一、背景
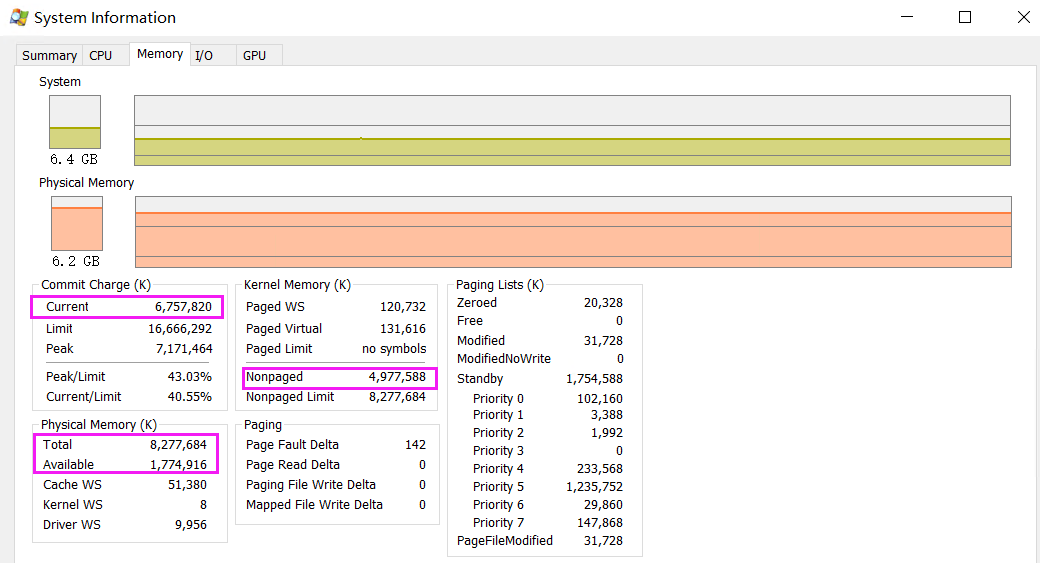
Hive中的数据需要同步到pg供在线使用,通常sqoop具有数据同步的功能,但是sqoop具有一定的问题,比如对数据的切分碰到数据字段存在异常的情况下,数据字段的空值率高、数据字段重复太多,影响sqoop的分区策略,特别是hash分区,调用hash函数容易使得cpu高产生报警。同时sqoop的mapreduce任务对数据表的分割以及数据文件也会有一定的不均衡性。为了弥补这些问题,开发了基于spark的数据同步组件,利用spark处理大数据的强大能力及分布式并行性上的优势,通过执行sparksql将数据写入到pg数据库,但是在sparksql 中,保存数据到数据,只有 Append , Overwrite , ErrorIfExists, Ignore 四种模式,不满足特殊场景的需求,尝试利用spark save 源码改进, 批量保存数据,存在则更新不存在则插入。
二、关键设计方案
- 方案一
利用DataFrame框架里自带的df.write.mode(“append”).jdbc(url,pg_table,prop)方法,尝试将df里的每一行row是org.apache.spark.sql.Row类型,结合schema类型转换成DataFrame,方法如下:
import org.apache.spark.sql.types._
val map = Map("col1" -> 5, "col2" -> 6, "col3" -> 10)
val (keys, values) = map.toList.sortBy(_._1).unzip
val rows = spark.sparkContext.parallelize(Seq(Row(values: _*)))
val schema = StructType(keys.map(
k => StructField(k, IntegerType, nullable = false)))
val df = spark.createDataFrame(rows, schema)
df.show()
经过分析:转DataFrame的过程有重要的两步:首先是通过spark.sparkContext.parallelize将Row类型转成RDD,其次获取schema后利用spark.createDataFrame把RDD和schema变为DataFrame。然而为了取到DataFrame的每一行Row,需要调用DataFrame的foreach方法。
Spark的DataFrame的foreach的执行原理:
Spark DataFrame 的 foreach() 方法将 DataFrame 的每一行作为 Row 对象进行循环,并将给定函数应用于该行。foreach() 的一些限制:Spark中的foreach()方法是在工作节点而不是Driver程序中调用的。这意味着,如果我们在函数内执行print()操作,将无法在会话或笔记本中看到打印结果,因为结果打印在工作节点中。行是只读的,因此您无法更新行的值。鉴于这些限制,foreach() 方法主要用于将每行的一些信息记录到本地计算机或外部数据库foreach方法无法改变原始的DataFrame数据,仅用于迭代处理每个分区的数据。
foreach方法的处理是并行的,可以提高处理效率,但需要注意处理的顺序可能不同于原始数据的顺序。常规性能调优四:广播大变量默认情况下,task 中的算子中如果使用了外部的变量,每个 task 都会获取一份变量的复 本,这就造成了内存的极大消耗。一方面,如果后续对 RDD 进行持久化,可能就无法将 RDD 数据存入内存,只能写入磁盘,磁盘 IO 将会严重消耗性能;另一方面,task 在创建对象的 时候,也许会发现堆内存无法存放新创建的对象,这就会导致频繁的 GC,GC 会导致工作 线程停止,进而导致 Spark 暂停工作一段时间,严重影响 Spark 性能。假设当前任务配置了 20 个 Executor,指定 500 个 task,有一个 20M 的变量被所有 task 共用,此时会在 500 个 task 中产生 500 个副本,耗费集群 10G 的内存,如果使用了广播变 量, 那么每个 Executor 保存一个副本,一共消耗 400M 内存,内存消耗减少了 5 倍。广播变量在每个 Executor 保存一个副本,此Executor 的所有 task 共用此广播变量,这让变 量产生的副本数量大大减少。在初始阶段,广播变量只在 Driver 中有一份副本。task 在运行的时候,想要使用广播变 量中的数据,此时首先会在自己本地的 Executor 对应的 BlockManager 中尝试获取变量,如 果本地没有,BlockManager 就会从 Driver 或者其他节点的 BlockManager 上远程拉取变量的 复本,并由本地的 BlockManager 进行管理;之后此 Executor 的所有 task 都会直接从本地的 BlockManager 中获取变量。
一般spark.SparkContext是存在Driver进程里的,工作节点获取不到,每个jvm只能有一个SparkContext,再创建新的SparkContext之前需要先stop()当前活动的SparkContext。
综上分析,方案一不能实现,即DataFrame里不能创建DataFrame
2、方案二
利用PrepareStatement执行插入更新的sql语句,将DataFrame里的每一行Row的字段数值解析出来封装成sql,每batch个执行一次并提交,碰到有重复的key执行update操作,新的数据执行insert操作。该方案的实现过程借鉴了spark的dataframe的save方法。tableSchema.fields.map(x => x.name).mkString(",")利用map和mkString方法进行字符串操作,同时利用spark的makeSetter方法实现PrepareStatement语句的填充。
三、碰到问题及解决
采用方案二在开发的过程碰到的问题:
- Spark error: value foreach is not a member of Object
当调用这样调用的时候:

