Stable Diffusion
- 1. Stable Diffusion能做什么?
- 2. 扩散模型
- 2.1 正向扩散
- 2.2 反向扩散
- 3. 训练如何进行
- 3.1 反向扩散
- 3.2 Stable Diffusion模型
- 3.3 潜在扩散模型
- 3.4 变分自动编码器
- 3.5 图像分辨率
- 3.6 图像放大
- 4. 为什么潜在空间是可能的?
- 4.1 在潜在空间中的反向扩散
- 4.2 什么是VAE文件?
- 5. 条件设定
- 5.1 文本条件(从文本到图像)
- 5.2 分词器
- 5.3 嵌入
- 5.4 将嵌入馈送给噪声预测器
- 5.5 交叉注意力
- 5.6 其他条件设定
- 6. Stable Diffusion逐步解释
- 6.1 从文本到图像
- 6.2 噪声进度表
- 6.3 从图像到图像
- 6.4 补白
- 6.5 深度到图像
- 7. 什么是CFG值?
- 7.1 分类器引导
- 7.2 无分类器引导
- 7.3 无分类器引导尺度
- 8.Stable Diffusion v1.5 vs v2
- 8.1 模型差异
- 8.2 训练数据差异
- 8.3 结果差异
- 9. SDXL模型
Stable Diffusion是一个生成AI图像的潜在扩散模型,它能够从文本中生成图像。与在高维图像空间中操作不同,它首先将图像压缩到潜在空间中。
我们将深入了解其内部运作机制。
为什么需要了解呢?除了本身是一个迷人的主题外,对内部机制的一些了解将使您成为一位更出色的艺术家。您可以正确使用这个工具,以更高的精度实现结果。
文本到图像与图像到图像有什么不同?什么是CFG尺度?什么是去噪强度?这些问题的答案将在本文中找到。
让我们深入了解。
1. Stable Diffusion能做什么?
Stable Diffusion简单来说是一个文本到图像的模型。给它一个文本提示,它会返回一张与文本匹配的人工智能图像。

2. 扩散模型
Stable Diffusion属于一类称为扩散模型的深度学习模型。它们是生成模型,意味着它们被设计用于生成类似于训练数据的新数据。在Stable Diffusion的情况下,这些数据是图像。
为什么它被称为扩散模型呢?因为它的数学表现非常类似于物理学中的扩散。让我们了解一下这个概念。
假设我用两种图像训练了一个扩散模型:猫和狗。在下图中,左侧的两个峰代表了猫和狗图像的群体。
2.1 正向扩散

正向扩散过程向训练图像添加噪声,逐渐将其转变为不具特征的噪声图像。正向过程将任何猫或狗图像转变为噪声图像。最终,你将无法分辨它们最初是狗还是猫(这很重要)。
这就像一滴墨水落入玻璃杯中。墨滴在水中扩散。几分钟后,它随机分布在整个水中。你无法再分辨它最初是在中心还是靠近边缘。
下面是图像经历正向扩散的示例。猫图像变成了随机噪声。

2.2 反向扩散
现在来看看令人兴奋的部分。如果我们能够反向扩散呢?就像倒放视频一样。倒退时间。我们将看到墨滴最初是如何添加的。
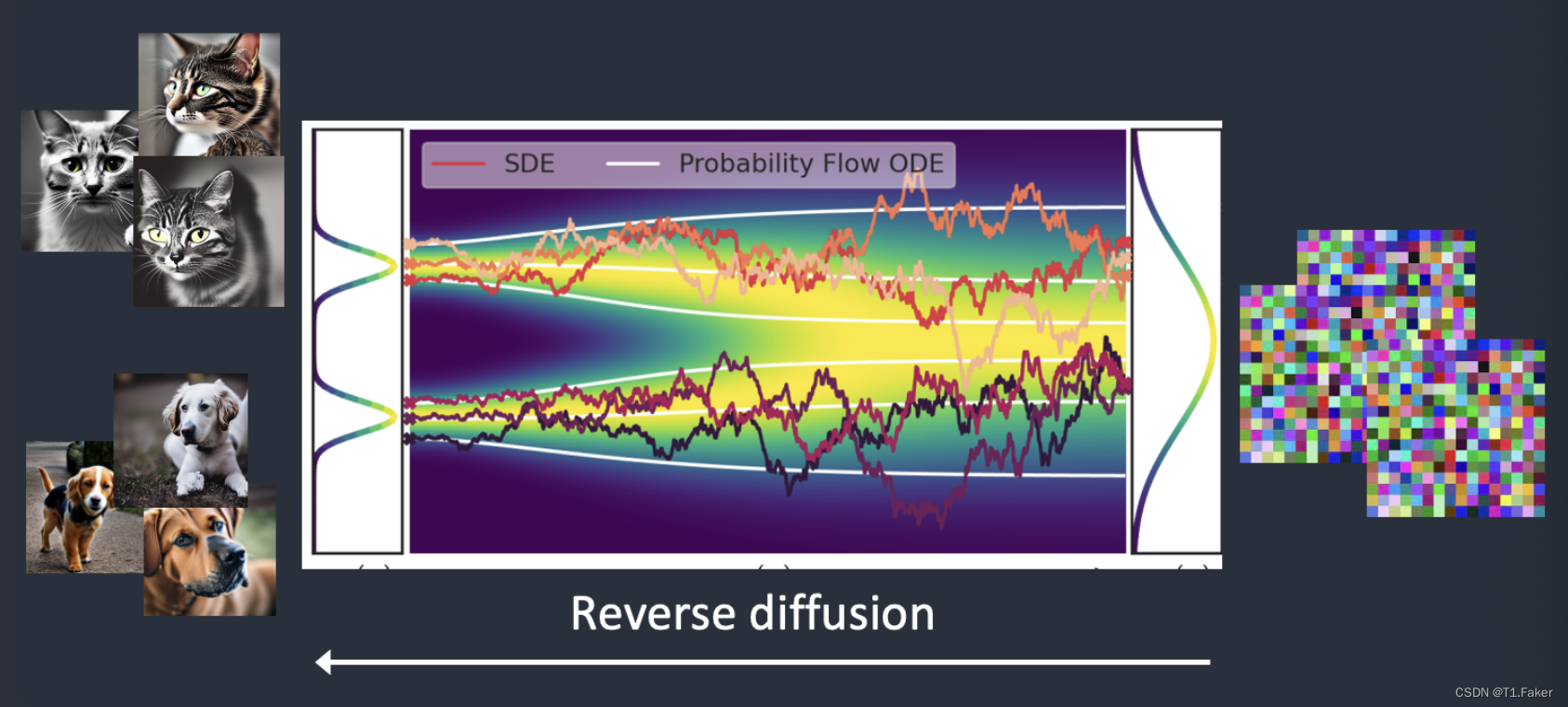
从一个嘈杂而无意义的图像开始,反向扩散将恢复出一个猫或狗的图像。这是主要的思想。
从技术上讲,每个扩散过程都有两个部分:(1)漂移和(2)随机运动。反向扩散向猫或狗图像漂移,但在两者之间没有其他情况。这就是为什么结果可能是猫或狗的原因。
3. 训练如何进行
反向扩散的思想无疑是聪明而优雅的。但是百万美元的问题是,“它怎么能做到呢?”
