一、redis中的数据库
- redis服务器将所有数据库都保存在服务器状态redis.h/redisServer结构的db数组中。
- db数组的每项都是一个redis.h/redisDb结构,而每个redisDb结构就代表一个数据库。
- 在初始化服务器时,程序会根据服务器状态的dbnum属性来决定应该创建多少个数据库。
struct redisServer {
// ...
// 一个数组,保存着服务器中的所有数据库
redisDb *db;
// ...
// 服务器的数据库数量
int dbnum;
// ...
};dbnum属性的值是由redis.conf配置文件中的databases来决定的,默认为16个。

二、数据库的切换(select命令)
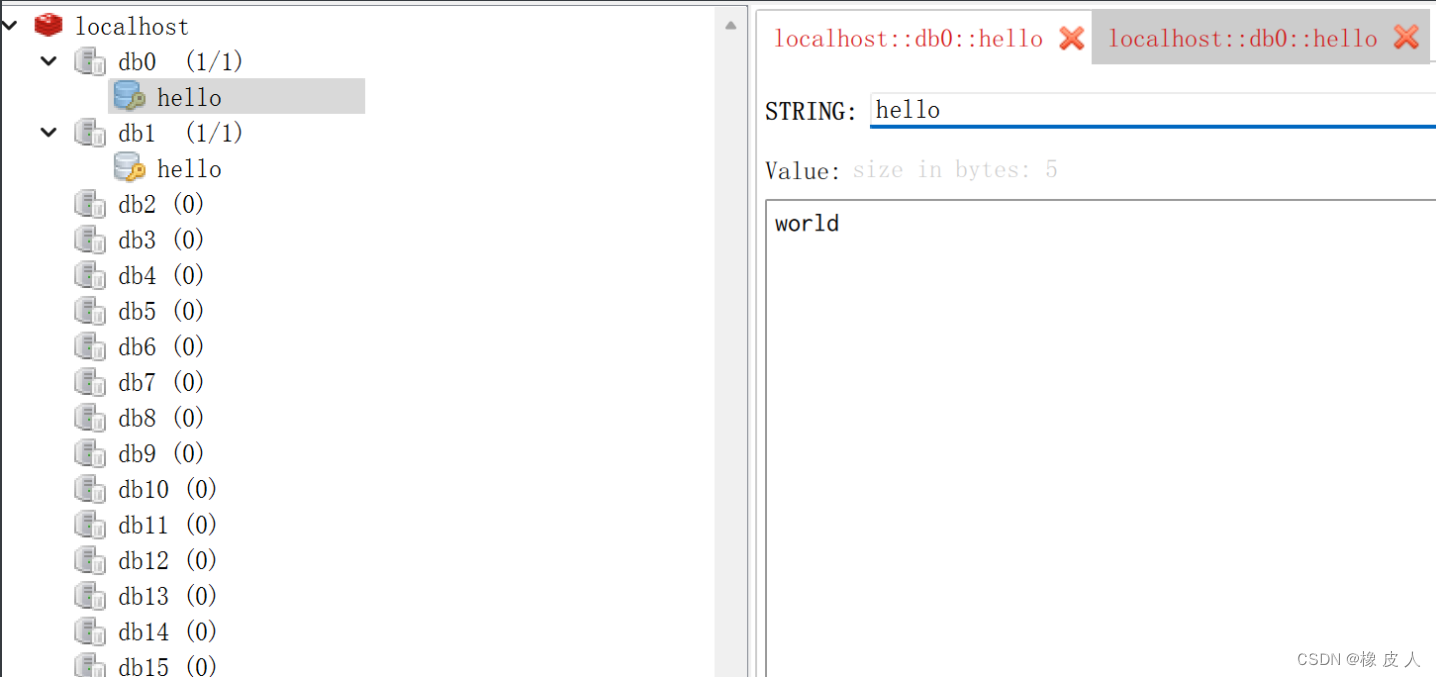
我们先用redis可视化工具连上我们本地的redis,如图:
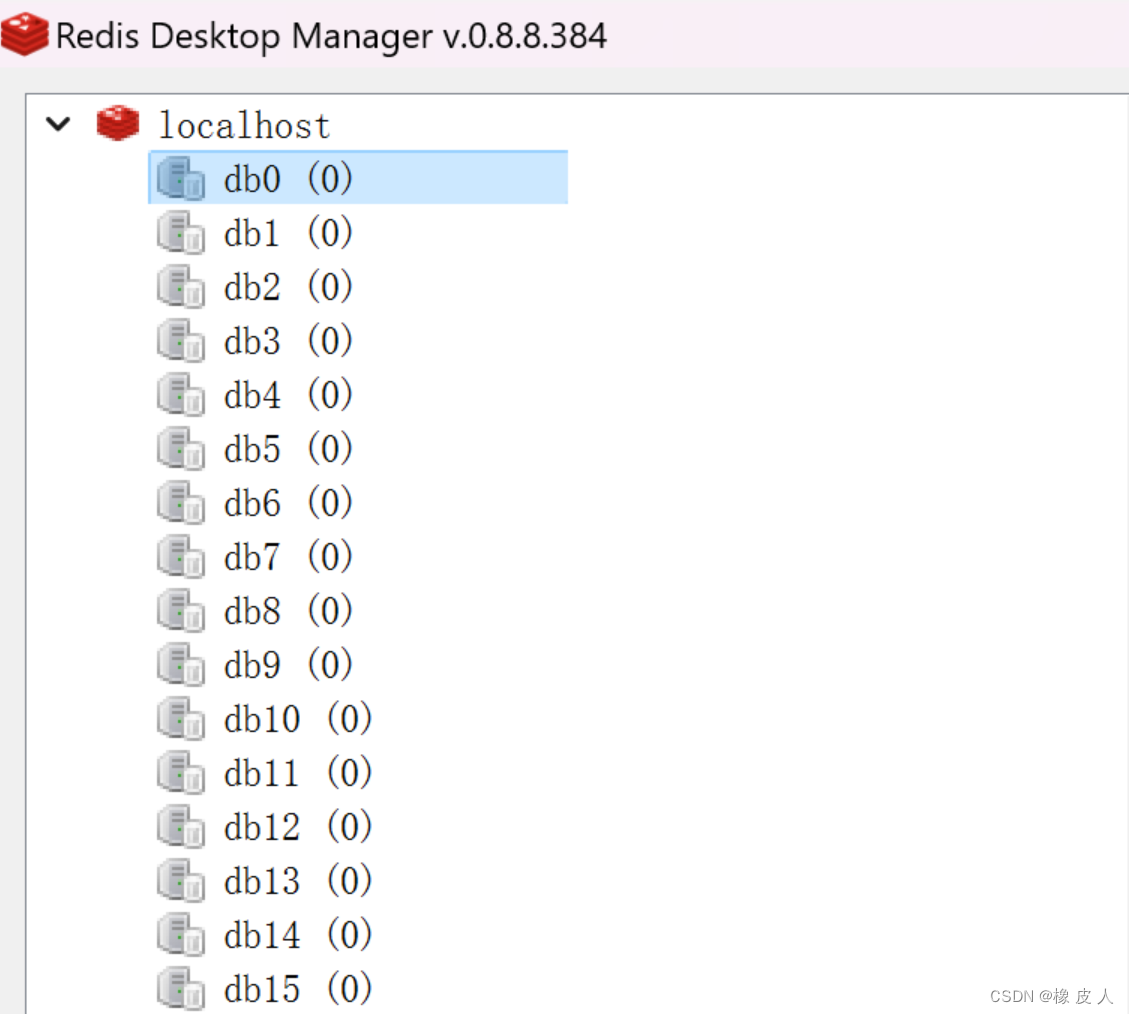
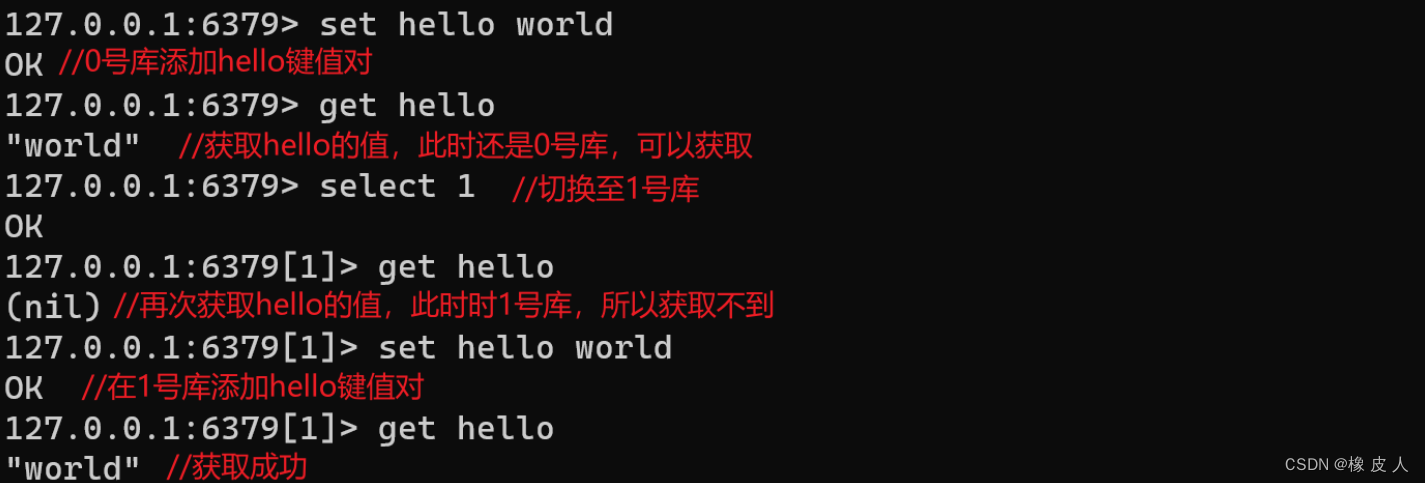
默认情况下,Redis客户端的目标数据库为0号数据库,但可以用select命令来切库:
在服务器内部,客户端状态redisClient结构的db属性记录了客户端当前的目标数据库,这个属性是一个指向redisDb结构的指针:
typedef struct redisClient {
// ...
// 记录客户端当前正在使用的数据库
redisDb *db;
// ...
} redisClient;简单地说就是:通过修改redisClient.db指针,让它指向服务器中的不同数据库,就可以实现切换数据库的功能——这就是select命令的实现原理。
三、数据库键空间(key space)
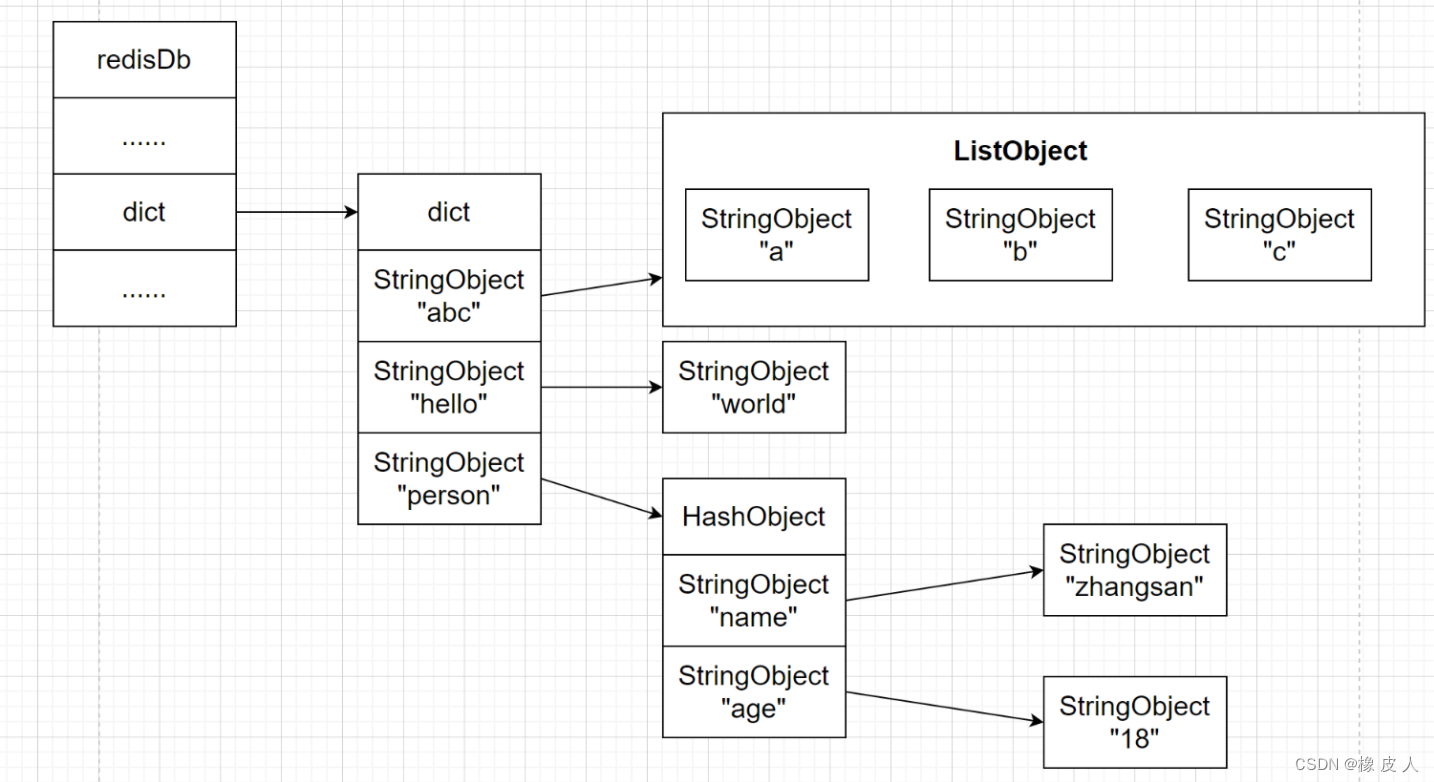
redis是一个键值对(key-value)的数据库,每个数据库都由一个redis.h/redisDb结构表示,而redisDb结构的dict字典则保存了数据库中所有键值对,我们通常称之为键空间(key space):
typedef struct redisDb {
//数据库键空间,保存数据库中所有键值对
dict *dict;
