目录
一、基本数据类型总结
二、基本数据类型
Number(数字)
String(字符串)
Bool(布尔类型)
List(列表)
Tuple(元组)
Set(集合)
Dictionary(字典)
Bytes(字节数组类型)
三、列表的增删改查
a.增加列表元素的方法
b.删除列表元素的方法
c.修改列表元素的方法
d.查询列表元素的方法
e.列表的其他方法
f.列表的嵌套
四、字典的增删改查
a.创建字典元素的方法
b.删除字典元素的方法
c.修改字典元素的方法
d.查询字典元素的方法
e.字典排序
一、基本数据类型总结
python3中常见的数据类型有:
- Number(数字)
- String(字符串)
- bool(布尔类型)
- List(列表)
- Tuple(元组)
- Set(集合)
- Dictionary(字典)
Python3 的六个标准数据类型中:
- 不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组)
- 可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)
二、基本数据类型
Number(数字)
Python3 支持 int、float、bool、complex(复数)
String(字符串)
Python中的字符串用单引号 ' 或双引号 " 括起来,同时使用反斜杠 \ 转义特殊字符。
字符串的截取的语法格式如下:
变量[头下标:尾下标]
索引值以 0 为开始值,-1 为从末尾的开始位置。
加号 + 是字符串的连接符, 星号 * 表示复制当前字符串,与之结合的数字为复制的次数。
Bool(布尔类型)
布尔类型即 True 或 False。
在 Python 中,True 和 False 都是关键字,表示布尔值。
List(列表)
List(列表)是写在方括号 [] 之间、用逗号分隔开的元素列表。
列表可以被索引和截取,列表被截取后返回一个包含所需元素的新列表。
列表截取的语法格式如下:
变量[头下标:尾下标]
索引值以 0 为开始值,-1 为从末尾的开始位置。
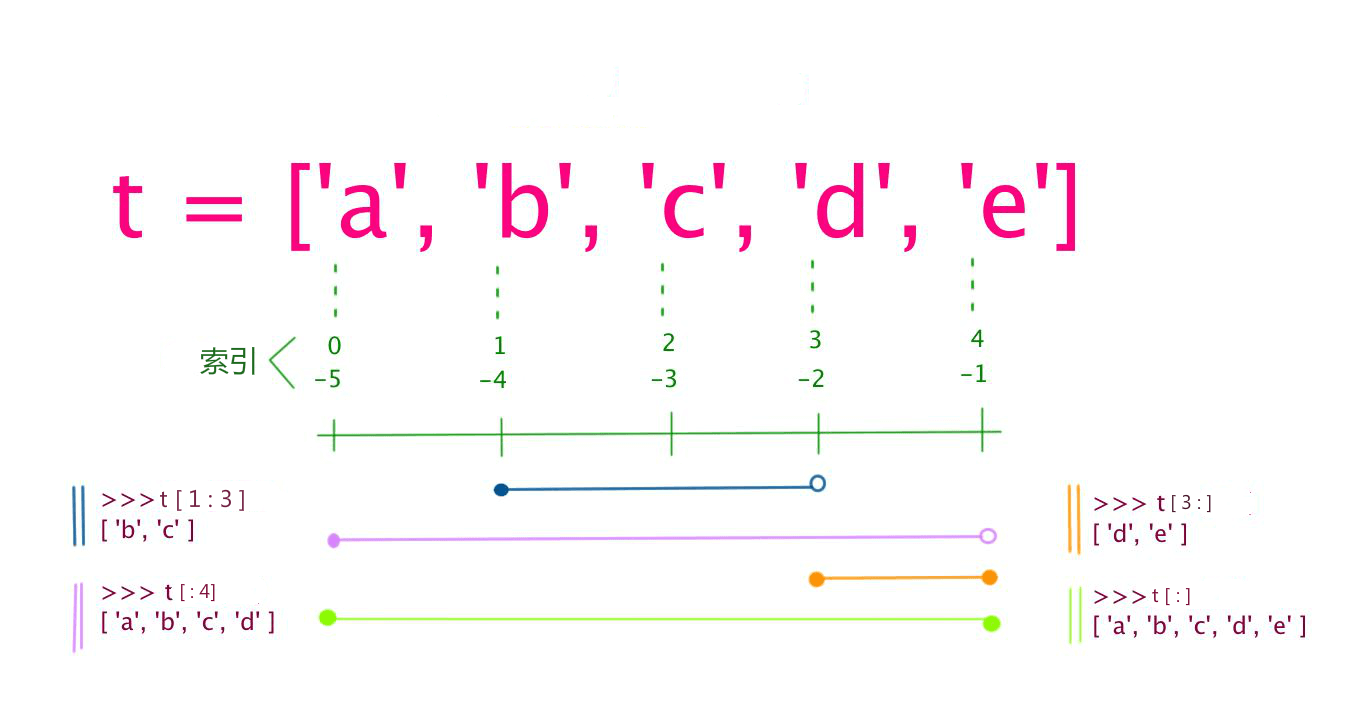
加号 + 是列表连接运算符,星号 * 是重复操作。
注意:
- List写在方括号之间,元素用逗号隔开。
- List可以被索引和切片。
- List可以使用+操作符进行拼接。
- List中的元素是可以改变的。
Tuple(元组)
元组(tuple)的元素不能修改。元组写在小括号 () 里,元素之间用逗号隔开。
元组可以被索引且下标索引从0开始,-1 为从末尾开始的位置。也可以进行截取。
注意:
- 元组的元素不能修改。
- 元组可以被索引和切片。
- 注意构造包含 0 或 1 个元素的元组的特殊语法规则。
- 元组也可以使用+操作符进行拼接。
Set(集合)
集合(Set)是一种无序、可变的数据类型,用于存储唯一的元素。
集合中的元素不会重复,并且可以进行交集、并集、差集等常见的集合操作。
集合使用大括号 {} 表示,元素之间用逗号 , 分隔。
另外,也可以使用 set() 函数创建集合。
集合创建格式:
parame = {value01,value02,...} 或者 set(value)
注意:
- 创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
Dictionary(字典)
字典(dictionary)是无序的对象集合。
字典当中的元素是通过键来存取的,而不是通过偏移存取。
字典是一种映射类型,字典用 { } 标识,它是一个无序的 键(key) : 值(value) 的集合。
键(key)必须使用不可变类型。
在同一个字典中,键(key)必须是唯一的。
注意:
- 字典是一种映射类型,它的元素是键值对。
- 字典的关键字必须为不可变类型,且不能重复。
- 创建空字典使用 { }。
Bytes(字节数组类型)
bytes 类型表示的是不可变的二进制序列。
bytes 类型中的元素是整数值(0 到 255 之间的整数),而不是 Unicode 字符。
bytes 类型通常用于处理二进制数据,比如图像文件、音频文件、视频文件等等。在网络编程中,也经常使用 bytes 类型来传输二进制数据。
创建 bytes 对象的方式有多种,最常见的方式是使用 b 前缀:
此外,也可以使用 bytes() 函数将其他类型的对象转换为 bytes 类型。bytes() 函数的第一个参数是要转换的对象,第二个参数是编码方式,如果省略第二个参数,则默认使用 UTF-8 编码:
x = bytes("hello", encoding="utf-8")
bytes 类型支持切片、拼接、查找、替换等。
由于 bytes 类型是不可变的,因此在进行修改操作时需要创建一个新的 bytes 对象。
三、列表的增删改查
a.增加列表元素的方法
append()方法:用于在列表的结尾处增加元素,只能添加一个元素,或者一个列表形式的元素。
示例代码:
list1=[1,2,3,4]
list1.append(['x','y',5])
print(list1)运行结果:
[1, 2, 3, 4, ['x', 'y', 5]]insert()方法:用来在列表的指定索引位置插入内容,后面参数分别传递索引值、插入元素。
示例代码:
list1=[1,2,3,4,5]
list1.insert(2,'x')
list1.insert(2,'y')
print(list1)运行结果:
[1, 2, 'y', 'x', 3, 4, 5]extend()方法:用来拓展列表,追加一些元素,后面的参数可以是字符串、列表以及任何可迭代对象(但是只能是1项元素),python解释器会将此对象一一拆分然后追加至列表。
示例代码:
list1=[1,2,3,4,5]
list1.extend('x')
list1.extend('yzw')
list1.extend(range(3))
print(list1)运行结果:
[1, 2, 3, 4, 5, 'x', 'y', 'z', 'w', 0, 1, 2]b.删除列表元素的方法
pop()方法:用于删除列表中的一个指定索引位置所对应的值,然后返回被删除的对象,参数为索引值,默认删除列表中最后一个元素。
示例代码:
list1=[1,2,3,4,5,'x','y',range(3),'w']
list1.pop() # 删除最后1个元素
list1.pop(2) # 删除列表中第三个元素
print(list1)运行结果:
[1, 2, 4, 5, 'x', 'y', range(0, 3)]remove()方法:用于删除列表中一个指定元素,参数就是指定元素,如果找不到会报错(只能删除一个元素)。
示例代码:
list1=[1,2,3,4,5,'x','y',range(3),'w']
list1.remove('x')
print(list1)运行结果:
[1, 2, 3, 4, 5, 'y', range(0, 3), 'w']clear()方法:用来清空列表中所有的值(原有的列表就变成一个空列表了)。
示例代码:
list1=[1,2,3,4,5,'x','y',range(3),'w']
list1.clear()
print(list1)运行结果:
[]del方法:用于删除整个列表(删除之后此列表就不存在了)。
示例代码:
list1=[1,2,3,4,5,'x','y',range(3),'w']
del list1
print(list1)运行结果:
Traceback (most recent call last):
File "/root/Python/main.py", line 3, in <module>
print(list1)
NameError: name 'list1' is not definedc.修改列表元素的方法
索引:list_name[0]='修改后的值'
示例代码:
list1=[1,2,3,4,5,'x','y','w']
list1[0]='k'
list1[-2]=7
print(list1)运行结果:
['k', 2, 3, 4, 5, 'x', 7, 'w']切片:list_name[0:3]=[a,b,c]
注意:后面需要修改的值的总数可以不与切片的长度相对应,比如说[0:3]这个切片长度为3,后面可以传一个有2个或者4个元素的列表,此时只是将切片所对应的值剔除,再将后面列表依次插入。
后面也可赋值一个字符串,此时只是将切片所对应的值剔除,然后将后面字符串拆开依次插入。
示例代码:
list1=[1,2,3,4,5,'x','y','w']
list1[0:3]='kfc1'
print(list1)
list1[3:5]=['ab','c']
print(list1)
list1[0:2]=['hh']
print(list1)运行结果:
['k', 'f', 'c', '1', 4, 5, 'x', 'y', 'w']