要实现反向扩散,我们需要知道向图像添加了多少噪声。答案是教一个神经网络模型来预测添加的噪声,这就是Stable Diffusion中的噪声预测器。它是一个U-Net模型。训练过程如下:
- 选择一张训练图像,比如一张猫的照片。
- 生成一个随机噪声图像。
- 通过将这个嘈杂图像添加到一定数量的步骤来破坏训练图像。
- 教会噪声预测器告诉我们添加了多少噪声。通过调整其权重并向其显示正确答案来完成这一过程。
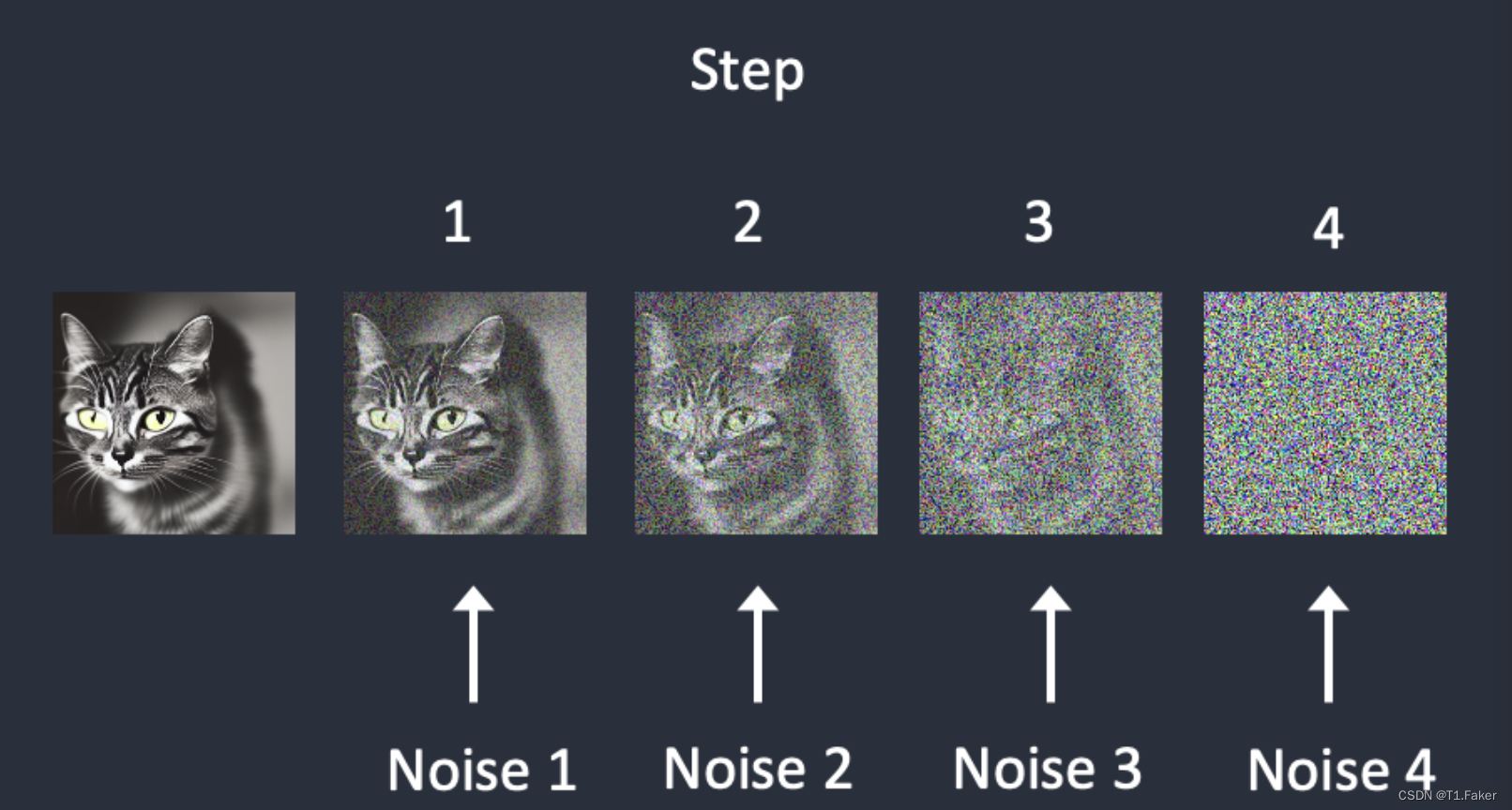
噪声在每个步骤逐渐添加。噪声预测器估计了每个步骤累积添加的总噪声。
训练结束后,我们有一个能够估计图像中添加的噪声的噪声预测器。
3.1 反向扩散
现在我们有了噪声预测器,怎么使用它呢?
我们首先生成一张完全随机的图像,然后请噪声预测器告诉我们噪声是多少。然后我们从原始图像中减去这个估计的噪声。重复这个过程几次,你将得到一张猫或狗的图像。
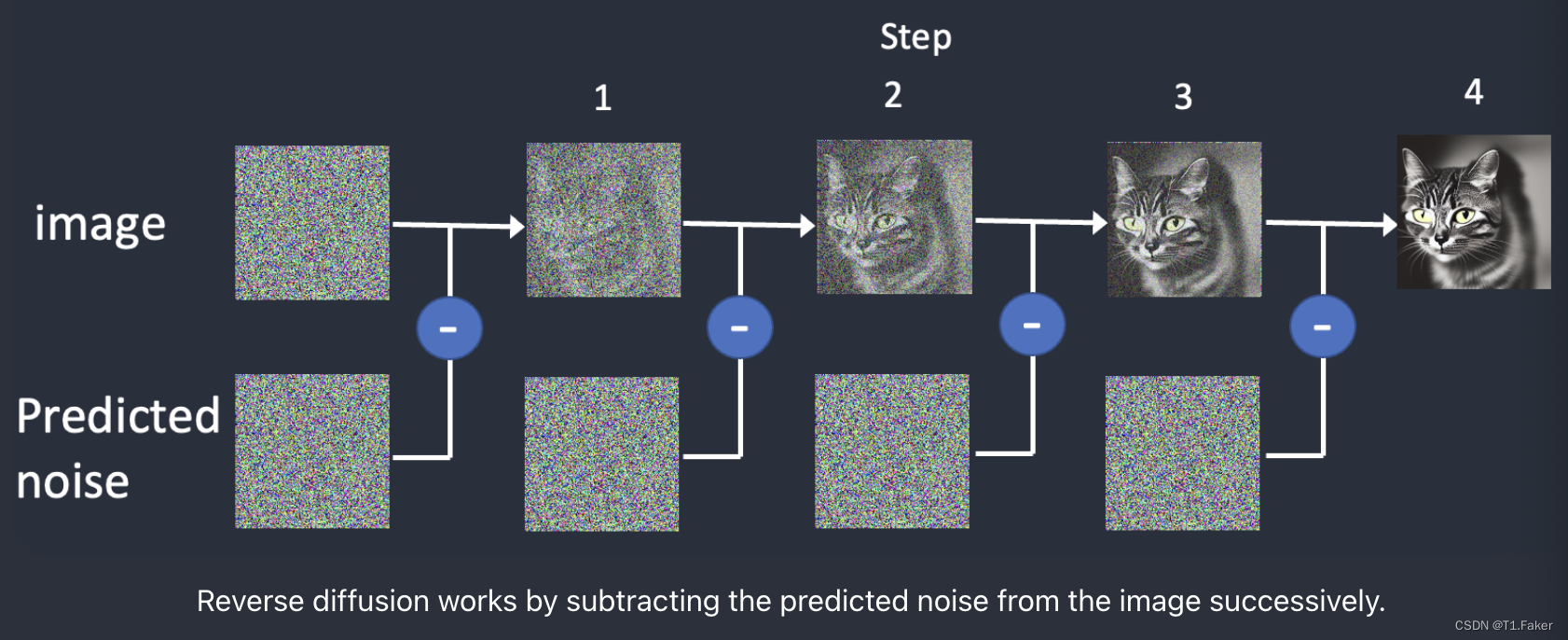
通过逐步从图像中减去预测的噪声来进行反向扩散。
你可能会注意到,我们无法控制生成猫或狗的图像。在谈到条件时,我们将解决这个问题。目前,图像生成是无条件的。
你可以在这篇文章中阅读有关反向扩散抽样和抽样器的更多信息。
3.2 Stable Diffusion模型
现在我需要告诉你一些坏消息:我们刚刚讨论的并不是Stable Diffusion的工作原理!原因是上述扩散过程是在图像空间进行的。在计算上非常慢。你甚至无法在任何单个GPU上运行,更不用说你笔记本电脑上的烂GPU了。
图像空间是巨大的。想想看:一个512×512像素的图像,有三个颜色通道(红、绿和蓝),是一个786,432维的空间!(你需要为一个图像指定那么多值。)
像Google的Imagen和Open AI的DALL-E这样的扩散模型都在像素空间。它们使用了一些技巧来使模型更快,但仍然不够。
3.3 潜在扩散模型
Stable Diffusion旨在解决速度问题。它是这样实现的。
Stable Diffusion是一个潜在扩散模型。它不是在高维图像空间中操作,而是首先将图像压缩到潜在空间。潜在空间小了48倍,因此它能够快速处理较少的数字。这就是为什么它更快的原因。
3.4 变分自动编码器
这是通过一种称为变分自动编码器(VAE)的技术完成的。是的,那就是VAE文件的精确内容,但我稍后会更清楚地解释。
