像描述方面的表现都很差。我们认为 BLEU4 并不是一个合适的指标,因为较长的图像描述可能会导致较低的分数,而 MLLM 往往会输出详细的描述。
分类任务:在细粒度分类任务和人脸分类任务中,所有 MLLM 的表现都很差。具体来说,在 CelebA (Smile) 数据集上,LLaVA 模型对所有查询都输出了 “是”,而 mPLUG 模型则随机给出预测。不过,在 CelebA (Hair) 数据集方面,MLLMs 可以识别头发的颜色,因为推断颜色识别的视觉知识相对简单。这些结果表明,MLLM 模型在需要精细区分的任务中可能会遇到困难。
OCR 任务:在 OCR 任务方面,LLaVA 可以识别和提取图像中的文本。但是,我们的基线模型在这项任务中表现不佳。我们将在附录中对结果进行更多分析,并找出性能差距的几个潜在原因。
Fine-tuning Setting on Image Tasks.
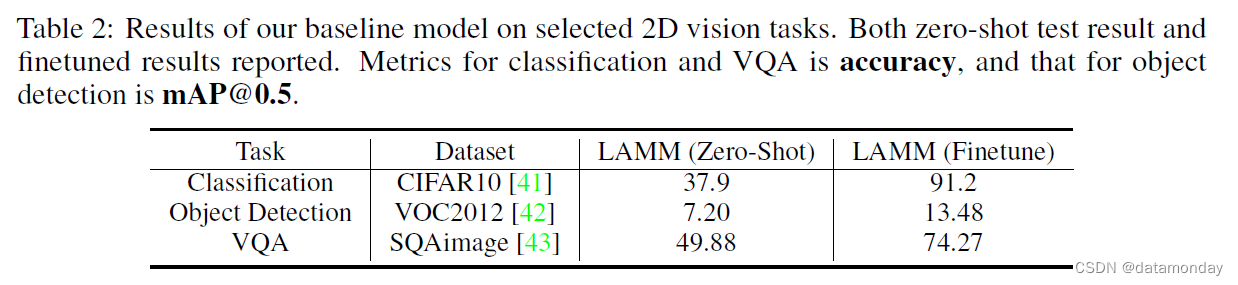
我们还在几个视觉数据集(包括 CIFAR10,VOC2012 和 SQAimage)上对基线模型进行了微调。结果如表 2 所示。微调后的基线模型在 CIFAR10 上达到了 91% 的准确率。在 VOC2012 上,它的 mAP 也达到了 13%,而在零样本设置下,mAP 只有 4.8%。这些结果表明,我们的基线模型在对检测数据进行微调后,可以获得定位物体的能力。
Zero-shot Setting on Point Cloud Tasks.
表 3 显示了我们的基线模型在3D场景理解任务中的结果,分别是在零样本摄和微调设置下的结果。在所有测试任务中,微调后的结果都明显优于零样本摄设置。我们在 ScanQA 多选数据上微调的基线模型几乎达到了 100%的准确率,这可能是由于训练/测试差距较小和3D数据集规模较小造成的过拟合问题。
5.3 Results of Binary Locating Metric and GPT Metric
Binary Locating Metric.
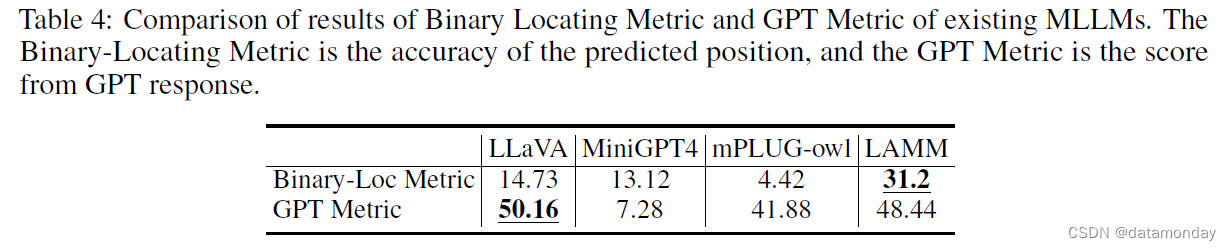
表 4 显示了 MLLMs 在拟议的二进制定位指标和 GPT 指标上的零样本测试结果。二进制定位指标涵盖了来自 VOC2012,FSC147 和 LSP 的数据。由于我们的基线模型是在带有检测指令的少量数据上训练出来的,因此在定位精度上有显著提高。
GPT Metric.
我们使用各种任务计算了 GPT 分数,包括 VQA,分类,图像描述以及少量检测和计数任务。如表 4 所示,LLaVA 在性能上超过了其他模型,而 LAMM 虽然略低于 LLaVA,但仍然远远超过 Minigpt4 和 mPLUG-owl。
5.4 Observation and Analysis
我们在各种任务中对 MLLM 模型进行了数十次实验和观察,以总结其当前的能力和局限性。
Better Performance in Counting Tasks with Small Number of Objects.
