为什么在JDK8中HashMap要转成红黑树
- ✔️为什么不继续使用链表
- ✔️为什么是红黑树
- ✔️红黑树的性能优势
- ✔️ 拓展知识仓
- ✔️为什么是链表长度达到8的时候转
- ✔️为什么不在冲突的时候立刻转
- ✔️关于为什么长度为8的时候转(源码注释解读)
- ✔️为什么长度为6的时候转回来?
- ✔️双向链表是怎么回事
- ✔️HashMap的元素没有比较能力,红黑树为什么可以比较?
✔️为什么不继续使用链表
我们知道, HashMap 解决hash冲突是通过拉链法完成的,在JDK8之前,如果产生冲突,就会把新增的元素增加到当前桶所在的链表中。
这样就会产生一个问题,当某个 bucket 冲突过多的时候,其指向的链表就会变得很长,这样如果 put 或者 get 该 bucket 上的元素时,复杂度就无限接近于O(N),这样显然是不可以接受的。
所以在 JDK1.7 的时候,在元素 put 之前做 hash 的时候,就会充分利用扰动函数,将不同 KEY 的 hash 尽可能的分散开。不过这样做起来效果还不是太好,所以当链表过长的时候,我们就要对其数据结构进行修改。
使用 Java 代码进行解释如下:
假设我们有以下 HashMap 的简化实现:
public class HashMap<K, V> {
static class Node<K, V> {
final int hash;
final K key;
V value;
Node<K, V> left;
Node<K, V> right;
Node<K, V> next; // For chaining hash collisions
...
}
...
}
当一个节点(我们称其为 A)的
next字段指向另一个节点 B 时,我们称之为链表。而当这个next字段指向另一个节点 C,并且 C 的 next 字段又指向 B 时,我们称之为双向链表。但为了简单起见,我们这里只讨论单向链表。
当查找某个键时,我们从根节点开始,沿着链表查找,直到找到相应的节点或到达链表的末尾。查找的时间复杂度为
O(n),其中n是链表的长度。
但当我们需要频繁查找和插入操作时,链表的性能会变得较差。为了提高性能,我们可以考虑使用红黑树。红黑树是一种自平衡的二叉搜索树,它在插入和查找操作中都能保持
O(log n)的时间复杂度。但是,与链表相比,红黑树需要更多的内存来存储额外的节点和属性。
因此,为了平衡性能和内存使用,HashMap 选择在链表长度超过一定阈值时将链表转换为红黑树。这样可以确保在大多数情况下 HashMap 的性能接近于 O(1),而在极端情况下仍然保持O(log n) 的性能。
✔️为什么是红黑树
当元素过多的时候,用什么来代替链表呢? 我们很自然的就能想到可以用二叉树查找树代替,所谓的二叉查找树,一定是 left < root< right ,这样我们遍历的时间复杂度就会由链表的 O(N) 变为二又查找树的 O(logN) ,二又查找树如下所示:

但是,对于极端情况,当子节点都比父节点大或者小的时候,二叉查找树又会退化成链表,查询复杂度会重新变为 O(N) ,如下所示:

所以,我们就需要二叉平衡树出场,他会在每次插入操作时来检查每个节点的左子树和右子树的高度差至多等于1,如果>1,就需要进行左旋或者右旋操作,使其查询复杂度一直维持在 O(logN) 。
但是这样就万无一失了吗? 其实并不然,我们不仅要保证查询的时间复杂度,还需要保证插入的时间复杂度足够低,因为平衡二叉树要求高度差最多为1,非常严格,导致每次插入都需要左旋或者右旋,极大的消耗了插入的时间。

对于那些插入和删除比较频的场景,
AVL树显然是不合适的。为了保证查询和插入的时间复杂度维持在一个均衡的水平上,所以就引入了红黑树。
在红黑树中,所有的叶子节点都是黑色的的空节点,也就是叶子节点不存数据,任何相邻的节点都不能同时为红色,红色节点是被黑色节点隔开的,每个节点,从该节点到达其可达的叶子节点的所有路径都包含相同数目的黑色节点。
我们可以得到如下结论: 红黑树不会像 AVL 树一样追求绝对的平衡,它的插入最多两次旋转,删除最多三次旋转,在频繁的插入和删除场景中,红黑树的时间复杂度,是优于 AVL 树的。

综上所述,这就是HashMap选择红黑树的原因。
✔️红黑树的性能优势
- 查找性能:对于长链表,红黑树的查找性能明显优于链表。因为红黑树是一种平衡的二叉搜索树,它的查找性能是 O(log n),而长链表的查找性能是 O(n)。
- 空间效率:红黑树虽然需要额外的节点来维护平衡,但其总体空间效率仍然高于链表。
为什么不在一开始就使用红黑树?