['k', 'f', 'c', 'ab', 'c', 5, 'x', 'y', 'w']
['hh', 'c', 'ab', 'c', 5, 'x', 'y', 'w']d.查询列表元素的方法
查询元素的方法用索引和切片的方法
索引:list_name[0]
切片:list_name[0:3]
list_name[0:3:2]
示例代码:
list1=[1,2,3,4,5,'x','y','w']
print(list1[0])
print(list1[2:4])
print(list1[2:6:2])运行结果:
1
[3, 4]
[3, 5]若需要查询列表中所有的元素,可以用for循环来实现。
示例代码:
list1=[1,2,3,4,5,'x','y','w']
for list in list1:
print(list)运行结果:
1
2
3
4
5
x
y
we.列表的其他方法
len(list)方法:用来计算列表的长度
count()方法:用于计算列表中一个元素出现的次数
sort()方法:对列表进行排序(列表中的元素要为数字类型),默认是正序,可以指定倒序(reverse=True)
示例代码:
list1=[1,2,3,4,5,6,9,7,6,1]
list1.sort() #默认为正序排序
print(list1)
list1.sort(reverse=True) #指定reverse为True,则为倒序
print(list1)运行结果:
[1, 1, 2, 3, 4, 5, 6, 6, 7, 9]
[9, 7, 6, 6, 5, 4, 3, 2, 1, 1]reverse()方法:将列表中所有元素进行翻转,注意,不是排序,是把所有元素倒过来。
示例代码:
list1=[1,2,3,4,5,6,9,7,6,1]
list1.reverse()
print(list1)运行结果:
[1, 6, 7, 9, 6, 5, 4, 3, 2, 1]join()方法:将列表中的元素用指定字符连接起来,字符可以是空格,可以是空字符,可以是下划线以及任意字符(注意:可利用此方法将一个列表转为字符串格式。
示例代码:
list1=['赵','钱','孙','李']
print('*'.join(list1))
print(' '.join(list1))
print(''.join(list1))
print('_'.join(list1))运行结果:
赵*钱*孙*李
赵 钱 孙 李
赵钱孙李
赵_钱_孙_李f.列表的嵌套
列表里可放一切元素,当然也可以嵌套列表。如果需要对列表里的列表进行增删改查,只需先索引到里面的列表,然后再进行操作即可。
示例代码:
list1=['赵','钱','孙',['李','周','吴'],'郑','王']
print(list1[3])
print(list1[3][0:2])
list1[3].pop(1)
print(list1)
list1[3].remove('吴')
print(list1)运行结果:
['李', '周', '吴']
['李', '周']
['赵', '钱', '孙', ['李', '吴'], '郑', '王']
['赵', '钱', '孙', ['李'], '郑', '王']四、字典的增删改查
字典采用键值对(key-value)的形式存储数据。字典是无序的对象集合,字典当中的元素是通过键来存储的,而不是通过偏移存取。
a.创建字典元素的方法
dict['key']=value:通过字典的key给字典添加元素,如果字典中已存在该key值,则会覆盖,如果不存在,则会添加。
示例代码:
dict={'name':'Alice','age':26,'sex':'female'}
dict['addr']='HangZhou'
print(dict)运行结果:
{'name': 'Alice', 'age': 26, 'sex': 'female', 'addr': 'HangZhou'}setdefault()方法:根据函数对字典增加元素,参数为('key','value'),value默认为none。
与直接用dict['key']=value增加字典元素方法不同,用setdefault(key,value)方法时,若字典中没有该key,则会正常添加,若key存在,不进行操作(不覆盖)。
示例代码:
dict={'name':'Alice','age':26,'sex':'female'}