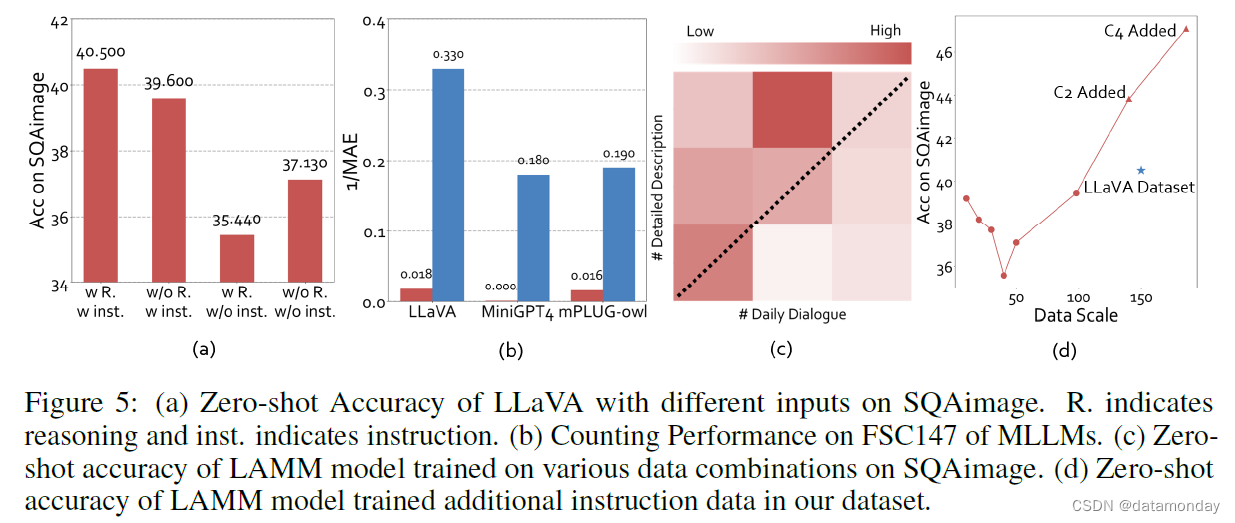
如表 1 所示,最近的 MLLM 在计数任务中表现不佳。在 FSC147 数据集中,有一些数据样本包含几十个甚至上百个物体,对于这些数据样本,MLLMs 会回答 “我无法准确计算数量”。因此,我们对 FSC147 数据集中少于 10 个对象的子集进行了测试,以评估模型在简单数据上的性能,如图 5 (b) 所示。结果表明,MLLM 能够大致估算出图像中指定物体的数量,但仍无法提供准确的数值。
GPT Metric is More Appropriate Than BLEU.

图 4 展示了 LLaVA 和 LAMM 在 Flickr30k 数据集样本数据上生成的图像描述之间的比较。很明显,LAMM 模型生成的图片说明更加详细。但是,一个明显的缺点是其生成的句子与ground truth句子之间的相关性较低,因此导致表 1 中所示的 BLEU 分数较低。因此,我们尝试采用 GPT 指标来评估模型输出的图像描述与ground truth图像描述的相关性和准确性。与 LLaVA 相比,GPT 给 LAMM 模型打出了更高的分数,这表明我们的模型更能生成高质量,与图像相关的文本输出。这一观察结果还提出了一种可能性,即使用基于 GPT 的指标来评估图像描述任务,而不是 BLEU,可能会提供更有效的评估标准。
Capable of Object Localization but Struggles with Precise Bounding Box Prediction.
我们将 LLaVA 在 VOC2012 数据集上的结果可视化。图 4 (a) 显示,LAMM 模型能够大致指出图像中的鸟,但无法准确定位整个物体。
LAMM Model Exhibits Fine-Grained Classification Ability on CIFAR10.
如图 4 所示,当显示一幅 32x32 像素的汽车图片时,模型的预测类别更为细化: “菲亚特 500L 2012”,准确地识别了汽车的品牌和型号。图 4 (b) 的左侧子图显示了 Autoevolution [54] 上的菲亚特 500L 2012 图像,显示它与 CIFAR10 的输入图像具有非常相似的特征。这些结果表明,使用我们的数据集训练的 MLLM 能够进行更精细的分类,能够识别图像中的细微差别并将其归入更具体的类别。
Instruction and Reasoning Enhance Performance on SQAimage Data.
根据 LLaVA [15],我们在 SQAimage 数据集上使用不同的推理方法进行了实验,包括带或不带推理或指令的提示。带推理的提示使 MLLM 在呈现最终结果之前输出推理过程。带指令的提示为 MLLM 提供了任务定义和问题输出结构,以帮助模型更好地理解任务。图 5 (a) 中的结果显示,指令和推理都提高了 MLLM 的 VQA 能力。这些结果凸显了在 MLLM 中加入特定任务信息和推理过程的重要性。
Difficulty in Comprehending Visual Information for Domain Shifted Data.
