目录
前言
一、准确率
二、精确率
三、召回率
四、F1-score
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
前言
很多时候需要对自己模型进行性能评估,对于一些理论上面的知识我想基本不用说明太多,关于校验模型准确度的指标主要有混淆矩阵、准确率、精确率、召回率、F1 score。另外还有P-R曲线以及AUC/ROC,这些我都有写过相应的理论和具体理论过程:
机器学习:性能度量篇-Python利用鸢尾花数据绘制ROC和AUC曲线
机器学习:性能度量篇-Python利用鸢尾花数据绘制P-R曲线
sklearn预测评估指标:混淆矩阵计算详解-附Python计算代码
这里我们主要进行实践利用sklearn快速实现模型数据校验,完成基础指标计算。
一、准确率
准确率是分类正确的样本占总样本个数的比例,即

我们知道混淆矩阵为:
| 真实情况 | 预测结果 | |
| 正例 | 反例 | |
| 正例 | TP(真正例) | FN(假反例) |
| 反例 | FP(假正例) | TN(真反例) |
其中,ncorrect为被正确分类的样本个数,ntotal为总样本个数。 结合上面的混淆矩阵,公式还可以这样写:

准确率是分类问题中最简单直观的评价指标,但存在明显的缺陷。比如如果样本中有99%的样本为正样本,那么分类器只需要一直预测为正,就可以得到99%的准确率,但其实际性能是非常低下的。也就是说,当不同类别样本的比例非常不均衡时,占比大的类别往往成为影响准确率的最主要因素。
from sklearn.metrics import accuracy_score
print('Accuracy:{}'.format(accuracy_score(y_true, y_pred))) ![]()
二、精确率
查准率。即正确预测为正类的占全部预测为正类的的比例。计算公式为:

sklearn的参数有:
sklearn.metrics.precision_score(y_true,
y_pred,
*,
labels=None,
pos_label=1,
average='binary',
sample_weight=None,
zero_division='warn')[source]参数说明:
y_true:array-like, or label indicator array / sparse matrix。真实值。
y_pred:array-like, or label indicator array / sparse matrix。预测值。
labels:array-like, default=None。当average != binary时被包含的标签集合,如果average是None的话还包含它们的顺序. 在数据中存在的标签可以被排除,比如计算一个忽略多数负类的多类平均值时,数据中没有出现的标签会导致宏平均值(marco average)含有0个组件. 对于多标签的目标,标签是列索引. 默认情况下,y_true和y_pred中的所有标签按照排序后的顺序使用.
pos_label:str or int, default=1。如果average='binary'且数据为二进制,则要报告的类。如果数据是多类或多标签的,则将忽略该数据;设置labels=[pos_label]和average!='binary”将只报告该标签的分数。
average:{‘micro’, ‘macro’, ‘samples’, ‘weighted’, ‘binary’} or None, default=’binary’。多类/多标签目标需要此参数。如果无,则返回每个类别的分数。否则,这将决定对数据执行的平均类型:
'binary':仅pos_label指定的类的结果。这仅适用于目标(y_{true,pred})为二进制的情况。- 'micro':通过计算总的真正例、假反例和假正例来计算全局度量。
'macro':计算每个标签的指标,并找到它们的未加权平均值。这没有考虑到标签不平衡。'weighted':为每个标签计算指标,并通过各类占比找到它们的加权均值(每个标签的正例数).它解决了’macro’的标签不平衡问题;它可以产生不在精确率和召回率之间的F-score.'samples':计算每个实例的度量,并找到它们的平均值(仅对多标记分类有意义,因为这与accuracy_score不同)。
sample_weight:array-like of shape (n_samples,), default=None。标签权重
zero_division:设置除零时返回的值。如果设置为“warn”,则该值将作为0,但也会引发警告。
from sklearn.metrics import precision_score
print('Percosopn:{}'.format(precision_score(y_true, y_pred, average='weighted')))- Macro Average
宏平均是指在计算均值时使每个类别具有相同的权重,最后结果是每个类别的指标的算术平均值。 - Micro Average
微平均是指计算多分类指标时赋予所有类别的每个样本相同的权重,将所有样本合在一起计算各个指标。
宏平均和微平均的概念也很重要:
- 如果每个类别的样本数量差不多,那么宏平均和微平均没有太大差异
- 如果每个类别的样本数量差异很大,那么注重样本量多的类时使用微平均,注重样本量少的类时使用宏平均
- 如果微平均大大低于宏平均,那么检查样本量多的类来确定指标表现差的原因
- 如果宏平均大大低于微平均,那么检查样本量少的类来确定指标表现差的原因
三、召回率
召回率指实际为正的样本中被预测为正的样本所占实际为正的样本的比例。
![]()
召回率是比率tp / (tp + fn),其中tp是真正性的数量,fn是假负性的数量. 召回率直观地说是分类器找到所有正样本的能力. 召回率最好的值是1,最差的值是0.
from sklearn.metrics import recall_score
print('Recall_score:{}'.format(recall_score(y_true, y_pred, average='weighted')))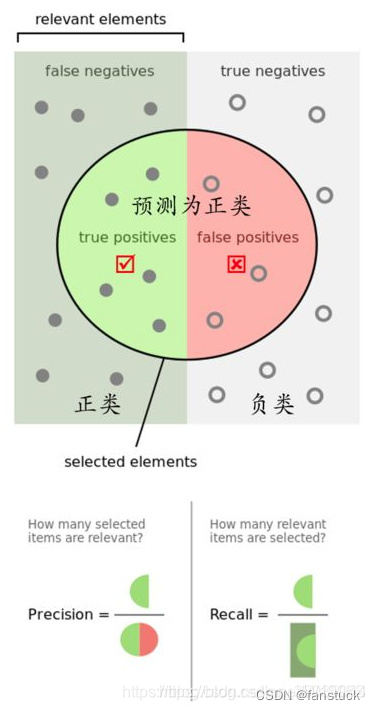
四、F1-score
F1 score是精确率和召回率的调和平均值,计算公式为:

Precision体现了模型对负样本的区分能力,Precision越高,模型对负样本的区分能力越强;Recall体现了模型对正样本的识别能力,Recall越高,模型对正样本的识别能力越强。F1 score是两者的综合,F1 score越高,说明模型越稳健。
from sklearn.metrics import f1_score
print('F1_socre:{}'.format(f1_score(y_true, y_pred, average='weighted')))
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见