大家下午好,我叫刘广东,然后是来自Apache SeaTunnel社区的一名Committer。今天给大家分享的议题是下一代高性能分布式海量数据集成工具,后面的整个的PPT,主要是基于开发者的视角去看待Apache SeaTunnel。后续所有的讲解主要是可能会硬核偏技术一点,主要是Apache SeaTunnel流程当中的一些详细的设计。
议题简介
- 介绍Apache SeaTunnel工具
- Apache SeaTunnel的一些核心设计架构
- Apache SeaTunnel自研引擎Zeta简介
- Apache SeaTunnel Web功能
- 社区近期的规划
SeaTunnel介绍
首先介绍一下Apache SeaTunnel的设计和目标。Apache SeaTunnel作为下一代数据集成平台。同时也是数据集成一站式的解决方案,有下面这么几个特点。
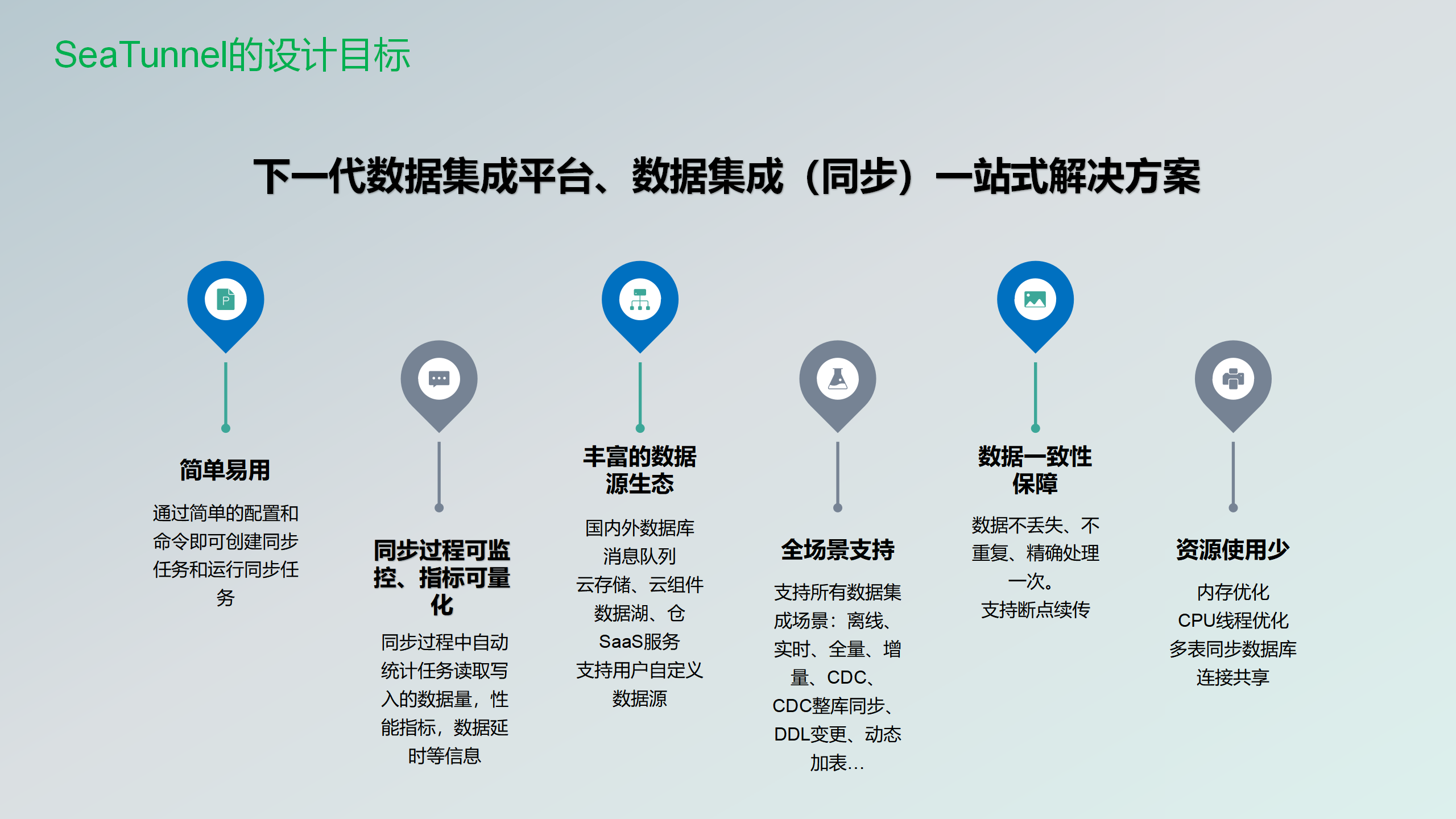
- 简单易用。如果用过的话都会知道它只需要通过一个配置文件就是config文件,通过执行一个shell脚本,就可以把一个任务给拉起来。使用的话是非常简单的
- 可监控/量化的。我们在这个任务带起来之后,同步过程当中会读取它的那个写入的数据,然后还有读取的数据,以及那个数据延迟的一些信息都会被收集起来,然后在下面就是任务结束的时候会统一的打印出来。
- 丰富的数据生态。现在已经接入了100多个数据源,包括Source、Sink有100多个了,然后包括国内外的一些数据库、消息队列以及云存储和一些数据湖的组件。包括的一些数仓saas服务都有。
- 全场景的支持,包括数据集成的一些离线的,实时的,全量的增量的,CDC的,以及CDC的一些整库同步,然后DDL变更、动态加表,这些特性已经都支持了。数据一致性的保障,它可以保障数据不丢失,不重复。精确处理一次,包括支持断点续传。
- 资源耗损低就是内存这块儿的优化,包括CPU的优化,多表同步的一些设计,以及JDBC的资源共享。
SeaTunnel的前世今生
下面介绍一下发展历史,Apache SeaTunnel进入孵化器之前,前身叫Waterdrop,然后在2017年开源了。在2021年12月份的时候进入进行Apache孵化器进行孵化。在2022年的3月份发布了首个Apache版本,然后在10月份的时候就支持了跨引擎和连接器分离的设计,之后就是就有大量的连接器被接入进来,那时候有七八十个,在2022年的10月份的时候接进来了。