dict.setdefault('addr','HangZhou') # 不存在key,则正常添加
dict.setdefault('age',28) # 存在此key,不覆盖
dict.setdefault('height') # value值默认为None
print(dict)运行结果:
{'name': 'Alice', 'age': 26, 'sex': 'female', 'addr': 'HangZhou', 'height': None}b.删除字典元素的方法
pop(key)方法:字典的pop()方法必须传一个key值,如果字典中没有此key值,则会报错
也可以用pop(key,'value')来指定返回值,此时当找不到key时,不会报错,会将指定的返回值返回。
示例代码:
dict={'name':'Alice','age':26,'sex':'female','job':'STE'}
dict.pop('name') # 删除name,此时key存在,不会报错
dict.pop('addr','HangZhou') # 此时虽然找不到key:'addr',但是不会报错,会将'HangZhou'返回
print(dict)
dict.pop('height') # 此时key不存在,会报错 KeyError: 'height'
print(dict) 运行结果:
{'age': 26, 'sex': 'female', 'job': 'STE'}
Traceback (most recent call last):
File "/root/Python/main.py", line 5, in <module>
dict.pop('height') #
KeyError: 'height'popitem()方法:用来随机删除一个元素,返回删除的那个元素的(键,值)
示例代码:
dict={'name':'Alice','age':26,'sex':'female','job':'STE'}
print(dict.popitem()) # 返回被删除元素的(键,值)
print(dict)
运行结果:
('job', 'STE')
{'name': 'Alice', 'age': 26, 'sex': 'female'}del dict[key]:用来删除字典中指定key以及它所对应的value值,若找不到该key,则会报错。
示例代码:
dict={'name':'Alice','age':26,'sex':'female','job':'STE'}
del dict['age']
print(dict)
del dict['height'] # 此时key:'height'不存在,报错:KeyError:'height'
print(dict) 运行结果:
{'name': 'Alice', 'sex': 'female', 'job': 'STE'}
Traceback (most recent call last):
File "/root/Python/main.py", line 4, in <module>
del dict['height'] # 此时key:'height'不存在,报错:KeyError:'height'
KeyError: 'height'clear()方法:用于清空字典
示例代码:
dict={'name':'Alice','age':26,'sex':'female','job':'STE'}
dict.clear()
print(dict)运行结果:
{}del dict:用于删除整个字典
示例代码:
dict={'name':'Alice','age':26,'sex':'female','job':'STE'}
del dict
print(dict) 运行结果:
<class 'dict'>c.修改字典元素的方法
dict['key']=value:通过字典的key来修改对应的value值,如果字典中已存在该key值,则会修改,如果不存在,则会重新添加。
示例代码:
dict={'name':'Alice','age':26,'sex':'female','job':'STE'}
dict['height']=180
print(dict)
dict['addr']='杭州'
print(dict)
dict['addr']='甘肃' # 此时key:'addr'存在,则会修改
print(dict)运行结果:
{'name': 'Alice', 'age': 26, 'sex': 'female', 'job': 'STE', 'height': 180}
