AIGC也就是AI内容生成已经成为新一轮人工智能发展的热点和必然趋势,它使得大规模高质量的创作变得更加容易。
一 、InstructGPT模型
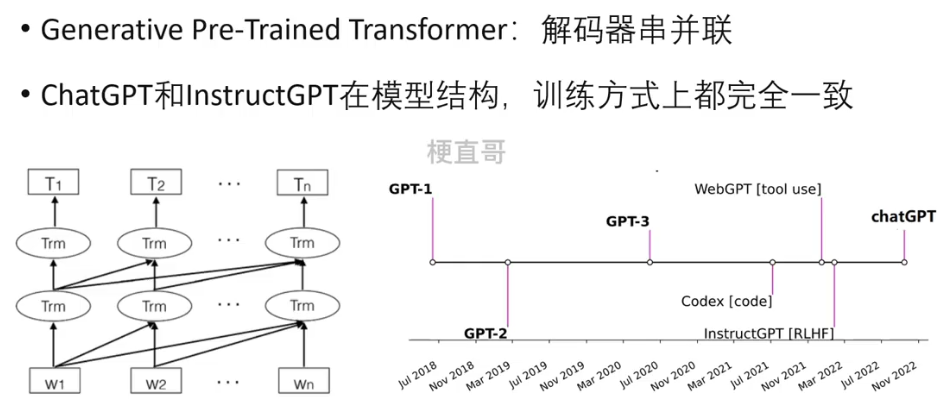
1、GPT系列回顾
chatGPT和InstructGPT都使用了指示学习和基于人工反馈的强化学习来指导模型的训练,不同点仅仅是在采集数据的方式上有所差异。
2、指示学习和提示学习
Instruct Learning:更加依赖于人类提供的示范数据和指令,给出明显的指令让模型做出正确的行动。
Prompt Learning:更加依赖于模型自身的推断能力,以及少量的提示信息。
很多情况下二者有重叠,都需要人类提供的信息和知识来训练模型,仅仅是在应用场景和关注点上有所不同。在InstructGPT中都会混用,所以本文不再刻意究其不同。
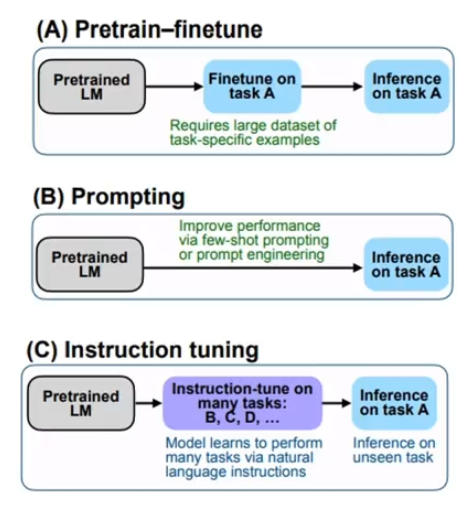
微调,也就是预训练模型的 finetuning ,它需要使用大量的下游数据集来进行训练;
而prompt Learning过程中的微调,需要少量下游数据集的样本;
而指示学习 Instructing tuning,是先通过在各种不同的下游任务上进行学习之后,再在未知的任务上进行预测。
指示学习和提示学习能够快速获得专业知识和技能,成为LLM大语言模型研究的热点之一;
能够有效的缩小模型搜索的空间,更准确学习到任务的关键特征和规律。
3、人工反馈强化学习 RLHF
RLHF: Deep Reinforcement Learning from Human Feedback
单纯训练得到的模型并不是非常可控的,模型是训练集分布的一个拟合,当用它来生成内容时,训练集的分布将极大影响生成内容的质量。
因此引入人类反馈提升模型的可控性,解决对齐 (alignment) 问题。