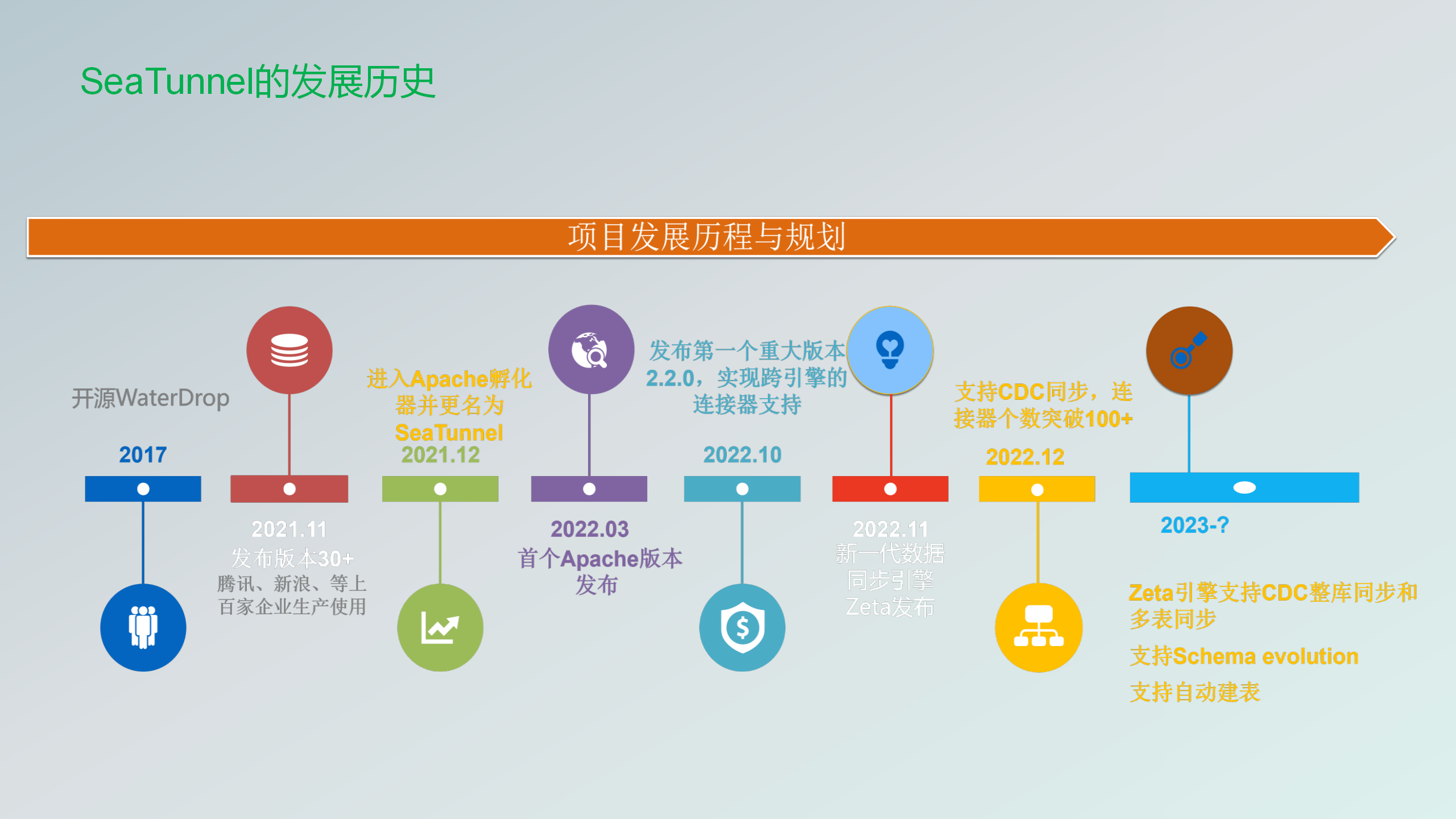
在10月份的时候,社区讨论说需要有一个专门为数据同步设计的一个引擎,那时候还是基于Flink Spark之上去做了一个数据同步。
其实Apache Flink和Spark主要还是做计算用的,所以为了去节省资源更加简单,然后去设计了一个叫Zeta引擎。
在12月份的时候,连接器就达到了100多个,包括也支持了cdc的一些连接器。
现在Zeta引擎已经支持了cdc和多表的同步,然后就是schema evolution的支持。包括后面的自动建表已经提出了方案,目前的话也在开发中了。
整体架构
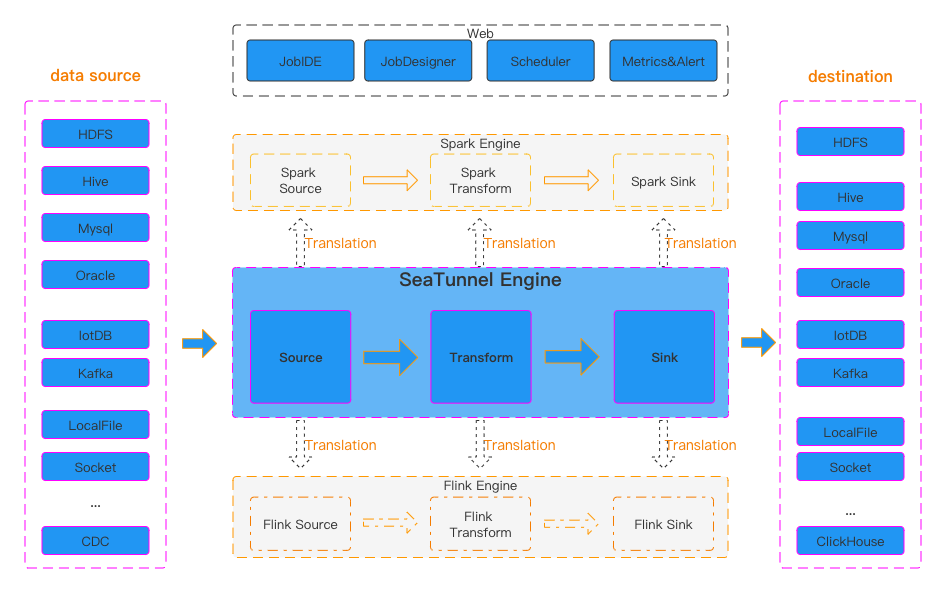
整体架构就是这张图,是从官网拉下来的。可以分为四部分来去看,Apache SeaTunnel大家都知道它是做数据同步用的,所以一般的话都会有一个source数据源以及一个Sink数据源,这个分别在左右两边,然后上面是最近那个社区发布的Web。这个Web也是最近刚刚发布它里面支持的一些功能,就是可以让用户可以更加简单的把数据同步任务给建立起来。中间的很大一部分,这块叫core部分,主要是引擎部分。现在主要是那个三种引擎吧,一个是spark engine,然后还有一个是Flink engine,自研的Zeta engine,然后里边的主要还是三部分内容就是Source、Transform、Sink,然后这是大概的一个整体的架构。
引擎解耦设计
然后就讲一下第一个社区重大贡献的引擎解耦设计。因为因为它才让社区发展的非常迅速,包括连接器的接入变得非常简单。与引擎解耦专为数据集成场景设计。

连接器适配繁杂第一个就是以前在这个特性之前。想接入一个connector是非常麻烦的,就如果你要适配的话Flink,他们要接入的适配Flink的一个的特性,然后还要接Spark的话,可能还要再改一下代码,让它适配Spark是非常复杂的。可能这个引擎可能这个connect可能只支持Flink,或者说只支持Spark。后期维护也是非常困难的。自从引擎解耦进来了之后,connector只需要实现一次了。
支持多版本的Flink/Spark就我如果在特性设计实现之前,比如说你想支持1.14版本?可能你就要丢弃1.13版本,是它没法去让每个版本都支持。
