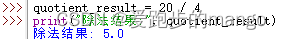系列文章目录
机器学习(一) -- 概述
机器学习(二) -- 数据预处理(1-3)
机器学习(三) -- 特征工程(1-2)
机器学习(四) -- 模型评估(1-4)
未完待续……
目录
系列文章目录
前言
三、分类模型评估指标
1、错误率与精度
2、查准率(精确率)、查全率(召回率)与F1值(F1_score)
2.1、混淆矩阵(confusion matrix)
2.2、查准率(precision,精确率)
2.3、查全率(recall,召回率)
2.4、P-R图
2.5、F1值(F1_score)
2.6、其他
3、ROC与AUC
4、分类报告
机器学习(四) -- 模型评估(1)
前言
tips:这里只是总结,不是教程哈。
“***”开头的是给好奇心重的宝宝看的,其实不太重要可以跳过。
此处以下所有内容均为暂定,因为我还没找到一个好的,让小白(我自己)也能容易理解(更系统、嗯应该是宏观)的讲解顺序与方式。
第一文主要简述了一下机器学习大致有哪些东西(当然远远不止这些),对大体框架有了一定了解。接着我们根据机器学习的流程一步步来学习吧,掐掉其他不太用得上我们的步骤,精练起来就4步(数据预处理,特征工程,训练模型,模型评估),其中训练模型则是我们的重头戏,基本上所有算法也都是这一步,so,这个最后写,先把其他三个讲了,然后,在结合这三步来进行算法的学习,兴许会好点(个人拙见)。
衡量模型泛化能力的评价标准就是性能度量(模型评估指标、模型评价标准),而针对不同的任务有不同的评价指标。按照数据集的目标值不同,可以把模型评估分为分类模型评估、回归模型评估和聚类模型评估。
三、分类模型评估指标
错误率与精度(准确率)、混淆矩阵、查准率(精确率)、查全率(召回率)与F1值(F1_score)、PR曲线、ROC与AUC
1、错误率与精度
概述里面就说过了,这是分类任务中最常用的两种性能度量。
错误率(error rate):分类错误的样本数/样本总数
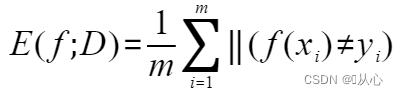
(公式还是要知道的,Ⅱ(*)是指示函数,在*为真(假)时取值为1(0))
精度(accuracy):1-错误率=分类正确的样本数/样本总数
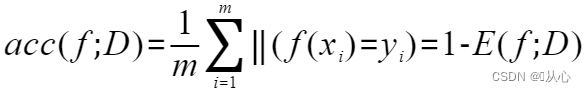
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
# 引入数据集
iris = load_iris()
# 划分数据集以及模型训练
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=134)
# 模型训练
model = DecisionTreeClassifier()
model.fit(x_train, y_train)
模型训练那一部分可以先不用管,我们现在主要是了解性能度量。
from sklearn.metrics import accuracy_score
# 精度
accuracy_score(y_test, model.predict(x_test)) 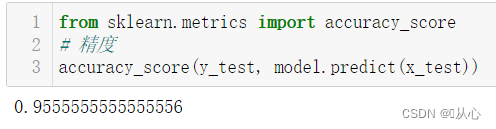
为了更形象一点,我们直接使用自制数据。
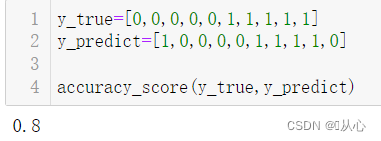
2、查准率(精确率)、查全率(召回率)与F1值(F1_score)
2.1、混淆矩阵(confusion matrix)
混淆矩阵是衡量分类型模型准确度中最基本,最直观,计算最简单的方法。如下是一个二分类问题结果的混淆矩阵。
| 真实情况 | 预测结果 | |
|---|---|---|
| P(正例) | N(反例) | |
| 正例 | TP(真正例) | FN(假反例) |
| 反例 | FP(假正例) | TN(真反例) |
预测结果是我们看到的,也就是经过模型计算出来的结果,TP+FP+TN+FN=样例总数。
API:
from sklearn.metrics import confusion_matrix还是用刚才的自制数据来看哈,就很明了了。