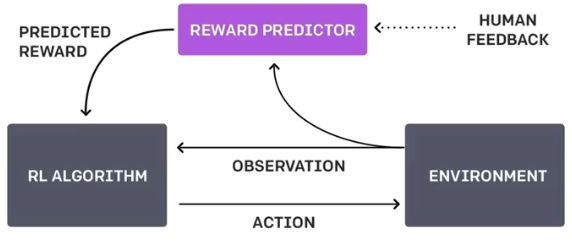
奖励机制其实可以看做传统模型训练的损失函数,只不过他的计算更加灵活多样,但是需要付出代价,代价就是奖励的计算时不可导的,因此不能直接拿来作反向传播;
强化学习的思路是通过对奖励大量采样来拟合损失函数,进而训练模型。
RLHF的研究最早可以追溯到谷歌2017年的一个研究:
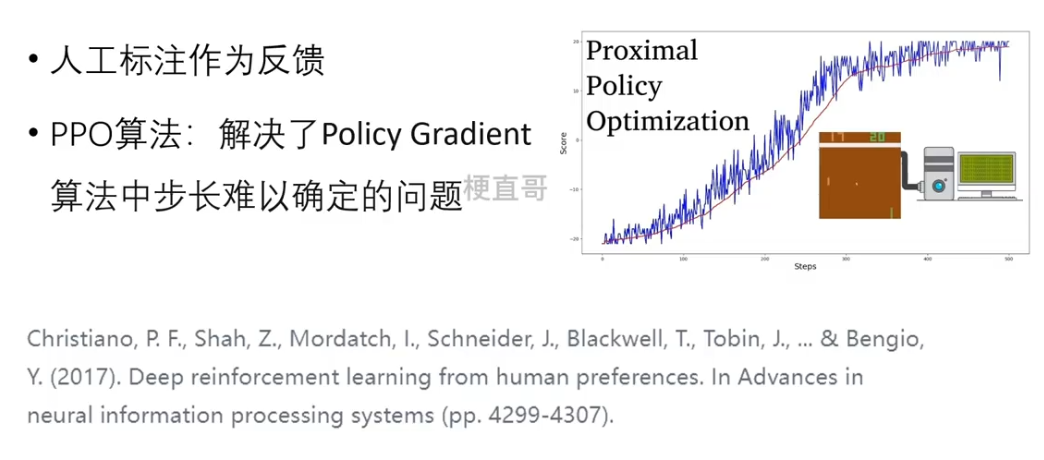
无论是chatGPT还是InstructGPT都用到了强化学习中的一个经典算法 —— PPO算法,近似策略优化,它的核心是解决了策略梯度算法中步长难以确定的问题。
4、训练流程
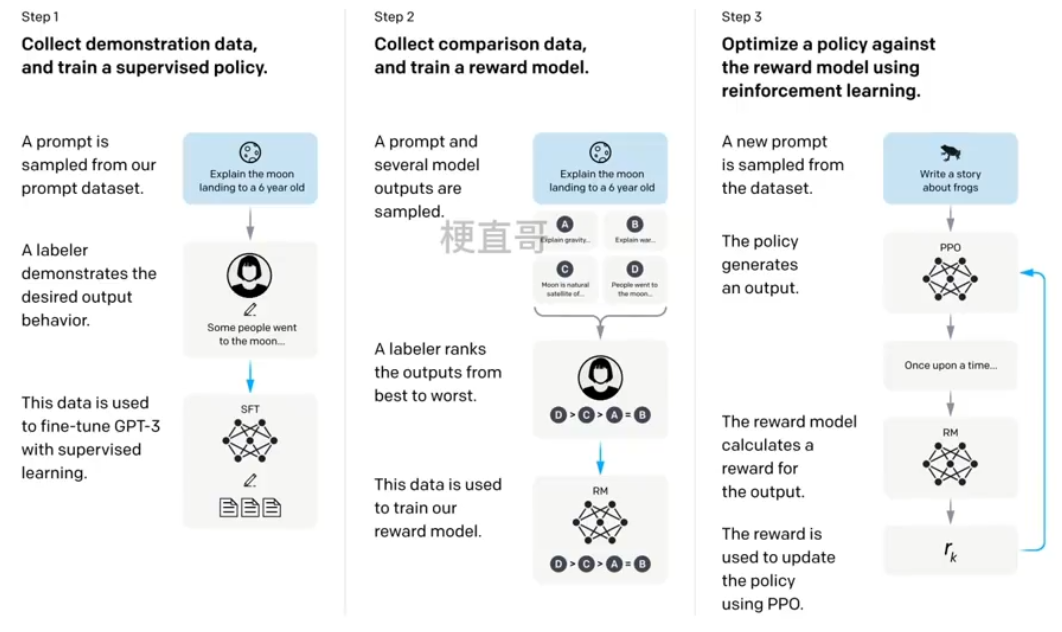
1.SFT 有监督微调
在GPT-3预训练模型的基础上进行标准的监督式学习。
2.RM modol 奖励模型
模型是SFT训练后模型去掉最后的嵌入层模型;
输入是提示+答案对,输出是奖励值;因为训练RM模型的数据是标注工根据生成的结果排序的形式,因此整体上可以看成是一个回归模型,实际上是一个标准的成对的排序算法。
对于每一个提示,InstructGPT都会随机生成 k 个输出,他们选择的k
是4~9,则对应C k 2个Q-A对,6~36个Q-A对。
损失函数目标是最大化人类喜欢的答案和不喜欢的答案之间的差值。
r 是奖励函数,yw 表示最喜欢的那个答案,yl 表示不喜欢的答案,σ 是差值归一化函数,D是整个的数据集,分母是Q-A对的总数 。
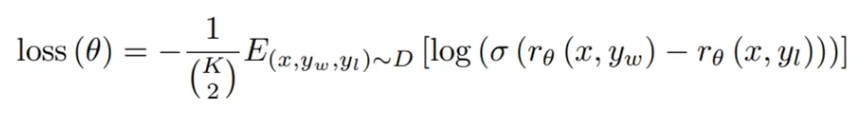
3.PPO 强化学习
将强化学习引入到预训练语言模型是最大创新点;
KL散度做惩罚项确保PPO模型的输出和SFT的输出差距不会很大;
加入预训练语言模型,目标是保证通用NLP任务上的性能。
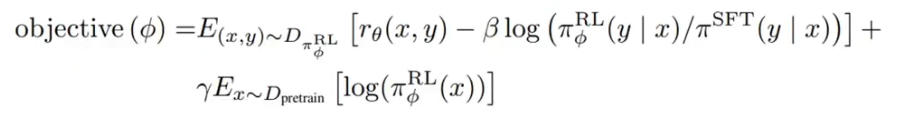