支持流批一体就只要通过简单的特性,就是你在配置任务的时候,只要配上你的任务无论是batch,还是streaming任务就直接就可以无缝的两边迁移。
JDBC的复用包括连接池的复用、数据库的日志多表解析等等。就是实时多表或者整库同步解决JDBC连接过多的问题,以及多表或整库数据库日志读取解析,以及解决CDC多表场景下的一些重复的解析的问题。这也是在设计当中得到了支持。这也是设计的动机!
SeaTunnel 核心设计及架构
下面这张图就是整体的一个流程。从这张图里面看,也可以看到它是四部分组成,一个是Source的部分,一个是Sink的部分。下面的engine以及上面的config或者是web。
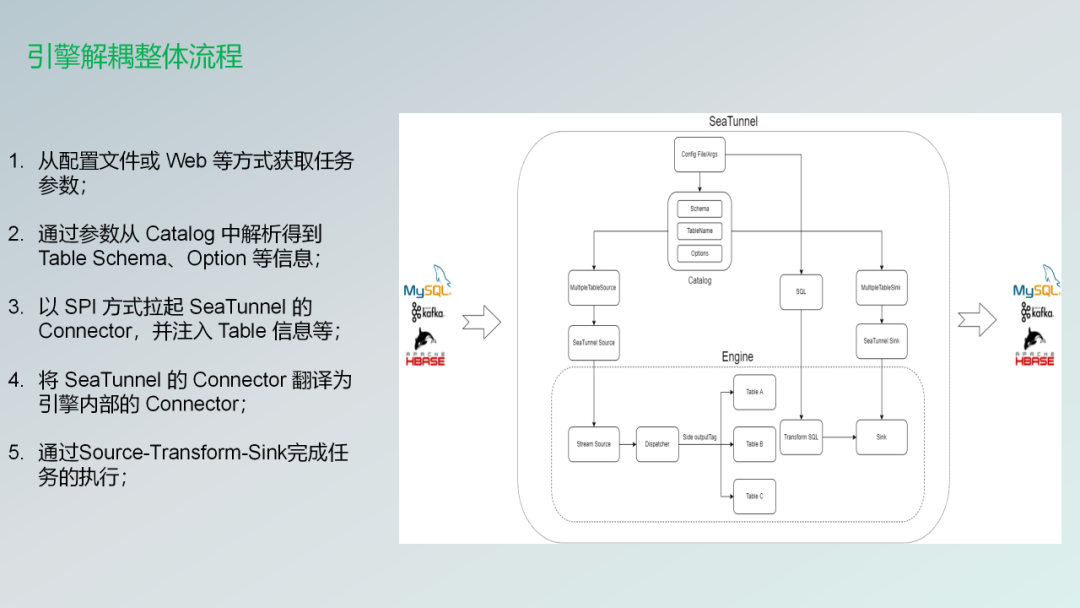
它整体的流程,第一步比较好理解,可以在配置任务的时候,在web功能出来之前是通过一个配置文件。
- 第一步就是把这个配置文件读取到我们的那个项目里边。
- 第二步读取到我们的工程里面之后被catalog解析会得到Table、Schema、Option 等信息。
- 第三步就是我们基于SPI的方式通过让SeaTunnel拉起connector。把这些table的信息注入到connector里边。让connector可以得到需要拉取的信息。
- 第四步就是将SeaTunnel的connector翻译为各种引擎的内部的connector,比如说Flink connector,可能就会经过一个translation,然后把它翻译出来。
- 第五步就是通过Source-Transform-Sink,然后完成一个任务的执行。之前的架构是非常复杂的,我就没贴进来了,就现在的架构是变得非常的清晰。也变得非常的简单。
下面的话就是更加详细的解析。进入到我们的source里面就是有一个组件就是叫sourceCoordinator。
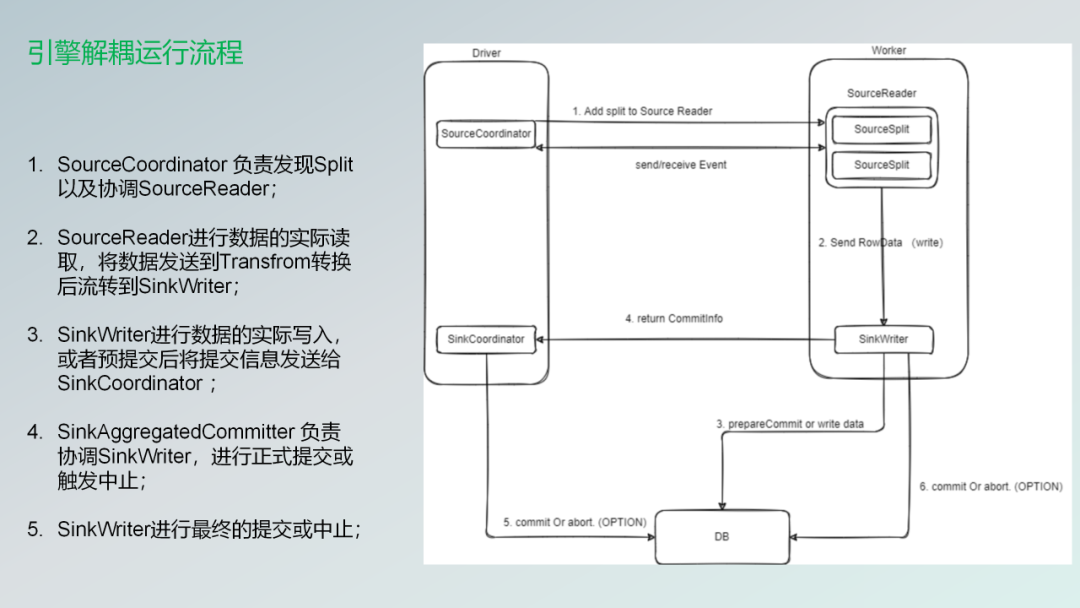
- 第一个是协调器,然后专门的去拆任务的就是类似于source一个完整的一张表,可能通过你配置的并行度,然后会切成很多的分片。
- 第二个就是这些分片会被分发到不同的Reader上面去,因为我们是并行的话可能就会有很多的Reader。Reader拿到这个Split之后,然后读取数据之后,经过Transform转换成 Sink Writer下游那边去。