我们对 UCMerced,CelebA 和 LSP 等几个与训练数据集存在显著偏差的数据集进行了分析。UCMerced 数据集由场景的自上而下视图组成,CelebA 是一个可以描述表情和头发颜色的面部数据集,LSP 数据集涉及人体的 14 个关键点,它们在训练阶段与 COCO 数据集存在显著差异。这些结果表明,在与训练数据集有明显偏差的数据集上,MLLM 模型的性能可能会明显下降。
Difficulty in Reading Text on SVT data.
我们分析了基线模型在 SVT 数据集上的表现,结果不尽人意,见表 1。一种可能的解释是,我们使用 TextVQA [55] 数据集生成视觉任务对话,该数据集更倾向于对话文本,而不是与 OCR 相关的视觉任务。这种数据集特性上的不匹配可能导致我们的模型在 SVT 数据集上的泛化效果不理想。为了解决这个问题,我们打算进行进一步的研究,并在训练过程中加入更合适的 OCR 数据,以提高我们的模型在 OCR 相关视觉任务中的表现。
Data volume validation on SQAimage data.
如图 5 © (d) 所示,我们的四种图像指令微调数据集在所有子集上的性能都优于 LLaVA[15],从而使整个数据集的整体性能提高了 7%。此外,我们还研究了按不同比例采样日常对话和详细描述数据的影响。值得注意的是,即使只有 10k 例子的小规模数据集,我们的数据集也取得了与 LLaVA 数据集相当的结果。随着数据集规模的增大,我们模型的整体性能不断提高,这表明我们的数据集是可扩展的,可以通过添加更多数据进一步优化。
6 Limitations
在这一部分,我们将从数据集,基准和框架的角度讨论这项工作的局限性和社会影响。
Dataset
在我们的研究中,我们使用了最先进的语言模型 GPT-API 来生成多模态教学数据。为了达到所需的格式(包括多轮对话和一轮详细说明),我们提供了系统消息和对话示例,作为使用 GPT-API 生成数据的指导。使用 GPT-API 生成基于文本的对话在自然语言处理领域已被广泛采用,之前在多模态数据方面的工作[8, 15, 16]已在各种任务中展示了可喜的成果。
不过,必须承认 GPT 模型的固有局限性,使用 GPT-API 不会改变这些局限性。GPT-API 无法直接获取视觉信息,只能依赖文字上下文,如图像描述和属性,这限制了它对图像的理解,并可能导致遗漏详细信息。虽然 GPT-API 擅长生成连贯且与上下文相关的回答,但偶尔也会生成看似合理但与事实不符或缺乏适当上下文的回答。在理解复杂或模棱两可的查询时,它也可能会遇到困难。此外,用于训练的生成数据可能会无意中反映出 GPT-API 的固有偏见和其他真实性问题。为了解决与 GPT-API 生成的数据有关的道德问题,我们对数据进行了人工抽样检查,确保生成的数据符合社会价值观,隐私,安全,毒性和公平性要求和期望。在附录中,我们对数据质量进行了评估,并展示了其他数据样本。我们还透明地提供了用于调用 GPT-API 的完整提示,以确保整个工作的透明度。
Benchmark
LAMM 在格式化的计算机视觉任务和数据集上评估 MLLM。由于语言模型输出的多样性,指标可能会在不同实验中出现波动。此外,LAMM 目前采用 GPT-eval 和二进制定位等指标作为评估 MLLM 性能的初步尝试。要提高基准结果的稳定性并设计出更合适的度量标准,还需要进一步的研究,这也是未来研究的一个很有前景的方向。
Framework
我们的工作建立了一个简单的 MLLM 框架,为我们的数据集和基准建立了一个基准模型。不过,在未来的工作中,MLLM 仍有进一步开发和精心设计的潜力,以提高其能力和性能。
7 Conclusion
最后,我们的工作介绍了多模态大型语言模型领域的开源项目 LAMM。我们介绍了图像和点云指令微调数据集和基准,旨在将 LAMM 打造成一个用于训练和评估 MLLM 的繁荣生态系统。我们还提供了一个可扩展的框架,便于将 MLLM 扩展到其他模态。我们的研究展示了 MLLMs 在处理图像和点云等视觉模态方面的有效性,并强调了其通过指令微调实现通用化的潜力。通过公开我们的代码库,基线模型,指令微调数据集和评估基准,我们旨在为 MLLMs 培养一个开放的研究社区。我们相信,我们的工作将为 MLLMs 的发展和通用多模态智能体(Agent)的开发做出贡献。
![【算法每日一练]-图论(保姆级教程篇14 )#会议(模板题) #医院设置 #虫洞 #无序字母对 #旅行计划 #最优贸易](https://img-blog.csdnimg.cn/direct/dc616bd3440146dca36838bed4baecc3.png)