5、数据集采集
SFT数据集:提示-答案对,来自于OpenAl的playground和人工标注;
RM数据集:模型生成候选文本,然后人工排序打分;
PPO数据集:无人工标注答案,问题来自用户。
与Instruct数据集的不同:
chatGPT提高了对话任务的占比,将提示的方式转化成了问答式的方式。
6、优缺点
优点
效果比GPT-3更加真实;
无害性比GPT-3效果有提升;
具有很强的Coding能力。
缺点
降低了通用NLP任务上的效果;
有时会给出一些荒谬的输出;
模型对指示非常敏感;
模型对简单概念的过分解读;
对有害指示依然输出有害答案。
二、 CLIP模型
Contrastive Language-lmage Pre-Training
它是openAI在2021年初在多模态领域提出的优秀模型,延续了GPT系列大力出奇迹的传统,使用了超过四亿的图像文本对,在图像检索、地理定位、视频动作识别等很多多模态任务上取得了非常好的效果。
1、核心思想
在计算机视觉领域,最常采用的迁移学习方式就是,先在一个较大规模的数据集,比如imagenet上预训练,然后再在具体的下游任务上进行微调,这里的预训练是基于有监督训练的,往往需要大量的数据标注,因此成本较高。
近些年来出现了一些基于自监督的方法,但是无论是有监督还是自监督的方法,他们在迁移到下游任务时,还是需要进行有监督的微调,当标签更改时,需要重新训练整个模型,因而无法实现零样本学习 zero-shot。
在NLP领域,基于自回归以及语言掩码的预训练方法已经取得了很不错的成绩,相对来说比较成熟,而且预训练模型很容易进行zero-shot,比如openAI的GPT-3。
这种差异一方面是由于文本和图像属于两个不同的模态,另外一个原因是NLP模型可以采用从互联网上收集的大量文本。
那么,能不能采用互联网上收集的大量文本来训练视觉模型呢?