三分类问题在用混淆矩阵时,得到的是一个 3 X 3 的矩阵。此时预测结果和真实情况不再以正例、反例命名,而是数据集真实的分类结果。用鸢尾花结果来看。

2.2、查准率(precision,精确率)
分类正确的正样本个数占预测结果为正的样本个数的比例。
API:
from sklearn.metrics import precision_score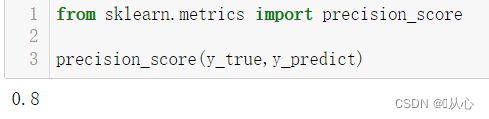
2.3、查全率(recall,召回率)
分类正确的正样本个数占真实值为正的样本个数的比例。
API:
from sklearn.metrics import recall_score
!!!注意:precision_score 和 recall_score 方法默认用来计算二分类问题,若要计算多分类问题,则需要设置 average 参数。
average:评价值的平均值的计算方式。
可以接收[None, 'binary' (default), 'micro', 'macro', 'weighted']
'micro', 'macro':微和宏,下面会说到。
' weighted ' : 相当于类间带权重。各类别的P × 该类别的样本数量(实际值而非预测值)/ 样本总数量
查准率和查全率是一对矛盾的度量。一般来说,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。
2.4、P-R图
( P-R 曲线只能用于二分类问题)以查准率为纵轴、查全率为横轴作图,就得到查准率-查全率曲线,简称“P-R 曲线”,显示该曲线的图称为“P-R”图。
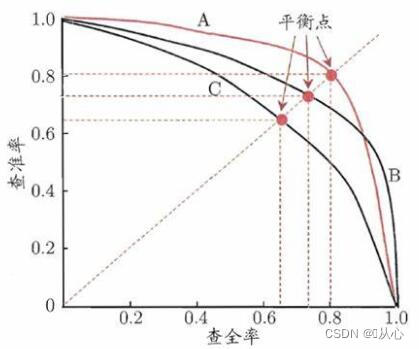
若一个学习器的 P-R 曲线被另一个学习器的 P-R 曲线完全“包住”,则可断言后者的性能优于前者。
若两个学习器的 P-R 曲线发生了交叉,例如学习器 A 与 B,则难以一般性地断言两者孰优孰劣,只能在具体的查准率或查全率条件下进行比较。
平衡点(Break-Even Point,简称 BEP):查准率=查全率时的取值。综合考虑查准率、查全率的性能度量,基于该方法则可断言学习器 A 优于学习器 B。
2.5、F1值(F1_score)
F1值是基于查准率与查全率的调和平均(harmonic mean)定义的:
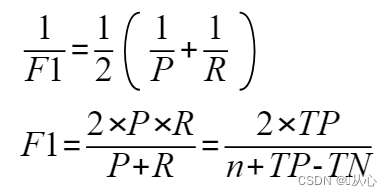
n为样例总数。
在一些应用中,对查准率和查全率的重视程度有所不同,会相应地添加权重。
Fβ则是加权调和平均定义:

其中β>0 度量了查全率对查准率的相对重要性。
β=1时退化为标准的 F1;
β>1 时查全率有更大影响;
β<1 时查准率有更大影响。
API
from sklearn.metrics import f1_score
from sklearn.metrics import fbeta_scorefrom sklearn.metrics import f1_score
f1_score(y_true,y_predict)
from sklearn.metrics import fbeta_score
print(fbeta_score(y_test, model.predict(x_test), beta=1, average='weighted'))
# 查全率有更大影响
print(fbeta_score(y_test, model.predict(x_test), beta=2, average='weighted'))
# 查准率有更大影响
print(fbeta_score(y_test, model.predict(x_test), beta=0.5, average='weighted'))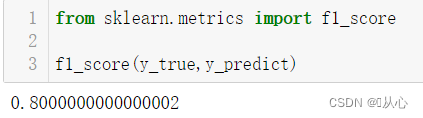

2.6、其他
很多时候我们有多个二分类混淆矩阵,需要进行多次训练/测试,每次得到一个混淆矩阵;或是在多个数据集上进行训练/测试,希望估计算法的“全局”性能,甚或是执行多分类任务,每两两类别的组合都对应一个混淆矩阵。总之,希望在 n 个二分类混淆矩阵上综合考察查准率和查全率。
所以就有了
宏查准率(macro-P)、宏查全率(macro-R)和宏F1(macro-F1)
微查准率(micro-P)、微查全率(micro-R)和微F1(micro-F1)
宏:先计算再平均