dict *expires; //过期字典,保存键的过期时间(4.2会提到)
dict *blocking_keys;
dict *ready_keys;
dict *watched_keys;
int id;
long long avg_ttl;
} redisDb;键空间的每个键(key)都是字符串对象,而值(value)则可以是字符串、列表、哈希、集合等对象中的任意一种。
举个例子:
执行上述命令后,数据库的键空间将会是下图的样子:
四、过期键
有时候我们希望给某些键一个过期时间,即希望它存活一段时间就失效,redis同样也给我们提供了这样的机制。
4.1 设置过期时间
4.1.1 expire和pexpire
expire用于设定某个键的过期时间,单位是秒,格式如下:
expire [key] [time]
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> get hello
"world"
127.0.0.1:6379> expire hello 10
(integer) 1
127.0.0.1:6379> get hello
(nil)可以看到,10秒后redis删除了hello键,与之对应的还有一个pexpire命令,它的time时间单位为毫秒,即[pexpire hello 5]经过5毫秒后删除hello键。
4.1.2 expireat和pexpireat
expireat用于设定某个键在某个具体Unix时间戳过期,单位为秒,基本格式如下:
expireat [key] [time]
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> time
1) "1704285269" //当前Unix时间戳
2) "434279"
127.0.0.1:6379> expireat hello 1704285289 //时间戳到1704285289时删除
(integer) 1
127.0.0.1:6379> get hello
(nil)过期键会在我们指定的Unix时间戳删除,当然它也有一个对应毫秒单位的命令——pexpireat。
ps:当然也可以用setex,在设置一个字符串键的同时设置过期时间,但他仅限于string数据类型,这里就不介绍了。