CLIP模型的主要思想就是 将图像和文本映射到同一个特征空间。
比如,当我们看到“修狗狗”这个文字和看到小狗的图片时,心中想的都是狗,那么心中的这个“狗”,就是这里的特征空间了。
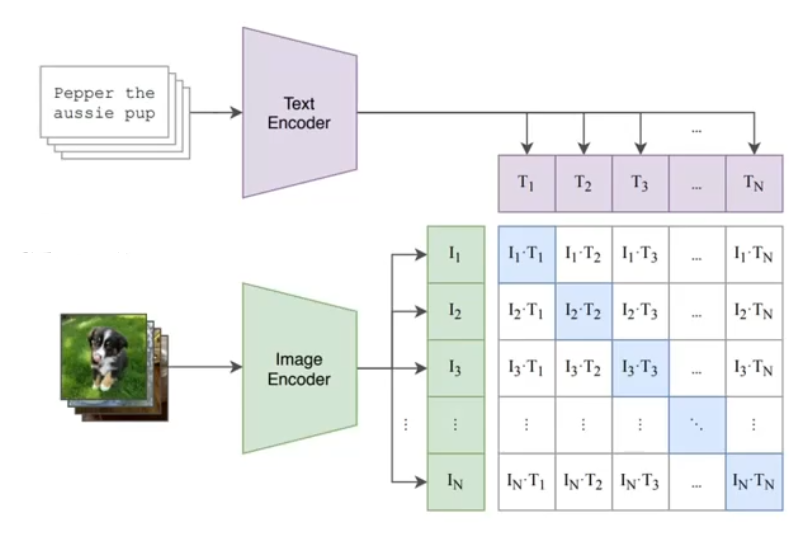
2、对比学习预训练
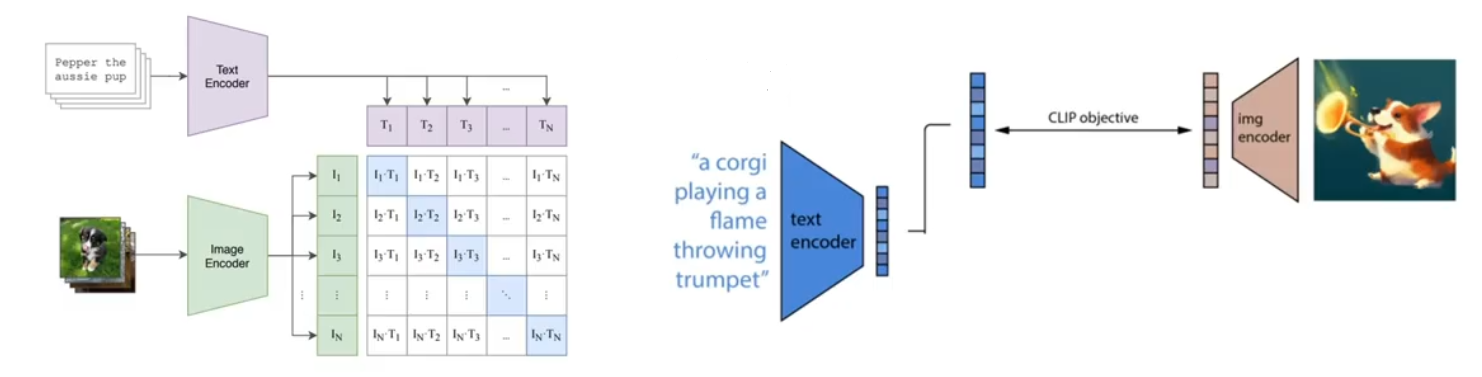
CLIP的整个模型是由 图像 + 文本,两个编码器 构成的。训练过程中取到的每一个batch都是由 n 个图像和文本对组成的,经过两个编码器后,会分别得到 n 个图像特征向量 I 和 n 个文本特征向量 T。
两两组合可以得到 n方 个相似度,也就是上图中的矩阵。
其中对角线上的 n 个文本-图像对是正样本,剩余的是 负样本。
训练的目标就是:最大化正样本相似度,最小化负样本相似度。
3、图像编码器
五个不同的残差网络
ResNet-50作为基础模型。
引入了模糊池化,核心是在降采样之前加一个高斯低通滤波。
将全局平均池化 (GlobalAverage Pooling) 替换为注意力池化(Tranformer中介绍的自注意力)。
ResNet-50、ResNet-100, ResNet-50x4, ResNet-50x16, ResNet-50x64
三个不同的ViT模型
在patch embedding和position embedding后添加一个LN层。
更换了初始化方法。
一共训练了ViT-B/32,ViT-B/16以及ViT-L/14三个模型。
4、文本编码器
使用的是标准的Transformer。
5、数据收集
WIT数据集(Weblmage Text):总量超过4亿图像-文本对。
6、应用 —— 图像分类
与CV中常用的先预训练然后微调不同,CLIP模型可以直接实现zero-shot分类,也就是说不需要任何的训练数据就能在某个具体的下游任务上实现分类,这也是CLIP模型的亮点和强大之处。具体来说有两步:
1、将所以得类别文本转换为句子,将句子映射成一组特征向量。
2、待识别图像映射为特征向量。
3、看两个特征向量相似度。
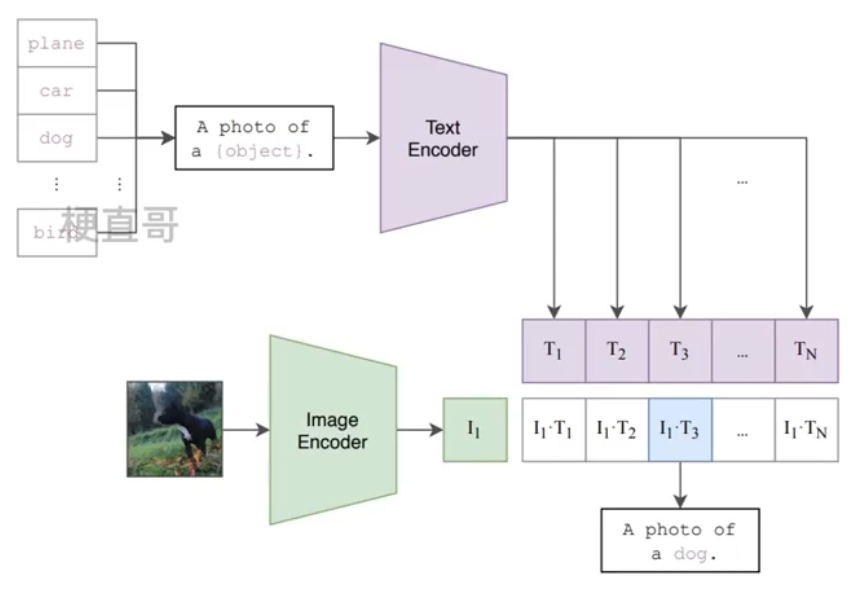
可以看到CLIP模型的多模态特性为具体任务构建了动态的分类器,其中文本decoder提取的文本特征可以看成是分类器的权重,而图像特征是分类器的输入。
7、模型训练情况
训练32个epochs;
采用Adamw优化器;
batch size: 32768;
ResNet50在592个V100卡上训练18天;
ViT-L/14需要在256张V100卡上训练12天。
8、优缺点
采取了对比学习的训练方式,可以在一个大小为 n 的batch中,同时构建 n方 个训练目标,因此实现简单快捷、训练高效。
其次,图像对应的标签不再是一个值,而是一个句子,这就让模型映射到足够细颗粒度的类别上提供了可操作的空间,可以对这个细颗粒度进行人为的控制,进而规避一些政治等敏感话题。
CLIP模型的学习不再是图像中的一个物体,而是整个图像中的所有信息,不仅包含图像中的目标,还包含这些目标中的语义、位置等逻辑关系,这就使得将CLIP模型迁移到任何计算机视觉模型上成为可能。
数据集未开源,通用效果有待提升。
零样本学习能力有限。
9、应用领域
zero-shot检测、图像检索、视频理解、图像生成、图像描述、视觉问答。
三、DALL-E模型
这是openAI的另一个多模态预训练模型。他的名字来自皮克斯动画电影《怪兽电力公司》中的一个角色。最显著的效果是在文本和图像的生成上达到以假乱真,这个系列目前有两代,2021年发布的初代和2022年发布的DALL-E 2。
1、初代模型结构
DALL-E的目标是把文本token和图像token当成一个数据序列,通过Transformer进行自回归。
由于图片的分辨率很大,如果把单个像素当做token来处理会导致计算量过于庞大,于是引入了一个 dVAE 模型(离散VAE模型)来降低图片的分辨率。
