DQL用于查找数据库中存放的记录~
目录
一.语法
二.基础查询
1.查询多个字段
2.设置别名
3.去除重复记录
三.条件查询
1.基础语法
2.常见条件
四.分组查询
1.聚合函数
2.语法
五.排序查询
六.分页查询
附注:DQL执行顺序
1.编写顺序
2.执行顺序
一.语法
- select:字段列表
- from:表名列表
- where:条件列表
- group by:分组字段列表
- having:分组后条件列表
- order by:排序字段列表
- limit:分页参数
二.基础查询
1.查询多个字段
select 字段1,字段2,...from 表名;当要查询全部的字段时,可以采用如下的操作:
select * from 表名;不过实际开发中不建议这样写,一方面效率不高,另一方面并不直观~
2.设置别名
意义在于赋予字段更加直接现实的意义~
select 字段名 as 别名 from 表名;
3.去除重复记录
select distinct 字段列表 from 表名;三.条件查询
1.基础语法
select 字段名 from 表名 where 条件列表;注意:条件可以有多个~
2.常见条件

in相当于一个并列多项的“or”:(满足其一即可)
select * from students where age in(21,23);如上,查询年龄为21岁或者23岁的存在~
like用于模糊匹配的场景:_表示一个任意字符,而%表示多个任意字符
- 如:任意两个字符组成的名字,即“--”
- 最后一位是h的字符串:“%h”——前面是什么、多少个都无所谓~
- null值时一定要注意是is null的运算公式
- 不等号<>是一个比较区别于主流语言的写法~
- between后面跟着最小值,and后面跟着最大值,顺序很重要(类比积分上下限,虽然没什么理论上的相似性)

四.分组查询
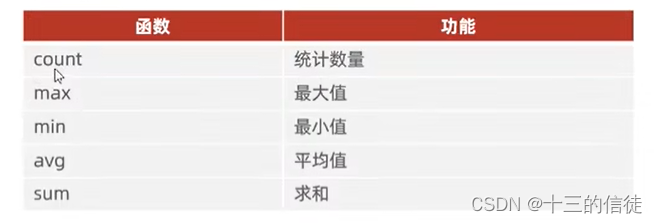
1.聚合函数
将一列数据作为一个整体,进行纵向的计算~(作用于某一列)
select 聚合函数(字段列表) from 表名;- (字段列表同样可以写*,不过不推荐~)
- null值不参与所有聚合函数的计算~
2.语法
所谓的分组,即将原有的数据先分为若干组,然后再执行一些有关查询的操作~
select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后的条件];- where的条件作用于分组前就已经过滤掉一部分,而having的条件则是分好组后再进行一次!
- where 后面可以使用聚合函数,而having后面则不行
- 执行顺序:where>聚合函数>having
- 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段毫无意义~
五.排序查询
即将查询到的数据按照某种方式排序出来~
select 字段列表 from 表名 order by 字段1 排序方式,字段2 排序方式;- 所谓的排序方式只有两种,asc表示升序,而desc表示降序
- 多字段排序的意义是,当前一个字段的值相同时,才根据第二个字段排序~
六.分页查询
select 字段列表 from 表名 limit 起始索引,查询记录数;- 起始索引是从0开始,起始索引=(查询页码-1)*每页显示的记录数量
- 分页查询是数据库的方言,不同的数据库有不同的实现,MySQL中是limit
- 如果查询的是第一页的数据——即索引从0开始,可以直接简写为limit 10~
附注:DQL执行顺序
1.编写顺序
select——from——where——group by——having——order by——limit
2.执行顺序
from——where——group by——having——select——order by——limit






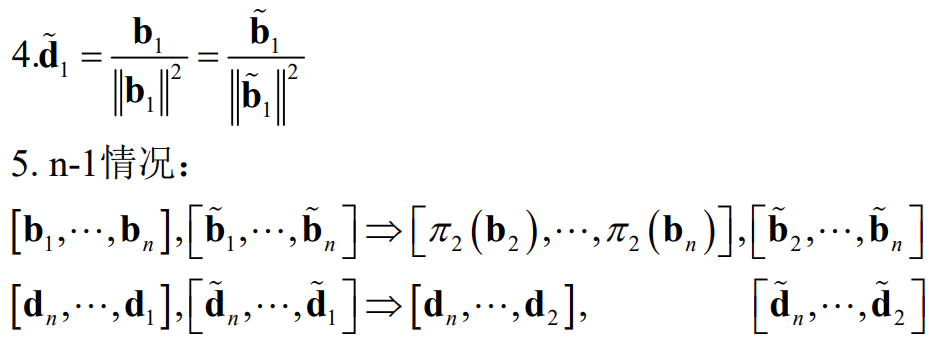


![[NSSRound#3 Team]This1sMysql](https://img-blog.csdnimg.cn/direct/2bb6b5bebe484ea4ae05473870405a13.png)
![[C#]利用opencvsharp实现深度学习caffe模型人脸检测](https://img-blog.csdnimg.cn/direct/9abd939faa5d437584fbbeff3a37e5e8.jpeg)