4.1.3 ttl、pttl和persist
ttl和pttl两个命令用于查看过期键还剩余多少时间。
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> expire hello 20
(integer) 1
127.0.0.1:6379> ttl hello
(integer) 17
127.0.0.1:6379> pttl hello
(integer) 10317 //毫秒单位,约为10.3秒persist用于移除某个键的过期时间,使其永久有效:
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> expire hello 100
(integer) 1
127.0.0.1:6379> ttl hello
(integer) 96
127.0.0.1:6379> persist hello //移除hello键过期时间
(integer) 1
127.0.0.1:6379> ttl hello
(integer) -1 //-1表示永久有效4.2 保存过期时间
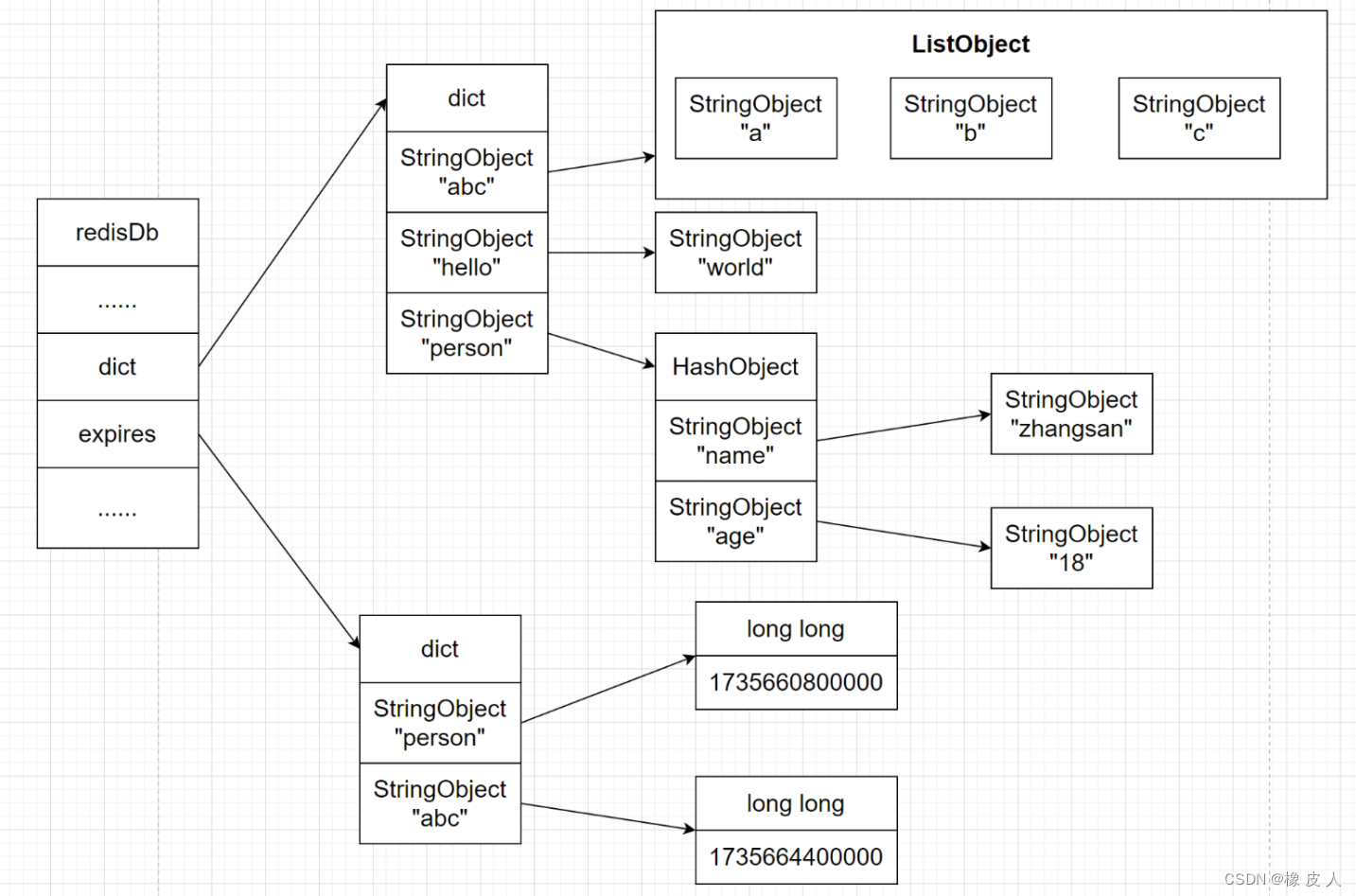
redisDb结构的expires指针保存了数据库中所有键的过期时间,我们称之为过期字典:
- 过期字典的键是一个指针,这个指针指向键空间中的某个键对象。
- 过期字典的值是一个longlong类型的整数,这个整数保存了键所指向的数据库键的过期时间——一个毫秒精度的UNIX时间戳。
我们给person、abc键设置过期时间:
127.0.0.1:6379> pexpireat person 1735660800000 //2025年1月1日 00:00:00
(integer) 1
127.0.0.1:6379> pexpireat abc 1735664400000 //2025年1月1日 01:00:00
(integer) 1
127.0.0.1:6379> pttl person
(integer) 31374276693
127.0.0.1:6379> pttl abc
(integer) 31377871933那么此时对应的键空间如下图:
redis判断键是否过期的大致步骤如下:
- 检查键是否存在过期字典,如果存在则取到过期时间。