- 第三步就是进行数据的实际的写入到我们的那边去,或者说如果你是配置了exactly-once语义的话。可能他的信息就会被SinkAggregatedCommitter这个组件去接收到,下一次会统一的去写入进去。
- 第四步SinkAggregatedCommitter负责协调SinkWriter,进行正式提交或触发中止.
- 第五步是Sinkwriter,然后把这些数据最终的写入,如果失败的话可能就会终止掉。大概这么一个流程。
CDC的设计
接下来介绍一下CDC的一个设计,就是为什么会设计?
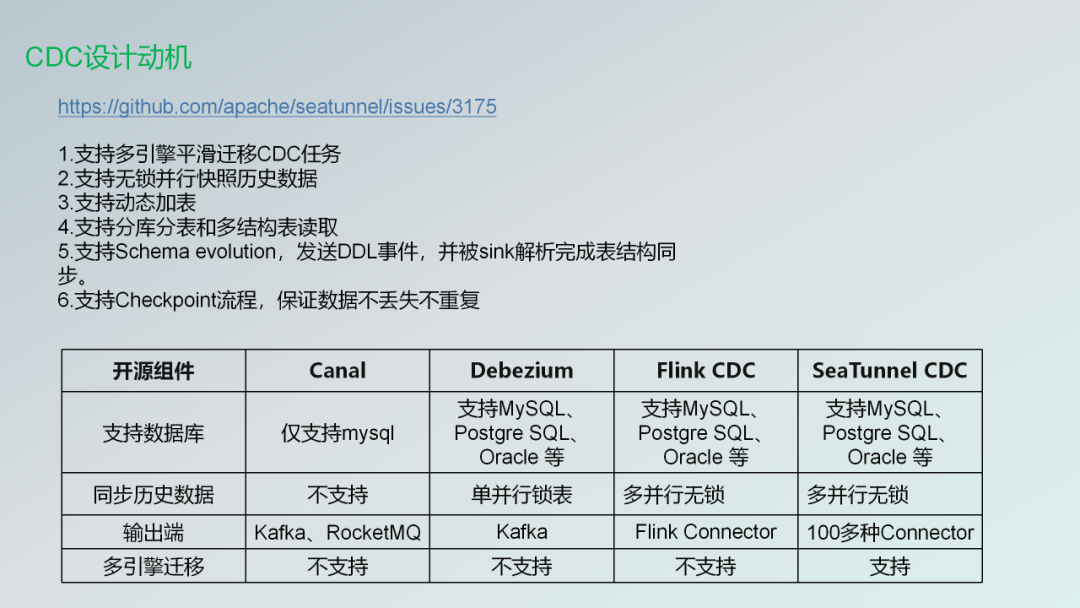
因为市面上像FlinCDC、Debezium、Canal等CDC组件也有一些比较好的,或者说已经有这些组件了,为什么还要设计SeaTunnel自己的CDC组件?有几个设计的动机
- 支持多引擎平滑迁移CDC任务
- 支持无锁并行快照历史数据
- 支持动态加表
- 支持分库分表和多结构表读取
- 支持Schema evolution,发送DDL事件,并被sink解析完成表结构同步。
- 支持Checkpoint流程,保证数据不丢失不重复
- 更加简单,你想介入到里边来的话可能。只需要改个命令。就可以把你的CDC让我接过来。
快照数据读取完之后,然后再解锁之后再去进行下面的流式的数据的读取。
CDC基础流程包含:
- 快照阶段:用于读取表的历史数据
- 最小Split粒度: 表的主键范围数据
- 增量阶段:用于读取表的增量日志更改数据
- 最小Split粒度: 以表为单位
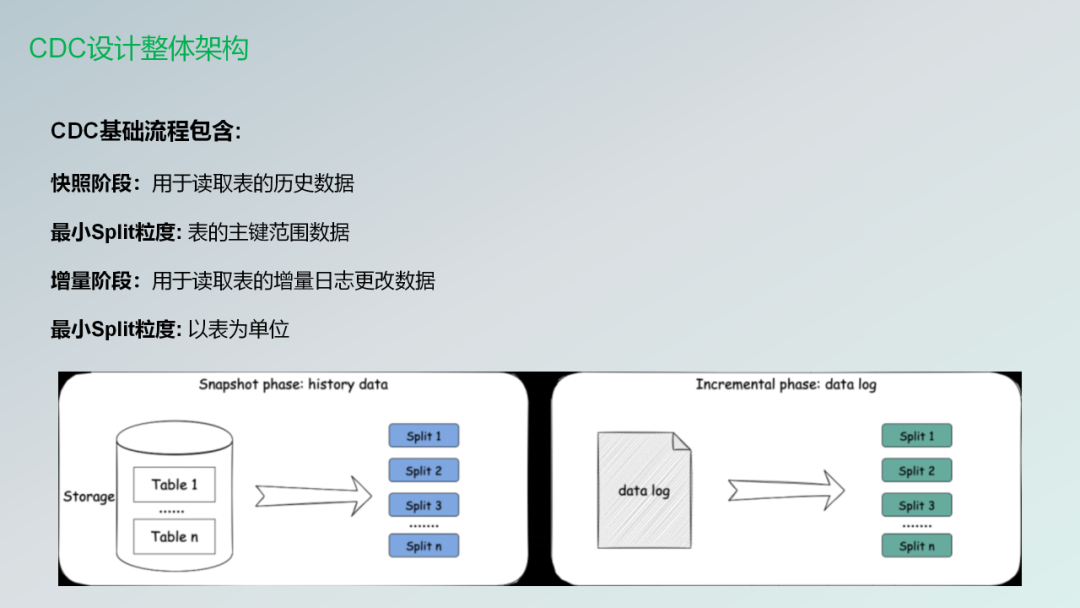
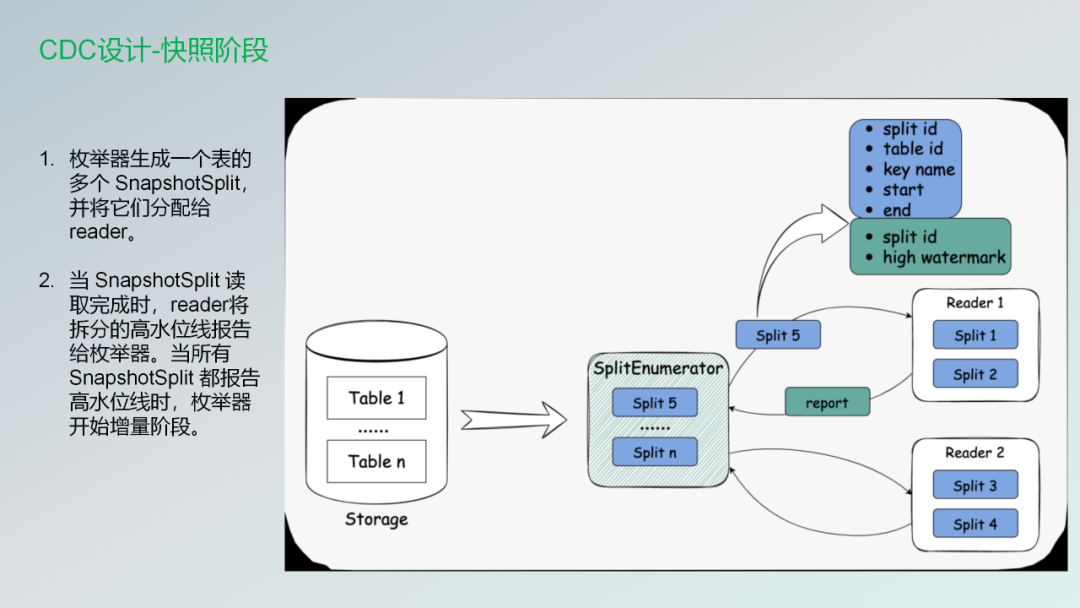
上面这张图就是两个阶段需要做的事情。
枚举器Snapshotsplint把它们发送给不同的reader。第二个阶段就是Split读取完成的时候Reader会将拆分的高水位线报告给枚举器。通知枚举器之后,让枚举器进行下一个增量的阶段。
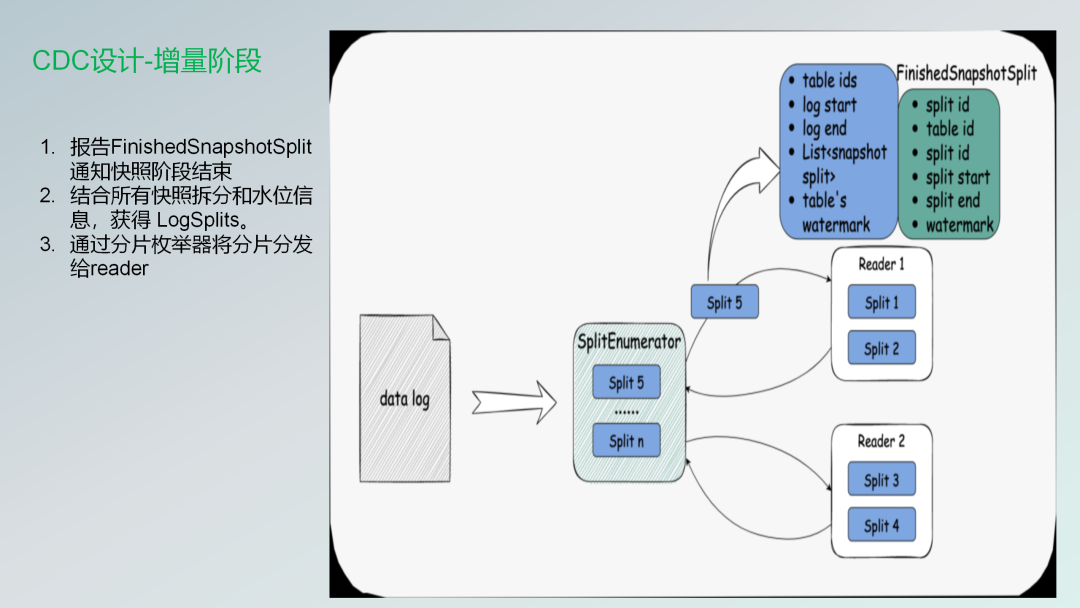
CDC的增量阶段
当那个枚举器收到Snapshotsplint会通知快照阶段结束,然后下面的话就是就会根据那个就是Binlog或者说一些日志的水位线获取。