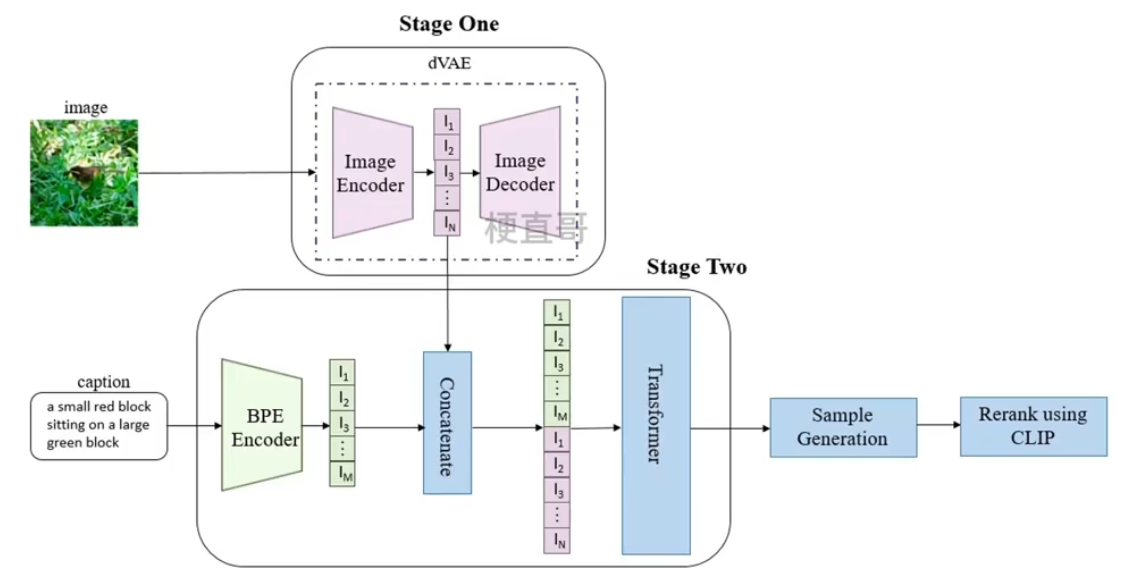
整个模型的结构分为三部分:
1、将256x256大小的图片,分成32x32的patch,然后使用训练好的 dVAE 模型中的编码器encoder将每个patch映射到大小为 8192 的词表中,最终将一张图片转化为用1024大小的token来表示。
DALL-E的dVAE的编码器和解码器都是基于残差网络构建的,保持基础结构的同时做了一些调整,比如编码器输入层卷积核的大小选择7x7,最后卷积层的卷积核大小选择的是1x1,这样产生大小是 32x32x8192 的特征图,其中采用最大池化而非原来的平均池化进行下采样等等。
2、使用BPE Encoder对文本进行编码。BPE是byte pair encoding的缩写,是一种基于字符级别的文本压缩技术,主要思想是不断地把出现频率最高的字符或者字符序列合并成一个新的符号,经过BPE Encoder之后最多得到256个token,如果不满256就进行填充;
再把这256个文本token与上面第一个阶段得到的1024哥图像token进行拼接,最后得到长度为1280的数据向量,喂给Transformer模型。
3、样本生成、基于CLIP的排序模块,主要用于推理阶段。
(1)dVAE模块
VAE变分自编码器:在 all to encoder也就是自编码器的基础上给浅空间变量添加了限制条件,让他服从高斯分布,这样通过训练得到的Decoder就可以直接使用了。
将随机生成的一个高斯分布喂给decoder就能生成图片。
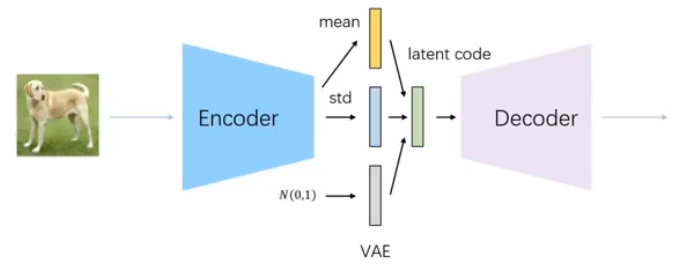
dVAE:编码器和解码器的结构比较简单,主要用来为图像的每个patch生成token,但是与常见的VAE相比有两点区别:
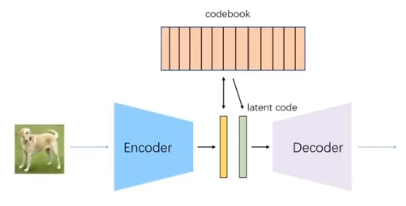
1、编码器将图像的patch映射到8192的词表,他的分布设为在词表向量上的均匀分类分布,由于是一个离散分布,存在不可导的问题,所以使用了Gumbel-SoftMax trick解决不可导问题。