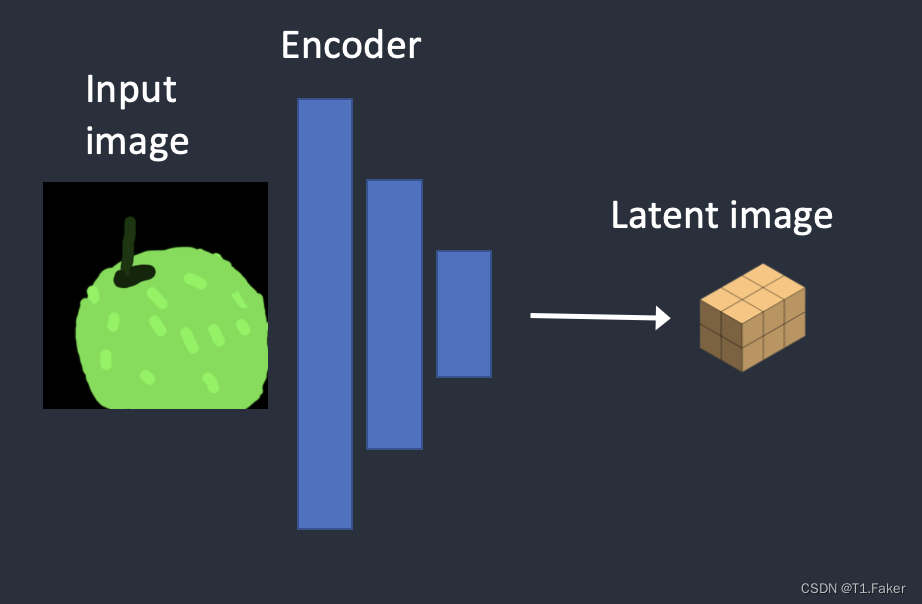
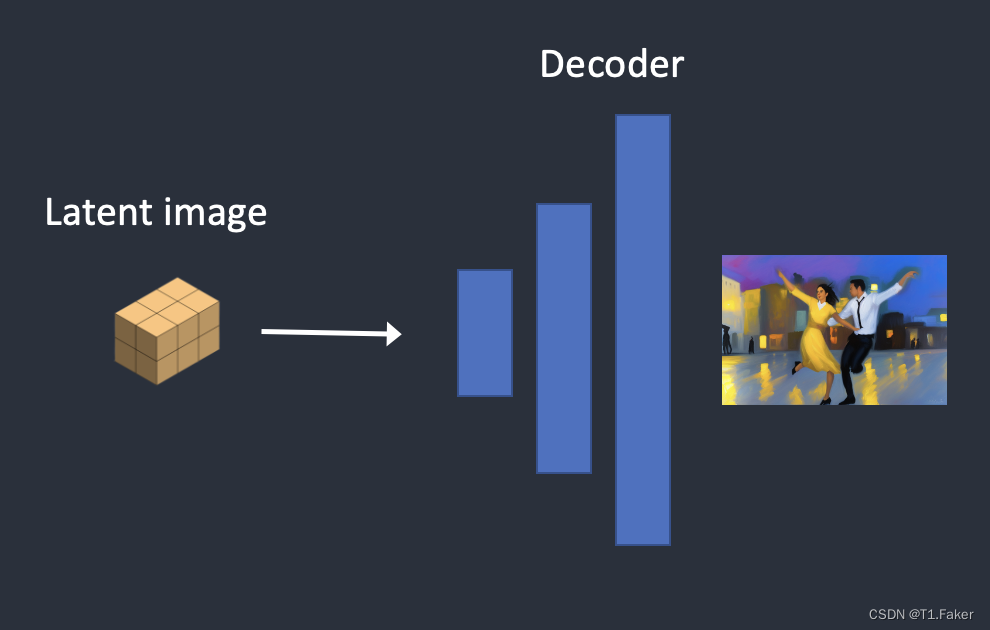
变分自动编码器(VAE)神经网络有两个部分:(1)编码器和(2)解码器。编码器将图像压缩到潜在空间中的较低维表示。解码器从潜在空间还原图像。
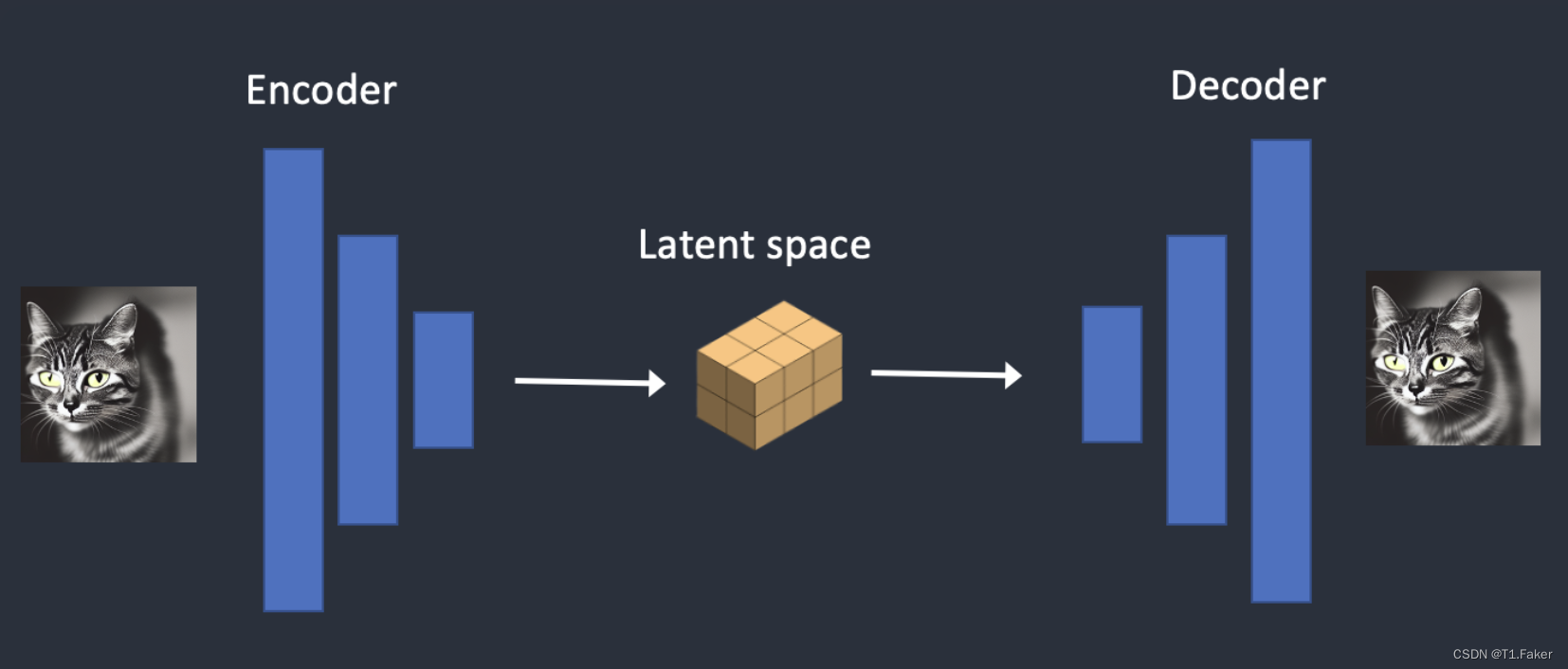
变分自动编码器在图像和潜在空间之间进行转换。
Stable Diffusion模型的潜在空间是4x64x64,比图像像素空间小了48倍。我们讨论的所有正向和反向扩散实际上都是在潜在空间中完成的。
因此,在训练过程中,我们不是生成嘈杂的图像,而是生成潜在空间中的随机张量(潜在噪声)。我们不是用噪声破坏图像,而是用潜在噪声破坏图像在潜在空间中的表示。这样做的原因是它更快,因为潜在空间较小。
3.5 图像分辨率
图像分辨率反映在潜在图像张量的大小上。对于512×512像素的图像,潜在图像的大小为4x64x64。对于768×512的竖向图像,潜在图像的大小为4x96x64。这就是为什么生成较大图像需要更长的时间和更多的显存的原因。
由于Stable Diffusion v1是在512×512像素的图像上进行微调的,生成大于512×512的图像可能会导致重复的对象,例如臭名昭著的双头现象。
3.6 图像放大
要生成大幅印刷品,请保持图像的至少一侧为512像素。使用AI放大器或图像到图像函数进行图像放大。
或者,使用SDXL模型。它具有较大的默认大小为1,024 x 1,024像素。
4. 为什么潜在空间是可能的?
你可能会想知道为什么VAE可以将图像压缩到一个远远较小的潜在空间而不丢失信息。原因是,毫不奇怪,自然图像并不是随机的。它们具有很高的规律性:一个脸遵循眼睛、鼻子、脸颊和嘴巴之间特定的空间关系。狗有4条腿,有特定的形状。
换句话说,图像的高维度是人为的。自然图像可以轻松地压缩到远远较小的潜在空间而不丢失任何信息。这被称为机器学习中的流形假设。
4.1 在潜在空间中的反向扩散
这是Stable Diffusion中潜在反向扩散的工作原理。
- 生成一个随机的潜在空间矩阵。
- 噪声预测器估计潜在矩阵的噪声。
- 然后从潜在矩阵中减去估计的噪声。
- 重复步骤2和3,直到特定的采样步骤。
- VAE的解码器将潜在矩阵转换为最终图像。
4.2 什么是VAE文件?