进枚举会对它进行一个分发,然后分发给不同的Reader。
Zeta引擎
SeaTunnel的自研引擎Zeta,这个也是我比较感兴趣的,当时进入社区的时候也对这块比较感兴趣,分享一下。

Zeta Engine 是一个专门为数据同步场景设计和开发的数据同步引擎,更快、更稳定、更省资源也更加易用。
其特性包括:
- 简单易用:不依赖hadoop组件,部署非常简单
- 集群自治(无中心化):实现了集群的自治,自动选择master实现高可用
- 更省资源:使用了动态线程分享以及尽量复用jdbc链接资源,极大的减少资源浪费
- 更稳定:以Pipeline做为Checkpoint和容错的最小粒度,pipeline级别的失败不会导致整个任务失败。
- 更快速:使用专属的执行计划优化器来减小数据可能的网络传输,从而降低数据序列化和反序列化带来的整体同步性能的损耗,更快地完成数据同步操作。
- 全场景数据同步支持:支持流批一体任务以及CDC任务
简单易用。它是不依赖于Hadoop组件,你不需要去部署HDFS,为了存储它的一些中间过程的数据,也不需要依赖zookeeper保证它的高可用。你只需要部署一个Zeta引擎的Server和Client就可以部署起来了。
集群是自治的无中心化,就保证它的高可用。Master是自我选举的!
更省资源。因为它用了动态线程的分享,以及尽量的复用JDBC的一些链接资源,极大的减少了资源的浪费。
更稳定了,任务就task里面还切分了很多的pipeline就是比如说你一个任务里边。一个表可能就是一个pipeline,那么你一个任务的里面的一个pipeline如果失败了,那并不会导致整个任务的失败,其他的那些表可能还会继续工作。
更加快速,就是使用了专属的一个执行计划的一个优化器来减少数据可能的一个网络传输,从而降低了一个数据的序列化和反序列化带来了整体的同步性能的损耗,更快的去完成同步操作,因为SeaTunnel在引擎接入的时候,加入了一个translation翻译层,就是Flink Spark都需要做一层转换。把数据源里面的数据转换成Flink、Spark数据源的数据才能同步到下游,而且下游还要去做一次转换,所以这块是浪费资源的,这块的话也是非常大的一个变动。
全场景的数据同步,它支持流批一体以及CDC的一些任务。下面的话就是这张图就是Zeta一个总体的架构设计。
