官方解读:YOLO之外的另一选择,手机端97FPS的Anchor-Free目标检测模型NanoDet现已开源~ - 知乎
official implementation:
GitHub - RangiLyu/nanodet: NanoDet-Plus⚡Super fast and lightweight anchor-free object detection model. 🔥Only 980 KB(int8) / 1.8MB (fp16) and run 97FPS on cellphone🔥
Backbone
backbone采用ShuffleNetV2-1.0x,采用stage2、3、4的输出作为neck的输入,下采样倍数分别为为8、16、32。ShuffleNetV2的具体介绍见ShuffleNet v2。
Neck
neck部分采用PAN的结构并进行了一些修改,原始PAN的具体介绍见PANet(CVPR 2018)原理与代码解析。backbone中C2~C4的输出通道数为[116, 232, 464],lateral_conv的输出通道为96。这里的修改主要是将bottom-up path中的下采样方式由stride=2的3x3卷积改成了和top-down path中上采样一样的方式,即双线性插值。
至于官方解读里提到的不同尺度特征融合之前yolo采用的是concatenate,这里采用的是add,原始PAN采用的也是add,因此也不算修改。
Head
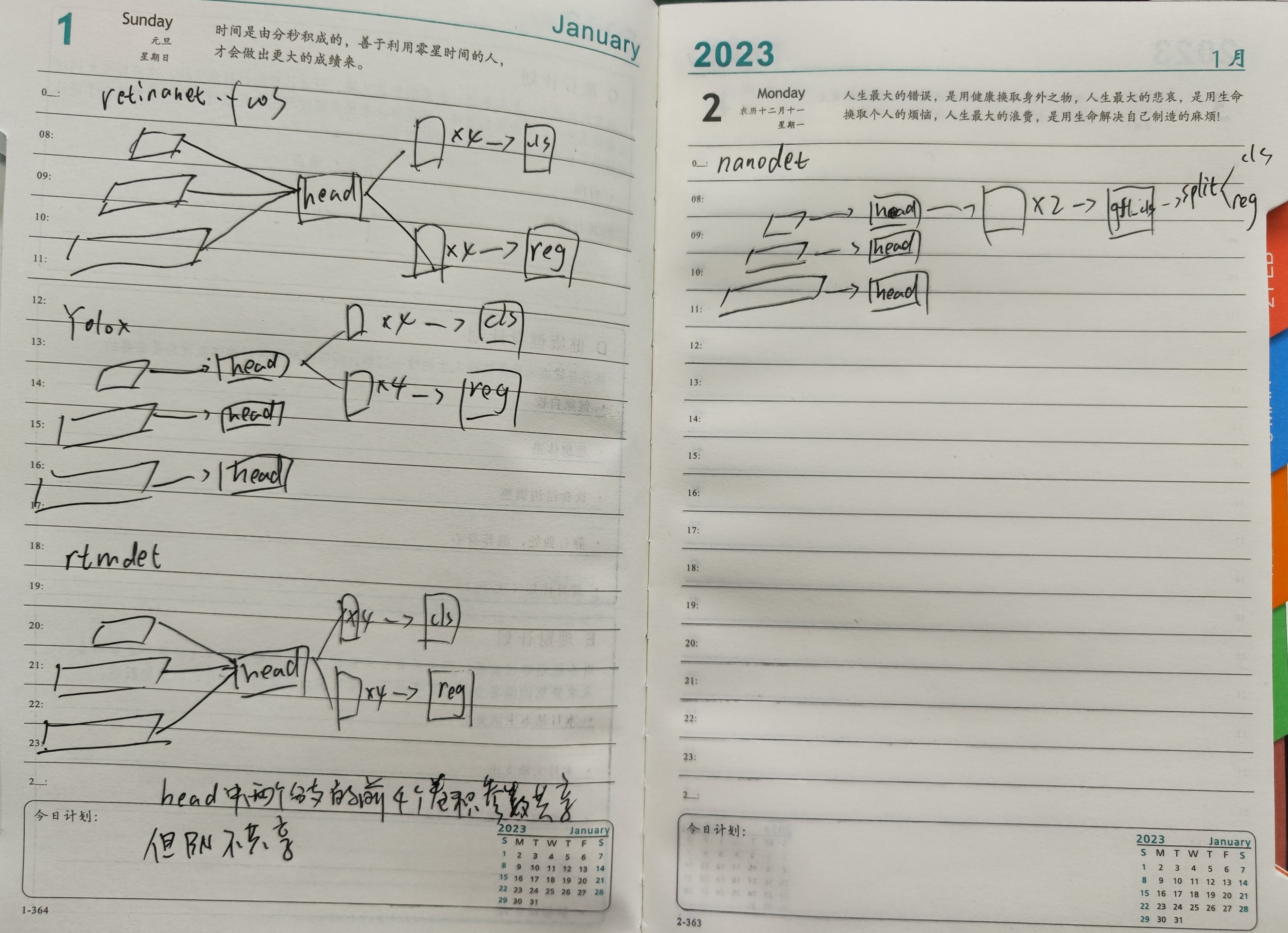
head部分的改动比较多。RetinaNet、FCOS中FPN不同层级的输出进入同一个检测头,检测头分为分类、回归两个分支,每个分支首先是4个卷积层,然后分别是分类和回归的输出卷积层。YOLOX中采用的是decoupled head,不同FPN层级的输出接不同的检测头,检测头的内部结构和FCOS是一样的。RTMDet中不同FPN层级的输出共享卷积参数,但BN层独立。即不同层级FPN的输出还是进入不同的检测头,但不同检测头里两个分支的前4个卷积是相同的,但BN层以及最后的分类、回归的输出卷积层是独立的。
最后是nanodet,采用的是和YOLOX一样的decoupled head,但检测头内部不再分为分类和回归两个分支,前面的4个卷积改为2个,最后经过一个输出卷积层,然后沿通道split得到分类和回归的输出。
Label Assignment
标签分配采用的是ATSS,没有做修改,具体介绍见ATSS:Adaptive Training Sample Selection原理与代码解读。
Loss
损失函数采用的是Genreal Focal Loss,具体介绍见Generalized Focal Loss 原理与代码解析。
![[LitCTF 2023]这是什么?SQL !注一下 !](https://img-blog.csdnimg.cn/direct/ca34cbe85b7346d2a00a3f49762010d6.png#pic_center)