微:先平均再计算

print(f1_score(y_test, model.predict(x_test), average='macro'))
print(f1_score(y_test, model.predict(x_test), average='micro'))
3、ROC与AUC
很多学习器为测试样本产生一个实值或概率预测,然后将这个预测值与一个“分类阈值”进行比较,大于阈值则分为正类,否则为负类。
分类阈值也就是截断点(cut point)。分类过程就相当于在排序中以某个“截断点”将样本分为两部分,前一部分判作正例,后一部分则判作反例。
在不同的应用任务中,可根据任务需求来采用不同的截断点。
查准率:选择排序中靠前的位置进行截断。
查全率:选择排序中靠后的位置进行截断。
ROC 全称是“受试者工作特征”(Receiver Operating Characteristic)曲线。根据学习器的预测结果对样例进行排序,按此顺序逐个把样本作为正例进行预测,以“真正例率(True Positive Rate,简称 TPR)”为纵轴,以“假正例率(False Positive Rate,简称 FPR)”为横轴作图,就得到了“ROC曲线”。

API:
from sklearn.metrics import roc_curvefrom sklearn.metrics import roc_curve
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei' # 设置字体为SimHei # 显示中文
plt.rcParams['axes.unicode_minus']=False # 修复负号问题
fpr,tpr,thresholds=roc_curve(y_true,y_predict)
plt.plot(fpr, tpr)
plt.axis("square")
plt.xlabel("假正例率/False positive rate")
plt.ylabel("正正例率/True positive rate")
plt.title("ROC curve")
plt.show()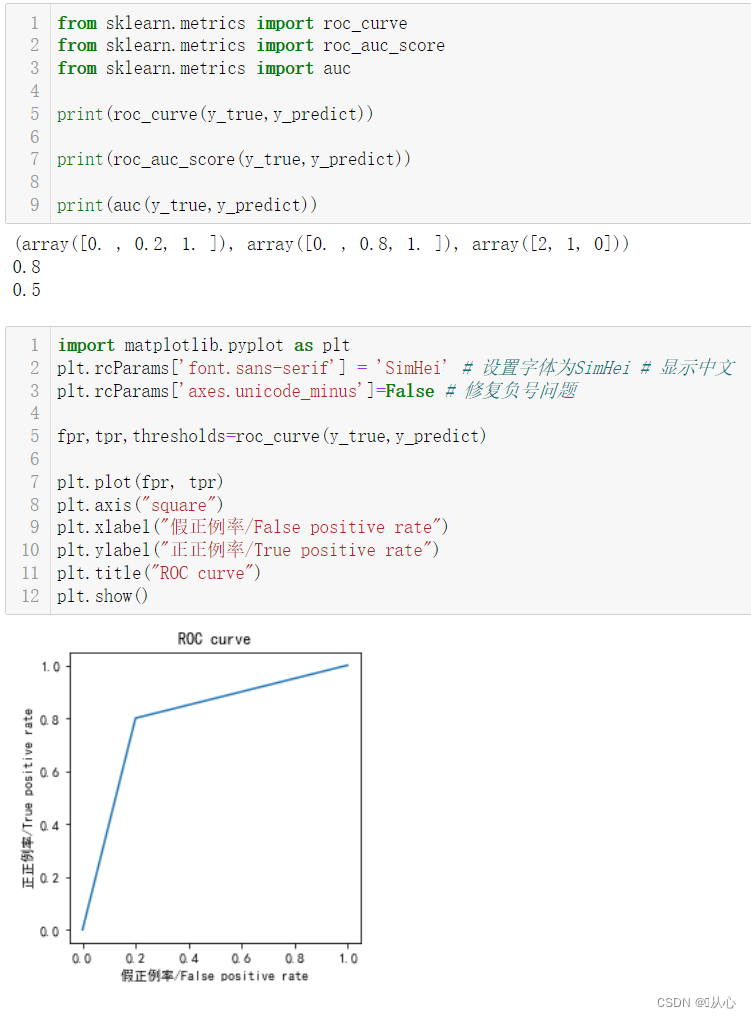
AUC(Area Under ROC Curve): ROC 曲线下的面积大小。该值能够量化地反映基于 ROC 曲线衡量出的模型性能。
!!!注意:roc_curve() 同 precision_recall_curve(),都只能用于二分类问题,但 roc_auc_score() 方法支持计算多分类问题的 auc 面积。
4、分类报告
scikit-learn 中提供了一个非常方便的工具,可以给出对分类问题的评估报告,Classification_report() 方法能够给出精确率(precision)、召回率(recall)、F1 值(F1-score)和样本数目(support)。
API:
from sklearn.metrics import classification_reportfrom sklearn.metrics import classification_report
# 自制数据
print(classification_report(y_true,y_predict))
# 鸢尾花数据
print(classification_report(y_test, model.predict(x_test)))