在Stable Diffusion v1中,VAE文件用于改善眼睛和面部的效果。它们是我们刚刚讨论的自动编码器的解码器。通过进一步微调解码器,模型可以呈现更精细的细节。
你可能意识到我之前提到的并不完全正确。将图像压缩到潜在空间确实会丢失信息,因为原始的VAE没有恢复出精细的细节。相反,VAE解码器负责绘制精细的细节。
5. 条件设定
我们的理解还不完整:文本提示从何处进入?没有它,Stable Diffusion不是一个文本到图像的模型。你将得到一张猫或狗的图像,没有任何控制它的方式。
这就是条件设置发挥作用的地方。条件设置的目的是引导噪声预测器,使得在从图像中减去预测的噪声之后,能够得到我们想要的结果。
5.1 文本条件(从文本到图像)
下面是文本提示如何处理并输入到噪声预测器的概述。分词器首先将提示中的每个单词转换为称为标记的数字。然后,每个标记转换为称为嵌入的768值向量。嵌入是由文本转换器生成的,准备好被噪声预测器使用。
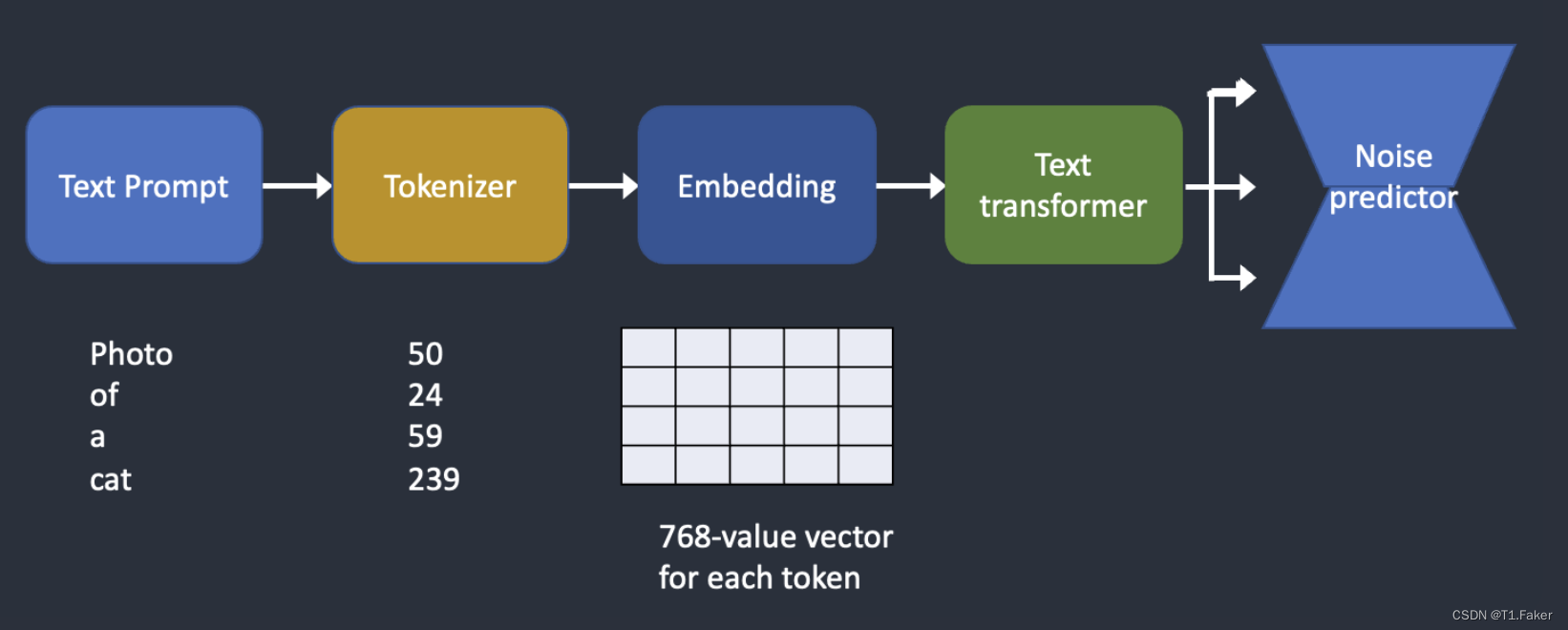
如何处理文本提示并将其输入到噪声预测器中以引导图像生成。
现在让我们更深入地了解每一部分。如果以上高级概述对您来说足够好,您可以跳到下一节。
5.2 分词器
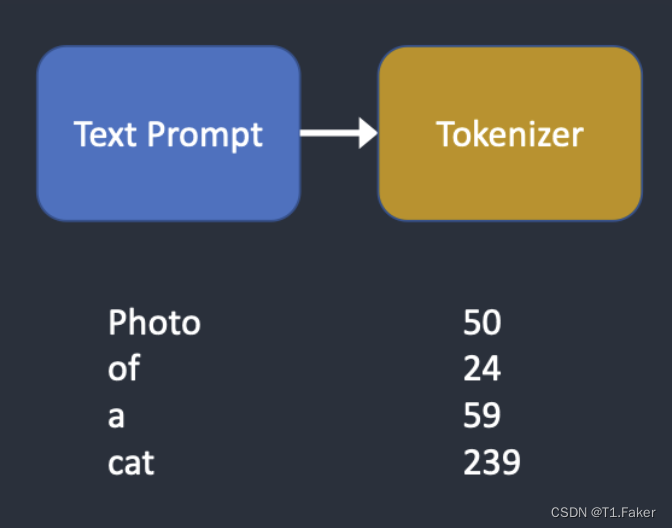
文本提示首先由CLIP分词器进行标记。CLIP是由OpenAI开发的深度学习模型,用于生成任何图像的文本描述。Stable Diffusion v1使用CLIP的分词器。
标记化是计算机理解单词的方式。我们人类可以阅读单词,但计算机只能读取数字。这就是为什么文本提示中的单词首先转换为数字的原因。
分词器只能对其在训练期间看到的单词进行标记。例如,CLIP模型中有“dream”和“beach”,但没有“dreambeach”。分词器将“dreambeach”分解为两个标记“dream”和“beach”。因此,一个单词并不总是意味着一个标记!
另一个细微之处是空格字符也是标记的一部分。在上述情况中,“dream beach”短语产生两个标记“dream”和“[space]beach”。这些标记与“dreambeach”产生的标记“dream”和“beach”(beach前面没有空格)不同。
Stable Diffusion模型限制在提示中使用75个标记。现在你知道它不同于75个单词了!