升级2.12之后,DataFrame的foreachPartition 里面不能处理 Row的Iterator;
解决方法:(1)

(2)就是使用foreach替代foreachPartition
2、Caused by: java.io.NotSerializableException: org.postgreslq.jdbc.PgPrepareStatement

原因: prep是一个PrepareStatement对象,这个对象无法序列化,在标1的地方执行,而传入map中的对象是需要分布式传送到各个节点上,传送前先序列化,到达相应机器上后再反序列化,PrepareStatement是个Java类,如果一个java类想(反)序列化,必须实现Serialize接口,PrepareStatement并没有实现这个接口,对象prep在driver端,collect后的数据也在driver端,就不需prep序列化传到各个节点了。但这样其实会有collect的性能问题。
解决方案:使用mappartition在每一个分区内维持一个pgsql连接进行插入

3、在insert on conflict的语句上报Postgre SQL ERROR:there is no unique or exclusion constraint matching the ON CONFLICT specification。
执行insert into test values('a','b') on conflict(a,b) do update set c='1';由于建表时没有建关于a,b的CONSTRAINT,于是就会报错,为表添加CONSTRAINT
4、java jar 后面传参数,参数中含有空格的处理方法。将含有空格的参数加上双引号。
四、总结
该组件实现了对于数据规整规范的情况下,直接调用DataFrame的write.mode()方法批量写入,对于特殊的情况hive表里对于pg表的主键字段有重复的情况,进行了重新的封装,通过执行s"INSERT INTO $table ($columns) VALUES ($placeholders) on conflict($id) do update set name1=? ,name2=?"



![[NISACTF 2022]bingdundun~](https://img-blog.csdnimg.cn/direct/5e4f68799f9247a2b474577cf366b188.png#pic_center)