{'name': 'Alice', 'age': 26, 'sex': 'female', 'job': 'STE', 'height': 180, 'addr': '杭州'}
{'name': 'Alice', 'age': 26, 'sex': 'female', 'job': 'STE', 'height': 180, 'addr': '甘肃'}update({key:value})方法:用来追加、拓展原字典元素,参数必须为一个字典。
如果传入的字典中有部分key与原字典相同,则该key所对应的值会被覆盖;其他没有的key会被添加。
示例代码:
dict={'name':'Alice','age':26,'sex':'female','job':'STE'}
dict.update({'age':30,'addr':'杭州','job':'singer'})
print(dict)运行结果:
{'name': 'Alice', 'age': 30, 'sex': 'female', 'job': 'singer', 'addr': '杭州'}d.查询字典元素的方法
dict[key]:可以通过key来索引查询字典的元素,如果查不到,则会报错。
示例代码:
dict={'name':'Alice','age':26,'sex':'female','job':'STE'}
print(dict['name'])
print(dict['addr']) # 搜索不到会报错,KeyError:'addr'运行结果:
Alice
Traceback (most recent call last):
File "/root/Python/main.py", line 3, in <module>
print(dict['addr']) # 搜索不到会报错,KeyError:'addr'
KeyError: 'addr'get(key)方法:用指定索引的方法来查找其所对应的元素,如果找不到,不会报错,可以通过dict.get(key,'value')方法指定找不到key时候的返回值。
示例代码:
dict={'name':'Alice','age':26,'sex':'female','job':'STE'}
print(dict.get('name'))
print(dict.get('addr'))
print(dict.get('addr','找不到该数据')) 运行结果:
Alice
None
找不到该数据keys()方法:用来查询字典所有的key,也可以使用for循环进行遍历
示例代码:
dict={'name':'Alice','age':26,'sex':'female','job':'STE'}
print(dict.keys())
for key in dict.keys():
print(key) 运行结果:
dict_keys(['name', 'age', 'sex', 'job'])
name
age
sex
jobvalues()方法:用来查询字典所有的value,也可使用for循环进行遍历
示例代码:
dict={'name':'Alice','age':26,'sex':'female','job':'STE'}
print(dict.values())
for value in dict.values():
print(value) 运行结果:
dict_values(['Alice', 26, 'female', 'STE'])
Alice
26
female
STEitems()方法:用来查询字典中所有的键值,可用for循环进行遍历
示例代码:
dict={'name':'Alice','age':26,'sex':'female','job':'STE'}
print(dict.items())
for item in dict.items():
print(item)
for key,value in dict.items():
print(key,value) 运行结果:
dict_items([('name', 'Alice'), ('age', 26), ('sex', 'female'), ('job', 'STE')])
('name', 'Alice')
('age', 26)
('sex', 'female')
('job', 'STE')
name Alice
age 26