5.3 嵌入
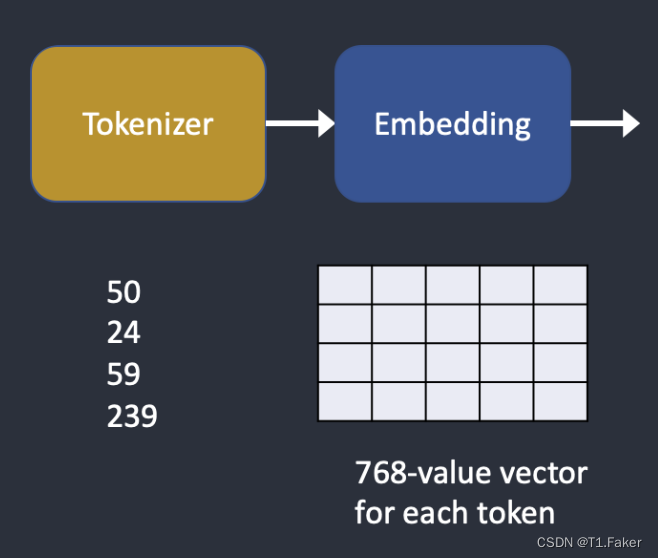
Stable Diffusion v1使用OpenAI的ViT-L/14 Clip模型。嵌入是一个768值向量。每个标记都有自己独特的嵌入向量。嵌入由CLIP模型固定,这在训练期间学到。
我们为什么需要嵌入?这是因为一些单词与彼此密切相关。我们想利用这个信息。例如,man、gentleman和guy的嵌入几乎相同,因为它们可以互换使用。Monet、Manet和Degas都以印象主义风格绘画,但以不同的方式。这些名称具有紧密但不完全相同的嵌入。
这就是我们之前讨论的使用关键词触发样式的嵌入。嵌入可以产生神奇的效果。科学家已经证明,找到适当的嵌入可以触发任意的对象和样式,这是一种称为文本反演的微调技术。
5.4 将嵌入馈送给噪声预测器
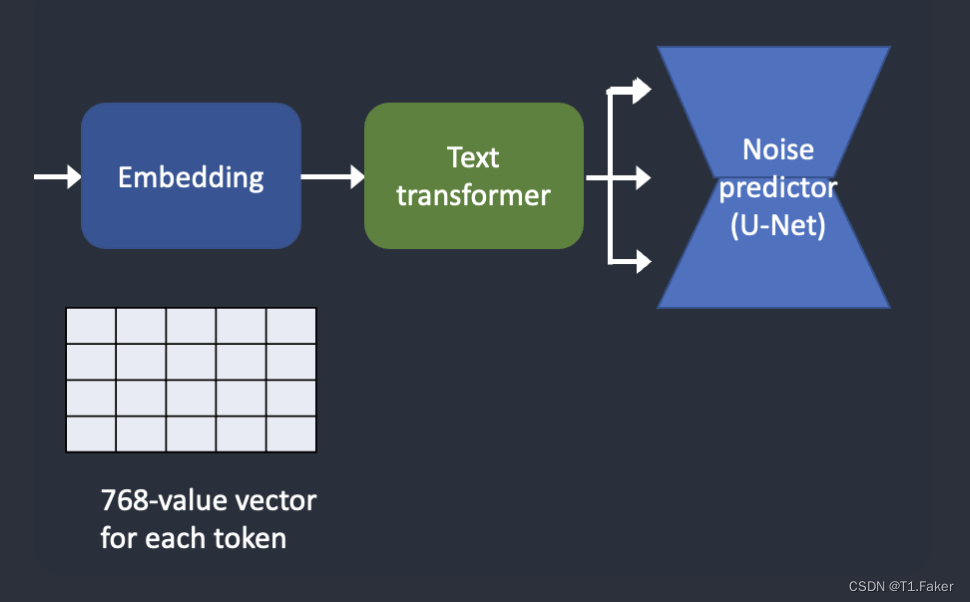
从嵌入到噪声预测器。
在馈送到噪声预测器之前,嵌入需要被文本变换器进一步处理。变换器就像条件设置的通用适配器。在这种情况下,它的输入是文本嵌入向量,但它也可以是其他东西,比如类标签、图像和深度图。变换器不仅进一步处理数据,还提供包含不同条件模式的机制。
5.5 交叉注意力
文本变换器的输出在整个U-Net中被噪声预测器多次使用。U-Net通过交叉注意力机制使用它。这就是提示遇到图像的地方。
让我们以“一个有蓝眼睛的男人”为例。Stable Diffusion将“蓝”和“眼睛”两个词配对在一起(在提示内部进行自注意),以便生成一个有蓝眼睛的男人,而不是穿蓝衬衫的男人。然后,它使用这些信息来引导反向扩散,生成包含蓝眼睛的图像(在提示和图像之间进行交叉注意力)。
一点说明:Hypernetwork是微调Stable Diffusion模型的一种技术,它劫持了交叉注意力网络以插入样式。LoRA模型修改交叉注意力模块的权重以更改样式。仅修改该模块就可以微调Stabe Diffusion模型的事实告诉你该模块有多重要。
5.6 其他条件设定
文本提示并不是Stable Diffusion模型进行条件设定的唯一方式。
文本提示和深度图像都用于在深度到图像模型中进行条件设定。
ControlNet使用检测到的轮廓、人体姿势等对噪声预测器进行条件设定,并实现对图像生成的出色控制。
