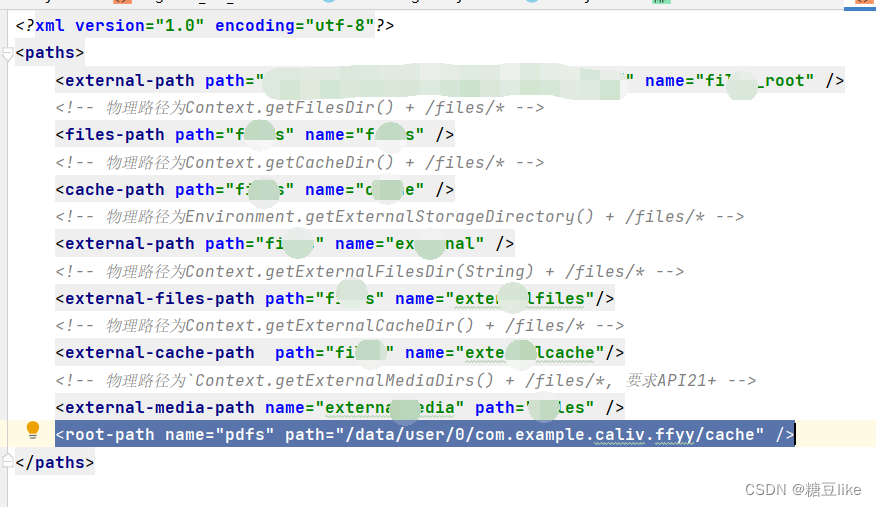
数据增强是通过对原始数据进行各种转换和修改来人工生成附加数据的过程,旨在增加机器学习模型中训练数据的大小和多样性。这对于计算机视觉领域尤为重要,因为图像经常被用作输入数据。
计算机视觉中的数据增强
数据增强的主要目标是解决过拟合问题,这在模型使用小样本量进行训练时尤为常见。过拟合导致模型难以泛化到新数据,处理实际任务时可能会出现困难。通过增加训练数据的多样性,数据增强有助于加强和调整模型,可以视为一种正则化技术。
常用的数据增强方法包括:
- 生成合成数据
- 旋转、调整大小或裁剪照片
- 添加噪点
这些转换可以随机或按预设顺序应用于原始数据,生成具有更大变化范围的数据集。
在计算机视觉中,模型通过应用各种图像转换(如旋转或翻转)来学习从不同角度检测物体,这增强了模型的鲁棒性并能够应对数据中的真实变化。
总结来说,数据增强是一种提高机器学习模型训练数据多样性的有效技术。它有助于防止过拟合,提升模型的泛化能力,使模型更能适应实际应用场景。
AI插图

GPT说: 这张插图展示了计算机视觉中数据增强的概念。图中描绘了一个中央电脑屏幕显示原始图像,周围是多个小屏幕展示了原始图像的各种变换,如旋转、调整大小、裁剪和添加噪点。这些变换说明了数据增强是如何增加机器学习训练数据集的多样性和大小的。整个场景呈现出未来感和数字化的特点,强调了计算机视觉和机器学习的高科技性质。


![[NSSRound#3 Team]This1sMysql](https://img-blog.csdnimg.cn/direct/2bb6b5bebe484ea4ae05473870405a13.png)
![[C#]利用opencvsharp实现深度学习caffe模型人脸检测](https://img-blog.csdnimg.cn/direct/9abd939faa5d437584fbbeff3a37e5e8.jpeg)