- 判断当前UNIX时间戳是否大于键的过期时间,如果是,那么此键就过期,反之则未过期。
五、删除策略(避免内存泄漏)
我们每设置一个键的过期时间,redis就会在过期字典中保存一份。当键过期后,如果没有触发删除策略的话,过期后的数据依然会保存在内存中,即便已经过期,我们还是能够获取到这个键的数据。那么它们如何被删除呢,有三种策略,下面我们介绍下。
5.1 定时删除
定时删除:在设置键的过期时间同时,创建一个定时器(timer),到了过期时间,立即执行对建的删除操作。
很显然,这是一种时间换空间的做法:
优点:对内存友好,通过定时器可以保证过期的建尽可能快的被删除,从而释放内存。
缺点:
对CPU很不友好,在过期键比较多的情况下,删除操作会占用一部分CPU时间,在内存不紧张但CPU紧张的情况下,将CPU时间用在删除和当前任务无关的过期键上,无疑会对服务器的响应时间和吞吐量造成影响。
除此之外,创建一个定时器需要用到redis服务器中的时间事件,而当前时间事件的实现方式——无序链表,查找一个事件的时间复杂度位O(N)——并不能高效地处理大量时间事件。
5.2 惰性删除
不会主动去删除过期的键,而是在你要获取某个键时,会先检查一下这个键是否过期,如果没过期就返回给你,过期就会删除这个键。
很显然,这是一种空间换时间的做法:
优点:对CPU友好,程序只会在获取键的时候进行过期检查,并不会在删除其它无关的过期键上花费任何CPU时间。
缺点:对内存不友好,如果有非常多的过期键,并且这些键不会被访问到,那么它们将会永远不会被删除(除非flushdb),这可能会导致内存泄漏的风险。
5.3 定期删除
每隔一段时间,程序就对数据库进行一次检查,删除里面的过期键。
定期删除则是对定时和惰性删除的一种折中方案:
优点:
定期删除策略每隔一段时间执行一次删除过期键的操作,并会限制删除操作执行的时长和频率来减少对CPU时间的影响。
通过定期删除,可以有效地减少了因为过期键带来的内存浪费。
缺点:
如果删除操作执行太频繁或时间太长,定期删除则会退化为定时删除。
如果删除操作执行的太少,又会退化为惰性删除。
所以,定期删除虽然是一个这种方案,但执行时长和频率难以把握。
5.4 redis中的删除策略
前面提到了三种策略,而redis采用的则是惰性删除+定期删除两种策略,那么它俩之间是如何配合的呢,我们一起来看看。