6. Stable Diffusion逐步解释
现在你知道了Stable Diffusion的所有内部机制,让我们通过一些例子来看看在幕后发生了什么。
6.1 从文本到图像
在文本到图像中,你给Stable Diffusion一个文本提示,它返回一张图像。
步骤1:Stable Diffusion在潜在空间生成一个随机张量。通过设置随机数生成器的种子,你可以控制这个张量。如果将种子设置为某个值,你将始终得到相同的随机张量。这是你在潜在空间中的图像。但现在它只是噪声。

步骤2:噪声预测器U-Net以潜在嘈杂图像和文本提示作为输入,并预测潜在空间中的噪声(一个4x64x64张量)。
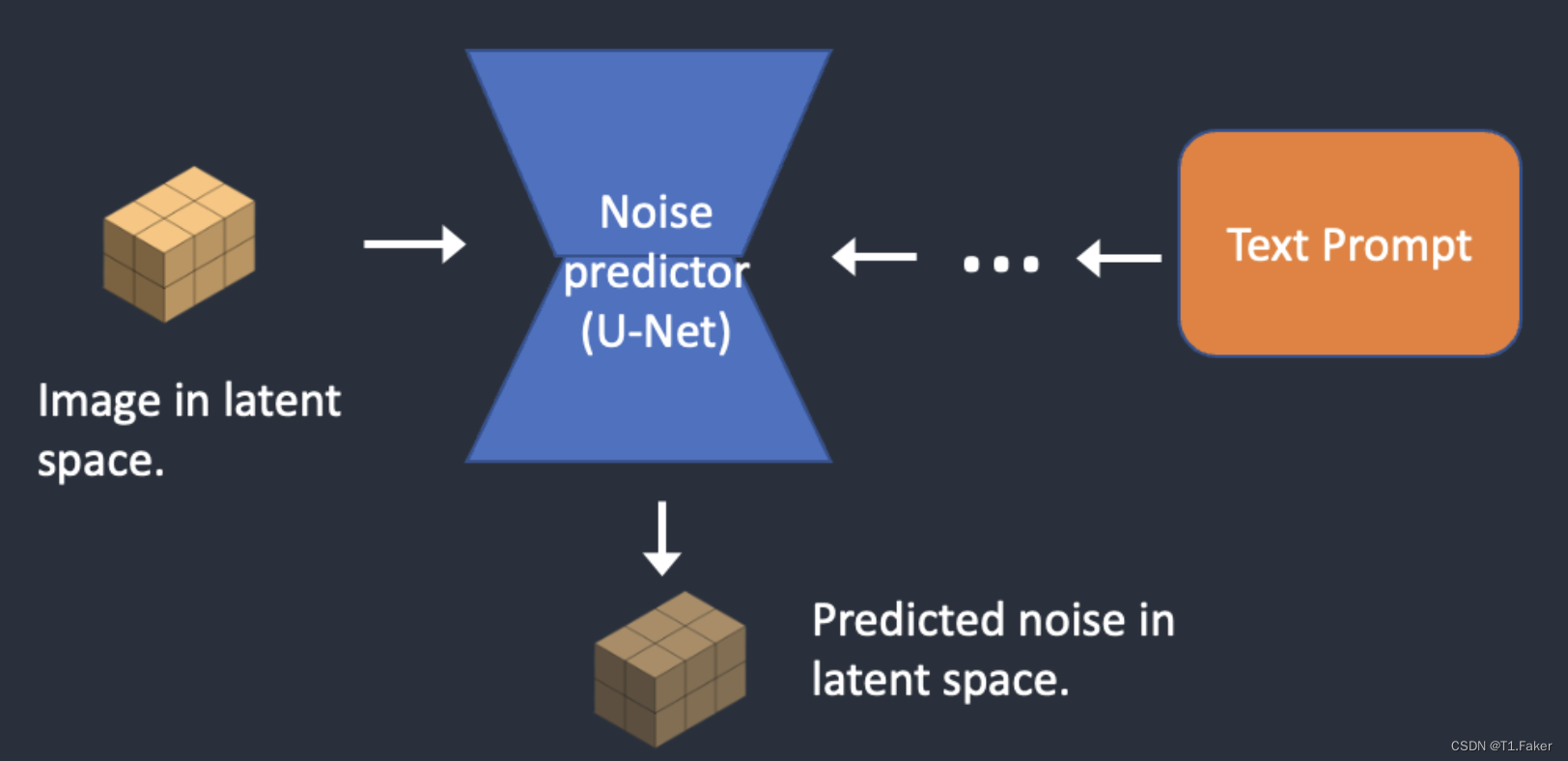
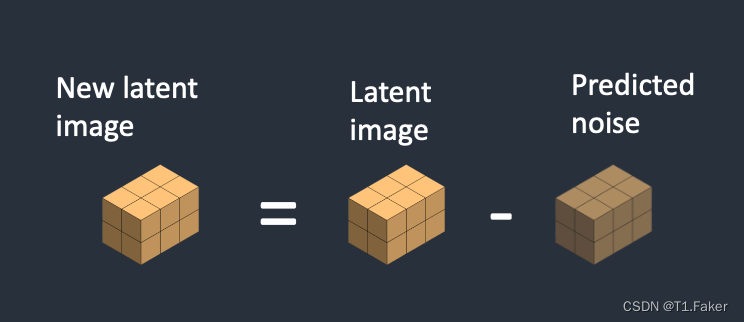
步骤3:从潜在图像中减去潜在噪声。这将成为新的潜在图像。
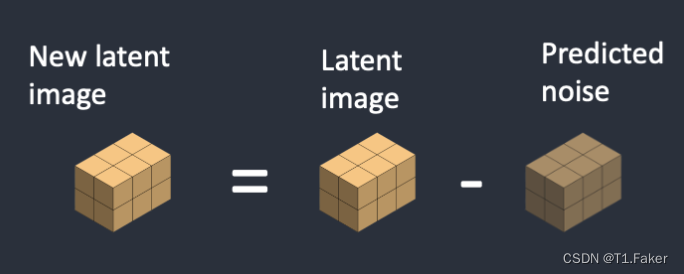
步骤4:重复步骤2和3,直到达到特定的采样步骤,例如,20次。
步骤5:最后,VAE的解码器将潜在图像转换回像素空间。这是运行Stable Diffusion后得到的图像。
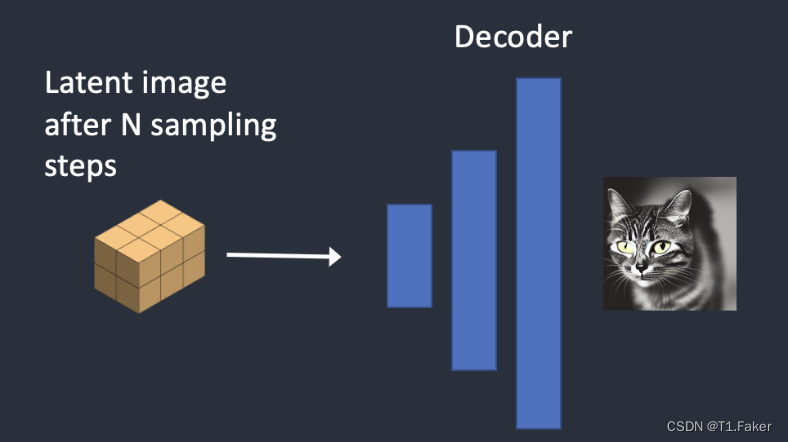
以下是如何在每个采样步骤中对图像进行演变。

6.2 噪声进度表
图像从嘈杂到清晰。你是否想知道噪声预测器在初始步骤中是否工作不好?实际上,这只是部分正确。真正的原因是我们尝试在每个采样步骤中获得预期的噪声。这被称为噪声进度表。下面是一个例子。
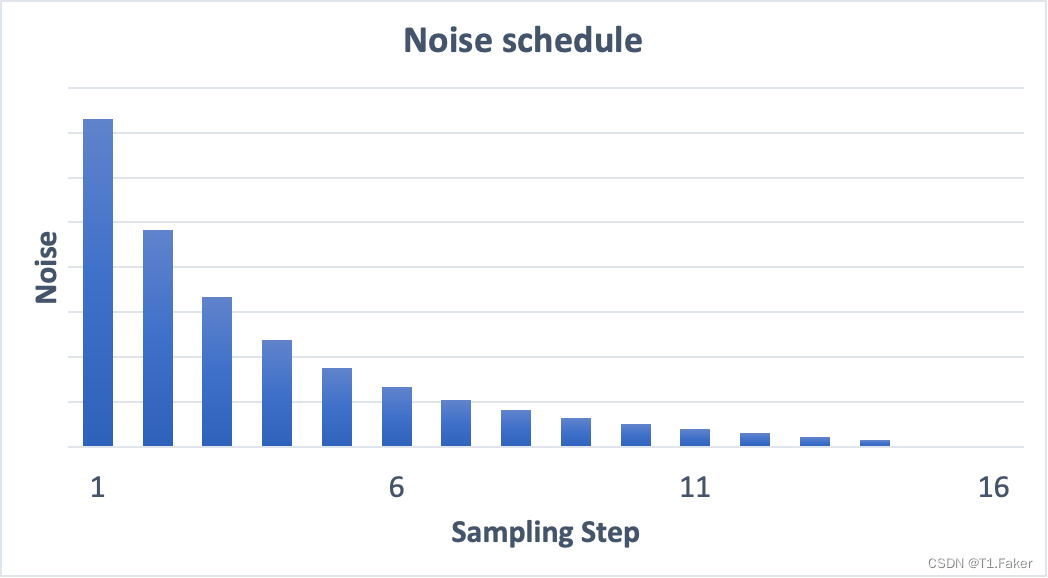
噪声进度表是我们定义的。我们可以选择在每一步中减去相同数量的噪声。或者我们可以在开始时减去更多,就像上面那样。采样器在每一步中刚好减去足够的噪声,以在下一步中达到预期的噪声。这就是你在逐步图像中看到的。
6.3 从图像到图像
图像到图像使用Stable Diffusion将一幅图像转换为另一幅图像。这首次在SDEdit方法中提出。SDEdit可应用于任何扩散模型,因此我们有了Stable Diffusion的图像到图像(潜在扩散模型)。
在图像到图像中,输入包括输入图像和文本提示。生成的图像将受到输入图像和文本提示的条件影响。例如,使用下图中的素描和提示“带茎的完美绿苹果照片,水滴,戏剧性光线”作为输入,图像到图像可以将其转换为专业的图画:

现在让我们逐步了解这个过程。
步骤1:将输入图像编码到潜在空间。
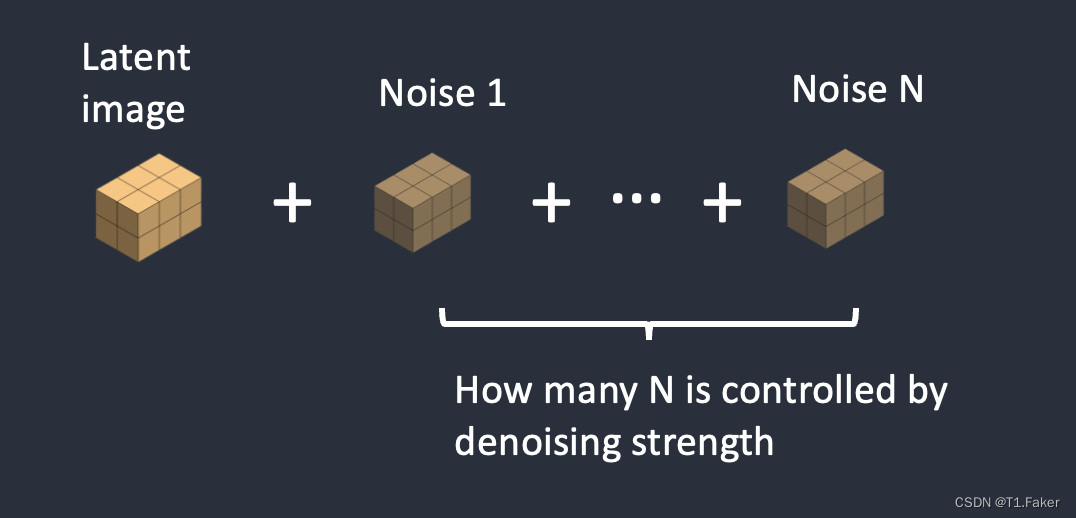
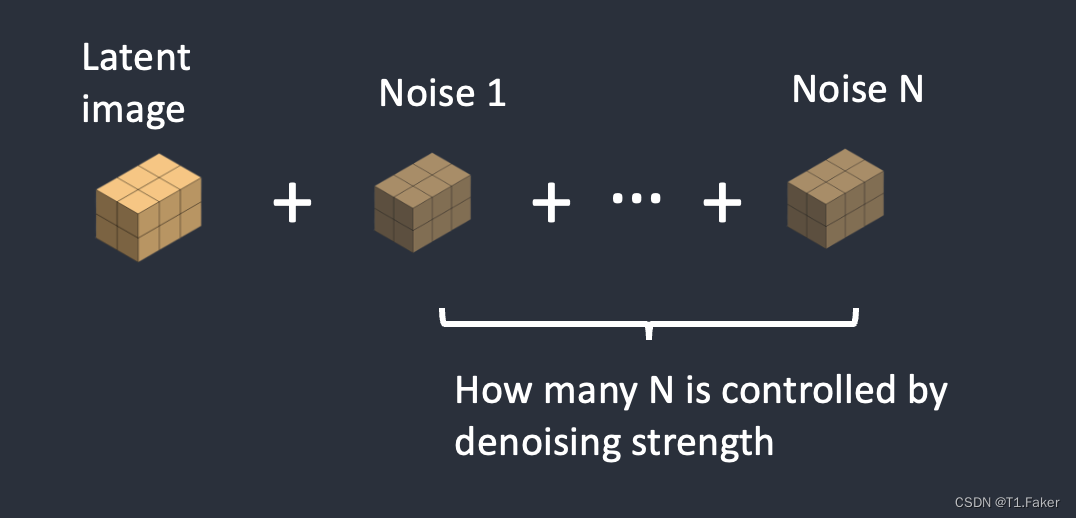
步骤2:在潜在图像中添加噪声。去噪强度控制添加多少噪声。如果为0,则不添加噪声。如果为1,则添加最大量的噪声,使潜在图像成为完全随机的张量。
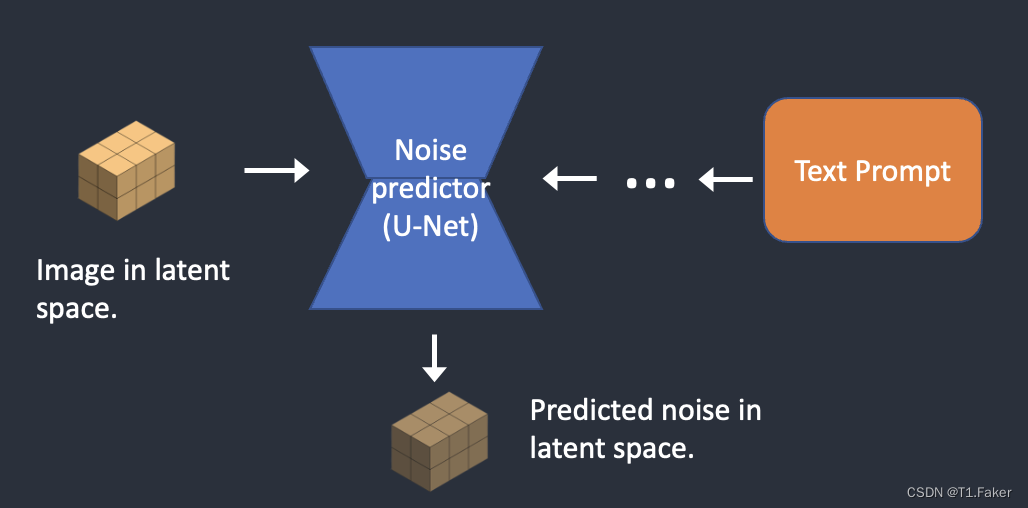
步骤3:噪声预测器U-Net以潜在嘈杂图像和文本提示作为输入,并预测潜在空间中的噪声(一个4x64x64的张量)。
步骤4:从潜在图像中减去潜在噪声。这将成为新的潜在图像。

步骤3和4在一定数量的采样步骤中重复,例如20次。
步骤5:最后,VAE的解码器将潜在图像转换回像素空间。这是运行图像到图像后得到的图像。
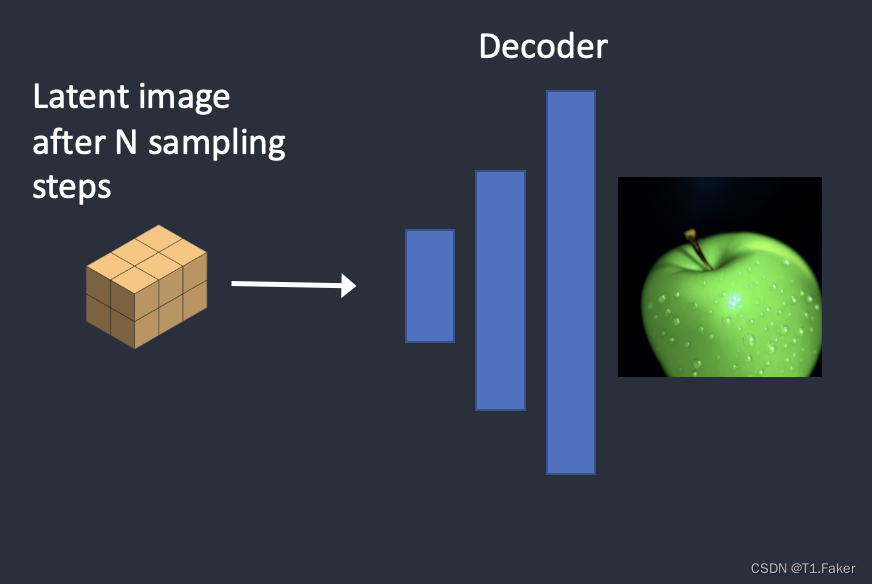
所以现在你知道图像到图像是什么了:它只是在初始潜在图像中加入一些噪声和输入图像。将去噪强度设置为1等同于文本到图像,因为初始潜在图像完全是随机的。
6.4 补白
修复图是图像到图像的一个特殊案例。在你想要修复图像的部分添加噪声。噪声的数量同样由去噪强度控制。
6.5 深度到图像
深度到图像是图像到图像的增强版本;它使用深度图生成带有额外条件的新图像。
步骤1:将输入图像编码成潜在状态。
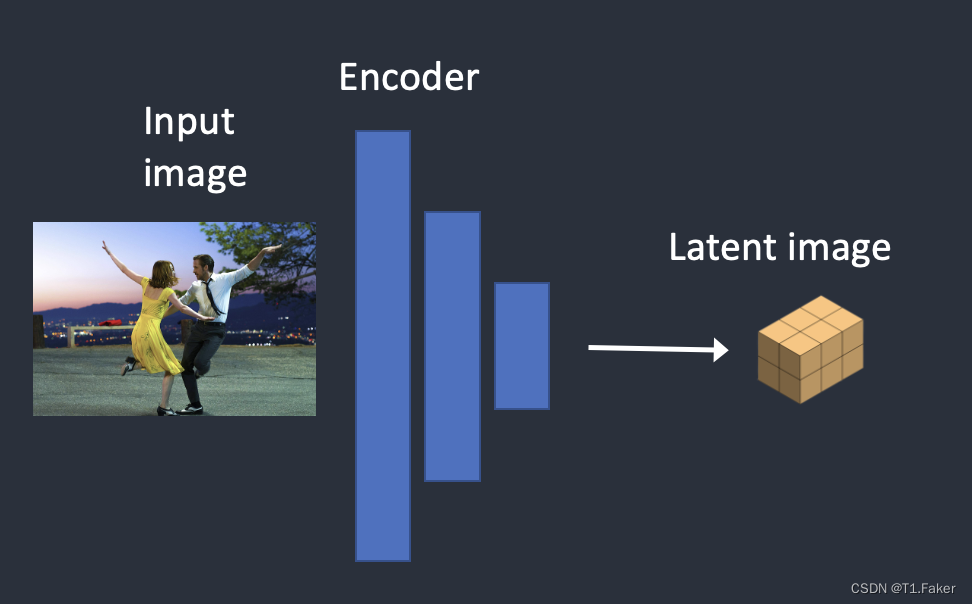
步骤2:MiDaS(一种AI深度模型)从输入图像估计深度图。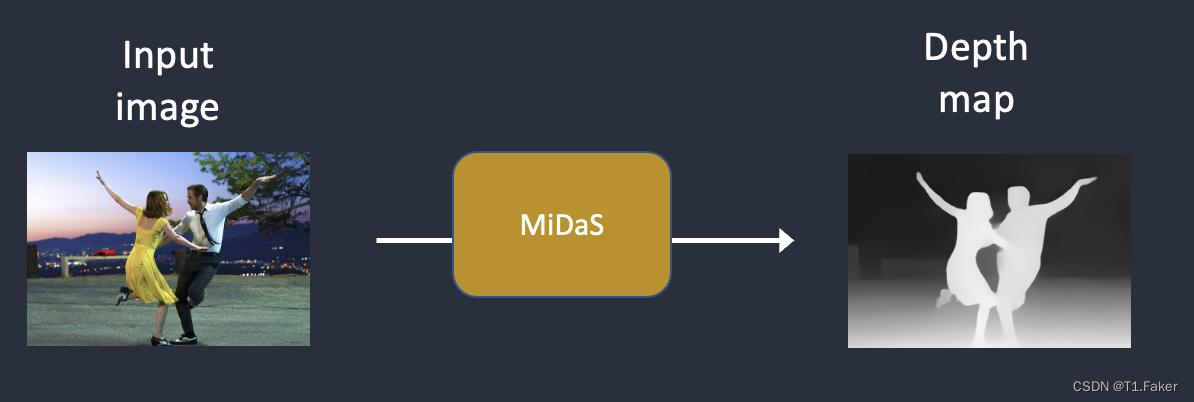
步骤3:在潜在图像中添加噪声。去噪强度控制添加多少噪声。如果去噪强度为0,则不添加噪声。如果去噪强度为1,则添加最大噪声,使潜在图像成为一个随机张量。
步骤4:噪声预测器估计潜在空间的噪声,由文本提示和深度图条件控制。
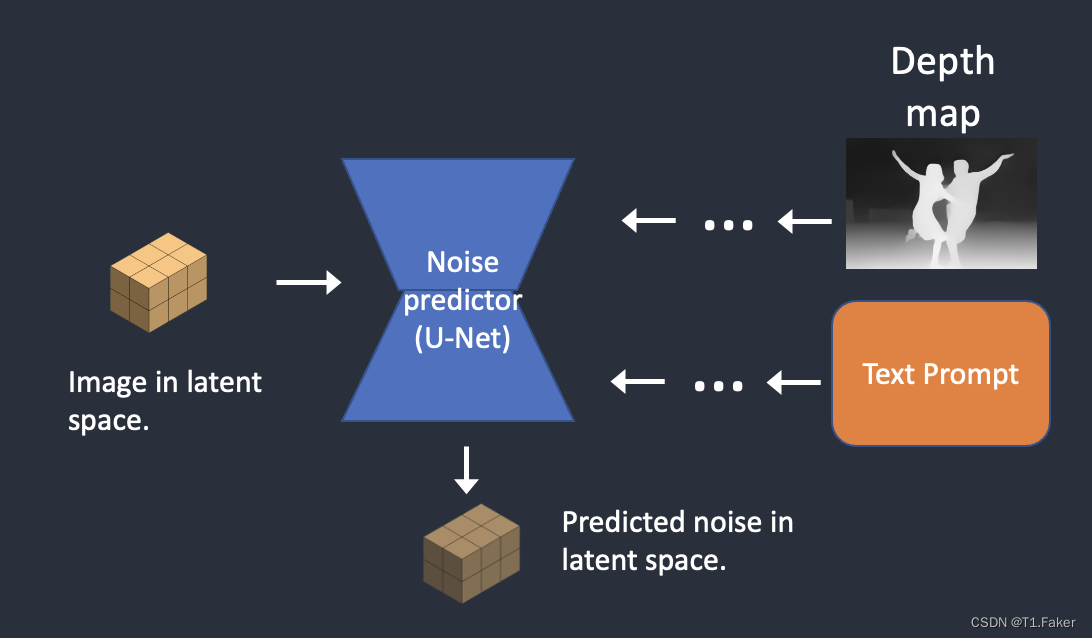
步骤5:从潜在图像中减去潜在噪声。这将成为新的潜在图像。
步骤4和5在一定数量的采样步骤中重复。
步骤6:VAE的解码器解码潜在图像。现在,你从深度到图像得到了最终图像。
7. 什么是CFG值?