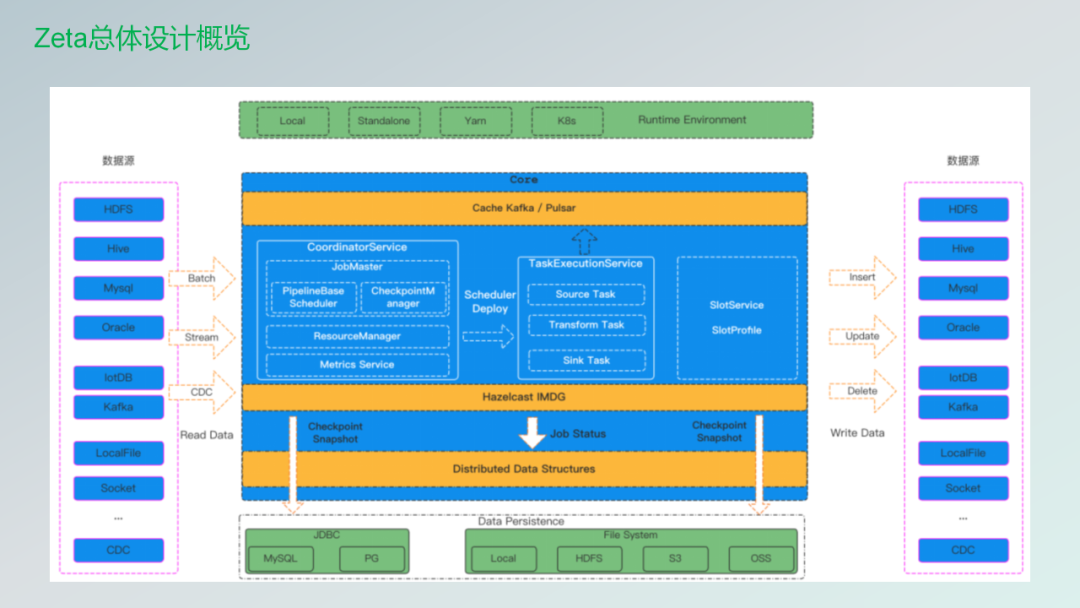
这张图就是也是从社区的官网拿过来的。主要的话也是可以分为五部分,就是数据源那块儿的话就不用讲了,就是那些connector。然后上游的话最上面绿色的这块是运行的那些资源。一个任务需要从一个地方去拿到资源,现在我们已经支持了Standlone,未来的话Yarn会支持的话checkpoint存储,如果有了解Zeta的朋友的话,就知道它是基于hazelcast做的,它是自己就是有一套专门的让数据可以在集群里边传输,可以保证那个数据在每个地方都可以拿到,也支持高可用,目前来讲已经支持了,就是HDFS、S3、OSS上面的一个数据的保存,未来的话也是会支持JDBC的一些数据保存,比如说可以把那些checkpoint存储的数据去保存在我们的MySQL,或者说PG上面。
然后中间的话这块是我后续会再去分享的。主要是CoordinatorService、TaskExecutionService、SlotService这么三部分.一个任务以及运行的整体流程都会在这里面去做。我后面有几页ppt就专门基于去讲。第一个核心的组件就是Zeta的核心组件,它是那个CoordinatorService,如果知道Zeta,其实它就是一个CS架构,就是客户端,然后把数据配置好的Config文件,然后处理完了之后,然后丢到我们的Service里边?Service去基于我们那些Worker节点上面的那些资源,然后把这些任务通过DAG,然后把它拆成一些算子,然后把这些算子会丢到不同的那个Worker上面去,然后去调度执行。

第一个核心的组件CoordinatorService 是集群的 Master 服务,提供了每个作业从 LogicalDag 到 ExecutionDag,再到 PhysicalDag 的生成流程,并最终创建作业的 JobMaster 进行作业的调度执行和状态监控
它包含了以下四部分内容。
- JobMaster,负责单个作业的 LogicalDag 到 ExecutionDag,再到 PhysicalDag 的生成流程,并由 PipelineBaseScheduler 进行调度运行。
- CheckpointCoordinator,负责作业的 Checkpoint 流程控制。