5.4.1 惰性删除
惰性删除策略由db.c/expireIfNeeded函数实现,所有读写数据库的redis命令在执行之前都会调用该函数对输入键进行检查,大致流程也很简单:
对所有读写命令进行检查(调用expireIfNeeded函数)。
判断键是否过期,如果过期则删除键,没过期就不做任何操作。
ps:甭管键过没过期都会执行实际的命令流程,比如get命令,如果键过期则会被删除,返回结果为null,如果没过期就返回实际的值。
5.4.2 定期删除
定期删除由redis.c/activeExpireCycle函数实现,redis默认每隔100ms就随机抽取部分设置了过期时间的key,检查这些key是否过期,如果过期就删除。
100ms的执行周期是默认的,可以在redis.conf文件中更改:
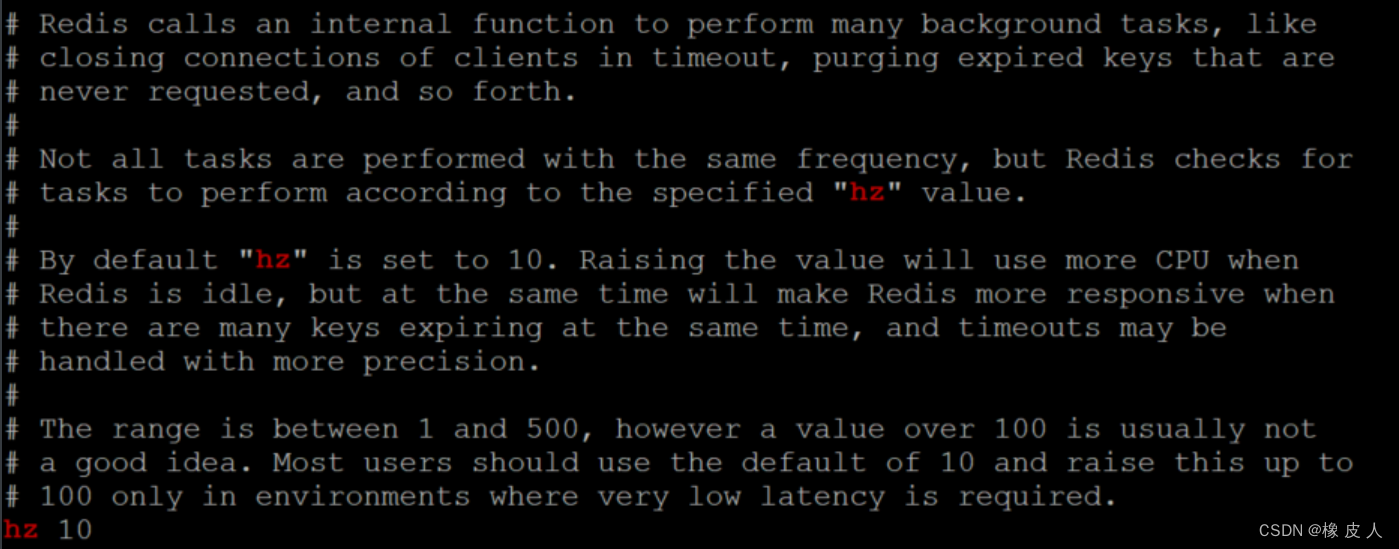
它的执行频率由hz参数值指定,默认是10,也就是每一秒执行10次。
注释翻译:
Redis调用内部函数执行许多后台任务,例如关闭超时的客户端连接,清除从未被请求的过期键等。 并非所有任务的执行频率都相同,但Redis会根据指定的“hz”值检查要执行的任务。 “hz”被设置为10。提高该值将在Redis空闲时使用更多的CPU,但同时在有许多键同时过期且需要更高的精度的情况下,会使Redis的响应更快。 范围介于1和500之间。然而,通常不建议超过100的值,而应该默认使用10,并将其升至100的值仅适用于需要非常低延迟的环境。大多数用户不需要设置高于10的“hz”值。
5.0版本之前,hz参数一旦设定就会被固定,但如果链接数比较多的情况下,10的默认值可能就不能够满足这种情况,就需要手动去更改hz的值,这样就很不方便。
redis 5.0之后,有了dynamic-hz参数,默认就是打开的,当连接数很多时,就会自动加倍hz,以便处理更多的链接:
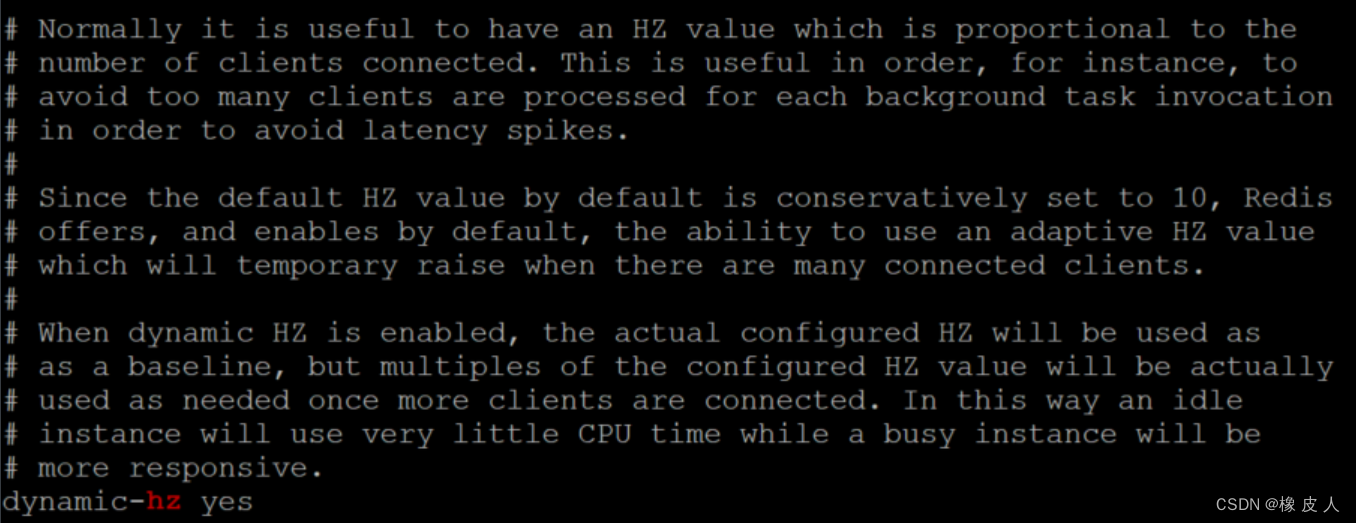
注释翻译:
通常情况下,拥有与连接的客户端数量成比例的 Hz 值是很有用的。例如,这对于在每次后台任务调用期间避免处理太多客户端以避免延迟峰值是很有用的。 由于默认情况下,HZ 值被保守地设置为 10,Redis 提供并默认启用了使用自适应 Hz 值的能力,该值在存在许多连接的情况下会临时增加。 启用动态 Hz 时,实际配置的 Hz 值将作为基线使用,但在连接更多客户端时,将根据需要使用配置的 Hz 值的倍数。这样,空闲实例的 CPU 时间将很少,而繁忙实例将更加响应。