这篇文章不完整,没有解释分类器免费引导(CFG),这是AI艺术家每天都在调整的一个值。为了理解它是什么,我们首先需要谈谈它的前身,分类器引导…
7.1 分类器引导
分类器引导是将图像标签纳入扩散模型的一种方式。你可以使用标签来指导扩散过程。例如,标签“cat”会引导反向扩散过程,生成猫的照片。
分类器引导尺度是一个用于控制扩散过程应该多紧密地遵循标签的参数。
下面是我从这篇论文中偷来的一个例子。假设有三组图像,分别带有标签“cat”、“dog”和“human”。如果扩散是未引导的,模型将从每组总体中抽取样本,但有时可能会抽取适合两个标签的图像,例如一个男孩抚摸一只狗。
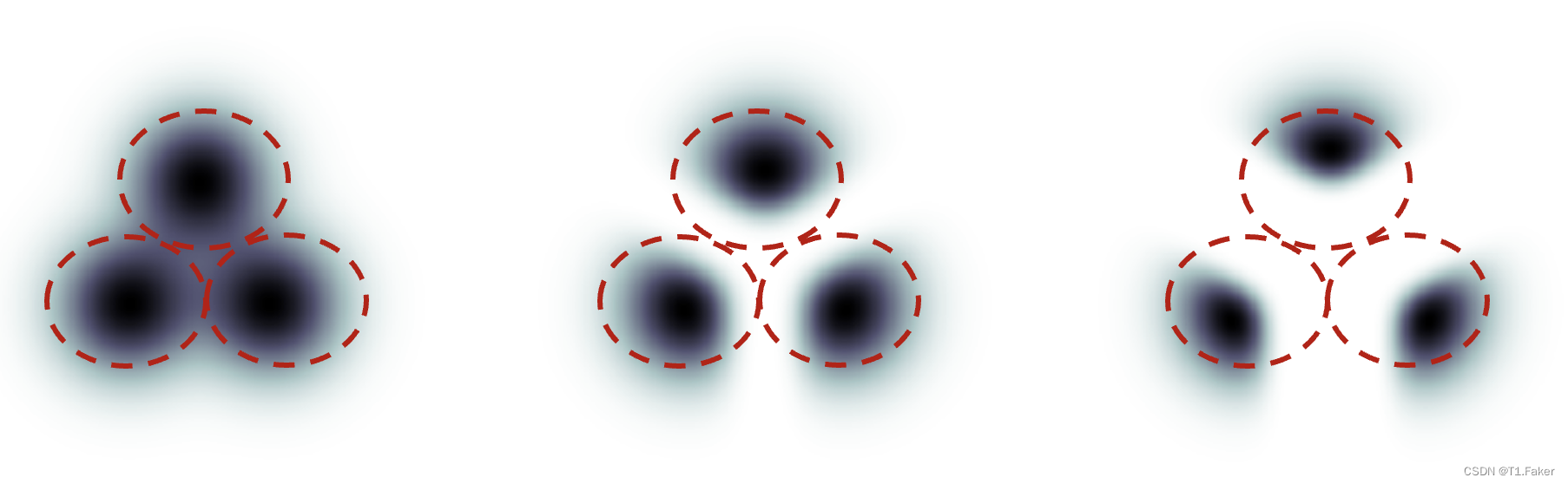
分类器引导。左:未引导。中:小引导尺度。右:大引导尺度。
通过高分类器引导,扩散模型生成的图像将偏向极端或明显的示例。如果你向模型询问一只猫,它将返回一张明显是猫而没有其他东西的图像。
分类器引导尺度控制引导的密切程度。在上图中,右侧的采样具有比中间的更高的分类器引导尺度。在实践中,该尺度值简单地是朝着具有该标签数据的漂移术语的乘法器。
7.2 无分类器引导
尽管分类器引导取得了创纪录的性能,但它需要额外的模型来提供引导。这在训练中带来了一些困难。
无分类器引导,根据其作者的说法,是一种实现“无分类器引导”的方式,即“没有分类器的分类器引导”。与使用类标签和一个单独的模型进行引导不同,他们建议使用图像标题并训练一个条件扩散模型,就像我们在文本到图像中讨论的那样。
他们将分类器部分作为噪声预测器U-Net的条件,实现了所谓的“无分类器”(即没有单独的图像分类器)引导图像生成。
文本提示在文本到图像中提供了这种引导。
7.3 无分类器引导尺度
现在,我们有了使用条件的无分类器扩散过程。我们如何控制AI生成的图像应该多么遵循引导?
无分类器引导尺度(CFG尺度)是一个值,用于控制文本提示应该如何引导扩散过程。当CFG尺度设置为0时,AI图像生成是无条件的(即忽略了提示)。较高的CFG尺度将扩散引导到提示。
8.Stable Diffusion v1.5 vs v2
这已经是一篇很长的文章了,但如果不比较v1.5和v2模型之间的差异,它将不完整。
8.1 模型差异
Stable Diffusion v2使用OpenClip进行文本嵌入。Stable Diffusion v1使用Open AI的CLIP ViT-L/14进行文本嵌入。更改的原因有:
- OpenClip是ViT-G/14型号的5倍大。更大的文本编码器模型提高了图像质量。
- 尽管Open AI的CLIP模型是开源的,但这些模型是使用专有数据训练的。切换到OpenClip模型使研究人员更容易研究和优化该模型。这对于长期发展更有利。
v2模型有两个版本:
- 512版本生成512×512的图像。
- 768版本生成768×768的图像。
8.2 训练数据差异
Stable Diffusion v1.4 is trained with
Stable Diffusion v1.4的训练数据为:
- 237k步,分辨率为256×256,使用laion2B-en数据集。
- 194k步,分辨率为512×512,使用laion-high-resolution数据集。
- 225k步,分辨率为512×512,“laion-aesthetics v2 5+”数据集,文本条件下降10%。
Stable Diffusion v2的训练数据为:
- 550k步,分辨率为256×256,使用LAION-5B的子集,过滤掉显式色情材料,使用LAION-NSFW分类器,punsafe=0.1,美学评分>=4.5。
- 850k步,分辨率为512×512,相同数据集,图像分辨率>=512×512。
- 150k步,使用相同数据集的v目标。
- 再次在768x768图像上进行140k步的继续训练。
Stable Diffusion v2.1在v2.0的基础上进行了微调:
- 在相同数据集上额外进行了55k步(punsafe=0.1)。
- 使用punsafe=0.98进行了额外的155k步。
实质上,他们在最后的训练步骤中关闭了NSFW过滤器。
8.3 结果差异
用户普遍发现使用Stable Diffusion v2难以控制风格和生成名人。虽然Stability AI并未明确过滤掉艺术家和名人的名称,但它的效果在v2中要弱得多。这可能是由于训练数据的差异造成的。Open AI的专有数据可能包含更多的艺术品和名人照片。他们的数据可能经过高度筛选,使得一切都看起来美好漂亮。
v2和v2.1模型并不受欢迎。人们主要使用经过微调的v1.5和SDXL模型。
9. SDXL模型
SDXL模型是v1和v2模型的官方升级版。该模型以开源软件的形式发布。
这是一个更大的模型。在AI领域,我们可以期望它更好。SDXL模型的总参数数量为66亿,而v1.5模型为9.8亿。
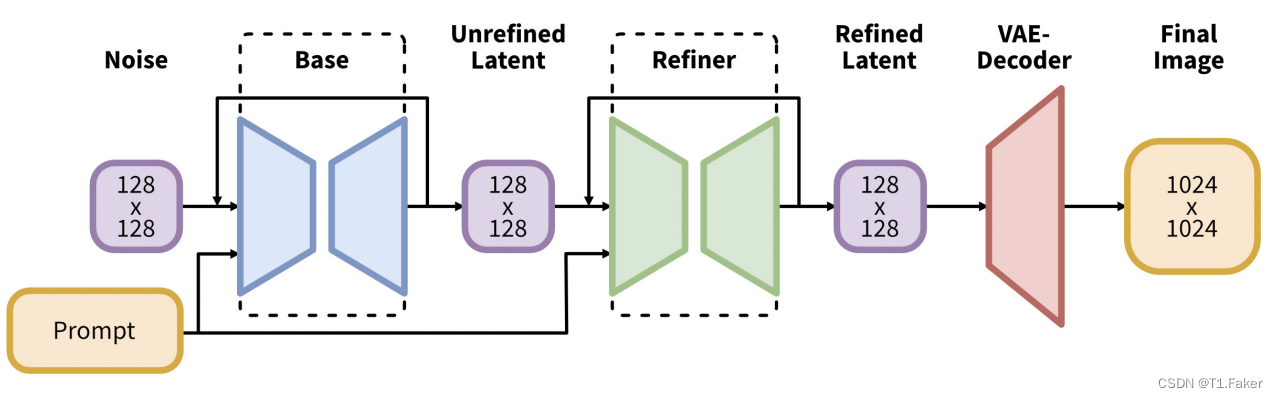
SDXL管道包括一个基础模型和一个细化模型。
实际上,SDXL模型是两个模型。您运行基础模型,然后是细化模型。基础模型设置全局组成,而细化模型添加更细的细节。
您可以仅运行基础模型,而不使用细化模型。
SDXL基础模型的变化包括:
- 文本编码器结合了最大的OpenClip模型(ViT-G/14)和OpenAI的专有CLIP ViT-L。这是一个明智的选择,因为它使得SDXL易于提示,同时保持了功能强大且可训练的OpenClip。
- 新的图像大小调整,旨在使用小于256×256的训练图像。这通过不丢弃39%的图像显著增加了训练数据。
- U-Net比v1.5大三倍。
- 默认图像大小为1024×1024。这比v1.5模型的512×512大4倍。 (查看与SDXL模型一起使用的图像尺寸)
请注意,由于篇幅原因,上述内容已经进行了适度的压缩和调整,以便更好地适应给定的文本段落。如果有其他具体的翻译需求或问题,欢迎随时提出。