- ResourceManager,负责作业资源的申请和管理,目前支持 Standalone 模式,未来会支持 On Yarn 和 On K8s。
- Metrics Service,负责作业监控信息的统计和汇总。
下面一个核心的组件就是TaskExecutionService 是集群的 Worker 服务,提供了作业中每个 Task 的真正运行时环境,TaskExecutionService 使用了 Dynamic Thread Sharing 技术降低 CPU 使用。
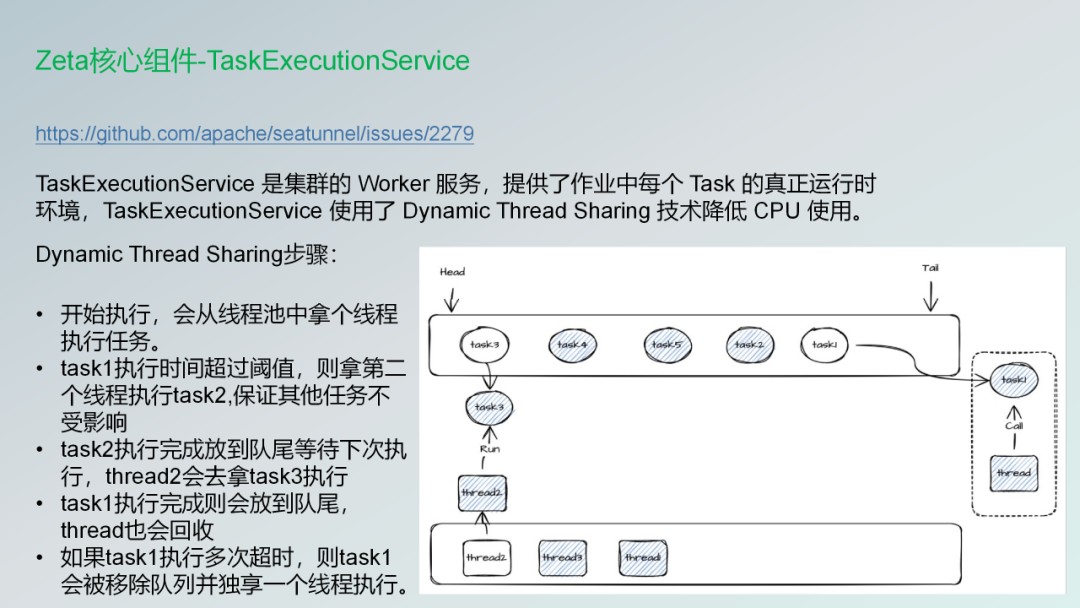
什么意思呢?就是我们不需要每一个任务过来的时候都要独占一个独占线程,然后让它运行完了才结束。
有些任务如果是那种大表的话,人家小表的话,就是通过这个线程就可以结束了。如果那些大表的话,会可能会把这个资源给独占了,就是我们可能会运行到最后,所有的那些任务都由那些比较大的表给独占了,然后那些小表可能就没有得到资源去运行。
所以通过这种技术,我们就可以让资源比较大的就是耗时比较长的那些任务会独占一个线程,让他去跑在另外一个地方去跑。而其他的那些小表的话,可以在这个线程里面去共享所有的资源。保证我们每一个任务都可以得到cpu的运行时间。
第三个组件的话是资源申请的一个组件。SlotService 在集群每个节点上都会运行,主要负责节点上资源的划分、申请和回收。
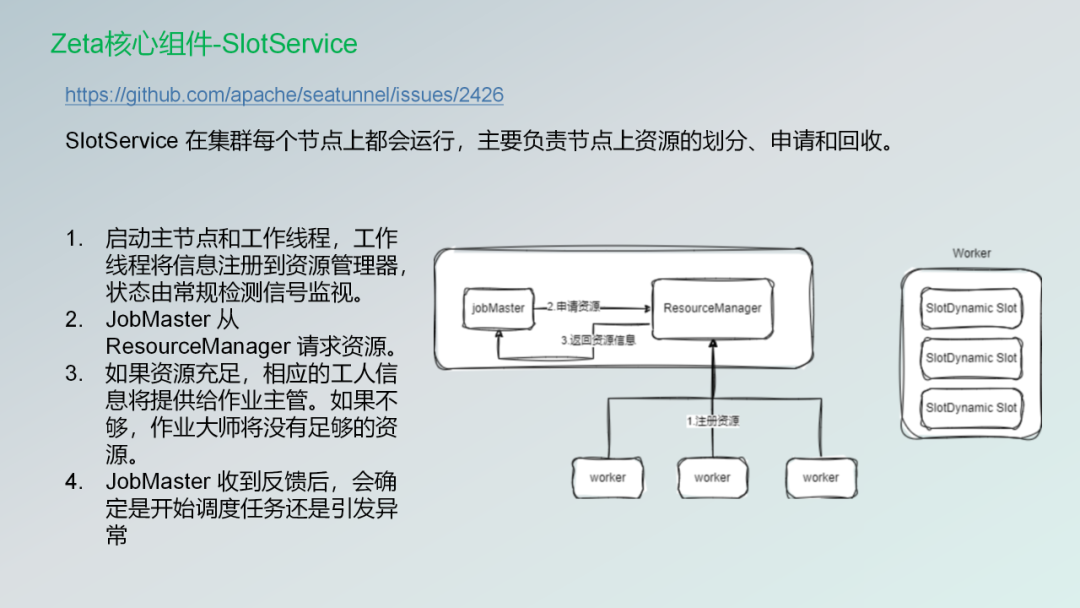
它主要的工作内容如下: 1.启动主节点和工作线程,工作线程将信息注册到资源管理器,状态由常规检测信号监视。 2.JobMaster 从 ResourceManager 请求资源。 3.如果资源充足,相应的工人信息将提供给作业主管。如果不够,jobmaster将没有足够的资源。 4.JobMaster 收到反馈后,会确定是开始调度任务还是引发异常 然后再把这些我们使用的门槛,以及对于运维人员来说,我们也提供了一些比较好的监控的一些平台。
Web功能发布
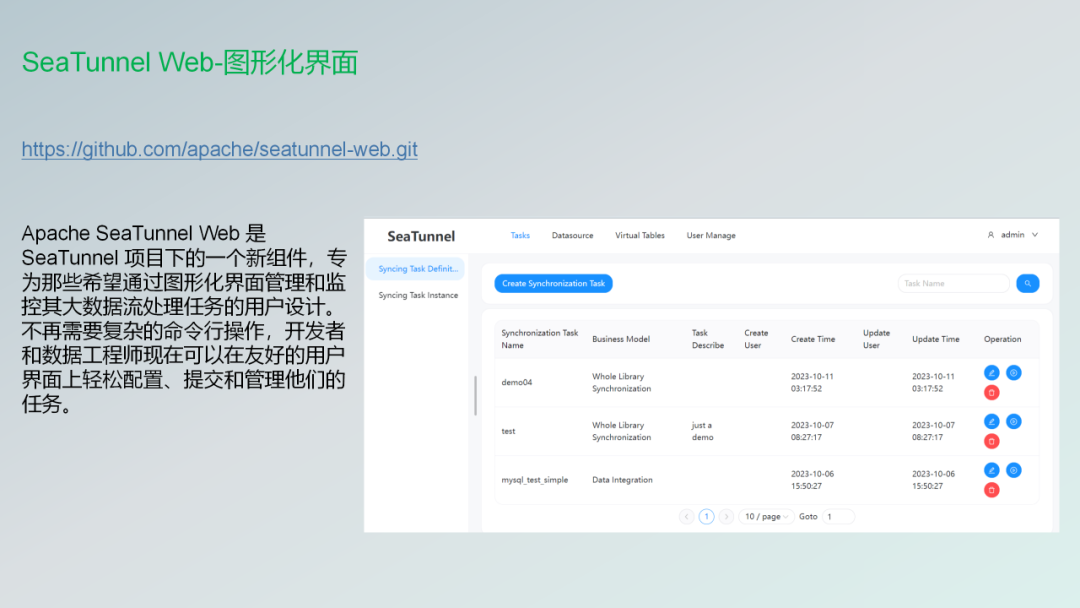
这个大概就是我截了一张图就是SeaTunnel的Web页面 目前来往来讲的话,因为刚刚发布也是最近投票刚刚发布的第一个版本,还是页面上面看起来还是有点少的,所以如果有感兴趣的朋友的话,后期也可以一起加入进来共建这个社区。
近期规划