sex female
job STEe.字典排序
sorted函数,sorted(iterable,key,reverse)
iterable:可迭代的对象,可以是dict.items()、dict.keys()、dict.values()等
key:一个函数,用来选取参与比较的元素
reverse:用来指定是顺序还是倒序,reverse=True则是倒序,reverse=False则是顺序,默认顺序
e1.按照key排序
(1)直接使用sorted(dict.keys())就能按key值对字典排序,使用sorted(dict.keys(),reverse=True)按key值对字典进行倒序排序
示例代码:
dict={'name':'Alice','age':26,'sex':'female','job':'STE'}
print(sorted(dict.items())) # 按照键值对对字典进行顺序排序
print(sorted(dict.items(),reverse=True)) # 按照键值对对字典进行倒序排序
print(sorted(dict.keys())) # 按照key对字典进行顺序排序
print(sorted(dict.keys(),reverse=True)) # 按照key对字典进行倒序排序
dict1={'Alice':26,'bjt':30,'Tina':28,'Jim':37}
print(sorted(dict1.values())) # 按照value对字典进行顺序排序
print(sorted(dict1.values(),reverse=True)) # 按照value对字典进行倒序排序
运行结果:
[('age', 26), ('job', 'STE'), ('name', 'Alice'), ('sex', 'female')]
[('sex', 'female'), ('name', 'Alice'), ('job', 'STE'), ('age', 26)]
['age', 'job', 'name', 'sex']
['sex', 'name', 'job', 'age']
[26, 28, 30, 37]
[37, 30, 28, 26]e2.按照value值排序
(1)key使用lambda匿名函数取value进行排序
示例代码:
dict={'name':'Alice','addr':'HangZhou','sex':'female','job':'STE'}
print(sorted(dict.items(),key=lambda item:item[1]))
print(sorted(dict.items(),key=lambda item:item[1],reverse=True)) 运行结果:
[('name', 'Alice'), ('addr', 'HangZhou'), ('job', 'STE'), ('sex', 'female')]
[('sex', 'female'), ('job', 'STE'), ('addr', 'HangZhou'), ('name', 'Alice')](2)使用operator的itemgetter进行排序
示例代码:
import operator
dict={'name':'Alice','addr':'HangZhou','sex':'Female','job':'STE'}
print(sorted(dict.items(),key=operator.itemgetter(1)))
print(sorted(dict.items(),key=operator.itemgetter(1),reverse=True)) 运行结果:
[('name', 'Alice'), ('sex', 'Female'), ('addr', 'HangZhou'), ('job', 'STE')]
[('job', 'STE'), ('addr', 'HangZhou'), ('sex', 'Female'), ('name', 'Alice')](3)将key和value分装成元组,再进行排序
示例代码:
dict={'Alice':26,'bjt':30,'Tina':28,'Jim':37}
f=zip(dict.keys(),dict.values())
print(sorted(f))运行结果:
[('Alice', 26), ('Jim', 37), ('Tina', 28), ('bjt', 30)]