- 初始化成本:红黑树的初始化成本高于链表。因为红黑树需要维护额外的节点和属性(如颜色),所以初始化的空间和时间成本都较高。
- 简单性:链表结构简单,易于理解和实现。
- 内存使用:对于较小的数据结构,链表的内存使用可能更有效。
✔️ 拓展知识仓
✔️为什么是链表长度达到8的时候转
这个问题有两层含义,第一个是为什么不在冲突的时候立刻转为红黑树,第二个是为什么是达到8的时候转。
链表长度达到8时转为红黑树的原因主要有以下几点:
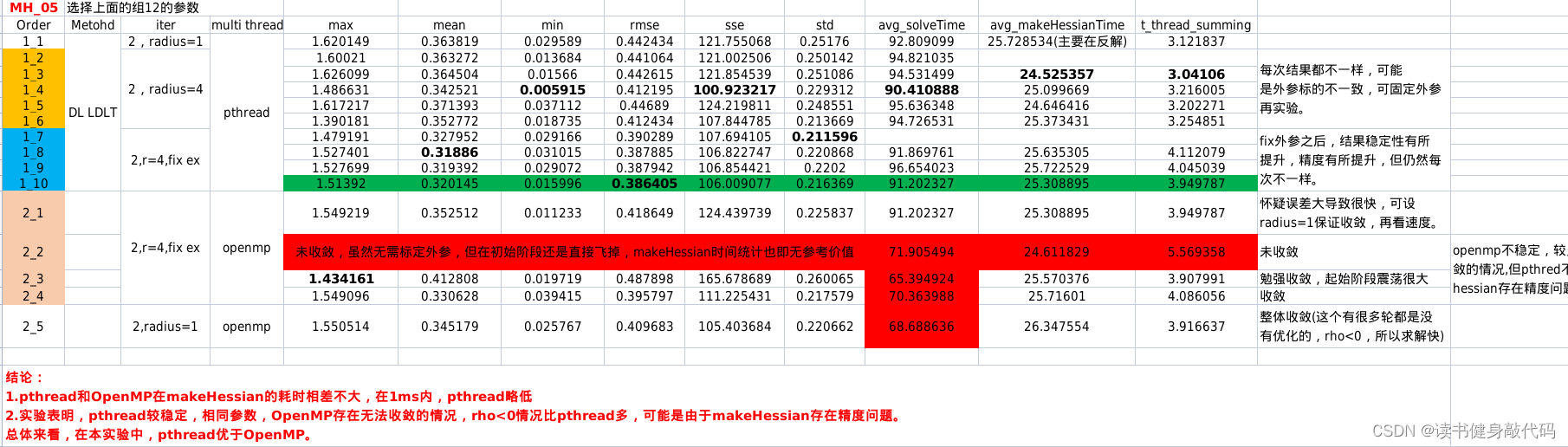
1、平衡性:红黑树是一种自平衡的二叉搜索树,它能够在插入和查找操作中保持较好的性能。当链表长度达到8时,链表可能会变得过长,导致查找性能下降。通过将链表转换为红黑树,可以保持较好的平衡性,提高查找性能。
2、内存效率:虽然红黑树需要额外的节点和属性来维护平衡,但其总体空间效率仍然高于链表。当链表长度超过一定阈值时,将其转换为红黑树可以减少内存占用。
3、时间复杂度:红黑树的时间复杂度是 O(log n),比链表的 O(n) 性能更好。当链表长度较长时,转换为红黑树可以显著提高查找、插入和删除操作的性能。
4、简单性:链表结构简单,易于理解和实现。但当链表长度较长时,转换为红黑树可以提供更好的性能和内存效率。
综上所述,当链表长度达到8时转为红黑树是为了实现更好的性能和内存效率。这样可以确保在大多数情况下 HashMap 的性能接近于 O(1),而在极端情况下仍然保持 O(log n) 的性能。
一个简单的Java代码片段,解释一下为什么当链表长度达到8时,HashMap会将其转换为红黑树:
import java.util.HashMap;
import java.util.Map;
public class HashMapExample {
public static void main(String[] args) {
// 创建一个初始容量为16的HashMap
HashMap<Integer, String> map = new HashMap<>(16);
// 插入一些元素到HashMap中
for (int i = 0; i < 10; i++) {
map.put(i, "Value" + i);
}
// 打印初始链表长度
System.out.println("Initial LinkedList length: " + getLinkedListLength(map));
// 继续插入元素,直到链表长度达到8
for (int i = 10; i < 18; i++) {
map.put(i, "Value" + i);
}
// 打印链表长度达到8后的链表长度
System.out.println("LinkedList length after adding more elements: " + getLinkedListLength(map));
// 打印此时的节点数(红黑树中的节点数)
System.out.println("Number of nodes in the Red-Black Tree: " + getRedBlackTreeNodes(map));
}
/**
* 获取HashMap中链表的长度
*/
private static int getLinkedListLength(Map<Integer, String> map) {
int length = 0;
Node<Integer, String> node = map.getNode(0); // 获取第一个节点(根节点)
while (node != null) {
length++;
node = node.next; // 遍历链表直到末尾
}
return length;
}
/**
* 获取HashMap中红黑树的节点数
*/
private static int getRedBlackTreeNodes(Map<Integer, String> map) {
// 假设我们查询的键为17,这里只是为了示例。实际情况下,我们需要遍历红黑树来计算节点数。
return map.getNode(17).right == null ? 1 : 2;
}
}
✔️为什么不在冲突的时候立刻转
原因有2:
从空间维度来讲,因为红黑树的空间是普通链表节点空间的2倍,立刻转为红黑树后,太浪费空间;