第五部分的话,如果有感兴趣的开发者的话,如果近期想参与Apache的开源社区,或者说像没有了解过开源文化的朋友。也想参与开源的,甚至不知道如何提交代码的?欢迎来社区跟我交流!
我会先分享一下目前这个SeaTunnel社区有几个正在做的一个比较大的特性,然后特性最近也在包括设计已经完成了,现在正在疯狂的提交代码。第一个就是我们可以在Sink里面一个这任务当中可以支持多表了,然后这个我在下面贴了 conference的一个链接 如果有感兴趣的朋友的话,也可以了解一下,然后这里边已经有应该拆了很多任务,对这些任务,我们都门槛都是比较低的。

如果有感兴趣的朋友可以一起来开发,或者去关注"good frist issue"一起开发起来。
第二个就是我们也是马上也要支持多表了。我们在一个任务里面可以配置到多表的同步了。

我参与开源的经历
我最后还是想再去分享一下自己的经历!也简单聊一下就是怎么样的去参与开源社区。我之前在公司当中,就调研过一款数据同步的产品,当时还不是调研的SeaTunnel。而是调研了另一款产品,现在已经叫那个FlinkX,现在已经给人叫chunjun。当时这款产品也是做专门做数据集成平台的。调研之后发现了一些不足,社区也不是很活跃。有一些功能,它也不支持了。
机缘巧合下,我接触到了Apache SeaTunnel社区,并见证了社区成员对代码贡献的热情和持续的激烈讨论,我的第一个PR还是非常简单的,可能就是文档的一个说明改动,然后提交了一个PR,就出现了什么代码格式的问题,然后就导致这个PR隔了好久才合并进去。
然后自从那一次,然后我就感觉很有兴趣,包括你可以在社区里面去展现自己的一些个人的想法,然后社区的功能设计你也可以参与进去,也可以把你的代码贡献给社区。
如果你也想第一次提交代码的话,可以去在那个GitHub里面去搜一下good frist issue,然后可以找到非常简单的可能像文档优化或者说一些小的改动。就可以把PR提交上去,然后会得到社区的反馈,流程还是比较简单的,也是希望那个大家都能参与进来,我今天的分享就到这,感谢大家的聆听!
本文由 白鲸开源科技 提供发布支持!




![[NISACTF 2022]bingdundun~](https://img-blog.csdnimg.cn/direct/5e4f68799f9247a2b474577cf366b188.png#pic_center)