(简单来说就是 arg max是不可导的,转换成了 arg softmax 是可导的。)
2、提出了 logit-Laplace分布 解决重建图像时真实像素值与高斯分布不匹配问题。重建图像时,真实像素值是在有界区间内的,而VAE中使用的是高斯分布和拉普拉斯分布,他们都是在整个实数集上,这就造成了模型目标和实际生成内容的一种不匹配。
logit-Laplace分布的核心思想就是将 sigmiod 作用到拉普拉斯分布的随机变量上从而得到的值域是在0-1之间的随机变量。
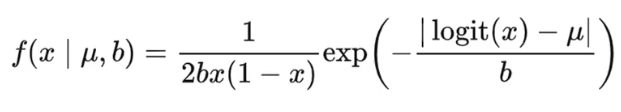
(2)Transformer模块
64层注意力层,每层注意力头数为62,每个注意力头维度为64
每个token的向量表示维度为3968 = 62x64
此外如下图所示,注意力层使用了三种稀疏的注意力计算方式:

上图为稀疏注意力方式,分别为行注意力、列注意力、卷积注意力。
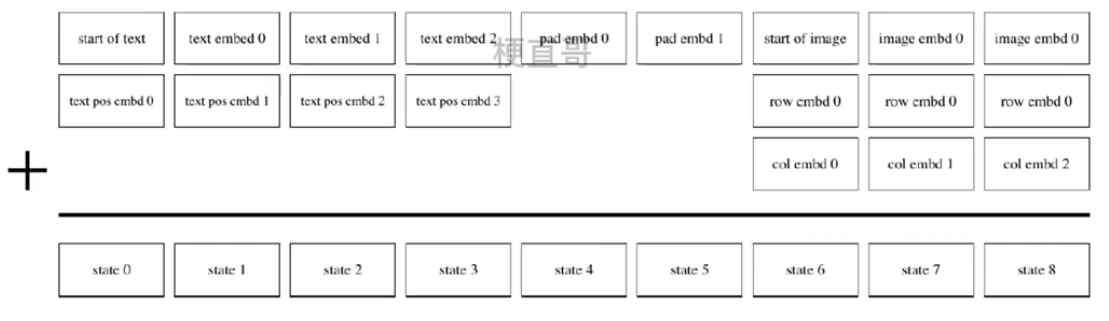
Transformer的输入如下:
pad embd 0是通过学习得到的,为每个位置都训练了一个pad embd,也就是说有256个pad embd,那么在对文本token进行embd时,使用相对应位置的pad embd。
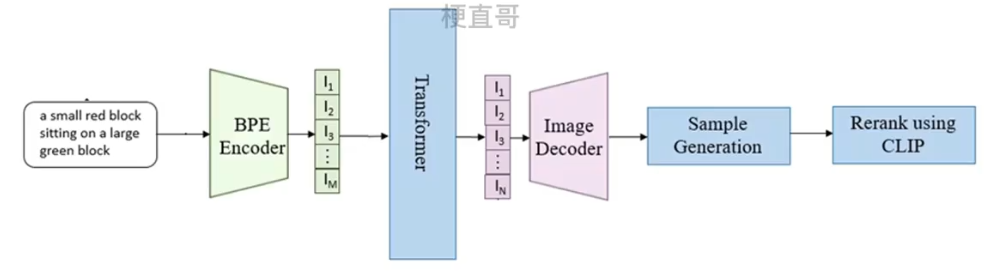
2、推理部分 —— 图像生成流程
输入文本通过BPE Encoder编码成特征向量,
送入自回归的Transformer中生成图像token,
再将图像token进入dVAE解码器中得到生成图像,再用CLIP评估,得到最终结果。
3、DALL-E 2 模型结构
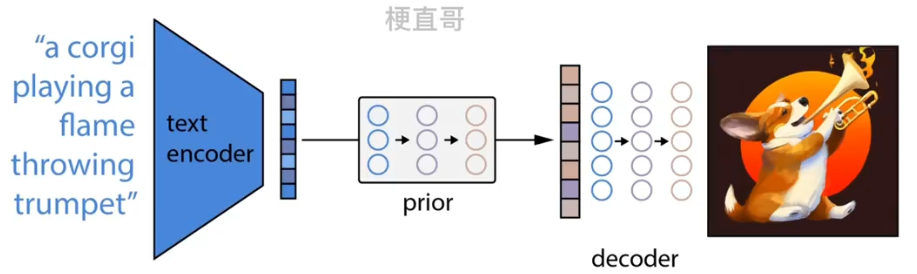
整个模型包括三个部分:CLIP、先验模块prior和img decoder。
虚线上面的部分为CLIP模块。