那么它到底是这么删的呢,源码如下
for (j = 0; j < dbs_per_call; j++) {
int expired;
redisDb *db = server.db+(current_db % server.dbnum);
current_db++;
/* 超过25%的key已过期,则继续. */
do {
unsigned long num, slots;
long long now, ttl_sum;
int ttl_samples;
/* 如果该db没有设置过期key,则继续看下个db*/
if ((num = dictSize(db->expires)) == 0) {
db->avg_ttl = 0;
break;
}
slots = dictSlots(db->expires);
now = mstime();
/*但少于1%时,需要调整字典大小*/
if (num && slots > DICT_HT_INITIAL_SIZE &&
(num*100/slots < 1)) break;
expired = 0;
ttl_sum = 0;
ttl_samples = 0;
if (num > ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP)
num = ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP;// 20
while (num--) {
dictEntry *de;
long long ttl;
if ((de = dictGetRandomKey(db->expires)) == NULL) break;
ttl = dictGetSignedIntegerVal(de)-now;
if (activeExpireCycleTryExpire(db,de,now)) expired++;
if (ttl > 0) {
/* We want the average TTL of keys yet not expired. */
ttl_sum += ttl;
ttl_samples++;
}
}
/* Update the average TTL stats for this database. */
if (ttl_samples) {
long long avg_ttl = ttl_sum/ttl_samples;
/样本获取移动平均值 */
if (db->avg_ttl == 0) db->avg_ttl = avg_ttl;
db->avg_ttl = (db->avg_ttl/50)*49 + (avg_ttl/50);
}
iteration++;
if ((iteration & 0xf) == 0) { /* 每迭代16次检查一次 */
long long elapsed = ustime()-start;
latencyAddSampleIfNeeded("expire-cycle",elapsed/1000);
if (elapsed > timelimit) timelimit_exit = 1;
}
/* 超过时间限制则退出*/
if (timelimit_exit) return;
/* 在当前db中,如果少于25%的key过期,则停止继续删除过期key */
} while (expired > ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP/4);
}大致的逻辑如下:
- 依次遍历每个db(默认是16个),针对每个db随机选择20个设置了生存时间的(ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP)键,并对过期的键进行删除。
- 如果被删除的key超过了25%,再次随机筛选出20个设置了生存时间的key....
- 如果被删除的key不超过25%,这次定期删除结束。
六、内存淘汰策略(避免内存溢出)
本来没想介绍这节的,但发现删除策略和淘汰策略关系还挺密切的,索性一起介绍了吧。
我们现在想一个问题,定期+惰性可以保证过期的key一定会被删掉,但是只能保证最终一定会被删除,要是定期删除遗漏了大量的过期键,而且很长一段时间都不会访问这些键,那么久而久之redis内存可能会被耗尽,由于可能会存在这样的问题,所以redis又引入了“内存淘汰机制”来解决:
当Redis的内存空间不足,还需要再存储数据时,就会触发淘汰策略,默认策略就是抛出异常…………
- volatile-lru -> Evict using approximated LRU among the keys with an expire set.
在设置了生存时间的key中,采用最近最少使用的策略删除key
- allkeys-lru -> Evict any key using approximated LRU.
在全部的key中,采用最近最少使用的策略删除key
- volatile-lfu -> Evict using approximated LFU among the keys with an expire set.
在设置了生存时间的key中,采用最近最少频次使用的策略删除key
- allkeys-lfu -> Evict any key using approximated LFU.
在全部的key中,采用最近最少频次使用的策略删除key
- volatile-random -> Remove a random key among the ones with an expire set.
闹着玩,随机删……
- allkeys-random -> Remove a random key, any key.
闹着玩,随机删……
- volatile-ttl -> Remove the key with the nearest expire time (minor TTL)
在设置了生存时间的key中,删除剩余生存时间最少的key
- noeviction(默认策略) -> Don't evict anything, just return an error on write operations.
抛出异常!
那么如何选择,以下是腾讯针对redis淘汰策略给出的建议:
- 当redis作为缓存使用的时候,推荐使用allkeys-lru。该策略会将最近最少使用的key淘汰。默认情况下,使用频率最低则后期命中的概率也最低,所以将其淘汰。
- 当redis作为半缓存半持久化使用时,可以用volatile-lru。因为redis本身不建议保存持久化数据,所以只做备选方案。
End:希望对大家有所帮助,如果有纰漏或者更好的想法,请您一定不要吝啬你的赐教🙋。