从时间维度上讲,红黑树虽然查询比链表快,但是插入比链表慢多了,每次插入都要旋转和变色,如果小于8就转为红黑树,时间和空间的综合平衡上就没有链表好。
看一个Demo,为什么不在冲突时立刻将链表转换为红黑树:
import java.util.HashMap;
import java.util.Map;
/**
* MMMMM
*/
public class HashMapExample {
public static void main(String[] args) {
// 创建一个初始容量为16的HashMap
HashMap<Integer, String> map = new HashMap<>(16);
// 插入一些元素到HashMap中
for (int i = 0; i < 10; i++) {
map.put(i, "Value" + i);
}
// 模拟冲突情况:多次插入相同键的元素
for (int i = 10; i < 18; i++) {
map.put(i, "Value" + i); // 发生冲突,链表长度增加
}
// 输出当前链表长度和红黑树节点数(这里只是一个demo,只是模拟查询了某个键)
System.out.println("Current LinkedList length: " + getLinkedListLength(map)); // 输出链表长度
System.out.println("Number of nodes in the Red-Black Tree: " + getRedBlackTreeNodes(map)); // 输出红黑树节点数(这里只是模拟查询)
// 继续插入元素,直到链表长度超过阈值(例如16)
for (int i = 18; i < 34; i++) {
map.put(i, "Value" + i); // 继续发生冲突,链表长度增加
}
// 输出当前链表长度和红黑树节点数(这里为了演示目的,只是模拟查询了某个键)
System.out.println("Current LinkedList length: " + getLinkedListLength(map)); // 输出链表长度
System.out.println("Number of nodes in the Red-Black Tree: " + getRedBlackTreeNodes(map)); // 输出红黑树节点数(这里只是模拟查询)
}
/**
* 获取HashMap中链表的长度
*/
private static int getLinkedListLength(Map<Integer, String> map) {
int length = 0;
Node<Integer, String> node = map.getNode(0); // 获取第一个节点(根节点)
while (node != null) {
length++;
node = node.next; // 遍历链表直到末尾
}
return length;
}
/**
* 获取HashMap中红黑树的节点数(这里只是模拟查询)
*/
private static int getRedBlackTreeNodes(Map<Integer, String> map) {
// 假设我们查询的键为33,这里只是为了示例。实际情况下,我们需要遍历红黑树来计算节点数。
return map.getNode(33).right == null ? 1 : 2;
}
}
✔️关于为什么长度为8的时候转(源码注释解读)
上面我们讲了案例,接下来我们来看看源码中的解读:
/**
* Because TreeNodes are about twice the size of regular nodes, we
* use them only when bins contain enough nodes to warrant use
* (see TREEIFY THRESHOLD). And when they become too small (due to
* removal or resizing) they are converted back to plain bins. In
* usages with well-distributed user hashCodes, tree bins are
* rarely used. Ideally, under random hashCodes, the frequency of