模型在训练时,各个子模块先分开训练,然后再拼接起来。
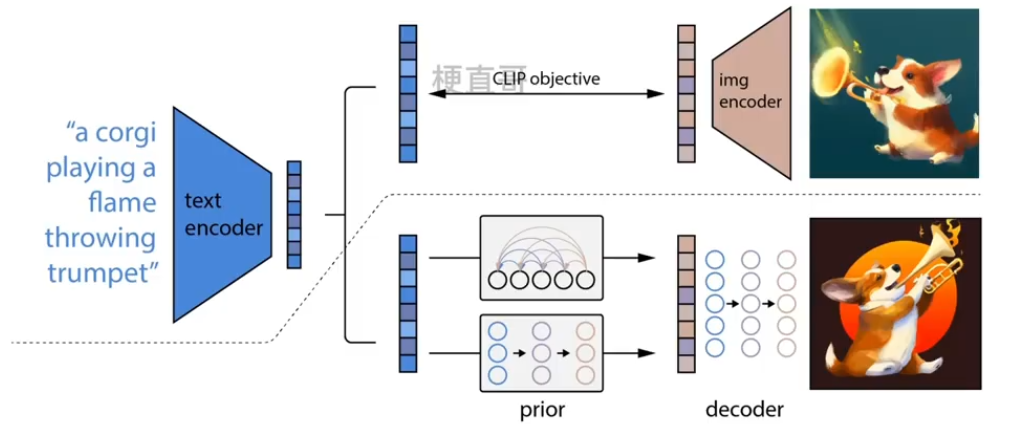
(1)CLIP模块
与CLIP模型的训练方式完全一样,目的是得到训练好的text encoder和img encoder,编码文本和对应图像。
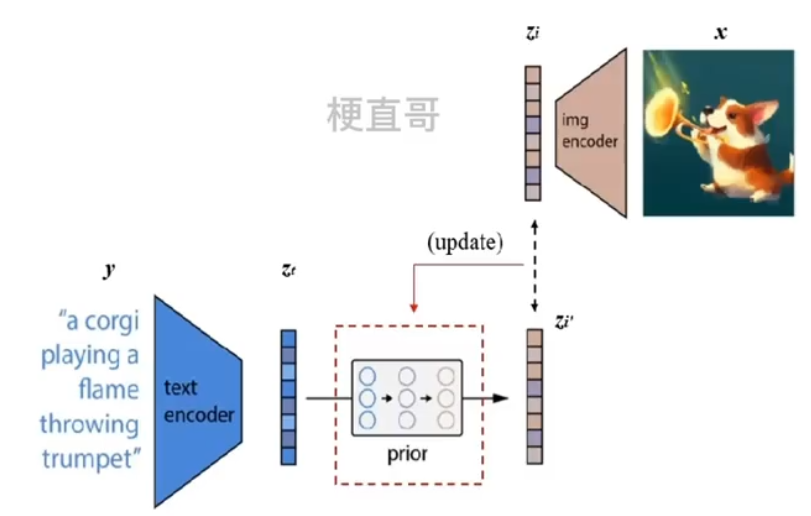
(2)Prior模块
先将CLIP中训练的文本编码器拿出来,输入一个文本 y,得到文本的编码 zt;
同样将CLIP中训练的图像编码器拿出来,输入一个图像 x,得到图像的编码 zi;
Prior模块训练的目标就是根据 zt 来获取对应的 zi,zt 通过 Prior之后的输出是zi‘ ,zi‘ 和 zi 之间的差异即为损失函数,从而更新Prior。
再将训练好的Prior和文本编码器串联起来,就可以根据输入的文本y,生成对应的图像编码特征 zi 了。
具体来讲,Prior可以使用 扩散 模型实现。
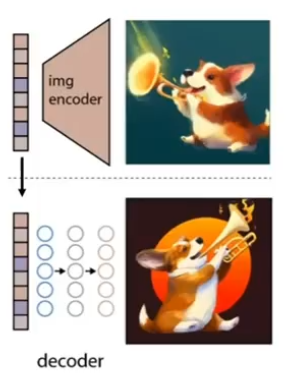
(3)Decoder模块
从图像特征 zi 还原出真实图像 x ,但又不完全一样,便于多样化生成。
具体来说使用的是GLIDE模型。
4、DALL-E 2 推理过程
经过上面三个步骤的训练,就完成了DALL-E 2预训练模型的搭建。
此时丢掉CLIP模块中的图像编码器,留下文本编码器,Prior,decoder。
文本编码器将文本进行编码,再由prior将其转换为图像编码最后由decoder进行解码生成图像。
5、模型效果

6、局限分析
1)容易将物体和属性混淆,不太能将红色上下分辨出来,这可能是由于CLIP模型的embedding过程没有将属性绑定在物体上,并且在解码器的重建过程中也经常混淆属性和物体。

2)将文本放入图像的能力不足。可能是CLIP模型的embedding不能精确的从文本当中提取出拼写的信息。
3)复杂场景下细节处理有缺陷。
参考
哔哩哔哩_bilibili