* nodes in bins follows a Poisson distribution
* (http://en.wikipedia.org/wiki/Poisson distribution) with a
* parameter of about 0.5 on average for the default resizing
* threshold of 0.75, although with a large variance because of
* resizing granularity. Ignoring variance,the expected
* occurrences of list size k are (exp(-0.5) * pow(0.5,k) /
* factorial(k)). The first values are:
*
* 0: 0.60653066
* 1: 0.30236533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
* more: less than 1 in ten million
*/
翻译注释:
大概的翻译就是
TreeNode占用的内存是Node的两倍,只有在node数量达到8时才会使用它,而当node数量变小时(删除或者扩容),又会变回普通的Node。当hashCode遵循泊松分布时,因为哈希冲突造成桶的链表长度等于8的概率只有0.00000006 。官方认为这个概率足够的低,所以指定链表长度为 8 时转化为红黑树。所以 8 这个数是经过数学推理的,不是瞎写的。
✔️为什么长度为6的时候转回来?
但是,当红黑树节点数小于 6 时,又会把红黑树转换回链表,这个设计的主要原因是出于对于性能和空间的考虑。前面讲过为什么直接用红黑树,那同理,转成红黑树之后总要在适当的时机转回来,要不然无论是空间占用大,还是插入性能都会下降。
8的时候转成红黑树,那么如果小于8立刻转回去,那么就可能会导致频繁转换,所以要选一个小于8的值,但是又不能是7。而通过前面提到的泊松分布可以看到,当红黑树节点数小于 6 时,它所带来的优势其实就是已经没有那么大了,就不足以抵消由于红黑树维护节点所带来的额外开销,此时转换回链表能够节省空间和时间。
但是不管怎样,6 这个数值是通过大量实验得到的经验值,在绝大多数情况下取得比较好的效果。
✔️双向链表是怎么回事
HashMap 红黑树的数据结构中,不仅有常见的 parent , left , right 节点,还有一个next 和 prev 节点,这很明显的说明,其不仅是一个红黑树,还是一个双向链表,为什么是这样呢?
这个其实我们也在之前红黑树退化成链表的时候稍微提到过,红黑树会记录树化之前的链表结构,这样当红黑树退化成链表的时候,就可以直接按照链表重新链接的方式进行 (详细分析可以见前面扩容的文章)。
不过可能有人会问,那不是需要一个next节点就行了,为什么还要prev节点呢?
这是因为当删除红黑树中的某人节点的时候,这人节点可能就是原始链表的中间节点,如果把该节点删除,只有next属性是没办法将原始的链表重新链接的,所以就需要prev节点,找到上一个节点,重新成链。
✔️HashMap的元素没有比较能力,红黑树为什么可以比较?
这里红黑树使用了一个骚操作:
1 . 如果元素实现了comparable接口,则直接比较,否则
2 . 则使用默认的仲裁方法,该方法的源码如下
static int tieBreakOrder(Object a, Object b) {
int dd;
if (a == null || b == null ||
(dd = a.getClass( ).getName().
compareTo(b.getClass()getName())) == 0) {
dd = (System.identityHashCode(a) <= System.identityHashCode(b) ? -1 : 1);
}
return dd;
}






![漫谈大模型的[幻觉]问题](https://img-blog.csdnimg.cn/direct/2811493988cb432dbfd13fc9c0fb8f8f.png)


![[JavaWeb玩耍日记] 数据库](https://img-blog.csdnimg.cn/direct/6e7e1a288b2147639760530781dc090f.png)